




Zilliz x Confluent: Build Real-Time RAG Applications Without Hallucination
Kafka is an open-source, real-time data streaming platform and message broker that allows applications to publish(write) and subscribe to (read) data streams efficiently. Developers use Kafka to build scalable, fault-tolerant data pipelines that can feed into vector databases to enhance retrieval augmented generation (RAG) applications. Confluent is a company that provides commercial solutions and tools built around Kafka to simplify its use for event-driven applications and streaming data architectures.
Generative AI (LLMs, diffusion models, GANs, etc.) is broadly applicable in many different industries and verticals. Injecting domain data into these models through RAG is becoming increasingly common at the application level - the CVP (ChatGPT, vector database, prompting) framework is a frequently used instantiation of RAG that leverages a vector database to perform semantic search.
The Confluent integration leverages Zilliz Cloud (Hosted Milvus) and Confluent Kafka to perform real-time ingestion, parsing, and processing of data to reduce hallucination in Large Language Models (LLMs) by providing up-to-date and contextually relevant information that helps to enhance the user experience.
There are a vast number of use cases that can benefit from this integration, such as chatbots, real-time sentiment analysis, and customer support.
Besides GenAI, you can also use this integration to build real-time recommender systems, detect anomalies, and develop various other applications that benefit from real-time AI.
How Confluent and Zilliz Cloud Integration Works
How the Integration Works
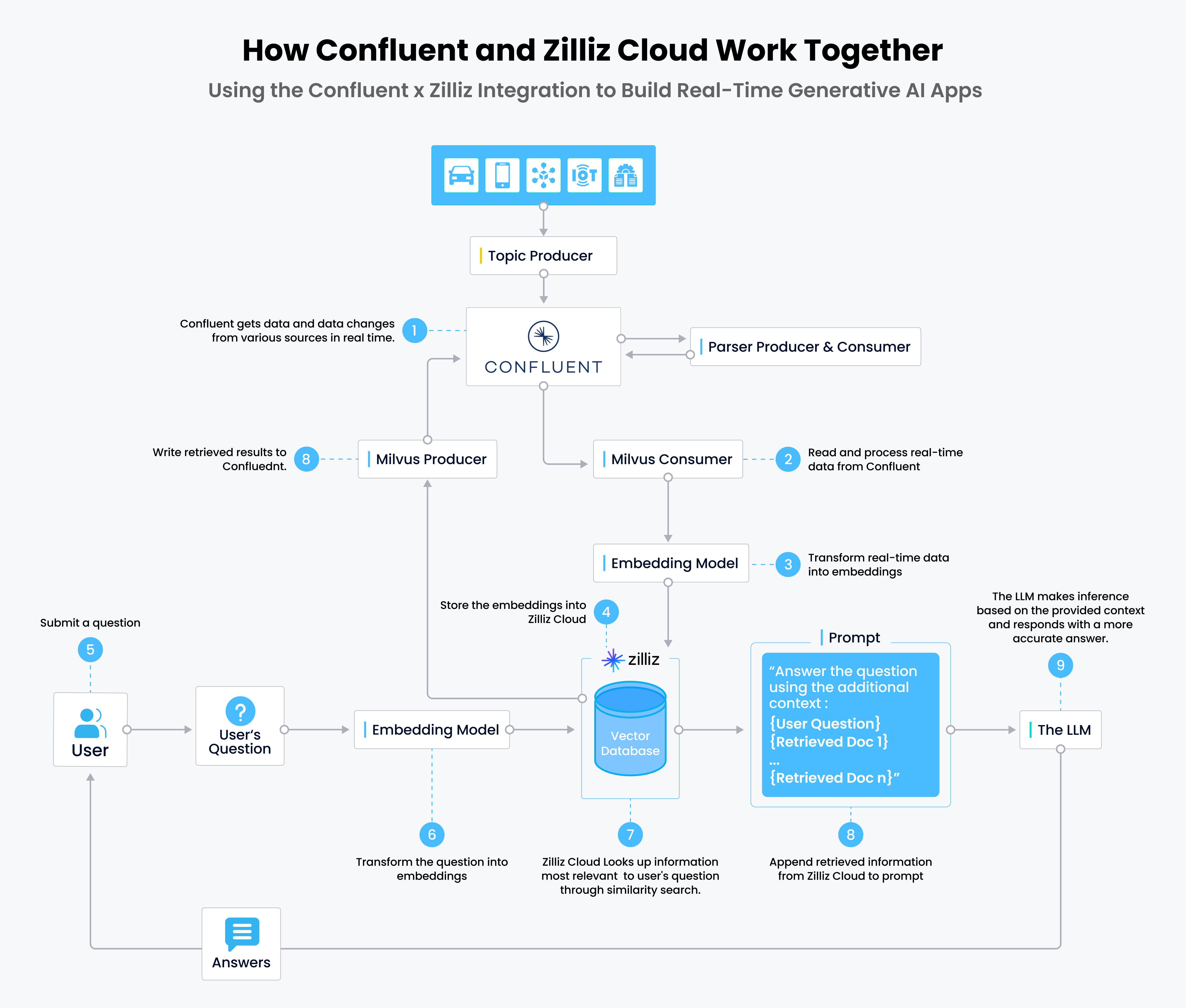
- Real-time data is written to Confluent via topic producers; this data is parsed and sent back to Confluent.
- Milvus consumers read and process the real-time data from Confluent.
- The real-time data is converted into vector embeddings via embedding models.
- The vector embeddings are stored in Zilliz Cloud.
- Users submit their questions to the chatbot (or RAG app).
- The question is transformed into vector embeddings for queries.
- Zilliz Cloud finds the top k results most relevant to the question through a similarity search.
- The retrieved results from Zilliz Cloud are appended to the prompt and sent to the LLM.
- The LLM generates the answer and sends it to the user via the chatbot.
Learn How
Check out these tutorials to learn how to use the Confluent integration.