




Training Text Embeddings with Jina AI
Recently, we heard from Bo Wang at the Berlin Unstructured Data Meetup about training state state-of-the-art general text embeddings. Text embeddings already power up modern vector search and Retrieval-Augmented Generation (RAG) systems. Wang helps us understand the intricacies of developing state-of-the-art text embeddings with the main focus on Jina embeddings.
Watch the replay of Bo Wang’s talk on Youtube
Why Should You Care about Jina Text Embeddings?
The release of Jina-Embeddings-V2 made waves in the AI community, garnering over 3 million downloads on Hugging Face. This model has been integrated into numerous AI frameworks such as LangChain and LlamaIndex, and vector databases like Milvus and Zilliz Cloud. The buzz around Jina embeddings even reached the top of Hacker News, sparking extensive debates and discussions about long-context encoders. Jina embeddings closely compete with OpenAI embeddings, one of the industry's finest.
With that in mind, let's dig into Wang’s talk about the intricacies of developing Jina text embeddings.
Evolution from Fine-Tuning to Training Embedding Models at Scale
Jina AI did not start by training its own embedding model. Instead, it began by fine-tuning already existing models such as BERT. The fine-tuned models performed better than the existing ones. Let’s take a look at the statistics. The delta value at the end represents how well the fine-tuned model performs compared to the original pre-trained model.
 Performance Comparison between pre-trained and fine-tuned models
Performance Comparison between pre-trained and fine-tuned models
As you can see, all the fine-tuned models improved significantly, implying that the algorithm worked well. But was the product well received by the tech industry? The simple answer is no.
This was when the industry, even the search industry, was slowly moving towards vectors and had just started using pre-trained embedding models. However, they were not ready for fine-tuning embedding models. Embedding models were not widely adopted in other industries either, as no LLMs or RAG systems existed.
So, while fine-tuning allowed Jina AI to achieve incremental improvements, they soon realized that the industry was unprepared for fine-tuning techniques. This realization prompted them to embark on an ambitious endeavor: training their embedding model from scratch. They believed that developing a homegrown solution would enable them to push the boundaries of what was possible.
Creating Jina-Embeddings-V1
Creating Jina-Embeddings-V1 involved following a comprehensive approach. Wang takes us through the approach used:
Researching state-of-the-art models: The first step is studying cutting-edge embedding models, including minilm, mpnet, sentence-t5, GTR, and instructors from tech giants like Microsoft and Google. This approach helps in understanding the strengths and limitations of existing solutions and identifying the areas that need improvement.
Collecting a massive training dataset: The next step is assembling a huge dataset. Jina AI used 2 billion records of English training data. This massive corpus is essential for training a high-quality, general-purpose embedding model capable of handling a wide range of tasks and domains.
Extensive data cleaning and curation: To ensure the quality of the training data, extensive data cleaning and curation processes are performed, including deduplication, language detection, and quality filtering. After this rigorous process, Jina AI was left with 400 million high-quality pre-training data records and 5 million lines of human-annotated fine-tuning data.
Refactoring for distributed training: Jina AI refactored its Finetuner codebase to enable efficient large-scale model training to support distributed training across multiple nodes and GPUs. This scalable infrastructure is crucial for training models on such a massive dataset.
The model was a success but did not stand out from all the other models in the industry as it had a limited context length. To solve this limitation, Jina AI trained Jina-Embeddings-V2.
Introducing Jina-Embeddings-V2: Train Short, Inference Long
To overcome the 512-token barrier and achieve their goal of handling longer sequences, Jina AI introduces Jina-Embeddings-V2, an embedding model that can handle sequences up to 8,192 tokens during inference while training on shorter sequences. This is achieved through several key modifications. Wang breezes through these modifications. Let's take a deep dive:
Removing Position Embedding
Traditional transformer models, including BERT, rely on position embeddings to encode the order of tokens within a sequence. These position embeddings are fixed vectors representing each token's position relative to others. However, they have limitations:
- Context Length: Position embeddings restrict the context window to a fixed size (e.g., 512 tokens in BERT). Longer documents or sequences exceed this limit, leading to information loss. Look at how the perplexity skyrockets for BERT models when you exceed 512 tokens, which means there is information loss. Perplexity measures how the model can understand the semantics of the text. The lower the perplexity, the better.
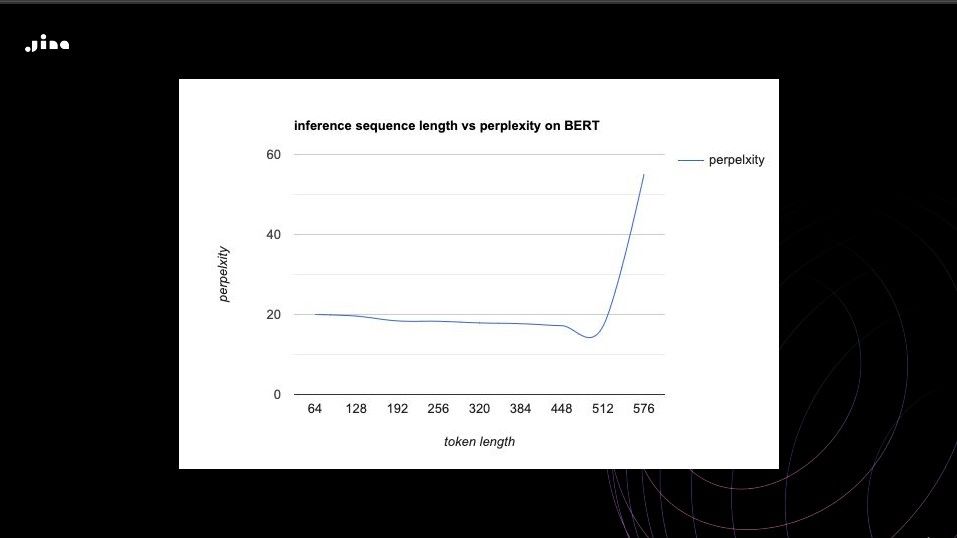 Inference sequence length vs perplexity on BERT
Inference sequence length vs perplexity on BERT
- Positional Constraints: Tokens at distant positions receive similar embeddings, ignoring their context.
Jina-Embeddings-V2 removes position embeddings entirely, allowing it to handle longer sequences without positional constraints. The model captures context across extensive documents, making it suitable for document summarization, legal analysis, and long-form content understanding.
Attention with Linear Biases (ALiBi)
ALiBi is a technique developed for large language models. Instead of relying on fixed position embeddings, ALiBi captures word order information dynamically during attention calculations. It then adapts to the context of each token, allowing it to consider both preceding and following tokens without positional constraints.
Effect on Embeddings: ALiBi enhances context understanding, even in lengthy texts. It enables Jina-Embeddings-V2 to capture rich semantic relationships between tokens, regardless of their position.
Adapting ALiBi for Bidirectional Transformers
Bidirectional understanding is crucial for tasks like question answering, summarization, and semantic search. Here’s how Jina-Embeddings-V2 achieves it:
Concept: ALiBi was originally designed for decoder-only models. Jina AI extends it to bidirectional architectures like BERT.
Bidirectional Context: Jina-Embeddings-V2 considers both left and right context, capturing dependencies across the entire sequence.
Effect on Embeddings: The model excels in tasks where understanding the context in both directions matters. For instance, semantic search benefits from bidirectional embeddings, as it requires analyzing user queries and document content simultaneously.
Retraining BERT from Scratch
Jina AI retrained BERT with advanced techniques, resulting in JinaBERT, which serves as the backbone for Jina-Embeddings-V2:
Concept: Jina AI applies various tricks, including whole word masking, RoBERTa recipe, GeGLU activations, and aggressive masking.
ALiBi Support: JinaBERT is trained in ALiBi, which ensures dynamic context modeling.
Effect on Embeddings: Jina-Embeddings-V2 benefits from a robust backbone capable of handling diverse tasks. It summarizes lengthy articles, extracts essential information, and maintains context integrity.
The retained JinaBERT perplexity remains low even when the 512 token limit is exceeded. Thanks to the removal of positional embeddings and the adaption of AliBi. Take a look at the new graph with BERT and JinaBERT compared:
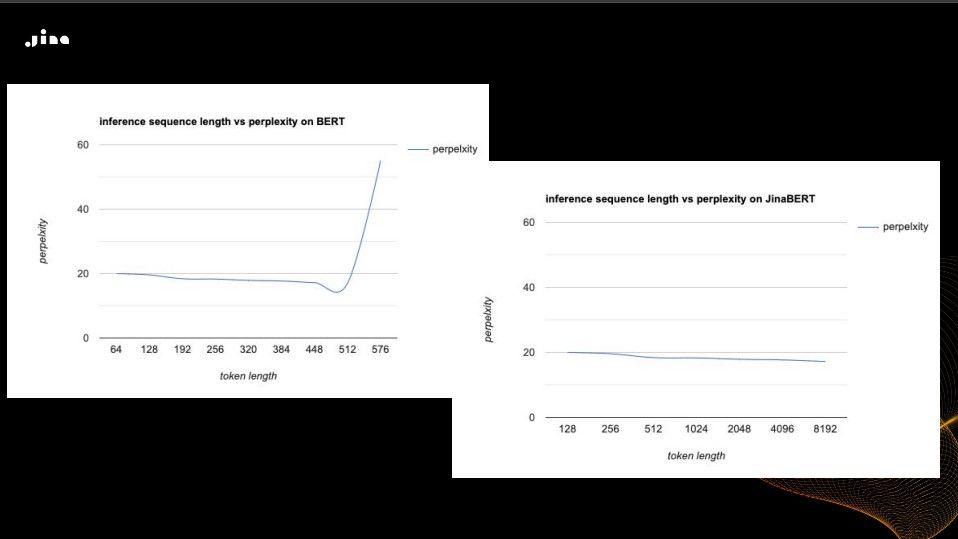 Inference sequence length vs perplexity on JinaBERT and BERT
Inference sequence length vs perplexity on JinaBERT and BERT
Bridging Languages: Bilingual Embeddings
Recognizing the limitations of existing multilingual embedding models, which often rely heavily on English training data, Jina AI started developing bilingual embeddings. Their goal is to create models that can handle multiple languages and cross-lingual relationships between them.
Jina AI's approach to bilingual embeddings departs from the norm. Most multilingual models, such as Multilingual BERT and Multilingual E5, suffer from a significant skew in their training data distribution. For example, the popular Multilingual E5 model has 91.5% of its training data in English, with only 4.2% in Chinese and 4.3% in other languages combined.
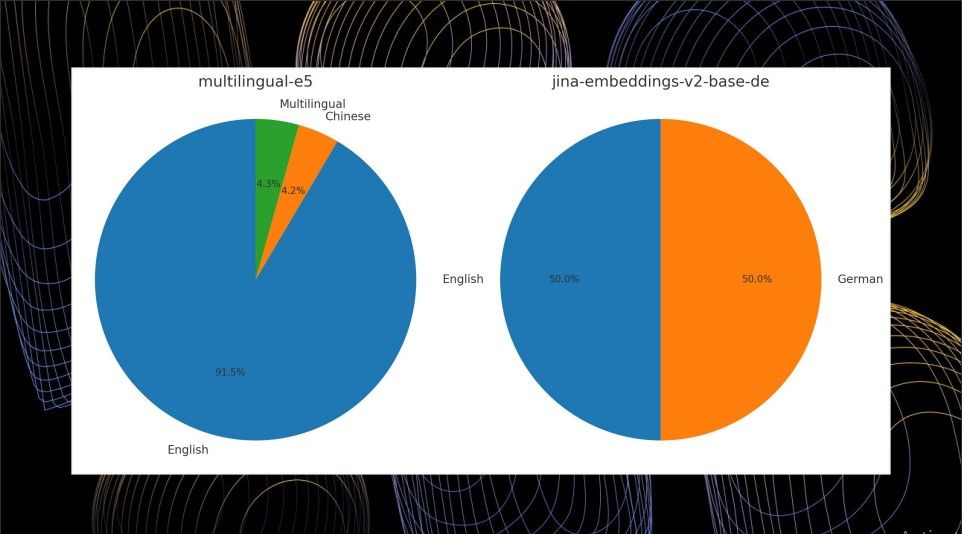 Multilingual E5 vs Jina Embedding v2 on pre-trained multilingual data
Multilingual E5 vs Jina Embedding v2 on pre-trained multilingual data
In contrast, Jina AI's Jina-Embeddings-V2-Based-German model features a balanced 50% English and 50% German training data distribution. This cross-lingual data is specifically designed to improve the model's understanding of the similarities and relationships between the two languages.
Despite being smaller than the multilingual models, Jina-Embeddings-V2-Based-German consistently outperforms its competitors, achieving higher scores on German-to-German, German-to-English, and English-to-German search tasks.
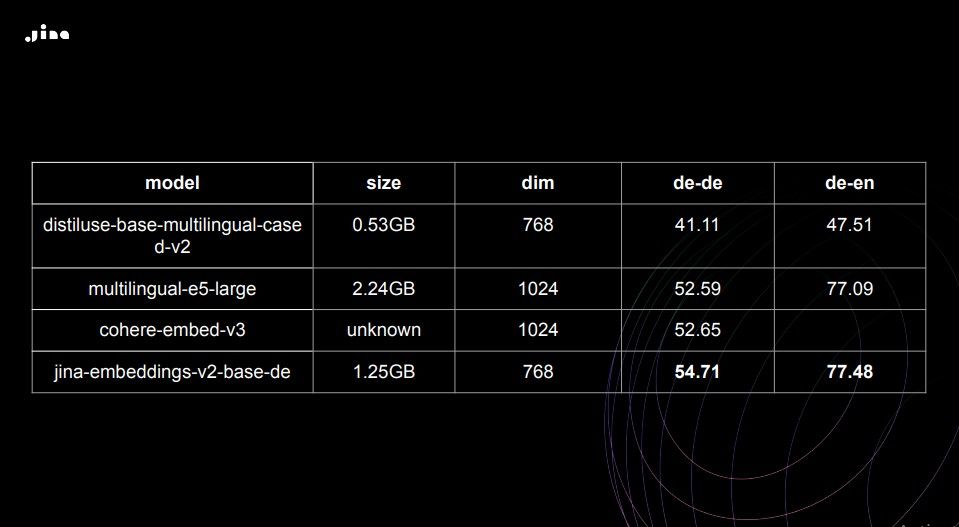 Search performance comparison between different embedding models
Search performance comparison between different embedding models
The results show the superiority of Jina AI's bilingual embeddings over popular multilingual models like Multilingual E5 and Cohere Embed V3, both in monolingual and cross-lingual search tasks.
What to Consider When Building RAG Applications With Jina-Embeddings-V2
When developing Retrieval-Augmented Generation (RAG) applications using Jina-Embeddings-V2, it’s essential to understand how the model handles documents of varying lengths and the positioning of relevant information within these documents. Bo Wang highlighted several key considerations:
Short Documents: If your documents are always smaller than 512 tokens, Jina-Embeddings-V2 performs comparably to other average encoders like E5 or BGE.
Long Documents (Early Information): If your documents are longer than 512 tokens, but the relevant information is at the beginning, Jina-Embeddings-V2 might perform worse.
Long Documents (Later Information): If your documents are longer than 512 tokens, and the relevant information is in the middle or at the end, Jina-Embeddings-V2 significantly boosts search performance.
Jina AI Integration with Milvus Vector Database
Both vector databases and embedding models are indispensable for building efficient information retrieval systems and RAG applications. These components are often integrated to conduct vector similarity search and retrieval tasks.
Milvus is an open-source vector database designed to efficiently store and retrieve billion-scale vector embeddings. Recently, Jina embeddings have been integrated into the PyMilvus model library, streamlining the development of RAG or other GenAI applications by eliminating the need for additional embedding components.
The recent introduction of Milvus Lite, a lightweight version of Milvus, has further simplified this process. Milvus Lite shares the same API as the full version of Milvus deployed on Docker or Kubernetes but can be easily installed via a one-line pip command without setting up a server. It is ideal for prototyping and can seamlessly transition to various Milvus deployments as your requirements grow.
To learn more about this integration, refer to the following resources:
Milvus Documentation: Integrate Milvus with Jina Embeddings
Blog: Implementing a Chat History RAG with Jina AI and Milvus Lite
Looking Ahead: Jina-Embeddings-V3
The team at Jina AI is already working on Jina-Embeddings-V3, which promises to bring even more advancements:
Speed and Efficiency: Jina-Embeddings-V3 will be faster and more memory-efficient, particularly for longer sequences.
Multilingual Support: The new version will offer optimized language distribution and better handling of multilingual data.
Real-World Problem Solving: Jina-Embeddings-V3 will address real-world problems with compressive failure analysis on V2 and other embedding models.
Task-Specific Enhancements: It will include carefully designed task instructions and task heads, along with clever routing to better handle different tasks.
Chunk and Schema Awareness: The model will be chunk-aware and schema-aware, improving its understanding of semi-structured data and hierarchical embeddings.
Summary
Jina embedding models boast high performance, featuring an 8192 token-length input window that excels in comprehensive data representation. With multilingual support and seamless integration with leading platforms like OpenAI, these embeddings are ideal for cross-lingual applications.
Embedding models and vector databases are essential for efficient similarity search and information retrieval. By integrating Jina embedding models with PyMilvus, the Python SDK for Milvus, the development of RAG and various GenAI applications becomes more efficient and straightforward.
In a recent talk by Bo Wang, he discussed the creation of Jina text embeddings for modern vector search and RAG systems. He also shared methodologies for training embedding models that effectively encode extensive information, along with guidance on selecting the most appropriate embedding models for various business needs.
For more details, watch the replay of Bo Wang’s talk on Youtube.
Keep Reading

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.