




Enhancing AI Reliability Through Fine-Grained Hallucination Detection and Correction with FAVA
Imagine relying on an AI tool to draft a report. You ask it for details about the Apollo missions, and it confidently tells you Neil Armstrong landed on the moon in 1965. Without verifying this, you include the error in your report. This is an example of hallucination, where AI generates plausible but incorrect or unverifiable information.
Hallucinations challenge AI’s reliability, especially in fields like healthcare, education, and journalism, where even minor inaccuracies can lead to serious consequences. Errors can range from simple factual mistakes to entirely fabricated entities or events, requiring more than a basic classification of factual or not. To tackle this challenge, FAVA, a retrieval-augmented language model for detecting and correcting hallucinations, was introduced in the paper Fine-Grained Hallucination Detection and Editing for Language Models. This approach also includes a fine-grained taxonomy to categorize errors and a benchmark dataset called FAVABENCH to evaluate model performance. Together, these tools improve the reliability of AI in high-stakes contexts.
In this blog, we will explore the nature of hallucinations, the taxonomy that provides a framework for categorizing them, the FAVABENCH dataset designed for evaluation, and how FAVA detects and corrects errors.
Why Existing Methods Struggle with Detecting AI Errors
Most systems for identifying errors in AI outputs treat the task as a simple decision, classifying a statement as either factual or not. While this binary approach is straightforward, it often fails to address the complexity of AI-generated errors. For instance, identifying a wrong date might seem simple, but recognizing a fabricated entity or correcting a subtle relational mistake requires a deeper understanding of the content and context.
A more detailed approach is needed to go beyond labeling entire statements as incorrect. Consider the sentence, Messi is a soccer player in Barcelona. He is known for the 2017 film The Messi Diaries. A binary system might flag the statement as false without explaining why. Fine-grained detection, on the other hand, pinpoints specific issues: the incorrect location (Barcelona should be Miami) and the invented claim about a non-existent film.
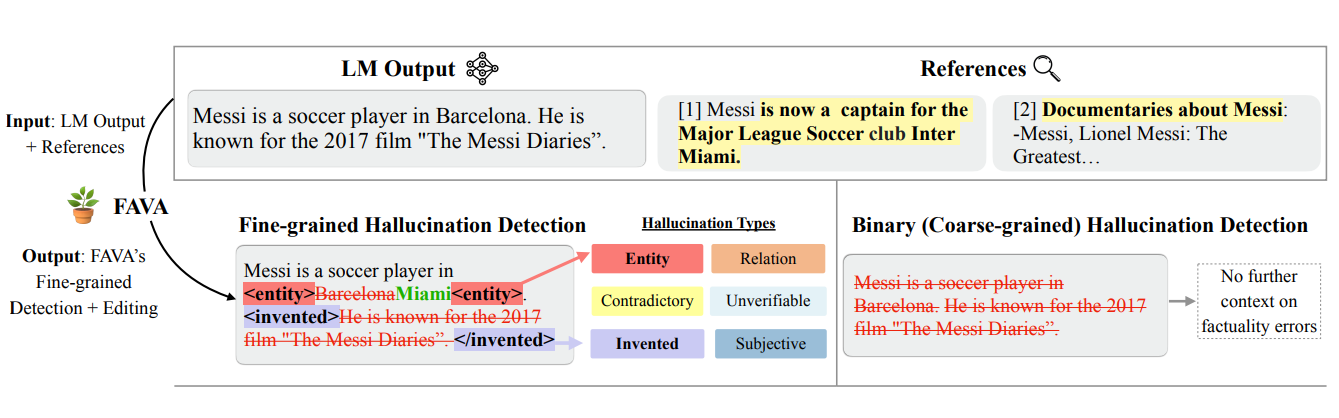
Figure: A comparison between binary and fine-grained hallucination detection, demonstrating how fine-grained methods identify specific types of errors within a statement.
By identifying the specific nature of errors, such as inaccurate details or fabricated claims, fine-grained detection provides clarity and enables targeted corrections. This approach overcomes the limitations of binary classification, offering a more nuanced and actionable solution for addressing AI errors effectively.
Understanding the Categories of Hallucinations
Errors generated by AI systems are not all the same. Some involve simple factual inaccuracies, such as misstating a date, while others fabricate entirely new entities or unverifiable claims. To address this diversity, a fine-grained taxonomy categorizes hallucinations into six distinct types. This structure provides clarity about the nature of errors and enables precise corrections.
The process of categorizing hallucinations begins with analyzing the information against the available evidence. The decision tree below shows how different types of hallucinations are identified step by step. For instance, errors can arise from contradictory facts, unverifiable statements, or entirely invented entities. By following this structured approach, the taxonomy offers a systematic way to evaluate and address hallucinations.
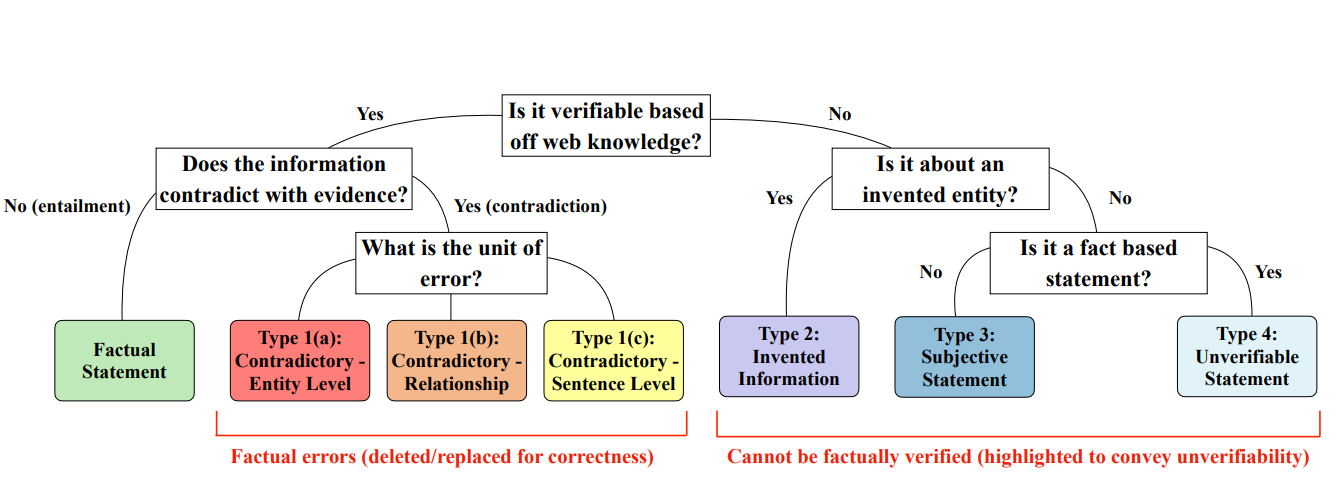
Figure: Decision tree explaining the taxonomy and how errors are categorized into six types, with examples.
The six categories of hallucinations are as follows:
Entity ErrorsThese involve incorrect details like names, dates, or locations. For example, claiming that Neil Armstrong landed on the moon in 1965 instead of 1969 is an entity error. These mistakes are often straightforward to detect and correct using well-documented sources.
Relation ErrorsRelation errors occur when the relationship between two entities is misrepresented. For example, stating that Lionel Messi was acquired by PSG instead of joining PSG alters the meaning of the relationship. Correcting these errors requires understanding the context of the entities involved.
Sentence ErrorsThese are entire sentences that contradict factual evidence. For instance, the statement: Messi was never the captain of Argentina's football team conflicts with well-established facts. Sentence-level errors often require more context to identify and correct.
Invented InformationErrors in this category involve fabrications of entities or concepts that do not exist. For example, claiming that Messi is known for his famous airplane kick creates an entirely fictional action. These errors can be harder to detect because they may sound plausible but have no basis in reality.
Subjective StatementsSubjective statements occur when opinions are framed as factual claims. For example, saying Messi is the best soccer player in the world is subjective and cannot be universally verified. While opinions are valid in casual contexts, presenting them as facts can lead to misunderstandings.
Unverifiable ClaimsThese involve statements that lack sufficient evidence to confirm or deny their validity. For example, a claim like Messi enjoys singing for his family in his free time is unverifiable without specific evidence or direct corroboration.
Each category highlights the diverse ways hallucinations manifest, demonstrating that a one-size-fits-all approach to detecting and correcting errors is insufficient. By breaking errors into these categories, the taxonomy provides the clarity needed to address hallucinations with precision.
Evaluating AI Performance with FAVABENCH
The taxonomy provides a structured way to understand hallucinations, but evaluating how well AI models address these errors requires a reliable testing framework. FAVABENCH, a benchmark dataset, was created to analyze AI outputs and assess their ability to detect and correct specific types of errors.
FAVABENCH includes annotated responses from large language models such as ChatGPT and Llama2-Chat, covering a range of tasks. Each response is analyzed at the span level, with specific parts of text flagged based on the six categories of hallucinations.
The dataset also uncovers trends in the types of errors models generate. The graph below illustrates how hallucinations are distributed across different models and datasets. Entity errors are common across all models, while errors like fabricated information or unverifiable claims show more variability.
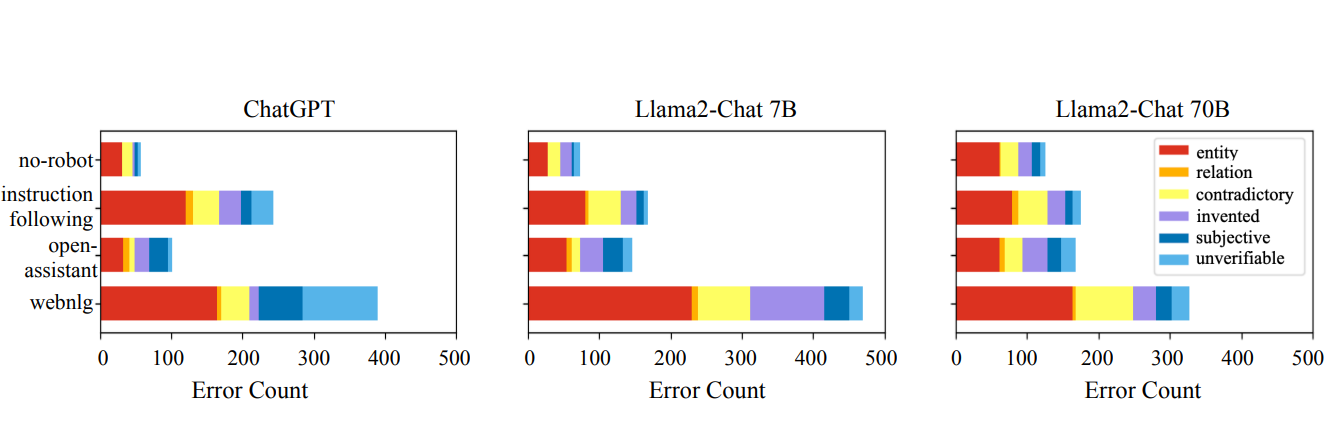
Figure: Graph showing the distribution of hallucination types across AI models and datasets
To further illustrate the types of errors captured by FAVABENCH, the table below presents examples for each category, along with their prevalence in different models. These examples highlight recurring issues, such as frequent entity errors, as well as less common but significant problems like invented information.

Figure: Examples of hallucination types with their prevalence across models
FAVABENCH helps identify patterns in how AI systems handle hallucinations by offering detailed annotations and a clear breakdown of model performance. It connects the theoretical framework of the taxonomy with practical evaluation, enabling us to pinpoint areas for improvement in AI models.
How FAVA Detects and Corrects Hallucinations
Detecting and correcting hallucinations in AI outputs requires both identifying errors and verifying claims using reliable external evidence. FAVA (Fact Verification and Augmentation) employs a two-step process combining retrieval and editing to handle a wide range of hallucination types effectively. The model’s training on a diverse dataset of synthetic errors plays a key role in its capabilities.
Training FAVA with Synthetic Data
To prepare FAVA for identifying and correcting hallucinations, a synthetic dataset was created tailored to the six types of errors defined in the taxonomy. This process started with factually accurate passages sourced from reliable documents like Wikipedia. These passages were then systematically modified to introduce errors, ensuring the dataset reflected the variety and complexity of real-world hallucinations. Instruction-tuned models such as Chatgpt were used to insert errors into the passages, such as:
Replacing factual details like dates, names, or locations to generate entity errors.
Adding completely fabricated information to simulate invented claims.
Introducing unverifiable statements to represent ambiguous or unsupported assertions.
Each modified passage was paired with its original, unaltered version, allowing FAVA to learn both how to detect the errors and how to correct them based on context and evidence. The systematic nature of the dataset generation process ensured that FAVA could generalize well to unseen errors during real-world applications.
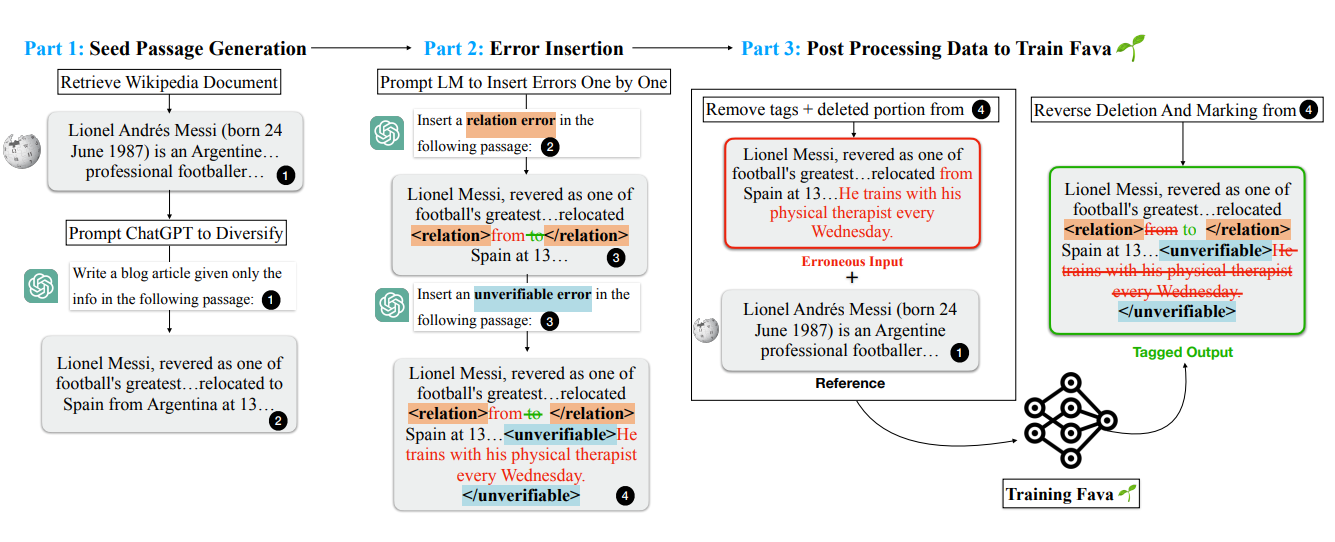
Figure: Illustration of the synthetic data generation process, showing how accurate content was modified to include various types of hallucinations for training purposes
This diverse training dataset allowed FAVA to recognize patterns in hallucinations and equipped it with the ability to categorize and resolve errors accurately.
Retrieving Evidence and Correcting Errors
Once trained, FAVA operates in two key stages: retrieval and editing.
Retrieving EvidenceWhen presented with a statement, FAVA begins by searching external sources, such as Wikipedia, for relevant information. This step ensures that the model has access to factual data to verify the input text. For example, if the input states Messi was born in Miami, the retrieval component searches for documents that provide evidence about Messi’s birthplace. These documents serve as the foundation for the next step in the process.
Detecting and Correcting ErrorsUsing the evidence retrieved, FAVA identifies specific hallucinations in the input text. It categorizes these errors based on the taxonomy, flagging them as entity errors, invented claims, or unverifiable statements, among others. The editing component then proposes corrections informed by the retrieved evidence. For instance, in the earlier example, FAVA would detect that Miami is incorrect and replace it with the verified fact, Rosario, Argentina.
This structured process allows FAVA to address errors at both the identification and correction levels, ensuring that outputs are not only accurate but also grounded in verifiable information.
Evaluating FAVA’s Performance
To measure how effectively FAVA and other models detect and correct hallucinations, key metrics like precision, recall, and F1 score are used. These metrics provide insight into the reliability, thoroughness, and overall performance of the model.
Precision
Precision measures the proportion of predictions made by the model for a specific error type that are correct. It evaluates the reliability of the model when identifying hallucinations, focusing on avoiding false positives. In the formula for precision, Pₜ, the numerator represents the sum of correct predictions for error type t across all sentences, while the denominator is the total number of predictions the model made for that error type. A higher precision value indicates that the model makes fewer incorrect predictions when identifying specific errors.
Formula: Pₜ = Σᵢ∈ᴸ [eₜ,ᵢ = eₜ,ᵢ*] ÷ Σᵢ∈ᴸ [eₜ,ᵢ = TRUE]
Recall
Recall reflects the proportion of true instances of a specific error type that the model successfully identifies. This metric highlights the thoroughness of the model in capturing all relevant cases for each error type. In the formula for recall, Rₜ, the numerator represents the sum of correctly identified instances of error type t, while the denominator is the total number of true instances of that error type across all sentences. A higher recall value means the model captures a greater number of actual errors, minimizing the chances of missing relevant instances.
Formula: Rₜ = Σᵢ∈ᴸ [eₜ,ᵢ = eₜ,ᵢ] ÷ Σᵢ∈ᴸ [eₜ,ᵢ = TRUE]
F1 Score
The F1 score balances precision and recall, offering a harmonic mean that reflects both accuracy and thoroughness. This score is particularly useful when precision and recall exhibit trade-offs. The F1 formula averages the scores across all error types, using P_t and R_t to represent precision and recall for a specific error type. A higher F1 score indicates that the model performs well in both identifying errors correctly and ensuring most errors are detected.
Formula: F1 = (1 ÷ |E|) × Σₜ∈ᴱ [2 × Pₜ × Rₜ ÷ (Pₜ + Rₜ)]
By combining evidence retrieval with fine-grained editing, FAVA provides a robust framework for improving the factual accuracy of AI-generated content. Its reliance on external sources ensures that detections and corrections are grounded in reliable evidence, while its training on diverse error types equips it to address a wide range of hallucinations. FAVA’s performance was evaluated against baseline systems, including retrieval-augmented ChatGPT and GPT-4, using F1 scores as a measure of fine-grained detection across various hallucination types. The table below highlights FAVA’s ability to outperform its counterparts in identifying errors across categories like entity errors, invented information, and contradictory sentences.
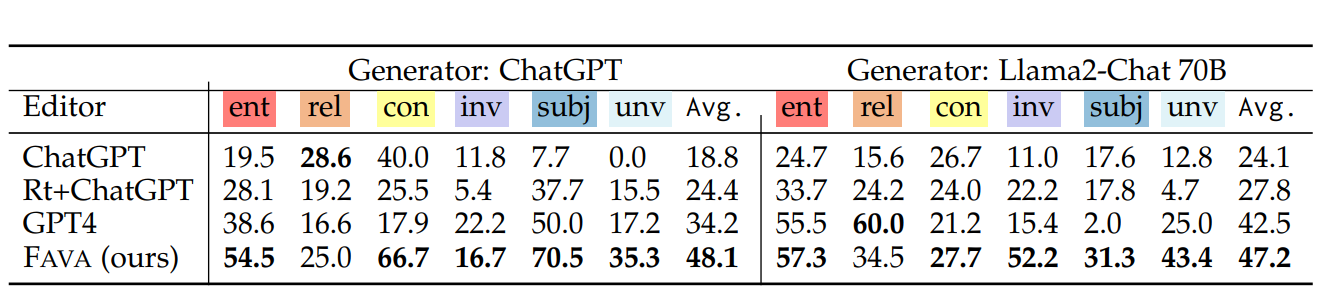
Figure: Results on fine-grained detection (metric: F1)
The results, based on F1 scores, indicate that FAVA’s approach of combining retrieval and editing significantly outperforms its counterparts across various hallucination types. For example, FAVA achieves an average F1 score of 48.1 when editing ChatGPT-generated outputs and 47.2 for Llama2-Chat 70B outputs, surpassing all baseline models in both cases. Its reliance on external evidence and training on diverse error types equips it to identify errors accurately, giving it a clear advantage in improving the reliability of AI outputs.
Applications and Implications of FAVA
The ability to identify and correct hallucinations makes FAVA particularly valuable in scenarios where AI outputs must meet high standards of accuracy. Its approach to categorizing errors and grounding corrections in reliable evidence positions it as a practical tool across several domains.
Healthcare
In healthcare, precision is paramount. AI systems are increasingly used for drafting patient care summaries, suggesting treatments, or analyzing research papers. Errors in these outputs, even minor ones, can have significant consequences. By validating claims and correcting inaccuracies, FAVA ensures that AI-generated medical information aligns with established knowledge, making these tools safer and more effective.
Education
Students and educators rely on AI for explanations, summaries, and research assistance. Hallucinations in educational content can introduce misinformation, leading to misunderstandings. FAVA’s focus on identifying specific types of errors helps improve the quality of educational materials, ensuring that learners have access to accurate and verifiable information.
Journalism and Content Creation
For journalists and content creators, factual errors in AI-generated drafts can damage credibility. Whether generating summaries, reports, or articles, outputs must adhere to verifiable facts. FAVA’s ability to detect and address fabricated claims or unverifiable statements ensures that content remains reliable, even when produced at scale.
Sensitive Applications
Fields such as legal, governmental, and financial analysis often deploy AI to process large amounts of text or generate reports. In these domains, errors can have far-reaching implications. FAVA’s capability to correct errors before outputs are finalized ensures that these systems can operate with the reliability demanded in high-stakes environments.
By refining AI-generated content for accuracy and credibility, FAVA opens new opportunities for responsible AI use in critical areas. Its approach to error correction addresses specific challenges faced in real-world applications, enhancing the practical value of AI in professional and sensitive domains.
Limitations and Future Directions for FAVA
While FAVA marks progress in addressing hallucinations in AI outputs, certain limitations restrict its current capabilities.
Limitations
Retrieval DependencyFAVA’s reliance on external sources for evidence restricts its ability to handle claims when relevant or accurate information is not readily available. Limiting the model to the top five retrieved documents can reduce its effectiveness in addressing complex claims requiring a broader evidence base.
Performance on Complex ErrorsFAVA is more effective at handling straightforward errors like incorrect entities and contradictory sentences but faces challenges with complex error types such as invented statements or unverifiable claims. These require deeper contextual verification that the current approach does not fully address.
Subjectivity in AnnotationThe taxonomy relies on subjective human annotations for error categorization, particularly for ambiguous categories like subjective statements or unverifiable claims. This introduces inconsistency, as interpretations can vary among annotators.
Synthetic Data LimitationsThe synthetic dataset used for training, while diverse and controlled, may not fully capture the subtlety or complexity of real-world hallucinations. This can limit FAVA’s ability to generalize to real-world inputs that differ from its training scenarios.
These challenges provide opportunities for refinement and future development.
Future Directions
Enhancing Retrieval MechanismsImproving retrieval processes to incorporate a broader range of evidence sources and refine document selection could strengthen FAVA’s ability to verify complex claims. Incorporating domain-specific databases or real-time information retrieval may further enhance its accuracy.
Expanding the TaxonomyExtending the taxonomy to include additional types of errors, such as logical inconsistencies, numerical inaccuracies, or contextual mismatches, would allow FAVA to address a wider range of hallucinations. A more comprehensive taxonomy would also benefit applications beyond information-seeking scenarios.
Scalable and Efficient Data GenerationDeveloping methods for generating high-quality training data at scale is essential to reduce costs and improve realism. Leveraging semi-automated approaches or advanced models to create diverse training instances could address the limitations of synthetic datasets.
Improving Evaluation BenchmarksExpanding the size and diversity of evaluation datasets like FAVABENCH would provide a more accurate measure of model performance. Incorporating scenarios from varied domains, including long-form text and domain-specific challenges, could better reflect real-world use cases.
By addressing these areas, FAVA can evolve into a more robust tool capable of handling diverse and complex scenarios.
Conclusion
FAVA addresses the critical challenge of hallucinations in AI by combining evidence retrieval with fine-grained error detection and correction. Its detailed taxonomy, evaluation benchmark, and training on diverse error types enhance the factual accuracy of AI outputs, making it a valuable tool for real-world applications. While limitations like retrieval dependency and challenges with complex claims remain, future improvements in retrieval processes, data generation, and taxonomy expansion will further strengthen FAVA’s capabilities. As AI continues to shape industries like healthcare, education, and journalism, tools like FAVA are crucial for ensuring reliability and trust in AI systems.
Keep Reading

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.