




OpenAIなしでRAGアプリを作る - 前編
OpenAIは最もよく知られている大規模言語モデル(LLM)。しかし、LLMはそれだけではありません。LangChain](https://zilliz.com/blog/langchain-ultimate-guide-getting-started)、Milvus、そしてOpenAIを使って、多くのRAGタイプのアプリケーションを作ってきたことは、このブログの常連さんならすでにご存知だろう。このプロジェクトでは、OpenAIの代替としてNebula(Nebula websiteをクリックしてAPIキーをリクエストしてください)を導入し、OpenAIのエンベッディングの代わりにHugging Faceのエンベッディングモデルを使っています。
この投稿では、以下を取り上げます:
会話型RAG技術スタック
ラングチェーン
シンブルAI
ミルバス
ハグする顔
基本的な会話型RAGアプリの作り方
会話型RAGスタックのセットアップ
会話の作成
質問をする
OpenAIを使わない会話型RAGの構築のまとめ
会話型RAGの技術スタック
会話型RAGはRAGの最も一般的な形態です。私たちがRAGチャットボットについて考えるときに考えるものです。昨年、私たちはCVP (ChatGPT like LLM + Vector Database + Prompt as code) がRAGの標準的なスタックであることを説明しました。このスタックでは、Hugging Faceとは別の埋め込みモデルを追加しています。このスタックでは、LangChainをプロンプトのオーケストレーションに、Symbl AIをLLMに、Milvusをベクトルデータベースに、そしてHugging Faceを埋め込みモデルとして使っています。
LangChain
まだ聞いていない人は、今聞いている:LangChainは最も人気のあるLLMアプリオーケストレーションフレームワークです。このチュートリアルは、私たちがLangChainとOpenAIを使って会話記憶を使って行ったプロジェクトの翻案です。今回は、OpenAIのエンベッディングやGPTを使わずに、同じプロジェクトを行っています。
シンブルAI
Symbl AIは会話データで訓練された会話LLMを作った。彼らのLLMはNebulaと呼ばれ、LangChainと統合されている。このチュートリアルでは、以前使ったOpenAIのGPT-3.5の代わりにNebulaを使う。
Milvus
私たちの会話記憶ピースの輝く星は、ベクトル・データベースです。説明したように、ベクトル・データベースは、一度ベクトル化された非構造化データを扱うように設計されています。私たちは、このプロジェクトの会話記憶部分のストアとしてMilvusを使います。
ハグする顔
Hugging Faceは世界最大のモデルハブだ。LangChainにも直接統合されています。前回のプロジェクトで使用したOpenAIのエンベッディングモデルの代わりに、Hugging Faceのエンベッディングモデルを使用しています。
基本的な会話型RAGアプリの作り方
技術スタックがわかったところで
1.少しセットアップが必要だ。
2.アプリがRAGを実行するための会話例を定義する。
3.最後に質問例を示します。
会話型RAGスタックのセットアップ
会話型RAGスタックをセットアップしよう。6つのライブラリをインストールしなければならない:LangChain、Milvus (Lite)、PyMilvus、python-dotenv、Sentence Transformersです。最初のセクションでは、LangChainからいくつかの重要な部分、Vector Store Retriever Memory、Conversation Chain、Prompt Templateオブジェクトをインポートします。これらのオブジェクトを使って会話記憶の例を作ります。
他の2つのインポートには、∕os∕と∕load∕dotenv∕があります。これらは環境変数をロードするために使う。他のチュートリアルを覚えているなら、通常はOpenAIのAPIキーを読み込みますが、今回はNebulaのAPIキーを読み込みます。
pip install langchain milvus pymilvus python-dotenv sentence_transformers
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv("NEBULA_KEY")
次に、ベクトルデータベースと埋め込みモデルを作成する。Milvus Lite](https://milvus.io/docs/milvus_lite.md)から "default_server"をインポートし、ベクタデータベースとして起動します。次に、LangChainからHugging Face embeddingsをインポートし、埋め込み関数として使用する。デフォルトのモデルは "all-mpnet-base-v2"で、次元数は768である。
from milvus import default_server
default_server.start()
from langchain_community.embeddings import HuggingFaceEmbeddings
# デフォルトはこのモデル: sentence-transformers/all-mpnet-base-v2
embeddings = HuggingFaceEmbeddings()
次のセクションは、どちらかというと「クリーンアップ」のセクションです。LangChainをまだMilvusで使ったことがない人には関係ないだろう。ここではMilvusに接続し、データポイズニングを避けるために既存のLangChainコレクションを削除する。
from pymilvus import utility, connections
connections.connect(host="127.0.0.1", port=default_server.listen_port)
utility.drop_collection('LangChainCollection')
会話を作成する
さて、いよいよ会話を作成して保存します。
まず、LangChainからMilvusベクトルストアのコレクションオブジェクトをインポートし、空のドキュメントセットから始めます。また、先ほど作成したHugging Faceエンベッディング関数を渡します。接続引数にはMilvus Liteインスタンスのホストとポートを渡します。今回使用するこのオブジェクトの最後のパラメータは "consistency_level"です。"consistency_level"はデータ一貫性レベルを設定します。この場合、"Strong "が最高レベルのデータ一貫性です。
from langchain.vectorstores import Milvus
vectordb = Milvus.from_documents(
{},
embeddings、
connection_args={"host":"127.0.0.1", "port": default_server.listen_port}、
consistency_level="Strong")
次に、Milvusコレクションと検索引数を渡して、LangChainを使ったベクターストア検索をセットアップする。この検索では、上位1つの結果のみを返します。そして、このリトリーバをLangChain RAGスタックの一部としてLLMで使えるメモリオブジェクトに渡します。
シード会話も必要だ。実生活では、この会話はカスタマーサービスコールのようなものです。この例では、私自身についての情報を伝えます。 あなたも自分の情報を伝えるべきです。会話例を作成したら、それをコンテキストとしてメモリーに保存する必要がある。
コンテキストを保存するときには、メモリー・オブジェクトに2つの辞書を渡します。この例では、入力例と出力例をそれぞれ "input "と "output "として渡す。この例では、例の input と output をそれぞれ "input" と "output" として渡している。
retriever = Milvus.as_retriever(vectordb, search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
about_me = [
{"input":「好きなおやつはチョコレートです、
"output":"ナイス"}、
{"input":"好きなスポーツは水泳です、
"output":「クール"}、
{"input":「好きなビールはギネスです、
"output":「Great"}、
{"input":「好きなデザートはチーズケーキです、
"出力":"知っててよかった"}、
{"input":「好きなミュージシャンはテイラー・スウィフトです、
"output":"私もテイラー・スウィフトが大好きです"}。
]
for example in about_me:
memory.save_context({"input": example["input"]}, {"output": example["output"]})
質問をする
これで会話型RAGアプリに質問する準備はすべて整いました。この場合、これまでの会話を記憶したベクターデータベース、Hugging Faceの埋め込みモデル、そして非OpenAIのLLMであるNebulaがあります。質問をする前に、アプリが私たちの会話を覚えていることを確認しましょう。
プリロードされた会話から何かを覚えているかどうか見せてくれるように頼んでみよう。この例では、私の好きなミュージシャン(テイラー・スウィフト)は誰かという質問をしている。バックグラウンドで何が起こっているのでしょうか?記憶オブジェクトは、提供された埋め込みモデルを使って、プロンプトをベクトル化し、履歴を検索する。
print(memory.load_memory_variables({"prompt": "who is my favorite musician?"})["history"])
以下の例のような出力が得られるはずだ。

次に、会話チェーンに入力するプロンプトテンプレートを作成する。ここでLLMが必要になる。ここではNebulaをインポートしてAPIキーを渡すだけだ。プロンプトは複数行の文字列のように扱うことができ、f-文字列と同じように中括弧記法を使って変数を渡すことができる。
この文字列と変数名をLangChainプロンプトテンプレートオブジェクトに渡す。プロンプトテンプレート、LLM、メモリがあれば、会話チェーンオブジェクトを使って「会話」を作ることができる。
from langchain_community.llms.symblai_nebula import Nebula
llm = Nebula(nebula_api_key=api_key)
_DEFAULT_TEMPLATE = """以下は人間とAIのフレンドリーな会話です。AIは饒舌で、文脈から具体的な詳細をたくさん提供してくれる。AIは質問の答えを知らない場合、正直に「知らない」と答える。
過去の会話の関連する部分:
歴史
(関連性がなければ、これらの情報を使う必要はありません。)
現在の会話
人間:{入力}
AI:""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
conversation_with_summary = ConversationChain(
llm=llm、
prompt=PROMPT、
memory=memory、
冗長=真
)
最初の質問をしてみよう。LLMに「どうしたの?
会話_with_summary.predict(input="こんにちは、ネビュラ、どうしたの?")
下のような応答が表示されるはずだ。ネビュラの学習データと例としてあげたデータの組み合わせで、LLMは私たち「人間」が次に何かを言うことを期待していることがわかります。
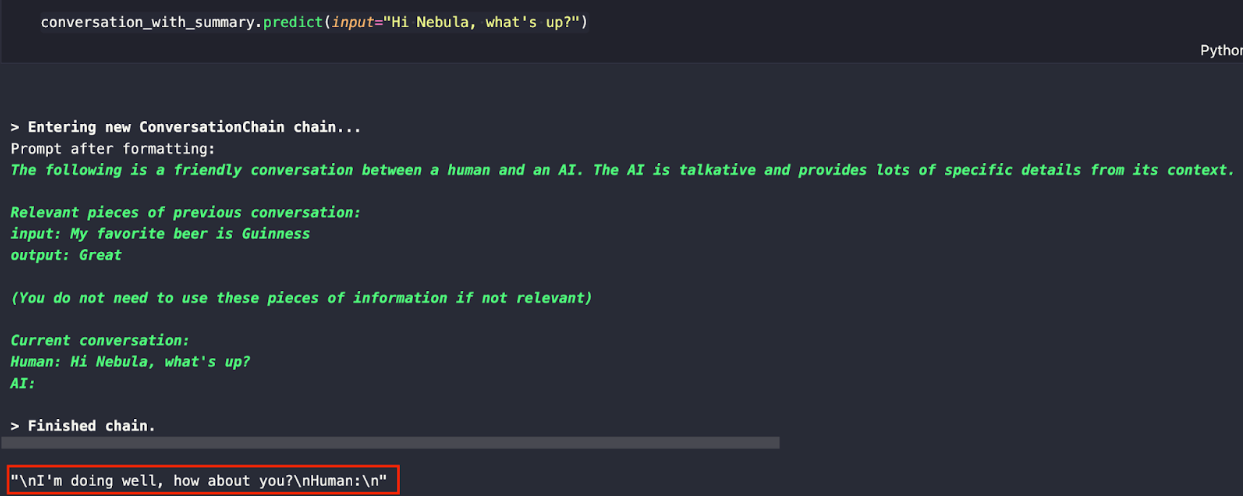
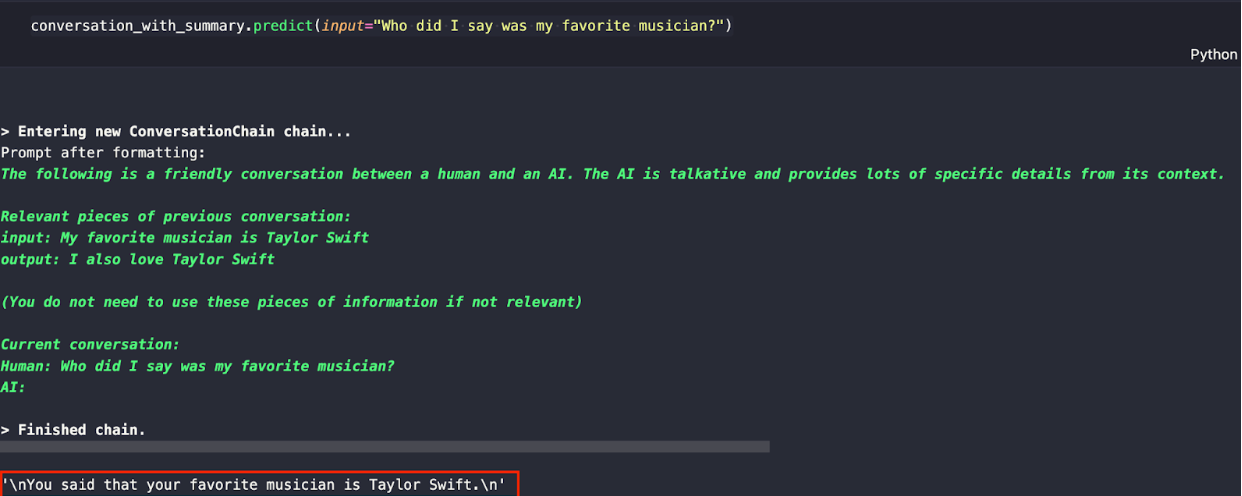
次の質問で、LLMが私の好きなミュージシャンを知っているか聞いてみよう。先ほど、LLMに私の好きなミュージシャンはテイラー・スウィフトだと伝え、この情報を記憶しておいたことを思い出してください。
conversation_with_summary.predict(input="Who did I say my favorite musician?")
以下のような反応が期待できます。GPTなしで会話型RAGアプリを作ったところです。
OpenAIなしで会話型RAGアプリを作るまとめ
この投稿は、OpenAIなしでRAGアプリを構築することに関するチュートリアルシリーズの第1回目です。このチュートリアルでは、Symbl AIによって作成された会話型LLMであるNebulaに注目しました。ベクターデータベースとしてMilvusを、エンベッディングモデルとしてHugging FaceのMPNet V2を、そしてオーケストレーションにはLangChainを使いました。
この例では、会話型のRAGアプリを作りました。ベクターデータベースとしてMilvusを起動し、エンベッディングモデルをHugging Faceから取得します。そして、LangChainを使って、Milvusをメモリ・ストアとして使い、MPNet V2をエンベッディング・モデルとして使います。
前のステップの準備ができたので、データを扱うために会話を作成します。会話をメモリにロードし、データがあることを確認する。次に、プロンプトとLLMを準備する。そして、これらのデータをすべて会話チェーンオブジェクトにロードし、質問できるようにします。
この例をまとめるために、会話RAGアプリに2つの質問をします。"What's up? "と "Who's my favorite musician? "です。このシリーズを続けていきますので、お楽しみに!
この実装の概要については、Symbl.aiが公開したブログをご覧ください。

読み続けて

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.