




Processing streaming data in Kafka with Timeplus Proton
In April 2024, Jove Zhong, co-founder of Timeplus, took the stage at the Seattle Unstructured Data Meetup to deliver a talk on "Processing Streaming Data in Kafka with Timeplus Proton." As an expert in data streaming and real-time processing, Jove provided a comprehensive overview of how Timeplus integrates with Kafka to handle real-time data while also giving us live demos that were both engaging and educational. Let’s dive into the key points and insights from this insightful session.
Link to the YouTube replay of Jove Zhong’s talk: Watch the talk on YouTube
Timeplus and Its Real-Time Capabilities
Jove Zhong is a software engineering maestro. If you don’t believe me, check out his track record. Co-founder and Head of Product at Timeplus, former Engineering Director at Splunk, holder of 17 patents, and 4 AWS certifications. Oh, and he’s been a “world-class dad” since 2010. Jove draws fascinating parallels between fatherhood and business leadership, showing that nurturing a child and running a company have more in common than you'd think.
With that, let's dig into Jove’s talk on “Processing Streaming Data in Kafka with Timeplus Proton.”
Headquartered in Santa Clara, California, Timeplus is revolutionizing real-time data handling with its innovative streaming SQL database and real-time analytics platform. Backed by top venture capitalists and technologists, Timeplus offers both open-source and commercial versions, enabling efficient management and processing of live data streams. Its standout features include dynamic dashboards and SQL-based processing, making real-time data manipulation accessible and user-friendly.
Timeplus Proton, the core engine of Timeplus, serves as a powerful alternative to platforms like ksqlDB and Apache Flink. It is lightweight, written in C++, and optimized for performance. With capabilities such as streaming ETL, windowing functions, and high cardinality aggregation, Proton enables developers to tackle streaming data processing challenges efficiently. The platform supports diverse data sources, including Apache Kafka, Confluent Cloud, and Redpanda, and allows for real-time insights and alerts.
Whether for FinTech, AI, machine learning, or observability, Timeplus provides end-to-end capabilities that help data teams process streaming and historical data quickly and intuitively. It’s a simple, powerful, and cost-efficient solution designed for organizations of all sizes and industries.
Live Demo: Real-Time Bitcoin Price Monitoring
To kick things off, Jove demonstrated Timeplus’s real-time capabilities by showcasing a live Bitcoin price feed. This demo was not just a display of technological prowess but also an illustration of how Timeplus can process and display data faster than conventional sources like Google. The audience was captivated as Jove compared the real-time feed with Google’s, highlighting the superior performance of Timeplus.
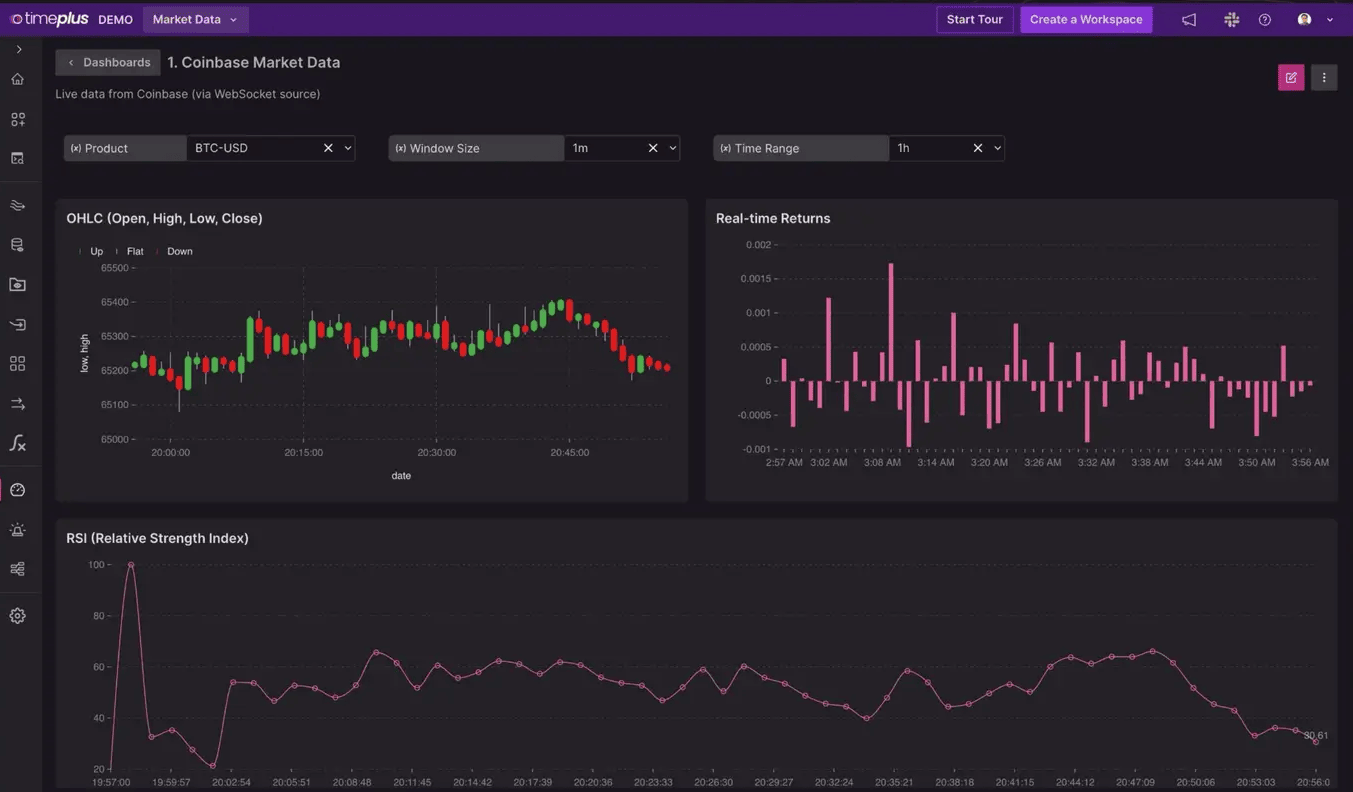
Kafka: The Backbone of Real-Time Data Streaming
Jove provided a deep dive into Kafka, explaining its architecture and functionality. Kafka is a powerful open-source event streaming platform for handling diverse data types and managing distributed computing environments. Written in Java and Scala, Kafka is designed to handle real-time data feeds with high throughput and low latency. Trusted by over 80% of Fortune 100 companies, including industry giants like Goldman Sachs, Target, and Cisco, Kafka is known for its reliability and performance.
Understanding Kafka’s Architecture
Kafka operates as a distributed data streaming platform capable of handling millions of events per second. By visualizing Kafka’s architecture through the following diagram, Jove demonstrated the platform's ability to handle real-time data feeds with high throughput and low latency, making it a powerful tool for modern data streaming needs. The diagram explains the architecture of how producers, consumers, and brokers work together to ensure data is efficiently processed and delivered. He also discussed Kafka’s replication and partitioning strategies, which provide fault tolerance and scalability.
Kafka operates as a distributed system consisting of servers and clients communicating via a high-performance TCP network protocol. It can be deployed on bare-metal hardware, virtual machines, and containers in both on-premise and cloud environments.

The architecture of Kafka, as illustrated in the diagram, consists of several key components:
Clients and Brokers: Kafka operates as a distributed system consisting of clients and brokers. Clients are applications that produce and consume messages. Brokers are servers that store and forward these messages. The diagram shows how clients connect to a broker, which acts as a bootstrap server to route the data to other brokers in the cluster.
Producers and Consumers: Producers are responsible for sending data to Kafka topics, while consumers read data from these topics. The diagram depicts how a producer sends messages to different topics (Topic A, Topic B, Topic C) across multiple brokers. Consumers then read from these topics, ensuring data is processed and delivered efficiently.
Topics and Partitions: Kafka topics are divided into partitions, which allow for parallel processing of data. Each partition is replicated across multiple brokers to ensure fault tolerance. The diagram shows a topic with three partitions being consumed by different consumers, demonstrating how Kafka distributes load and maintains high availability.
Scalability and Fault Tolerance: Kafka clusters are highly scalable and can span multiple data centers or cloud regions. The architecture supports elastic expansion and contraction, ensuring continuous operations without data loss. If a broker fails, the system can recover by rerouting data to other brokers.
Streaming LLM and Vector Databases
A significant portion of the talk was dedicated to exploring how data streaming integrates with Large Language Models (LLMs) and vector databases. Jove emphasized the potential of these integrations to enhance AI applications, making data processing more efficient and accurate. The fusion of streaming data with AI models can significantly improve the responsiveness and intelligence of various applications.
Recently, Zilliz Cloud and Confluent Cloud for Apache Flink® announced a partnership that further demonstrates this concept. Leveraging this, you can build real-time GenAI apps using Kafka and Flink; businesses can create real-time data pipelines that feed into vector databases like Milvus. This setup enables the development of advanced AI applications, such as real-time semantic search and Retrieval Augmented Generation (RAG). With real-time data processing, LLMs can access the most current information, ensuring accurate and timely responses in applications ranging from enterprise search to personalized recommendations in e-commerce.
Practical Applications: AI-Powered Chatbots
One of the practical applications Jove discussed was the use of real-time data in AI-powered chatbots. By leveraging real-time data streams, these chatbots can provide up-to-date information, such as flight status updates. For example, a chatbot could instantly inform users about flight delays and suggest alternative flights, demonstrating the practical benefits of real-time data processing.

Jove gave an example that imagines you're chatting with a flight status bot:
User: "What's my flight status to New York?"
Chatbot: "Your flight is delayed by 2 hours."
User: "Can I find another flight that gets me there sooner?"
Chatbot: "Yes, there is an alternative flight available with one seat left. It will cost you $1500, but you'll arrive on time."
User: "Great, book it for me."
In this scenario, the chatbot utilizes Kafka’s real-time data streams to provide up-to-date flight information. It not only informs the user about delays but also checks available flights, seats, and pricing in real time. The chatbot then presents this information to the user, enabling quick and informed decisions. This example showcases how Kafka's real-time data processing capabilities enhance the functionality and responsiveness of AI-powered chatbots, making them valuable tools for users seeking immediate and accurate information.
Integrating Timeplus with Vector Databases
Jove’s demo continued with an impressive integration of Timeplus and vector databases i-e Milvus, showcasing how data from Hacker News was processed and queried in real-time. This process is illustrated in the diagram below. The workflow begins with retrieving data from the Hacker News API, followed by converting HTML to text using Bytewax. The text is then embedded with Hugging Face, and streamed using Timeplus's SQL capabilities. The data is connected to Kafka via the Milvus sink connector, enabling real-time querying and processing in the Milvus vector database.
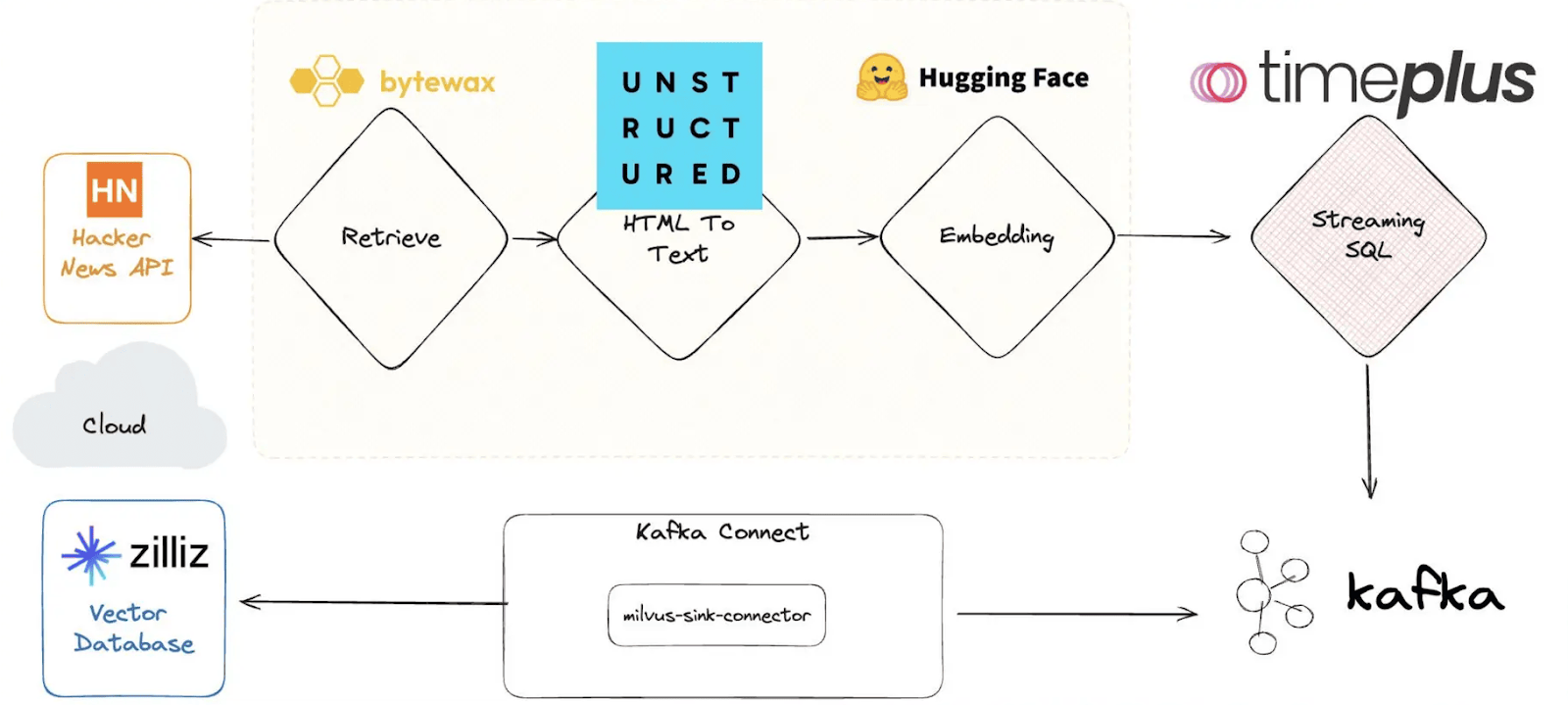
He walked us through a concrete example to illustrate this integration's power.
Imagine you're working with Hacker News data. Let's pull in the latest data from Hacker News. Using Timeplus, we can stream this data in real time. Jove inputs a command, and within seconds, a stream of Hacker News posts appears. Now, let's say we want to find all posts mentioning 'dogfooding.' We can run a complex query across this unstructured data. He types in the query, and almost instantly, the system returns a list of relevant posts.
But we're not stopping there. Let's see the sentiment analysis of these posts. With another command, the data is processed, and the sentiment analysis is displayed, showing which posts are positive, negative, or neutral.
This is the power of integrating Timeplus with vector databases. We can handle vast amounts of unstructured data, run complex queries, and extract valuable insights in real-time."
In addition to Timeplus, Milvus also offers integration with Kafka using the Confluent Kafka Connector, enabling real-time vector data streaming to Milvus or Zilliz Cloud. This setup allows for real-time semantic searches and similarity searches, enhancing the ability to derive immediate insights from streaming data.
To give you a quick insight, the following table lists some important products with their description and use cases discussed in this article.
| Product | Description | Use Case |
| Timeplus | A real-time analytics platform with powerful streaming SQL capabilities. | Real-time data processing and analytics. |
| Timeplus Proton | The core engine of Timeplus is lightweight, written in C++, and optimized for performance. | Streaming ETL, windowing functions, high cardinality aggregation. |
| Kafka | Distributed event streaming platform, that handles high-throughput, low-latency data feeds. | Data pipelines, streaming analytics, data integration. |
| Confluent Kafka Connector | Tool for integrating Kafka with Milvus and Zilliz Cloud, enabling real-time vector data streaming. | Real-time data streaming to vector databases. |
| Apache Flink | Unified stream and batch processing framework, integrated with Kafka on Confluent Cloud. | High-performance stream processing. |
Conclusion
Jove Zhong’s talk at the Seattle Unstructured Data Meetup was a masterclass in real-time data processing. From practical demos to deep dives into advanced concepts, Jove provided a comprehensive overview of how Timeplus and Kafka are shaping the future of data analytics. The talk concluded with a look towards the future of streaming SQL and real-time processing. Jove highlighted the growing importance of these technologies in building smarter and more responsive AI systems. The ability to process data in real-time and make immediate decisions is becoming crucial in many industries, from finance to healthcare.
For those interested in exploring these technologies further, the full replay of the talk and presentation slides are available.

Keep Reading

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.