




Create a Movie Recommendation Engine with Milvus and Python
This article was originally published in The New Stack and is reposted here with permission.
Use open source tools to help people find movies they might be interested in watching.
Recommender systems or recommendation engines are information-filtering systems that aim to predict and suggest things users might be interested in. These items include products, services, and content such as movies, books, music, or news articles.
There are various types of recommender systems, such as collaborative filtering, content-based filtering, hybrid recommendation systems, and vector-based recommendation systems. Vector-based systems use the vector space to find (recommend) the closest items in the database. There are various ways to store these vectors; one of the most efficient ones is using the Milvus open source vector database. This database is highly flexible, fast and reliable and allows for trillion-byte-scale addition, deletion, updating, and nearly real-time search of vectors.
This article explains how to build a movie recommender with Milvus and Python. This system will use SentenceTransformers to convert the text information to vectors and store these vectors in Milvus. Milvus enables users to search for a movie in the database based on the text information they provide.
 Featured image by Tima Miroshnichenko on Pexels
Featured image by Tima Miroshnichenko on Pexels
Setting up the environment
For this article, you'll need the following requirements installed:
Python Package Manager (PIP) to install packages
Jupyter Notebook for writing code
A system with at least 32GB of RAM or a Zilliz Cloud account
Python requirements
You also need to install a set of libraries that will be needed throughout this tutorial. Install the libraries using PIP:
$ python -m pip install pymilvus pandas sentence_transformers kaggle
Vectors data store (Milvus)
You'll use the Milvus vector database to store the embeddings that you'll generate using movie descriptions. The dataset is relatively large, at least for a server running on a personal computer. So you may want to use a Zilliz Cloud instance to store these vectors.
If you prefer to stay with a local instance, you can download a docker-compose configuration and run it with:
$ wget https://github.com/milvus-io/milvus/releases/download/v2.3.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
$ docker-compose up -d
You now have all the requirements to build your own movie recommender system with Milvus.
Data collection and preprocessing
For this project, you'll use the Movies Dataset from Kaggle that contains metadata for 45,000 movies. You can download this dataset directly or use the Kaggle API to download the dataset using Python. To do so with Python, you need to download the kaggle.json file from the profile section of Kaggle.com and put it in a location where the API will find it.
Next, set up some environment variables for Kaggle authentication. For this, you can open the Jupyter Notebook and write the following lines of code:
%env KAGGLE_USERNAME=username
%env KAGGLE_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
%env TOKENIZERS_PARALLELISM=true
Once done, you can use Kaggle’s Python dependency to download the dataset from Kaggle:
# import kaggle dependency
import kaggle
kaggle.api.authenticate()
kaggle.api.dataset_download_files('rounakbanik/the-movies-dataset', path='dataset', unzip=True)
Once the dataset is downloaded, you can use the read_csv() method from pandas to read the dataset:
# import pandas
import pandas as pd
# read csv data
movies=pd.read_csv('dataset/movies_metadata.csv',low_memory=False)
# check shape of data
movies.shape
 Dataset Shape
Dataset Shape
The image shows that you have 45,466 records with 24 columns of metadata. Check all these metadata columns with:
# check column names
movies.columns
 Dataset Columns
Dataset Columns
There are a lot of columns you don't need to create the recommender system. You can filter out the required columns with:
# filter required columns
trimmed_movies = movies[["id", "title", "overview", "release_date", "genres"]]
trimmed_movies.head(5)
 Required Columns
Required Columns
Also, some of the fields in the data are missing, so get rid of those rows to produce a clean dataset:
unclean_movies_dict = trimmed_movies.to_dict('records')
print('{} movies'.format(len(unclean_movies_dict)))
movies_dict = []
for movie in unclean_movies_dict:
if movie["overview"] == movie["overview"] and movie["release_date"] == movie["release_date"] and movie["genres"] == movie["genres"] and movie["title"] == movie["title"]:
movies_dict.append(movie)
Connect to Milvus
Now that you have all the required columns, connect to Milvus to start uploading the data. To connect to the Milvus cloud instance, you'll need the Uniform Resource Identifier (URI) and token, which you can download from your Zilliz Cloud dashboard.
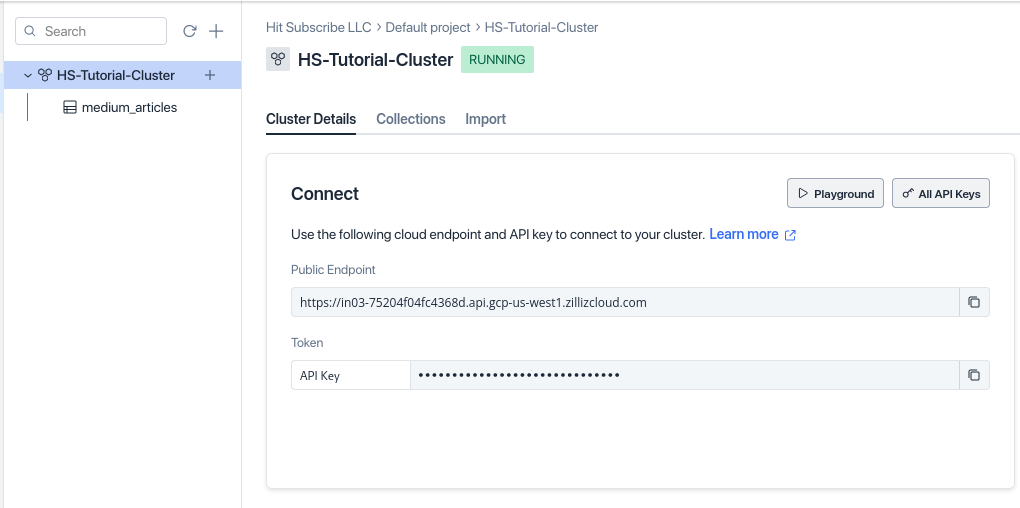 Zilliz Dashboard
Zilliz Dashboard
Once you have your URI and API key, you can use the connect() method from PyMilvus to connect to the Milvus server:
# import milvus dependency
from pymilvus import *
# connect to milvus
milvus_uri="YOUR_URI"
token="YOUR_API_TOKEN"
connections.connect("default", uri=milvus_uri, token=token)
print("Connected!")
Generate embeddings for movies
Now it's time to calculate the embeddings for the text data in the movie dataset. First, create a collection object that will store the movie ID and embeddings for the text data. Also create an index field to make searches more efficient:
COLLECTION_NAME = 'film_vectors'
PARTITION_NAME = 'Movie'
# Here's our record schema
"""
"title": Film title,
"overview": description,
"release_date": film release date,
"genres": film generes,
"embedding": embedding
"""
id = FieldSchema(name='title', dtype=DataType.VARCHAR, max_length=500, is_primary=True)
field = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=384)
schema = CollectionSchema(fields=[id, field], description="movie recommender: film vectors", enable_dynamic_field=True)
if utility.has_collection(COLLECTION_NAME): # drop the same collection created before
collection = Collection(COLLECTION_NAME)
collection.drop()
collection = Collection(name=COLLECTION_NAME, schema=schema)
print("Collection created.")
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
print("Collection indexed!")
Now that you have an indexed collection, create a function for generating the embeddings for the text. Although overview is the primary column used to generate the embeddings, you'll also use the genre and release data information along with an overview to make the data more logical.
To generate the embeddings, use the SentenceTransformer:
from sentence_transformers import SentenceTransformer
import ast
# function to extract the text from genre column
def build_genres(data):
genres = data['genres']
genre_list = ""
entries= ast.literal_eval(genres)
genres = ""
for entry in entries:
genre_list = genre_list + entry["name"] + ", "
genres += genre_list
genres = "".join(genres.rsplit(",", 1))
return genres
# create an object of SentenceTransformer
transformer = SentenceTransformer('all-MiniLM-L6-v2')
# function to generate embeddings
def embed_movie(data):
embed = "{} Released on {}. Genres are {}.".format(data["overview"], data["release_date"], build_genres(data))
embeddings = transformer.encode(embed)
return embeddings
This function uses the build_genres() method to clean the genre column and get the text out of it. Then it creates a SentenceTransformer object to help generate the embeddings from the text. Finally, it uses the encode() method to generate the embeddings using the overview, release_date, and genre features.
Send embeddings to Milvus
Now you can create the embeddings using the embed_movie() method. This dataset is too large to send to Milvus in a single insert statement, but sending data rows one at a time would create unnecessary network traffic and add too much time. So, instead create batches (e.g., 5,000 rows) of data to send to Milvus:
# Loop counter for batching and showing progress
j = 0
batch = []
for movie_dict in movies_dict:
try:
movie_dict["embedding"] = embed_movie(movie_dict)
batch.append(movie_dict)
j += 1
if j % 5 == 0:
print("Embedded {} records".format(j))
collection.insert(batch)
print("Batch insert completed")
batch=[]
except Exception as e:
print("Error inserting record {}".format(e))
pprint(batch)
break
collection.insert(movie_dict)
print("Final batch completed")
print("Finished with {} embeddings".format(j))
Note: You can play with the batch size to suit your individual needs and preferences. Also, a few movies will fail for IDs that cannot be cast to integers. You could fix this with a schema change or by verifying their format.
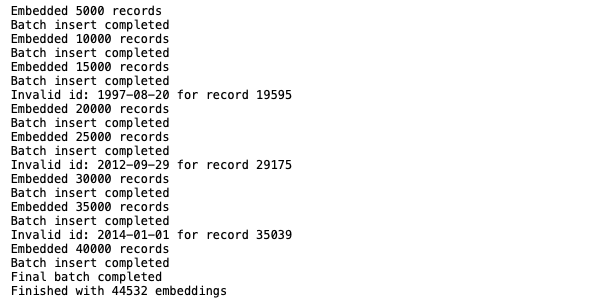 Send Embeddings to Milvus
Send Embeddings to Milvus
Recommend new movies using Milvus
Now you can leverage Milvus’ near real-time vector search functionality to get a close match of movies that meet the viewer's criteria. For this, create two different functions:
embed_search(): You need a transformer to convert the user's search string to an embedding. This function takes the viewer's criteria and passes it to the same transformer you used to populate Milvus.
search_for_movies(): This function performs the actual vector search using the other function for support.
# load collection memory before search
collection.load()
# Set search parameters
topK = 5
SEARCH_PARAM = {
"metric_type":"L2",
"params":{"nprobe": 20},
}
# convert search string to embeddings
def embed_search(search_string):
search_embeddings = transformer.encode(search_string)
return search_embeddings
# search similar embeddings for user's query
def search_for_movies(search_string):
user_vector = embed_search(search_string)
return collection.search([user_vector],"embedding",param=SEARCH_PARAM, limit=topK, expr=None, output_fields=['title', 'overview'])
The above code defines the parameters topK for getting the top five similar vectors, metric_type as L2 (squared Euclidean) that calculates the distance between two vectors and nprobe that indicates the number of cluster units to search. It also implements different functions to get similar vectors from the user's query (recommendation).
Finally, use the search_for_movies() function to recommend movies based on the user's search string:
from pprint import pprint
search_string = "A comedy from the 1990s set in a hospital. The main characters are in their 20s and are trying to stop a vampire."
results = search_for_movies(search_string)
# check results
for hits in iter(results):
for hit in hits:
print(hit.entity.get('title'))
print(hit.entity.get('overview'))
print("-------------------------------")
 Recommend Movies
Recommend Movies
By using Milvus's vector search feature, the code recommends the top five similar movies based on the user's query. This is it: You have now built your own movie recommender system using Milvus.
Conclusion
After reading this article, you know what a vector-based recommendation system is and how to create a movie recommender system with Milvus. Milvus helps build an efficient and scalable movie recommendation system. Leveraging vector storage and similarity search, Milvus has great potential for enabling personalized recommendations, enhancing user engagement and showcasing the role of advanced vector-based models in modern recommendation systems. You can learn more about it on the Milvus website.

Keep Reading

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.