




すべての開発者が知っておくべき最新のRAG進化8選
大規模言語モデル(LLM)は強力ですが、その性能は学習データの質に左右されます。複雑な質問をする場合、AIには内蔵された知識と外部ソースからの新鮮で関連性の高い情報を組み合わせてほしいものです。まさにそれを行うのが検索拡張生成です。これは、静的な学習データと動的で最新の情報とのギャップを埋めます。
従来のRAGは重要な存在でしたが、開発者たちは可能性の限界を押し広げてきました。この記事では、あなたが直面しているかもしれない実際の問題、つまり検索の遅さ、文脈理解の不十分さ、マルチモーダルデータの扱い、リソース最適化を解決できる、8つの高度なRAGバリアントを紹介します。
これらの新しいRAGタイプが重要な理由
従来のRAGシステムは、2つのステップを組み合わせていました。Milvusなどのベクトルデータベースを基盤とするナレッジベースから文脈として関連データを検索し、言語モデルを使って回答を生成することです。
効果的ではあるものの、RAGの初期実装は、効率性、スケーラビリティ、データフロー管理の課題に直面していました。多くの場合、重要なニュアンスを見落とす可能性のある単純な類似度指標に依存していたため、複雑なクエリに対して一般的な応答になりがちでした。こうした制限を克服するため、研究者たちはモデルが次のことを可能にする新しい戦略を導入しました。
検索ステップを動的に決定する: 常に一度でデータを検索するのではなく、新しい手法では外部情報を検索する最適なタイミングを判断します。
マルチモーダルデータを取り込む: テキストに加えて、一部のシステムは生成コンテンツを豊かにするために画像や動画を検索できます。
リソース使用を最適化する: 高度なRAGフレームワークは、クエリの複雑さに基づいて計算リソースの割り当てを調整します。
ここで、RAGにおける刺激的な進歩が登場します。これらの強化により、開発者とビジネス双方のニーズによりよく応える、より正確で文脈を理解した出力が可能になりました。
クイックリファレンス: どのRAGを使うべきか?
ここでは、これから取り上げる内容を開発者向けにわかりやすく概観します。
| RAGタイプ | 主要なイノベーション | 最適な用途 |
| DeepRAG | 段階的な検索判断プロセス | 法務または医療分析 |
| RealRAG | リアルタイムデータ処理 | ソーシャルメディア監視、ニュースアプリ |
| CoRAG | 逐次的で適応的な多段階検索 | 技術的トラブルシューティング |
| VideoRAG | 動画からテキストへの理解 | 講義の要約 |
| CFT-RAG | ツリーベース(テキスト + 画像)の検索 | 不正検出 |
| CG-RAG | グラフベースの文脈推論 | 引用を伴う学術研究 |
| GFM-RAG | グラフニューラルネットワークによる知識のつながり | 特許分析 |
| URAG | 統合(テキスト + 画像 + 音声)サポート | 教育用チャットボット |
DeepRAG
DeepRAGは、従来の検索パイプラインを、エンドツーエンドで学習された単一のニューラルネットワークに置き換えます。これは、検索拡張推論を意思決定プロセスとしてモデル化します。検索と生成を別々のタスクとして扱うのではなく、外部データに依存するタイミングと内部推論に頼るタイミングを動的に判断します。この段階的なアプローチは、特定の知識ギャップを効果的に狙い撃ちします。
推論集約型タスクを約8〜15%改善することで深さと正確性を高め、不要なデータ検索を減らして計算リソースを節約します。一方で、システム設計の複雑さが増し、検索頻度のバランスを取るための微調整が必要になる場合があります。ファクト検証、マルチステップ推論タスク、研究集約型ドメイン、詳細なレポート生成(例:法的文書分析や医療診断支援)に最適です。
主な特徴:
動的検索: 各ステップを評価し、検索が必要かどうかを判断します。
戦略的意思決定: マルコフ決定過程に似た意思決定プロセスを使用します。
GitHub: https://github.com/microsoft/deepRAG
論文: https://arxiv.org/html/2502.01142v1
RealRAG
RealRAGは、現実世界の画像を検索することで、テキストから画像を生成するモデル(例:FluxやStable Diffusion V3)を強化します。生成された画像を検索された例と比較することで、システムは知識のギャップを埋め、リアリズムを向上させます。
よりリアルな画像出力を生成し、視覚コンテンツの品質を向上させます。ただし、24時間365日のマルチモーダル処理には高いインフラコストがかかります。また、高品質な画像データセットが限られているドメインでは苦戦する可能性があります。正確な視覚表現が不可欠なプロダクトデザインや医用画像処理で特に有用です。
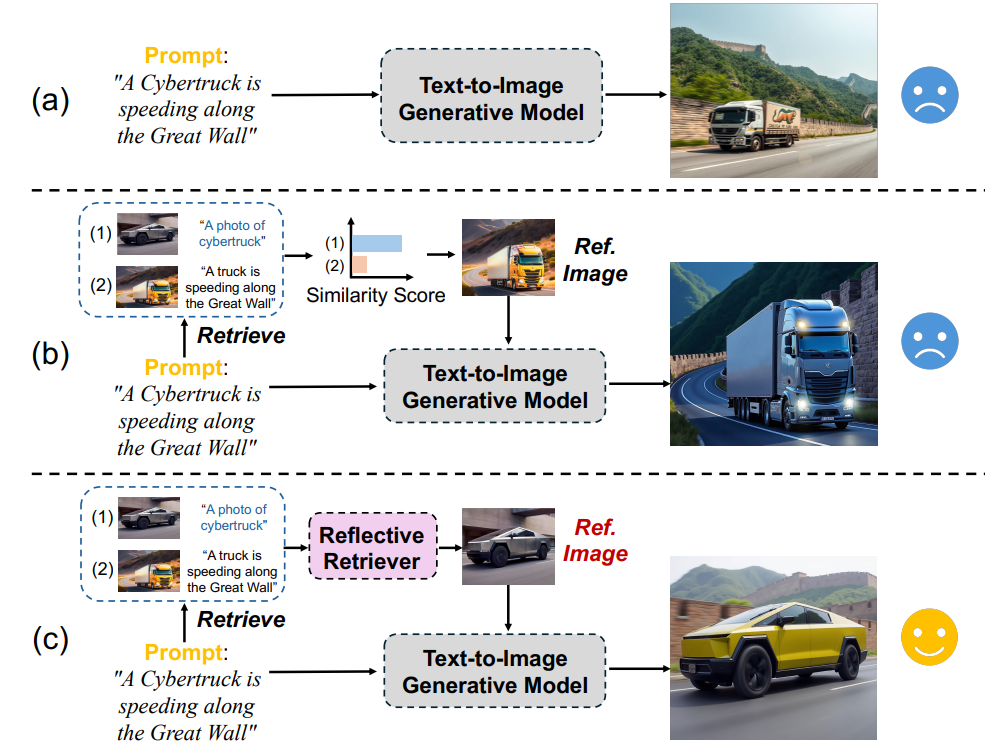 図- RealRAGの概要
図- RealRAGの概要
図: RealRAGの概要 (出典).
主な特徴:
FIDスコアの向上: Stanford Carベンチマークで16.18%
画像ベースの検索: 外部の視覚データで生成を強化します。
自己反省的学習: 画像比較からのフィードバックを通じて出力を改良します。
論文: https://arxiv.org/abs/2502.00848
CoRAG: 検索連鎖拡張生成
chain-of-thought promptingに着想を得たCoRAGは、クエリをサブ質問に分解し、情報を順次検索します。クエリの複雑さに基づいて検索の深さと広さを調整し、必要に応じてクエリを再定式化します。
最大30%高い精度で多面的な質問に対応し、順次検索を通じて重要な情報を優先します。ただし、複数回の検索ラウンドによりレイテンシが増加します。クエリが多層的な情報を必要とする技術的トラブルシューティングや研究に最適です。
主な特徴:
順次検索: 回答を洗練するために複数のステップでデータを検索します。
適応的な計算資源配分: データの必要性に基づいてリソースのバランスを取ります。
論文: https://arxiv.org/abs/2501.14342
VideoRAG: 動画コーパス上の検索拡張生成
動画コンテンツは豊富な情報源ですが、従来のRAGは主にテキストベースの文書向けに設計されています。VideoRAGは、CLIPのような視覚言語モデル(VLM)に加え、音声テキスト変換、フレーム分析、音声処理を使用して情報を抽出することで、RAGの機能を動画コンテンツへ拡張します。これにより、LLMは動画に関連するクエリを理解、処理し、応答できるようになります。動画フレームをテキスト埋め込みに変換し、「感情的対立のあるシーンを見つける」のようなクエリを可能にします。
VideoRAGは、精度を損なうことなく非常に長い動画コンテンツを処理できます。そのデュアルチャネルアーキテクチャは、動画データの詳細で文脈豊かな要約を提供します。残念ながら、4K動画処理には高いGPUリソースが必要であり、マルチモーダルデータストリームの管理にも複雑さがあります。動画コンテンツ分析、講義要約、マルチメディアコンテンツ生成に適しています。
主な特徴:
デュアルチャネルアーキテクチャ: テキストデータと視覚データを別々に処理します。
無制限長の動画処理: 長い動画シーケンスにわたって文脈を維持します。
以下は、その仕組みを示すシンプルなワークフローです。
動画をフレームに分割します。
CLIPを使用して埋め込みを生成します。
埋め込みを類似検索用のベクトルデータベース(Milvus)に保存します。
関連するクリップを取得し、要約を生成します。
論文: https://arxiv.org/abs/2501.05874
GitHub: https://github.com/starsuzi/VideoRAG
CFT-RAG: Cuckoo Filter TreeベースのRAG
CFT-RAGは、構造化データ(例: CSVファイル、SQLテーブル)に対して、改良されたCuckoo Filterを用いたツリーベースの高速化手法を使用します。これにより、検索時のエンティティ特定が高速化され、関連情報へのより迅速なアクセスが可能になります。テキストと画像の両方をサポートしています。たとえば、“Show me healthy meal recipes” と尋ねると、材料リスト and 料理動画が返されます。
検索プロセスを大幅に高速化し、主要なエンティティに焦点を当てることで精度を向上させます。ただし、クリーンで適切に構造化されたデータが必要であり、ツリー構造の維持には定期的な更新が必要です。リアルタイムサポートシステム、不正検出、または高頻度取引プラットフォームに最適です。
主な特徴:
検索と生成: マルチモーダル埋め込みにはMilvus、視覚機能を備えたGPT-4。
エンティティツリー構造: 情報を階層的なツリーに整理します。
Cuckoo Filter最適化: 検索速度と精度を向上させます。
論文: https://arxiv.org/abs/2501.15098
CG-RAG: Contextualized Graph RAG
CG-RAGは、知識グラフを使用してエンティティ(人物やイベントなど)間の関係を捉えることで、コンテキストを強化します。Lexical-Semantic Graph Retrieval(LeSeGR)を活用し、概念間の相互関係を考慮することで回答品質を向上させます。たとえば、“Apple’s product launches”とクエリすると、エンティティ(例: iPhones、CEOs)とその関係が取得されます。Neo4jのようなツールがグラフ保存に使用され、Graph Neural Networks(GNNs)が探索に使用されます。
このRAGの革新は、引用関係をマッピングすることで、複雑なトピックや研究上の問いに優れた効果を発揮します。しかし、事前のスキーマ設計が必要であり、グラフクエリはリソースを大量に消費する可能性があります。全体として、学術研究、技術文書、相互に関連するデータへの深い洞察を必要とするシナリオで非常に効果的です。
主な特徴:
グラフベースの検索: 情報を相互接続されたノードとして構造化します。
引用関係: さまざまな情報がどのように関連しているかを捉えます。
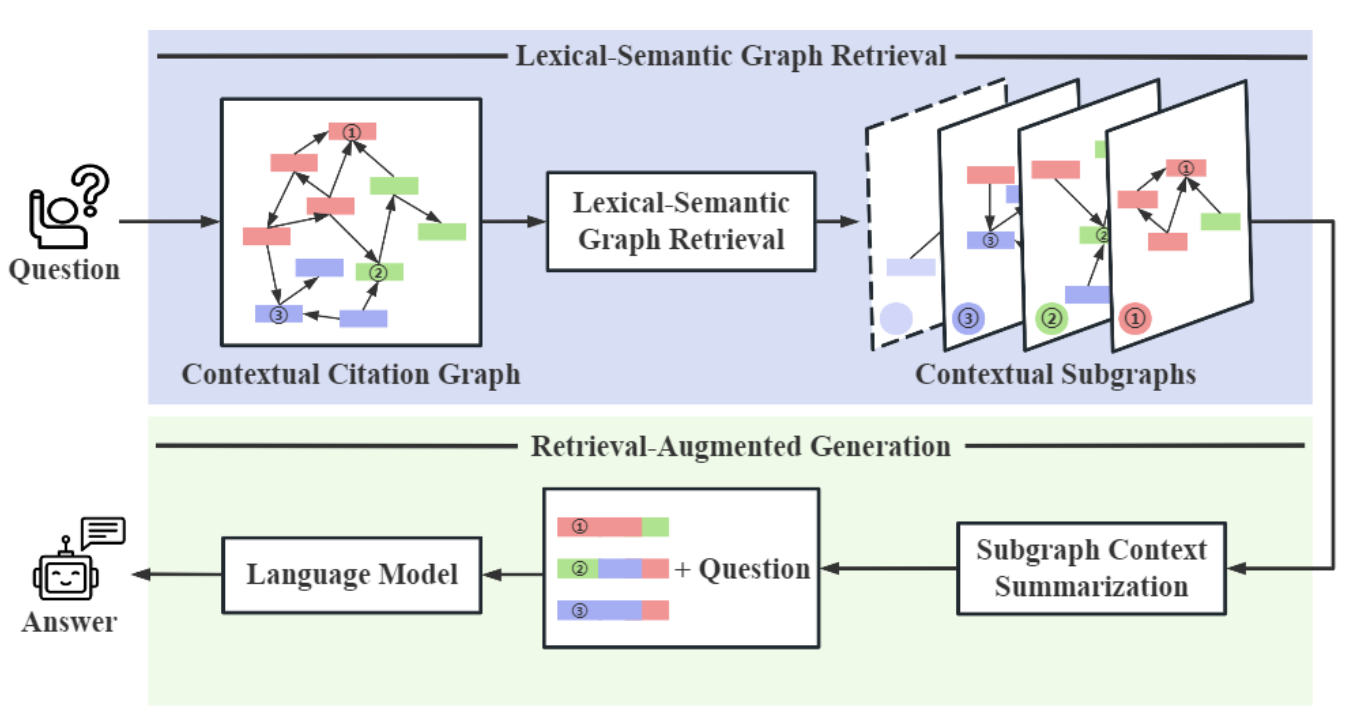 CG-RAGの概要図
CG-RAGの概要図
図: CG-RAGの概要 (出典).
論文: https://arxiv.org/abs/2501.15067
その他のGraphRAGの革新:
GFM-RAG: RAGのためのGraph Foundation Model
GFM-RAGは、GNNsを用いたグラフ基盤モデルを採用し、専門用語の多い分野向けに、ニッチなデータセット(例: 学術論文、特許出願)上のクエリ間のつながりを洗練します。このアプローチにより、構造化された知識グラフ上でのマルチホップ推論が可能になり、知識集約型クエリにおける精度が大幅に向上します。
知識集約型クエリにおける精度を向上させ、大規模データセット内の複雑な関係を処理できます。ただし、明確に定義された特徴セットが必要であり、複雑なクエリでは応答が遅くなる場合があります。正確なデータマッピングを必要とする科学研究で効果的です。
主な特徴:
Graph Neural Network(GNN): 取得されたデータを意味的に豊かにします。
マルチホップ推論: 文書間の分散した情報を結びつけます。
論文: https://arxiv.org/abs/2502.01113
URAG: Unified RAG
URAGは、テキスト、画像、音声、動画を1つのアーキテクチャに統合します。RAG技術とルールベースの手法を使用して軽量LLMをサポートし、計算リソースが限られた環境で正確な回答を提供します。
計算オーバーヘッドを削減しながら、正確な応答を提供します。ただし、ルールベースのコンポーネントは柔軟性を制限する可能性があります。検索とルールベースのロジックのバランスを取ることは難しい場合があります。テキストや図を用いて回答する教育用チャットボットに最適です。
主な特徴:
モジュラー設計: 検索/生成コンポーネントを入れ替え可能。
マルチフォーマット対応: 10種類以上のデータ形式を処理。
ハイブリッドシステム: ルールベースのロジックと最新のRAG技術を統合。
軽量モデル対応: 小規模モデル向けにパフォーマンスを最適化。
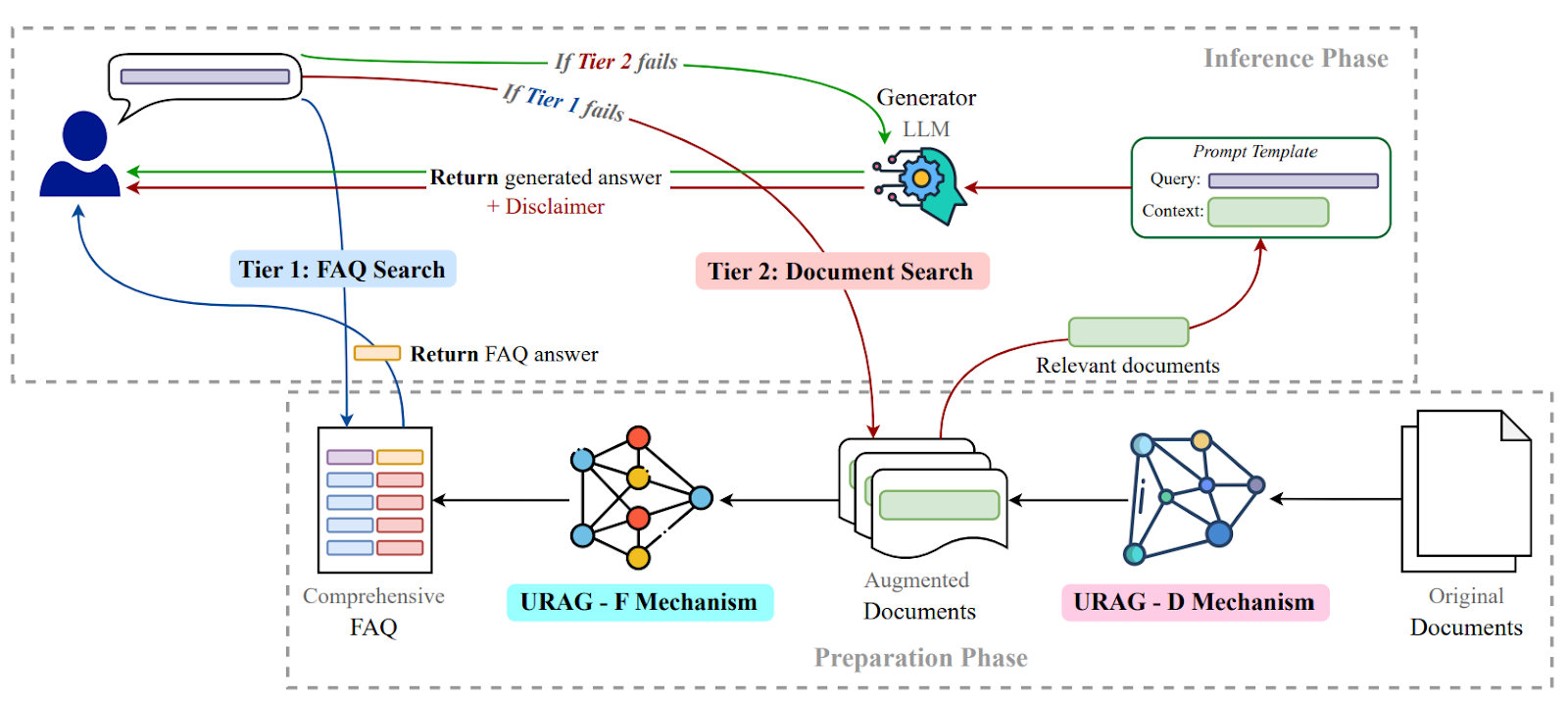 図- 大学チャットボットにおけるLLM性能向上のためのURAGフレームワーク
図- 大学チャットボットにおけるLLM性能向上のためのURAGフレームワーク
図: 大学チャットボットにおけるLLM性能向上のためのURAGフレームワーク (出典).
論文: https://arxiv.org/abs/2501.16276
リソース要件の比較
| RAGタイプ | GPUメモリ | レイテンシ | セットアップの複雑さ | 最高のパフォーマンス |
|---|---|---|---|---|
| DeepRAG | 中 | 中 | 中 | 推論タスク |
| RealRAG | 高 | 高 | 高 | ライブデータストリーム |
| CoRAG | 中 | 高 | 中 | マルチステップクエリ |
| VideoRAG | 非常に高 | 非常に高 | 高 | 動画コンテンツ |
| CFT-RAG | 低 | 低 | 中 | 構造化データ |
| CG-RAG | 中 | 中 | 高 | 関係性クエリ |
| GFM-RAG | 高 | 中 | 非常に高 | 複雑な推論 |
| URAG | 中 | 中 | 中 | 混合コンテンツ |
ここで紹介した8つのRAGバリアントは、この分野における最近の刺激的な発展を示しており、その多くは研究論文や初期段階の実装から生まれています。これらの革新は大きな可能性を示し、一般的なRAGの課題に対する興味深いアプローチを実証していますが、コミュニティがさまざまな文脈で実験を重ねる中で、まだ進化の途上にあります。
新興技術全般と同様に、これらのアプローチが特定のデータやユースケースでどのように機能するかを確認するため、小規模な実験から始めることをおすすめします。以下のコード例や推奨事項は、本番環境向けの設計図としてではなく、探索を始めるための助けとなることを意図しています。各バリアントは、特定の要件やインフラストラクチャに合わせるために、多少の適応が必要になる場合があります。
結論
RAGの最新の進歩は、精度、速度、コンテキスト認識を強化することでAIにおける重要な課題を解決しており、ニーズに合わせたRAGバリアントが常に存在します。これらの革新により、よりスマートで応答性の高いシステムが実現し、新たな可能性を引き出し、業界全体でLLMの応用範囲を拡大できます。
Zilliz CloudのマネージドMilvusサービスを活用することで、開発者はこれらのRAGバリアントを容易にデプロイできます。RAGが進化し続けるにつれて、AIの未来を形作る上で重要な役割を果たし、応答が流暢であるだけでなく、最新のデータやコンテキストの手がかりに深く基づいたものになることを保証します。
関連リソース

読み続けて

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.