




RocketQA: Optimized Dense Passage Retrieval for Open-Domain Question Answering
Imagine asking, “Who invented electricity?” and expecting a system to pinpoint the most relevant passage from billions of unstructured documents spanning diverse topics and formats. This shows the challenge of open-domain question answering (QA), where systems must quickly retrieve and rank relevant information from large, uncurated datasets like Wikipedia or web archives. Early QA systems tackled this challenge through intricate pipelines for tasks like question analysis and document retrieval. Later, the two-stage approach simplified the process by retrieving passages and extracting precise answers using dense retrieval techniques.
Dense retrieval, which uses dual-encoder architectures, represents questions and passages as dense embeddings for efficient semantic matching. However, training these models introduces several challenges, including discrepancies between training and inference, mislabeled positives, and limited annotated datasets. To address these obstacles, RocketQA, introduced in the paper Optimized Training of Dense Retrieval Models with Hard Negatives, presents a series of strategies, including cross-batch negatives, denoising hard negatives, and data augmentation. These methods improve the robustness of dual-encoder training and enhance passage retrieval accuracy.
This article will discuss RocketQA’s contributions to dense retrieval for open-domain QA, including its architecture and training strategies.
Understanding the Challenges of Open-Domain QA
Open-domain QA systems aim to answer user queries by finding the most relevant passage from a massive corpus of documents. These documents are typically divided into smaller passages to make searching and retrieval more efficient. For each relevant passage retrieved, the system must also identify the exact span of text that answers the question.
This task is particularly challenging due to the size and complexity of the data. Systems must balance three key aspects: ensuring speed for real-time retrieval, maintaining precision to identify the most relevant passages accurately, and maximizing recall to avoid missing important information. Striking this balance is essential for effective open-domain QA.
Dense retrieval systems have made significant strides in addressing these challenges by focusing on semantic matching rather than relying solely on keyword-based approaches. However, while they improve efficiency and accuracy in certain areas, they also face specific obstacles that limit their performance.
Gaps in Traditional Dense Retrieval
Dense retrieval systems face several key limitations:
Training vs. Real-World Discrepancy: Models are often trained on small, curated datasets, while real-world systems must handle billions of passages. This mismatch reduces their ability to perform consistently across larger, more complex datasets.
Sparse Annotations: Many QA datasets have limited labeled data, often pairing queries with only one or two positive passages. This leads to false negatives during training, where relevant passages are incorrectly treated as irrelevant.
Hard Negatives: These systems often struggle with passages that seem relevant but do not actually answer the query. For example, a query about “Who discovered electricity?” might retrieve passages about Benjamin Franklin’s experiments that are related but incorrect. If such passages are mismanaged during training, they can confuse the model and lower retrieval accuracy.
Let’s see how RocketQA addresses these challenges by introducing techniques that improve training strategies and refine how models handle data.
What is RocketQA?
RocketQA is a highly optimized dense passage retrieval framework designed to enhance open-domain question-answering (QA) systems. Developed by Baidu, RocketQA employs a dual-encoder model architecture for retrieving relevant passages, where the query and document encoders are trained collaboratively to improve retrieval performance. The framework introduces innovative training techniques, such as cross-batch negative sampling and denoising, which address common challenges like sparse negative samples and noisy training data.
How RocketQA Improves Dense Retrieval
RocketQA builds on the dual-encoder architecture, which enables efficient semantic matching by precomputing dense embeddings for questions and passages. The dual encoder consists of two separate encoders:
Question Encoder (Eq(q)): Transforms the query into a dense vector representation.
Passage Encoder (Ep(p)): Transforms each passage into a dense vector representation.
The similarity between a question and a passage is calculated as the dot product of their embeddings:
sim(q, p) = Eq(q) ⋅ Ep(p)
This precomputed structure allows for fast retrieval, as the embeddings of all passages can be stored in an index and reused for multiple queries. However, while dual-encoders offer scalability, their performance in capturing nuanced relationships between queries and passages is limited.
To address this, RocketQA incorporates cross-encoders to improve the quality of training. Cross-encoders process a query and passage together, allowing for richer contextual interactions. By combining the scalability of dual-encoders with the refinement of cross-encoders, RocketQA achieves a balance between efficiency and accuracy. Here is how dual encoders and cross-encoders work.
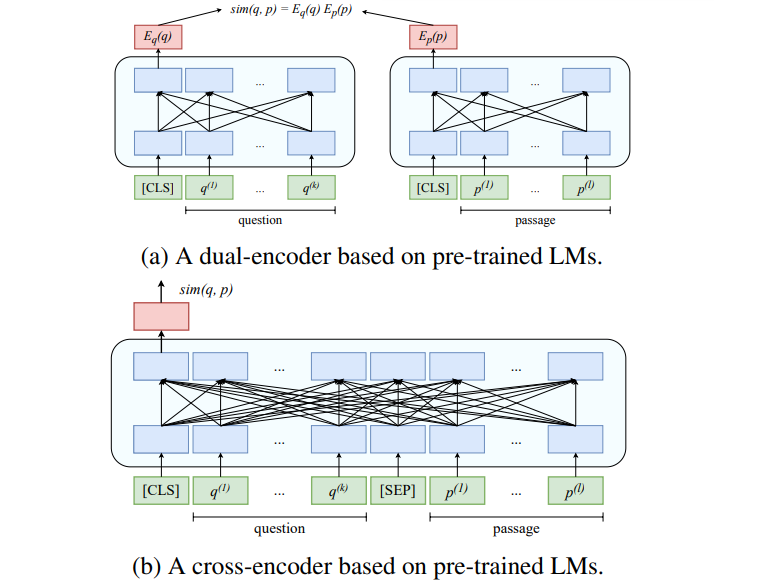
Figure: Illustration of the dual-encoder and cross-encoder architectures
The dual-encoder independently encodes the query and the passage into dense embeddings. For example, the query “Who invented electricity?” is encoded into a vector representation based on its semantic meaning, while passages like “Michael Faraday made major contributions to electromagnetism” and “Benjamin Franklin’s kite experiment” are also encoded into vectors. The system compares these vectors to determine which passage is most similar to the query. This process is highly efficient because the passage embeddings can be precomputed and reused.
In contrast, the cross-encoder processes the query and passage together. Instead of encoding them separately, it examines the relationship between the two. For instance, when evaluating the same query and passages, the cross-encoder can better understand that the passage mentioning Benjamin Franklin’s kite experiment is related to electricity but doesn’t answer the query directly. This richer understanding comes at the cost of computational efficiency, making it more suitable for fine-tuning and generating training data.
Smarter Sampling with Cross-Batch Negatives
One of the challenges in dense retrieval is training models with a diverse set of negative examples (passages that do not answer the query). Traditional approaches use in-batch negatives, which are limited to the passages within the same batch. RocketQA addresses this limitation by introducing cross-batch negatives, which share negative examples across multiple GPUs during training.
This approach greatly expands the pool of negative samples, making it more representative of real-world scenarios. By exposing the model to more diverse and challenging negatives, RocketQA reduces overfitting and enhances its ability to distinguish between relevant and irrelevant passages.
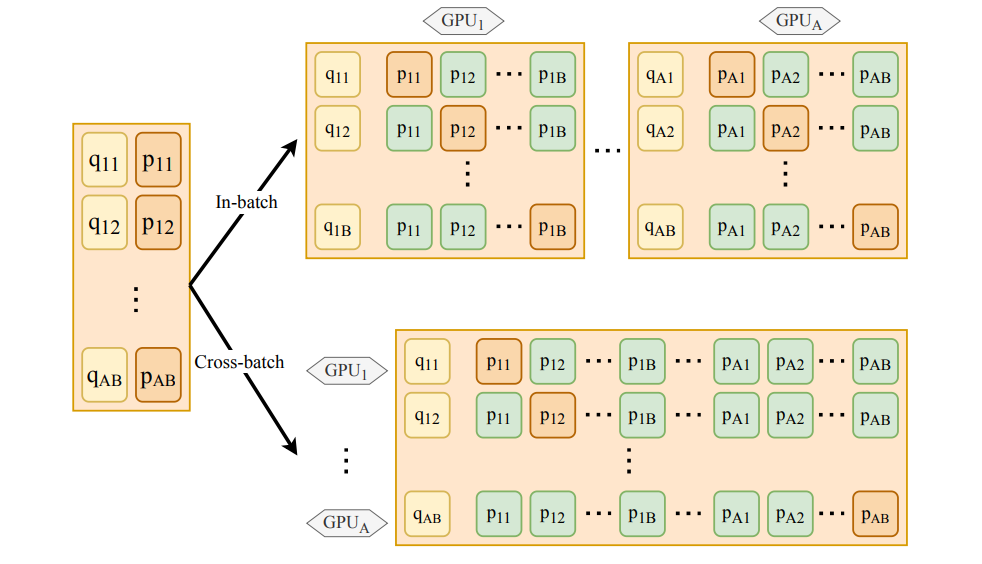
Figure: Comparison of in-batch vs. cross-batch negatives in multi-GPU training, where A is the number of GPUs and B is the batch size.
Unlike traditional methods that restrict negative sampling to the batch level, RocketQA enables each question to be paired with negatives from other batches, increasing diversity without requiring additional memory.
Optimized Training Objective
The training process in RocketQA focuses on improving the model's ability to identify relevant passages for a given query by optimizing a loss function. This loss function encourages the model to assign higher similarity scores to positive query-passage pairs (relevant passages) and lower scores to negative query-passage pairs (irrelevant passages).
The loss function is expressed as:
L(qi, p⁺i, {p⁻i,j}) = - log ( exp(sim(qi, p⁺i)) / ( exp(sim(qi, p⁺i)) + Σj=1^m exp(sim(qi, p⁻i,j)) ) )
Here’s how the optimization works:
Positive Passages (p⁺i): For each query qi, the model identifies a positive passage labeled as relevant. The objective is to maximize the similarity score sim(qi, p⁺i), which measures how closely the query and the positive passage align.
Negative Passages (p⁻i,j): For the same query qi, multiple negative passages (irrelevant to the query) are introduced. The model is trained to assign these passages lower similarity scores sim(qi, p⁻i,j).
Balancing the Scores: The denominator of the loss function includes the similarity scores of both positive and negative passages. By minimizing this loss, the model learns to increase the similarity score of the positive passage relative to the negative passages.
Visualizing the Process: Think of this optimization as reshaping the semantic space. The embeddings of relevant passages are pulled closer to the query in the semantic space, while the embeddings of irrelevant passages are pushed farther away.
Ranking Improvement: The result of this optimization is a model that ranks positive passages higher than negatives for a given query, improving the system's ability to retrieve relevant information accurately.
By optimizing this loss function, RocketQA ensures that its dense retrieval model is more effective at distinguishing relevant passages from irrelevant ones, even in scenarios where the negatives are contextually similar. This improvement directly enhances the precision and recall of the retrieval system, enabling better performance in open-domain QA tasks.
Training RocketQA: A Four-Stage Optimization Pipeline
RocketQA’s training process is implemented through a structured four-stage pipeline that systematically refines the dual-encoder to improve its retrieval capabilities. Each stage builds on the previous one to address the key challenges we discussed such as handling hard negatives, diversifying training examples, and compensating for sparse annotations.
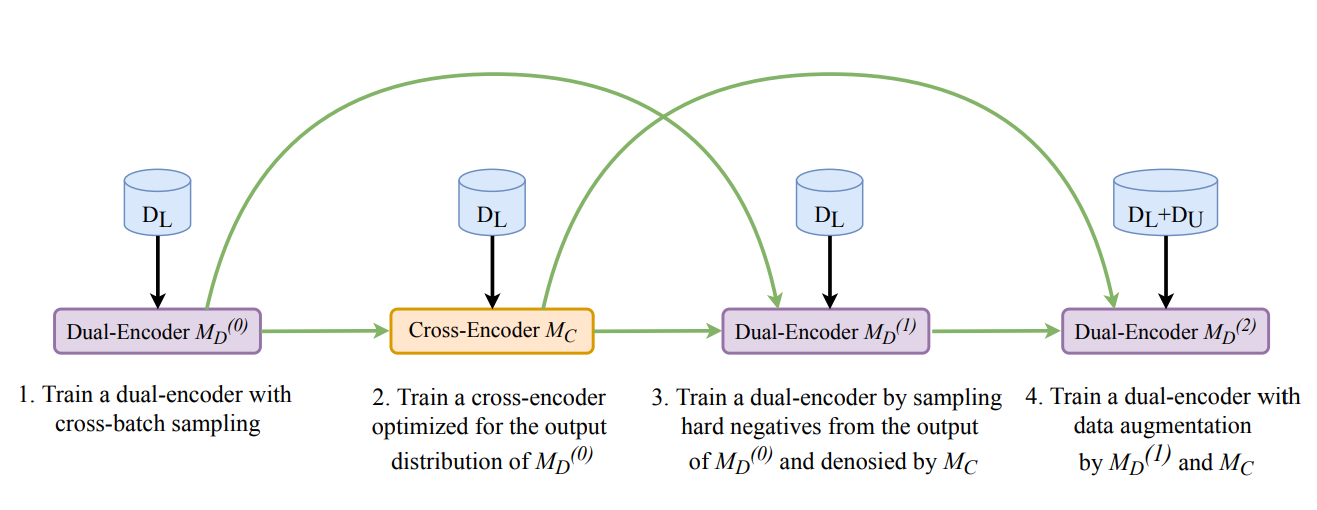
Figure: The four stages of RocketQA’s training pipeline:
Here is what each stage entails:
1. Cross-Batch Negative Sampling
The dual-encoder is first trained using cross-batch negatives, which share negative passages across GPUs. This increases the diversity of negatives available for training, helping the model simulate real-world conditions more effectively. By leveraging this technique, RocketQA exposes the model to harder negatives, refining its ability to differentiate between relevant and irrelevant passages.
2. Cross-Encoder Fine-Tuning
After initial training, a cross-encoder is fine-tuned to evaluate query-passage pairs with greater contextual understanding. The cross-encoder identifies challenging hard negatives, which are then used to refine the dual-encoder further. This step ensures that the dual-encoder benefits from the deeper relational insights of the cross-encoder.
3. Denoising Hard Negatives
The dual-encoder is retrained with denoised hard negatives curated by the cross-encoder. This process reduces noise in the training data by excluding mislabeled or less informative negatives. As a result, the model focuses on meaningful distinctions between relevant and irrelevant passages, improving precision.
4. Data Augmentation
In the final stage, the cross-encoder generates pseudo-labels to enrich the training dataset. These pseudo-labels help address the issue of sparse annotations by creating additional labeled data, allowing the dual-encoder to generalize better across diverse queries.
This structured process ensures that RocketQA effectively integrates the improvements discussed earlier into a cohesive and optimized workflow, ultimately enhancing its performance in dense retrieval tasks.
RocketQA’s Performance on Benchmarks
After optimizing its training pipeline, RocketQA demonstrates strong performance on various open-domain question answering (QA) benchmarks. These benchmarks evaluate how well RocketQA retrieves relevant passages across different datasets, each presenting unique challenges such as complex queries, sparse annotations, or misleading negatives.
It has been tested on MS MARCO, Natural Questions, and TriviaQA. MS MARCO focuses on pairing user queries with relevant and irrelevant passages, emphasizing retrieval accuracy. Natural Questions contains real user queries from Google Search, requiring systems to identify relevant passages from Wikipedia. TriviaQA poses trivia-style questions that often require contextual reasoning and deeper understanding to retrieve accurate answers.
It achieves a Mean Reciprocal Rank (MRR@10) of 37.0 on the MS MARCO dataset, outperforming other dense retrievers like DPR and ANCE, which scored 32.7 and 33.0, respectively. The model also performs well on the Natural Questions (NQ) dataset, reaching a recall rate (R@100) of 88.5, compared to ANCE's 87.5 and DPR's 85.4. These results show RocketQA has the ability to retrieve relevant passages with higher precision and recall after optimization.
Future Directions for RocketQA
RocketQA’s success on diverse benchmarks underscores its strength as a dense retrieval system. Yet, as open-domain question answering grows more complex, there are clear opportunities to refine its capabilities, address limitations, and expand its functionality to meet emerging challenges and use cases.
Multimodal Retrieval Integration
Expanding beyond text to include multimodal data such as images, videos, and structured data would allow RocketQA to handle richer and more diverse queries. For example, a query like Explain the information in this chart about global warming would require integrating visual and textual understanding. Combining modalities would make RocketQA applicable in areas such as medical diagnostics, scientific research, and multimedia search.
Context-Aware Personalization
Incorporating user-specific context into RocketQA’s retrieval process can improve result relevance. By embedding signals from user history or preferences, the model could tailor answers for individual needs. For instance, a student researching energy might prefer simplified explanations, while a domain expert would benefit from detailed, source-heavy results.
Domain-Specific Customization
Fine-tuning RocketQA on domain-specific datasets—such as legal documents or medical literature—could enhance its performance in specialized fields. Integrating with knowledge graphs would also improve accuracy by leveraging structured relationships (e.g., symptoms → diseases in healthcare). This approach would make RocketQA more effective in industries like law, medicine, and engineering.
Conclusion
RocketQA has redefined dense retrieval for open-domain question answering by overcoming challenges such as sparse annotations, hard negatives, and large-scale retrieval demands. Its combination of dual- and cross-encoder architectures, alongside strategies like cross-batch negatives and optimized training, delivers both scalability and precision.
With proven benchmark success and the potential to expand into multimodal retrieval, domain-specific applications, and personalized systems, RocketQA is poised to lead advancements in question-answering. As the demands of open-domain QA evolve, RocketQA provides a strong, adaptable foundation for tackling complex queries accurately and efficiently.
Further Resources
Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.