




高度なRAGテクニック:より正確な回答のためのテキストとビジュアルの橋渡し
大規模言語モデル(LLMs)は、様々なタイプのコンテンツ、テキストやビジュアルを理解し、生成する際に卓越した能力を発揮し、様々な業界で広く採用されている。その多機能性にもかかわらず、LLMは、限られたドメイン知識や古いデータのために、しばしば不正確な情報や捏造された情報-幻覚-を生成します。
検索補強型生成(RAG)は、LLMの生成能力と、外部ソースから関連情報を取得する検索システムを組み合わせることによって、これらの課題に対処する技術である。LLMの応答を実世界の最新データに基づかせることで、RAGは回答の正確さと文脈上の関連性を向上させ、システム全体の効率を高める。この生成と検索の組み合わせは、イノベーションを促進し、データ処理を変革し、実世界のアプリケーションにおいてLLMの信頼性を高めます。
最近Zillizが主催したUnstructured Data Meetupで、以前LlamaIndexのタイプスクリプトとパートナーシップの責任者であったYi Dingは、RAGへの新しいアプローチ:Small to Slideに関する洞察を共有した。このメソッドは、プレゼンテーションや画像を含むドキュメントのような視覚的なデータを扱うときに、マルチモーダルLLMのパフォーマンスを向上させる。このブログでは、RAGがどのように機能するのか、RAGの課題、Small to Slide RAGのような高度なRAGテクニックを探ります。
RAGを理解するRAGは、LLMのパワーと、ベクトルデータベースによって提供される知識ベースから特定の情報を検索する能力を組み合わせたものである。ユーザーが質問をすると、RAGシステムは関連する情報をデータベースから検索し、その情報を使ってより正確な回答を生成する。RAGプロセスがどのように機能するか見てみよう。
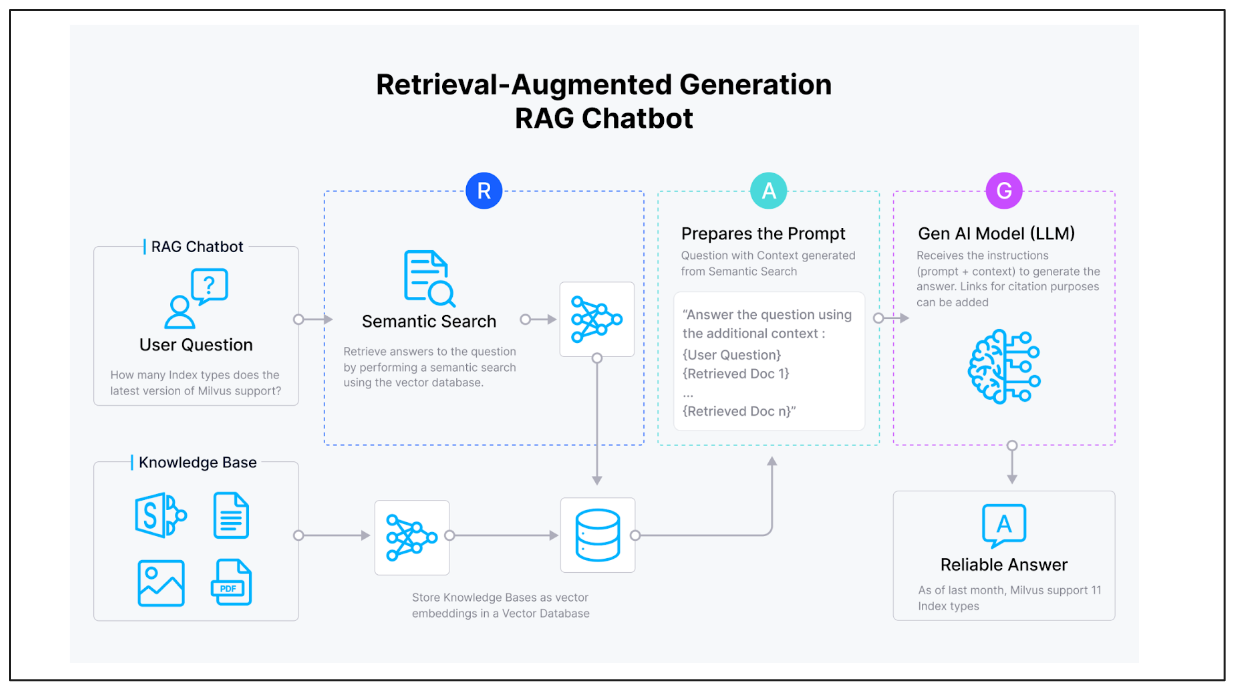
*図:RAGの仕組み
RAGシステムは、埋め込みモデル、ベクトルデータベース、LLMの3つから構成される。
ユーザが質問をすると、システムは同じ埋め込みモデルを用いてクエリをベクトルに変換する。
そして、ベクトルデータベースは類似検索を行い、最も関連性の高い情報を検索する。この検索された情報は、元の質問と組み合わされ、「文脈のある質問」となり、LLMに送られる。
LLMは、より正確で文脈に関連した回答を生成するために、この強化された入力を処理します。
この方法は、専門的な知識や動的で頻繁に更新される情報を扱うのに特に有効で、AIシステムが正確で信頼できる回答を提供できるようにする。
例えば、大規模なeコマース・プラットフォームは、商品推薦システムを動かすためにこのアプローチを使うことができる。システムは何百万もの商品説明、カスタマーレビュー、利用データを処理し、それらをベクトルとして保存することができる。ユーザーが商品を検索すると、システムはキーワードだけでなく、クエリの意味的な意味も考慮して、最も関連性の高い商品を素早く検索する。
RAGの課題と高度なRAG技術
RAGは強力な機能を提供する一方で、特にデータが大きく複雑になるにつれて、その有効性に影響を与える可能性のある課題にも直面している。
スピード:*** 大きなデータベースの検索には時間がかかる。これは、GPUやその他のハイパフォーマンスシステムに最適化するなど、ハードウェアアクセラレーションコンピューティングを活用することで軽減できる。
正確性:*** 最も関連性の高い情報を確実に検索することは困難です。開発者は、ニーズに応じてパフォーマンスとデータの精度をバランスさせる方法を必要としています。
マルチモーダルデータ:基本的なRAGは、画像や図表のような非テキストデータに苦労します。このようなケースでは、異なるタイプのベクターデータを扱うことが重要になる。
以下のセクションでは、これらの課題を解決し、RAGシステムのスピード、精度、汎用性を向上させる、いくつかの高度なRAGテクニック(*Small to Big RAG、Small to Slide RAG、ColPali)を紹介します。
小さなRAGから大きなRAGへ
Small to Big RAGは、RAGシステムの精度を高める手法である。核となる考え方は、LLMが意味のある完全な応答を生成できるように、文書をより小さく、意図に焦点を当てたチャンクに分割して正確な検索を行うが、完全に一致する部分のみを返すのではなく、より大きなコンテキストセクションを取得することである。なぜなら、より小さなチャンクは、特定の詳細に焦点を当てることで検索精度を向上させる一方で、重要なコンテキストを見逃す可能性があり、不完全または不正確な回答につながるからである。
一つの例を見てみましょう。
次のクエリを考えてみましょう:チュリロさんはどこで働いていますか?
その結果、システムは"Churilo"に言及した文章を検索しますが、重要な情報を提供することができません:クリスは現在Zillizのマーケティング担当副社長です。
Small to Big RAGは、彼女の役割が言及されている段落全体を検索することによってこの制限に対処し、LLMに正しく完全な回答を提供するために必要な完全な文脈を与えます。
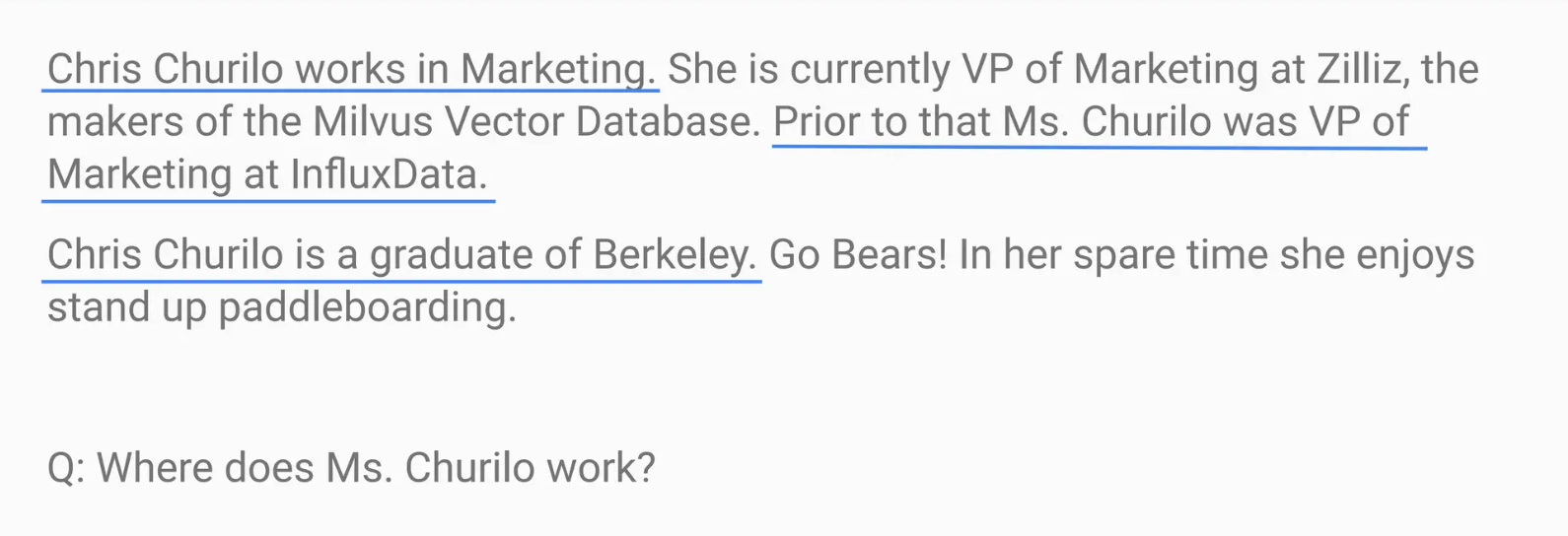
図:従来のRAGにおける誤った検索
Small to Big RAGは、複雑なテキストデータや多層的なテキストデータを扱うのに特に効果的である。例えば、テクニカルサポートシステムでは、関連するキーワードで単一の文章を検索すると、理解するために重要な周辺の詳細が省かれてしまう可能性がある。その代わりに、Small to Big RAGは、クエリに関連するすべてのセクションを検索する。例えば、ユーザーが「パスワードをリセットするにはどうすればいいですか」と質問した場合、システムは直接的な答えが書かれた段落を取得し、セキュリティに関する推奨事項などの追加のコンテキストを含めることで、応答をより包括的で有用なものにすることができます。
より小さなエンベッディングの精度と、より広範な検索のコンテキストの深さを組み合わせることで、Small to Big RAGは正確さと完全性のバランスを保証する。このアプローチにより、AIシステムは、正確なだけでなく、コンテキストに富んだ回答を提供することができ、実世界のアプリケーションにおける信頼性を向上させることができる。
スモール・トゥ・スライドRAG
Small to Big RAGはテキストベースのデータを扱うことに優れているが、スライド、チャート、グラフなどのビジュアルに埋め込まれた情報を捉えることに苦戦している。Small to Slide RAGは、この問題を解決するために改良されたRAGメソッドであり、スライドのような視覚的要素からテキストを埋め込み、スライド画像全体を取得する。この検索結果は、テキストと画像の両方を分析できるマルチモーダルLLMに提供され、処理される。
その仕組みはこうだ:
テキスト埋め込み:**システムはスライドからテキストを抽出し、埋め込む。
ビジュアル検索:***テキストのみを検索する代わりに、関連情報を含むスライド画像全体を検索します。
マルチモーダル処理:***検索されたスライド画像は、視覚とテキストを同時に処理できるマルチモーダルLLM(例えば、視覚機能を持つGPT-4)に送られる。
この方法は、重要な情報が視覚を通して伝達される複雑な文書を扱うのに特に有効である。例えば、四半期ごとの財務報告書では、重要な洞察はグラフやチャートの中に見出されることが多く、従来のテキストベースのRAGシステムでは見逃してしまう可能性があります。スライド画像全体を検索して分析することにより、Small to Slide RAGは、重要な細部が見落とされないようにし、より正確で包括的な回答を提供します。
Small to Slide RAGのパワーを示すために、Yi Ding氏はNvidiaのスライドデッキを使用した実用的な例のデモを行った。デモはこちらからご覧いただけます](https://youtu.be/i3Ou3OUo3T4?list=PLPg7_faNDlT7SC3HxWShxKT-t-u7uKr--&t=2080)。
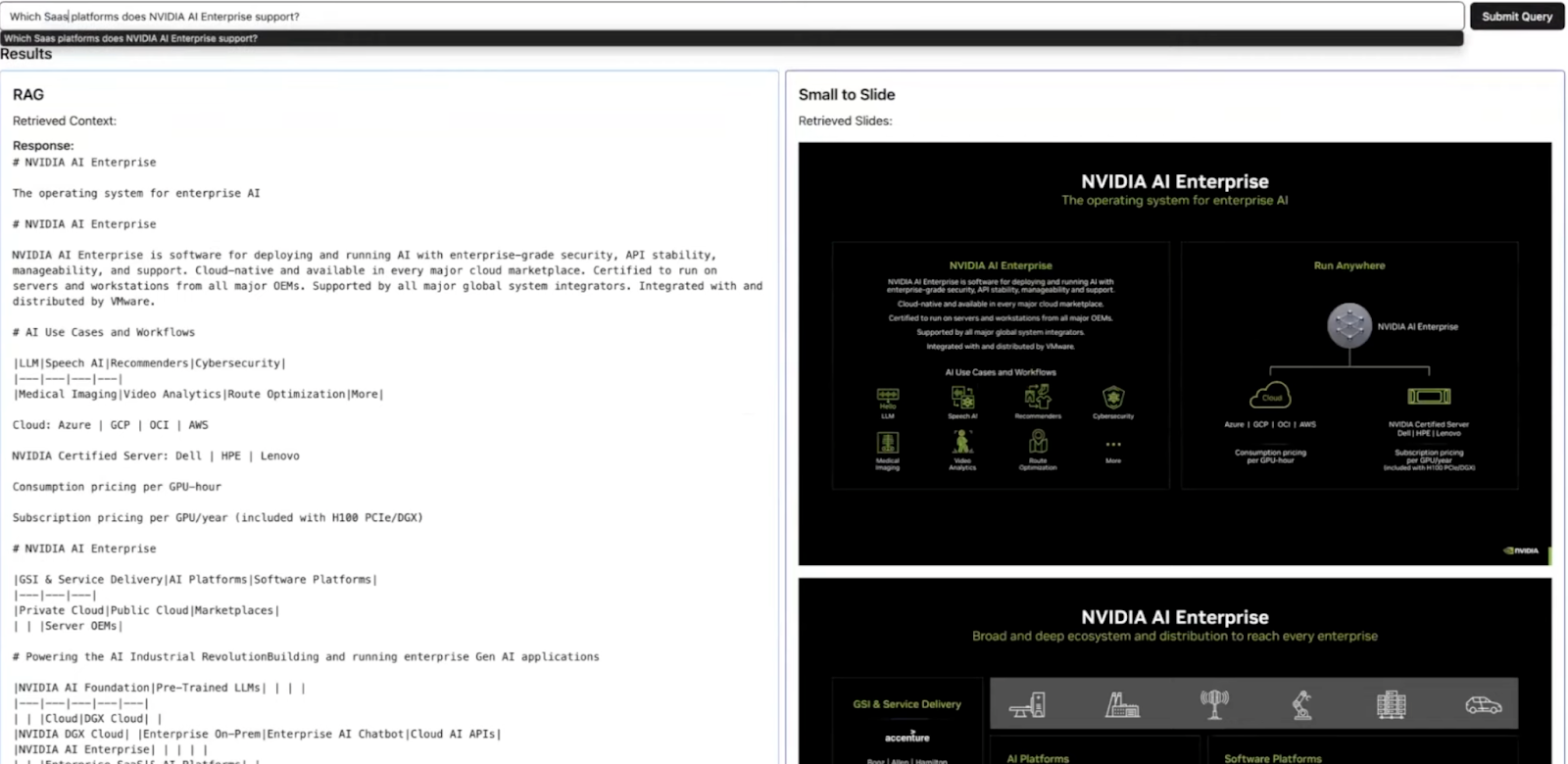
図:従来のRAGとSmall to Slide RAGで取得されたコンテキストの比較_。
このデモでは、Yi Ding氏が同じ質問に答える際に、従来のRAGシステムとSmall to Slide RAGで取得したコンテキストを比較した:**NVIDIA AI EnterpriseはどのSaaSプラットフォームをサポートしていますか?
従来のRAG:***従来のテキストベースのRAGシステムは、完全な回答を提供するのに苦労しました。スライドから抽出したテキストだけに頼っていたため、図表に埋め込まれた重要な情報が欠落していたのです。この制限により、不完全で情報量の少ない回答となっていました。
Small to Slide RAG:**対照的に、Small to Slide RAGははるかに優れた結果をもたらした。このシステムは、関連情報を含む実際のスライド画像を検索し、それらをマルチモーダルLLM(例えば、視覚機能を備えたGPT-4)に入力した。これにより、モデルはテキストと視覚的要素の両方を解釈し、より包括的で正確な回答を生成することができた。
この例は、Small to Slide RAGのユニークな強みである、重要な情報がテキストとビジュアルにまたがる複雑な文書を処理する能力を示しており、視覚的に豊かなコンテンツを処理するための貴重なツールとなっている。
これらのRAGメソッドがスムーズに機能するためには、複雑なクエリーと検索操作を管理するインフラが必要です。
##コルパリ限界への挑戦
Yi氏は講演の最後に、ColPaliと呼ばれる新しい技術を紹介した。これは、RAG(Retrieval-Augmented Generation)の限界を押し広げる新しい文書検索モデルである。ColPaliは、(スライドやPDFのような)視覚データを含む文書をテキストに変換する従来の手法とは異なり、文書の視覚的特徴**を直接扱うことで、エラーが発生しやすいテキスト抽出のステップなしにインデックスを作成し、情報を検索することを可能にする。
ColPali の仕組み
ColPaliはまだ初期段階ですが、ビジュアルデータに注目することで、通常の文書検索の方法を変えます:
ドキュメントは画像として扱われ、テキスト変換は完全にバイパスされます。
ビジュアルNグラム](https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models)に似た複数の埋め込みが画像ごとに生成され、きめ細かな視覚的特徴を捉えます。
検索は、視覚的埋め込みをクエリと比較することによって行われ、文書の最も関連性の高い領域を特定する。
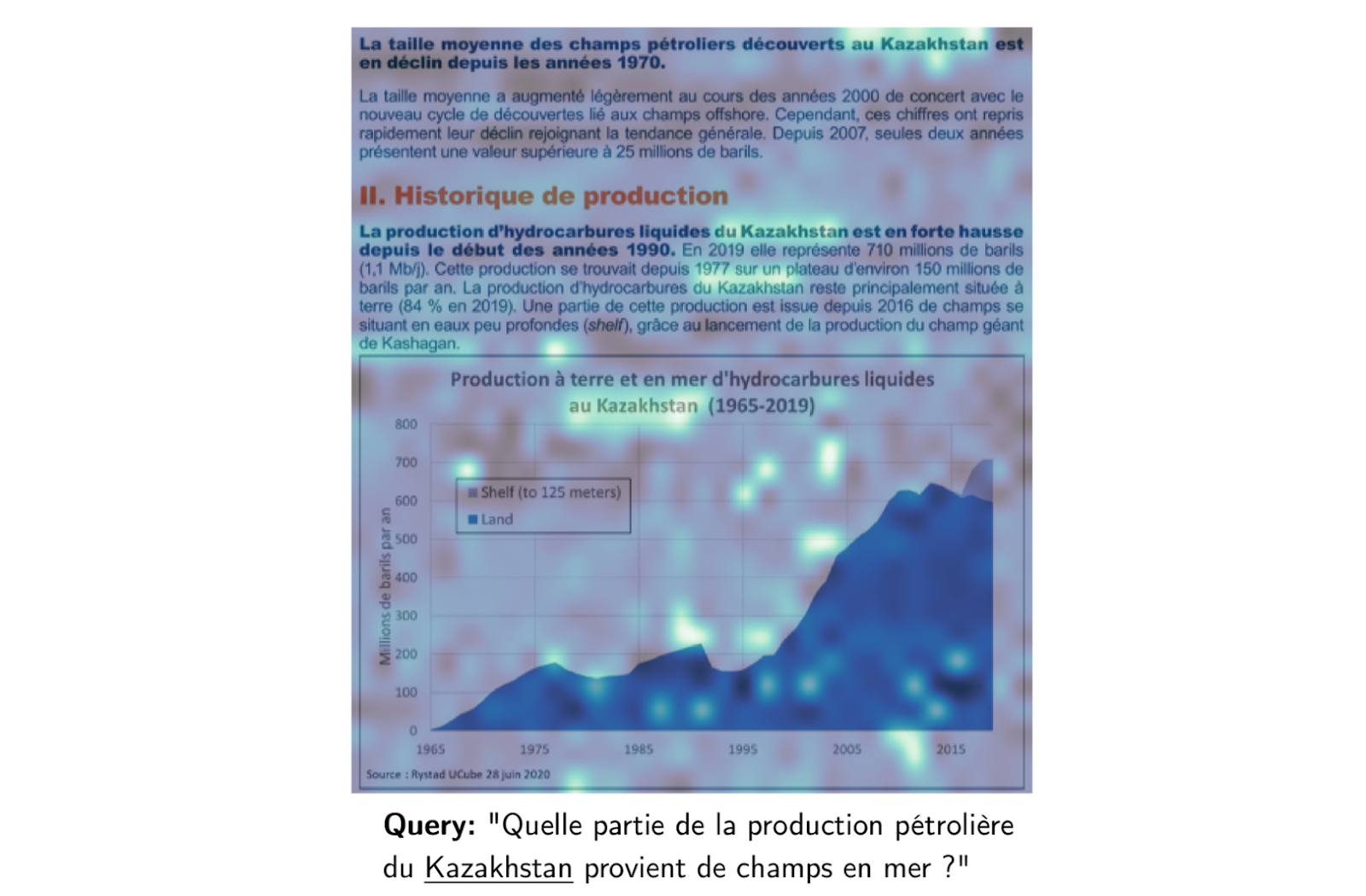
図:カザフスタンの石油生産に関するフランスの文書。
上の画像の例を見てみよう。カザフスタンの石油生産に関するフランスの文書である。沖合での石油生産について質問されると、ColPaliはクエリに最も関連する図表など、文書の特定の領域をハイライトします。これにより、テキストとビジュアルの両方の要素が考慮され、コンテンツの包括的な理解が可能になります。
ColPaliがエキサイティングな理由
ColPaliは、従来のRAGシステムと比較して、いくつかの重要な利点を提供します:
画像を直接扱うことで、複雑な文書(PDFなど)をテキストに変換する際に生じる不正確さを避けることができます。
レイアウト、ダイアグラム、書式設定など、テキストベースの手法では失われがちな視覚情報をキャプチャします。
ColPaliはビジュアルデータの検索とサーチを可能にし、テクニカルデザインや法的文書などの分野での可能性を広げます。
ColPaliの実用的なアプリケーションとしては、建築設計のレビューが考えられます。設計図や技術図面を直接分析するAIシステムを想像してみてほしい。特定の設計要素について問い合わせがあった場合、システムは図面の関連部分を強調表示し、テキスト注釈と視覚的特徴の両方を組み込むことができます。
ColPaliの課題と限界
ColPali は有望ではありますが、まだ初期段階であり、いくつかの課題があります:
画像ごとに複数の埋め込みを生成し比較することは計算量が多く、実用化にはGPUアクセラレーションが不可欠です。
より確立されたRAG技術と比較すると、ColPaliを実装するためのツールやリソースは少ない。
言語とトレーニングに特化したモデル:** ColPaliモデルは現在、特定のトレーニングデータセットに依存しているため、異なるドメイン間での一般化が制限される可能性があります。
各 RAG テクニックの長所と短所
上記で説明した各手法には、それぞれ明確な利点と限界がある。
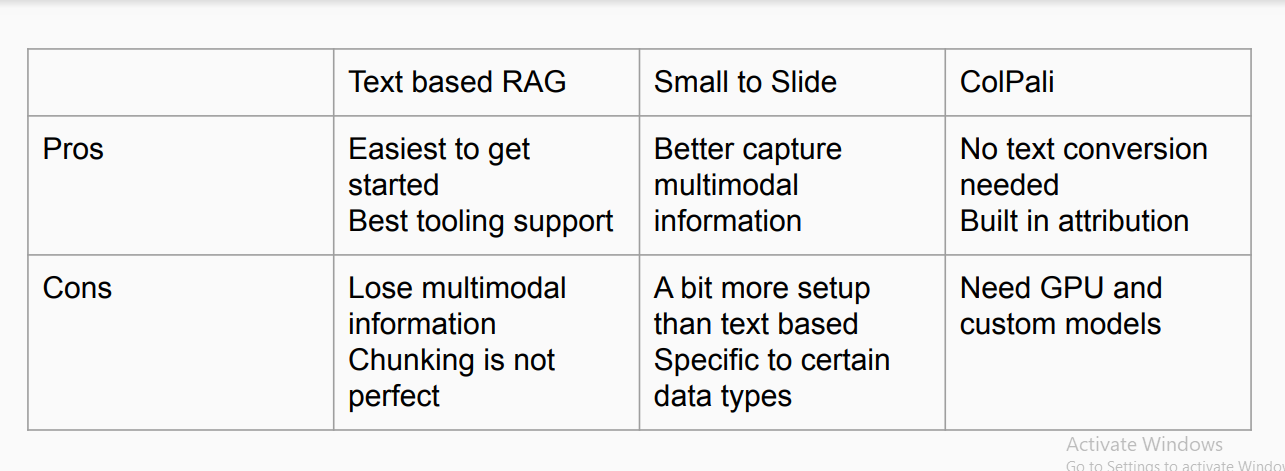
図:異なるRAG技術の比較
テキストベースのRAGは、実装が最も簡単で、広範なツールサポートの恩恵を受けている。しかし、マルチモーダルな情報の維持に苦労し、チャンキングを完璧に扱えるとは限らない。一方、Small to Slideはマルチモーダルデータのキャプチャを改善するが、より複雑なセットアップが要求され、特定のデータタイプで最もよく機能する。最後に、ColPaliは、テキスト変換の必要性を回避し、ビルトインのアトリビューションを統合することで、プロセスを簡素化しますが、GPUとカスタムモデルを必要とするため、プロジェクトによってはアクセシビリティが制限される可能性があります。
高度なRAGの実装:実践的な考察
これらの高度なRAGテクニックを自分のプロジェクトに実装することを検討している場合、以下の点に留意する必要があります。
データの評価
扱っているデータの種類を見てください。図表、画像、複雑なレイアウトの文書が多い場合、Small to Slide RAGのようなアプローチが特に有益かもしれない。例えば、財務報告書を分析するシステムを構築している場合、財務報告書にはテキスト、表、チャートが混在していることが多く、Small to Slide RAGはテキストのみのアプローチよりも包括的な洞察を提供できる可能性がある。
計算リソース
Small to Slide RAG や ColPali のような手法は、従来の RAG よりも計算量が多くなる可能性があります。特に大きなデータセットを扱う場合は、必要なリソースを確保してください。
モデルの選択
これらの高度なテクニックは、しばしば特定のタイプのモデルを必要とする。Small to Slide RAGの場合、テキストと画像を処理できるマルチモーダルLLMが必要になる。ニーズに合ったモデルを選択し、それを実行するためのリソースがあることを確認する。
ベクターデータベースの機能
ニーズに合わせたRAGシステムを導入するには、適切なベクターデータベースを選択することが重要です。例えば、Small to Big RAGを実装する場合、より小さなチャンクから生成された埋め込みを使用して、より大きなテキストのチャンクを効率的に検索できるベクターデータベースが必要になります。億単位のデータセットのような大量のベクトルデータを扱うアプリケーションでは、スケーラビリティが鍵となります。Milvus**](https://zilliz.com/what-is-milvus)やそのマネージドサービスであるZilliz Cloudのようなソリューションは、このようなシナリオのために設計されており、非常にスケーラブルで効率的なベクトル検索を提供します。
評価指標
検索された情報の関連性、生成された応答の正確さ、検索と生成のスピードなど、RAGシステムのパフォーマンスを評価するための明確な指標を開発する。
反復開発
RAGは急速に進化しています。異なるアプローチを簡単にテストし比較できるように、反復的な開発プロセスを計画してください。基本的なRAGの実装から始め、Small to Big RAGやSmall to Slide RAGのようなより高度なテクニックを徐々に導入する。パフォーマンスとユーザーからのフィードバックを継続的に評価し、開発プロセスの指針とする。
結論
RAGのテクニックは進化し続けており、テキストベースのRAG、Small to Slide RAG、ColPaliのような様々なニーズに対応する異なるアプローチを提供している。テキストベースのRAGは一般的なアプリケーションのための堅実な出発点を提供するが、より専門的なケース、特にビジュアルデータを扱うケースでは、Small to Slide RAGやColPaliのような高度な手法の恩恵を受けることができる。
適切な手法の選択は、データと手持ちのリソースに依存する。各アプローチは、AIシステムの効率と精度を向上させる方法を提供し、複雑さ、スピード、コストのバランスを改善します。RAGを活用し、ユーザーに対して適切な情報を適切なタイミングで適切なフォーマットで提供するシステムを構築することができます。
その他のリソース
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
マルチモーダルRAG:よりスマートなAIのためのテキストを超えた拡張 ](https://zilliz.com/blog/multimodal-rag-expanding-beyond-text-for-smarter-ai)
ColPali: 視覚言語モデルによる効率的な文書検索](https://arxiv.org/html/2407.01449v2)
Milvusとは|Milvusドキュメント](https://milvus.io/docs/overview.md)
vLLMとMilvusによるマルチモーダルRAGシステムの展開](https://zilliz.com/blog/deploy-multimodal-rag-using-vllm-and-milvus)
Trulensを用いたマルチモーダルRAGの評価](https://zilliz.com/blog/evaluating-multimodal-rags-in-practice-trulens)
GenAIエコシステムの展望:LLMとベクトルデータベースを超えて ](https://zilliz.com/blog/landscape-of-gen-ai-ecosystem-beyond-llms-and-vector-databases)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
MilvusでAIアプリを作る:チュートリアル&ノートブック](https://zilliz.com/learn/milvus-notebooks)
 Fendy Feng
Fendy FengFendy Feng is the Technical Marketing Writer at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 Simon Mwaniki
Simon Mwaniki
読み続けて

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.