




Grounding Our Chat Towards Data Science Results
This is the third installment in a series. The first two posts introduce a basic vector database-only implementation of a chatbot using Milvus and a LlamaIndex implementation of the chatbot. We continue using LlamaIndex in this edition, but we will add something to “ground” our results. TruEra has a great commentary about groundedness and a short description in one of their RAG evaluation blogs.
In this article, we’ll cover how to ground our RAG results for Towards Data Science via LlamaIndex in three sections:
Setup for Grounding Our RAG Results
Defining the Parameters of Our Towards Data Science Chatbot
Grounding Our Results via Citations
Setup for grounding our RAG results
As with any app, the first step is to set up the prerequisites. For this example, we start off by installing four different libraries. We need llama-index, python-dotenv, pymilvus, and openai. These four libraries help us orchestrate our LLM with retrieval, manage our environment variables, work with a vector database, and work with OpenAI, respectively.
! pip install llama-index python-dotenv openai pymilvus
This next code block sets up OpenAI and Zilliz (the managed Milvus vector database). We use the load_dotenv function to pull our environment variables, typically stored in the '.env' file. Then, we pass the necessary variable names using os to get the values. OpenAI is our LLM, and Zilliz is our vector database. In this example, we use Zilliz and a collection stored in the cloud to persist our data across multiple app versions.
import os
from dotenv import load_dotenv
import openai
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
Defining the parameters for our Towards Data Science Chatbot
Next, we define the parameters of our RAG chatbot. We must set up three items: the embeddings model, the Milvus vector database, and the LlamaIndex data passing abstractions. First, we set up our embedding model. For this example, we use the embedding model we used in my previous blog to scrape and embed the data, which is the HuggingFace MiniLM L12 model. We can load this data via LlamaIndex using the HuggingFaceEmbedding module.
from llama_index.embeddings import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L12-v2")
Second, we set up the vector database. Since Zilliz Cloud is a fully managed and optimized version of Milvus, we can connect it using the MilvusVectorStore module. We provide the URI, token, collection name, similarity metric, and text key to connect to our Milvus instance hosted in Zilliz Cloud.
We got our Zilliz URI and tokens earlier from our environment variables. The collection name, similarity metric, and text key are inherited from the first part of this blog series, where we created the collection during ingestion.
from llama_index.vector_stores import MilvusVectorStore
vdb = MilvusVectorStore(
uri = zilliz_uri,
token = zilliz_token,
collection_name = "tds_articles",
similarity_metric = "L2",
text_key="paragraph"
)
Lastly, we get our LlamaIndex data abstractions together. The two natives we need are the service context, which passes in some predefined services, and the vector store index, which creates a LlamaIndex “index” from a vector store. We use the service context to pass our embed model in this case. Then we pass the existing Milvus vector database and the created service context to create our vector index.
from llama_index import VectorStoreIndex, ServiceContext
service_context = ServiceContext.from_defaults(embed_model=embed_model)
vector_index = VectorStoreIndex.from_vector_store(vector_store=vdb, service_context=service_context)
Grounding our results via citations in LlamaIndex
Citations and attributions are an important addition to your RAG. They allow you to know where the answers are coming from in your document corpus and evaluate how grounded your RAG results are.
LlamaIndex provides an easy way to implement citations via their CitationQueryEngine module. It’s super easy to get started with this module. Using from_args and passing in the vector index, we can instantiate a citation query engine. We defined the text field in the vector index earlier, so we don’t need to add anything.
from llama_index.query_engine import CitationQueryEngine
query_engine = CitationQueryEngine.from_args(
vector_index
)
Once we have a query engine, we only need to send a query. For this example, I’ve asked, “What is a large language model?” This is an answer that we expect to be able to get from Towards Data Science. I’ve also added pprint to pretty print the output.
res = query_engine.query("What is a large language model?")
from pprint import pprint
pprint(res)
The image below shows an example of what a response would look like. It has the answer and cites its sources in the text. It lets us know the answer is grounded and where it came from.
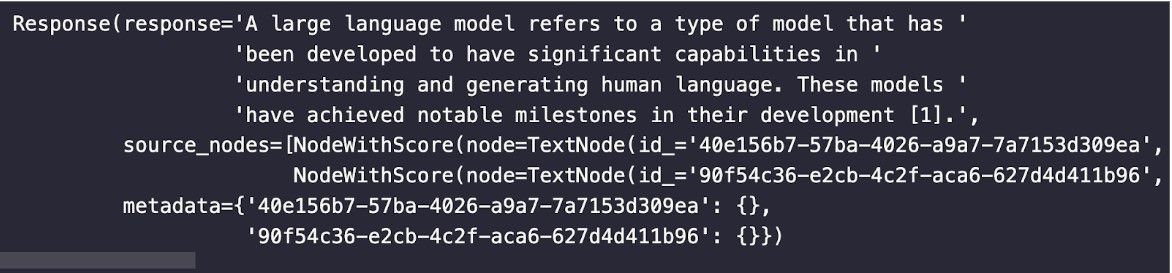
Summary of grounding RAG results via citations and attributions
This tutorial is the third in a series revolving around creating a chatbot via RAG. We use the same data from Towards Data Science for all these tutorials. This tutorial uses citations and attributions to ensure your results are grounded.
Citations and attribution solve two problems that RAG traditionally has. One, they allow us to know where we are pulling data from. Two, they allow us to see how “true” or responses are according to the data. This concept is also called “groundedness.”
We used LlamaIndex and Zilliz Cloud to build this RAG tutorial. LlamaIndex allows us to easily spin up an engine that will pull the citations as long as they exist in the vector store. Zilliz Cloud allows us to persist data easily across multiple projects.
To read the entire Chat Towards Data Science series again, here are the links:

Keep Reading

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.