




フルRAG:ハイパーパーソナライゼーションのためのモダン・アーキテクチャ
パーソナライゼーションは、多くのユーザー中心の製品にとって、長期的な顧客維持の鍵となる。例えば、ネットフリックスやディズニーは、パーソナライズされた映画のレコメンデーションを通じて、ユーザーの満足度を確保することができる。人工知能は、顧客の履歴データを活用し、製品にパーソナライゼーションを提供するさまざまな技術を提供する。
TectonのCEO兼共同創設者であるMike Del Balsoは、最近、Zilliz主催のUnstructured Data Meetupで、AIレコメンデーションエンジンのパーソナライゼーションを改善するためのRAGアーキテクチャの使用について講演した。
マイクは、あるコンサルティング・レポートで読んだ興味深い事実を共有した:「彼はまた、超パーソナライゼーションを実現するためのRAG(Retrieval Augmented Generation)に基づくアーキテクチャを発表した。
この記事では、AIを活用したパーソナライゼーションに関する彼の重要な洞察と、企業がどのように人工知能で製品をパワーアップできるかを振り返る。
生成AIモデルによるパーソナライゼーション
マイクは、Booking.comやMakeMyTripのような、超パーソナライズされた旅行レコメンデーションを備えた製品を作るというユースケースの例から始める。
GPTのような大規模言語モデル(LLMsは、膨大なテキストコーパスで訓練され、旅行の推奨を生成することができる。例えば、LLMに "今年の夏はどこに行くべきですか?"と問い合わせると、パリや東京のような、夏に最も人気のある目的地に基づいた回答が得られるだろう。しかし、このようなレコメンデーションを個々の顧客に合わせる方法が必要だ。
レコメンデーションモデルを改善するために、2つのテクニックが利用できる:微調整とプロンプトエンジニアリングです。
微調整](https://assets.zilliz.com/how_can_we_get_better_recs_6f8379061e.png)
これらのテクニックは、利用可能なトレーニングデータに基づいてモデルの応答をより適切なものにすることができますが、顧客の入力データを与える方法を提供するものではありません。Full-RAGはこの問題を解決できる手法である。Full-RAGが何であり、どのように機能するかを理解する前に、従来のRAGがどのように機能するかを復習しておこう。
##RAG入門
Retrieval Augmented Generation(RAG)は、品質と関連性に関して大規模な言語モデルのレスポンスを改善する技術である。RAGエンジンは通常、レトリーバとジェネレータの2つの主要コンポーネントから構成される。リトリーバは埋め込みモデルとMilvusやZilliz Cloudのようなベクトルデータベースを組み合わせたもので、ジェネレータはLLMである。
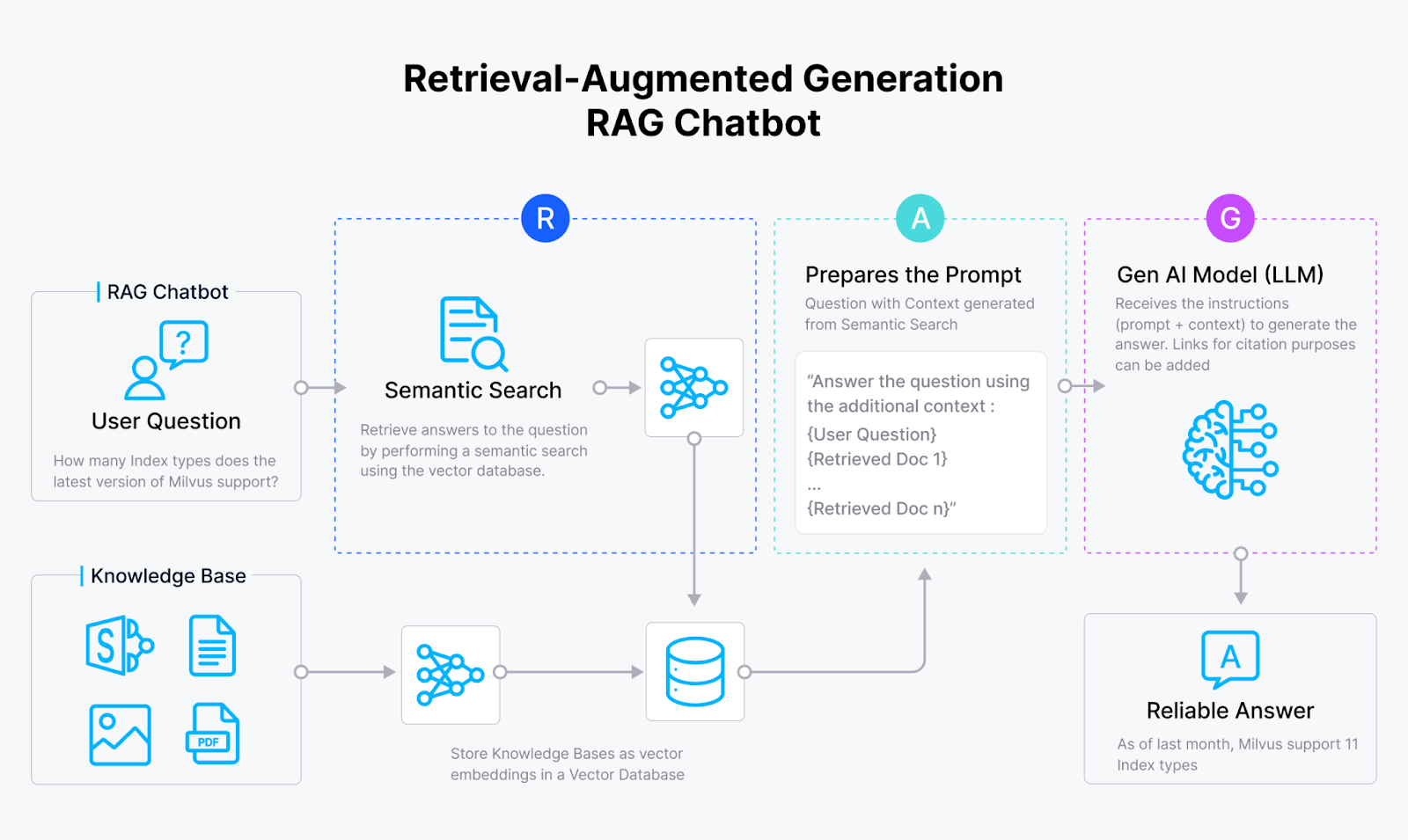
検索段階では、全ての文書を格納したベクトルデータベースを検索し、最も関連性の高いものを選択する。トップKの文書または候補が選択され、生成AIモデルへの入力として提供される。このモデルは、クエリとTop-Kの候補を用いて、首尾一貫した応答を生成する。
以下のRAGパイプラインは、従来のRAGがどのように機能するかを説明している。
全ての文書はvector embeddingsに変換され、ベクトルデータベースに格納される。
ユーザクエリもベクトル埋め込みに変換される。
このベクトルを用いて、ベクトルデータベースから最も類似した候補を検索する。
パリや東京のようなこれらの上位候補はLLMに送られ、LLMが応答を生成する。
しかし、ここで検索された上位候補は、特定のユーザーの好き嫌いに関する文脈を持っていないため、「文脈のない候補」となる。
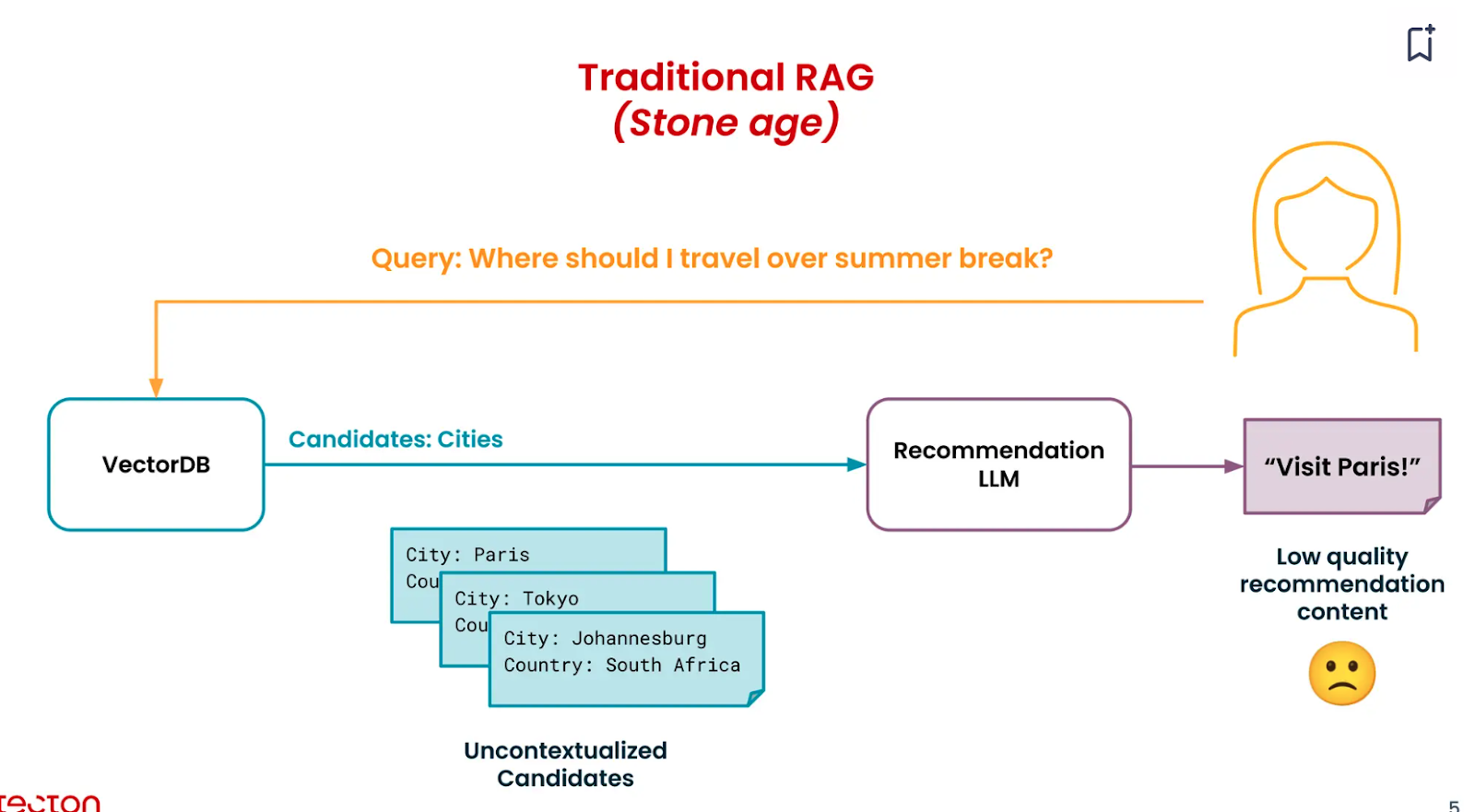
フルRAG:検索パイプラインにコンテキストを追加する
基本的なRAGパイプラインで検索された候補は文脈化されていないため、より良い回答を得るためには文脈を追加する必要がある。目的は、高いコンテキストと専門知識を持つエンジンを構築することである。
Mikeは、コンテキストを提供することで、検索された情報がいかに豊かになるかを強調している:「コンテキストとは、AIモデルが状況を理解し、意思決定を行うために使用する関連情報である。

先ほどのAI旅行代理店を構築するユースケースの例では、2つの方法でモデルにコンテキストを追加することができます:
1: 候補地(場所)のコンテキストを追加する: 都市を推薦する間、モデルは動態の詳細を認識する必要がある。例えば、現在の天気、アクティビティの種類、有名な郷土料理、おおよその予算、訪れるべき歴史的名所や遺産などである。この情報は、ユーザーが休暇を計画するのに役立ちます。
2.ユーザー・パーソナライズド・コンテキスト: ユーザーがどのような人物で、どのような嗜好や制約があるのかという情報を提供することです。この情報は、ユーザーレベルの情報で検索された上位候補を豊かにします。例えば、以下のような質問に対してコンテキストを提供します:
ユーザーは歴史に興味がありますか?
ユーザーはどのような気候を好むか?
ユーザーはアドベンチャースポーツに興味があるか?
どのような宿泊施設を好むか?
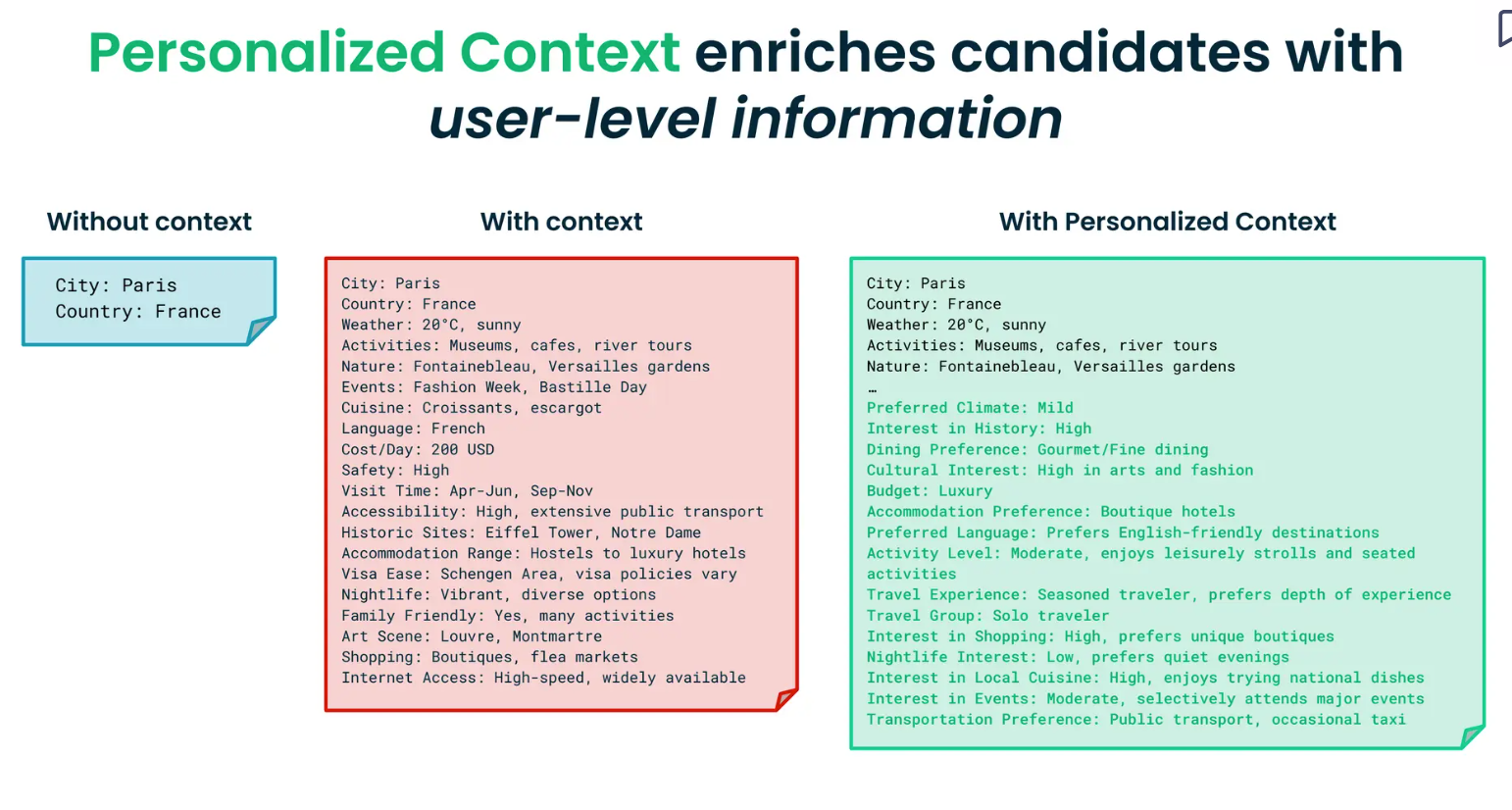
都市が何を提供し、ユーザーが何を望んでいるかについての文脈があれば、AIモデルは適切な目的地をより適切にマッチングすることができる。さらに、ユーザーの好みに合わせたアクティビティやイベント、宿泊施設を提案することもできる。
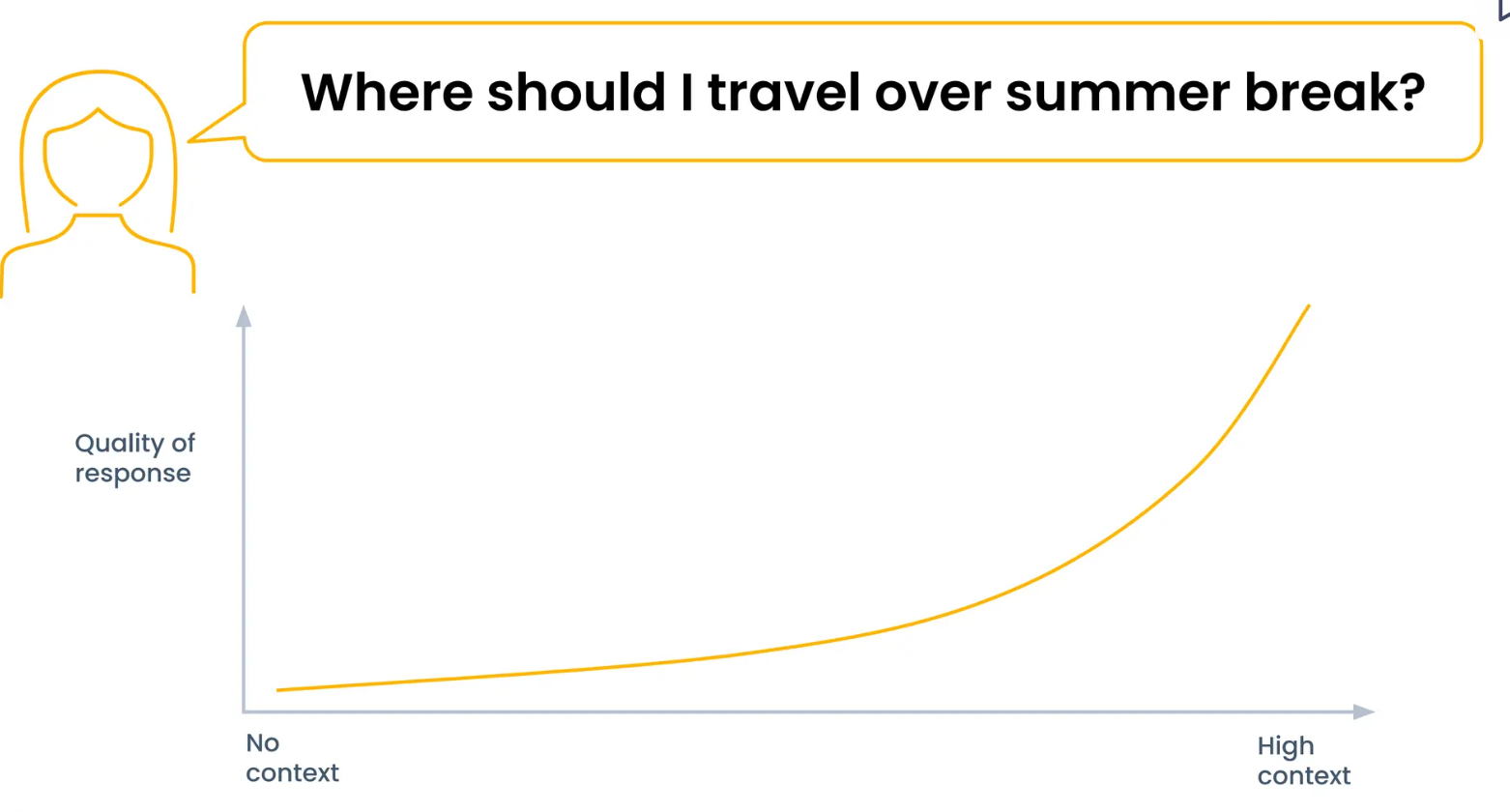
Tectonでパーソナライズされた素晴らしいコンテキストを構築するには?
テクトンは、様々なビジネスデータソースを統合するための機能プラットフォームを開発しました。推薦アルゴリズムに必要なパーソナライズされたコンテキストを簡単に作成・管理することができます。フィーチャープラットフォームは、候補者と関連するユーザーデータを取得し、Milvusのようなベクトルデータベースからコンテキスト化された候補者を検索します。
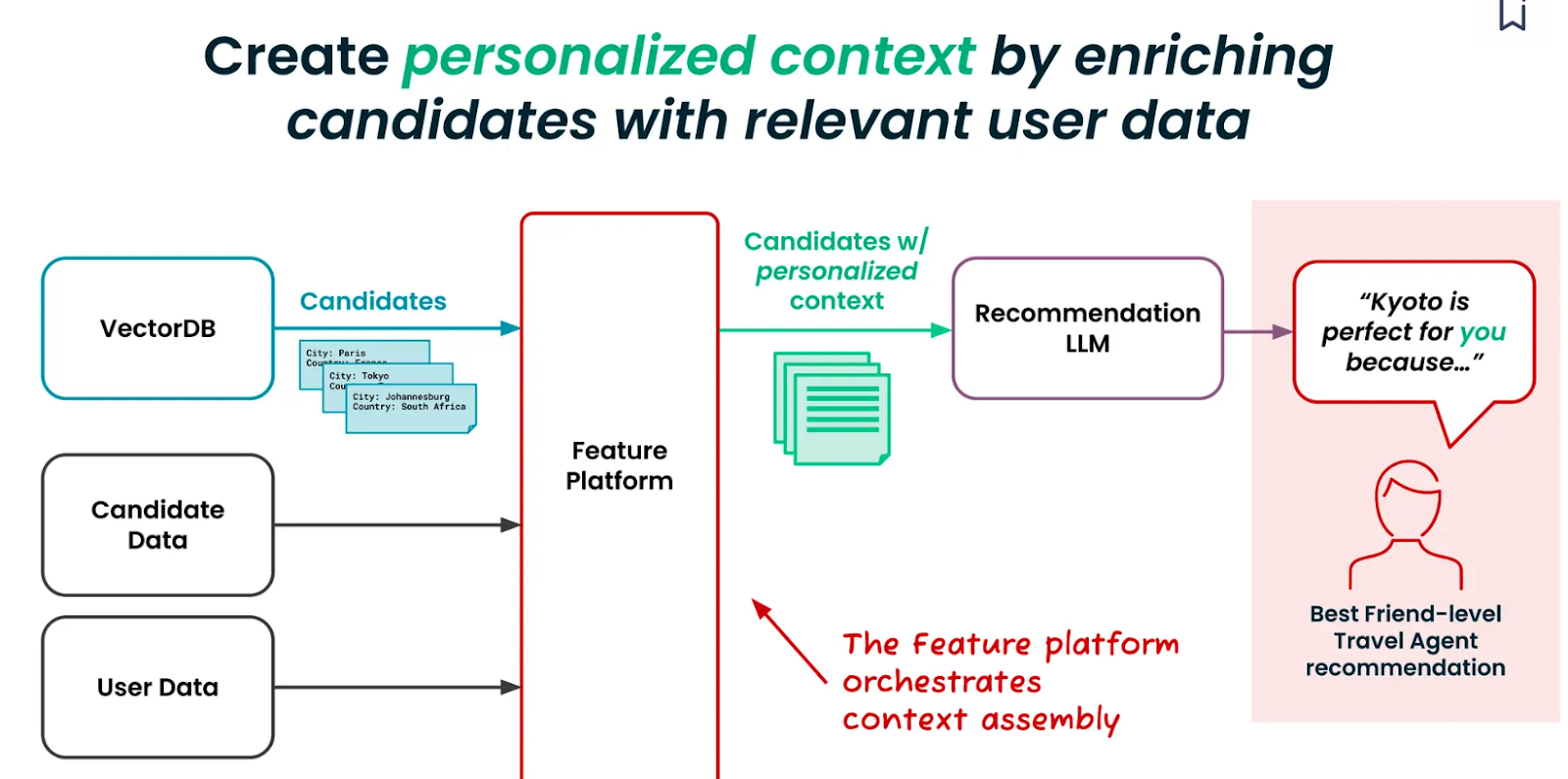
パーソナライズされたコンテキストは、4つの大まかなレベルで構築・管理することができる。
レベル0:ベース
これはベースレイヤーまたは出発点であり、追加情報はない。下図は、コンテクスト情報がゼロの状態でRAGがどのように機能するかを示している。

レベル1:バッチコンテキスト
次のレベルは、旅行履歴やお気に入りのアクティビティなどの履歴データを提供する。このレベルの実装は、異なるウェアハウスやデータレイクからデータを取得して結合するパイプラインを構築する必要があるため、難しい。また、ベンチマークや開発のために過去の評価データセットを作成する必要もある。
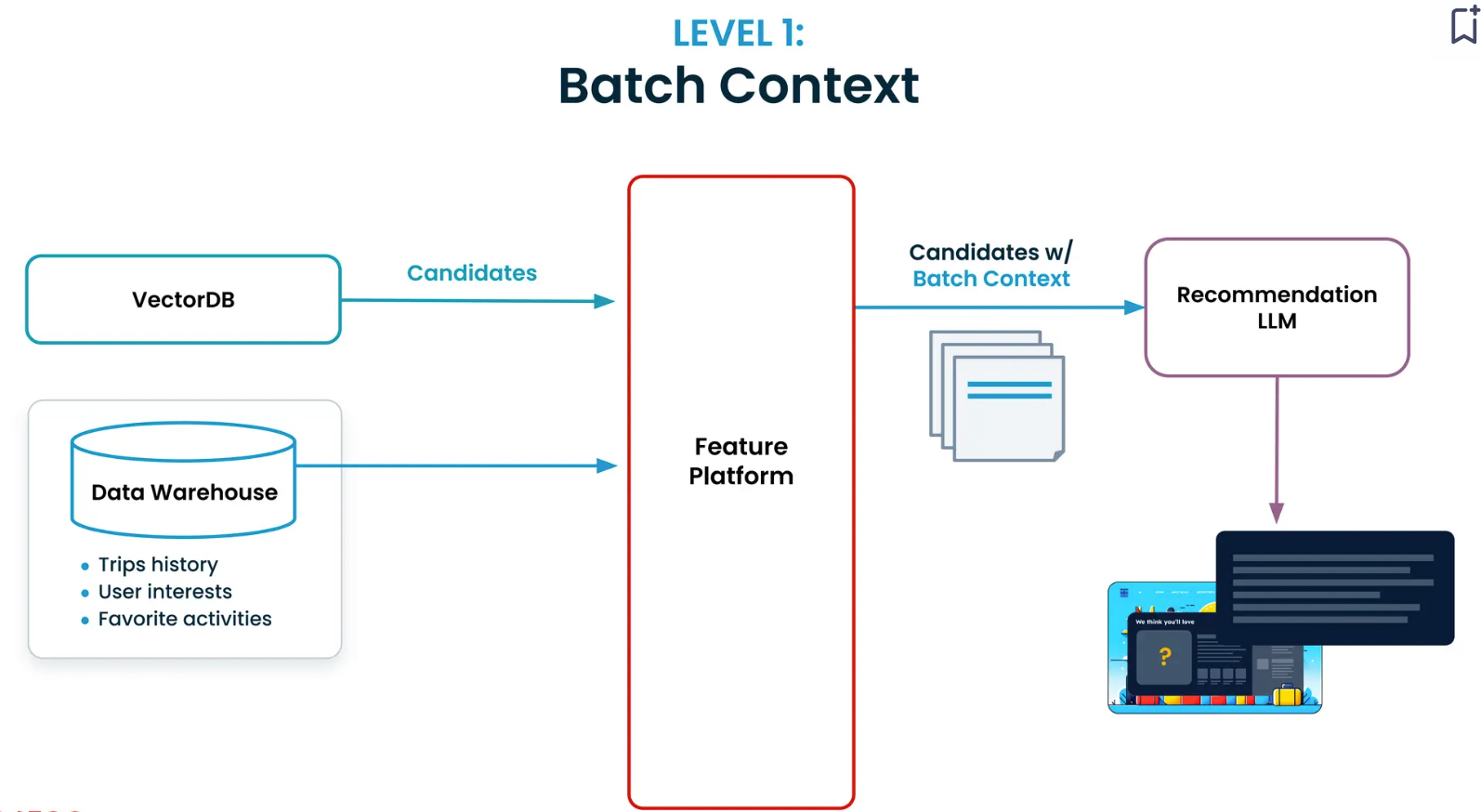
Tectonの機能プラットフォームは、バッチコンテキストの構築プロセスを簡素化します。このユーザーが最近訪れた5つの場所はどこか」というような簡単なコンテキスト定義から始めることができる。このプラットフォームはまた、あなたの定義をコーディングするためのPython SDKを提供し、リアルタイムでのデータの読み込みと評価をサポートします。
この段階で、レコメンデーションLLMは過去のコンテキストから洞察を引き出し、提案を提供することができる。例えば、ユーザーが過去に多くの史跡を訪れたことがあれば、古都京都の寺院を訪れることを提案するだろう。

レベル2:バッチ+ストリーミング・データ・コンテキスト
ユーザーが見たり読んだりしている映画、ビデオ、ブログなどのユーザーに関するストリーミング情報を追加することで、モデルがユーザーの現在の興味を理解するのに役立ちます。このストリーミング情報には、ユーザーの検索データ、購入データ、あるいはウェブページでのセッションのインタラクションが含まれるかもしれない。
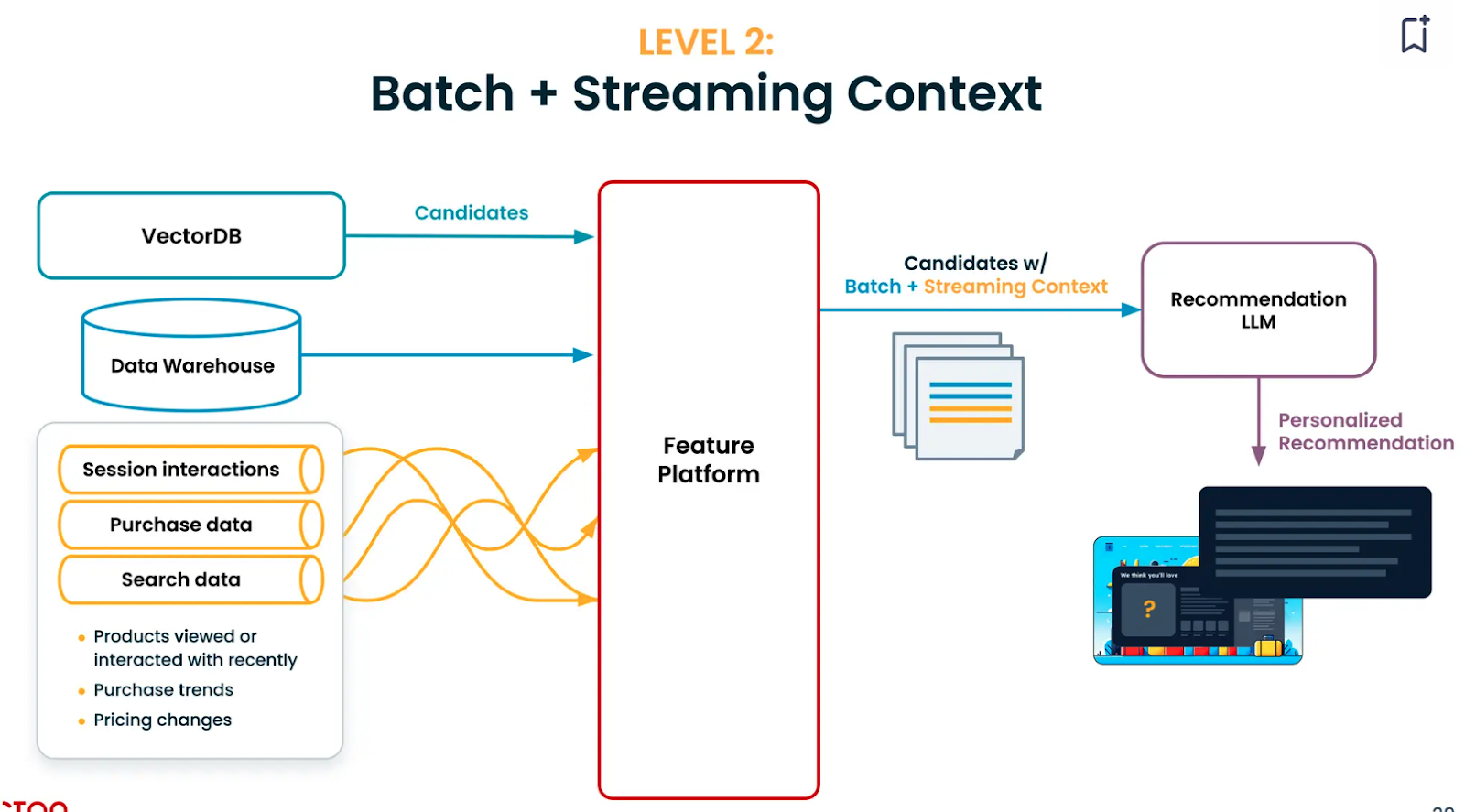
ここでの課題は、ストリーミング・データ・パイプラインを組み込み、それを製品化することである。大規模に実装する一方で、モデル構築とリアルタイム推論の両方のコストが高くなる可能性がある。

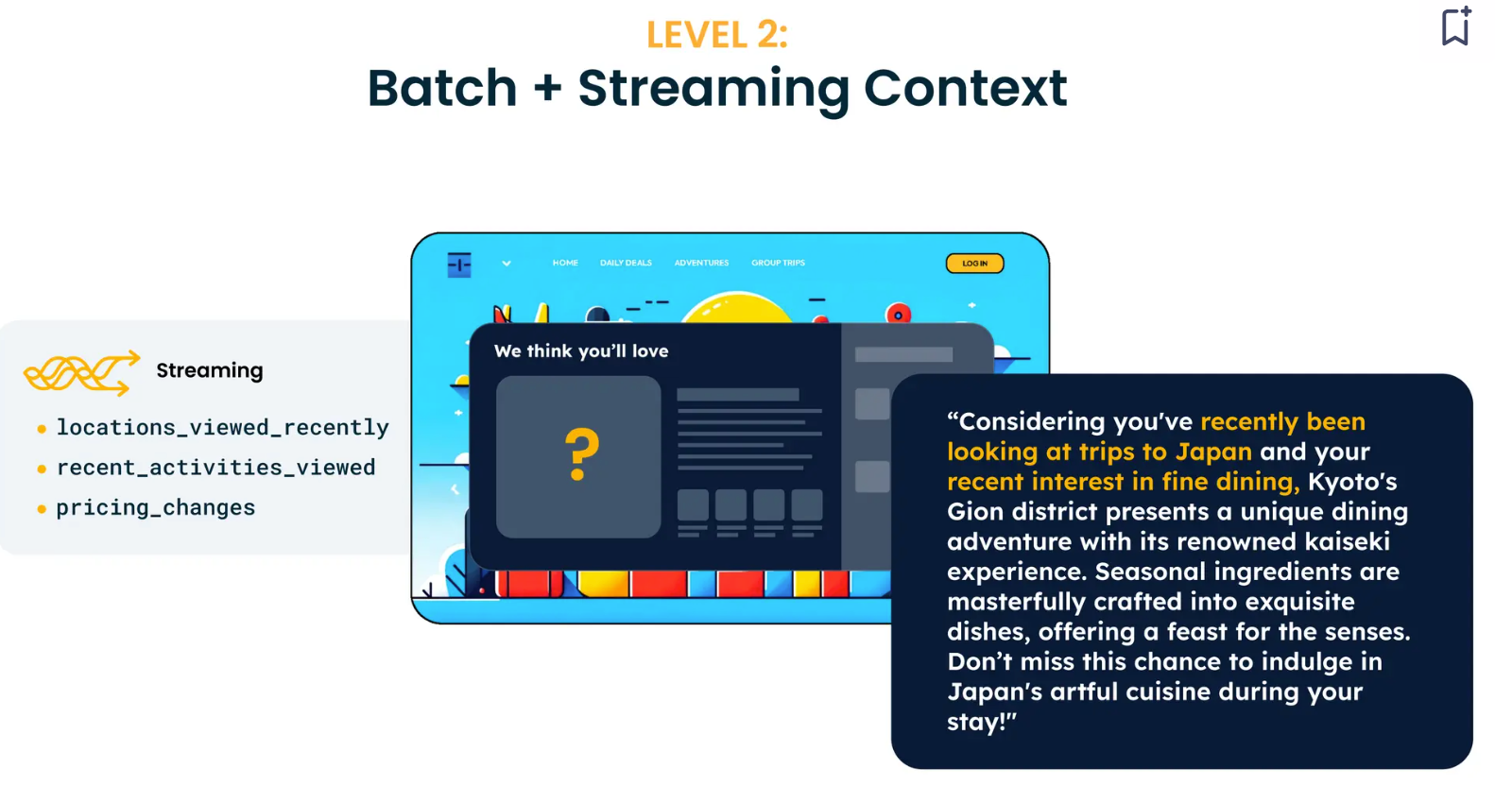
Tectonはストリーミング・コンテキストの構築を単純化する。例えば、単純なコンテキスト定義から始まる:例えば、"過去1時間に、ユーザーはどのようなトピックについてのビデオを見たか?"というシンプルなコンテキスト定義から始まる。これは、プラットフォームのPython SDKにコード化できる。私たちはこれをテストし、本番環境にデプロイし、リアルタイムで使用することができる。この段階でのレコメンデーションは、以前のものよりもかなり優れている。例えば、ユーザーが日本へのフライトを検索していて、高級レストランが好きな場合、LLMは日本でのダイニング体験をキュレートする。
レベル3:バッチ+ストリーミング・データ+リアルタイム・コンテキスト
次の段階は、高品質な信号のためにリアルタイムデータを取り込むことだ。このコンテキストは、モデルがユーザーの意図をよりよく理解するのに役立つ。このデータには、ユーザーの検索クエリや、リアルタイムで他のアプリケーションからデータを調べることが含まれる。例えば、最も安いオプションを提案するためには、リアルタイムのフライト価格を調べなければならない。

最大の課題は、サードパーティのリアルタイム・データ・ソースを統合し、スピードとコストのトレードオフを管理することである。リアルタイムでパーソナライズされたレコメンデーションがあれば、ユーザーは一人でリサーチする代わりに時間を節約できるため、非常に価値があると感じるだろう。

この上にフィードバックレベルのコンテキストを追加することもできる。提供されたレコメンデーションに対するユーザーのフィードバックは、モデルが正しい方向に舵を切るのに役立つ。
結論
コンテキストは、オーダーメイドのショッピング体験、チャットボットの構築、パーソナルファイナンスのアドバイス、新しい映画の推薦など、数多くのケースでAIのパーソナライゼーションを強化することができる。パーソナライゼーションのレベルが高ければ高いほど、製品体験は向上するが、構築の難易度も並行して高まる。
RAGは、より良い、より関連性の高い情報のために、LLMに追加のドメイン固有情報を提供するための重要なテクニックである。また、多くのユーザー中心のGenAI製品の長期的な顧客維持の鍵でもある。
標準的なRAGはベクターデータベースを搭載したリトリーバーとLLMジェネレーターで構成される。すべての追加情報はMilvusのようなベクトルデータベースに格納され、LLMはユーザーのクエリに関連する検索された情報に基づいて回答を生成する。
幻覚に対処するには効果的であるが、標準的なRAGシステムは、超個別化された推薦を提供するようなユースケースでは不十分である。これは、検索されたトップk候補が、特定のユーザーの好き嫌いに関する、よりパーソナライズされたコンテキストを持っていない可能性があるためである。
Tectonは、LLMのためにパーソナライズされたコンテキストを組み立てるソリューションを提供し、企業のプロセスを合理化する。しかし、バージョン管理、モデルガバナンス、根本的な原因を見つけるためのデバッグなど、大きな課題が残っている。
このトピックの詳細については、マイクのミートアップビデオ録画をご覧ください。

読み続けて

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.