




Enhancing Data Flow Efficiency: Zilliz Introduces Upsert, Kafka Connector, and Airbyte Integration
In today’s data-driven landscape, efficient data ingestion and robust data pipelines form the backbone of any powerful database system. At Zilliz, our recent enhancements in these areas—specifically the introduction of Upsert, Kafka Connector, and Airbyte integration—underscore our commitment to providing developers with a vector database that excels in performance, versatility, and ease of integration. We designed these new additions to streamline data handling, offering seamless integration and enhanced control over data flow, thereby enabling developers to focus on creating innovative applications without the overhead of managing complex data ingestion processes.
Streamlining data updates with Upsert
In the previous Milvus versions, updating data in many user scenarios involved a two-step process: delete, then insert. This method, while functional, had notable drawbacks, primarily the inability to ensure data atomicity and operational convenience. Recognizing these challenges, we introduced Upsert in Milvus 2.3, fundamentally changing how data updates are handled. We’re excited that Upsert is now in Public Preview in Zilliz Cloud.
Upsert simplifies the update process: if data does not exist in the system, it inserts it; if it exists, it updates it. This approach is built around the crucial concept of atomicity, ensuring that Upsert operations are perceived as a single action externally, irrespective of whether they involve an insertion or deletion.
Internally, this method is unconventional but highly effective - we insert first and then delete. This sequence is key to maintaining data visibility during the operation, especially in a system like Milvus, where insertions and deletions are handled in different segments.
Moreover, Upsert is specifically designed to handle primary key modifications with careful consideration. The primary key column cannot be altered during an update, which aligns with how Milvus manages data across shards based on the primary key hash. This constraint avoids the complexities and potential inconsistencies of cross-shard operations.
Using Upsert is straightforward and mirrors the Insert operation in many ways. Developers can easily integrate Upsert into their existing workflows with minimal adjustments. For instance, in SDKs like Pymilvus, the Upsert command can be invoked similarly to Insert, providing a seamless experience for those familiar with the platform.
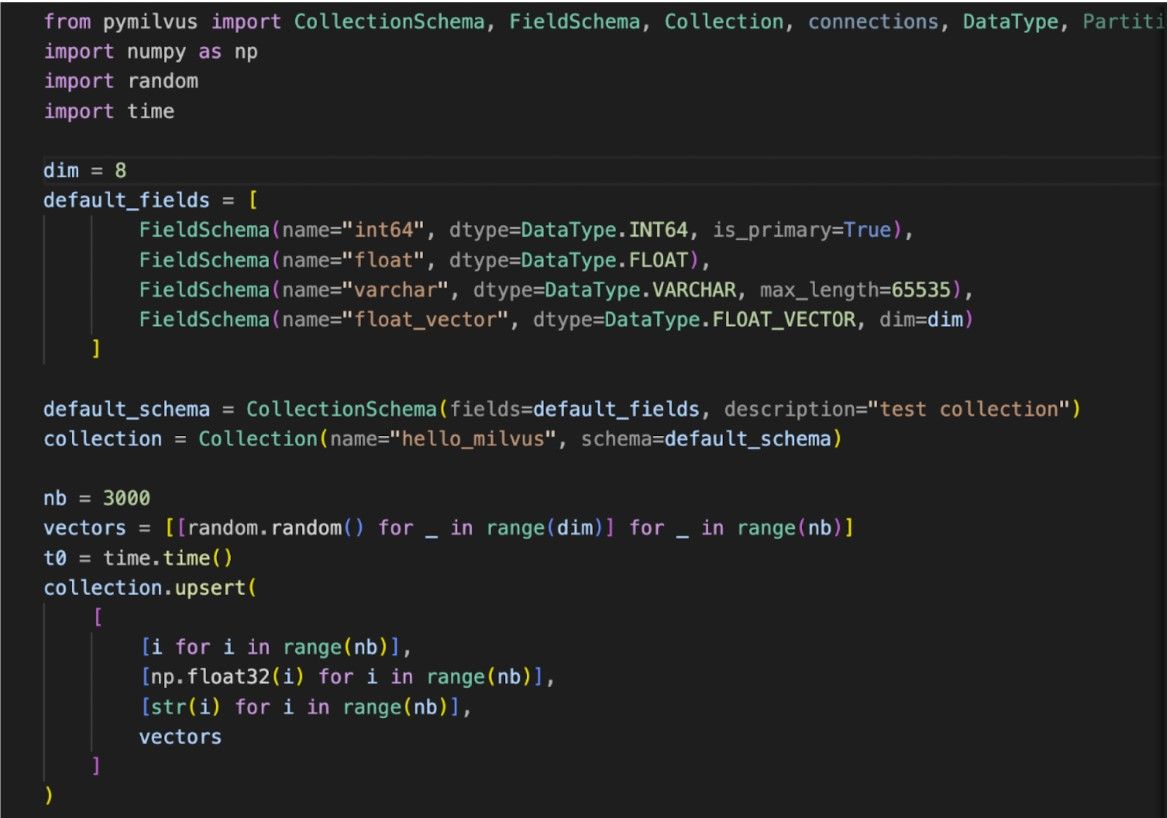
When executed, Upsert provides feedback on the operation’s success and the number of rows affected, adding to the ease of use for developers. This simplicity in usage, coupled with the robustness of the operation, makes Upsert a valuable tool in the data management arsenal. For more details, you can check the Upsert documentation.
However, it’s important to acknowledge specific considerations with Upsert.
AutoID Constraint: Upsert requires AutoID to be set to false. Upsert operations cannot be performed if a collection's schema has AutoID set to true. This limitation exists because Upsert, an update operation, requires submitting a primary key to update the corresponding batch of data. There's a potential conflict if a user-supplied primary key clashes with an AutoID-assigned primary key, leading to data overwriting. Hence, collections with AutoID enabled cannot support Upser for now. However, future iterations might remove this restriction.
Performance Overhead: Upsert can incur performance costs. Milvus uses a Write-Ahead Logging (WAL) architecture, and excessive deletions can lead to performance degradation. This is because deletion operations in Milvus don't immediately erase data. Instead, they mark the data with a deletion record. This record is only processed, and the data is removed during a later compaction process. Therefore, frequent deletions can lead to data bloat and impact performance. It is advised not to overuse or misuse Upsert for optimal performance.
As we move forward, more new features like Upsert will be released as our continuous effort to refine and advance our data management capabilities, ensuring that developers are equipped with the tools needed for efficient and effective data handling.
Empowering real-time data solutions with Kafka Connector
We recently announced the Kafka Sink Connector with open-source Milvus and Zilliz Cloud. This development enables seamless, real-time streaming of vector data from Confluent/ Kafka into Milvus or Zilliz vector databases. This integration is crucial for harnessing the power of unstructured data and enhancing the capabilities of real-time Generative AI, especially with advanced models like OpenAI’s GPT-4.
The collaboration between Zilliz and Confluent represents a significant advancement in managing and utilizing the ever-growing volume of unstructured data, which now makes up over 80% of newly created information. By enabling real-time vector data streaming, we provide a robust solution for efficiently storing, processing, and making this data easily searchable.
Example use cases with this connector include:
Enhancing Generative AI: Providing up-to-date vector data for GenAI applications enables more accurate and timely insights. This is especially beneficial in sectors like finance and media, where streaming vector embeddings from various data sources are crucial.
Optimizing E-commerce Recommendations: With real-time inventory and customer behavior updates, e-commerce platforms can dynamically adjust their recommendations, enhancing the user experience.
Getting started with this integration is straightforward:
Download the Kafka Sink Connector from GitHub or Confluent Hub.
Configure your Confluent and Zilliz accounts, ensuring matching field names on both platforms.
Load and configure the Connector, following detailed instructions on our GitHub repository.
Launch the Connector and experience real-time data streaming from Kafka to Zilliz.
For an in-depth guide on setup, use cases, and step-by-step instructions, we encourage you to visit our GitHub repository and explore our Confluent integration page.
Facilitating efficient data integration with Airbyte Integration
We recently collaborated with the Airbyte team to integrate Airbyte into Milvus, transforming data ingestion and utilization in Large Language Models (LLMs) and vector databases. This integration enhances the storage, indexing, and searching of high-dimensional vector data, which is crucial for applications like Generative Chat responses and product recommendations.
Key highlights of the integration:
Efficient Data Transfer: Airbyte seamlessly transfers data from various sources into Milvus/ Zilliz, enabling on-the-fly vector embedding calculation and streamlining data processing.
Enhanced Search Functionality: This integration boosts semantic search capabilities within vector databases. Utilizing embeddings, the system can automatically identify and present closely related content based on semantic similarity, which is invaluable for applications needing efficient retrieval from unstructured data.
Simple Set-Up Process: Setting up a Milvus cluster and configuring Airbyte for data synchronization are straightforward, as is building applications using Streamlit and the OpenAI embedding API if desired.
This integration streamlines data transfer and processing and opens new possibilities for real-time, AI-driven applications. For example, in customer support systems, integrating this technology can create intelligent support forms using semantic search. This enables the system to provide instant, relevant information to users, reducing the need for direct intervention by support agents and improving the overall user experience.
Refer to our release blog for a detailed practical application example, such as using Zendesk as a data source. This example demonstrates how to apply the integration in real-world scenarios, enhancing support ticket management and knowledge base accessibility.
The Airbyte and Milvus integration represents a significant step forward in AI and data management, providing an efficient solution for managing vector data. It creates new opportunities for developers and businesses seeking to exploit the full potential of AI in their operations.
Conclusion
The ongoing development and integration of tools like Upsert, Kafka Connector, and Airbyte with Zilliz's vector database underscore our commitment to advancing unstructured data management technologies. These enhancements are tailored to improve search performance and streamline the entire data pipeline, making it more efficient and developer-friendly.
Looking ahead, we have plans further to expand our suite of data ingestion and pipeline features. Stay tuned for these updates as we continue to innovate and provide tools that cater to the evolving needs of unstructured data handling and AI-driven applications.
We deeply value the feedback and insights from the developer community and are dedicated to continuous improvement. Your experiences and suggestions are crucial in our journey to advance these technologies. We’d love to hear from you. Feel free to join our GitHub community or submit your feedback directly by filing a ticket here.

Keep Reading

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.