




Fuzz Testing Explained: Uncover Hidden Flaws in Software

TL; DR: Fuzz testing (or fuzzing) is a software testing technique that inputs large amounts of random or unexpected data ("fuzz") into a program to identify bugs, crashes, or vulnerabilities. By exposing how the system behaves under unexpected conditions, fuzz testing helps uncover edge cases, security flaws, and weaknesses that traditional testing might miss. It’s commonly used for improving software reliability and security, particularly in systems that process complex inputs like web services, file parsers, and APIs.
Fuzz Testing Explained: Uncover Hidden Flaws in Software
What is Fuzz Testing?
Fuzz testing is a software testing method that finds hidden bugs by feeding unexpected or random data into a program to see how it responds. By deliberately causing unusual or "fuzzy" situations, this testing technique uncovers vulnerabilities that regular tests might miss, especially in complex or security-sensitive software.
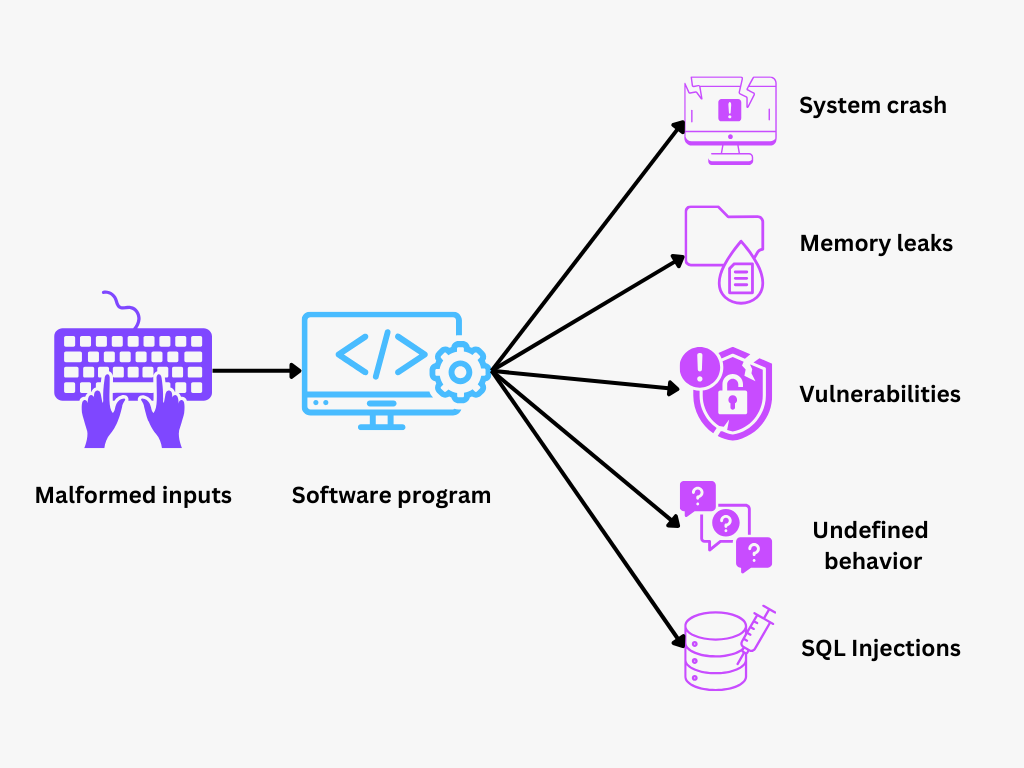 Figure- Fuzz Testing.png
Figure- Fuzz Testing.png
Figure: Fuzz Testing
History of Fuzz Testing
Fuzz testing began as an accidental discovery in the late 1980s. Professor Barton Miller at the University of Wisconsin was experimenting with networked computer programs when he noticed unexpected crashes caused by random input noise. This led him to investigate further, intentionally feeding random data into various programs to observe their reactions. He found many applications vulnerable to these random inputs, revealing security weaknesses and stability issues. Miller's work laid the foundation for fuzz testing, establishing it as an effective method to uncover software bugs and vulnerabilities.
How Fuzz Testing Works?
Fuzz testing feeds random, unexpected, or invalid data ("fuzzed" inputs) into a program to assess its behavior and uncover potential bugs. This approach forces the program into unpredictable states, often revealing bugs or vulnerabilities that traditional tests might miss. The idea is to see how healthy software holds up under stress from unexpected inputs without crashing or behaving unexpectedly.
Phases of Fuzz Testing
The fuzz testing process consists of steps that guide identifying, testing, and analyzing issues within a target system.
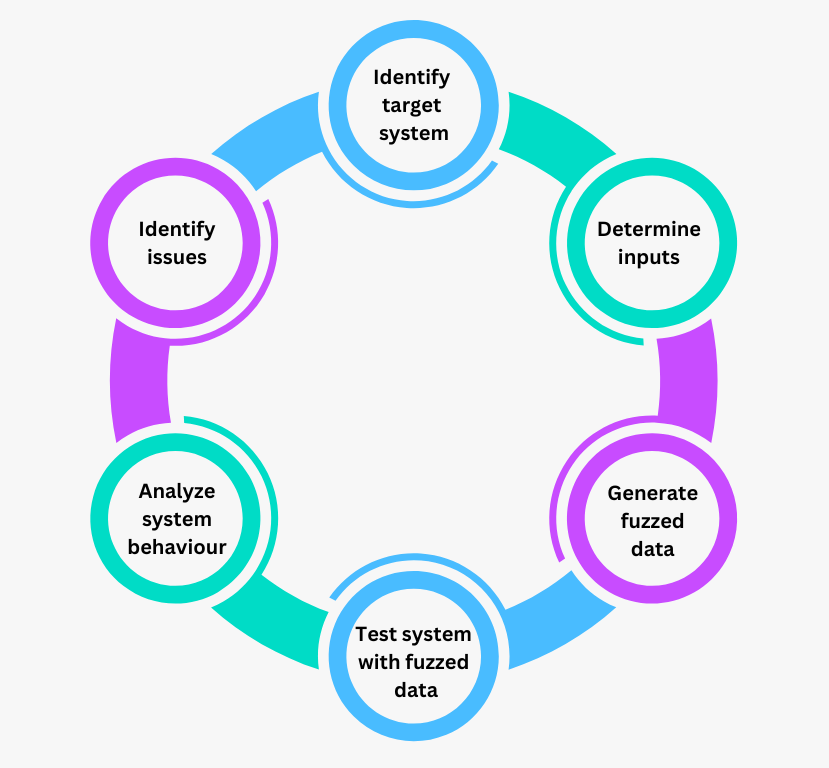 Figure- Phases of Fuzz testing.png
Figure- Phases of Fuzz testing.png
Figure: Phases of Fuzz testing
Identify Target System
The first step in fuzz testing is to choose the program or component you want to test. This could be an application, a function within a more extensive system, or even a specific input field.
Determine Inputs
Once the target system is identified, the next step is to decide what type of inputs will be tested. This involves understanding the data formats or input types that the system typically handles. For example, if the target system processes network packets, the inputs might consist of various packet structures. Testers set up a foundation for creating relevant fuzzed data by defining relevant inputs.
Generate Fuzzed Data
In this phase, the fuzzing engine creates a variety of unexpected or invalid inputs. These inputs could be randomly generated, mutated forms of valid data, or crafted sequences that simulate edge cases. The goal is to produce inputs that can challenge the target system’s boundaries for any weaknesses in its handling of unexpected data.
Test System with Fuzzed Data
Now, the generated fuzzed data is fed into the target system. During this phase, the system interacts with each input and responds to unusual or invalid data. Due to the repeated exposure of the system to diverse inputs, fuzz testing reveals points where the system fails to answer correctly or crashes.
Analyze System Behavior
As the system processes each input, its behavior is closely monitored. Testers look for signs of abnormal activity, such as crashes, unresponsive behavior, or unexpected error messages. This phase helps identify vulnerabilities or potential weaknesses that could be exploited in a real-world scenario.
Identify Issues
Finally, any anomalies detected during testing are reviewed to determine if they indicate genuine issues. Testers analyze the observed behavior using debugging tools, to identify the root cause of each failure.
Types of Fuzz Testing
Fuzz testing comes in various forms, each with distinct strategies and applications. Here’s a breakdown of the main types and categories of fuzz testing:
1. Input-Based Fuzzing
This type of fuzzing focuses on generating various inputs to test how a program handles different data. It includes two primary approaches:
Mutation-Based Fuzzing: This method alters existing data samples by making random modifications. For example, mutation-based fuzzing might add unexpected characters, swap sections, or change values if the input is a text file. The idea is to take known, valid inputs and create new, slightly “mutated” versions, which can reveal vulnerabilities while maintaining some resemblance to realistic data.
Generation-Based Fuzzing: Unlike mutation-based fuzzing, generation-based fuzzing builds inputs from scratch. It uses predefined rules and structures to create new data that mimic specific formats or protocols. For example, generation-based fuzzing might construct XML files with various structures, tags, and attribute values if testing an XML parser.
2. Structure-Aware Fuzzing
Structure-aware fuzzing understands the underlying structure of the data being tested. Instead of feeding random or mutated data, it maintains the correct format or protocol structure while varying the content.
- Protocol Fuzzing: A typical application of structure-aware fuzzing, protocol fuzzing is used to test network protocols by generating inputs that conform to specific communication standards (like HTTP or TCP/IP).
3. Coverage-Guided Fuzzing
Coverage-guided fuzzing uses feedback from the program’s execution to generate new inputs. It tracks code coverage metrics to identify which parts of the code were executed with each input, then creates inputs that aim to cover untested code paths. This approach is highly effective for achieving thorough testing, as it maximizes code coverage, which increases the chances of discovering hidden bugs and vulnerabilities.
4. Black-Box, White-Box, and Gray-Box Fuzzing
These categories differ based on how much information the tester has about the target software:
Black-Box Fuzzing: The tester has no internal program knowledge in black-box fuzzing. Inputs are randomly generated and fed into the software without considering the program's structure or code. Black-box fuzzing is simple to set up and doesn’t require source code. It helps test closed-source applications, though it may not uncover as many issues as other methods.
White-Box Fuzzing: The tester has full access to the program’s source code in white-box fuzzing. This allows the fuzzing process to target specific parts of the code, using techniques like static analysis and control flow tracking to guide input generation. White-box fuzzing is more precise and can uncover complex bugs, but it requires detailed code knowledge, making it more resource-intensive.
Gray-Box Fuzzing: Gray-box fuzzing strikes a balance between black-box and white-box approaches. Testers have partial access to the program’s internal workings, typically through instrumentation that provides feedback about code coverage. This approach benefits from the efficiency of black-box fuzzing with the added guidance from code coverage.
5. Hybrid Fuzzing
Hybrid fuzzing combines multiple fuzzing strategies to improve testing depth and efficiency. For instance, it might blend mutation-based fuzzing with coverage-guided techniques to maximize code coverage while exploring a broader range of input variations. Hence, testers can target complex software with greater accuracy to find vulnerabilities that might be missed by a single fuzzing method alone.
Use Cases of Fuzz Testing
Fuzz testing has diverse applications across industries, especially where security, stability, and resilience are critical. Here are some of the primary use cases for fuzz testing:
1. Security Testing
One of the most common applications of fuzz testing is in security testing. By feeding random or malformed inputs into a program, fuzz testing can reveal vulnerabilities that hackers might exploit, such as buffer overflows, input validation flaws, and injection vulnerabilities.
2. Software Robustness
Fuzz testing also improves software robustness by ensuring that applications can gracefully handle unexpected or malformed data without crashing. Many programs are designed with specific input expectations, but real-world data isn’t always predictable. By testing with various unexpected inputs, fuzz testing can expose areas where software might fail under stress, especially for applications that run in unpredictable environments or handle diverse data.
3. Protocol Testing
Protocol fuzzing is widely used to test the resilience of network protocols. Network protocols define the rules for data exchange between devices, and any weakness in these protocols can lead to security breaches or disruptions. Through fuzz testing network protocols, testers can assess how well these protocols handle unexpected or malformed packets to identify vulnerabilities that could affect data integrity, security, or communication reliability.
4. Automotive and IoT Testing
In automotive systems, fuzz testing can expose vulnerabilities in communication between the car’s subsystems, to make sure they remain operational and safe. Similarly, for IoT devices, fuzz testing is essential in confirming that these devices can handle a range of network conditions and data inputs without compromising functionality or security.
Benefits of Fuzz Testing
Early Discovery of Hidden Bugs and Vulnerabilities: Fuzz testing reveals bugs that traditional testing methods may miss, especially those triggered by rare or unexpected input scenarios.
Improves Software Robustness and Reliability: By exposing software to various inputs, including malformed or unexpected data, fuzz testing helps developers identify weak points and harden the software against real-world conditions.
Enhanced Security Measures: Fuzz testing finds vulnerabilities that could be exploited for attacks, such as buffer overflows, memory leaks, and injection flaws. Hence, It allows security teams to proactively address these weaknesses to protect the software from potential cyberattacks and unauthorized access.
Boosts Code Coverage: Coverage-guided fuzzing ensures that even less frequently used parts of the code are tested, uncovering bugs in rarely executed paths. This broad testing approach improves the overall quality and stability of the software by exploring code paths that might otherwise be neglected.
Challenges and Limitations of Fuzz Testing
Complexity in Handling Intricate Data: Fuzz testing struggles with complex, stateful programs that rely on intricate data formats, which make it challenging to generate adequate inputs without breaking the data structure. E.g. In protocol or file format testing, fuzzing requires knowledge of the structure, which adds complexity and requires advanced fuzzing techniques.
Resource and Time Constraints: Large-scale fuzzing can consume significant processing power and memory, making it resource-intensive. Long runtimes are often needed to produce meaningful results, especially for complex applications, which can delay the testing and development process.
Limitations of Random Input Generation: Fuzz testing relies on random or semi-random inputs, which may not always reach deeper parts of the code, especially in complex programs with intricate logic or dependencies. Additionally, purely random fuzzing lacks the focus required to target specific vulnerabilities, so bugs in certain code paths might remain undetected.
Difficulty in Reproducing Issues: Fuzz testing can reveal obscure bugs, but reproducing the exact conditions that triggered these bugs can be challenging. Debugging becomes more complicated when the specific input or sequence of events that caused the issue cannot be easily replicated.
False Positives and Noise in Results: Fuzz testing can produce a high volume of data, with some results indicating issues that aren't actual vulnerabilities, known as false positives. Filtering out false positives and focusing on genuine vulnerabilities can be time-consuming and require expertise.
Ongoing Monitoring and Analysis: Fuzz testing isn’t a one-time process; it requires continuous monitoring. Moreover, effective fuzzing requires interpreting extensive logs and results, demanding skilled personnel to analyze and address detected issues.
Fuzz Testing Tools and Frameworks
AFL (American Fuzzy Lop): Known for its efficiency in mutation-based fuzzing, AFL uses a combination of intelligent input mutation and code coverage feedback to discover vulnerabilities.
libFuzzer: A coverage-guided fuzzer designed for libraries and applications, libFuzzer generates inputs that aim to code coverage for uncovering hidden bugs in complex software.
OSS-Fuzz: A large-scale fuzzing platform tailored for open-source projects, OSS-Fuzz provides continuous, automated fuzz testing to improve the security and stability of widely used open-source software.
Peach: A comprehensive fuzzing framework that supports a range of protocols and data formats for testing complex software and communication protocols, including generational and mutation-based testing.
Sulley: Primarily used for network protocol fuzzing, Sulley is valued for its ability to simulate a wide variety of network inputs and is often used in security research.
Radamsa: A lightweight mutation-based fuzzer that is simple to use and effective for generating unexpected inputs to test software resilience and robustness.
Fuzz Testing for Vector Databases and AI Applications
Fuzz testing is highly relevant in vector databases like Milvus (created by Zilliz) and GenAI applications, as these technologies handle large volumes of diverse and complex data. In AI-driven solutions, like Retrieval-Augmented Generation (RAG) and other machine learning models, fuzz testing is vital in maintaining data integrity, system stability, and security, especially when dealing with unstructured data. Here’s how fuzz testing is beneficial:
Ensuring Robust Data Handling in Vector Databases: Since vector databases often support complex queries and filtering, fuzz testing can reveal how well they handle edge cases in query inputs. Hence, it identifies potential failures or inefficiencies in the indexing and retrieval.
Testing Resilience in AI-Powered Applications like RAG: RAG and similar AI models rely on retrieving relevant information from external databases to generate responses or perform specific tasks. These models are sensitive to the quality and structure of the retrieved data. Fuzz testing can simulate corrupted or unexpected data inputs to see how the model reacts to unusual retrievals.
Securing Vector Databases and AI Pipelines Against Potential Attacks: Fuzz testing can simulate hostile data inputs, like adversarial examples designed to manipulate the AI model’s behavior. This identifies weak points that attackers could exploit, enabling developers to reinforce security.
Improving Reliability in Distributed AI Architectures: Many AI applications, especially those powered by Large Language Models (LLMs) or image recognition systems, are distributed across multiple nodes and systems. Fuzz testing can reveal issues in the data synchronization process across nodes in a distributed vector database to check if all instances of the database can handle inconsistent or unexpected inputs smoothly.
Best Practices for Fuzz Testing
Implementing fuzz testing effectively requires careful planning and adherence to best practices. Here are some essential tips to optimize fuzz testing:
Optimize Input Generation
Use mutation-based and generation-based fuzzing to ensure a broad range of inputs, covering common and rare edge cases.
Tailor input generation to match the target software’s expected data formats or protocols to avoid irrelevant errors and focus on meaningful issues.
Use structure-aware or coverage-guided fuzzing for complex data types to maximize code coverage and find deeper bugs.
Set Up Comprehensive Monitoring and Feedback
Implement detailed logging to capture program behavior during testing, including crashes, memory leaks, and abnormal outputs.
Monitoring tools like Prometheus can be used to track memory usage, CPU load, and execution paths to gain insights into software performance under fuzzed inputs.
Enable crash reporting and debugging tools to help trace the root cause of any detected issues, making it easier to reproduce and fix the bugs.
Select the Right Tools
Choose fuzzing tools based on the specific requirements of the project. For instance, AFL can be used for mutation-based fuzzing, libFuzzer can be used for libraries, and OSS-Fuzz can be used for open-source projects.
Ensure the tool integrates well with your development and testing environment, allowing seamless incorporation into CI/CD pipelines.
Experiment with multiple tools and combine different fuzzing strategies to yield better coverage and results.
Design an Effective Test Environment
Create a controlled test environment that isolates the fuzzed software from critical systems to prevent accidental damage or data loss.
Allocate sufficient computing resources, as fuzz testing can be resource-intensive. Consider running tests in a virtual machine or container to manage resource allocation effectively.
Regularly update your test environment to include the latest dependencies and patches, as outdated components can introduce unintended issues.
Avoid Common Pitfalls
Pitfall: Relying solely on random inputs without targeting specific areas. Solution: Use coverage-guided or structure-aware fuzzing to direct the test toward code paths that matter most.
Pitfall: Ignoring false positives, which can overwhelm the results. Solution: Regularly review and filter results to focus on genuine issues, using tools or scripts to help sort the output.
Pitfall: Failing to reproduce issues found during fuzz testing. Solution: Log all fuzzed inputs and execution paths so that detected issues can be reproduced and fixed accurately.
Make Fuzz Testing Continuous
Integrate fuzz testing into your CI/CD pipeline to ensure new code changes are consistently tested for potential vulnerabilities.
Schedule regular fuzz tests, especially for critical software components, as part of the ongoing development process. Continuous fuzzing increases the likelihood of catching issues early.
Conclusion
In summary, fuzz testing is a powerful method for uncovering hidden bugs and vulnerabilities across various software applications, including vector databases and AI systems. Fuzz testing helps improve robustness, security, and reliability by feeding random or malformed inputs into a program. Although it comes with challenges, adopting best practices and using the right tools can maximize its effectiveness.
FAQs on Fuzz Testing
- What is fuzz testing, and why is it important?
Fuzz testing is a software testing method that inputs random or unexpected data into a program to find bugs and vulnerabilities. It improves software security, robustness, and reliability by uncovering issues that traditional testing methods might miss.
- How does fuzz testing work in practice?
Fuzz testing involves several phases: identifying the target system, determining the types of inputs to test, generating fuzzed data, running the program with this data, analyzing the program’s behavior, and identifying any issues. This process reveals how well the software handles unexpected or malformed inputs.
- What are some common types of fuzz testing?
Common types include mutation-based fuzzing (altering existing data), generation-based fuzzing (creating inputs from scratch), coverage-guided fuzzing (maximizing code coverage), and protocol fuzzing (testing specific data formats or communication standards).
- Can fuzz testing be applied to AI applications and vector databases?
Yes, fuzz testing is highly relevant for AI and vector databases. It helps these systems handle unpredictable inputs, improve data integrity, and maintain security, especially in applications like Retrieval-Augmented Generation (RAG) and complex data handling in AI pipelines.
- What are the main challenges of fuzz testing?
Key challenges include handling complex data structures, the resource-intensive nature of large-scale fuzzing, limitations of random input generation, and difficulty reproducing issues. Following best practices and selecting the right tools can help address these challenges.
Related Resources
- What is Fuzz Testing?
- History of Fuzz Testing
- How Fuzz Testing Works?
- Types of Fuzz Testing
- Use Cases of Fuzz Testing
- Benefits of Fuzz Testing
- Challenges and Limitations of Fuzz Testing
- Fuzz Testing Tools and Frameworks
- Fuzz Testing for Vector Databases and AI Applications
- Best Practices for Fuzz Testing
- Conclusion
- FAQs on Fuzz Testing
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free