




Масштабный бенчмарк текстовых эмбеддингов (MTEB)
Масштабный бенчмарк текстовых эмбеддингов (MTEB)
Текстовые эмбеддинги часто тестируются на небольшом количестве наборов данных только из одной задачи, что не показывает, насколько хорошо они работают для других задач. Неясно, работают ли лучшие эмбеддинги для семантического текстового сходства (STS) одинаково хорошо для таких задач, как кластеризация или реранжирование. Это затрудняет оценку прогресса в этой области, поскольку новые модели и эмбеддинги обычно оцениваются и постоянно предлагаются без согласованного тестирования.
Чтобы решить эту проблему, исследователи создали Massive Text Embedding Benchmark (MTEB). MTEB охватывает 8 задач эмбеддингов на 58 наборах данных на 112 языках. Исследователи протестировали 8 задач эмбеддингов, охватывающих 33 модели, на MTEB, что делает его самым полным на сегодняшний день бенчмарком для текстовых эмбеддингов.
Они обнаружили, что ни один метод эмбеддингов не является лучшим для всех задач. Это говорит о том, что универсальный метод текстовых эмбеддингов, который лучше всего работает для всех задач эмбеддингов, еще не разработан, даже при масштабировании. Это также подчеркивает важность тщательной проверки, чтобы выбрать модели эмбеддингов, которые лучше всего соответствуют вашим требованиям.
MTEB поставляется с кодом с открытым исходным кодом, публичной таблицей лидеров и увлекательной MTEB Arena, где можно голосовать за такие вещи, как какие модели извлекают лучший документ, лучше выполняют кластеризацию и т. д., — все это на сайте Hugging Face. Этот бенчмарк поможет сообществу последовательно тестировать новые методы и отслеживать улучшения в технологии текстовых эмбеддингов.
Предпосылки и мотивация
Текстовые эмбеддинги стали ключевой частью многих задач обработки естественного языка (NLP). Эти эмбеддинги преобразуют слова, предложения или документы в числовые представления, которые отражают их смысл. Они используются в различных приложениях, таких как машинный перевод, распознавание именованных сущностей, ответы на вопросы, анализ тональности и суммаризация.
За прошедшие годы исследователи создали множество наборов данных и бенчмарков для тестирования этих эмбеддингов. Среди известных примеров — SemEval, GLUE, SuperGLUE, Big-Bench, WordSim353 и SimLex-999. Обычно они сосредоточены на оценке стандартных и контекстуальных эмбеддингов слов.
Однако в оценке текстовых эмбеддингов все еще есть некоторые пробелы:
Немногие бенчмарки охватывают как эмбеддинги слов, так и эмбеддинги предложений.
Многие оценки сосредоточены на конкретных задачах NLP, а не на том, насколько хорошо эмбеддинги отражают общий смысл текста.
Существующие бенчмарки часто не учитывают, как эмбеддинги могут использоваться в реальных приложениях.
Существует потребность во всеобъемлющем бенчмарке, который может оценивать широкий спектр задач понимания текста. Такой бенчмарк должен быть полезен как исследователям NLP, так и людям, работающим над практическими приложениями. Massive Text Embedding Benchmark (MTEB) стремится заполнить этот пробел.
Текстовые эмбеддинги
Текстовый эмбеддинг — это способ представить текст в виде списка чисел. Эти числа могут представлять отдельное слово, предложение или даже целый документ. Обычно список состоит из сотен чисел.
Текстовые эмбеддинги используются во многих задачах NLP. Для слов они применяются в таких вещах, как проверка орфографии и поиск связей между словами. Для более длинных текстов они используются в задачах вроде определения тональности фрагмента текста или генерации нового текста.
Существует множество различных способов создания текстовых эмбеддингов. Некоторые популярные методы включают:
Методы на основе языковых моделей, такие как ULMFit, GPT, BERT и PEGASUS
Методы, обученные на различных задачах NLP, такие как ELMo
Методы на основе слов, такие как word2vec и GloVe, которые часто используются в исследованиях компьютерного зрения
Исследователи создали множество различных эмбеддингов — есть как минимум 165 для сравнения. Они также создали 15 различных инструментов (например, деревья решений и Random Forests), чтобы помочь понять сильные и слабые стороны этих эмбеддингов.
Однако стандартного способа сравнивать все эти разные эмбеддинги не существует. Именно эту проблему пытается решить Massive Text Embedding Benchmark (MTEB).
Проектирование и реализация Massive Text Embedding Benchmark
MTEB был разработан с учетом нескольких важных целей:
Разнообразие: MTEB тестирует модели эмбеддингов на множестве различных задач. Он включает 8 различных типов задач, до 15 наборов данных для каждой. Из 58 наборов данных в общей сложности 10 работают с несколькими языками, охватывая в сумме 112 языков. Бенчмарк тестирует как короткие (на уровне предложений), так и длинные (на уровне абзацев) тексты, чтобы увидеть, как модели справляются с разной длиной текста.
Простота: MTEB прост в использовании. Можно протестировать любую модель, которая может принимать список текстов и выдавать список числовых представлений (векторов). Это означает, что можно сравнивать множество различных типов моделей.
Расширяемость: В MTEB легко добавлять новые наборы данных. Для существующих задач нужно лишь добавить файл, который описывает задачу и указывает, где данные хранятся на Hugging Face. Добавление новых типов задач требует немного больше работы, но MTEB приветствует вклад сообщества, чтобы помочь ему развиваться.
Воспроизводимость: MTEB облегчает повторение экспериментов. Он отслеживает различные версии наборов данных и программного обеспечения. Результаты в статье MTEB доступны в виде JSON-файлов, поэтому любой может их проверить или использовать.
Эти возможности делают MTEB комплексным и гибким инструментом для оценки моделей текстовых эмбеддингов в задачах, охватывающих в общей сложности широкий спектр задач и языков.
Задачи и оценка в Massive Text Embedding Benchmark
Massive Text Embedding Benchmark включает 8 различных типов задач для тестирования моделей эмбеддингов. Вот простое описание каждой задачи:
Bitext Mining: Поиск соответствующих предложений на двух разных языках. Основная метрика — F1 score.
Classification: Использование эмбеддингов для распределения текстов по категориям. Основная метрика — accuracy.
Clustering: Группировка похожих текстов. Основная метрика — v-measure.
Pair Classification: Определение того, похожи два текста или нет. Основная метрика — average precision.
Reranking: Упорядочивание списка текстов на основе того, насколько хорошо они соответствуют запросу. Основная метрика — MAP (Mean Average Precision).
Retrieval: Поиск релевантных документов для заданного запроса. Основная метрика — nDCG@10.
Semantic Textual Similarity (STS): Измерение того, насколько похожи два предложения. Основная метрика — корреляция Спирмена.
Summarization: Оценка машинно-сгенерированных резюме относительно написанных человеком. Основная метрика — также корреляция Спирмена.
Для каждой задачи MTEB использует модель эмбеддингов, чтобы преобразовать тексты в векторные эмбеддинги. Затем он использует методы вроде косинусного сходства или логистической регрессии, чтобы выполнить задачу и вычислить оценки.
MTEB включает множество наборов данных для каждой задачи, охватывающих разные языки и длины текстов. Это помогает проверить, насколько хорошо модели эмбеддингов работают в различных ситуациях.
Используя эти разнообразные задачи и наборы данных, Massive Text Embedding Benchmark предоставляет комплексный способ оценки и сравнения различных моделей текстовых эмбеддингов.
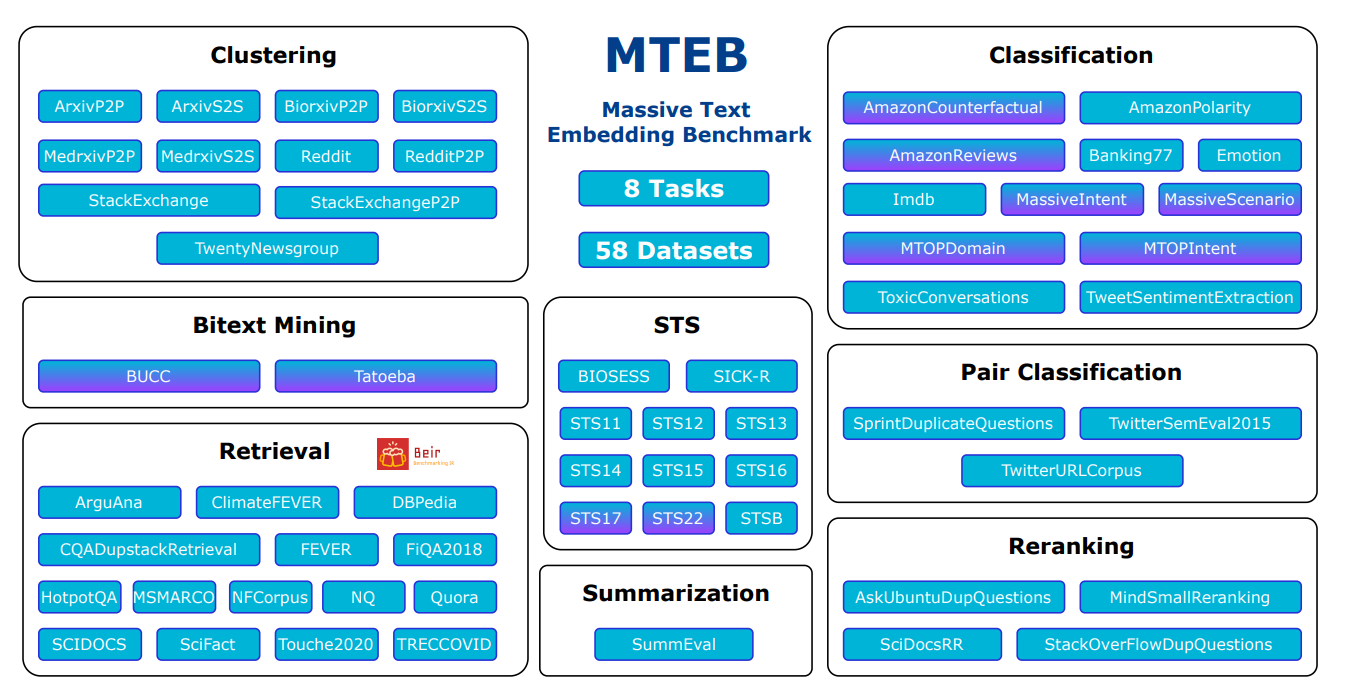 Обзор задач и наборов данных в MTEB
Обзор задач и наборов данных в MTEB
Источник: MTEB: Massive Text Embedding Benchmark
Наборы данных в Massive Text Embedding Benchmark
Massive Text Embedding Benchmark использует множество различных наборов данных для тестирования конкретного метода и моделей текстовых эмбеддингов. Эти наборы данных сгруппированы в три основных типа в зависимости от длины сравниваемых текстов:
Предложение к предложению (S2S): Это когда одно предложение сравнивается с другим. Например, в задачах семантического текстового сходства цель — определить, насколько похожи два предложения.
Абзац к абзацу (P2P): Это включает сравнение более длинных фрагментов текста. MTEB не устанавливает ограничение на их длину, оставляя моделям возможность обрабатывать более длинные тексты при необходимости. Некоторые задачи, такие как кластеризация, выполняются как в формате S2S (сравнение только заголовков), так и в формате P2P (сравнение заголовков и содержимого).
Предложение к абзацу (S2P): Это используется в некоторых задачах поиска, где короткий запрос (предложение) сравнивается с более длинными документами (абзацами).
MTEB включает 56 различных наборов данных. Некоторые из этих наборов данных похожи друг на друга:
Некоторые используют одни и те же базовые текстовые данные (например, ClimateFEVER и FEVER).
Наборы данных для похожих задач (например, разные версии CQADupstack или STS) обычно похожи.
Версии S2S и P2P одного и того же набора данных часто похожи.
Наборы данных по похожим темам (например, научные статьи) обычно похожи, даже если они предназначены для разных задач.
Используя такой широкий спектр наборов данных, MTEB может проверять, насколько хорошо модели эмбеддингов работают с разными типами текста и разными задачами. Это помогает получить более полное представление о сильных и слабых сторонах каждой модели.
Модели в первоначальном бенчмаркинге Massive Text Embedding Benchmark
Для первого раунда тестирования с MTEB исследователи рассмотрели модели, которые заявляют о себе как о лучших, а также те, которые популярны на Hugging Face Hub. Это означало, что они протестировали множество трансформерных моделей. Они сгруппировали модели в три типа, чтобы помочь людям выбрать лучшую для своих потребностей:
Самые быстрые модели: Модели вроде Glove очень быстрые, но они плохо понимают контекст. Это означает, что в целом они получают не такие высокие оценки в MTEB.
Сбалансированные модели: Модели вроде all-mpnet-base-v2 или all-MiniLM-L6-v2 немного медленнее самых быстрых, но работают намного лучше. Они предлагают хорошее сочетание скорости и качества.
Модели с наивысшей производительностью: Большие модели с миллиардами параметров, такие как ST5-XXL, GTR-XXL или SGPT-5.8B-msmarco, показывают лучшие результаты в MTEB. Но они могут быть медленнее и требовать больше места для хранения. Например, SGPT-5.8B-msmarco создает эмбеддинги с 4096 числами, что занимает больше пространства.
Важно отметить, что эффективность модели может сильно меняться в зависимости от конкретной задачи и набора данных. Исследователи предлагают проверять таблицу лидеров MTEB, чтобы понять, какая модель может лучше всего подойти для отдельной задачи и ваших конкретных потребностей.
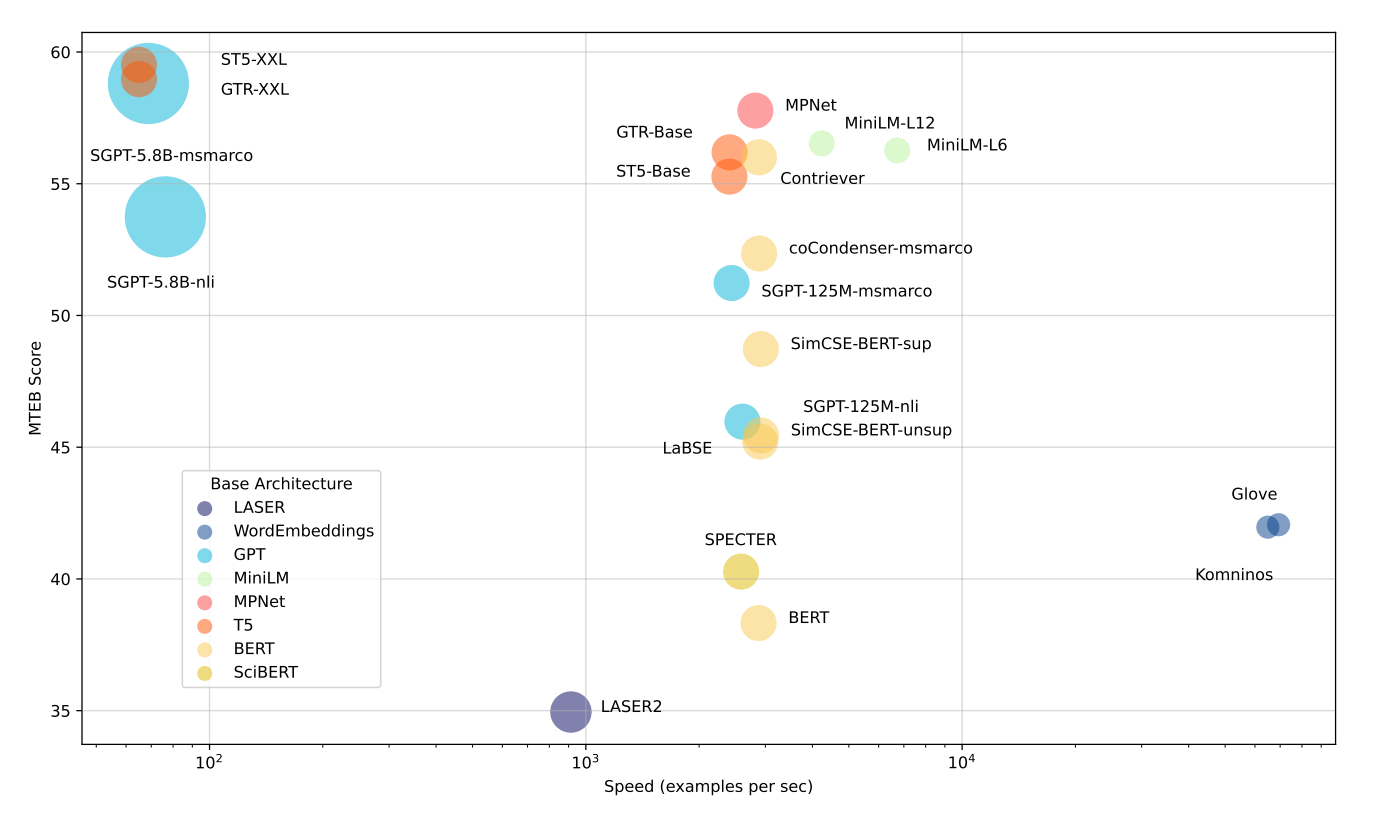 Результаты бенчмарков первоначального теста
Результаты бенчмарков первоначального теста
Источник: MTEB: Massive Text Embedding Benchmark
Такой подход к тестированию дает ясное представление о компромиссах между скоростью и производительностью в разных моделях эмбеддингов, помогая пользователям принимать обоснованные решения с учетом их конкретных требований. Если вы хотите попробовать самостоятельно, на Huggigng Face есть отличный блог, который пошагово показывает, как провести бенчмаркинг любой модели, создающей векторные эмбеддинги.
Когда использовать Massive Text Embedding Benchmark
MTEB — это инструмент для тестирования того, насколько хорошо модели текстовых эмбеддингов работают на множестве разных задач. Он полезен в нескольких ситуациях:
Тестирование вашей модели: Если вы создали новую модель эмбеддингов, вы можете использовать MTEB, чтобы увидеть, как она сравнивается с другими моделями. Вы можете добавить свои результаты в публичную таблицу лидеров, что поможет вам понять, как ваша модель выглядит на фоне других.
Выбор подходящей модели: Разные модели лучше подходят для разных задач. Таблица лидеров MTEB показывает, как модели справляются с различными задачами, помогая вам выбрать лучшую модель для ваших конкретных потребностей.
Помощь в улучшении MTEB: MTEB имеет открытый исходный код и поэтому открыт для вклада любого желающего. Если вы создали новую задачу, датасет, способ измерения производительности или модель, вы можете добавить это в MTEB. Это помогает сделать бенчмарк еще лучше.
Исследования: Если вы изучаете текстовые эмбеддинги, MTEB дает вам тщательный способ тестировать модели. Он может показать, на что способны лучшие современные модели и где есть возможности для улучшения.
Предоставляя стандартный способ тестирования моделей на множестве задач, MTEB помогает исследователям и разработчикам понимать и совершенствовать технологию текстовых эмбеддингов. Это ценный инструмент для всех, кто работает с текстовыми эмбеддингами или изучает их.
Как использовать таблицу лидеров Massive Text Embedding Benchmark
Прежде всего, не дайте себя ввести в заблуждение оценками MTEB!
MTEB — полезный инструмент, но важно понимать его ограничения. Хотя он показывает оценки, он не сообщает, являются ли различия между оценками значимыми. У многих лучших моделей очень близкие средние оценки, которые получены из множества разных задач, но нет информации о том, насколько эти оценки варьируются. Лучшая модель может выглядеть лучше, но разница может быть неважной. Пользователи могут получить сырые результаты, чтобы проверить это самостоятельно. Некоторые исследователи обнаружили, что несколько лучших моделей в определенных языковых бенчмарках на самом деле одинаково хороши со статистической точки зрения. Вместо того чтобы смотреть только на средние оценки, лучше сосредоточиться на том, как модели работают на задачах, похожих на предполагаемый сценарий использования. Это может дать больше понимания того, как модель будет работать в конкретном приложении, чем общий балл. Не обязательно подробно изучать датасеты, но полезно знать, какой тип текста они содержат. Эта информация обычно доступна в описании датасета и при быстром просмотре нескольких примеров. Massive Text Embedding Benchmark — полезный инструмент, но он не идеален. Важно критически относиться к результатам и к тому, как они применимы к конкретным потребностям. Вместо того чтобы просто выбирать модель с самым высоким общим баллом, лучше посмотреть глубже, чтобы найти лучшую модель для текущей задачи.
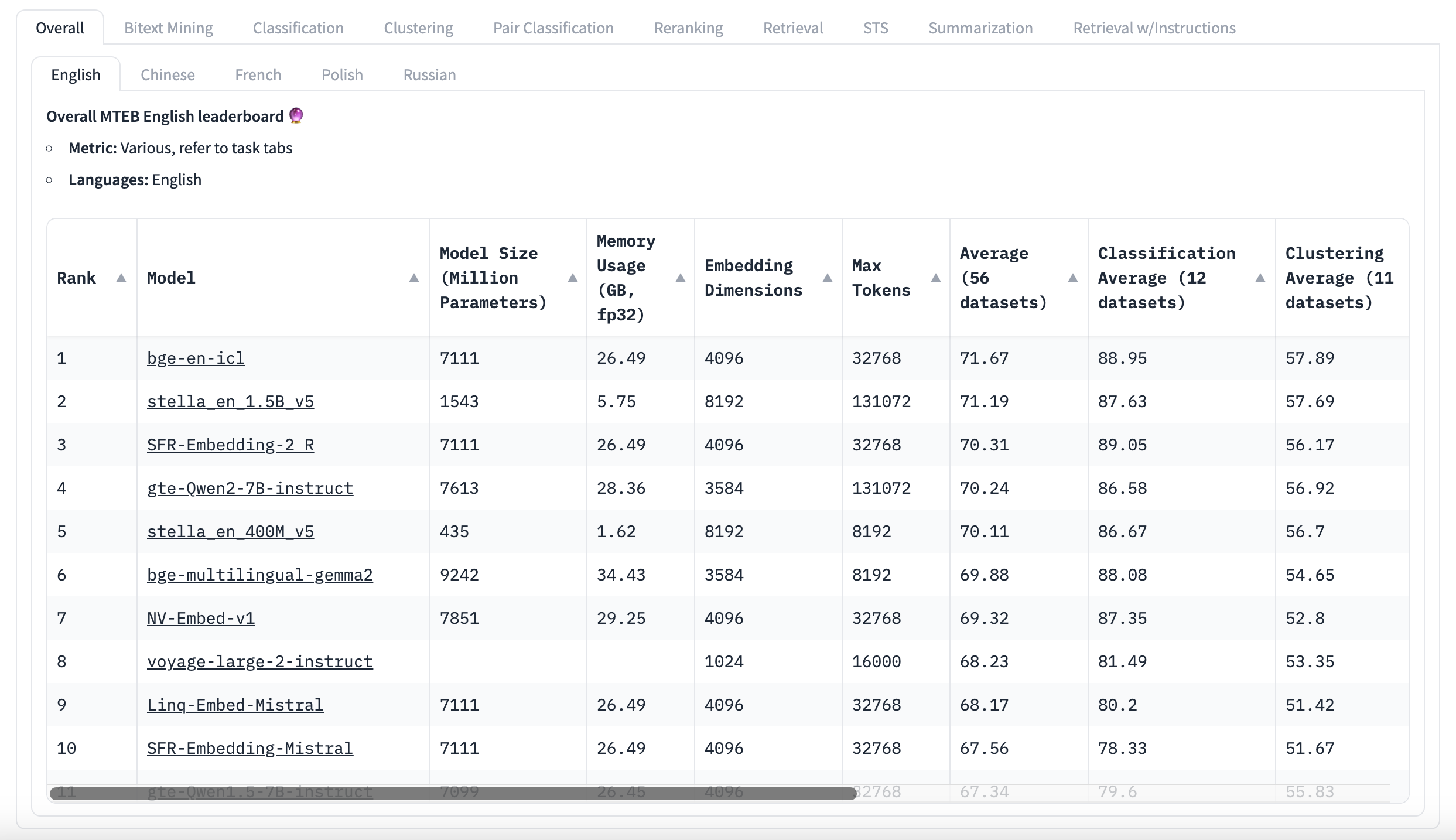 MTEB Leaderboard English
MTEB Leaderboard English
Не забывайте учитывать потребности вашего приложения
Не существует универсальной модели для каждой задачи. Именно поэтому существует Massive Text Embedding Benchmark — чтобы помочь вам выбрать подходящую модель для ваших конкретных потребностей. При просмотре таблицы лидеров Massive Text Embedding Benchmark важно подумать о том, что требуется вашему приложению. Вот некоторые моменты, которые стоит учитывать:
Язык: Поддерживает ли модель язык, с которым вы работаете?
Специализированная лексика: Если вы работаете с финансовыми или юридическими текстами, вам понадобится модель, которая понимает термины, специфичные для данной области.
Размер модели: Подумайте о том, где вы будете запускать модель. Должна ли она помещаться на ноутбуке?
Использование памяти: Сколько оперативной памяти компьютера вы можете выделить для модели?
Максимальная длина входных данных: Насколько длинными являются тексты, с которыми вы будете работать?
Как только вы поймете, что важно для вашей задачи, вы сможете отсортировать различные модели в таблице лидеров MTEB на основе этих характеристик. Это упрощает поиск модели, которая не только хорошо работает, но и соответствует вашим практическим требованиям.
Учитывая как производительность, так и практические потребности, вы можете выбрать модель, которая лучше всего подходит для вашей конкретной ситуации.
Ресурс Zilliz AI Model
Теперь, когда вы выбрали свою модель текстовых эмбеддингов из Massive Text Embedding Benchmark, давайте применим ее для создания текстовых эмбеддингов, которые можно хранить и извлекать в open source Milvus или Zilliz Cloud. На сайте Zilliz вы можете найти страницу AI Models, где перечислены некоторые из более популярных мультимодальных моделей и моделей текстовых эмбеддингов.
 Страница Zilliz AI Model
Страница Zilliz AI Model
После того как вы выберете модель на этой странице, вы увидите несколько подробных инструкций о том, как создавать векторные эмбеддинги с использованием различных SDK, PyMilvus и других инструментов.
Заключение
Massive Text Embedding Benchmark (MTEB) — это значительный шаг вперед в оценке моделей текстовых эмбеддингов. Он устраняет ограничения предыдущих бенчмарков, охватывая широкий спектр задач, языков и длин текстов. Дизайн MTEB сосредоточен на разнообразии, простоте, расширяемости и воспроизводимости, что делает его ценным инструментом как для исследователей, так и для практиков в области обработки естественного языка.
Наиболее комплексный подход MTEB к бенчмаркингу, тестирующий модели по 8 различным задачам и 58 наборам данных, дает более полное представление о возможностях модели, чем предыдущие бенчмарки. Он показывает, что ни один метод эмбеддингов не превосходит остальные во всех задачах, подчеркивая важность выбора правильной модели для конкретных приложений.
При использовании MTEB крайне важно смотреть не только на общие оценки, но и учитывать конкретные потребности вашего приложения. Такие факторы, как поддержка языков, специализированная лексика, размер модели, использование памяти и максимальная длина входных данных, должны играть роль в процессе принятия решения.
Хотя MTEB является мощным инструментом, важно использовать его критически. Различия в оценках между лучшими моделями не всегда могут быть статистически значимыми, а производительность может сильно варьироваться в зависимости от конкретной задачи и набора данных.
Как проект с открытым исходным кодом, MTEB приветствует вклад сообщества, что позволяет ему расти и адаптироваться к меняющимся потребностям области. Такой совместный подход гарантирует, что MTEB продолжит оставаться актуальным и ценным ресурсом для оценки и улучшения технологии текстовых эмбеддингов.
Предоставляя стандартизированный способ оценки моделей текстовых эмбеддингов по широкому спектру задач и языков, MTEB помогает стимулировать прогресс в этой области, что в конечном итоге приводит к созданию более качественных и универсальных моделей текстовых эмбеддингов для различных приложений.
Ссылки
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils. "MTEB: Massive Text Embedding Benchmark" arXiv 2022
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff. "C-Pack: Packaged Resources To Advance General Chinese Embedding" arXiv 2023
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao. "Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents" arXiv 2023
Silvan Wehrli, Bert Arnrich, Christopher Irrgang. "Немецкий бенчмарк кластеризации текстовых эмбеддингов" arXiv 2024
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini. "FollowIR: оценка и обучение моделей информационного поиска следованию инструкциям" arXiv 2024
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li. "LongEmbed: расширение моделей эмбеддингов для поиска в длинном контексте" arXiv 2024
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo. "Скандинавские бенчмарки эмбеддингов: комплексная оценка многоязычных и одноязычных текстовых эмбеддингов" arXiv 2024
- Предпосылки и мотивация
- Текстовые эмбеддинги
- Проектирование и реализация Massive Text Embedding Benchmark
- Когда использовать Massive Text Embedding Benchmark
- Как использовать таблицу лидеров Massive Text Embedding Benchmark
- Ресурс Zilliz AI Model
- Заключение
- Ссылки
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно