





#抽出から洞察へ:ETLを理解する
 ETLパイプライン.png
ETLパイプライン.png
企業はどのようにして膨大な生のデータセットを強力な洞察に変換しているのか?分析前にデータを統合し、洗練させるために、組織はどのようなステップを踏んでいるのだろうか?その答えは、Extract, Transform, and Load (ETL). にあります。
ETLは最新のデータ管理の鍵である。ETLによって、組織はデータを収集し、処理し、分析のためにロードすることができる。ETLは、複数のリソースから情報を抽出し、エラーを排除するために修正し、一元化されたデータベースに格納する。このプロセスにより、洗練され、正確で、整理された情報が得られ、ビジネス上の意思決定に役立ちます。
ETLなしのデータは、散在し、歪んだ性質を持つため、分析が困難である。非効率なデータはエラーにつながり、顧客との関係や業務パフォーマンスなど、さまざまな側面に影響を及ぼします。ETLは、ワークフローを自動化し、データの整合性を維持することで、データの質の低下を解決します。これにより、レポーティングを合理化し、分析を強化し、意思決定を改善することができます。
企業があらゆるものをデータドリブンにする中で、ETLを理解することは非常に重要になります。構造化データベース、クラウドシステム、リアルタイム分析のいずれに取り組んでいる場合でも、ETLは質の高いデータの統合と処理を保証します。
この記事では、ETLがどのように機能し、どのような影響を与え、どのように組織がETLをフル活用できるのかについて説明します。また、ETLプロセスを円滑にするために使用できるトップツールも紹介する。
ETL(抽出、変換、ロード)とは?
ETLはデータ管理と統合の中核となるプロセスです。異なるソースからデータを抽出し、データウェアハウスやデータレイクのような目的地にロードするのに適した形式に変換することから始まる。組織は、分析をサポートするために、別々のデータソースを1つのリポジトリに統合することで、データ統合を実現する。
ETLは、システムやプラットフォームの違いに関係なく、データの一貫性、品質、アクセシビリティを維持するためのバックボーンです。このアプローチは、金融、ヘルスケア、eコマースなど、さまざまな業界で活用されています。
企業はこの方法でデータを整理し、矛盾を取り除くことで、意思決定能力を高めています。最新のETLツールは、構造化データと非構造化データの両方を効率的に処理できる。
よく設計されたETLパイプラインシステムにより、企業は傾向を分析し、洞察を明らかにすることができる。自動化されたワークフローは、データ処理の自動化を通じて業務効率を高める。企業はETLを利用して、正確なレポーティングと戦略的プランニング活動をサポートする統合ビューを作成します。
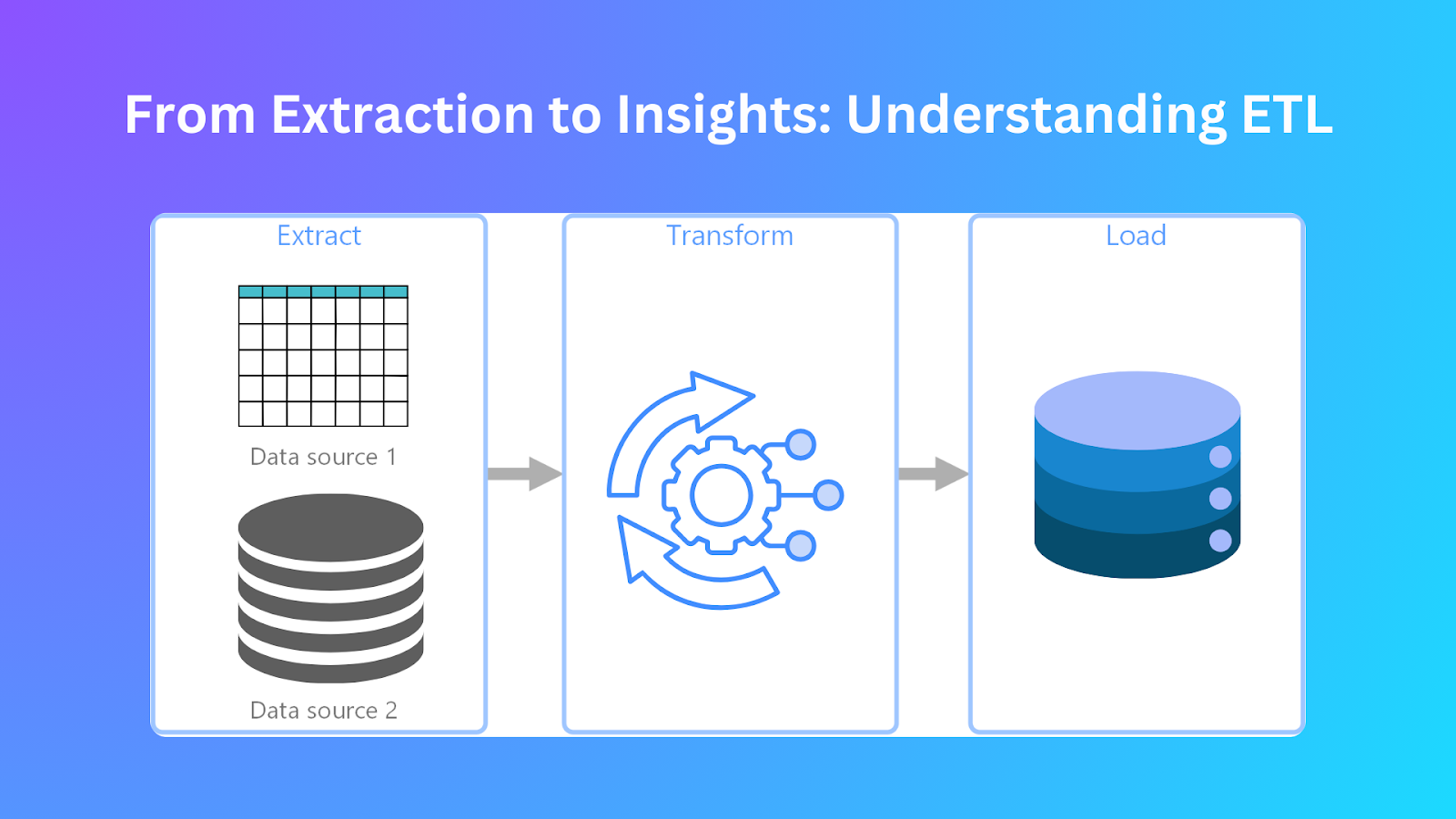
ETLの仕組み
ETLによるデータ処理は、各ステージで正確性と効率性を保証する3段階のプロセスに従って行われる。これらの段階は以下の通りである:
1.### 抽出
ETL パイプラインは、初期段階としてデータ抽出から始まる。この段階では、異なるソースからデータを収集し、それらを処理目的で統合する。抽出プロセスを通じて、組織はデータベース、フラットファイル、クラウドストレージ、API などの多様なシステムから完全なデータセットを取得する。以下に、データ抽出段階におけるいくつかのステップを紹介する:
データソースの特定:データソースの特定:抽出の最初のステップでは、データがどこに存在するかを特定します。データは、MySQLやPostgreSQLのリレーショナル・データベース、MongoDBやCassandraのNoSQLデータベース、サードパーティのAPI、CSVやJSONファイル、ストリーミング・データ・プラットフォームから来るかもしれない。効果的なETLパイプラインを構築するには、適切なデータソースを適切に特定する必要がある。
データ検索データ検索方法は、ビジネス要件と利用可能なシステム機能によって異なります。データの取り出しには、完全取り出しと増分取り出しの2つの方法がある。完全抽出はソースからすべてのデータを収集し、増分抽出は最後の抽出以降の変更点のみを収集する。インクリメンタル抽出は、処理時間を短縮し、ソース・システムの負担を軽減できるため、好まれます。
抽出されたデータには、空のフィールド、一貫性のないデータ型、構造形式が含まれている可能性があります。組織は、変換フェーズを開始する前に、不整合を特定し、管理するための前処理チェックを行うべきである。
2.### 変換
抽出後、ターゲットシステムのスキーマとの互換性を確保し、ビジネスルールを適用するために、データを変換する必要がある。この変換プロセスは、データ品質の向上、一貫性のあるデータ、使いやすさの向上につながります。ここでは、データを変換する方法をいくつか紹介します:
データクリーニング:データクリーニング: 基本的な変換手順の1つです。重複の除去、欠損データのインピュテーション、命名規則の標準化が必要です。これにより、正確で間違いのないレポートを作成することができます。
データ統合:データ統合: データは、別々のデータ構造を含む複数のソースに由来する。データ統合は、さまざまな個別のデータセットから単一の一貫したデータビューを作成します。このプロセスには、異なるカラム名のマッピング、タイムゾーンの相違の調整、参照整合性の確保などが含まれます。
データ集計**:効率的な分析のためにデータを要約します。ビジネスでは、地域ごとの売上合計、四半期ごとの顧客支出平均、月ごとの収益パターンを含むレポートが必要になることがよくあります。集計プロセスは、より迅速なデータクエリを可能にし、データの解釈を簡素化します。
データ変換**:必要なシステムと互換性を持たせるために、複数のデータタイプを変換する必要があります。データ・フォーマットの標準化は非常に重要であり、テキスト・フィールドの正規化と数値データの単位変換がプロセスを完成させます。データ変換プロセスにより、ロードされたすべてのデータが分析ニーズと正確に一致することが保証されます。
ビジネスルールの適用組織は通常、データ変換プロセスのためにビジネスルールを作成する。金融機関はトランザクションのしきい値を使用してカテゴリーを開発し、eコマース企業は購買活動に基づいて顧客をセグメントに分割する。定義されたルールは、未処理のデータを機能的なカテゴリーに整理することで価値を生み出す。
3.### 読み込み
変換されたデータは、データウェアハウス、データレイク、分析データベースなどのターゲットシステムにロードする必要がある。ロード・プロセスにより、データを効率的に照会・分析できるレベルが確立される。
ターゲットシステムへのロード**:完全なロード手順の間、ターゲットシステムは1回の操作ですべてのデータを受け取る。この方法は、主に最初のデータ移行時や小規模なデータセットを扱う場合に使用されます。もう1つの方法は、ソース・システムから新規レコードと更新データのみをロードする方法です。この方法は処理時間を短縮し、運用を効率化します。
インデックス作成とパーティショニング:*** データ・インデックス作成法とパーティショニング技術は、レコード検索におけるシステムのパフォーマンスを加速させる。パーティショニング技術はデータ・コレクションをより小さなセグメントに分割し、クエリー性能を向上させ、データをより管理しやすくする。
組織はバックアップ戦略を確立し、システム障害時の損失からデータを保護する。この方法はデータ保護を維持し、常にデータの可用性を保証する。
比較ETLとELTの比較
データ統合は、様々なソースからデータウェアハウスやデータレイクにデータを転送する主な方法として、ETL(抽出、変換、ロード)とELT(抽出、ロード、変換)に依存している。この2つの方法は、効率的なデータ転送という目標を共有しているが、現代のデータシステムに適合させ、処理する際の動作は異なる。ここでは両者の比較を行う:
| プロセスシーケンス** | Aspect | ETL | ELT |
| プロセスシーケンス** | 抽出 -> 変換 -> ロード | 抽出 -> ロード -> 変換 | |
| 変換はターゲット・システムにロードする前に行われる。 | |||
| データは変換の間、一時的なステージング・エリアに保存される。 | |||
| データ処理**|データはバッチ処理され、処理は通常リニアに行われる。 | |||
| スケーラビリティ**|ステージング・エリアとバッチ処理が必要なため、スケーラビリティは低い。 | |||
| ステージング・エリアとバッチ処理が必要なため、コストが高くなる可能性がある。 | |||
| 柔軟性**|処理順序が厳密であるため柔軟性に欠ける。 | |||
| バッチ処理、データ・ウェアハウス、ビジネス・インテリジェンス|リアルタイム分析、データ統合、ビッグデータ処理に適しています。 |
RTLとELTの比較|出典
利点と課題
ETLはデータの抽出、変換、ロードをサポートしますが、利点と課題もあります。それらを見てみよう:
メリット
データ・リネージ追跡:** ETLプロセスは、ソースから宛先へのデータ移動を追跡する。その主な機能には、エラーの特定、整合性の維持、正確性の遵守が含まれます。
歴史的データの保存**:ETLプロセスは、データの移動に沿ったスナップショットをキャプチャし、トレンド分析とレポーティングに必要な履歴情報を維持することができます。企業は、意思決定プロセスを支援するために比較を行いながらデータを追跡することができる。
複雑なデータ変換**:ETLツールは、集計処理、データタイプ変換、ビジネスロジックの実装など、複雑なデータ変換の実行に優れています。このシステムの機能により、データのクリーニング作業が容易になり、ターゲット・システムが情報を受け取る前に、構造化され標準化された情報を作成することができます。
データエンリッチメント:** ETL のデータエンリッチメントプロセスにより、企業は様々な外部データベースからの情報を結合し、データセットの品質と完全性を高めることができる。エンリッチメントによってコンテキスト情報を取り込むことで、意思決定のためにデータに付加価値を与え、分析的な洞察力を高めることができる。
バッチ処理の効率性ETLワークフローは、スケジュールされたオフピーク時に大容量のデータを処理するバッチ処理によって最大限の効率を達成します。このプロセスは、大規模なデータセットを効率的に管理しながら、通常業務時間中のシステム・パフォーマンスへの影響を最小限に抑えます。
課題
リアルタイム統合の制限**:従来の ETL プロセスでは、データをスケジュールされたバッチで統合するため、リアルタイムの データ要件が制限される。即座の分析と意思決定機能を必要とする組織は、従来の ETL プロセスに伴う遅延のために課題に直面します。
リソースを大量に消費する業務:** ETL 作業負荷の計算要件は、データ変換とロード処理が発生したときに特に厳しくなります。CPU](https://zilliz.com/jp/glossary/central-processing-unit-(cpu))とメモリリソースの使用率が高いため、システム操作の速度が低下し、パフォーマンスレベルに影響します。
エラー処理の複雑さETLパイプラインは多数のデータソースと複雑な変換ルールを扱う必要があるため、エラー管理が難しくなります。不整合を特定し、欠落データを処理し、品質を管理するためには、堅牢な監視ツールとデバッグ・システムが必要です。
スケーラビリティの制約データ量の増大は、ETLプロセスに新たなインフラ投資を確保するか、再設計されたアーキテクチャを採用しなければならないスケーラビリティの課題をもたらします。データの最適化が不十分な場合、データ量の増大は処理の遅延やシステム性能の限界につながる可能性があります。
依存関係の管理ETLワークフローのさまざまな段階は互いに依存しているため、1つの段階で障害が発生すると、パイプライン全体に連鎖的な影響が生じます。運用の中断を避けるため、依存関係の効果的な管理には、監視システムやエラーリカバリーの仕組み計画とともに、徹底したスケジューリングが必要です。
ユースケースとツール
ETLプロセスは、様々な業界にとって基本的な業務要件であり、効率的なデータ統合と分析の実現に役立っています。ここでは、その使用例とツールをご紹介します:
使用例
小売店:**ETLプロセスにより、小売店はチェックアウトシステムのデータを収集し、在庫記録と照合して正規化した後、統合データベースに保存することができます。このシステムにより、販売データの追跡、在庫管理、顧客理解の向上が可能になる。
金融機関では、複数のシステムからトランザクション・データを統合し、統合されたデータ・ストレージ・システムに変換してロードする前に、ETL手法を適用している。この統合プロセスにより、組織は不正を効果的に検出し、リスクを管理し、コンプライアンスに準拠したレポートを作成することができます。
ヘルスケア医療機関は、電子カルテ(EMR)、臨床データベース、管理システムのデータを統合するためにETLプロセスを適用します。システムの統合により、業務効率の向上とともに、十分な情報に基づいた意思決定プロセスをサポートし、より良い患者ケア管理を実現します。
人気のETLツール
AWS Glue: 70以上の多様なデータソースへの接続を容易にするサーバーレスデータ統合サービス。一元化されたデータカタログ、サーバーレス環境、カスタマイズ可能なスクリプトを提供。
Apache NiFi**](https://nifi.apache.org/):ETL機能を通じて自動データフロー処理を可能にするオープンソースシステム。このシステムは、使いやすいウェブベースのアクセス、即時処理機能、複雑なデータルーティング操作に役立つ広範なカスタマイズオプションを提供する。
Matillion**](https://www.matillion.com/):主要なクラウドベースのデータプラットフォーム上でシームレスに動作するクラウドネイティブのETLツール。ジェネレーティブAI、ビルド済みコネクター、コラボレーション・ワークフローなどの機能を提供する。
このツールとそのアプリケーションは、複数のビジネス領域において、生データを実用的な洞察に変換するためにETL手法がいかに不可欠であるかを示している。
よくある質問
1.ETLの主な目的は何ですか?
ETLは、様々なソースからのデータを単一の統合リポジトリにマージする機能です。データ処理ワークフローには3つの段階がある。データはソースから抽出され、分析システムにロードされる前に、運用上のニーズに合わせて変換される。
2.ETLとELTの違いは?
ETL プロセスは、まずソースシステムからデータを抽出し、それをターゲットシステムにロードするため のステージングエリアに変換することから始まる。その後、データはターゲットシステムにロードされ、変換はそのシステム上で直接実行される。
3.ETLプロセスの実装における一般的な課題とは?
ETLプロセスの実装は、異なるソースからの効果的なデータ管理、品質管理、膨大なデータ量の効率的な処理が必要となるため、複数の障害に直面する。このような課題は、効果的に解決するために徹底したリソース計画を必要とするパフォーマンスの問題を引き起こします。
4.ETLプロセスは自動化できるか?
ETLツールは、データ転送プロセスを実行するためのスケジューリングやワークフロー管理機能を通じて、自動化機能を提供します。自動化により、分析に必要なデータセットを最新の状態に保つために一貫したデータ品質を維持しながら、人間の関与を減らす自動データ処理によって効率的なオペレーションが可能になります。
5.なぜETLでデータ変換が重要なのか?
ETLオペレーションにおけるデータ変換は、異なるソースから取得したデータをクリーンアップ、標準化、フォーマットする上で非常に重要です。データ変換プロセスにより、ターゲットシステムは、分析およびレポーティングのために正確で一貫性のあるデータを受け取ることができ、信頼性の高いビジネス上の意思決定をサポートします。
関連リソース
データ移動におけるETLの役割とは](https://zilliz.com/ai-faq/what-is-the-role-of-etl-in-data-movement)
ビッグデータ処理におけるETLの役割とは](https://zilliz.com/ai-faq/what-is-the-role-of-etl-in-big-data-processing)
データ分析におけるETLの役割とは](https://zilliz.com/ai-faq/what-is-the-role-of-etl-in-data-analytics)
アナリティクスのために複数のソースからのデータをどのように統合するか](https://zilliz.com/ai-faq/how-do-you-integrate-data-from-multiple-sources-for-analytics)
リレーショナルデータベースとNoSQLデータベースの間でどのようにデータを同期しますか](https://zilliz.com/ai-faq/how-do-you-synchronize-data-between-relational-and-nosql-databases)