




Garbage In, Garbage Out: Why Poor Data Curation Is Killing Your AI Models
In the modern world, data has become as valuable as oil. While enterprises have traditionally focused on collecting vast amounts of data to build models and gain insights, the focus is shifting toward quality over quantity. Many organizations now realize that having high-quality data is more critical than just amassing large datasets. However, this shift reveals a significant challenge: many businesses struggle to fully understand and curate their existing data effectively.
At the Unstructured Data Meetup hosted by Zilliz, Alexandre Bonnet, Lead ML Solutions Engineer at Encord, addressed this issue in his talk on the pitfalls of poor data curation and how enterprises can overcome these challenges. He highlighted the importance of data quality and market trends, presenting a roadmap to help organizations establish high-quality data production pipelines. In this blog, we’ll recap Alexandre’s key points. You can also watch his full talk on YouTube.
 Speaker Alexandre Bonnet from Encord speaking at the July Unstructured Data Meetup in SF
Speaker Alexandre Bonnet from Encord speaking at the July Unstructured Data Meetup in SF
The Evolution of AI
Alex discusses the shift from traditional AI applications to modern generative AI in enterprises. About a decade ago, AI models had to be built from scratch for each use case, and they were typically limited to handling just one type of data (uni-modal). These early models were primarily used by technical teams of data scientists and engineers. However, today’s AI landscape has evolved significantly with foundational models like YOLO, GPT, and Claude, which can be fine-tuned for specific domains with relative ease. Additionally, modern architectures can process multiple data types (multimodal), making AI accessible even to general users who may not have a deep technical background. This shift has led to widespread adoption of AI across various industries, streamlining workflows and processes.
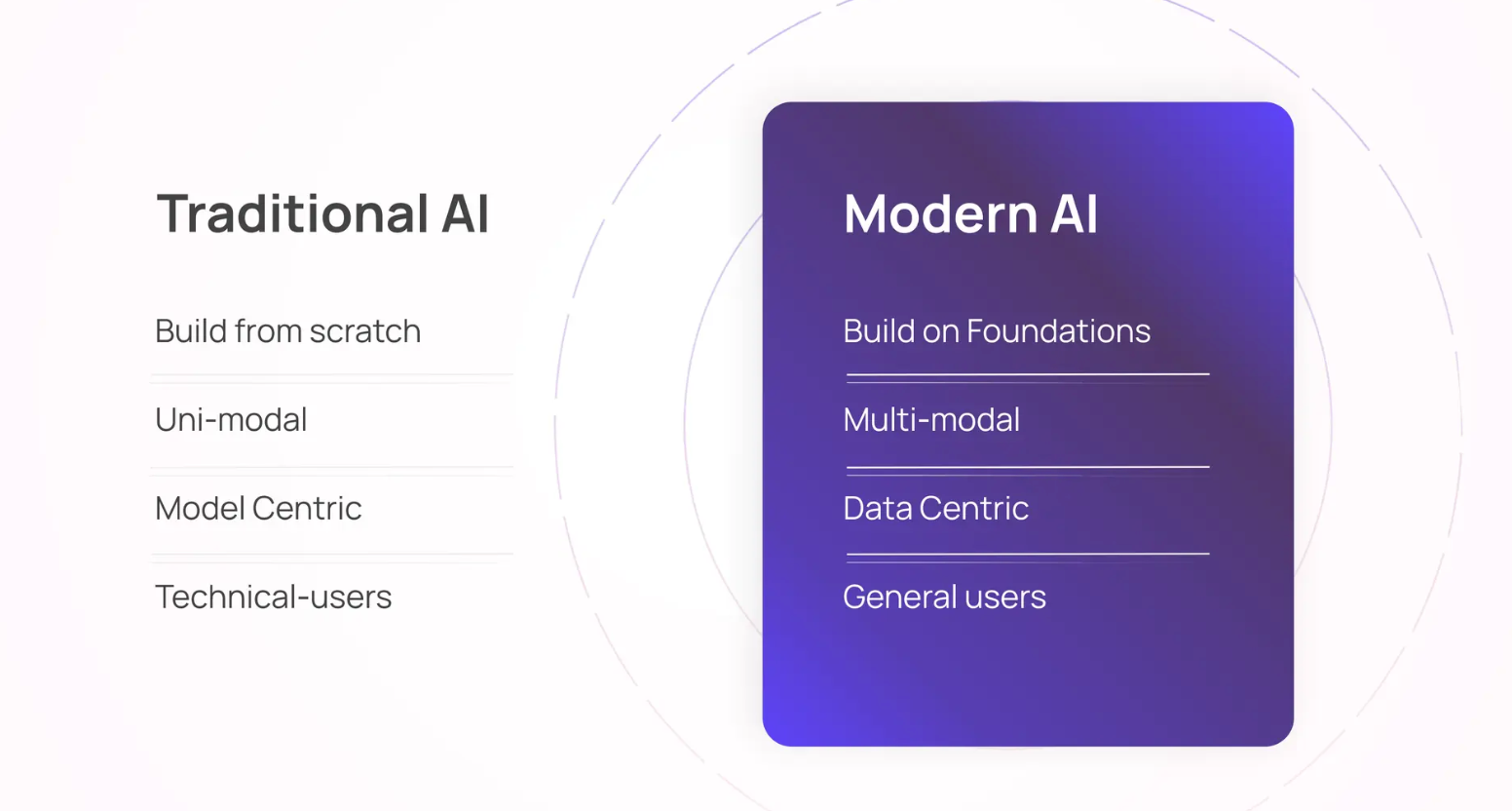 Figure- Traditional AI vs Modern AI
Figure- Traditional AI vs Modern AI
Alex points out, "Research in all fronts of Artificial Intelligence has been exploding in the last 10 years.” Despite advancements in areas such as synthetic data and generative AI, progress in computer vision has been comparatively slower. This is largely due to the complexities of understanding unstructured image data, which poses unique challenges.
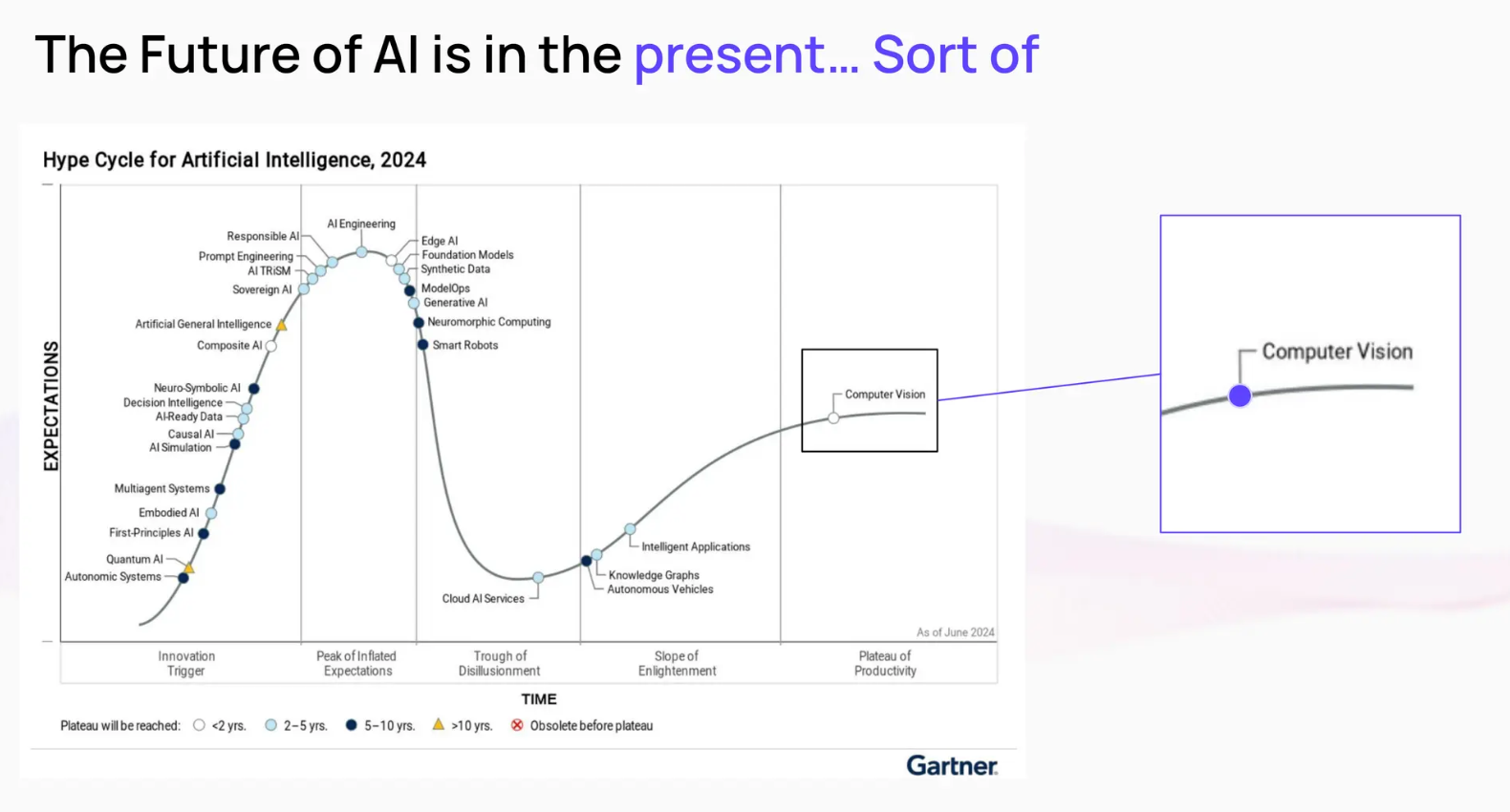 Figure: Developments in different spaces of AI over the past decade
Figure: Developments in different spaces of AI over the past decade
Alex highlights the three main pillars of AI: Data, Models, and Compute. While there have been rapid advancements in model architectures—such as transformers, attention mechanisms, and large language models (LLMs) that can be fine-tuned for specific tasks—there has also been significant progress in hardware, particularly with the development of high-performance GPUs designed to train complex models. However, despite these strides in models and compute power, data quality continues to lag behind, remaining in its early stages of maturity.
 Figure: Pillars of AI
Figure: Pillars of AI
Why Data Quality Matters for AI
Text-based models trained on noisy or unclean datasets often generate outputs with logical errors or even nonsensical characters. Similarly, image models, such as some diffusion-based ones, have been known to produce visuals with unexpected artifacts, like watermarks. The root cause? Poor data curation.
 Figure: Data cleaning vs data curation
Figure: Data cleaning vs data curation
To clarify, data curation refers to organizing, managing, and preparing data for labeling or model training, ensuring it’s relevant and structured for the specific task. Data cleaning focuses on identifying and correcting errors or inconsistencies in the data, such as removing duplicates, fixing corrupt samples, or addressing noise. Both processes ensure that only high-quality, reliable data is used in model training.
Cleaning and refining training data at scale is a major challenge. Take, for instance, the task of training a multi-modal model using YouTube videos. With the sheer volume of data, some clips may contain corrupted audio, inappropriate language, or irrelevant content. Without rigorous data curation, these issues can degrade the performance and reliability of the AI models.
Effective data curation involves meticulously filtering and analyzing datasets to ensure that only high-quality, appropriate data is fed into the models. Alex emphasizes that the principle "great data equals great models" is particularly true in generative AI. For domain-specific applications, such as detecting weld defects in industrial settings or aiding in surgical robotics, the training data must be highly relevant and precisely reflect the intended use cases. This level of curation helps the model to handle edge cases effectively and reduces the risk of failure.
During his presentation, Alex shared examples illustrating the importance of well-curated data. In one instance, a vision-based language model (VLM) like GPT-4 with vision failed to identify whether a school bus in an image was facing the front or rear. This failure highlights how even sophisticated models struggle without high-quality, curated data, reinforcing the necessity of comprehensive data curation and cleaning to improve model accuracy and performance.
 Figure: Vision-based LLMs have poor model performance due to noisy training data
Figure: Vision-based LLMs have poor model performance due to noisy training data
Data Curation for Domain-Specific Model Fine-Tuning
Now that we’ve learned the importance of data quality for AI performance, let’s explore an example demonstrating how data curation plays a vital role in fine-tuning models for specific domains.
LLaVA is a general-purpose large language model developed by Meta AI that is highly proficient in understanding human language. However, adapting it to more specialized fields, such as the medical domain, requires targeted data curation efforts. This fine-tuning process led to the creation of LLaVA-Med, a specialized AI assistant for medical applications.
Here are the key steps involved in this process:
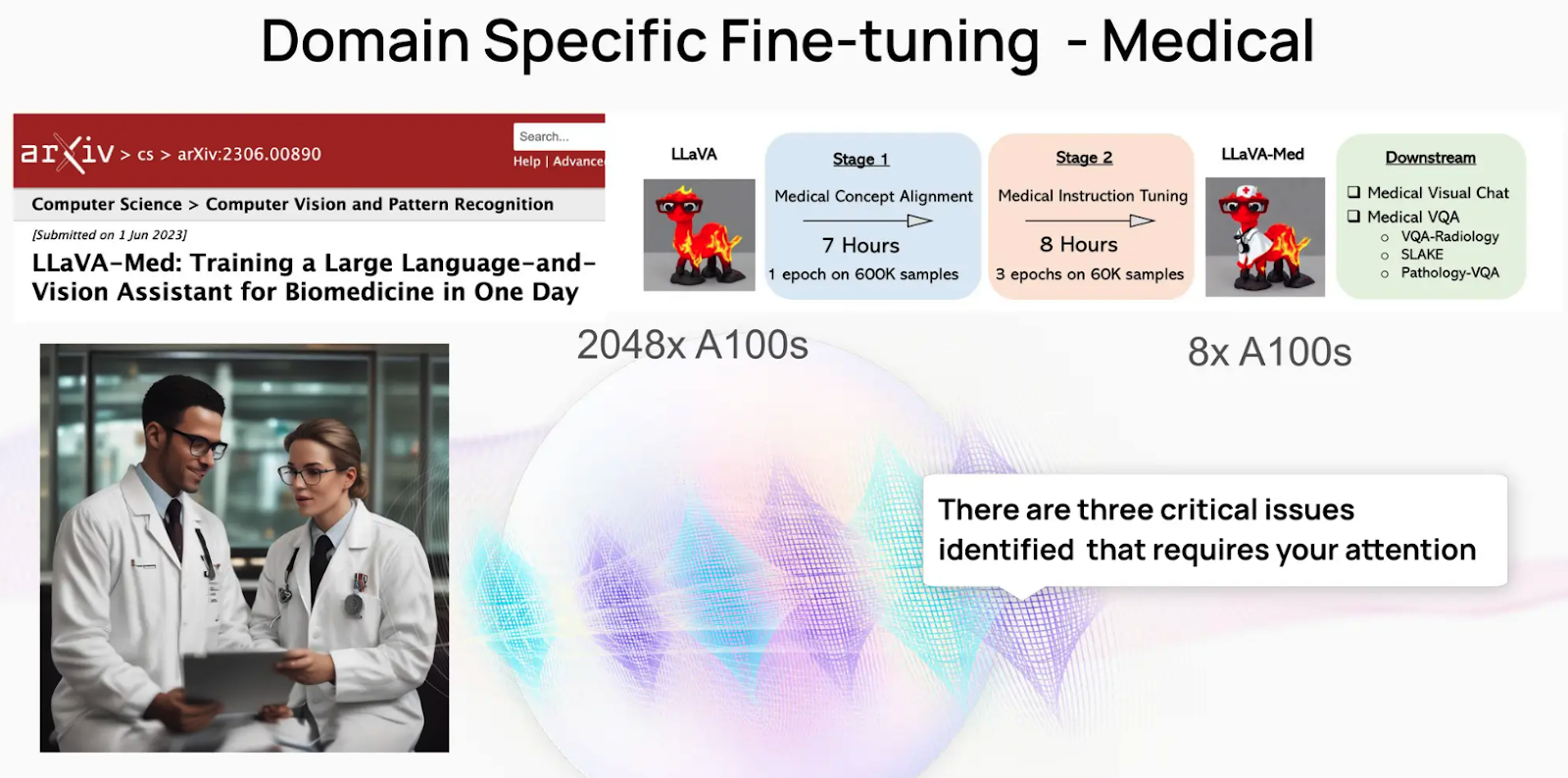 Figure: Fine-tuning LLM with medical knowledge
Figure: Fine-tuning LLM with medical knowledge
Medical Concept Alignment
The first fine-tuning stage used just 4% of the available dataset—600,000 image-text pairs sourced from textbooks and research papers. Considerable time and effort went into curating a well-balanced dataset to help the model learn essential medical concepts. This process involved a combination of human expertise and semi-automated techniques, ensuring that the curated data accurately reflected the medical domain's nuances.
Medical Instruction Tuning
In the second stage, the model was fine-tuned with 60,000 question-answer pairs to help it learn how to respond to medical queries. This phase enabled the model to understand input prompts, retrieve relevant information, and generate accurate responses based on medical context. The focus on instruction tuning improved the model’s ability to provide context-aware assistance in real-world medical situations.
By curating a smaller, high-quality dataset for training, the team could fine-tune LLaVA-Med efficiently and achieve accurate results—all while reducing training costs. This case study underscores the importance of data curation in developing domain-specific large language models (LLMs). It also highlights how meticulous curation and targeted fine-tuning can transform a general-purpose model into a specialized tool capable of shining in medical fields.
Evolving Trends in Data Quality & Curation
In traditional data pipelines, collected data would typically undergo manual annotation or pre-annotation using models with human oversight. Afterward, the annotated data would be used to train the model, which would then be deployed. While this linear approach may work for some scenarios, it falls short in specialized use cases, especially when dealing with vast amounts of unstructured data.
To address these challenges, Alex emphasizes the need for more flexible and robust data pipelines. Modern pipelines can incorporate additional stages for enhanced data curation. Once data is collected and stored in a data warehouse, external tools can be leveraged to verify, clean, and curate it before it proceeds to model training. These tools ensure data labeling quality after annotation, a critical step for refining the dataset.
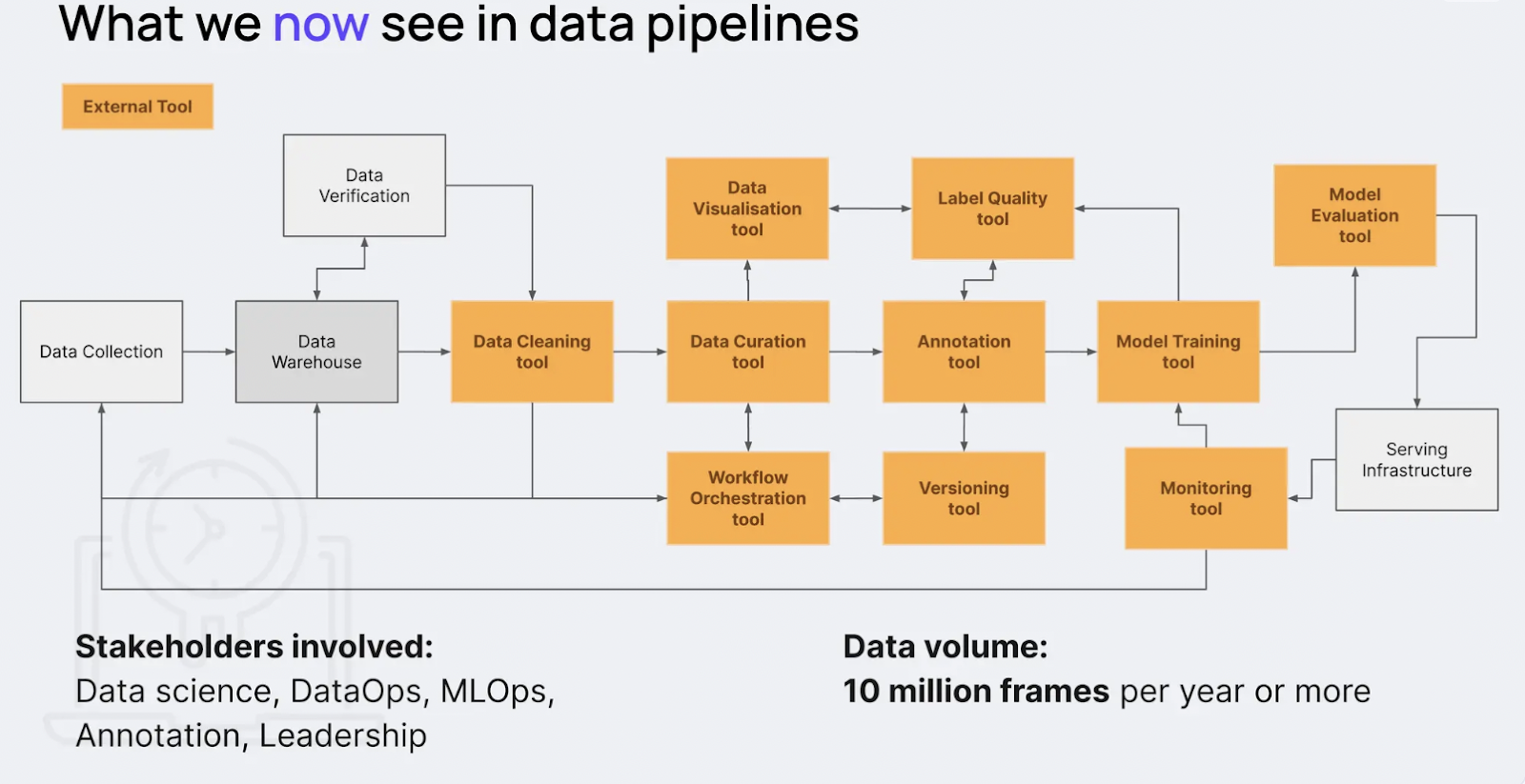 Figure- Data Curation & Validation tools in modern data pipelines
Figure- Data Curation & Validation tools in modern data pipelines
Additionally, Alex highlights the importance of setting up monitoring pipelines after model deployment. These pipelines allow for continuous evaluation and improvement, ensuring that the model adapts to new data and remains accurate. By refining the pipeline and implementing these additional steps, enterprises can enhance the quality of their data and improve model performance.
Common Challenges in Data Curation and Cleaning
Data curation and cleaning come with a range of challenges that can hinder the efficiency and accuracy of AI models:
Manual Data Review: Manually reviewing large datasets—such as scrolling through hours of video footage—is not only time-consuming but also prone to errors.
Ad-Hoc Approaches: Relying on makeshift solutions without a proper persistence layer often leads to inconsistencies and difficulties managing the data curation process effectively.
Data Quality Issues: Datasets frequently contain duplicates, corrupted samples, or noisy information, which can degrade model performance.
Cross-Modal Interactions: Analyzing the relationships between different data modalities (e.g., text, images, video) can be complex, requiring sophisticated tools and techniques to ensure accurate data representation and interaction.
How Organizations Can Overcome Data Curation Challenges
Alex shares the innovative approaches developed at Encord to tackle common data quality challenges such as duplicates, corrupted data, and noisy samples:
- Embeddings-Based Approaches: Unstructured data can be converted into high-dimensional vector embeddings through embedding models and stored in a vector database like Milvus. Organizations can quickly identify anomalies and outliers by visualizing embeddings in a low-dimensional space. This approach makes it easier to search, organize, and curate unstructured data.
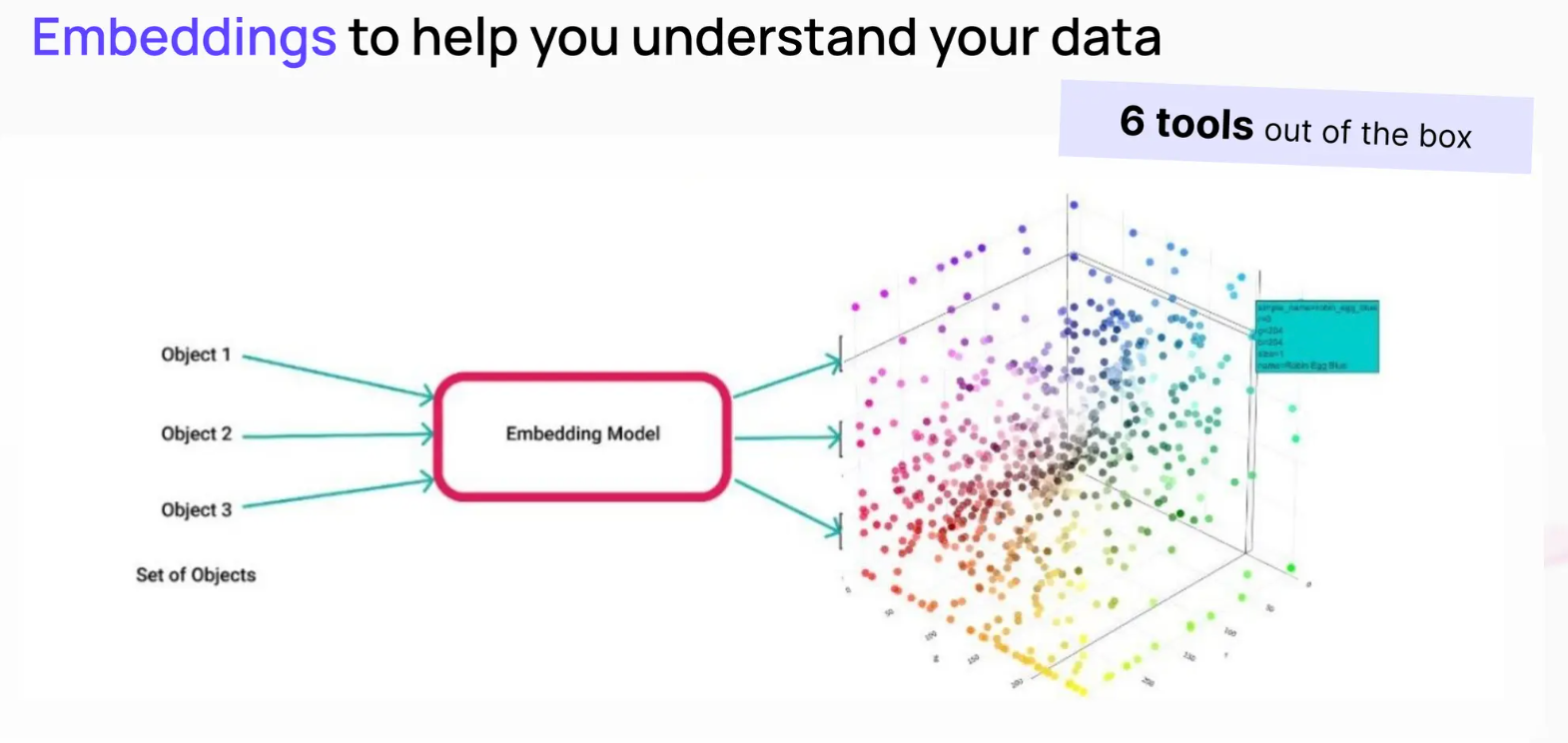 Figure: Using Embeddings to Visualize Training Data Samples
Figure: Using Embeddings to Visualize Training Data Samples
Data Quality Metrics: Metrics like blurriness, brightness, and embedding similarity can be used to assess the quality of image datasets in computer vision tasks, helping to flag and rectify issues before model training.
NLP for Data Curation: Natural language processing can filter and select only the most relevant data samples for training or testing, reducing noise and improving model accuracy.
Persistence Layers: Implementing a proper persistence layer is crucial for managing the data curation process, allowing for the consistent capture and storage of results.
Data Deduplication: Embedding-based similarity measurements help identify and remove duplicate samples, improving data quality and reducing storage needs. This also aids in finding similar data points for augmentation.
Metadata Validation: Automated tools validate metadata to ensure data integrity and detect corrupted samples. Encord offers specific tools designed for this task, streamlining the process.
Data Cleaning: Techniques like outlier detection, imputation, and normalization can address noise in datasets, ensuring the data is suitable for training high-performance models.
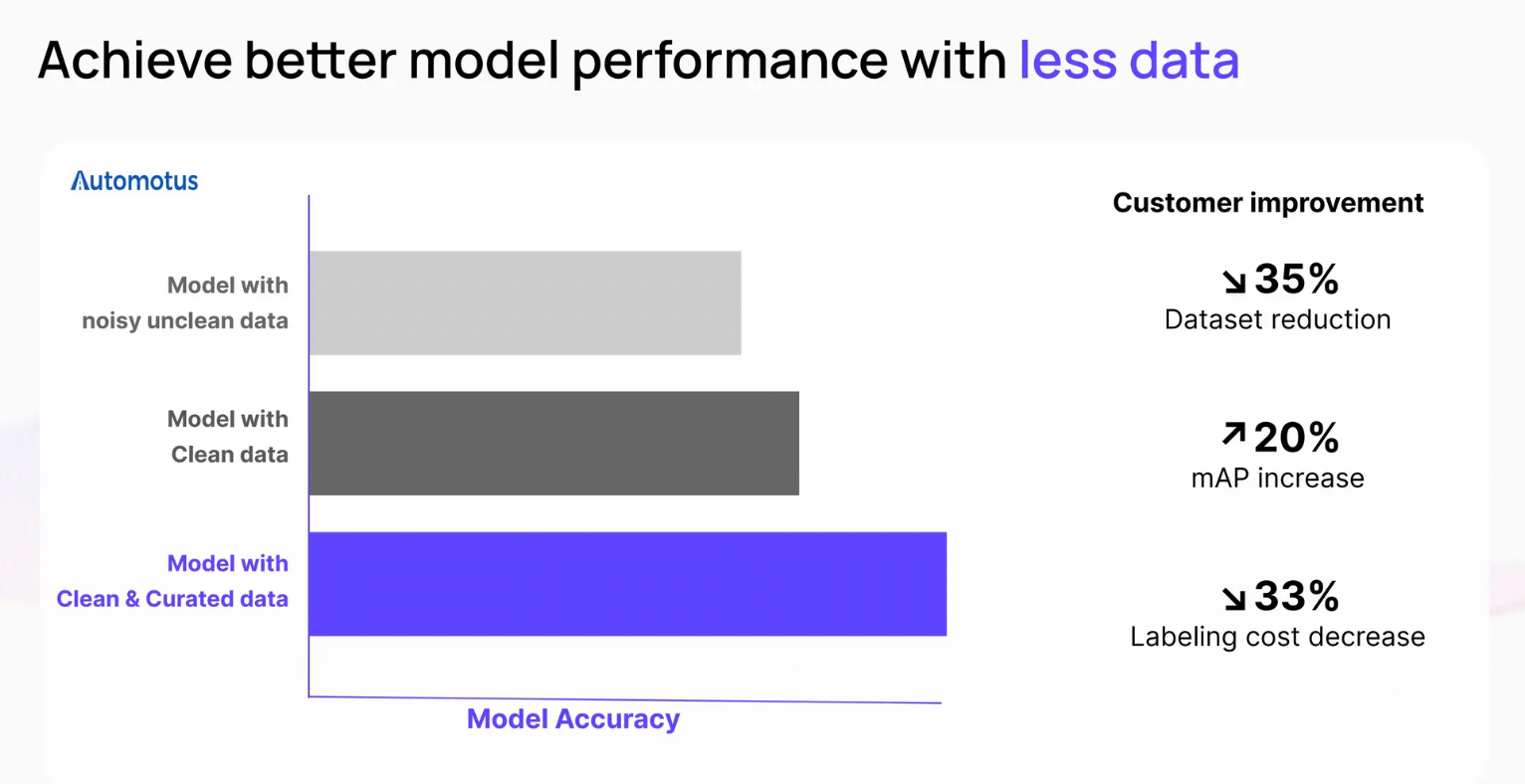
Benefits of Effective Data Curation and Cleaning
Improved model performance: High-quality data leads to more accurate and reliable models.
Reduced training time: Clean and curated data can accelerate the training process.
Lower costs: By avoiding the need for additional data collection and labeling, organizations can save money.
Enhanced model explainability: Well-curated data can improve the interpretability of model outputs.
Conclusion
Effective data curation becomes increasingly critical as AI applications grow more complex, particularly those that handle multiple data types like video and text. In Alex's talk, we gain a deeper understanding of the various challenges associated with curating image and text datasets and how these issues directly impact model performance.
Techniques such as vector embeddings and NLP-based querying offer valuable tools for teams to better visualize their data, identify mislabeled or duplicate samples, and clean datasets more efficiently before model training. To ensure success, data science teams must select the appropriate embedding models tailored to their specific data types—whether it’s image or text embeddings—and leverage vector databases like Milvus to streamline data storage and search processes.
Ultimately, investing in high-quality data curation not only improves model performance but also reduces the risk of errors and enhances the overall efficiency of AI workflows.
Further Resources
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 ShriVarsheni R
ShriVarsheni R
Keep Reading

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.