




GPTCacheを使用した100倍高速なレスポンスと大幅なコスト削減を実現するLLMアプリの構築
この記事はODBMSに掲載されたもので、許可を得てここに再掲載している。
魔法のようなChatGPTや他の大規模言語モデル(LLM)は、自然言語を理解し、複雑な質問に答える能力で、ほとんどすべての人を驚かせました。その結果、より多くの開発者がインテリジェントなアプリケーションを構築するためにLLMを活用しています。しかし、LLMアプリケーションの人気が高まり、トラフィックが急増すると、LLM API呼び出しのコストは大幅に増加します。また、レスポンスの遅延が大きいと、特にLLMのピーク時にフラストレーションが溜まり、ユーザーエクスペリエンスに直接影響します。
この投稿では、LLMアプリケーションの効率とスピードを妨げる課題に対する実用的な解決策を紹介する:GPTCacheです。このオープンソースのセマンティックキャッシュは、少なくとも100倍以上の検索速度を実現し、キャッシュがヒットしたときのLLMサービスの利用コストをゼロにするのに役立ちます。
LLMベースのアプリケーションを構築する際の主な課題
GPTCacheに深く潜る前に、まずLLMに基づくインテリジェントなアプリケーションを構築する際の2つの重要な課題について説明しましょう。
不必要なAPI呼び出しによるコスト増
アプリケーションはLLMのAPIを呼び出すことで、LLMの強力な推論機能を活用することができます。しかし、APIの呼び出しは無料ではありません。もしあなたのアプリケーションが本番用で、大規模なユーザーを抱えている場合、頻繁にAPIを呼び出すと莫大なコストがかかる可能性があります。さらに、LLMがすでに答えを出しているような、意味的に同じ質問に対して不必要なAPIコールをすることになり、お金とリソースを無駄にしてしまうかもしれません。
応答待ち時間が長く、パフォーマンスとスケーラビリティが低い。
大規模な言語モデルは、通常、驚異的なワークロードを処理します。ChatGPTを例にとってみましょう。2023年7月現在、アクティブ・ユーザーは1億人を超え、6月だけで約10億件のアクセスがあった。このような高負荷のため、特にピーク時にはLLMの応答が遅くなり、LLMに依存するアプリケーションも遅くなります。
さらに、LLMサービスはレート制限を実施し、アプリケーションが一定時間内にサーバーにコールできるAPI回数を制限します。レート制限にヒットすると、一定期間が経過するまで追加のリクエストがブロックされ、サービス停止につながる。このボトルネックはユーザーエクスペリエンスに直接影響し、アプリケーションが処理できるリクエスト数を制限します。
GPTCacheとは?
GPTCacheはオープンソースのセマンティックキャッシュで、言語モデルによって生成されたレスポンスを保存・検索することで、GPTベースのアプリケーションの効率と速度を改善するように設計されています。GPTCacheは、埋め込み、類似性評価、保存場所、および立ち退きポリシーの選択肢を提供し、ユーザーが特定の要件に合わせてキャッシュをカスタマイズすることを可能にします。さらに、GPTCacheはOpenAI ChatGPTインターフェースとLangchainインターフェースの両方をサポートしており、今後数ヶ月でさらに多くのインターフェースをサポートする予定です。
GPTCache はどのように動作しますか?
簡単に言うと、GPTCacheはLLMの応答をキャッシュに保存します。そのため、LLMが以前に応答した同様のクエリーをユーザーが行った場合、GPTCacheはLLMを再度呼び出すことなく検索し、結果をユーザーに返します。Redisのような従来のキャッシュシステムとは異なり、GPTCacheはセマンティック・キャッシングを採用しており、埋め込みによってデータを保存・検索します。GPTCacheは埋め込みアルゴリズムを利用して、ユーザからの問い合わせとLLMからの応答を埋め込みデータに変換し、Milvusのようなベクトルストアを使用して、これらの埋め込みデータに対して類似検索を行います。
GPTCacheは6つのコアモジュールから構成される:LLMアダプタ、プリプロセッサ(コンテキストマネージャ)、埋め込みジェネレータ、キャッシュマネージャ、類似度評価器、ポストプロセッサ。
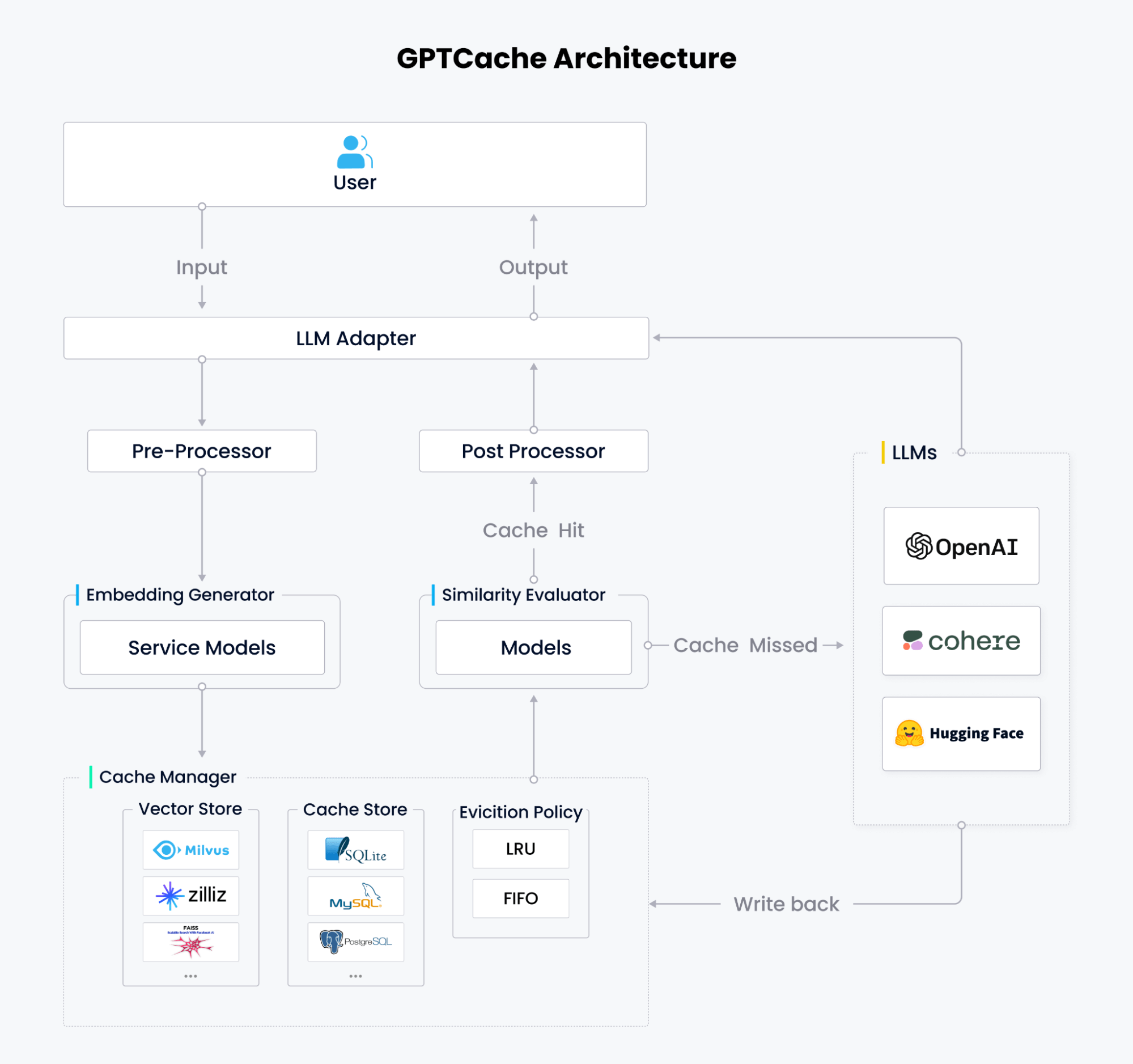
LLM アダプタ
LLM アダプターは GPTCache の外部インターフェイスとして機能します。クエリをキャッシュプロトコルに変換し、キャッシュワークフローを制御し、 キャッシュ結果を LLM レスポンスに変換します。LLM アダプタを使えば、コードを書き換えたり新しい API を学んだりすることなく言語モデルを切り替えられるので、さまざまな言語モデルの実験やテストがより簡単になります。
GPTCacheはすでにOpenAI ChatGPT API、LangChain API、MiniGPT4 API、Llamacpp APIをサポートしています。私たちのロードマップには、Hugging Face Hub、Bard、Anthropicなど、より多くのAPIの追加が含まれています。
プリプロセッサ
プリプロセッサは、入力から冗長な情報を削除したり、入力情報を圧縮したり、長いテキストをカットしたり、その他の関連タスクを実行したりするなど、LLMに送信されるクエリを管理、分析、フォーマットします。
エンベッディング・ジェネレーター
エンベッディング・ジェネレーターは、ユーザーのクエリーを、好みのエンベッディング・モデルを使用したエンベッディング・ベクターに変換します。GPTCacheは、HuggingFaceやGitHubのローカルモデルと、埋め込みを生成するためのクラウド埋め込みサービスをサポートしています。これには、OpenAIの埋め込みAPI、GPTCache/paraphrase-albert-onnxモデルによるONNX、Hugging Face埋め込みAPI、Cohere埋め込みAPI、fastText埋め込みAPI、SentenceTransformers埋め込みAPI、画像埋め込み用のTimmモデルなどがあります。
キャッシュマネージャ
Cache ManagerはGPTCacheのコアモジュールです。ユーザのリクエストとLLMのレスポンスを保存し、3つのコンポーネントから構成されます:
ベクトルストア** ベクトルの保存と類似検索の埋め込み用
ユーザーのリクエストとそれに対応するLLMのレスポンスを保存するキャッシュストア**。
LRU(Least Recently Used)またはFIFO(First In, First Out)に従ってキャッシュ容量を制御するための退去ポリシー**。
現在、GPTCacheはキャッシュストレージとしてSQLite、PostgreSQL、MySQL、MariaDB、SQL Server、Oracleを、ベクトルストレージと検索としてMilvus、Zilliz Cloud、Weaviateをサポートしています。ユーザーは、パフォーマンス、スケーラビリティ、コストのバランスを取りながら、ニーズに合わせて好みのベクトル・ストア、キャッシュ・ストア、および消去ポリシーを選択することができる。
類似性評価ツール
類似性評価機能は、キャッシュされた回答が入力クエリと一致するかどうかを判断します。GPTCacheは、複数の類似性ストラテジーを組み合わせた標準化されたインターフェイスを提供し、ユーザーが特定のニーズやユースケースに応じてキャッシュマッチをカスタマイズできるようにします。
ポストプロセッサー
ポストプロセッサーは、キャッシュにヒットしたときにユーザーに返す最終的なレスポンスを準備します。回答がキャッシュにない場合は、LLM アダプタが LLM に応答を要求し、Cache Manager に書き戻します。
GPTCache の利点
LLM APIコールの大幅なコスト削減
LLMはAPIコールのたびに料金を請求します。GPTCache は、開発者が LLM の回答を、似たような質問や繰り返し聞かれる質問に対して意味的にキャッシュし、キャッシュにヒットした場合に API コストをゼロにするのに役立ちます。GPTCacheはAPIコールの全体数を減らし、コストを劇的に削減します。超高トラフィックのアプリケーションには特に有益です。
100倍速いレスポンス
GPTCacheはLLMアプリケーションのレスポンスタイムを大幅に短縮できます。ChatGPTのピーク時には、レスポンスに数秒かかることもあります。しかし、GPTCacheを使用すると、アプリケーションは100ミリ秒未満で以前に要求された回答を取得することができ、これは少なくとも100倍高速です。
スケーラビリティの向上
LLMの応答をキャッシュすることで、LLMサービスの負荷が軽減され、アプリケーションのスケーラビリティが向上し、増大するリクエストを処理する際のボトルネックを防ぐことができます。
可用性の向上
LLMサービスにはレート制限が設定されていることが多く、アプリが特定の時間枠内でサーバーにアクセスできる回数が制限されています。GPTCacheは、API呼び出しの総数を減らし、クエリの増加に対応するためにアプリケーションを迅速に拡張できるようにします。このアプローチにより、アプリケーションのユーザーベースが拡大しても一貫したパフォーマンスが保証されます。
GPTCacheの利点の詳細については、GPTCacheとはのページをご覧ください。
GPTCache と CVP スタックを活用した AI チャットボット「OSS Chat
GPTCacheはRAG(Retrieval-Augmented Generation)に有益で、アプリケーションがCVP (ChatGPT/LLMs+vector database+prompt as code)スタックを実装することで、より正確な結果を得ることができます。OSSチャットは、GitHubプロジェクトに関する質問に答えることができるAIチャットボットで、GPTCacheとCVPスタックがRAGシナリオでどのように機能するかを示す最良の例です。
OSS Chatのアーキテクチャ](https://assets.zilliz.com/OSS_Chat_s_architecture_6944dd9569.png)
OSS Chatは、機械学習パイプラインであるTowheeを利用して、GitHubプロジェクトの情報と関連ドキュメントページをエンベッディングに変換します。そして、そのエンベッディングをフルマネージドベクターデータベースサービスであるZilliz Cloudに保存します。ユーザーがOSS Chatを通じて質問をすると、Zilliz Cloudはそのクエリに最も関連する上位k件の結果を検索します。これらの結果は、より広いコンテキストを持つプロンプトを作成するために、元の質問と組み合わされます。
ChatGPTにプロンプトを送信する前に、Zilliz CloudはまずGPTCacheに答えがないかチェックします。キャッシュにヒットした場合、GPTCacheはユーザーに直接答えを返します。キャッシュがヒットした場合、GPTCacheはユーザーに直接回答を返します。キャッシュがヒットしなかった場合、GPTCacheはChatGPTに元のプロンプトを送信して回答を求め、将来の使用のためにキャッシュに戻します。GPTCache により、OSS Chat は低コスト、低レスポンスレイテンシ、少ない開発工数で優れたユーザーエクスペリエンスを提供することができます。
要約
LLMをベースとしたアプリケーションの構築は、エコシステム内のすべての人に利益をもたらす成長トレンドです。しかし、アプリ開発者は、APIコールの高コストと応答レイテンシの高さという2つの主要な課題に直面しています。GPTCacheはこれらの課題を解決する完璧なオープンソース・ソリューションであり、ネットワーク遅延の削減、可用性の向上、スケーラビリティの向上など、さらに多くの利点を提供する。
GPTCacheを使い始めるための実践的なチュートリアルについては、GPTCacheドキュメントを参照してください。コミュニティ・オフィス・アワー](https://gptcache.readthedocs.io/en/latest/usage.html)で質問したり、アイデアを共有することができます。また、GPTCacheへの貢献も歓迎します。
 Fendy Feng
Fendy FengFendy Feng is the Technical Marketing Writer at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
読み続けて

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.