




FAVAによるきめ細かな幻覚検出と補正でAIの信頼性を高める
報告書の下書きをAIツールに頼ったとしよう。あなたはAIにアポロ計画の詳細を尋ね、AIは自信満々にニール・アームストロングが1965年に月面に着陸したと答えた。あなたはそれを検証することなく、報告書にその誤りを記載した。これは幻覚の一例で、AIはもっともらしいが正しくない、あるいは検証不可能な情報を生成する。
特に医療、教育、ジャーナリズムのような分野では、些細な不正確さが重大な結果につながりかねない。誤りは単純な事実誤認から完全に捏造された実体や出来事まで幅広く、事実か否かという基本的な分類以上のものを必要とする。この課題に取り組むため、幻覚を検出・修正するための検索機能付き言語モデルFAVAが論文Fine-Grained Hallucination Detection and Editing for Language Modelsで紹介された。このアプローチには、誤りを分類するための細かい分類法と、モデルの性能を評価するためのFAVABENCHと呼ばれるベンチマークデータセットも含まれている。これらのツールを組み合わせることで、利害関係の強い文脈におけるAIの信頼性を向上させることができる。
このブログでは、幻覚の性質、幻覚を分類するためのフレームワークを提供する分類法、評価のために設計されたFAVABENCHデータセット、そしてFAVAがどのようにエラーを検出し修正するかについて探求する。
既存の手法がAIのエラー検出に苦労する理由
AI出力の誤りを特定するシステムのほとんどは、そのタスクを単純な判断として扱い、発言を事実かそうでないかのどちらかに分類する。この二元的なアプローチは単純ではあるが、AIが生成するエラーの複雑さには対処できないことが多い。例えば、間違った日付を特定することは単純に思えるかもしれないが、捏造された実体を認識したり、微妙な関係性の誤りを修正したりするには、内容と文脈をより深く理解する必要がある。
文全体を間違っているとラベル付けするだけでなく、より詳細なアプローチが必要である。メッシはバルセロナのサッカー選手である。バイナリーシステムは、その理由を説明することなく、この文に偽のフラグを立てるかもしれない。一方、きめ細かな検出は、特定の問題、すなわち、誤った場所(バルセロナはマイアミであるべき)と、存在しない映画についての捏造された主張をピンポイントで検出する。
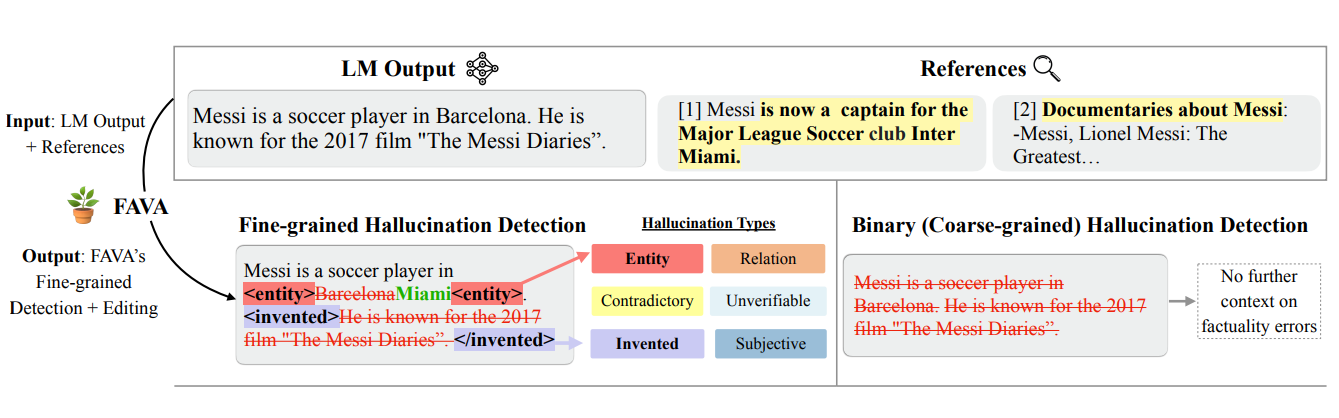
図:2進法と細粒度の幻覚検出の比較で、細粒度の方法がどのようにステートメント内の特定のタイプの誤りを識別するかを示す_。
不正確な詳細や捏造された主張など、誤りの具体的な性質を特定することで、細粒度検出は明瞭さを提供し、的を絞った修正を可能にする。このアプローチは、バイナリ分類の限界を克服し、AIエラーに効果的に対処するための、よりニュアンスに富んだ実行可能なソリューションを提供します。
幻覚の分類を理解する
AIシステムによって発生するエラーはすべて同じではない。日付を間違えるといった単純な事実誤認もあれば、まったく新しい実体や検証不可能な主張を捏造するものもある。この多様性に対処するため、きめ細かい分類法によって幻覚を6つの異なるタイプに分類している。この構造により、誤りの性質が明確になり、的確な修正が可能になる。
幻覚を分類するプロセスは、入手可能な証拠と照らし合わせて情報を分析することから始まる。下の決定木は、異なるタイプの幻覚がどのように段階的に識別されるかを示している。例えば、誤りは矛盾する事実、検証不可能な記述、あるいは完全に創作された実体から生じる可能性がある。この構造化されたアプローチに従うことで、分類法は幻覚を評価し、対処する体系的な方法を提供する。
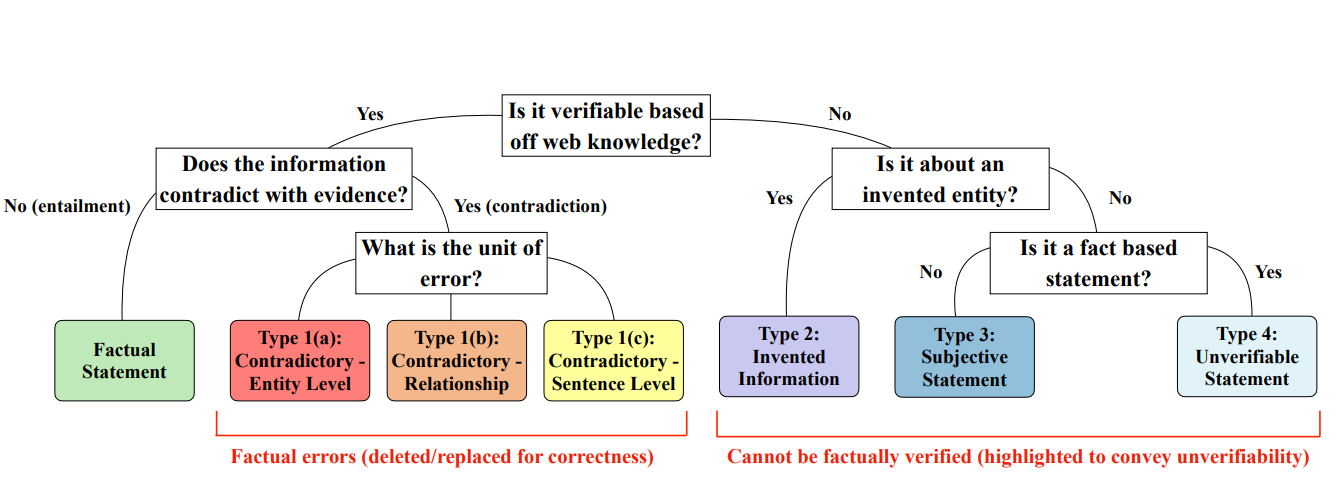
図:図:分類法と、エラーがどのように6つのタイプに分類されるかを説明するデシジョンツリー。
幻覚の6つの分類は以下の通りである:
1.エンティティエラー*名前、日付、場所などの詳細が間違っている。例えば、ニール・アームストロングが月面に降り立ったのは1969年ではなく1965年だと主張するのは、実体の誤りである。このような間違いは、文書化された情報源を用いれば簡単に発見し、修正できることが多い。
2.関係エラー*関係エラーは、2つのエンティティ間の関係が誤って表現されている場合に発生します。例えば、リオネル・メッシがPSGに入団したのではなく、PSGに獲得されたと記述すると、関係の意味が変わってしまう。このようなエラーを修正するには、関係するエンティティの文脈を理解する必要があります。
3.センテンス・エラー*事実と矛盾する文章を指します。例えば、次のような文章である: メッシはアルゼンチンサッカーチームのキャプテンを務めたことはない。センテンスレベルの誤りは、特定し訂正するために、より多くの文脈を必要とすることが多い。
4.**このカテゴリーの誤りは、存在しない実体や概念を捏造したものである。例えば、「メッシは有名な飛行機キックで知られている」と主張することは、まったく架空の行為を作り出すことになります。このような誤りは、もっともらしく聞こえるかもしれませんが、現実には何の根拠もないため、発見が難しくなります。
5.主観的な記述*主観的な記述とは、意見が事実の主張として組み立てられている場合に起こります。例えば、「メッシは世界最高のサッカー選手だ」というのは主観的であり、普遍的に検証することはできません。カジュアルな文脈では意見は有効ですが、それを事実として提示することは誤解を招きかねません。
6.検証不可能な主張これらの主張には、その妥当性を確認または否定する十分な証拠がない記述が含まれます。例えば、「メッシは自由な時間に家族のために歌うことを楽しんでいる」というような主張は、具体的な証拠や直接的な裏付けがなければ検証不可能である。
各カテゴリーは、幻覚の現れ方が多様であることを浮き彫りにし、エラーを発見し修正するための画一的なアプローチでは不十分であることを示している。エラーをこれらのカテゴリーに分類することで、分類法は幻覚に正確に対処するために必要な明確さを提供する。
FAVABENCHでAIのパフォーマンスを評価する
分類法は幻覚を理解するための構造化された方法を提供しますが、AIモデルがこれらのエラーにどの程度対処できるかを評価するには、信頼できるテストフレームワークが必要です。ベンチマーク・データセットであるFAVABENCHは、AIの出力を分析し、特定のタイプのエラーを検出して修正する能力を評価するために作成されました。
FAVABENCHには、ChatGPTやLlama2-Chatのような大規模言語モデルの注釈付き応答が含まれ、様々なタスクをカバーしている。各回答はスパンレベルで分析され、幻覚の6つのカテゴリーに基づいてテキストの特定の部分にフラグが付けられます。
このデータセットは、モデルが生成するエラーのタイプの傾向も明らかにしている。下のグラフは、さまざまなモデルやデータセットで、幻覚がどのように分布しているかを示しています。エンティティのエラーはすべてのモデルで共通ですが、捏造された情報や検証不可能な主張のようなエラーはより多様性を示しています。
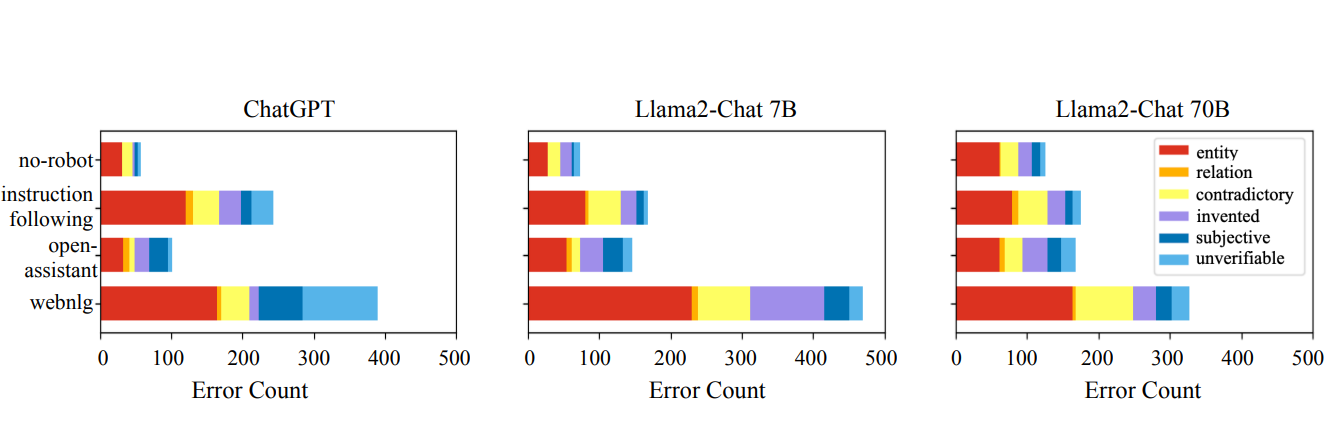
図:AIモデルとデータセット間の幻覚タイプの分布を示すグラフ_。
FAVABENCHが捉えたエラーの種類をさらに説明するために、下の表は各カテゴリーの例を、異なるモデルにおける有病率とともに示しています。これらの例は、頻繁に発生するエンティティのエラーなど、繰り返し発生する問題や、あまり一般的ではないが重大な問題(捏造された情報など)を浮き彫りにしています。

図:幻覚のタイプの例と、モデル間での有病率_。
FAVABENCHは、詳細な注釈とモデル性能の明確な内訳を提供することで、AIシステムが幻覚をどのように扱うかのパターンを特定するのに役立ちます。FAVABENCHは、分類法の理論的枠組みを実用的な評価と結びつけることで、AIモデルの改善すべき領域をピンポイントで特定することを可能にします。
FAVAはどのように幻覚を検出し修正するか
AIの出力における幻覚を検出し修正するには、誤りを特定することと、信頼できる外部証拠を用いて主張を検証することの両方が必要である。FAVA (Fact Verification and Augmentation)は、検索と編集を組み合わせた2段階のプロセスを採用し、幅広い種類の幻覚を効果的に処理する。このモデルは、合成された誤りの多様なデータセットに対するトレーニングが、その能力において重要な役割を果たしている。
合成データによるFAVAの訓練
FAVAが幻覚を識別し修正するための準備をするために、分類法で定義された6種類の誤りに合わせた合成データセットが作成された。このプロセスは、ウィキペディアのような信頼できる文書から入手した、事実に基づいて正確な文章から始まった。次に、これらの文章を体系的に修正してエラーを導入し、データセットが現実世界の幻覚の多様性と複雑性を反映するようにした。Chatgptのようなインストラクションチューニングされたモデルが、次のようなエラーを文章に挿入するために使われた:
日付、名前、場所のような事実の詳細を置き換えて、実体エラーを生成する。
完全に捏造された情報を追加して、発明された主張をシミュレートする。
曖昧な、あるいは裏付けのない主張を表現するために、検証不可能な記述を加える。
修正された各パッセージは、修正されていないオリジナル・バージョンと対にされ、FAVAは誤りの検出方法と、文脈と証拠に基づく修正方法の両方を学習することができた。データセット生成プロセスの体系的な性質により、FAVAは実世界での応用において、見たことのない誤りに対してうまく一般化できることが保証された。
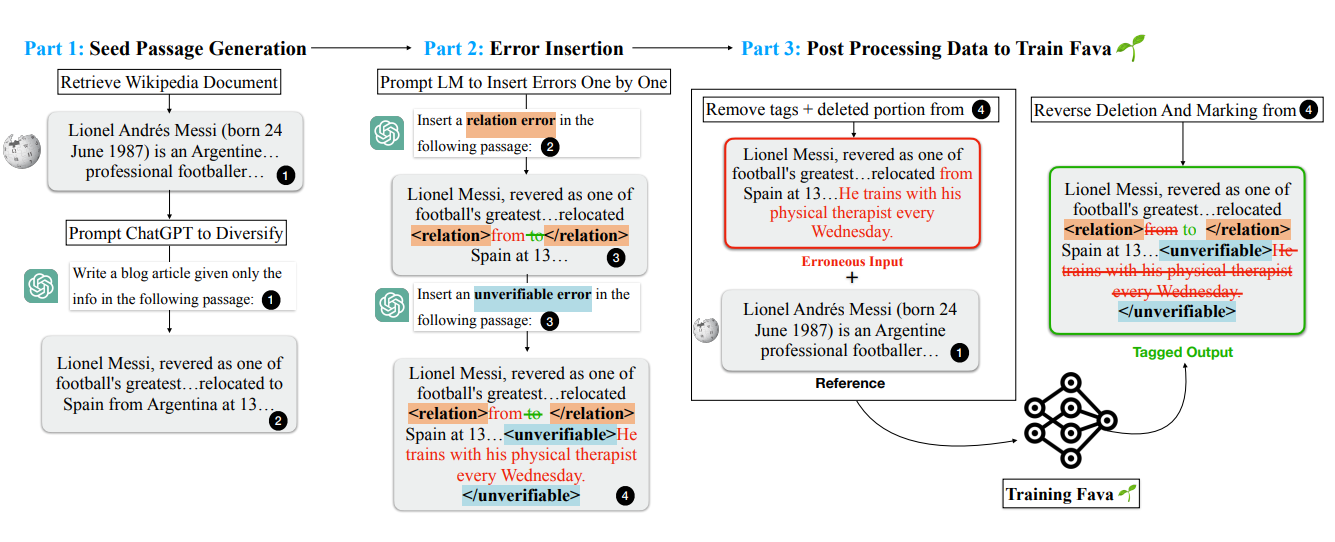
図: 図:合成データ生成プロセスの図解。学習目的のために、様々なタイプの幻覚を含むように正確な内容がどのように修正されたかを示す_。
この多様な訓練用データセットにより、FAVAは幻覚のパターンを認識できるようになり、エラーを正確に分類して解決する能力が備わった。
証拠の検索とエラーの修正
いったん訓練されると、FAVAは検索と編集という2つの重要な段階で動作する。
1.証拠の検索文章が提示されると、FAVAはまずウィキペディアなどの外部ソースから関連情報を検索する。このステップにより、モデルは入力テキストを検証するための事実データへのアクセスを確保する。例えば、入力がMessi was born in Miami*と記述されている場合、検索コンポーネントはメッシの出生地に関する証拠を提供する文書を検索する。これらの文書は、プロセスの次のステップの基礎となる。
2.**検索された証拠を用いて、FAVAは入力テキスト中の特定の幻覚を特定する。FAVAは、これらの誤りを分類法に基づいて分類し、特に、実体の誤り、捏造された主張、検証不可能な記述などにフラグを立てる。次に編集コンポーネントが、検索された証拠に基づいて修正を提案する。例えば、先の例では、FAVAはMiamiが正しくないことを検出し、検証済みの事実であるRosario, Argentina.に置き換える。
この構造化されたプロセスにより、FAVAは誤りの特定と訂正の両方のレベルで誤りに対処することができ、出力が正確であるだけでなく、検証可能な情報に基づいたものであることが保証される。
FAVAのパフォーマンスの評価
FAVAや他のモデルがどの程度効果的に幻覚を検出し修正するかを測定するために、精度、再現、F1スコアのような主要な測定基準が使用される。これらの指標は、モデルの信頼性、徹底性、全体的なパフォーマンスについての洞察を提供する。
精度
精度は、特定のエラー・タイプに対してモデルが行った予測のうち、正しいものの割合を測定する。これは、幻覚を識別する際のモデルの信頼性を評価するもので、誤検出を避けることに重点を置く。精度の式Pₜでは、分子はすべての文にわたるエラー・タイプtに対する正しい予測の合計を表し、分母はモデルがそのエラー・タイプに対して行った予測の合計数です。精度の値が高いほど、モデルが特定のエラーを識別するときに間違った予測をすることが少ないことを示します。
**式 Pₜ = Σₜ [e_1D62∈ₜ] ÷ Σₜ [e_1D62∈ₜ] Σₜ [e_1D62∈ₜ = TRUE
リコール
Recallは、モデルが識別に成功した特定のエラー・タイプの真のインスタンスの割合を反映する。この指標は、各エラータイプのすべての関連するケースを捕捉するモデルの徹底性を強調する。リコール(Rₜ)の式では、分子はエラー・タイプtの正しく識別されたインスタンスの合計を表し、分母はすべてのセンテンスにわたるそのエラー・タイプの真のインスタンスの合計数です。想起値が高いほど、モデルはより多くの実際のエラーを捕捉し、関連するインスタンスを見逃す可能性を最小化することを意味する。
式 Rₜ = Σᵢ∈ᴸ [eᵢ = eₜ,ᵢ] ÷ Σᵢ∈ᴸ [eᵢ∈ᴸ = TRUE] Σᵢ = TRUE
F1 スコア
F1スコアは精度と想起のバランスをとり、精度と完全性の両方を反映する調和平均を提供する。このスコアは、精度と再現率がトレードオフの関係にある場合に特に有用です。F1 計算式は、P_t と R_t を使用して特定のエラータイプの精度と想起を表し、すべてのエラータイプのスコアを平均します。F1スコアが高いほど、モデルがエラーを正しく識別し、かつほとんどのエラーを確実に検出できることを示します。
**計算式 F1 = (1 ÷ |E|) × σₜ [2 × P_209C × R_209C ÷ (P_209C + R_209C)].
証拠検索ときめ細かな編集を組み合わせることで、FAVAはAIが生成するコンテンツの事実精度を向上させるための強固なフレームワークを提供する。外部ソースに依存することで、検出と修正が信頼できる証拠に基づくことを保証する一方、多様なエラータイプに関するトレーニングにより、幅広い幻覚に対処することができる。FAVAの性能は、様々な幻覚タイプにわたるきめ細かな検出の尺度としてF1スコアを用い、検索を補強したChatGPTやGPT-4を含むベースラインシステムと比較して評価された。以下の表は、エンティティエラー、捏造情報、矛盾文のようなカテゴリーにわたるエラーの識別において、FAVAが他のシステムよりも優れていることを強調している。
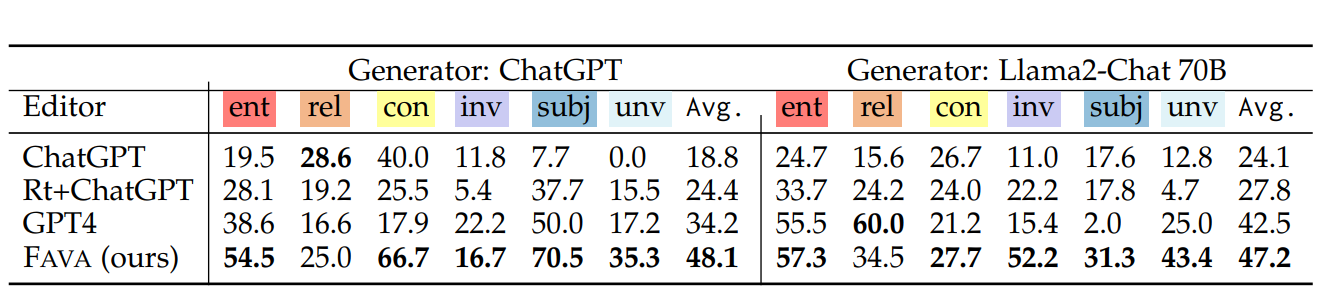
図:きめ細かい検出の結果(指標:F1)_。
F1スコアに基づく結果は、検索と編集を組み合わせたFAVAのアプローチが、様々な幻覚のタイプにおいて、FAVAを大きく上回っていることを示している。例えば、FAVAはChatGPT生成出力を編集した場合、48.1の平均F1スコアを達成し、Llama2-Chat 70B出力に対しては47.2を達成し、両ケースにおいて全てのベースラインモデルを凌駕した。外部証拠への依存と多様なエラータイプに対するトレーニングにより、エラーを正確に識別できるようになり、AI出力の信頼性を向上させる上で明確な優位性を与えています。
FAVAの応用と意義
幻覚を識別し修正する能力により、FAVAはAIの出力が高水準の精度を満たさなければならないシナリオにおいて特に価値がある。エラーを分類し、信頼できる証拠に基づいて修正を行うそのアプローチは、いくつかの領域にわたって実用的なツールとして位置づけられる。
**ヘルスケア
ヘルスケアでは、精度が最も重要です。AIシステムは、患者のケアサマリーの起草、治療法の提案、研究論文の分析にますます使用されるようになっている。これらの出力におけるエラーは、たとえ些細なものであっても、重大な結果をもたらす可能性があります。FAVAは主張を検証し、不正確な情報を修正することで、AIが生成する医療情報が確立された知識と一致することを保証し、これらのツールをより安全で効果的なものにします。
**教育
学生や教育者は、説明、要約、研究支援にAIを利用している。教育コンテンツにおける幻覚は、誤った情報をもたらし、誤解を招く可能性がある。FAVAは特定のタイプの誤りを特定することに重点を置いており、教材の質を向上させ、学習者が正確で検証可能な情報にアクセスできるようにします。
**ジャーナリズムとコンテンツ作成
ジャーナリストやコンテンツ制作者にとって、AIが生成した原稿の事実誤認は信頼性を損ないかねません。要約、レポート、記事のいずれを作成する場合でも、出力物は検証可能な事実に従わなければなりません。捏造された主張や検証不可能な記述を検出し、対処するFAVAの能力により、大規模なコンテンツ制作においても、コンテンツの信頼性を維持することができます。
**機密性の高いアプリケーション
法律、政府機関、財務分析などの分野では、大量のテキストを処理したりレポートを生成したりするためにAIを導入することがよくあります。これらの分野では、エラーが広範囲に影響を及ぼす可能性があります。出力が確定する前にエラーを修正するFAVAの機能により、これらのシステムは、高い信頼性が要求される環境でも確実に動作します。
AIが生成したコンテンツの正確性と信頼性を高めることで、FAVAは重要な分野における責任あるAIの利用に新たな機会を提供する。FAVAのエラー修正アプローチは、実際のアプリケーションで直面する特定の課題に対処し、専門的で機密性の高い領域におけるAIの実用的価値を高めます。
FAVAの限界と今後の方向性
FAVAは、AI出力における幻覚への対処に進歩を示す一方で、ある制限が現在の能力を制限している。
制限事項
1.検索依存性*FAVAは、エビデンスを外部ソースに依存しているため、関連する、あるいは正確な情報が容易に入手できない場合のクレーム処理能力が制限される。検索された上位5つの文書にモデルを限定すると、より広範な証拠ベースを必要とする複雑なクレームに対応する際の有効性が低下する可能性がある。
2.複雑なエラーに対する性能*FAVAは、不正確な実体や矛盾した文章のような単純なエラーに対してはより効果的であるが、捏造された記述や検証不可能な主張のような複雑なエラータイプに対しては課題に直面する。これらは、現在のアプローチでは十分に対応できない、より深い文脈の検証を必要とする。
3.アノテーションにおける主観性*分類法では、特に主観的な文や検証不可能な主張のような曖昧なカテゴリーでは、エラーの分類を人間の主観的なアノテーションに頼っている。これは、アノテーターによって解釈が異なる可能性があるため、矛盾をもたらします。
4.合成データの限界*訓練に使用される合成データセットは、多様で管理されてはいるが、現実世界の幻覚の微妙さや複雑さを完全に捉えることはできないかもしれない。これは、FAVAが訓練シナリオとは異なる現実世界の入力に対して一般化する能力を制限する可能性がある。
これらの課題は、改良と将来の開発の機会を提供する。
将来の方向性
1.**より広範な証拠ソースを組み込み、文書選択を洗練させる検索プロセスを改善することで、複雑なクレームを検証するFAVAの能力を強化することができる。分野別データベースやリアルタイムの情報検索を取り入れることで、その精度をさらに高めることができるかもしれない。
2.**論理的矛盾、数値の不正確さ、文脈の不一致など、エラーの種類を追加するために分類法を拡張することで、FAVAはより広範囲の幻覚に対処できるようになる。また、より包括的な分類法は、情報探索シナリオ以外の応用にも役立つだろう。
3.スケーラブルで効率的なデータ生成コストを削減し、リアリズムを向上させるためには、高品質な訓練データを大規模に生成する方法を開発することが不可欠である。多様なトレーニングインスタンスを作成するための半自動化アプローチや高度なモデルを活用することで、合成データセットの限界に対処することができる。
4.評価ベンチマークの改善*FAVABENCHのような評価データセットの規模と多様性を拡大することで、モデルの性能をより正確に測ることができる。長文のテキストやドメイン固有の課題など、様々なドメインのシナリオを取り入れることで、実世界のユースケースをよりよく反映することができる。
これらの分野に取り組むことで、FAVAは多様で複雑なシナリオに対応できる、より堅牢なツールへと進化することができる。
結論
FAVAは、証拠検索ときめ細かなエラー検出・修正を組み合わせることで、AIにおける幻覚という重大な課題に対処している。その詳細な分類法、評価ベンチマーク、多様なエラータイプに対するトレーニングは、AI出力の事実精度を高め、実世界のアプリケーションにとって価値あるツールとなる。検索依存性や複雑なクレームに対する課題といった限界は残るものの、検索プロセス、データ生成、分類法の拡張における今後の改善により、FAVAの能力はさらに強化されるだろう。AIが医療、教育、ジャーナリズムなどの業界を形成し続ける中、FAVAのようなツールはAIシステムの信頼性と信用を確保する上で極めて重要である。
読み続けて

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.