




Transformers4Rec: Bringing NLP Power to Modern Recommendation Systems
Introduction
As digital commerce and online content consumption continue to surge, the demand for effective, personalized recommendation engines is higher than ever. Shoppers and streamers alike expect tailored recommendations, whether they're searching for products, movies, or music. However, traditional recommendation systems, which rely on collaborative or content-based filtering, use static historical data and often struggle to adapt to changing user preferences. To address these limitations, recommendation systems that leverage dynamic AI models that capture evolving user behavior have become essential and popular.
At a recent Unstructured Data Meetup hosted by Zilliz, Kunal Sonalkar, a Data Scientist at Nordstrom, shared insights on using Transformers4Rec to enable sequential and session-based recommendations to better serve users’ evolving needs. This blog post highlights key takeaways from Kunal’s presentation, with our perspective on the future of recommendation systems. You can also watch Kunal’s full talk on YouTube for more details.
What is Transformers4Rec?
Transformers4Rec is a powerful and flexible library designed for creating sequential and session-based recommendation systems with PyTorch. By integrating with Transformers, one of the most popular frameworks in natural language processing (NLP), Transformers4Rec bridges between NLP and recommender systems.
The following figure shows the use of the transformers4Rec library in a recommender system. The input data for the library is a sequence of user interactions—such as items a user browses or adds to their cart during a session. Transformers4Rec processes these interactions to make intelligent predictions on what the user might want next. For example, imagine a customer is browsing an online bookstore. They first look at several science fiction novels, add one to their cart, and later view a few related author pages. Transformers4Rec analyzes this sequence of actions and predicts the customer might be interested in another popular sci-fi title or a related fantasy novel.
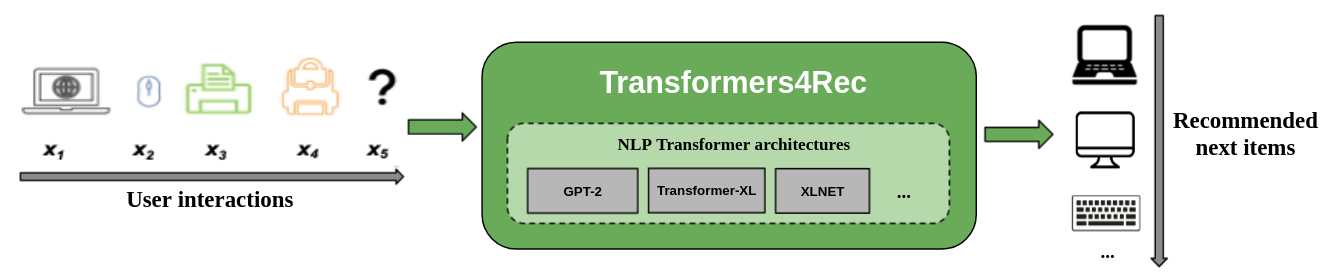 Figure- How Transformers4Rec works in a recommender system .png
Figure- How Transformers4Rec works in a recommender system .png
Figure: How Transformers4Rec works in a recommender system
Kunal highlights that to build an effective recommendation system, it’s essential to understand customer intent—such as the type of product they’re interested in and whether they’re price-sensitive—to tailor recommendations accordingly.
For instance, two customers searching for "shoes" may receive different recommendations based on their previous interactions and preferences, like budget or brand preference.
 shoes.png
shoes.png
Transformers4Rec Architecture
As we mentioned previously, Transformers4Rec’s architecture is designed to adapt transformer models for sequential and session-based recommendations by processing user interaction data in a structured way. Its architecture includes four main components that work together to make predictions: Feature Aggregation, Sequence Masking, Sequence Processing, and Prediction Head.
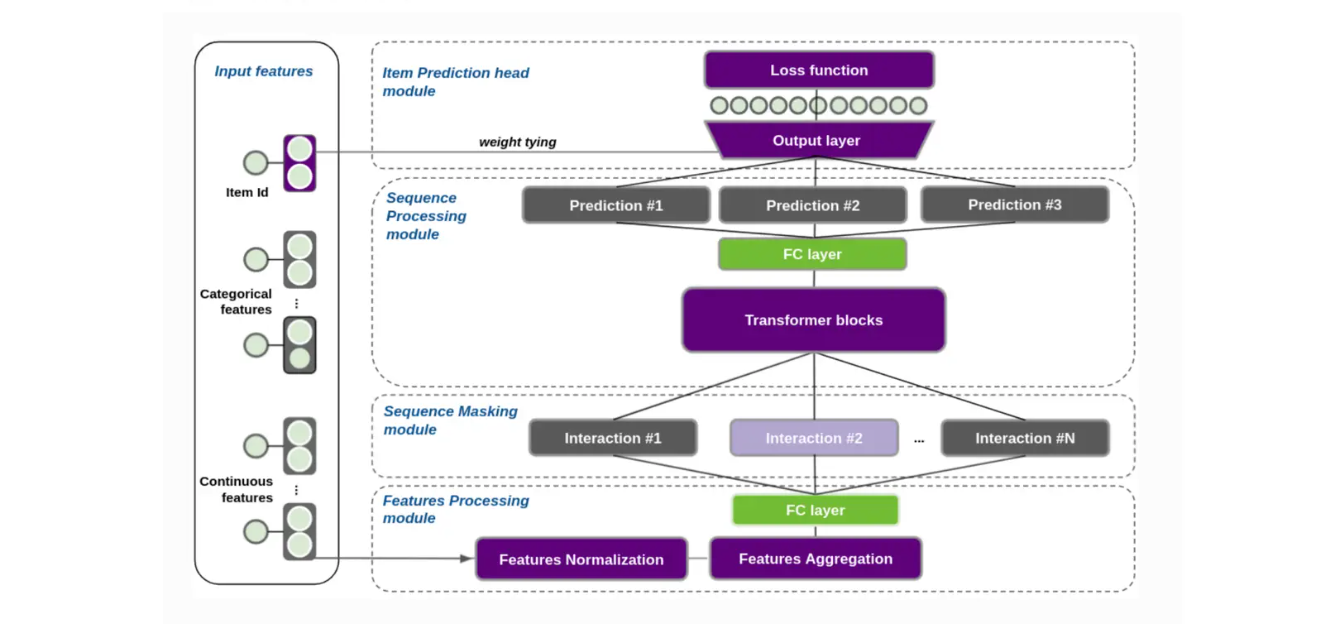 Figure- Transformers4Rec Architecture .png
Figure- Transformers4Rec Architecture .png
Figure: Transformers4Rec Architecture
Feature Aggregation
The Feature Aggregation component gathers data about user interactions—both continuous and categorical variables—to build a comprehensive profile for recommendation. For example, in an e-commerce recommendation system, categorical features might include attributes like brand and product type, while continuous features might capture price, discount rates, or recent interactions (e.g., the number of clicks on a product in the last 24 hours).
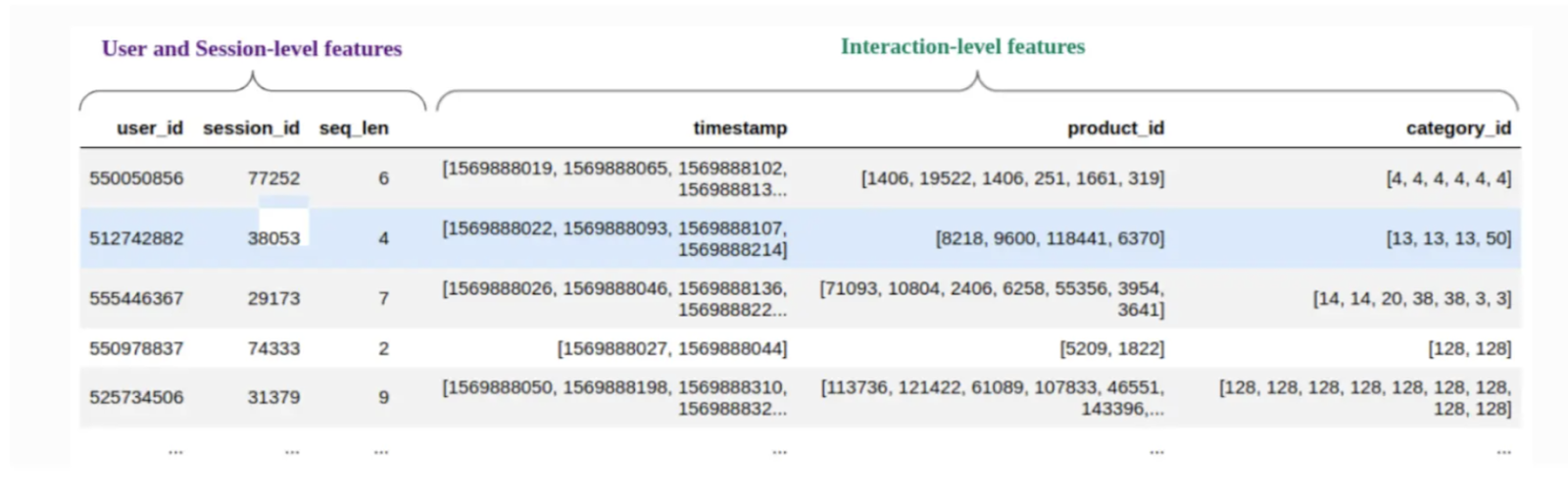 Figure- Feature Aggregation in Transformers4Rec.png
Figure- Feature Aggregation in Transformers4Rec.png
Figure: Feature Aggregation in Transformers4Rec
Before feeding these sequences into a transformer block, the interaction data needs to be pre-processed into a standardized format called vector embeddings (numerical representations of interaction data in a high-dimensional space). Inputs can be organized by user ID or session ID, with the sequence of interactions aggregated into a single vector representation, known as an "interaction embedding." This embedding contains contextual information about user interactions, such as the type of user actions, items involved, and interaction order, and can be stored in a vector database for efficient retrieval and semantic search. A robust vector database like Milvus or its managed service Zilliz Cloud, which integrates well with PyTorch, can streamline this process. Additionally, Transformers4Rec includes an NVTabular module to easily convert raw data into the required format, making data preparation more manageable.
Sequence Masking
The Sequence Masking component in Transformers4Rec applies masks to user interactions to prevent data leakage and maintain sequence order, ensuring the model respects the timeline of events. For instance, when predicting a user’s next item, this module hides any future actions, allowing the model to learn in a causal, step-by-step manner.
Different types of sequence masking in Transformers4Rec control what the model "sees" during training or inference, which helps it capture meaningful patterns in user behavior and improves its ability to predict the next interaction. Transformers4Rec provides multiple options in sequence masking:
Causal Language Modeling (CLM): This technique masks future items in a sequence, training the model to predict each item based only on prior items. CLM is ideal for sequential recommendations where the order of interactions is crucial.
Masked Language Modeling (MLM): In MLM, certain positions in the sequence are randomly masked, and the model learns to predict the hidden items using the surrounding context. This technique helps the model understand item relationships without depending on strict order.
Random Token Detection (RTD): RTD replaces a random item in the sequence with an unrelated one, and the model learns to spot this incorrect item. This method teaches the model to distinguish genuine patterns from random noise or anomalies.
Permutation Language Modeling (PLM): Here, items in the sequence are shuffled, and the model is trained to predict items in the new, permuted order. PLM encourages flexibility by helping the model recognize patterns in any order.
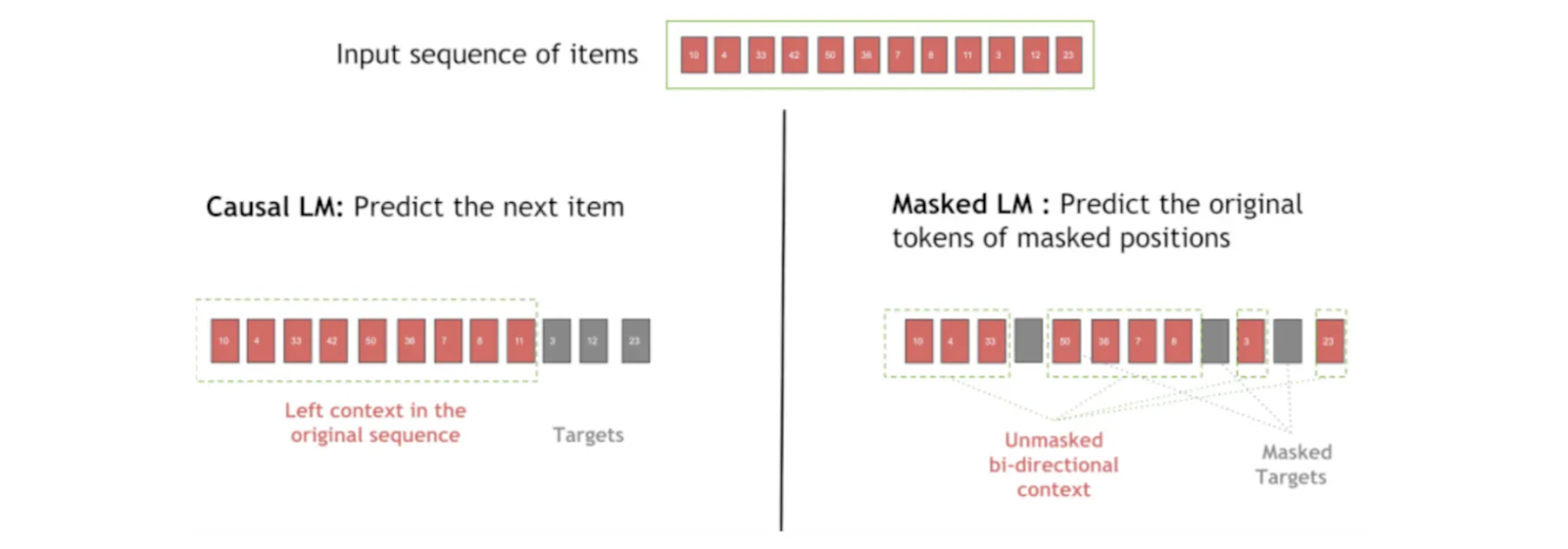 Figure- Difference in Casual LM and Masked LM during Sequence Masking.png
Figure- Difference in Casual LM and Masked LM during Sequence Masking.png
Figure: Difference in Casual LM and Masked LM during Sequence Masking
Usually, 20-30% of the positional embeddings are masked before training. The masking probability also plays a role in the robustness of the recommendation system.
These masking techniques allow the model to learn from user interactions in various ways, enhancing its ability to make accurate, context-aware recommendations.
Sequence Processing
The Sequence Processing component feeds input features to transformer models to predict masked items or positions in a user’s interaction sequence. Transformers4Rec supports various architectures for sequence processing, including XLNet, GPT-2, and LSTM, allowing users to choose the most suitable model for their recommendation system.
The interaction vector embeddings are passed into the transformer block, as illustrated in the code snippet below. Users can configure the transformer’s architecture by specifying parameters such as the number of layers and the sequence length. A sequential block in PyTorch can be created by passing the aggregated inputs, applying masking, and enabling the desired model configuration, enabling flexible setup for tailored recommendation tasks.
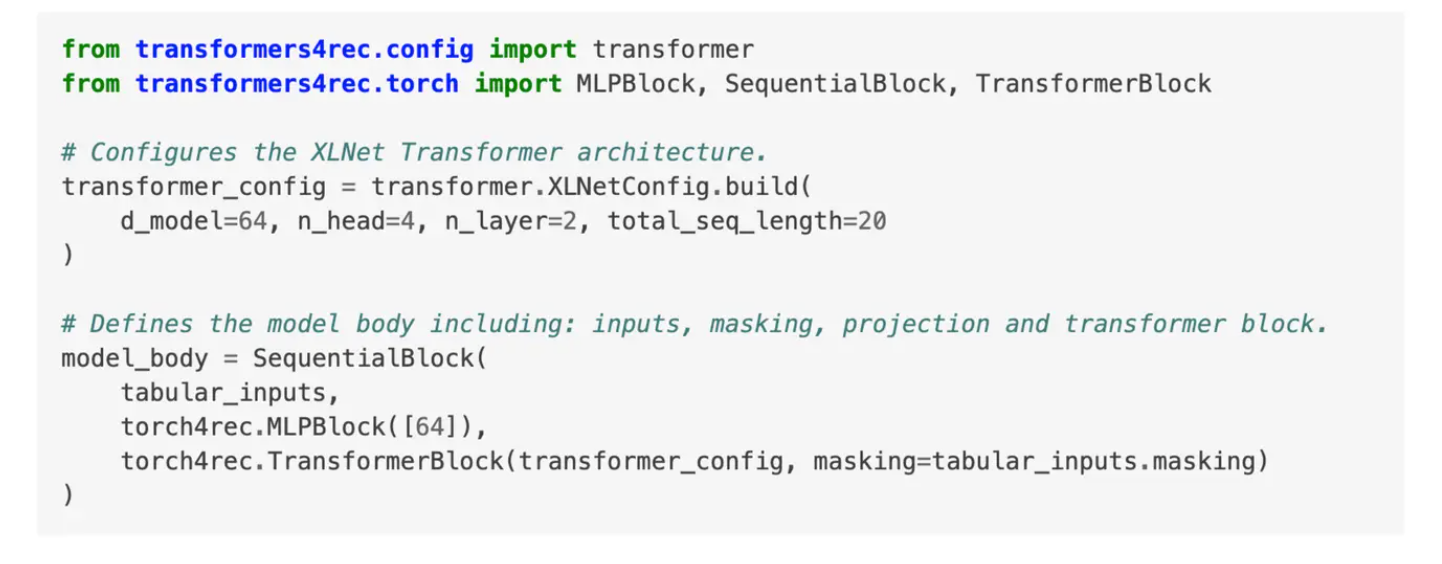 Sequence processing in Pytorch .png
Sequence processing in Pytorch .png
Fig) _Sequence processing in Pytorch_
Prediction Head
The Prediction Head is the final module in the Transformers4Rec framework, where outputs from the transformer model are used to generate actionable recommendations.
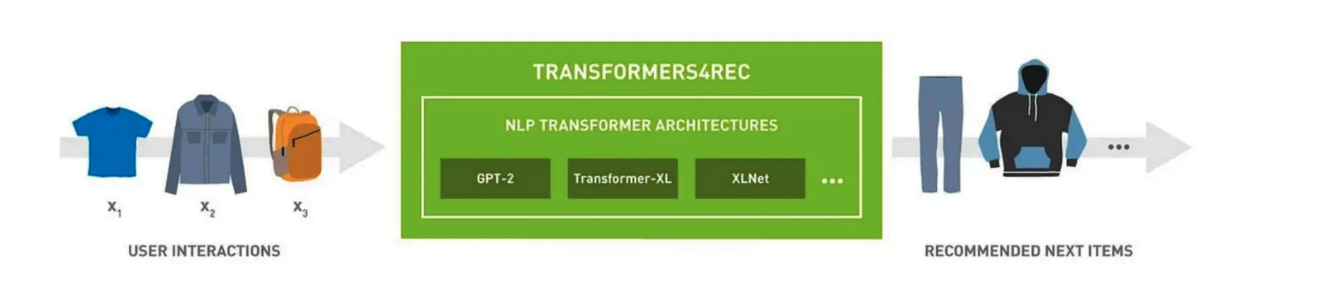 Figure- Outputs from the transformer model are used to generate actionable recommendations. .png
Figure- Outputs from the transformer model are used to generate actionable recommendations. .png
Figure: Outputs from the transformer model are used to generate actionable recommendations.
This module supports various use cases tailored to business needs, including:
Next Item Prediction: This option predicts the next item a user is likely to interact with based on their previous actions, helping deliver timely and relevant recommendations.
Binary Classification: Here, the model calculates the probability that a user will click on a specific item. This is valuable for click-through rate (CTR) prediction, as it helps determine which items are most likely to engage users, aiding in layout and content optimization.
Regression: Regression tasks enable the prediction of continuous values, such as the time a user might spend on an item, the number of interactions expected, or even an estimated purchase amount.
The diagram below illustrates the end-to-end production pipeline, including all four components—Feature Aggregation, Sequence Masking, Sequence Processing, and the Prediction Head—working together to deliver accurate and context-aware recommendations.
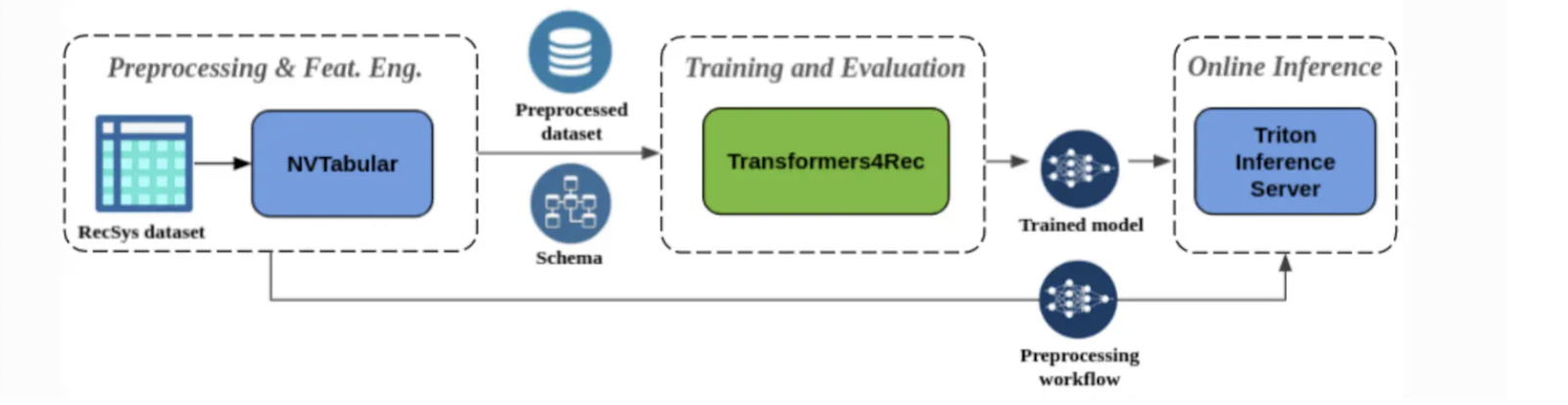 Figure- End-to-End pipeline of a recommendation system built using Transformers4Rec.png
Figure- End-to-End pipeline of a recommendation system built using Transformers4Rec.png
Figure: End-to-End pipeline of a recommendation system built using Transformers4Rec
Evaluation and Challenges for Using Transformers4Rec
Building a recommendation system with Transformers4Rec requires both effective evaluation and strategic planning to overcome scalability and maintenance challenges.
System Evaluation
The effectiveness of a recommendation system depends largely on how accurately it meets user needs. For Transformers4Rec, common evaluation metrics include precision and recall, which measure how well the system’s top ‘N’ recommendations align with user preferences. Additionally, ranking metrics like Mean Average Precision (MAP) and Normalized Discounted Cumulative Gain (NDCG) are also used to assess the relevance and order of recommended items.
Challenges
Scaling a recommendation system powered by Transformers4Rec comes with significant computational costs, particularly when deploying at large scale with GPU resources. Building and maintaining such a system also demands extensive infrastructure, covering everything from data collection and storage to model deployment and real-time inference.
Choosing the right infrastructure is crucial to creating a system that can quickly retrieve relevant recommendations. For example, using a vector database like Milvus allows for fast similarity searches and efficient storage of vector embeddings, which integrate well into the recommendation pipeline.
Another key challenge is handling new or frequently changing product catalogs. Transformers4Rec needs to provide accurate recommendations for these new items, even with limited historical data. This requires adaptability in both the model and the data infrastructure to update recommendations based on fresh context.
Summary
In this blog, we discussed how Transformers4Rec uses NLP-inspired techniques to create dynamic, personalized recommendation systems. With components like Feature Aggregation, Sequence Masking, Sequence Processing, and the Prediction Head, the framework captures complex user patterns to deliver real-time, relevant recommendations. Key metrics, including precision, recall, MAP, and NDCG, help evaluate system effectiveness, ensuring recommendations meet user needs.
We also discussed the challenges of scaling Transformers4Rec, particularly around infrastructure costs and storage needs, where tools like the Milvus vector database support efficient vector storage and retrieval. Fine-tuning parameters, such as vector dimensions and sequence length, is a key technique that optimizes model performance, making Transformers4Rec a flexible and powerful solution for modern recommendation systems.
Further Reading
Keep Reading

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.