




Классификация в машинном обучении: Все, что вы должны знать

Классификация в машинном обучении: Все, что вы должны знать
Что такое классификация?
Классификация - это контролируемый подход к машинному обучению, который распределяет данные по заранее определенным классам. Получив входные данные, модель классификации предсказывает, к какой категории или метке они относятся. Это одна из самых распространенных задач машинного обучения, которая используется во многих реальных приложениях, от обнаружения спама в электронной почте до медицинских диагнозов.
Например, если у вас есть набор данных электронных писем, модель классификации может научиться относить каждое письмо либо к категории "спам", либо к категории "не спам".
Как работает классификация?
При классификации модель машинного обучения обучается на наборе данных, чтобы распределять данные по заранее определенным классам на основе входных признаков. Модель обучается на наборе данных с метками, где каждый входной признак связан с выходным признаком. В процессе обучения модель изучает закономерности в данных и использует их для предсказания меток для новых, еще не полученных данных.
Например, представьте, что перед вами стоит задача классифицировать, является ли письмо спамом. На этапе обучения модель получает сообщения электронной почты вместе с их метками ("спам" или "не спам"). Она анализирует такие признаки, как наличие определенных ключевых слов или адрес отправителя, чтобы выявить закономерности. После обучения модели она анализирует те же признаки и при поступлении нового письма предсказывает, относится ли оно к категории "спам" или "не спам".
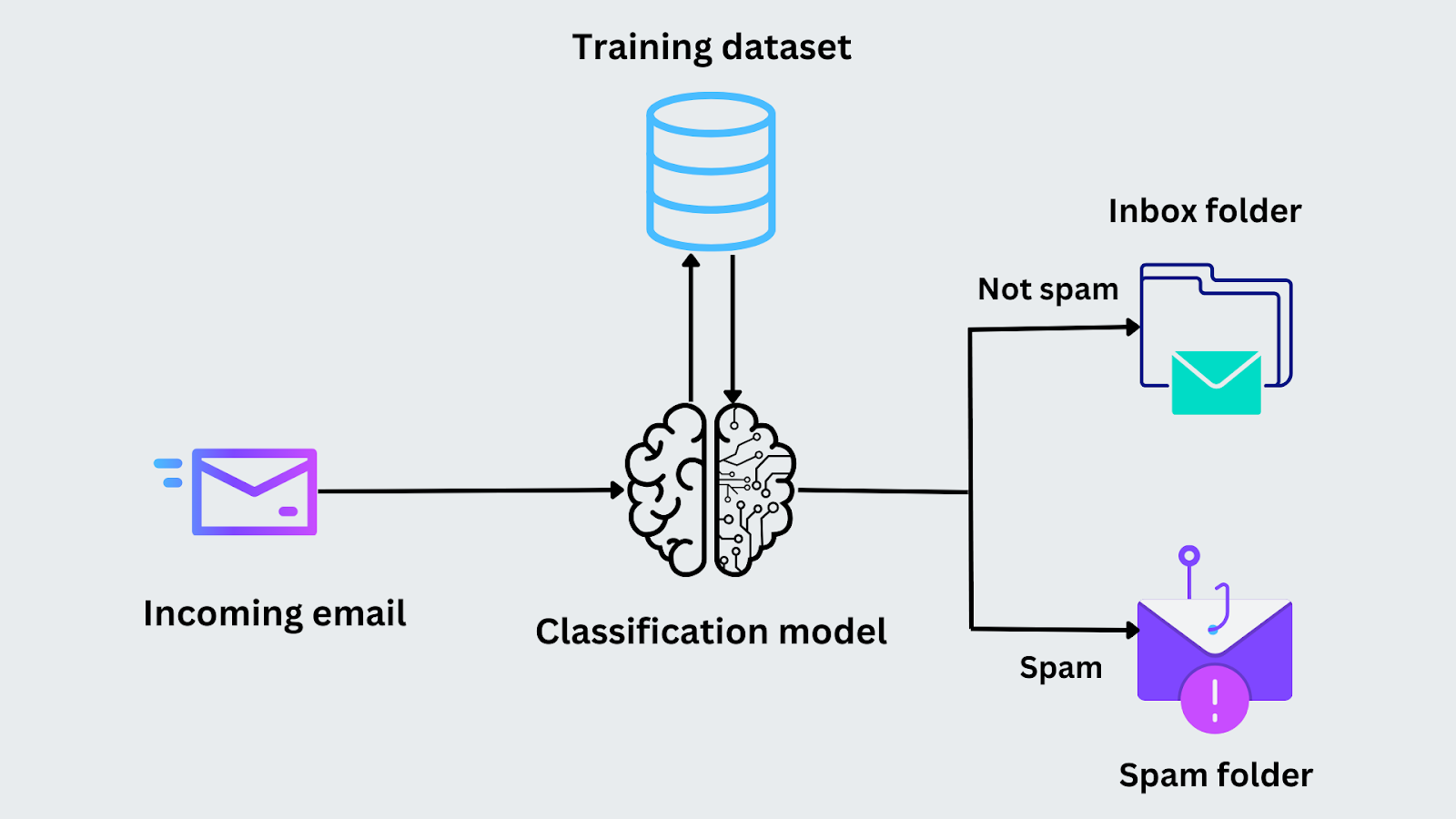 Рисунок - Процесс классификации электронной почты.png
Рисунок - Процесс классификации электронной почты.png
Рисунок: Процесс классификации электронной почты
Типы классификации
Проблемы классификации бывают разных видов, в зависимости от характера данных и количества классов. Вот наиболее распространенные типы:
Бинарная классификация
Бинарная классификация - это когда есть только два возможных класса или исхода. Модель предсказывает, к какой из двух категорий относится входной сигнал. Классический пример - обнаружение почтового спама. Модель должна решить, является ли входящее письмо либо "спамом", либо "не спамом". Поскольку вариантов всего два, это задача бинарной классификации.
Мультиклассовая классификация
При многоклассовой классификации модель предсказывает одну метку из более чем двух возможных категорий. Каждый входной сигнал относится ровно к одному классу. Хорошим примером является распознавание изображений, где модель может классифицировать изображение как "кошка", "собака" или "птица". В отличие от бинарной классификации, модель имеет дело с несколькими различными классами и должна определить правильный класс для каждого входного сигнала.
Multilabel Classification
Многопометная классификация - это классификация, при которой каждый входной сигнал может относиться к нескольким классам одновременно. Например, при маркировке фотографии на нее могут быть наклеены метки "закат", "пляж" и "люди" одновременно. Каждая метка представляет собой отдельный класс, и модель учится предсказывать все соответствующие метки для входных данных. Это отличается от многоклассовой классификации, поскольку одному и тому же входу можно присвоить несколько меток.
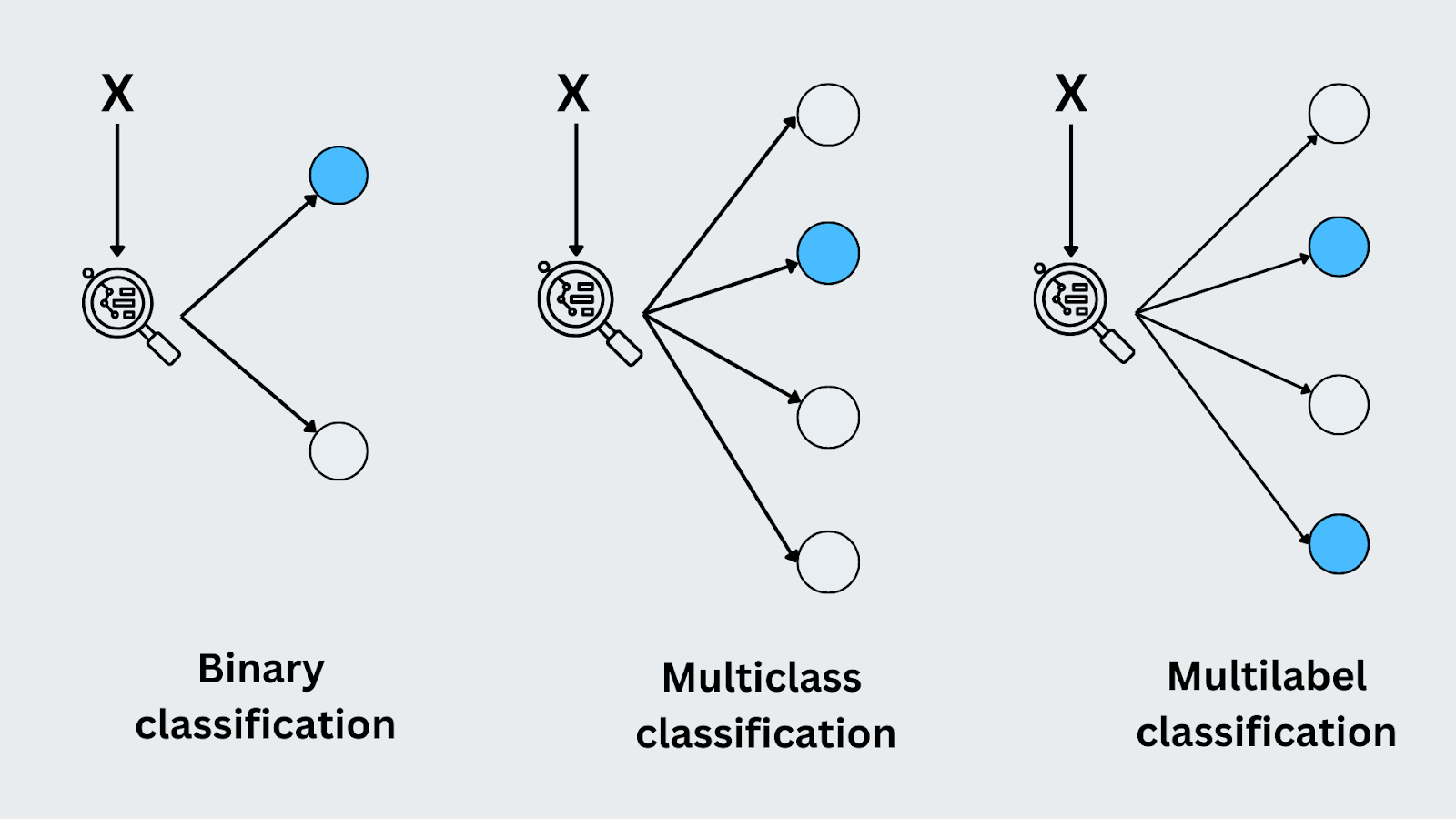 Рисунок - Типы классификации.png
Рисунок - Типы классификации.png
** Рисунок:** Виды классификации
Обучающиеся в алгоритмах классификации
В машинном обучении алгоритмы классификации можно разделить на категории в зависимости от того, как они обобщают обучающие данные. Это Ленивые обучающиеся и Усердные обучающиеся. Различие между этими двумя типами заключается в том, когда и как они обрабатывают данные для составления прогнозов.
Ленивые обучающиеся
Ленивые обучающиеся - это алгоритмы, которые откладывают обобщение до получения запроса на предсказание. Они не строят модель на этапе обучения; вместо этого они хранят обучающие данные и выполняют вычисления только тогда, когда требуется классифицировать новый входной сигнал.
Примеры алгоритмов: k-Nearest Neighbors (k-NN), Case-based Reasoning (CBR).
Eager Learners
В отличие от них, "энергичные" обучающиеся пытаются построить общую модель сразу же на этапе обучения. Они анализируют обучающие данные, изучают основные закономерности, а затем отбрасывают обучающие данные. Как только модель построена, она может быстро предсказывать новые данные.
Примеры алгоритмов: Деревья решений, случайный лес, машины опорных векторов (SVM), логистическая регрессия.
| Аспекты | Ленивые обучающиеся | Интеллектуальные обучающиеся | |
| Создание модели | Во время обучения модель не строится, она запоминает данные. | Обобщение данных в модель во время обучения. | |
| Время обучения | Короткое время обучения; модель не строится. | Более длительное время обучения; модель строится на основе данных. | |
| Время предсказания | Делает медленные предсказания, так как обрабатывает данные во время запроса. | Более быстрые прогнозы, поскольку модель уже построена. | |
| Потребность в памяти | Более высокая потребность в памяти; хранится весь набор данных. | Требуется меньше памяти; хранятся только параметры модели. | |
| Примеры алгоритмов | k-NN, Case-based Reasoning | Decision Trees, Logistic Regression, Random Forest |
Таблица: Ленивые обучающиеся против нетерпеливых обучающихся
Алгоритмы классификации
Теперь давайте обсудим некоторые часто используемые алгоритмы классификации.
Логистическая регрессия
Логистическая регрессия использует только вероятность для предсказания метки в задаче бинарной классификации. В отличие от линейной регрессии, которая предсказывает непрерывные значения, логистическая регрессия предсказывает вероятности для двух классов путем отображения результатов в диапазон между 0 и 1 с помощью логистической функции (sigmoid). Она широко используется для случаев с бинарными исходами, например, для сценариев "да/нет" или "0/1".
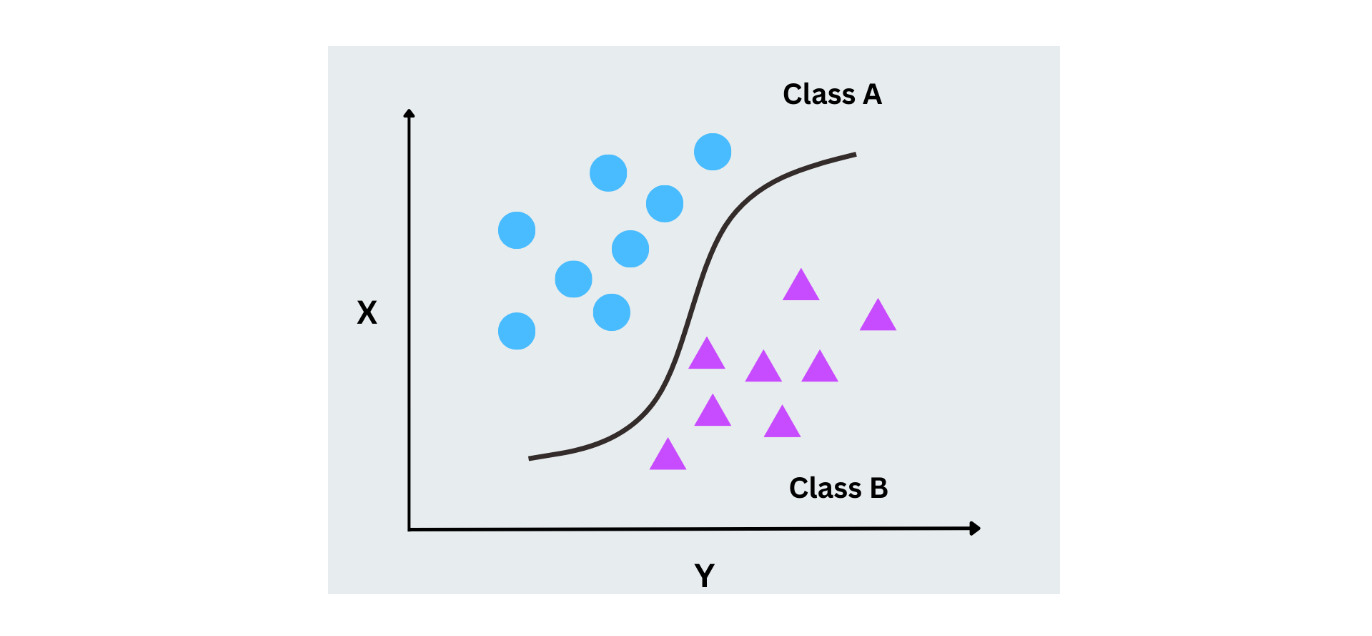 Рисунок - Работа логистической регрессии.png
Рисунок - Работа логистической регрессии.png
Рисунок - Работа логистической регрессии
Деревья решений
Дерево решений - это модель, которая разбивает данные на основе значений признаков, создавая ветви для каждого возможного решения. Каждый узел представляет собой признак, а ветви - решения, основанные на значении этого признака. Процесс продолжается до тех пор, пока алгоритм не определит узлы листьев предсказанного класса. Деревья решений легко интерпретируются и могут решать задачи бинарной и мультиклассовой классификации.
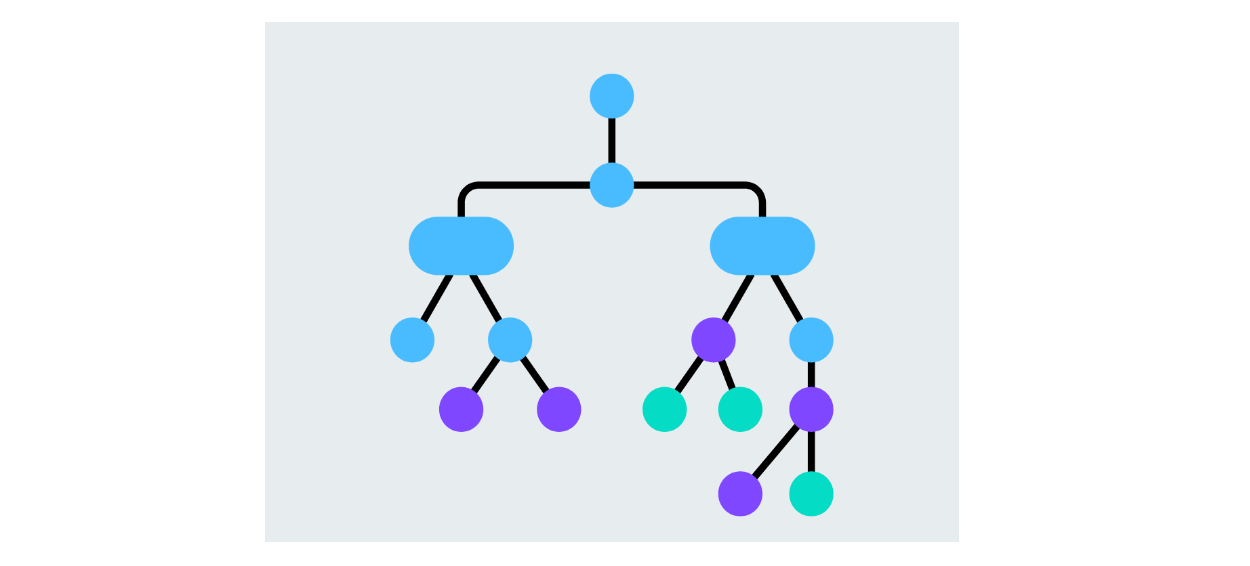 Рисунок - Структура дерева решений.png
Рисунок - Структура дерева решений.png
** Рисунок:** Структура дерева решений
Случайный лес
Случайный лес улучшает деревья решений, создавая несколько деревьев и объединяя их прогнозы. Каждое дерево в лесу строится на основе случайного подмножества данных и признаков. Окончательный прогноз делается путем усреднения результатов (для задач регрессии) или большинством голосов (для задач классификации). Это помогает уменьшить перебор и повысить точность.
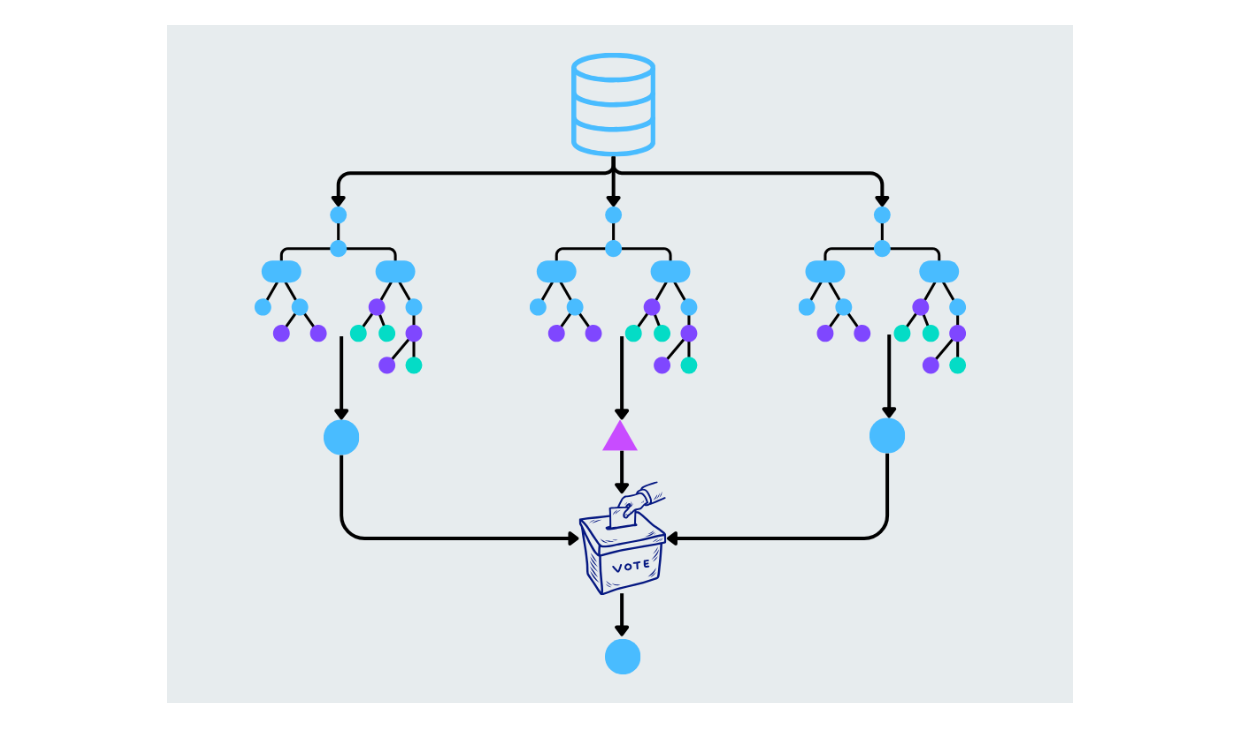 Рисунок - Работа случайного леса.png
Рисунок - Работа случайного леса.png
Иллюстрация: Работа случайного леса
Машины опорных векторов (SVM)
Векторные машины поддержки работают путем нахождения оптимальной гиперплоскости, разделяющей точки данных из разных классов. Эта гиперплоскость представляет собой линию в двух измерениях, но SVM могут работать и с высокоразмерными данными. Основная идея заключается в том, чтобы максимизировать маржу между ближайшими точками данных каждого класса (векторами поддержки). SVM хорошо подходят для решения задач бинарной и многоклассовой классификации, особенно когда данные не являются линейно разделяемыми.
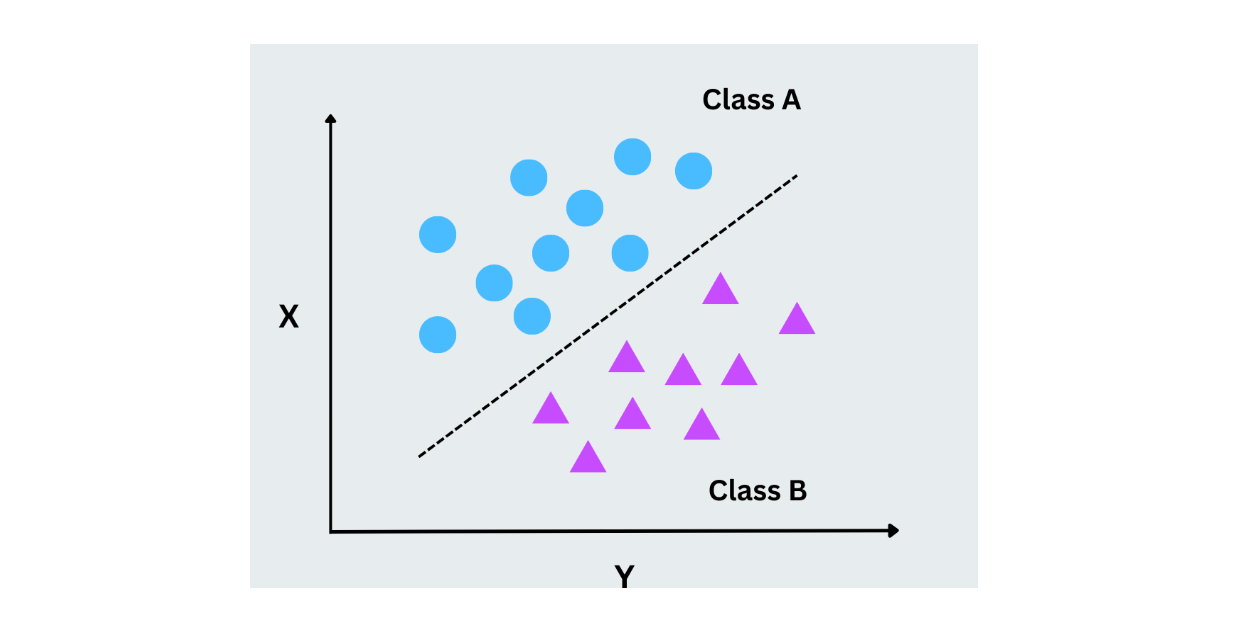 Рисунок- Работа SVM.png
Рисунок- Работа SVM.png
Рисунок - Работа SVM
k-Nearest Neighbors (k-NN)
Алгоритм k-NN классифицирует точки данных на основе классов k ближайших соседей. При введении новой точки данных алгоритм просматривает k ближайших точек (на основе метрики сходства, например евклидова расстояния) и присваивает новой точке класс большинства. Это простой алгоритм обучения на основе экземпляров, полезный для небольших наборов данных.
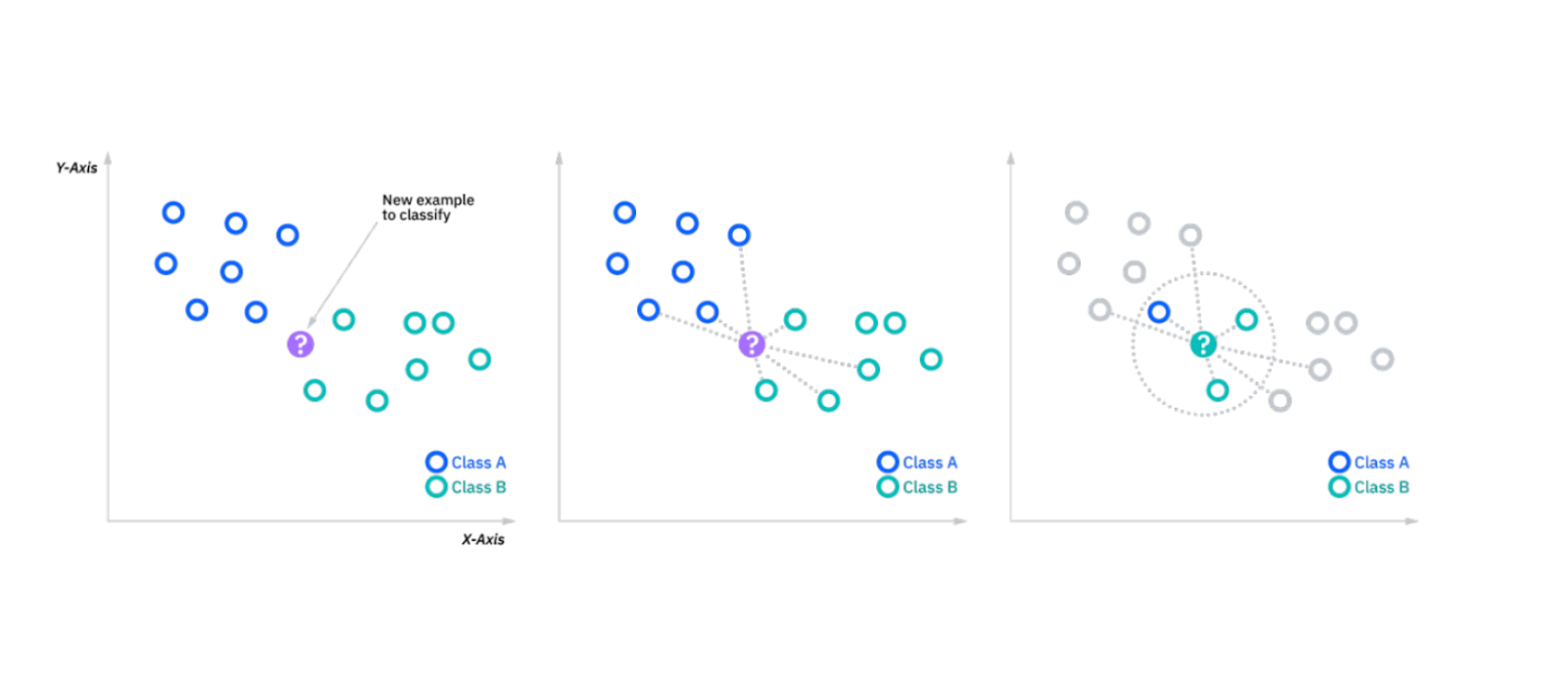 Рисунок - Работа алгоритма kNN.png
Рисунок - Работа алгоритма kNN.png
Иллюстрация: Работа алгоритма kNN
Наивный Байес
Наивный Байес основан на теореме Байеса и предполагает, что признаки в данных независимы друг от друга (отсюда и термин "наивный"). Несмотря на это предположение, он хорошо справляется с различными реальными задачами, особенно когда данные содержат категориальные признаки. Он работает, вычисляя вероятность каждого класса с учетом входных данных и присваивая класс с наибольшей вероятностью.
P(C|X) = P(X|C) . P(C)P(X))
Здесь P(C∣X) - апостериорная вероятность класса с учетом входных данных, P(X∣C) - вероятность входных данных с учетом класса, P(C) - предшествующая вероятность класса, а P(X) - вероятность входных данных. Наивный Байес выбирает класс с наибольшей апостериорной вероятностью для классификации на основе наблюдаемых признаков.
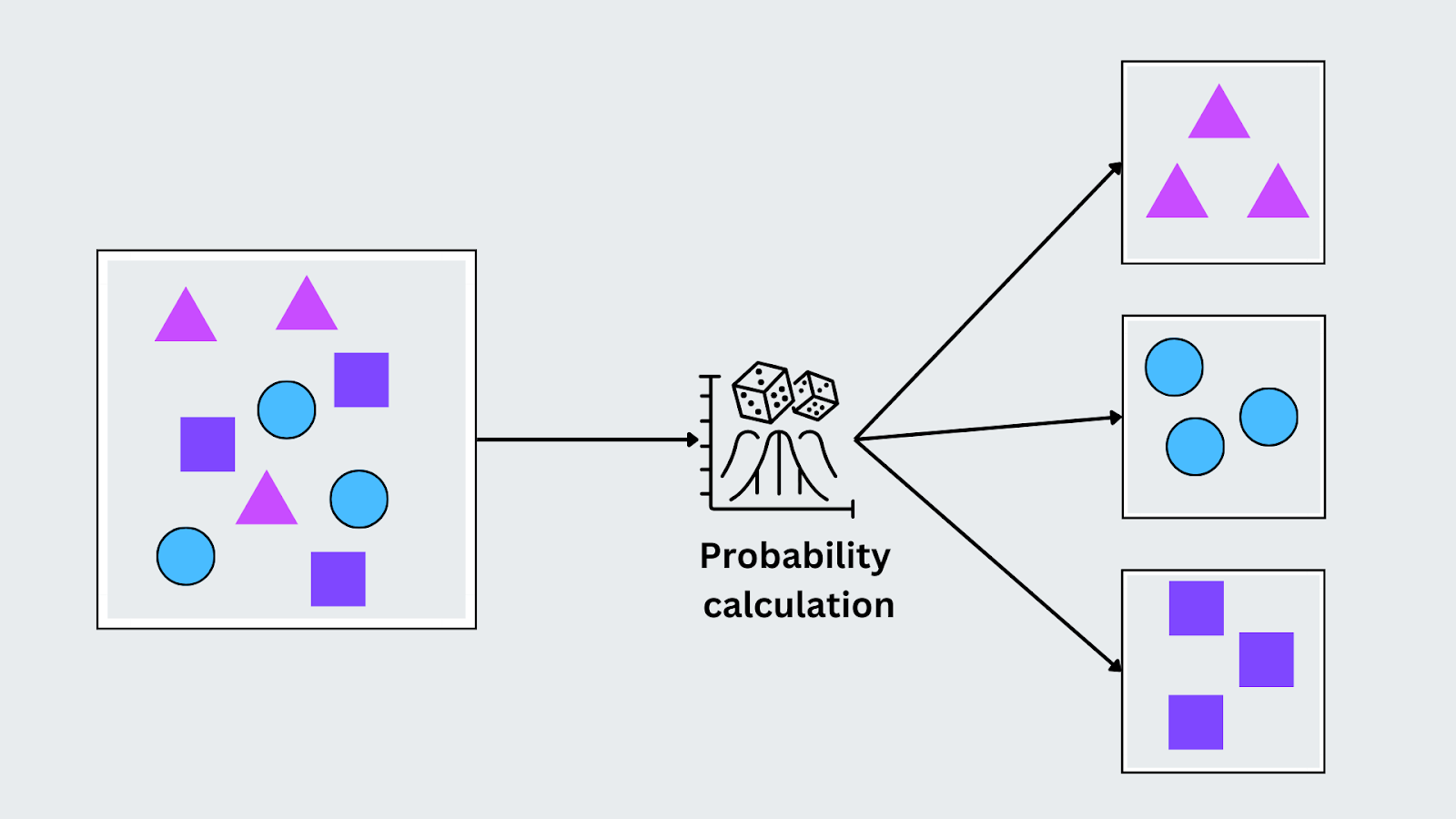 Рисунок - Работа алгоритма Наивного Байеса.png
Рисунок - Работа алгоритма Наивного Байеса.png
Рисунок: Работа алгоритма Наивного Байеса
Метрики оценки при классификации
Точность
Точность - самая простая метрика, которая измеряет, насколько часто предсказания модели оказываются верными. Она определяется путем деления количества правильно предсказанных случаев на общее количество случаев.
Формула:
Точность = (Истинно положительные результаты + Истинно отрицательные результаты)/Общее количество экземпляров
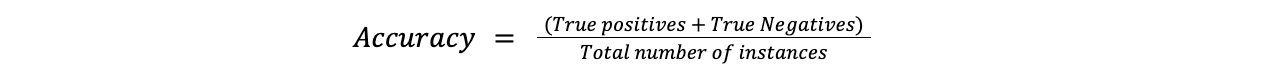 accuracy.png
accuracy.png
Точность
Точность определяет, сколько из предсказанных положительных случаев действительно являются положительными. Точность важна в ситуациях, когда ложные срабатывания дорого обходятся. Например, предсказание обычной транзакции как мошеннической при обнаружении мошенничества может привести к недовольству клиентов.
Формула:
Точность = Истинные положительные результаты/(Истинные положительные результаты + Ложные положительные результаты)
 precision.png
precision.png
Recall
Recall измеряет долю положительных случаев, точно идентифицированных как положительные. Показатель Recall полезен в тех случаях, когда пропуск положительного случая обходится дорого. Например, отсутствие диагноза (ложноотрицательный результат) гораздо более проблематично при выявлении заболеваний, чем ложная тревога.
Формула:
Recall = True positives/(True positives + False negatives)
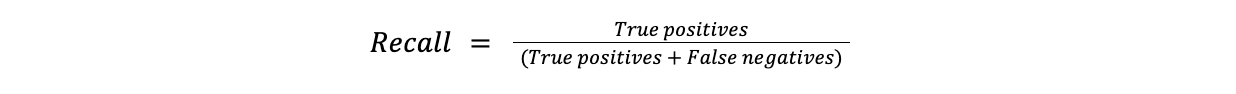 recall.png
recall.png
F1-Score
F1-Score - это среднее гармоническое между точностью и отзывом. Он полезен, когда нужно сбалансировать точность и отзыв, в частности, когда одно важнее другого.
Формула:
F1Score = 2x(Precision x Recall)/(Precision + Recall)
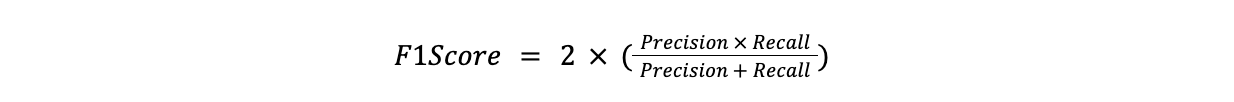 FI score.png
FI score.png
Реальные примеры использования классификации в реальном мире
Классификационные модели широко используются в различных отраслях для решения реальных задач. Вот несколько практических примеров:
Медицинская диагностика: Модели машинного обучения помогают врачам классифицировать данные о пациенте, например "заболевание" или "отсутствие заболевания". Например, модели используются для предсказания наличия у пациента диабета на основе медицинской карты.
Анализ настроения: Компании используют анализ настроения, чтобы понять отзывы клиентов. Например, модель может анализировать отзывы о продукте и классифицировать их как положительные, отрицательные или нейтральные, помогая компаниям улучшить свои предложения с учетом настроения клиентов.
**Банки и финансовые учреждения используют классификационные модели для выявления мошеннических операций. Модель изучает закономерности на основе данных о транзакциях и классифицирует каждую из них как "мошенническую" или "законную", чтобы предотвратить финансовые потери.
Распознавание объектов на изображениях: Модели распознавания объектов идентифицируют конкретные элементы изображения в таких отраслях, как производство и безопасность. Например, модель может классифицировать изображения изделий на сборочной линии, гарантируя, что только правильно собранные изделия пройдут проверку.
Распознавание лиц: Системы распознавания лиц используются для обеспечения безопасности и аутентификации. Эти модели классифицируют изображения лиц, чтобы идентифицировать или подтвердить личность человека, что обычно используется при разблокировке смартфонов, в системах цифровой регистрации или при проверке безопасности в аэропортах.
Распознавание голоса: Модели распознавания голоса преобразуют устную речь в текст или команды. Например, виртуальные помощники, такие как Siri или Alexa, классифицируют произнесенные слова в команды, чтобы пользователи могли взаимодействовать с устройствами с помощью голоса.
Медицинские диагностические тесты: Модели машинного обучения помогают интерпретировать диагностические тесты, такие как рентгеновские снимки или снимки МРТ. Они классифицируют медицинские изображения как "нормальные" или "ненормальные", помогая рентгенологам быстрее и точнее ставить диагнозы.
Прогнозирование поведения покупателей: Платформы электронной коммерции используют классификационные модели для прогнозирования поведения покупателей. Эти модели классифицируют пользователей как "вероятных покупателей" или "маловероятных покупателей", чтобы сделать персонализированные маркетинговые и товарные рекомендации.
Категоризация товаров: Розничные сети используют машинное обучение для автоматической классификации товаров, таких как "электроника", "одежда" или "товары для дома", на основе их описаний. Это упрощает управление запасами и улучшает поиск товаров.
Классификация вредоносного ПО: В сфере кибербезопасности модели классификации обнаруживают и классифицируют вредоносное ПО. Анализируя закономерности в поведении программного обеспечения, эти модели классифицируют программы как "безопасные" или "вредоносные", чтобы защитить системы от киберугроз.
Общие проблемы классификации
При построении моделей классификации может возникнуть несколько проблем, которые влияют на производительность модели. Вот три распространенные проблемы:
Overfitting
Overfitting означает, когда модель хорошо работает на обучающих данных, но не способна обобщить их на новые, неизвестные данные. Это происходит, когда модель становится слишком сложной и начинает улавливать шум или специфические детали обучающего набора, а не основные закономерности.
Дисбаланс данных
Дисбаланс данных - это когда один класс значительно превосходит другие. Например, при обнаружении мошенничества мошеннические транзакции могут составлять всего 1 % данных, что приведет к тому, что модель будет сильно смещена в сторону класса большинства. Это может привести к плохому обнаружению класса меньшинства.
Шум в данных
Под шумом понимаются случайные ошибки или нерелевантная информация в данных, которая может сбить модель с толку. Шумовые данные могут включать в себя неправильно помеченные примеры, выбросы или нерелевантные признаки, которые не способствуют решению задачи классификации. Наличие шума может снизить производительность модели и затруднить обнаружение закономерностей.
Классификация и регрессия
Классификация и регрессия - это оба типа алгоритмов контролируемого обучения, но они используются для разных задач. Ниже приведено сравнение классификации и регрессии по различным аспектам:
| Аспект | Классификация | Регрессия | |
| Цель | Прогнозирование дискретных меток или категорий. | Прогнозирование непрерывных числовых значений. | |
| Выходные данные | Категориальные: классы типа "спам" или "не спам". | Непрерывные: значения типа "цена" или "температура". | |
| Пример задачи | Классификация электронных писем как "спам" или "не спам". | Предсказание цен на дома на основе их характеристик. | |
| Используемые алгоритмы | Логистическая регрессия, деревья решений, случайный лес и т. д. | Линейная регрессия, гребневая регрессия, полиномиальная регрессия и т. д. | |
| Метрики оценки | Accuracy, Precision, Recall, F1-score, ROC-AUC и т.д. | Средняя квадратичная ошибка (MSE), R-квадрат, средняя абсолютная ошибка (MAE). | |
| Характер целевой переменной | Цель категориальная (например, метки классов). | Целевая переменная непрерывна (например, вещественные числа). | |
| Границы вывода | Имеет фиксированные границы классов (например, 0 или 1 для двоичных чисел). | Нет фиксированных границ; на выходе - диапазон вещественных чисел. | |
| Примеры использования в реальном мире | Обнаружение спама, мошенничество, классификация заболеваний. | Прогнозирование продаж, цен на акции и предсказание погоды. | |
| Моделирование комплексов | Он может работать как с бинарными, так и с мультиклассовыми выводами. | Обычно проще при прогнозировании одного непрерывного значения. |
Таблица: Классификация и регрессия
Как Milvus помогает в решении задач классификации?
По мере роста объема и сложности данных традиционные методы управления большими массивами данных и запросов к ним могут стать медленными и неэффективными. Именно здесь важную роль играет Zilliz со своей высокопроизводительной векторной базой данных с открытым исходным кодом Milvus.
Задачи классификации, такие как распознавание изображений, обнаружение объектов, поиск сходства видео, обнаружение спама и рекомендательные системы, часто требуют работы с высокоразмерными представлениями неструктурированных данных, такими как текстовые вкрапления, особенности изображений или аудиовекторы. Milvus специально разработан для эффективного управления и поиска в таких больших объемах векторных данных.
Преимущества Milvus для классификации
Работа с высокоразмерными данными: При классификации модели часто опираются на векторные данные (например, вкрапления слов или векторы признаков изображений), чтобы делать предсказания. Milvus оптимизирован для хранения и управления этими векторами, что позволяет быстро получать доступ к большим наборам данных во время обучения и вывода модели.
Быстрый поиск сходства: Классификационные модели часто нуждаются в поиске наиболее близких точек данных в наборе данных. Milvus ускоряет этот процесс, выполняя быстрый поиск сходства в векторных данных, что облегчает классификацию новых входных данных на основе их ближайших соседей.
Масштабируемость для больших наборов данных: Milvus обеспечивает высокую скорость и эффективность работы по мере роста наборов данных для классификации. Milvus легко масштабируется, чтобы задачи классификации выполнялись гладко даже при огромных объемах данных, будь то миллионы векторов продуктов, вкраплений изображений или тысячи вкраплений изображений.
Заключение
Классификация - это метод машинного обучения, позволяющий предсказывать метки или категории для данных в различных реальных приложениях, от выявления мошенничества до распознавания изображений. Успешное построение и развертывание моделей классификации требует обработки больших объемов данных, часто высокоразмерных векторов. Milvus обеспечивает эффективное хранение, быстрый поиск и масштабируемость векторных данных. Он повышает производительность задач классификации благодаря быстрому поиску сходства и плавно масштабируется по мере роста наборов данных. С помощью Milvus разработчики могут легко справиться с задачами классификации больших объемов, что делает его мощным инструментом в сфере машинного обучения.
Часто задаваемые вопросы по классификации
**Что такое классификация в машинном обучении?
Классификация в машинном обучении - это процесс предсказания категории или метки для заданного входного сигнала на основе его характеристик. Модель обучается на помеченных данных, чтобы выучить шаблоны и затем классифицировать новые, невидимые данные в заранее определенные классы, такие как "спам" или "не спам".
**Чем алгоритм классификации отличается от регрессии?
Алгоритмы классификации предсказывают категориальные результаты (например, классы или метки), в то время как алгоритмы регрессии предсказывают непрерывные числовые значения. Например, классификация может определить, является ли электронное письмо спамом, а регрессия - цену дома.
**Почему подготовка данных важна в задачах классификации?
Подготовка данных гарантирует, что входные данные чисты, структурированы и готовы к обработке моделью. Она обрабатывает пропущенные значения, нормализует данные и выбирает наиболее релевантные признаки. Правильная подготовка повышает точность и производительность модели.
**Как Milvus помогает решать задачи классификации?
Milvus - это векторная база данных с открытым исходным кодом, которая эффективно хранит и ищет высокоразмерные данные, такие как изображения или текстовые вкрапления. Она ускоряет классификацию благодаря эффективному поиску сходства, что облегчает работу с большими наборами данных в таких задачах, как распознавание изображений и рекомендательные системы.
Какие общие проблемы возникают при классификации и как их можно решить?
К общим проблемам относятся чрезмерная подгонка, дисбаланс данных и шум в данных. Их можно решить с помощью таких методов, как регуляризация, методы повторной выборки (например, SMOTE), стратегии подавления шума и масштабируемая инфраструктура, такая как Milvus, для эффективного управления большими наборами данных.
Связанные ресурсы
- Что такое классификация?
- Как работает классификация?
- Типы классификации
- Обучающиеся в алгоритмах классификации
- Алгоритмы классификации
- Метрики оценки при классификации
- Реальные примеры использования классификации в реальном мире
- Общие проблемы классификации
- Классификация и регрессия
- Как Milvus помогает в решении задач классификации?
- Заключение
- Часто задаваемые вопросы по классификации
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно