




Cardinalのご紹介:ベクトル検索に最適なエンジン
この投稿はアレクサンドル・グズヴァとリウ・リウによって書かれました。
データベースにおいて「パフォーマンス」は、特にベクトル・データベースにおいて重要な指標である。限られたリソースの中で大量のユーザーリクエストを効率的に処理する上で極めて重要です。アクセス待ち時間が気にならない状況もあるかもしれないが、ベクトル・データベースにとって、パフォーマンスは様々な理由から不可欠であることに変わりはない。
1.近似最近傍探索(ANNS)に依存するベクトル検索は、わずかな精度と引き換えにパフォーマンスを向上させる可能性がある。性能が向上すれば、精度を高めることができる。
2.一定のクエリ待ち時間の下で維持される卓越した性能は、同じリソースを使用してより高いスループットを促進し、より多くのユーザーベースに対応します。
3.さらに、パフォーマンスの向上は、同一の利用シナリオをサポートするために必要な計算リソースの削減につながります。
ベクターデータベースは本質的に計算集約型であり、リソース使用量の大部分(しばしば80%を超える)がベクター距離計算に費やされます。その結果、ベクトル検索タスクを処理するベクトル検索エンジンは、ベクトルデータベースの全体的なパフォーマンスを決定する重要な要因となります。
Zillizは、一貫してベクトルデータベースの性能向上を優先している。オープンソースのMilvusとフルマネージドのZilliz Cloudは、類似製品と比較して優れたパフォーマンスを示しています。Milvusのベクトル検索エンジンKnowhereは、新しい検索エンジンの基礎を築くことで、この成功の達成に重要な役割を果たしています。
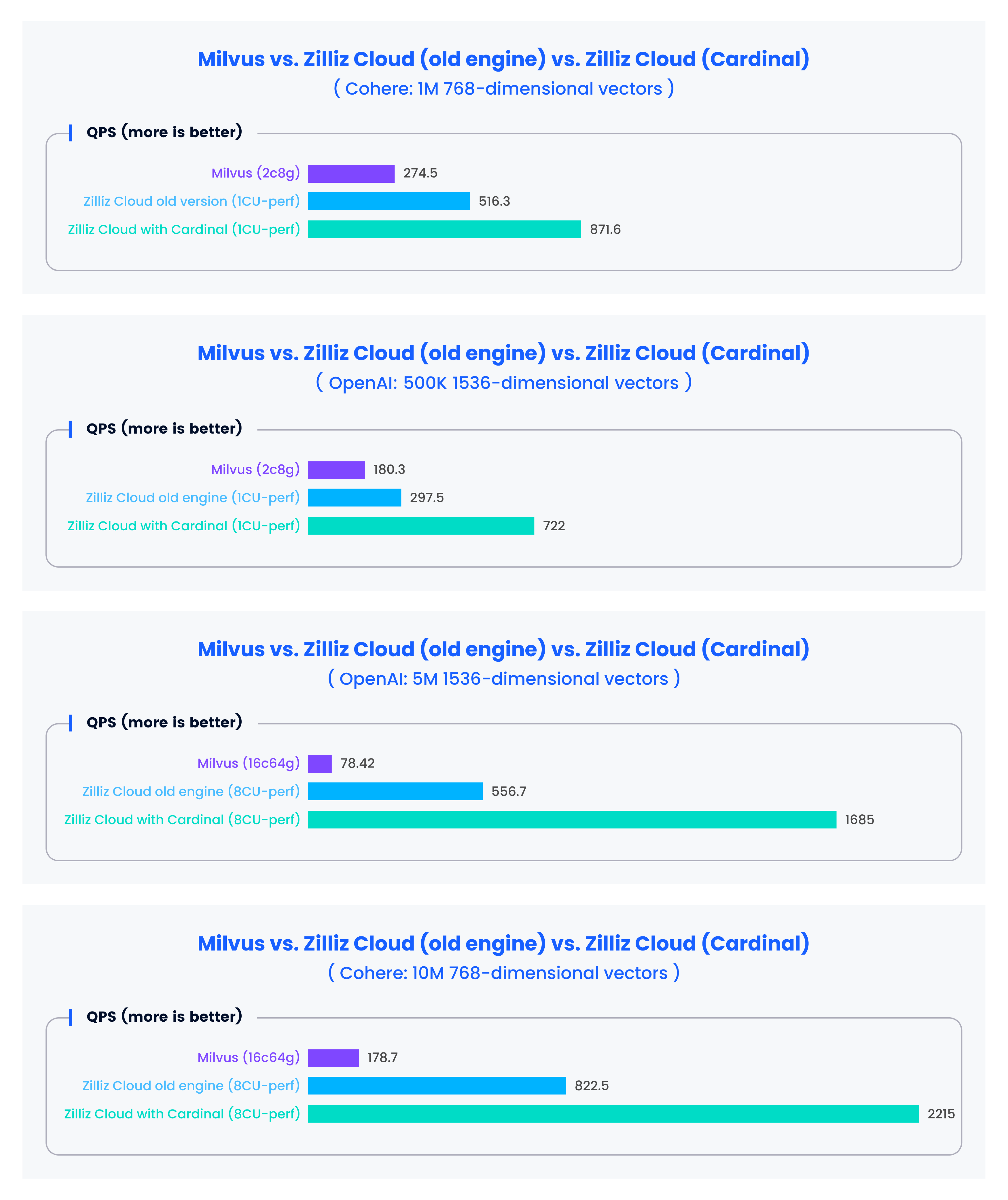
Zilliz Cloudの最新リリースの中核にあるのは、私たちが構築した新しいベクトル検索エンジンであるCardinalです。この検索エンジンは、すでに旧バージョンと比較して3倍の性能向上を実証しており、Milvusの10倍に達する検索性能(QPS)を提供している。
オープンソースのベクトルデータベースベンチマークツールを用いて最新のZilliz Cloudの性能を評価し、Milvusや旧エンジンを搭載したZilliz Cloudとの性能比較を行いました。評価結果を下図に示します。
カーディナルとは?
Cardinalは、最も実用的で広く使われているANNSメソッドを実装した、独自のマルチスレッド・モデルンC++テンプレートベースのベクトル検索エンジンです。Cardinalは、利用可能な計算資源を効率的に使用するためにゼロから設計・作成された。
Cardinalは以下のことが可能です:
ブルートフォース検索
ANNSインデックスの作成と修正、
インデックスTop-Kとインデックス範囲検索の実行、
FP32、FP16、BF16を含む様々な入力データ形式の操作
インメモリデータやメモリマップドデータの操作
ユーザーが指定した条件に基づいて検索結果をフィルタリングする。
カーディナルには以下が含まれる:
さまざまな内部パラメーターを簡単に設定できるANN手法の実装。ただし、デフォルトの動作ポイントは、妥当な精度(想起率)を維持しながら検索速度(QPS、1秒あたりのクエリー)を最大化するように一貫して調整されている。
ANNS手法をサポートする様々なアルゴリズムの効率的な実装。例えば、サンプルフィルター機能を提供するものなど。
検索や構築時に使用されるほとんどの計算集約的な処理に対して、低レベルに特化した最適化カーネル。複数のハードウェアプラットフォームに対応。Cardinalには、様々なメトリクスの距離を計算するカーネルの他に、融合カーネルやデータ前処理のためのカーネルも含まれています。
非同期操作、メモリマップドI/O機能、キャッシング、メモリアロケータ、ロギングなどのサポート機能。
Knowhere vs Cardinal
Knowhere](https://github.com/zilliztech/knowhere)ライブラリはオープンソースMilvusの内部コアであり、ベクトル探索を担当する。Knowhereは、Faiss、DiskANN、hnswlibといった業界標準のオープンソースライブラリのパッチ版をベースにしています。
KnowhereとCardinalを比較してみましょう:
| KnowhereとCardinalの比較をしてみましょう。 | ------------------------ | ------------------------------------------------------ | ---------------------------------------------------------------------------------- | | プロダクション・レディネス | スケーラビリティ能力 | 設計思想|実験と柔軟性|スコープを絞り込み、パフォーマンスについては既存機能の強化を優先 | ホスト互換性|すべてのホストタイプ|Zillizクラウドホスト環境に最適化 | 依存性|よく知られたOSSライブラリと実装に依存|自明でない修正と最適化を含む
MilvusとZilliz Cloudが必要とするすべてのスケーラビリティを提供します。
Knowhereは実験と柔軟性を念頭に設計されている。Cardinalは範囲が狭く、大規模な新機能を導入するよりも、スピードとパフォーマンスを向上させるために既存の機能を強化することを優先しています。
Knowhereはオープンソースであり、さまざまな環境に導入できるため、あらゆる種類のホストで動作します。CardinalはZilliz Cloudホスト環境に最適化されています。
Knowhereは有名なOSSライブラリや実装(Faiss、DiskANN、hnswlibなど)に依存しています。Cardinalには、自明でない修正や最適化が含まれています。
何がCardinalを高速にしているのか
Cardinalは様々なアルゴリズム関連、エンジニアリング、低レベルの最適化を実装している。CardinalはAUTOINDEXメカニズムを導入し、データセットに最適な検索ストラテジーとインデックスを自動的に選択する。これにより、手動でチューニングする必要がなくなり、開発者の時間と労力を節約できる。
では、その詳細を見ていこう。
アルゴリズムの最適化
この最適化は、検索プロセスの精度と有効性を大幅に向上させるもので、さまざまなアルゴリズムが連動する多面的なパイプラインです。このパイプライン内の多数のアルゴリズムを改良することで、全体的なパフォーマンスを向上させることができます。Cardinalにおけるアルゴリズム最適化の注目すべき候補には、以下のようなものがある:
IVFベースとグラフベースの両方のアプローチを包含する検索アルゴリズム、
フィルタリングされたサンプルの割合に関係なく、検索が必要な想起率を維持できるように設計されたアルゴリズム、
最良優先探索アルゴリズムの高度な反復、
プライオリティ・キュー・データ構造用にカスタマイズされたアルゴリズム。
パラメータ化可能なアルゴリズムは、パフォーマンスとRAM使用量のバランスなど、トレードオフのための柔軟性を提供する。その結果、枢機卿のアルゴリズムの最適化には、パラメータ空間内の最適な動作点を選択することも含まれる。
エンジニアリングの最適化
アルゴリズムは当初、抽象的なチューリングマシンを念頭において設計されるが、現実世界の実装では、ネットワークの遅延、クラウドプロバイダーによるIOPSの制限、貴重だが有限なリソースであるマシンRAMの制限などの課題に直面する。
エンジニアリングによる最適化により、Cardinalのベクトル検索パイプラインは実用的であり続け、コンピュート、RAM、その他のリソースの制約に沿ったものとなっています。Cardinalの開発では、標準的な手法と革新的な技術を融合させています。このアプローチは、C++コンパイラが計算上最適なコンパイルコードを生成することを可能にすると同時に、クリーンでベンチマークが可能な、拡張が容易なソースコードを維持し、新機能の迅速な追加を容易にします。
ここでは、Cardinalに実装されたエンジニアリングプラクティスの例をいくつか紹介し、具体的な最適化を紹介します:
特殊なメモリ・アロケータとメモリ・プール、
適切に実装されたマルチスレッドコード、
様々な検索パイプラインへの要素の組み合わせを容易にするコンポーネントの階層構造、
特定の重要なユースケースのためのコードのカスタマイズ。
低レベルの最適化
検索時間のほとんどは、カーネルとして知られる比較的小さなコードに費やされる。最も単純な例は、2つのベクトル間のL2距離を計算するカーネルです。
Cardinalには、異なる目的のための多数の計算カーネルが含まれており、それぞれが特定のハードウェアプラットフォー ムや使用ケースに特化して記述され、最適化されています。
Cardinalはx86とARMのハードウェア・プラットフォームをサポートしているが、他のプラットフォームも簡単に追加できる。
x86プラットフォームでは、CardinalカーネルはAVX-512のF、CD、VL、BW、DQ、VPOPCNTDQ、VBMI、VBMI2、VNNI、BF16、FP16拡張を使用する。また、新しいAMX命令セットの使用も検討しています。
ARMプラットフォームでは、NEON命令セットとSVE命令セットの両方に対応するCardinalカーネルが利用可能です。
私たちは、Cardinalが計算カーネルに最適なコードを取得できるようにしています。単に最新のC++コンパイラに頼っているわけではありません:
Linuxperfなどの専用ツールを使用して、ホットスポットとCPUメトリクスを分析します。
GodBolt Compiler Explorer](https://godbolt.org)やuiCAなどのマシンコード解析ツールを使用して、RAM/キャッシュアクセス数、使用CPU命令数、レジスタ数、コンピュートポート数などのハードウェア「リソース」の最適な使用を保証します。
私たちは、設計、ベンチマーク、プロファイリング、アセンブラコード解析の各段階を連動させる反復的アプローチを採用しています。
適切に最適化されたコンピュート・カーネルは、素朴だが最適化されていないカーネルと比較して、2倍から3倍のスピードアップをもたらす可能性がある。これはさらに、クラウドホストマシンのQPS値が2倍高くなったり、メモリ要件が20%低くなったりする。
AutoIndex: 検索戦略の選択
ベクトル検索は、量子化、インデックス構築、検索アルゴリズム、データ構造など、多くの独立したコンポーネントを含む複雑なプロセスです。各コンポーネントには調整可能なパラメータが多数あります。また、データセットやシナリオによって異なる検索戦略が必要となります。
性能向上の可能性をより引き出すために、Cardinalは、各コンポーネントで複数の戦略をサポートすることに加え、AUTOINDEXとして知られるAIベースの動的戦略選択メカニズム一式を実装した。これは、与えられたデータセットの分布、提供されたクエリー、ハードウェア構成に基づいて、最適な戦略を適応的に選択する。これにより、検索品質に対するユーザーの要求を満たしながら、最適なパフォーマンスを実現することができる。
カーディナルベンチマーク
Cardinalをテスト環境でサポートするために、ANN-benchmarksを採用しました。ANNベンチマークはANNS実装を評価するための標準的なベンチマークツールであり、異なる距離メトリクスを使用するいくつかの標準データセットで実行される。すべての性能評価は、シングルスレッド使用に制限されたドッカーコンテナ内で実施される。評価指標は、多数の単一クエリーリクエストを利用した複数の評価反復に基づいている。すべての評価フレームワークの結果は、recall-vs-QPSパレートフロンティアに集約される。
すべてのテストは、ベースラインのann-benchmarks(2024年1月現在)と同じ種類のマシン、つまりAmazon EC2 r6i.16xlargeマシンで、以下の構成で実行された:
CPU:インテル(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz
CPUコア数32
ハイパースレッディング無効
RAM: 512 GB
OSLinuxカーネル6.2.0-1017-awsを搭載したUbuntu 22.04.3 LTS
巨大ページのサポートが有効になっていませんでした。
parallelism=31`オプションを付けてテストを実行した。
Cardinalはclang 17.0.6コンパイラを使ってコンパイルした。
以下に示すベンチマーク結果はCardinalエンジンのみの結果であり、Zilliz Cloudが提供するインデックス以外の追加最適化は含まれていません。
注:* Zilliz Cloud固有の最適化を含む結果は、記事の冒頭に記載しています。
以下のチャートは、ANN-benchmark GitHubページに掲載されている結果を持つチャートの画像を取り込み、Cardinalの追加カーブを正確に追加して作成した。
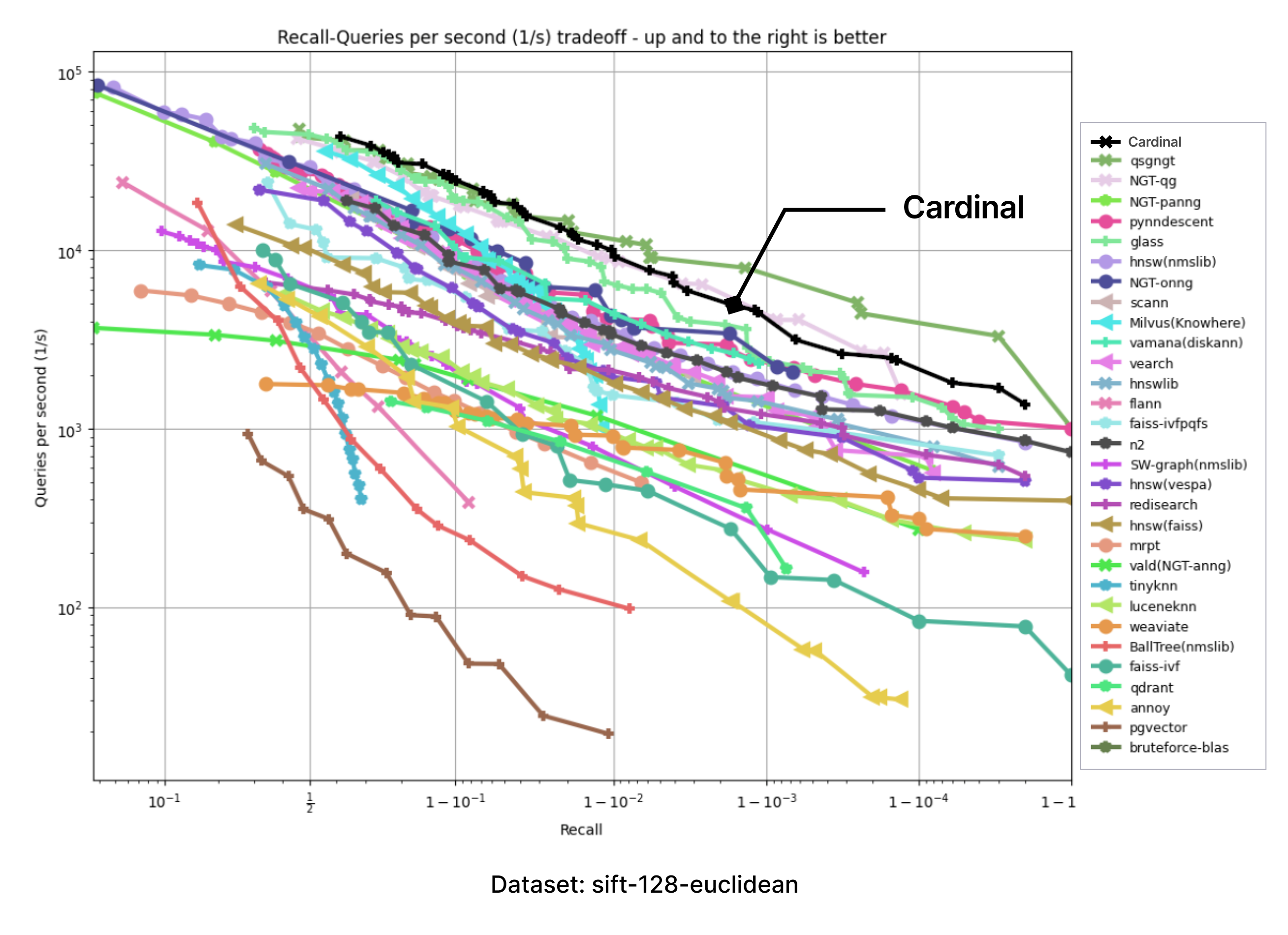
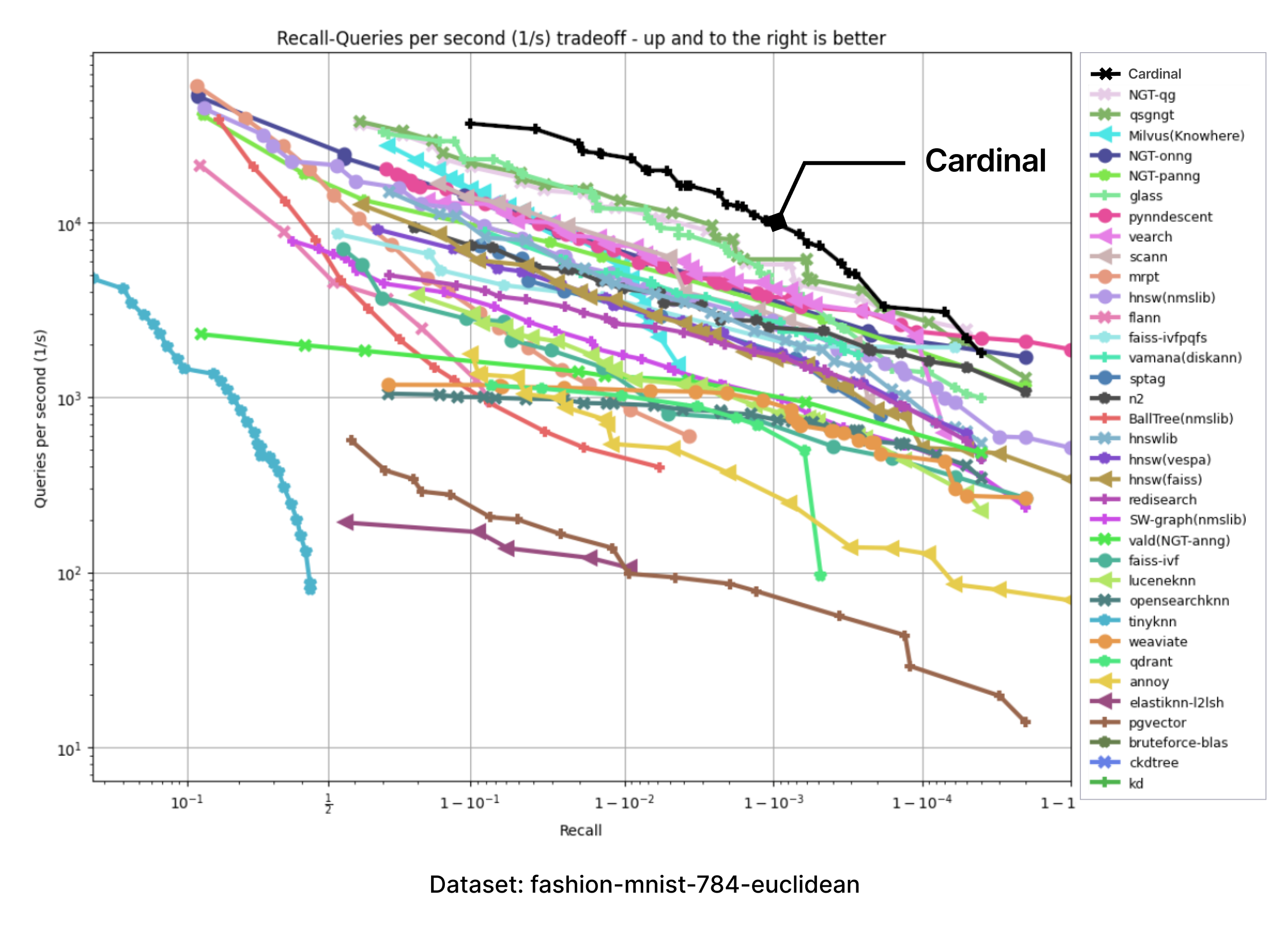
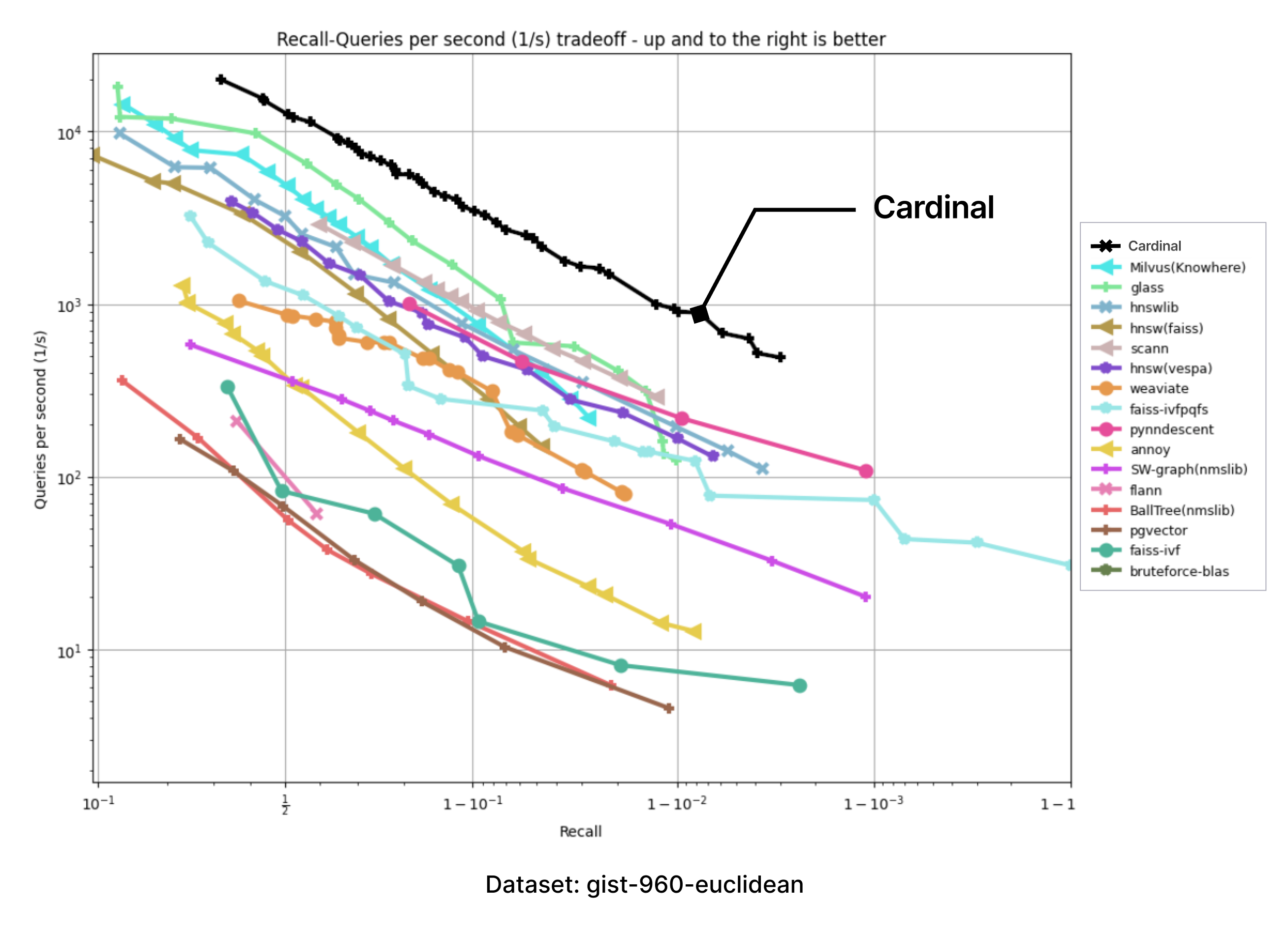
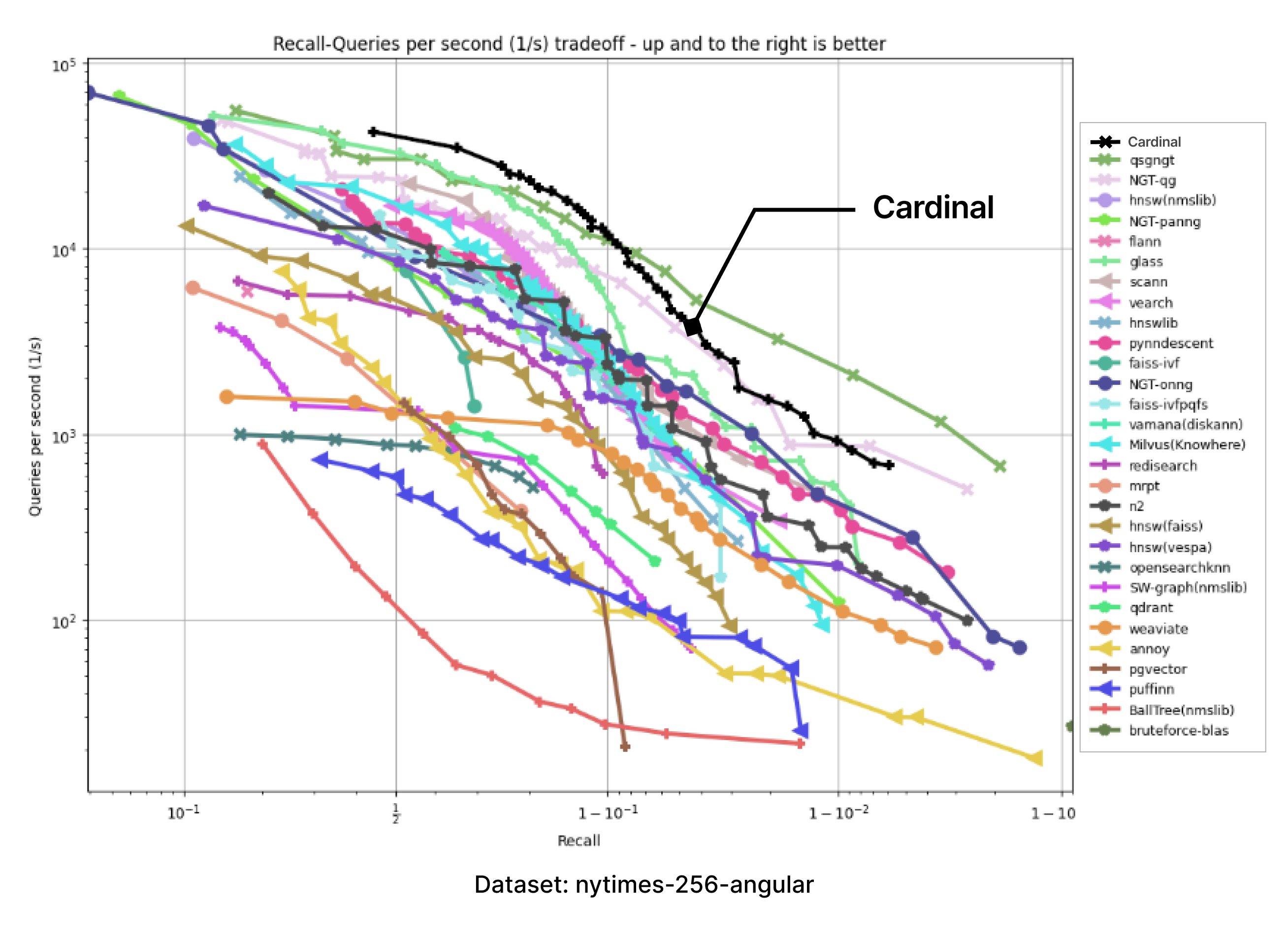
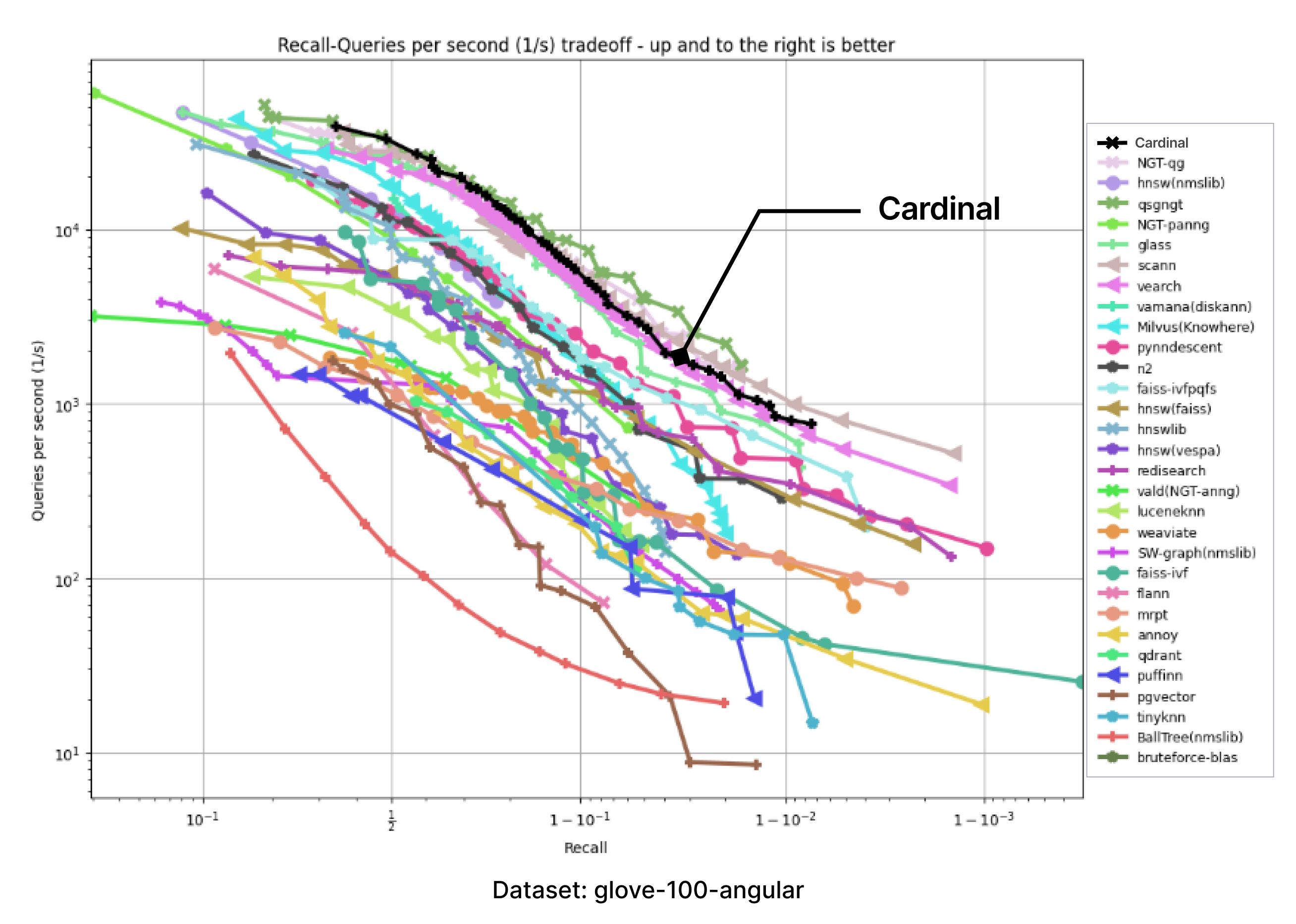
提供されたすべてのベンチマークにおいて、Cardinalは非常に競争力のある結果を示している。そして、さらなる改善の余地がある。
次は?
未来は間違いなく、私たちに新たな挑戦をもたらすだろう。異なる要件、異なるボトルネック、より大きなデータセット。私たちはCardinalをより良いものにするために努力を続けます。
道は照らされている。道は明らかだ。私たちに必要なのは、それをたどる強さだけだ :)

読み続けて

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.