




Building Secure RAG Workflows with Chunk-Level Data Partitioning
Vector databases have become a cornerstone for powering AI-driven applications, particularly RAG (retrieval augmented generation), enabling fast and efficient similarity searches across massive high-dimensional datasets. Effective partitioning becomes crucial as these databases scale to accommodate billions of vectors. By organizing data into logical segments, partitioning enhances query performance, supports scalability, and ensures secure data management through per-tenant isolation in multi-user environments.
Modern vector databases, such as Milvus and Zilliz Cloud (the managed Milvus), have introduced advanced partitioning features to address the demands of enterprise applications. However, as the number of partitions grows, so does the complexity of managing them effectively. Enterprises now seek privacy-first solutions that can scale partitioning while seamlessly integrating with AI workflows.
At a recent South Bay Unstructured Data Meetup hosted by Zilliz, Rob Quiros, CEO and Co-founder of Caber Systems, shared an innovative approach to partitioning vector databases using per-user, per-chunk access policies. He elaborated on how integrating permissions and authorization into partitions can secure data at the chunk level, addressing privacy concerns. This blog will recap his insights and explore how Caber Systems leverages the Milvus vector database to achieve robust, privacy-centric data management. For more details, watch the full replay of his talk on YouTube.
Challenges in Access Control for Vector Databases
Modern vector databases, like Milvus, effectively support multi-tenancy, allowing separate storage and management for distinct customer datasets. This capability ensures that one tenant's data is isolated and inaccessible to others, forming a robust foundation for secure and organized data management. However, while this separation caters well to overarching data isolation, implementing granular user-specific access controls within these datasets is more challenging. This is due to the diversity in access control modes that enterprises require.
Some of them are:
Role-Based Access Control (RBAC) - Assigns permissions based on predefined roles but struggles with complex, dynamic requirements.
Attribute-Based Access Control (ABAC) - Uses attributes like user roles, data sensitivity, or geographic location but requires a robust policy management system.
Relationship-Based Access Control (ReBAC) - Provides access based on relationships between departments or teams, adding complexity to enforcement mechanisms.
Additionally, providing and managing such access controls can become an administrative nightmare. From assigning permissions to handling access requests or disputes, the operational overhead can also overwhelm support teams. The figure below from Permit.io presents an example of ReBAC control. It illustrates a complicated process for accessing a specific chunk of data valid only during the ongoing session.
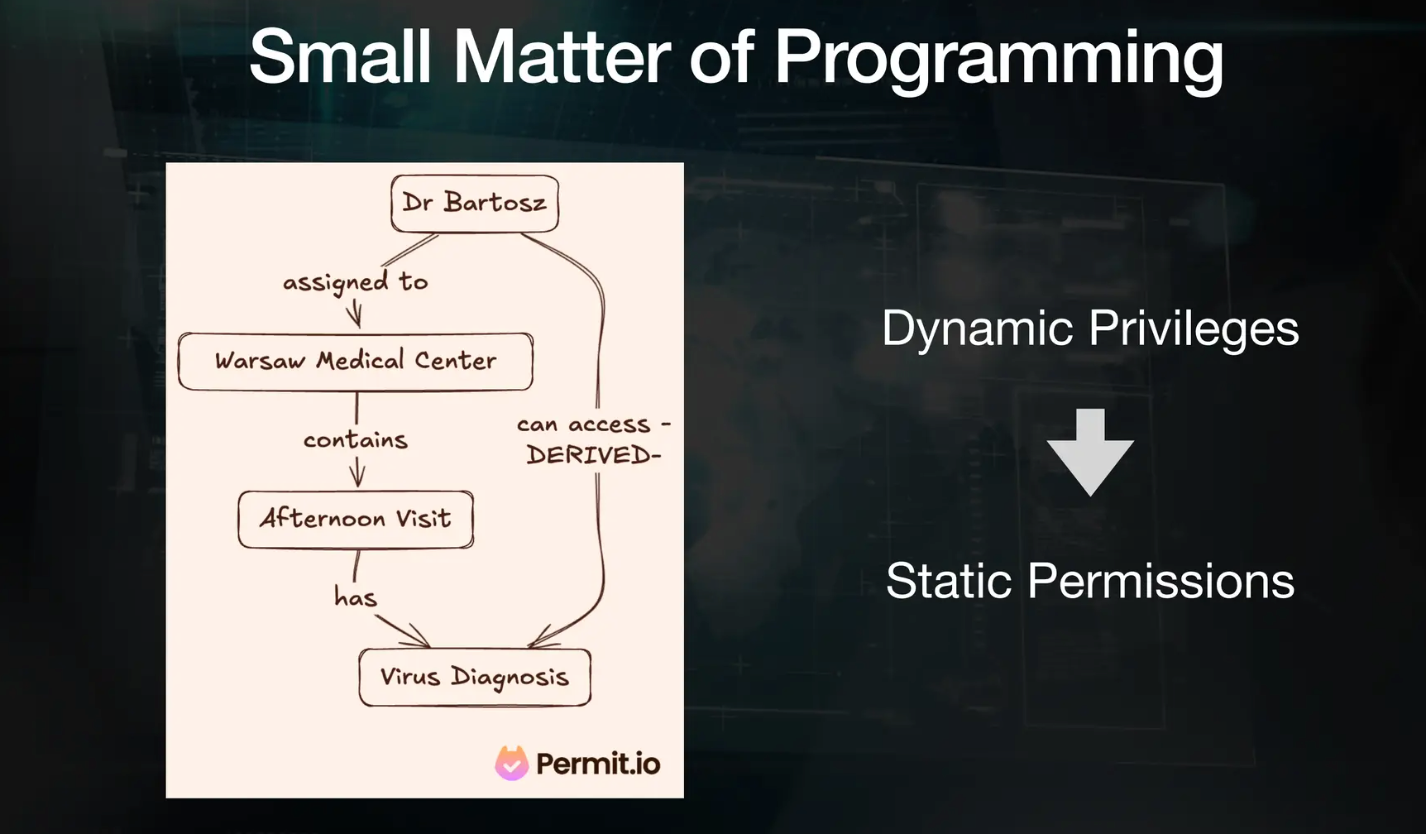 Figure: An example of ReBAC control
Figure: An example of ReBAC control
Figure: An example of ReBAC control
The Role of Agents in Data Access
In RAG systems, the agents acting on the users' behalf query vector databases and retrieve information. While they improve efficiency by automating the task, they pose a significant security challenge. Agents operate as proxies for user actions, which means they inherit user permissions during the data access. This mechanism, however, is vulnerable to attacks:
Agent Spoofing: Malicious actors can impersonate agents, exploiting user credentials to access sensitive data.
Data Leakage: If an agent’s session is compromised, it could grant unauthorized access to vast amounts of data.
 Figure: Security issues with Agentic RAG
Figure: Security issues with Agentic RAG
Figure: Security issues with Agentic RAG
To mitigate these risks, organizations must adopt stringent measures:
Authentication: Strong agent authentication to verify identities and prevent spoofing.
Session Management: Restrict agent sessions to predefined durations, as Reback demonstrated.
Logging and Monitoring: Comprehensive audit trails to track agent activity and detect anomalies.
While taking these measures can help tackle the attacks, implementing it all becomes very tedious.
Data Duplication - A Significant Challenge for Enterprises
Data duplication is a persistent issue in enterprise environments. Documents often undergo multiple iterations through copy-pasting, file sharing, or versioning, leading to redundant chunks stored in vector databases. This duplication increases storage overhead and deteriorates the generalisability of LLMs. Rob mentions his prior experience with data deduplication at Riverbed, where they encountered 90-95% of the data as duplicates, which had to be eliminated.
 Figure: Data duplication is a big challenge in setting permissions
Figure: Data duplication is a big challenge in setting permissions
Figure: Data duplication is a big challenge in setting permissions
A major complication arises when metadata, including permissions, is copied directly from documents to chunks in vector databases. If duplicate chunks exist across different documents with varying permissions, the metadata may be overwritten, causing conflicts or improper access controls. Therefore, resolving permissions at the chunk level is crucial to ensure data security and compliance.
Below is an example of the Apple 10-Q statement, wherein one can see that the boilerplate of both documents is common and that the differences between versions are minimal. Hence, here, the goal is to identify and track the origins of the data chunks and their associated permissions so that the correct access rules can be applied consistently.
 Figure: Example of similar documents from Apple’s 10Q filings
Figure: Example of similar documents from Apple’s 10Q filings
Securing Data at the Chunk Level
To address these issues, Caber proposed a solution to secure data at the chunk level. It does so by looking at the documents ingested into the vector database and constructing an index on the side to map the relationships between chunks and their sources. This lineage graph provides visibility into each chunk's origin and associated permissions, enabling deterministic assignment of permissions.
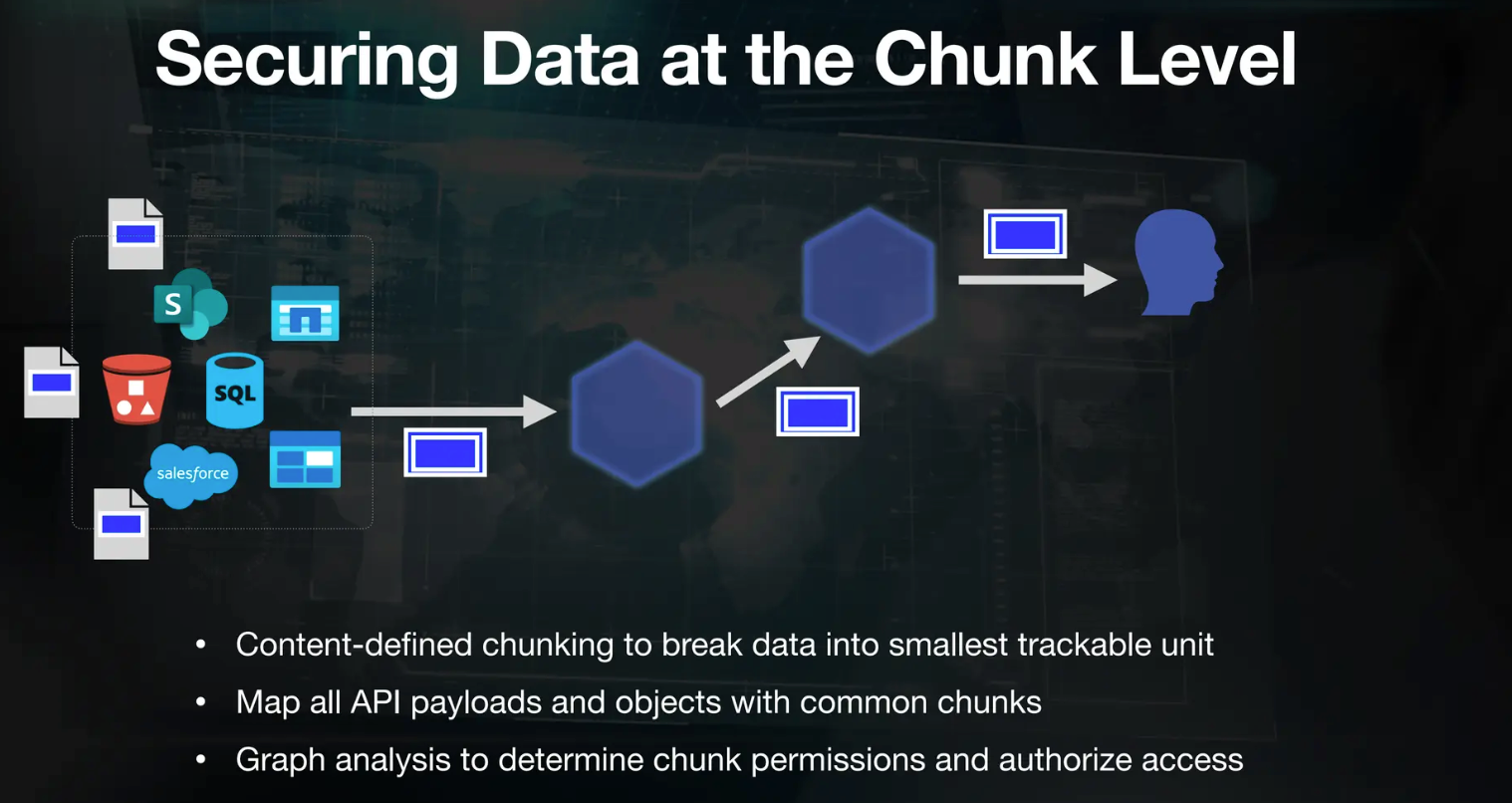 Figure- Caber’s approach to secure data at the chunk level
Figure- Caber’s approach to secure data at the chunk level
Figure: Caber’s approach to secure data at the chunk level (Source)
Example Lineage Graph with Apple’s 10Q Filings
Continuing Apple's example, the graph below contains data chunks from multiple versions of Apple’s 10-Q filings. The red nodes in the graph represent the common data chunks across all documents. Using a policy, the permissions for each of these chunks are determined. These permissions are then looked at while the data is being retrieved from the vector database to ensure the users have appropriate authorization to access these chunks.
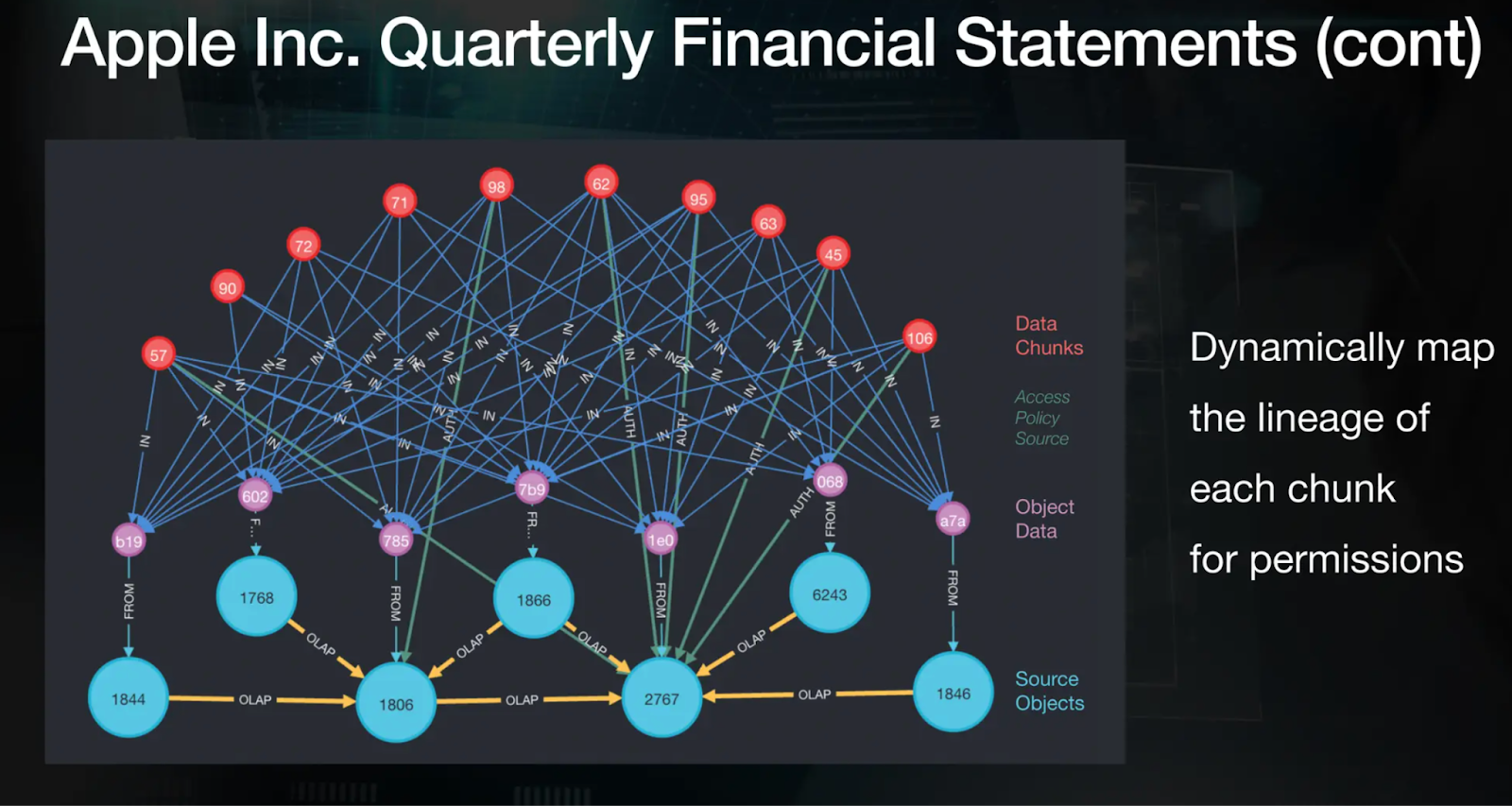 Figure: Dynamic mapping of the lineage of each chunk for permissions with Caber
Figure: Dynamic mapping of the lineage of each chunk for permissions with Caber
Example RAG Demo with Apple’s 10Q Filings
Initially, the data is stored in the vector database like Milvus without permissions metadata. When the data comes out from RAG, Caber’s integration into the workflow through an SDK allows for the filtering and redacting of this data at a granular level before it can be passed to the LLM. For instance, the figure demonstrates the access authorization for two different users - Amy, CFO of the company, is authorized to access all data chunks from 2023 and 2024 10Q statements. In contrast, Bob, another user, has been restricted to the same access and receives a generic answer.
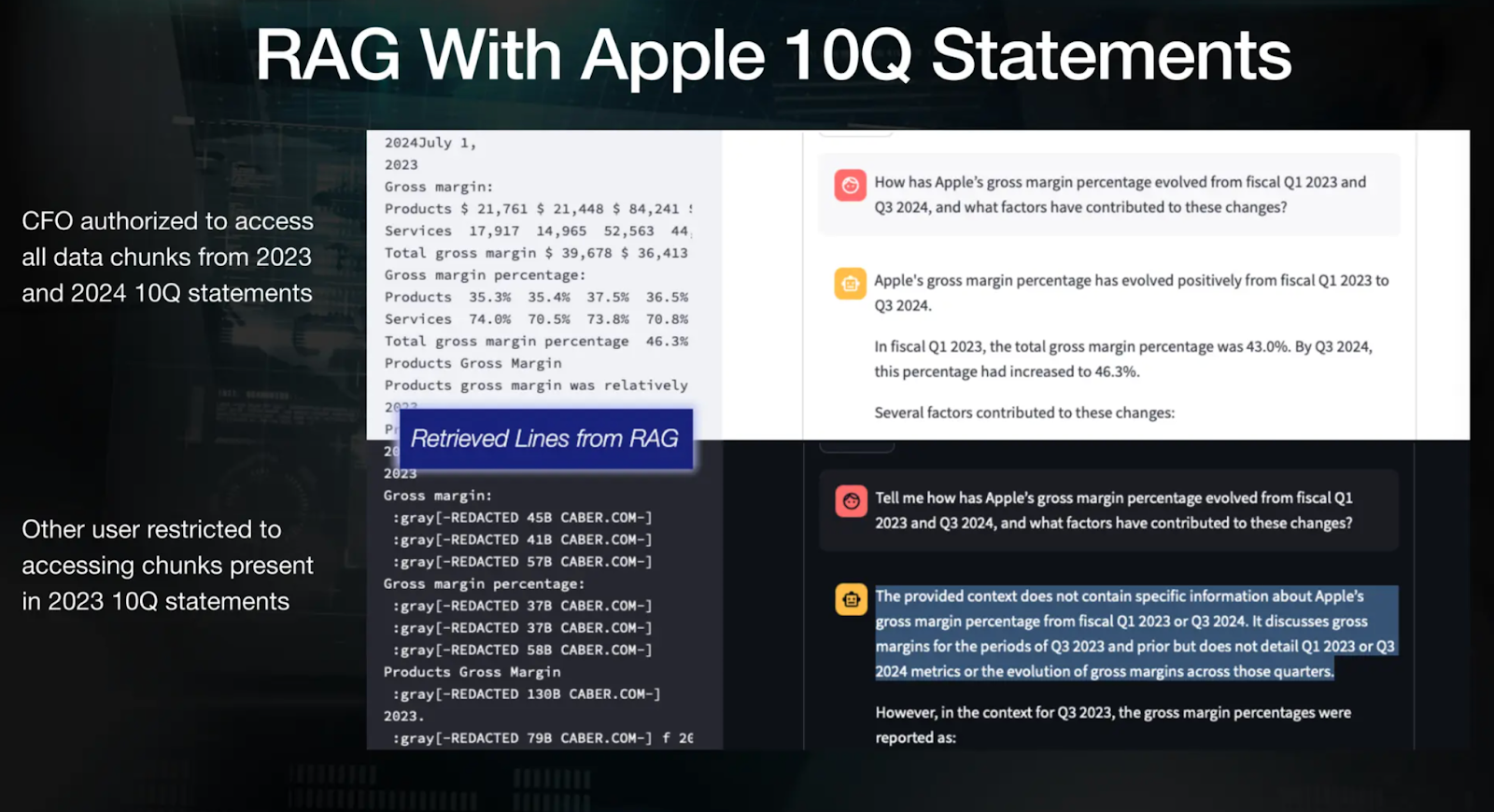 Figure: RAG example demonstrating varying access for two users
Figure: RAG example demonstrating varying access for two users
Caber’s Integration with LLM Workflows and Its Capabilities
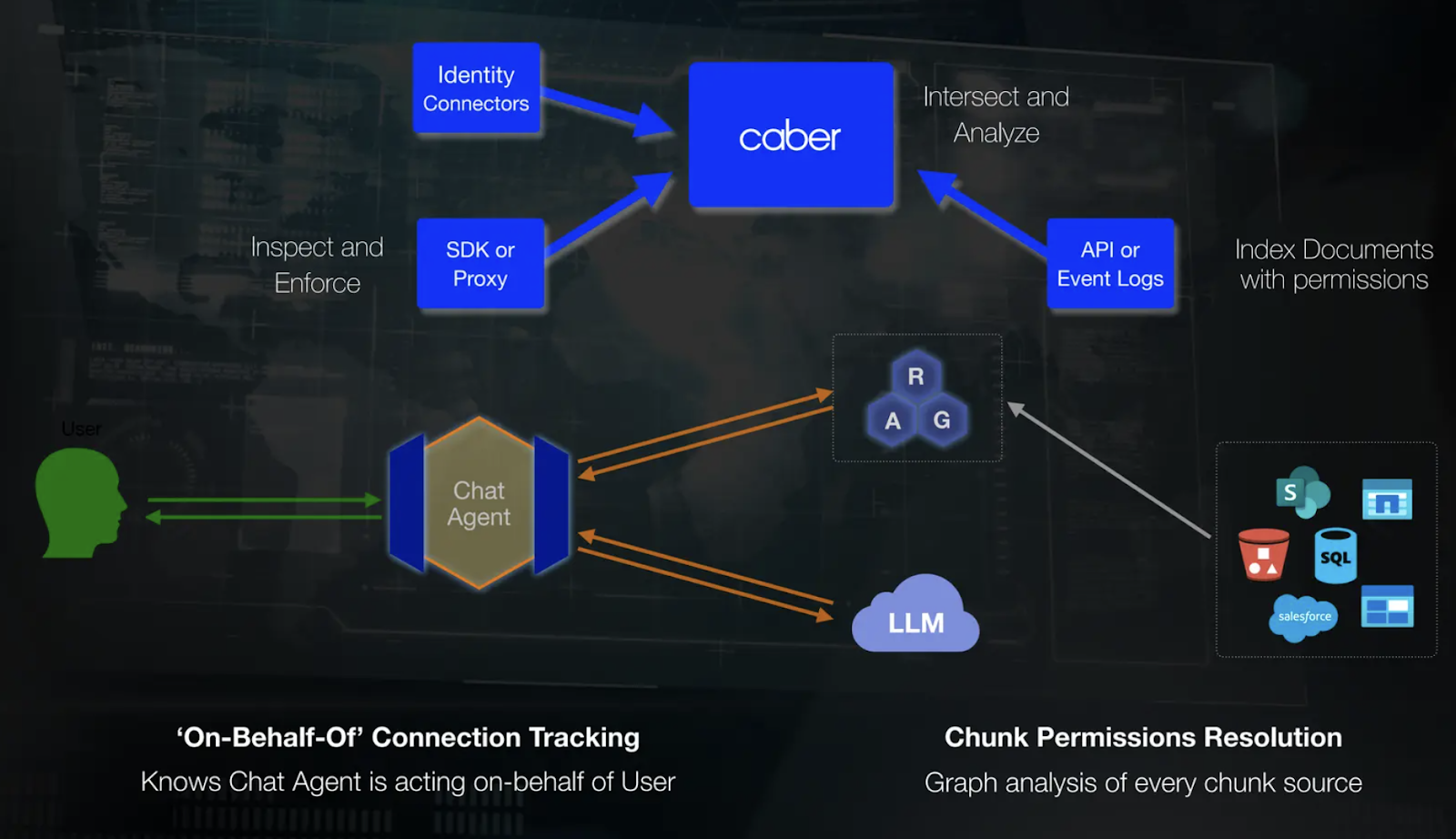 Figure: Caber integrates with LLM workflows
Figure: Caber integrates with LLM workflows
Caber can be integrated with LLM workflows using an SDK, allowing seamless access control management. Through identity connectors, the system retrieves user authentication information whereas other connectors help to build an index of data chunks along with their associated permissions. For example, when a user interacts with the system, the agent passes the prompt to the vector database. The RAG response is then sent to the LLMs which provide the final answer. During this process, the data is traced based on its flow and all the connections will be attributed to the particular user.
Here, using Milvus as the vector database helps support dynamic partitioning and multi-tenancy, making it ideal for privacy-focused applications requiring per-chunk access control. With features like HNSW indexing, it ensures high-speed queries across billions of vectors.
Accountability and Auditability
The traceability that Caber provides offers critical accountability and audit capabilities. Particularly in complex scenarios involving Agentic AI, where LLMs autonomously act on behalf of users, as the actions are quite unpredictable there is a high chance of something going wrong (for eg: sensitive data getting leaked). Here, the knowledge of how the data moved through various API and object calls is essential to find out at what exact step the system failed.
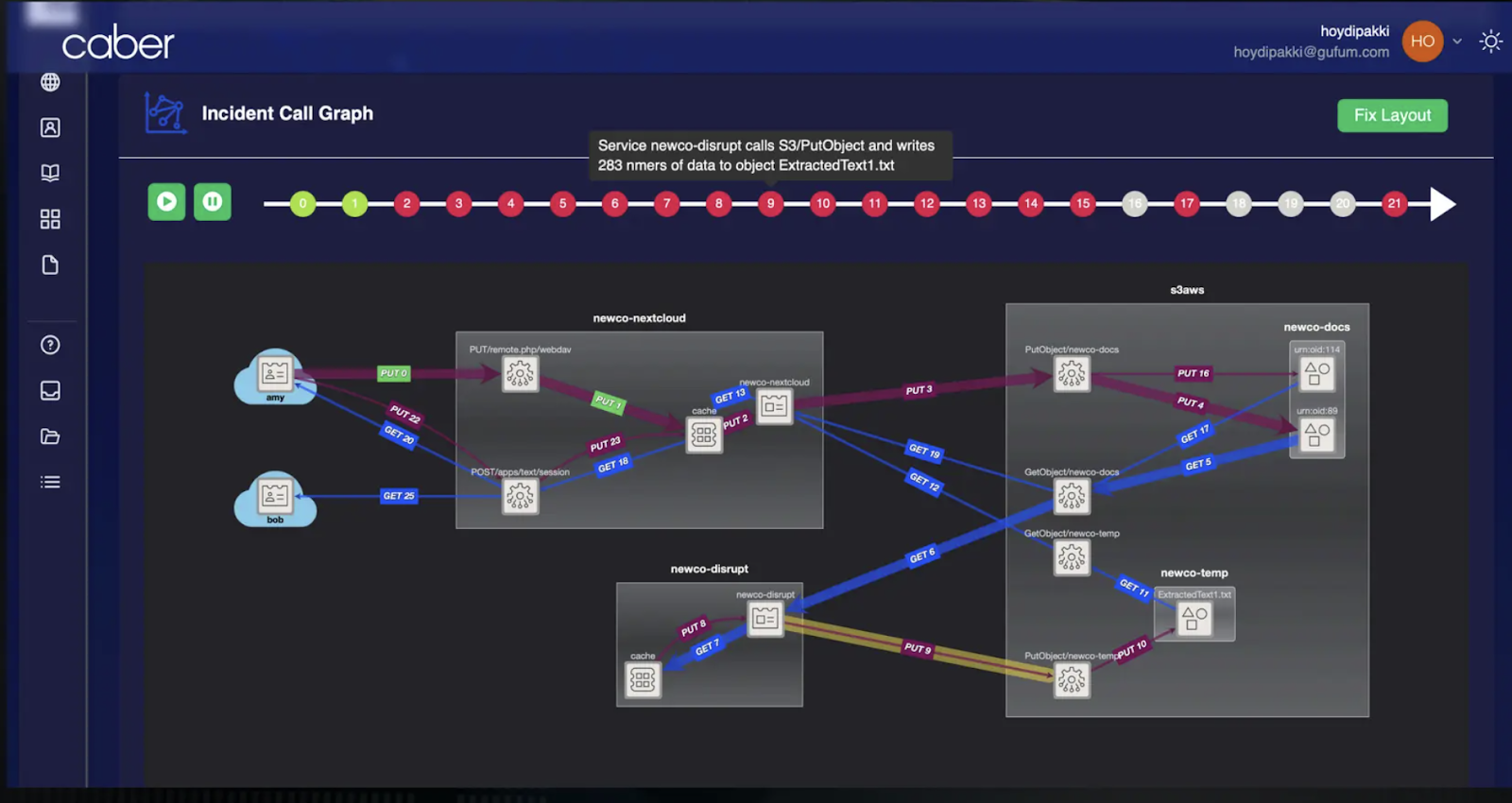 Figure: Accountability and Auditability
Figure: Accountability and Auditability
Detailed Observability of Application Flow
Caber also allows analysis and debugging of application tools through detailed observability of the application flow. The ability to track when and by which services the user’s data was accessed allows organizations to better identify bottlenecks, inefficiencies, and security risks within the application’s data pipelines.
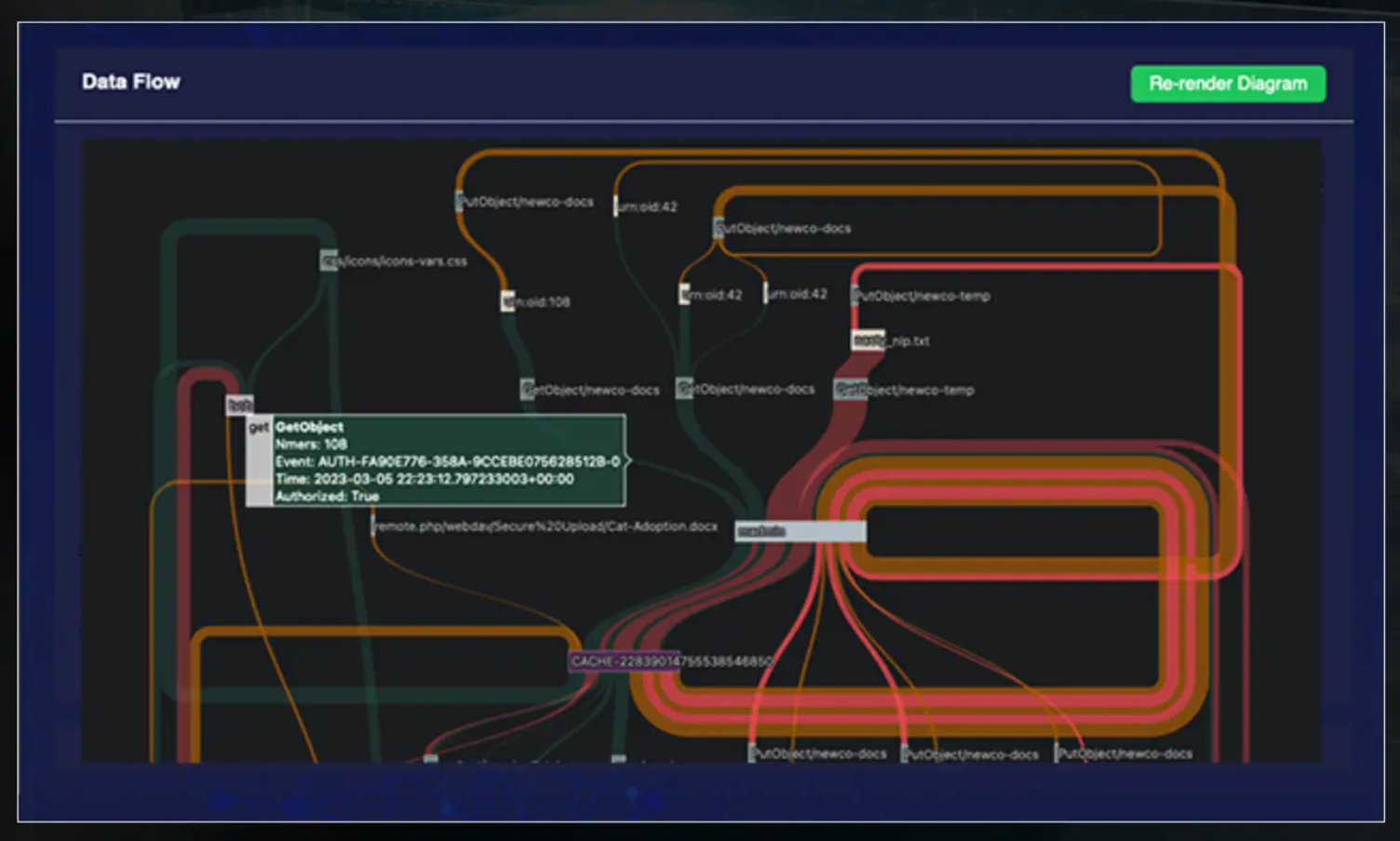 Figure: Observability of Application Flow
Figure: Observability of Application Flow
Data Compliance Requirements to Policy
The insights obtained from above can be fed back into LLMs to improve security policies and address gaps proactively. The framework supports access control, auditability, remediation, and analysis, ensuring compliance and enhancing system resilience.
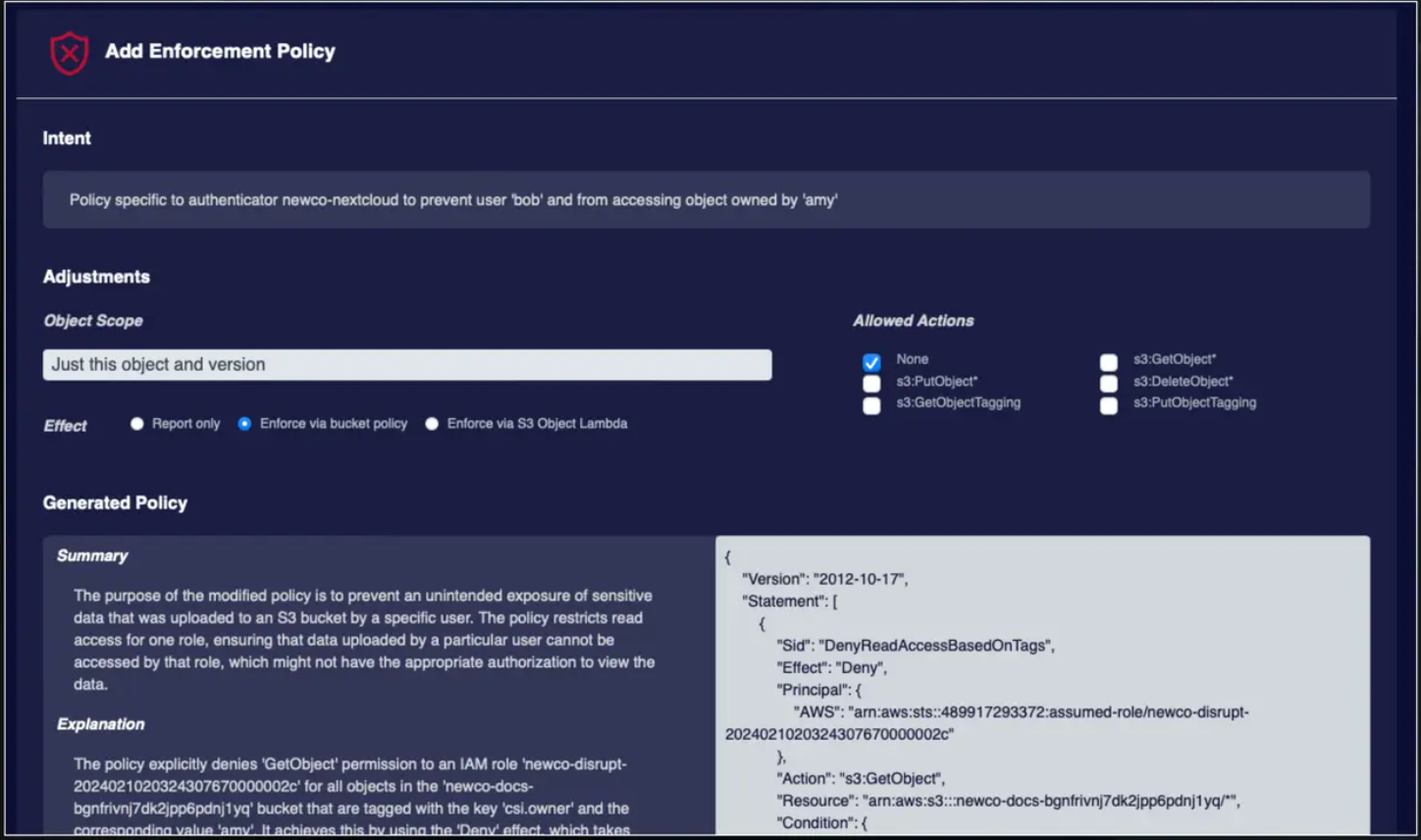 Data Compliance Requirements to Policy.png
Data Compliance Requirements to Policy.png
Data Compliance Requirements to Policy (Source)
Conclusion
As the use cases of LLM applications grow, more enterprises rely on RAG to perform their tasks. Hence, securing and managing data access at a granular level becomes very important. Solutions like Caber, combined with Milvus’s advanced partitioning and searching capabilities, provide the ideal framework for tackling challenges such as data duplication and setting the access control for secure use of data.
Relevant Resources
Keep Reading

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.