




Securing AI: Advanced Privacy Strategies with PrivateGPT and Milvus
Introduction
As organizations integrate Large Language Models (LLMs) and other AI tools into their operations, concerns about data security are rising. For example, key sectors like finance, banking, healthcare, and e-commerce are embracing AI to power a range of functions, from content creation and document summarization to customer support and prompt-based question answering. However, this widespread adoption of AI also introduces substantial risks, such as potential data privacy breaches and compliance standards violations.
To mitigate these risks, companies are searching for solutions that enable them to harness the power of AI without compromising the security of their sensitive data. At a recent webinar hosted by Zilliz, Daniel Gallego Vico, founder of PrivateGPT and Zylon, offered valuable insights into various data infrastructures designed to enhance data privacy in enterprise settings. In this blog post, we’ll summarize the key points from Daniel's presentation and offer our take on these developments. If you’re interested in more details, watch the replay of his talk on YouTube.
How AI Tools Threaten Data Privacy: Risks and Impacts
 Figure- AI adoption is unstoppable. .png
Figure- AI adoption is unstoppable. .png
Figure: AI adoption is unstoppable.
Daniel highlights a striking statistic from the 2024 Work Trend Index report: “75% of global knowledge workers are now using AI in their professional tasks.” This widespread adoption underscores the inevitability of AI integration in workplaces, but it also brings to light significant challenges in safeguarding private data:
Data Leakage in Model Outputs: When employees use LLMs like ChatGPT to analyze company data, these models, trained on extensive datasets, may inadvertently include fragments of their training data in their outputs. This can lead to the unintended leakage of sensitive information, potentially exposing details from prompts and documents used during the session.
Reverse Engineering of Anonymized Data: Despite efforts to encrypt or anonymize Personally Identifiable Information (PII), such as names, addresses, and credit card numbers, these protections are not impenetrable. Skilled hackers have successfully employed reverse engineering techniques to decode encrypted data, posing a significant threat to data privacy.
Model Inference Attacks: In these attacks, an adversary submits various inputs to an AI model and analyzes the responses to infer whether specific data was included in the training set. For instance, this method could reveal whether a particular patient’s medical records were used in training a healthcare AI system, thereby compromising patient confidentiality.
 Figure- AI breaks privacy. .png
Figure- AI breaks privacy. .png
Figure: AI breaks privacy.
Beyond these specific risks, data privacy threats also arise from data scraping, breaches due to inadequate security measures, and the potential for AI models to memorize sensitive data during training. Any exposure to customer or client data can lead to severe legal issues for organizations failing to adhere to regulatory standards.
Different Levels of AI Privacy
Developing AI applications, such as chatbots or retrieval augmented generation (RAG), often requires integrating various third-party services, including LLMs, cloud providers, embedding models, and vector databases like Milvus. Ensuring all these services meet stringent data privacy and security standards is essential but challenging.
A range of AI privacy solutions are available to address these privacy concerns, each offering different levels of data security based on its infrastructure. It's crucial for organizations to thoroughly understand each option to choose the solution that best meets their needs.
Daniel shared five distinct AI privacy strategies: compliant SaaS, data anonymization, local execution, in-house development, and on-prem infra agnostic. In the following sections, we will discuss these solutions, their benefits, and limitations to help inform your decision-making process.
Compliant SaaS
Compliant SaaS represents the foundational level of data privacy, where an organization adheres to regulatory standards such as GDPR or HIPAA. Initially, data is stored within the company’s infrastructure and then shared with an AI Software as a Service (SaaS) provider. This provider, in turn, may share the data with various third-party vendors for tasks like creating vector embeddings (with tools like Milvus), training LLMs (such as OpenAI), and managing data ingestion.
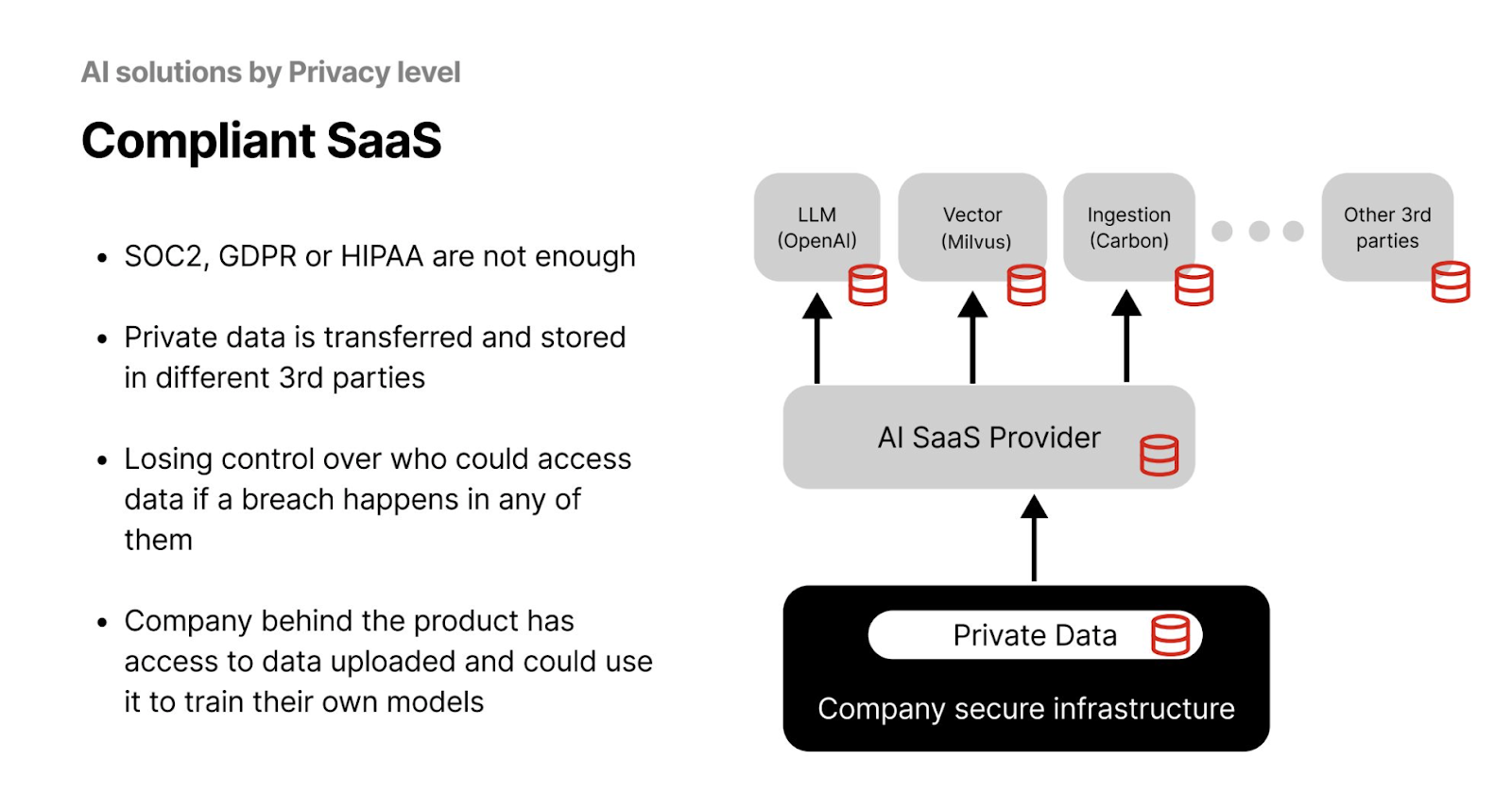 Figure- AI Solutions by Privacy Level - Compliant SaaS .png
Figure- AI Solutions by Privacy Level - Compliant SaaS .png
Figure: AI Solutions by Privacy Level - Compliant SaaS
However, this strategy comes with significant risks. A breach at any third-party vendor could lead to unauthorized access to your organization's data. Additionally, these third parties have complete access to the uploaded data and could potentially use it to train their own models, posing further risks of data misuse.
Data Anonymization
Data anonymization is a privacy-enhancing infrastructure solution designed to secure data in SaaS or cloud-based pipelines. An additional anonymization layer is applied before sharing data with a SaaS provider. During this process, Personally Identifiable Information (PII)—such as names, addresses, and credit card numbers—is obscured or replaced with encryption. This anonymization should ideally occur on-premise within the company’s secure infrastructure.
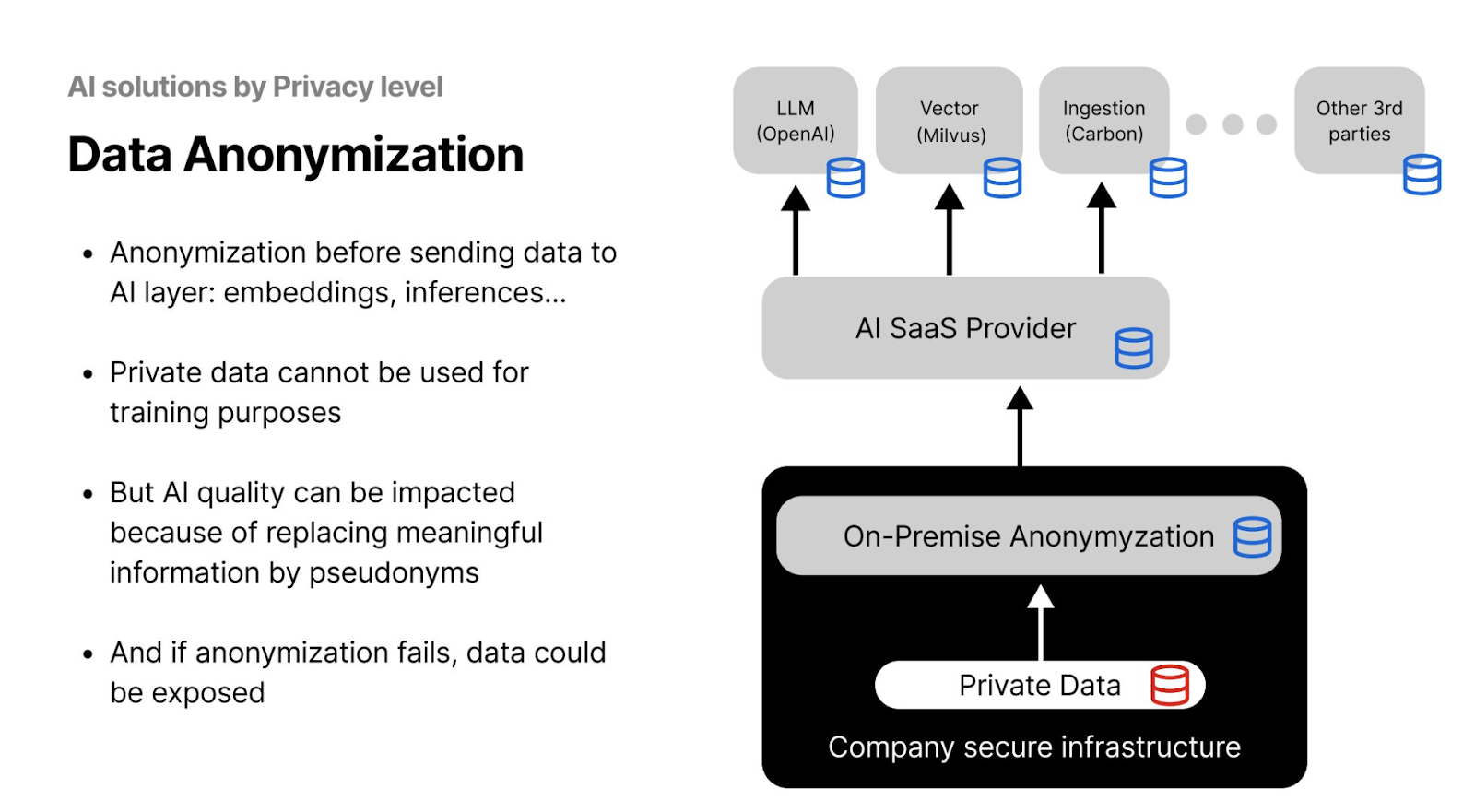 Figure- AI Solutions by Privacy Level - Data Anonymization .png
Figure- AI Solutions by Privacy Level - Data Anonymization .png
Figure: AI Solutions by Privacy Level - Data Anonymization
While anonymization can significantly reduce the risks of sensitive data being re-identified or misused by third parties, it has drawbacks. Training LLMs on anonymized data might lead to decreased accuracy in results or inferences. Additionally, despite the added layer of protection, attackers may still be able to re-identify partial information by correlating it with other datasets.
Local Execution
Local execution runs the entire AI pipeline on an isolated device, such as a personal computer or server. This method offers high data privacy, as the data remains within your system, and the LLMs can operate offline. It's particularly suited for individual researchers working with smaller datasets.
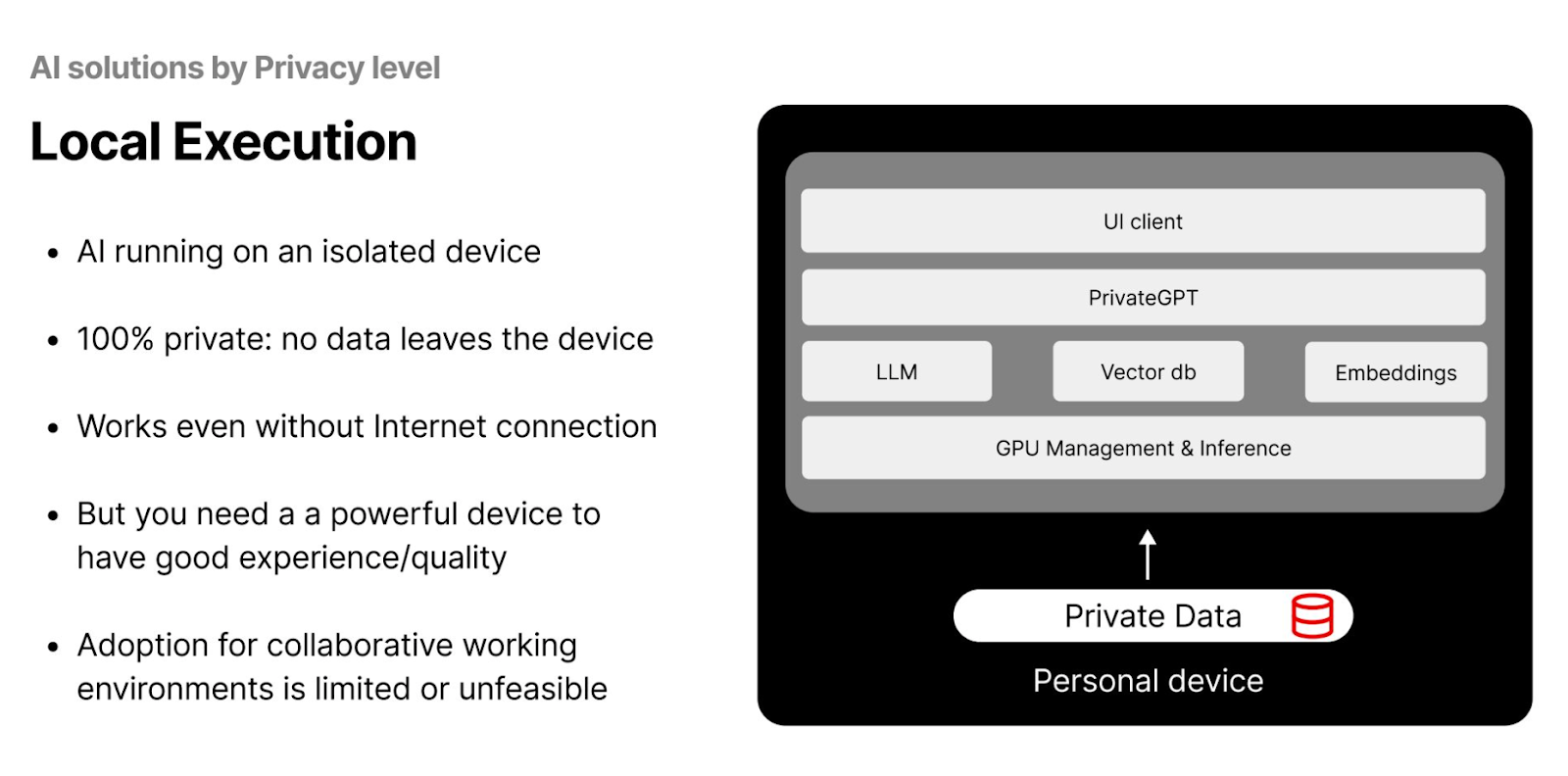 Figure- AI Solutions by Privacy Level - Local Execution.png
Figure- AI Solutions by Privacy Level - Local Execution.png
Figure: AI Solutions by Privacy Level - Local Execution
However, the feasibility of local execution can be limited due to high setup costs. Operating entirely on local systems requires high-computation GPUs and powerful devices to achieve high-quality results. Furthermore, local execution may not be the best option for collaborative projects with multiple people or teams, as it restricts data accessibility and real-time collaboration.
In-House Development
In-house development creates a complete end-to-end AI pipeline within a company’s secure infrastructure. This approach ensures that LLMs' performance is not compromised while significantly reducing the risk of data leakage. It also facilitates easier access to data and collaboration among teams within an enterprise.
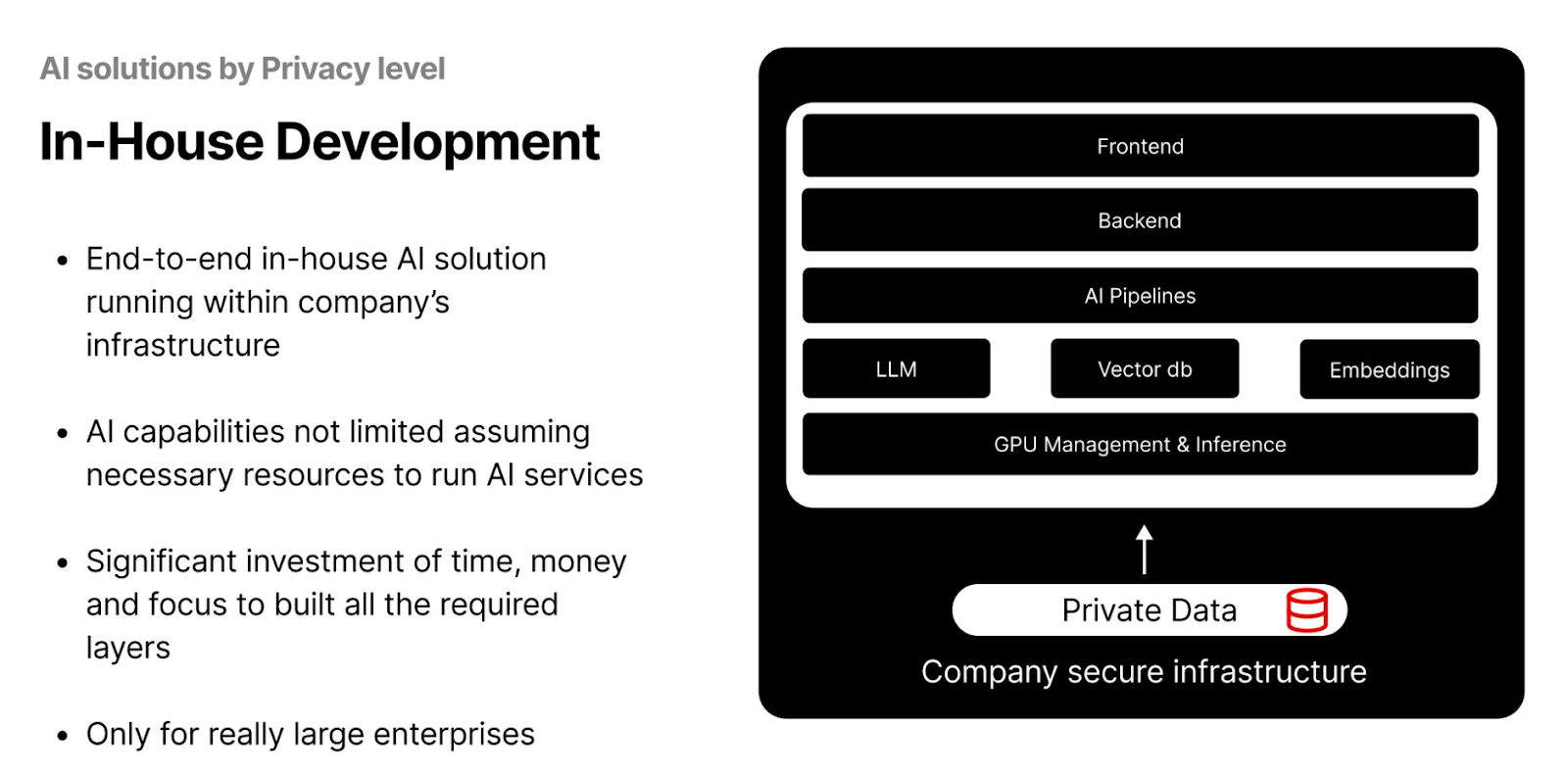 Figure- AI Solutions by Privacy Level - In-House Development.png
Figure- AI Solutions by Privacy Level - In-House Development.png
Figure: AI Solutions by Privacy Level - In-House Development
However, implementing an in-house solution requires substantial initial investment in terms of both money and time, making it feasible primarily for large enterprises. Companies must set up everything from scratch, including the vector database, embedding models, GPUs, and the front end. Additionally, technical teams must be hired and trained to build and maintain the system, adding to the long-term costs and operational demands.
On-Prem Infra Agnostic
For smaller enterprises and startups that cannot afford to build a full-scale infrastructure from scratch, all-in-one AI workspaces like Zylon offer a viable solution. In this model, data remains within the company’s infrastructure while the workspace provides the necessary components to run LLMs and perform inference tasks locally. Zylon incorporates privacy tools such as PrivateGPT, which enables users to operate generative AI models entirely on local hardware or within their secure infrastructure.
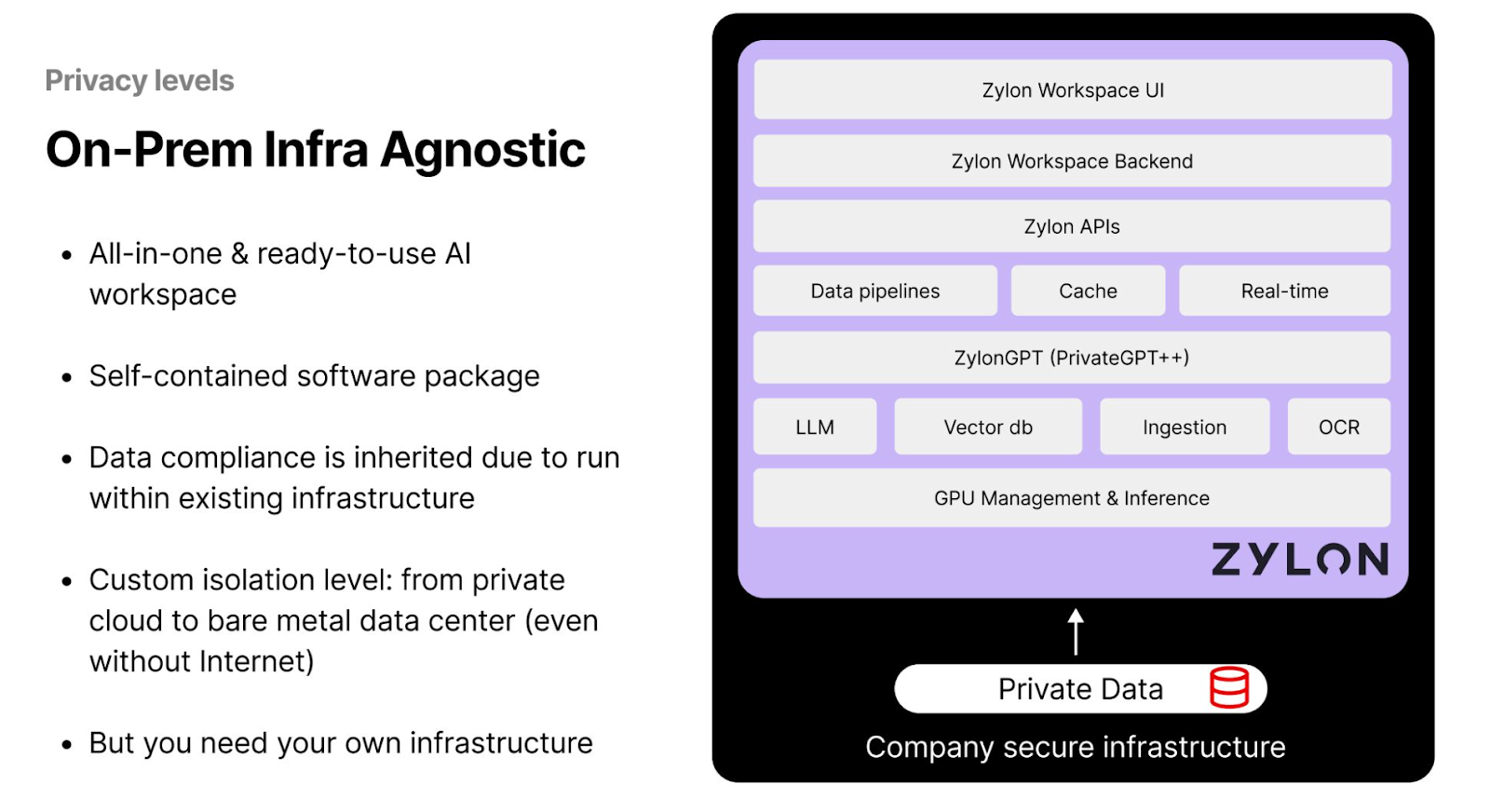 Figure- AI Solutions by Privacy Level - On-prem Infra Agnostic.png
Figure- AI Solutions by Privacy Level - On-prem Infra Agnostic.png
Figure: AI Solutions by Privacy Level - On-prem Infra Agnostic
With this approach, Zylon does not gain access to the company's data, allowing enterprises to leverage AI capabilities without compromising privacy. However, a significant limitation of this solution is the need for organizations to set up their data centers to maintain control over their data, which can be costly. This requirement may put constraints on smaller companies with limited capital resources.
What is PrivateGPT and How Does it Enhance AI Privacy?
PrivateGPT is a framework designed to develop context-aware LLMs with enhanced data privacy controls. It equips users with a suite of AI tools and APIs for various tasks, such as creating embeddings with embedding models, performing similarity searches using vector databases like Milvus, or utilizing pre-trained LLMs for inference.
The diagram below illustrates the PrivateGPT pipeline, which typically includes an LLM that end users can query, an embedding model that transforms text or images into vector embeddings, and a Vector Database for storing these embeddings.
 Figure- PrivateGPT Architecture and Components.png
Figure- PrivateGPT Architecture and Components.png
Figure: PrivateGPT Architecture and Components
PrivateGPT offers significant flexibility, allowing users to customize configurations and select the APIs or models that best meet their needs. For instance, users can choose from various LLMs like Llama or Mistral, depending on the required complexity and speed of the application. It is also crucial for users to select a vector database that is robust and capable of fast retrieval speeds, such as Milvus. Furthermore, multiple options are available for embedding models, including those from Hugging Face and NOMIC, providing a wide range of choices to accommodate different project requirements and enhance overall system performance.
To construct AI applications using PrivateGPT, developers have access to two main categories of REST APIs: Primitives API and Recipes API. These APIs are designed to facilitate the creation of private, context-aware AI applications while maintaining strict data privacy.
Primitives API
This API category allows teams to develop AI applications with varying levels of customization:
High-Level API: Tailored for users who prefer a straightforward approach without deep customization needs, this API offers a ready-to-use RAG pipeline. Teams can upload documents, and the API handles numerous data processing tasks such as parsing, splitting, creating metadata embeddings, and storing them. It also enables prompt engineering to deliver context-based answers to user queries.
Low-Level API: This API allows users seeking more control over their AI applications to create and customize individual components of the RAG pipeline. From the logic behind vector embeddings to the procedures for document ingestion, users can experiment to discover the most effective strategies for data retrieval.
Recipes API
A recently introduced advanced high-level API, the Recipes API enables users to construct structured workflows, or "recipes," for specific AI tasks such as summarization. This API is invaluable for enterprises aiming to develop customized workflows that align with their unique business requirements. It can integrate seamlessly with local databases or content management systems, empowering businesses to automate and optimize their internal processes without transmitting data to external servers.
PrivateGPT Setups for Local Execution
Daniel provides insights on configuring PrivateGPT for local execution, ideal for maintaining 100% data privacy and operating offline. Daniel recommends using Ollama for inference tasks in this setup, which supports GPU configurations and integrates seamlessly with various LLM models. This flexibility is crucial for adapting to different data types—text, audio, or images—and specific computational tasks. Popular LLM choices are Llama and Mistral AI, which are known for their robust performance across diverse use cases.
For the vector database, Daniel advises using Milvus Lite, a streamlined version of the widely recognized Milvus vector database renowned for its large-scale similarity search capabilities. Due to its low resource consumption, Milvus Lite is ideal for environments with limited resources. It facilitates rapid similarity searches and data retrieval, making it an excellent choice for small-scale applications that don't require extensive infrastructure.
Additionally, Daniel suggests selecting an embedding model that supports a diverse range of languages. This ensures that the vector embeddings created apply to various international contexts and linguistic needs, enhancing the overall utility and reach of the AI application.
 Figure- The Recommended PrivateGPT Setups for Local Deployment .png
Figure- The Recommended PrivateGPT Setups for Local Deployment .png
Figure: The Recommended PrivateGPT Setups for Local Deployment
PrivateGPT Setups for Cloud Execution
When developing large-scale AI applications, it is suggested that PrivateGPT be set up for cloud execution, allowing users to access their instances from anywhere globally. This setup involves more complex and demanding infrastructure requirements compared to local execution. Daniel outlines an effective strategy for establishing a cloud architecture that maximizes efficiency while safeguarding data privacy.
To begin, users will need a cloud instance from service providers such as AWS. Daniel recommends installing Milvus Standalone as the vector database on this cloud instance using Docker. Milvus Standalone offers a single-node deployment, which, despite its simplicity, still provides comprehensive vector search, indexing, and storage capabilities, making it ideal for PrivateGPT applications.
Additionally, setting up a NodeJS server on the cloud instance enables smooth access and interaction with the AI application. This server acts as an intermediary, handling requests to and from the PrivateGPT model, ensuring seamless and efficient operations across the network.
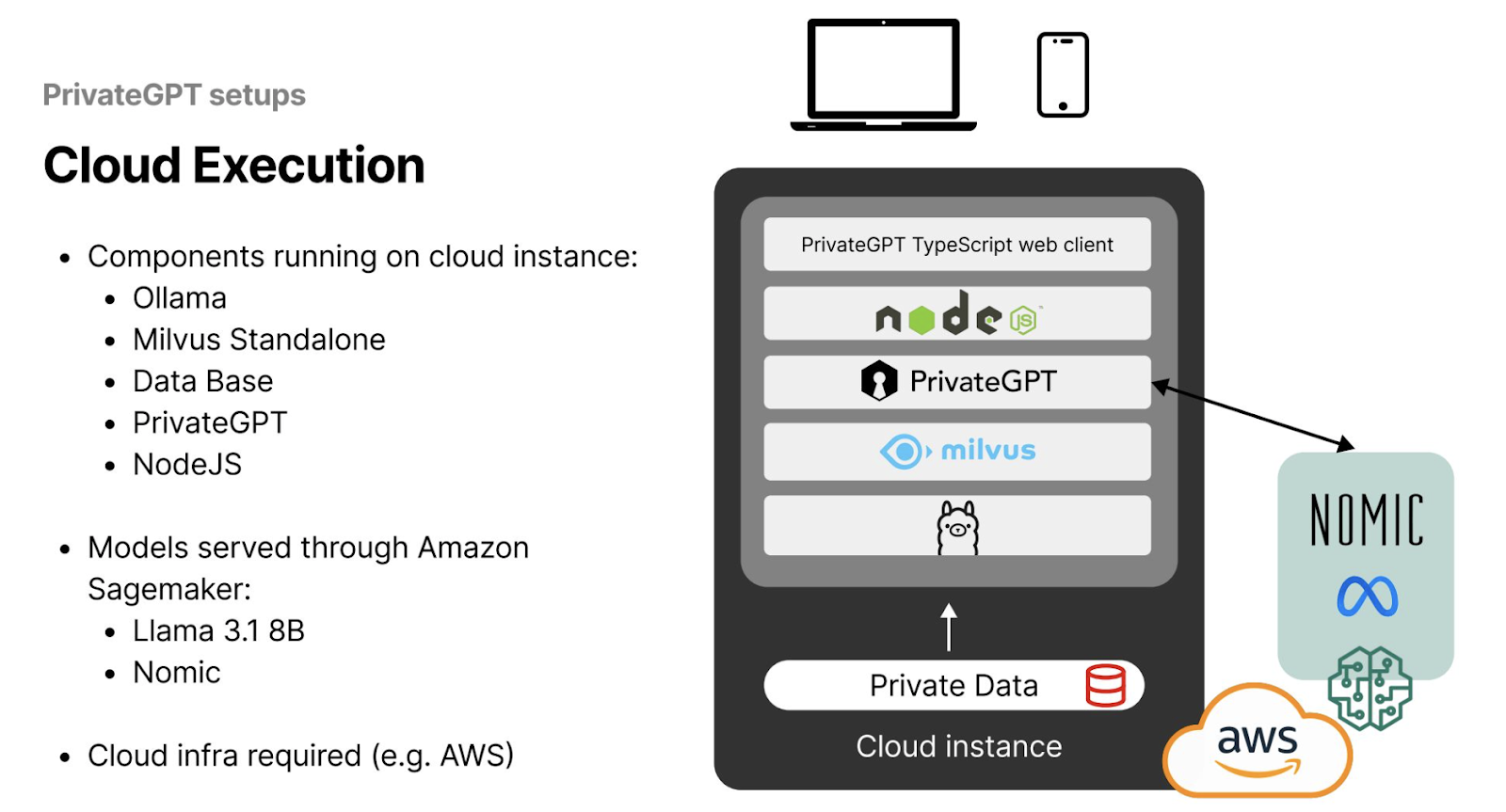 Figure- The Recommended PrivateGPT Setups for Cloud Deployment.png
Figure- The Recommended PrivateGPT Setups for Cloud Deployment.png
Figure: The Recommended PrivateGPT Setups for Cloud Deployment
Summary
In this post, we discussed data privacy in AI application development, particularly when handling sensitive customer information. We learned that simply following regulatory standards doesn't quite protect data against sophisticated attacks like reverse engineering and model inference.
We also took a close look at various data privacy strategies, assessing the investment and risks associated with each. Daniel shared insights on how integrating tools like PrivateGPT with vector databases such as Milvus boosts the accuracy of LLM outputs and safeguards privacy. We also offered practical advice on setting up secure architectures for local and cloud-based deployments, ensuring businesses can create robust and efficient AI systems while upholding strict data protection standards.
Further Resources
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 ShriVarsheni R
ShriVarsheni R
Keep Reading

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.