




DeepseekがOpenAIのようなAIの巨人を目覚めさせた理由と、あなたが気にかけるべき理由
DeepSeek R1は単なるAIモデルではなく、Nvidiaの株価が17%下落した理由であり、Metaがそれを研究するために4つのウォールームを設置した理由であり、トランプ大統領が警鐘を鳴らした理由であり、サム・アルトマンが公の場で対処せざるを得なくなった理由である。その台頭は、AIの統制、市場の混乱、国家安全保障に関する議論を巻き起こし、テック企業に戦略の再検討を促している。
ディープシークR1の出現は、企業が高度なツールへのアクセスに高額な料金を課す現在のAIビジネスモデルに挑戦している。開発者がコストのかかるインフラに頼ることなく、コーディング、推論、自動化のためにAIを導入できるようになれば、競争環境は大きく変わるかもしれない。
これは単なるビジネス上の問題ではなく、誰がAIの未来を支配するのかという問題なのだ。米国当局が国家安全保障上のリスクを指摘】(https://www.cbsnews.com/news/deepseek-ai-raises-national-security-concerns-trump/)する中、DeepSeek R1はOpenAIやGoogleといった企業に新たな現実を突きつける。DeepSeek R1はAIのターニングポイントなのか、それとも単なる一過性のトレンドなのか?もう少し詳しく見てみよう。
ディープシークR1とは?
図:DeepSeekのダッシュボードのスクリーンショット_。
DeepSeek R1は、DeepSeek AIによって作成された大規模言語モデルであり、正確なコーディング、数学的推論、構造化された問題解決を必要とするタスクのために構築されています。CodeCorpus-30M、arXivの数学論文、多言語ウェブテキストなどのデータセットを使用して、14.8兆のトークンで訓練された。この特別なトレーニングにより、ソフトウェア開発、科学研究、技術自動化の課題に対応することができます。
このモデルには2つのバージョンがある。1つ目は、DeepSeek-R1-Zeroとして知られるもので、強化学習だけを用いて開発された。これは、エージェントが環境と相互作用することによって意思決定を行うことを学習する機械学習の一種である。エージェントは行動を行い、報酬やペナルティの形でフィードバックを受け取る。エージェントの目標は、どの行動が最良の結果につながるかを学習することで、時間の経過とともに報酬総額を最大化することである。これによってエージェントは強力な推論能力を得たが、反復的な出力や言語の混在といった問題も引き起こした。これらの問題を解決するために、DeepSeek R1は強化学習フェーズの前に準備データを追加することで作成され、明瞭さと推論力を向上させた。
MITライセンスの下、オープンソースモデルとして公開されたため、開発者から研究者まで、誰でも制限なく使用、修正、導入することができる。このようなアプローチにより、DeepSeek R1は、技術的なタスクにおける精度と効率が鍵となるアプリケーションにとって実用的な選択肢となっている。
DeepSeek R1の仕組み
DeepSeek R1は、MoE(Mixture-of-Experts)アーキテクチャに基づいて構築されています。簡単に言うと、モデルには6710億個のパラメータがあり、学習中に調整されるが、タスクを処理するたびに使用されるのは370億個だけである。軽量のゲーティング・ネットワークが意思決定者のように機能し、どの特化したサブネットワークが入力を処理すべきかを選択する。つまり、モデルは必要なリソースだけを使用し、全体的な計算需要を下げるのだ。
トレーニング中、モデルはDeepSeek-R1-Zeroと呼ばれるバージョンからスタートした。この段階では、モデルは、思考の連鎖推論と呼ばれる、思慮深く段階的な回答を生成することで報酬を受け取って学習した。しかし、この方法では回答が繰り返され、言語が混在して出力されることになった。明瞭さを向上させるため、開発者たちは、慎重に選ばれた思考連鎖の例を使って、教師ありの微調整を行うコールドスタート段階を導入した。この後、モデルはGroup Relative Policy Optimization(GRPO)を使用した強化学習をさらに2ラウンド行った。GRPOでは、モデルは同じ入力に対して複数の回答を生成し、それらを比較し、最も明確で正確な回答に対して報酬を受け取る。そして、最良の出力が拒絶サンプリングによって選択され、さらなる微調整に使用される。
DeepSeek R1 には、いくつかの効率化技術も組み込まれています:
Multi-Head Latent Attention (MLA)**](https://arxiv.org/abs/2502.07864):このテクニックは、内部データ構造(キー・バリュー行列)をより小さな潜在ベクトルに圧縮し、処理中に必要なメモリを削減します。
FP8混合精度トレーニング**](https://arxiv.org/pdf/2310.18313):高精度数値の代わりに8ビット浮動小数点数値を多くの計算に使用することで、モデルのメモリ消費量を減らし、処理を高速化します。
Dynamic Token Inflation and Soft Token Merging:**これらのメソッドは、冗長な情報を持つトークンをマージし、後に重要な詳細を復元することで、テキスト処理を最適化します。
これらのアプローチを組み合わせることで、DeepSeek R1は数学的推論やコードデバッグのような複雑なタスクを確実に実行しながら、計算コストを低く抑え、トレーニング費用をGPT-4のようなモデルよりも大幅に低く抑えることができます。
DeepSeek R1の主な機能
DeepSeek R1 は、技術的なタスクに優れた性能を発揮するように設計されており、その性能は複数のベンチマークやアプリケーションで明らかです。以下は、その主な長所です:
数学的推論:** DeepSeek R1 は、数学の課題において素晴らしいパフォーマンスを発揮します。MATH-500ベンチマークでは97.3%の合格率を達成し、AIME 2024ベンチマークでは79.8%の合格率@1に達しました。これらの結果は、このモデルが複雑な数学的問題を高い精度で処理できることを示しています。
コーディングとデバッグ:**コーディングタスクにおいて、このモデルは強力な能力を発揮します。Codeforcesのレーティングは2029で、人間の参加者の中で96.3パーセンタイルに位置しています。デバッグの精度は約90%で、これは実世界のシナリオでコードの問題を確実に特定し、修正できることを意味します。
構造化された論理的推論:** DeepSeek R1 は、問題に取り組む際に明確なステップバイステップの推論を生成するように構築されています。この機能は、構造化された問題解決タスクでの一貫したパフォーマンスに反映されており、モデルでは複雑な課題を理解しやすい部分に分解します。この課題をどのように分解するかを見てみましょう。
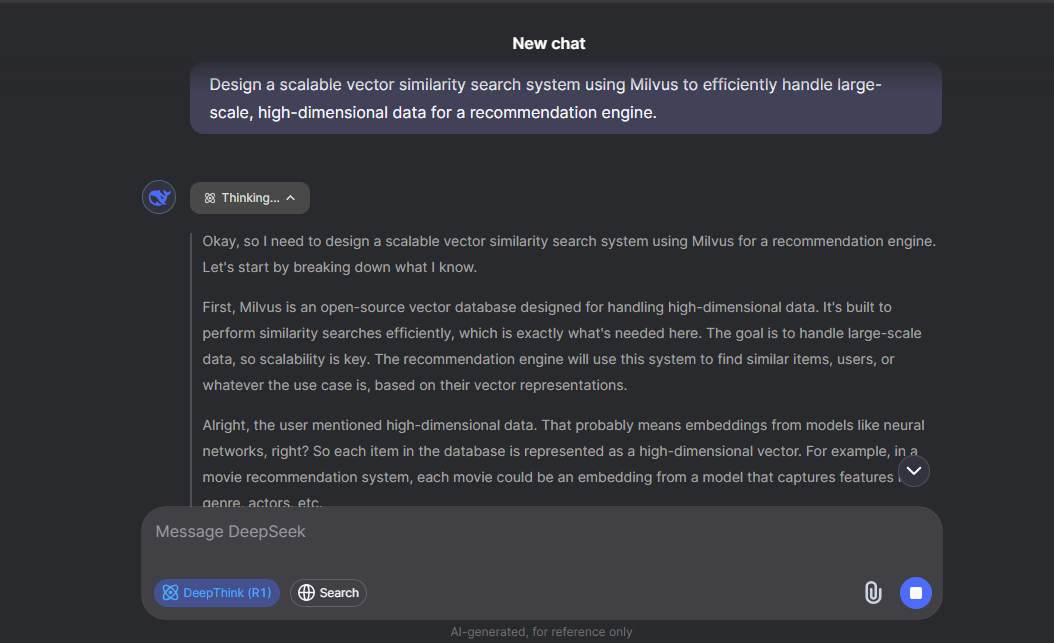
図:DeepSeekがMilvusベクトル検索システムの設計を段階的に分解したもの
ご覧のように、DeepSeekはまず、Milvusが高次元データに最適化されたオープンソースのベクトル・データベースであることを説明し、タスクをステップ・バイ・ステップで分解している。特に、類似アイテムを見つけるためにベクトル埋め込みを使用するレコメンデーションエンジンのために、大規模なデータセットを効率的に処理するという目標について言及している。DeepSeekはまた、これらの埋め込みがニューラルネットワークのようなモデルに由来することが多いとし、例として映画の推薦システムを挙げている。このスクリーンショットは推論フェーズ全体を示しているわけではありませんが、DeepSeekで同じプロンプトを使用することで、実装までの推論方法を確認することができます。
- 多言語理解:*** このモデルは多言語のウェブテキストでトレーニングされており、複数の言語でのクエリを処理し応答することができます。この幅広い言語能力により、正確で論理的な応答が必要とされるグローバルなアプリケーションに役立ちます。
1.**FAQページ、サポート記事、技術マニュアルのような、すべての関連文書を集めることから始める。これらの文書を、個々の質問と回答のペアのような、小さくまとまった部分に分割する。このセグメンテーションにより、各テキストの断片に焦点が絞られ、後で簡単に検索できるようになる。
DeepSeek R1 vs. OpenAI o1 vs. Claude 3.5 Sonnet
DeepSeek R1は、OpenAI o1やClaude 3.5 Sonnetのようなモデルと比較した場合、パフォーマンスだけでなく、コストやアクセシビリティにおいても際立っています。以下の表は、主要メトリクスをまとめたものです:
| ------------------------------------------------------------------------------------------------------------------------------------ | -------------------------- | ------------------------ | ------------------------ | | Metric | DeepSeek R1* | **OpenAI o1****** | クロード3.5ソネット | | コードフォース評価|2029(96.3パーセンタイル)|2061(89パーセンタイル)|公式には表示されていません。 | デバッグ精度|90%|80%|75 | MATH-500 合格@1|97.3%|96.4%|DeepSeek R1 よりも低い。 | SWE-bench 検証済み(解決済み)|49.2%|48.9%|50.8 | LiveCodeBench(Pass@1-COT)|65.9%|63.4%|33.8%|です。 | Aider-Polyglot(精度)| 53.3% | 61.7% | 45.3% | | 価格(入力トークン)|~0.14ドル/100万トークン|~15ドル/100万トークン|~3ドル/100万トークン | 価格(アウトプット・トークン)|~100万トークンあたり2.19ドル|~100万トークンあたり6000ドル|~100万トークンあたり1500ドル | ライセンス|オープンソース(MIT)|プロプライエタリ(専有) | コンテキスト・ウィンドウ|128Kトークン|200Kトークン|200Kトークン
DeepSeek R1は、いくつかの技術ベンチマークで独自の地位を確立しています。これは、競争の激しいプログラミングコンテストに由来し、モデルがコーディングの課題にどの程度対処できるかを示す、強力なCodeforces評価を達成しています。また、デバッグの精度にも優れています。数学的推論では、MATH-500で97.3%の合格率に達し、OpenAI o1をわずかに上回っています。さらに、SWE-bench(実際のGitHubの問題と対応するコードベースを提示することで、LLMが現実世界のソフトウェアの問題を解決する能力を評価する)とLiveCodeBench(LeetCode、AtCoder、Codeforcesのようなプラットフォームからの新しい問題を継続的に取り入れることで、動的で汚染のない評価を提供する)でのパフォーマンスは、複雑なタスクを解決するための信頼できる一貫した能力を反映しています。
主な利点は、コスト効率です。DeepSeek R1の投入コストは、OpenAI o1の料金がはるかに高いのに比べ、100万トークンあたり~0.14ドルと低い。出力トークンの価格設定も大幅に低い。これらの経済的メリットは、MITライセンスの下でのオープンソースの性質に加え、OpenAI o1やClaude 3.5 Sonnetが提供するプロプライエタリなモデルでは利用できない柔軟性をユーザーに提供します。
コンテキスト・ウィンドウが 128K トークンと、他社の 200K トークンよりも若干小さい DeepSeek R1 は、パフォーマンスをそれほど犠牲にすることなく、技術的なタスクに最適化されています。この比較は、DeepSeek R1が強力なパフォーマンス、コスト効率、オープンなアクセシビリティの魅力的な融合を提供していることを示しており、この組み合わせは、技術分野における高度なAIツールの導入方法を再構築する可能性がある。
DeepSeekとMilvusの統合
DeepSeek R1の技術的性能とコスト効率は、有能なベクトルデータベースと組み合わせることで、実世界の検索-拡張世代アプリケーションに適した候補となる。そのようなデータベースの1つがMilvusであり、GPUアクセラレーションとHNSWやIVFといった高度なインデックス作成技術をサポートしているため、低レイテンシかつ高スループットで数十億のベクトルを処理できるように設計されている。これらの機能により、Milvusはクエリに最も関連性の高いコンテキストを迅速に取得するのに最適なものとなっており、DeepSeek R1はこれを使用して、情報に基づいた応答を生成します。
広範なFAQや技術文書をホストする複雑なソフトウェア製品の顧客サポートポータルを考えてみましょう。ここでは、MilvusとDeepSeek R1を使用して、RAG(Retrieval-Augmented Generation)パイプラインを構築する方法を説明します:
1.1. データの準備: FAQ ページ、サポート記事、技術マニュアルなど、すべての関連ドキュメントを集めることから始めま す。これらのドキュメントを、個々の質問と回答のペアなど、小さくまとまった部分に分割します。このセグメンテーションにより、各テキストの断片に焦点が絞られ、後で簡単に検索できるようになる。
2.埋め込み生成: 各テキストセグメントを、埋め込みモデルを使って、埋め込みとして知られる数値ベクトルに変換する。これらの埋め込みは、テキストの意味的な意味を捉え、効果的な類似性比較を可能にする。この例では、各FAQセグメントは、その内容を正確に表す埋め込みに変換される。
3.Milvusへのデータの挿入: ベクトル次元や選択された距離メトリック(例えば、 内積)のような主要なパラメータを指定することにより、Milvusコレクションをセットアップする。生成された埋め込みデータを、関連するテキストとともにコレクションに挿入すると、ドキュメントの検索可能なインデックスが作成されます。
4.クエリ処理: 顧客がクエリ、例えば、**How do I reset my account password?クエリとドキュメントの埋め込みが同じベクトル空間であることを確認することは、正確なマッチングのために非常に重要です。
5.検索: Milvusを使って、クエリー埋め込みでコレクションを検索し、上位のマッチするドキュメントセグメントを検索します。Milvusは最も類似したテキストを素早く特定し、クエリに正確に答えるために必要な関連コンテキストを提供します。
6.DeepSeek R1 によるレスポンス生成: 取得したセグメントを首尾一貫したコンテキストに結合し、元のクエリとともに、OpenAI スタイルの API を介して DeepSeek R1 にフィードします。その後、このモデルは、検索されたドキュメントの情報を組み込んだ、コンテキストを意識した詳細な回答を生成します。
7.**最後に、生成された回答を顧客に提供します。回答は、特定のクエリと関連するコンテキストデータの両方を反映し、回答が正確で有用であることを保証します。
この統合は、Milvusの効率的なベクトル検索とDeepSeek R1の正確な言語生成を活用し、堅牢でスケーラブルなRAGパイプラインを作成します。顧客サポート、ナレッジ管理、技術的なトラブルシューティングなどの用途に強力なソリューションを提供し、情報へのアクセスや提供方法を変革します。
なぜDeepSeek R1はAIの巨人を脅かすのか
DeepSeek R1は、既存企業に戦略の見直しを迫っている。業界のリーダーたちは今、高い技術力と低い運用コストを備えたモデルが、高価なハードウェアとサブスクリプション料金に基づく従来の収益源を破壊する可能性に直面している。この変化によって、企業は研究投資や長期計画を再考し、高度なAIが経済的な障壁なしに利用できるようになるかもしれない状況に備えている。
波及効果は企業のバランスシートにとどまらない。独占企業は現在、代替アプローチを模索し、製品戦略を調整している。一方、このようなモデルが広く採用されることで、ハイテク業界全体でリソースの大幅な再配分が行われるのではないかという懸念も高まっている。このため、戦略転換の波が押し寄せており、AI開発モデルや価格体系の見直しを社内で開始する企業も出てきている。
さらに、その影響は政治領域にも及んでいる。規制当局や政府関係者は、高性能AIツールのオープンな利用可能性が、国家安全保障や世界的な技術的リーダーシップに関する問題を提起していることに注目している。高度なAIの制御と利用をめぐるこの議論は、将来の規制と技術世界のパワーバランスに関する議論を激化させ、DeepSeek R1のようなモデルがいかに複数のレベルで業界を再編成しうるかを浮き彫りにしている。
なぜ気にする必要があるのか?
開発者、企業、そして日常的なユーザーにとって、DeepSeek R1の意味は技術的なベンチマークにとどまりません。オープンソースで利用でき、運用コストが低いため、これまでは高額な料金や独自の制限に縛られていた技術革新やカスタマイズに新たな機会が生まれます。
開発者は現在、商用APIを待ったり、ライセンス条件に制限されたりすることなく、AIソリューションを構築し、カスタマイズするチャンスを手にしている。この自由は、より多くの実験、より迅速なアイデアの反復、ニッチなニーズに直接対応するツールを作成する能力を意味する。高性能の言語モデルを修正し、展開する能力は、自動化、技術サポート、さらには創造的なアプリケーションなどの分野で飛躍的な進歩をもたらす可能性がある。
企業にとっては、導入コストの低減がゲーム・チェンジャーとなる。企業は、高価なハードウェアやサブスクリプション料金を負担することなく、高度なAI機能をワークフローに組み込むことができる。その結果、より効率的なオペレーションが実現し、オーバーヘッドが削減され、最終的には各市場での競争力が高まる可能性がある。企業がこうした費用対効果の高いソリューションを採用することで、市場全体のダイナミクスが変化し、イノベーションの拡大と参入障壁の低下につながる可能性がある。
政策立案者や社会全体も注目すべきである。アクセス可能で高性能なAIの普及は、データ・セキュリティ、規制、世界規模での技術力のバランスに関する重要な問題を提起している。高度なAIツールはもはや一部の大企業に限定されるものではなく、倫理的な使用、説明責任、国家安全保障に関する議論がますます重要になっている。このような広範なアクセスはテクノロジーを民主化する可能性を秘めているが、同時に、このような強力なツールをどのように管理・規制するかについて慎重に検討する必要もある。
つまり、あなたがAIの限界を押し広げようとしている開発者であれ、業務の効率化を目指している企業であれ、テクノロジーの安全かつ公正な利用を確保することを任務とする政策立案者であれ、DeepSeek R1の出現は人工知能の将来の展望に大きな影響を与える可能性がある。
結論
DeepSeek R1は、AIについての考え方や利用方法を変えつつある。技術的なタスクにおける強力なパフォーマンス、低い運用コスト、オープンアクセスにより、高価なプロプライエタリモデルに代わる本格的な選択肢となっている。このモデルは、高品質なアウトプットと、高度なAIに対するより利用しやすいアプローチの両方を提供し、新たな期待を抱かせている。Milvusのようなツールと統合することで、DeepSeek R1は、顧客サポートから知識管理まで、実世界のアプリケーションでその価値を証明しています。企業や規制当局がAIにおけるコントロールとイノベーションを再評価する中、DeepSeek R1はテクノロジーの未来を形作り、開発者と企業に新たな道を開くモデルとして際立っている。
参考資料
https://arxiv.org/pdf/2402.03300
https://arxiv.org/abs/2502.07864
https://arxiv.org/pdf/2310.18313
https://milvus.io/docs/build_RAG_with_milvus_and_deepseek.md
読み続けて

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.