




Change Data Capture: синхронизация ваших систем в реальном времени

Change Data Capture: синхронизация ваших систем в реальном времени
Что такое Change Data Capture (CDC)?
Change Data Capture (CDC) — это метод, используемый для выявления и отслеживания изменений данных по мере их возникновения в базе данных. Вместо ручного мониторинга или повторяющихся запросов на наличие обновлений CDC автоматически фиксирует вставки, обновления и удаления в реальном времени или почти в реальном времени. Методы CDC, такие как журналы транзакций и триггеры базы данных, помогают организациям поддерживать согласованность и целостность данных в различных системах и средах развертывания. Это гарантирует, что нижестоящие системы и приложения — независимо от того, обеспечивают ли они традиционную аналитику или векторные AI-модели, — всегда имеют самые актуальные данные.
Например, в vector database CDC отслеживает обновления эмбеддингов в реальном времени для таких задач, как semantic search или fraud detection, где для точных результатов требуются самые актуальные данные.
Эволюция интеграции данных: роль CDC
В прошлом batch processing был основным подходом к интеграции данных. Однако он вызывал задержки, поскольку обновления данных обрабатывались пакетно через запланированные интервалы, часто через часы или дни после возникновения изменений. Это ограничение делало его неподходящим для таких приложений, как семантический поиск в реальном времени для чат-ботов на базе AI или recommendation systems, которые используют векторные базы данных для анализа высокоразмерных данных.
CDC решает эту проблему, фиксируя изменения по мере их возникновения и обновляя системы в реальном времени. Эта технология позволяет компаниям синхронизировать свои базы данных, поддерживать дашборды реального времени и создавать отзывчивые приложения. Рост CDC совпал с развитием современных distributed systems и cloud-native architectures, где своевременная репликация и интеграция данных имеют критическое значение. Вместо работы с устаревшими данными из периодических обновлений организации теперь могут фиксировать изменения и реагировать на них по мере их возникновения. Этот сдвиг сделал CDC важнейшим компонентом современных стратегий работы с данными, помогая компаниям оставаться отзывчивыми и конкурентоспособными в реальном времени.
Как работает Change Data Capture?
Представьте отслеживание взаимодействий клиента на платформе электронной коммерции. Каждое взаимодействие, такое как просмотр, добавление в корзину или покупка, генерирует новые данные. CDC передает эти измененные данные в векторную базу данных, такую как Milvus, в реальном времени, где их векторные представления, также известные как vector embeddings, могут обновляться для таких задач, как персонализированные рекомендации или предотвращение мошенничества.
Давайте разберем это на ключевые компоненты и механизмы, чтобы понять, как работает CDC.
Ключевые компоненты CDC
Чтобы CDC функционировал, несколько компонентов работают совместно. Диаграмма ниже иллюстрирует процесс CDC.
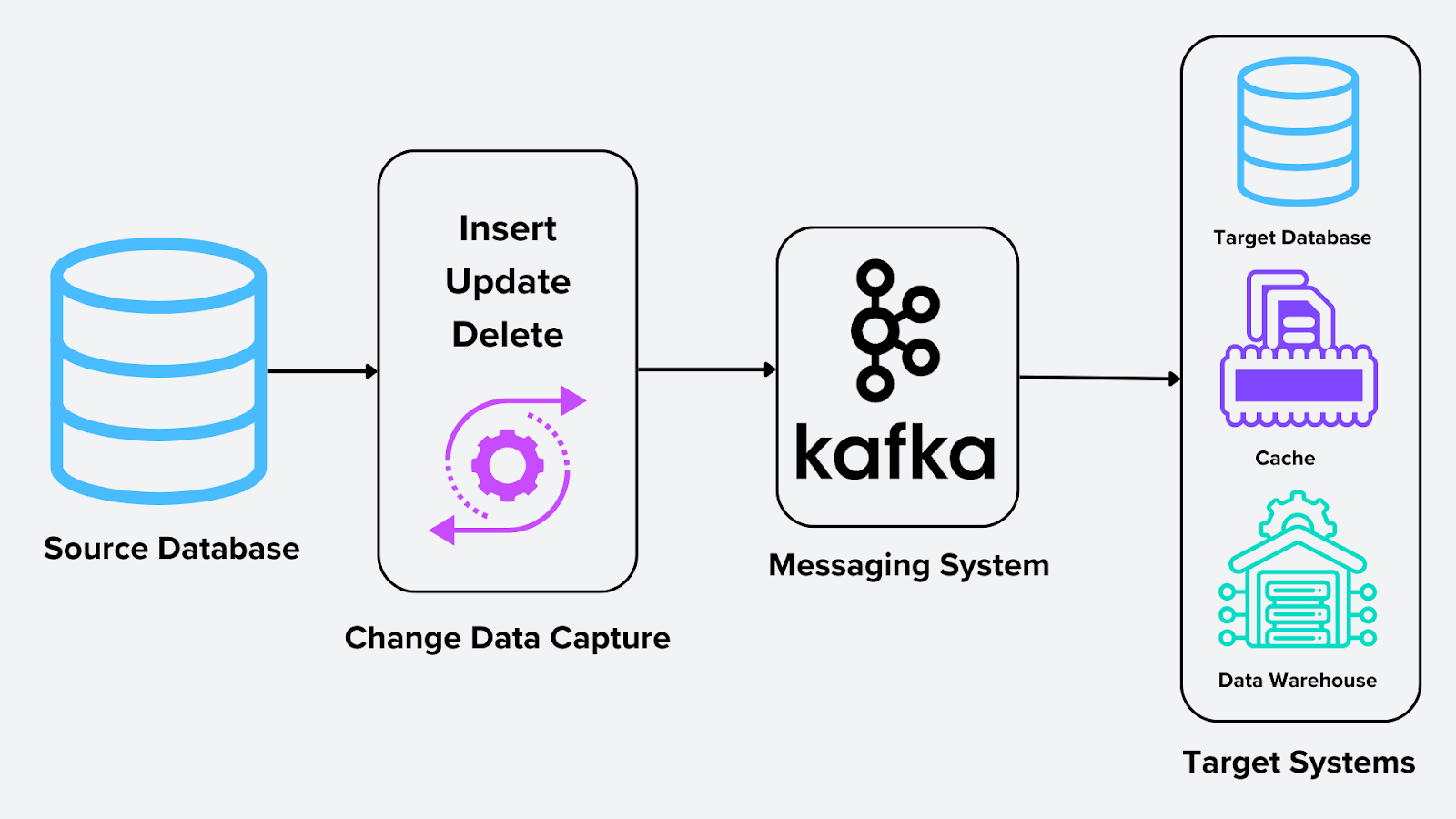 Figure- Change Data Capture Process .png
Figure- Change Data Capture Process .png
Рисунок: Процесс Change Data Capture
Источник: Система, в которой возникают изменения; это могут быть реляционные базы данных, NoSQL-системы или векторные базы данных. В случае векторной базы данных, такой как Milvus, источником могут быть эмбеддинги, созданные deep learning models или моделями image recognition.
CDC Engine: Основной процесс, который фиксирует и форматирует изменения. Для векторных баз данных это может означать обновление эмбеддингов, хранящихся в Milvus, с помощью таких инструментов, как Milvus-CDC или Confluent Kafka Connect.
Система обмена сообщениями: Система обмена сообщениями, такая как Apache Kafka, служит основой для распределения изменений в реальном времени. Она выступает посредником, который хранит и передает поток captured changes в одну или несколько целевых систем. Это обеспечивает масштабируемость и надежность в конвейере данных.
Целевые системы: Места назначения, куда отправляются обработанные изменения данных. Примеры включают:
Хранилища данных (например, Snowflake, BigQuery) для аналитики.
Кэши для более быстрых ответов на запросы.
Базы данных для репликации и синхронизации между системами.
Обзор механизмов CDC
Существует три основных способа, с помощью которых CDC может захватывать изменения из базы данных. В приведенных ниже примерах мы будем использовать SQL-базы данных для демонстрации.
1. CDC на основе журналов
Этот метод опирается на журнал транзакций базы данных — функцию системного уровня, которая записывает все изменения базы данных (вставки, обновления и удаления). Движок CDC читает эти журналы и извлекает соответствующие изменения для дальнейшего использования. В векторных базах данных это может означать захват обновлений embedding-векторов по мере их вставки или изменения в Milvus.
Как это работает:
Журнал транзакций является единым источником истины для всех операций с базой данных.
Инструмент CDC отслеживает журнал и непрерывно выявляет и захватывает изменения, не влияя на основную базу данных.
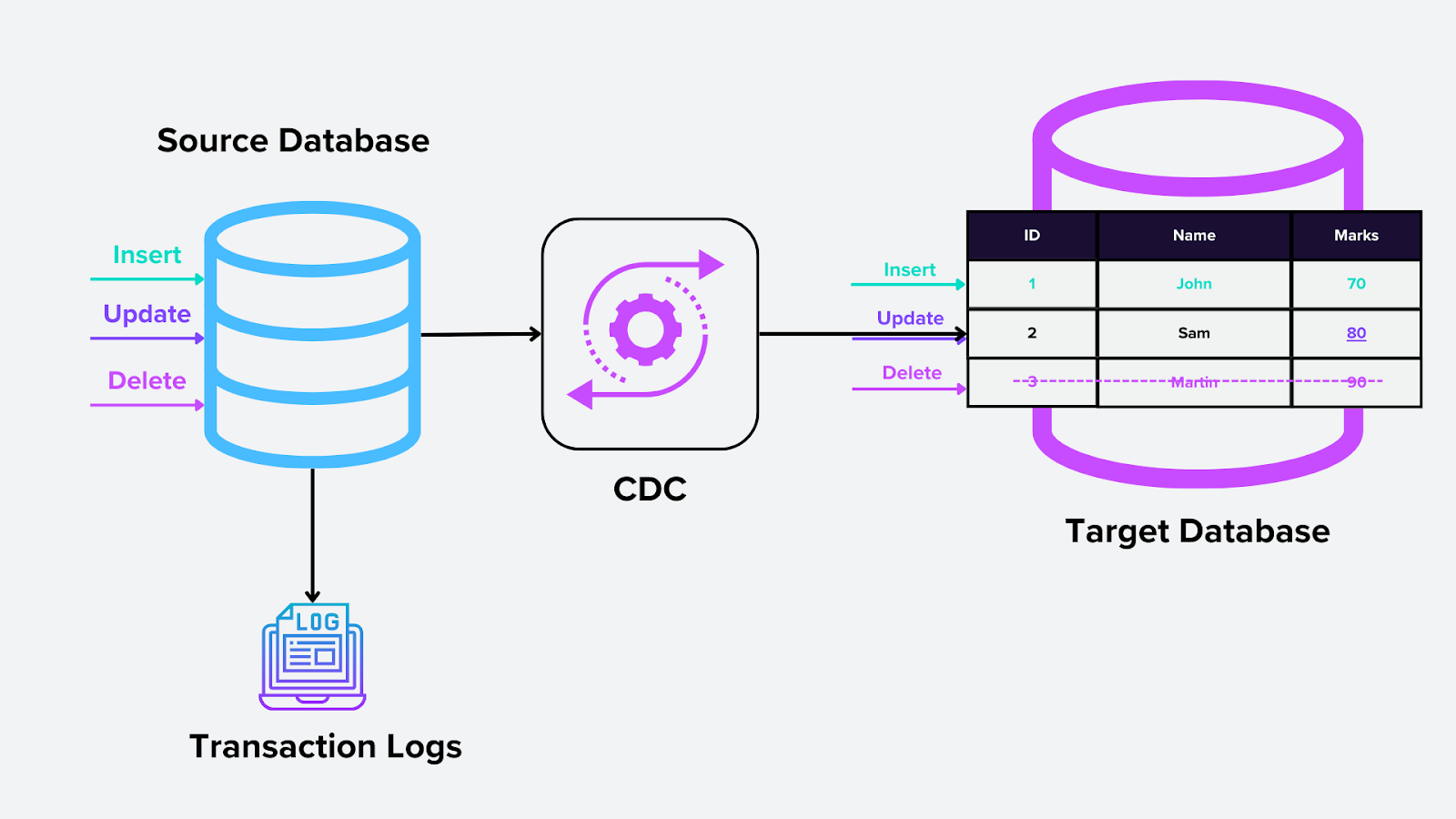 Figure- Log-based CDC.png
Figure- Log-based CDC.png
Рисунок: CDC на основе журналов
Плюсы:
Высокая производительность: Минимальное влияние на базу данных, поскольку чтение выполняется напрямую из журналов.
Всеобъемлющий охват: Захватывает все изменения, включая триггеры, хранимые процедуры или другие косвенные методы.
Масштабируемость: Хорошо работает с системами с высоким объемом транзакций.
Минусы:
Сложность: Требует глубокой интеграции с внутренней структурой журналов базы данных, которая может различаться в зависимости от типа базы данных.
Совместимость: Не все базы данных предоставляют внешнему доступу журналы транзакций.
2. CDC на основе триггеров
Этот подход использует триггеры базы данных — пользовательскую логику, которая выполняется автоматически при возникновении определенного изменения (например, вставки, обновления или удаления) в таблице. Например, триггеры могут автоматически обновлять векторный индекс Milvus при добавлении новых embedding-векторов.
Как это работает:
Триггеры добавляются к интересующим таблицам в базе данных.
Когда происходят изменения, триггер захватывает их и отправляет информацию в указанное место или таблицу для дальнейшей обработки.
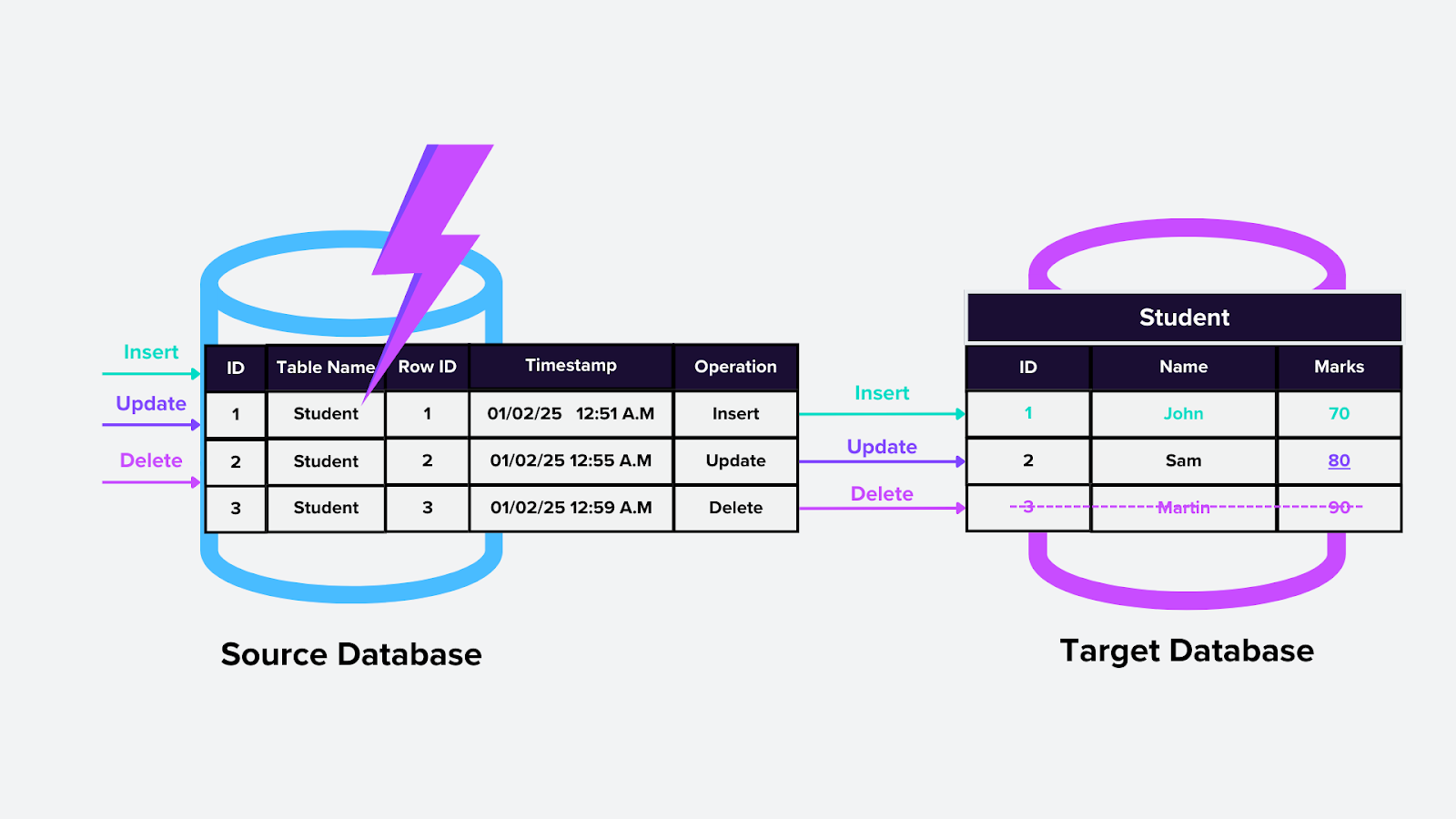 Figure- Trigger-based CDC.png
Figure- Trigger-based CDC.png
Рисунок: CDC на основе триггеров
Плюсы:
Гибкость: Может быть настроен для отслеживания изменений под конкретные сценарии использования.
Широкая поддержка: Почти все реляционные базы данных поддерживают триггеры.
Минусы:
Влияние на производительность: Триггеры добавляют нагрузку на базу данных, особенно при высокочастотных транзакциях.
Сложности сопровождения: Управление триггерами и их обновление в нескольких таблицах может стать затруднительным.
Подверженность ошибкам: Плохо написанные триггеры могут вызывать узкие места в производительности или не учитывать пограничные случаи.
3. CDC на основе запросов
Этот метод предполагает выполнение периодических запросов к базе данных для обнаружения изменений. Запросы обычно сравнивают временные метки или версии, чтобы определить недавно измененные записи, например при опросе векторной базы данных на наличие обновленных embedding-векторов.
Как это работает:
Движок CDC выполняет запросы по расписанию и выявляет изменения на основе определенных критериев (например, даты последнего изменения).
Обнаруженные изменения затем отправляются downstream.
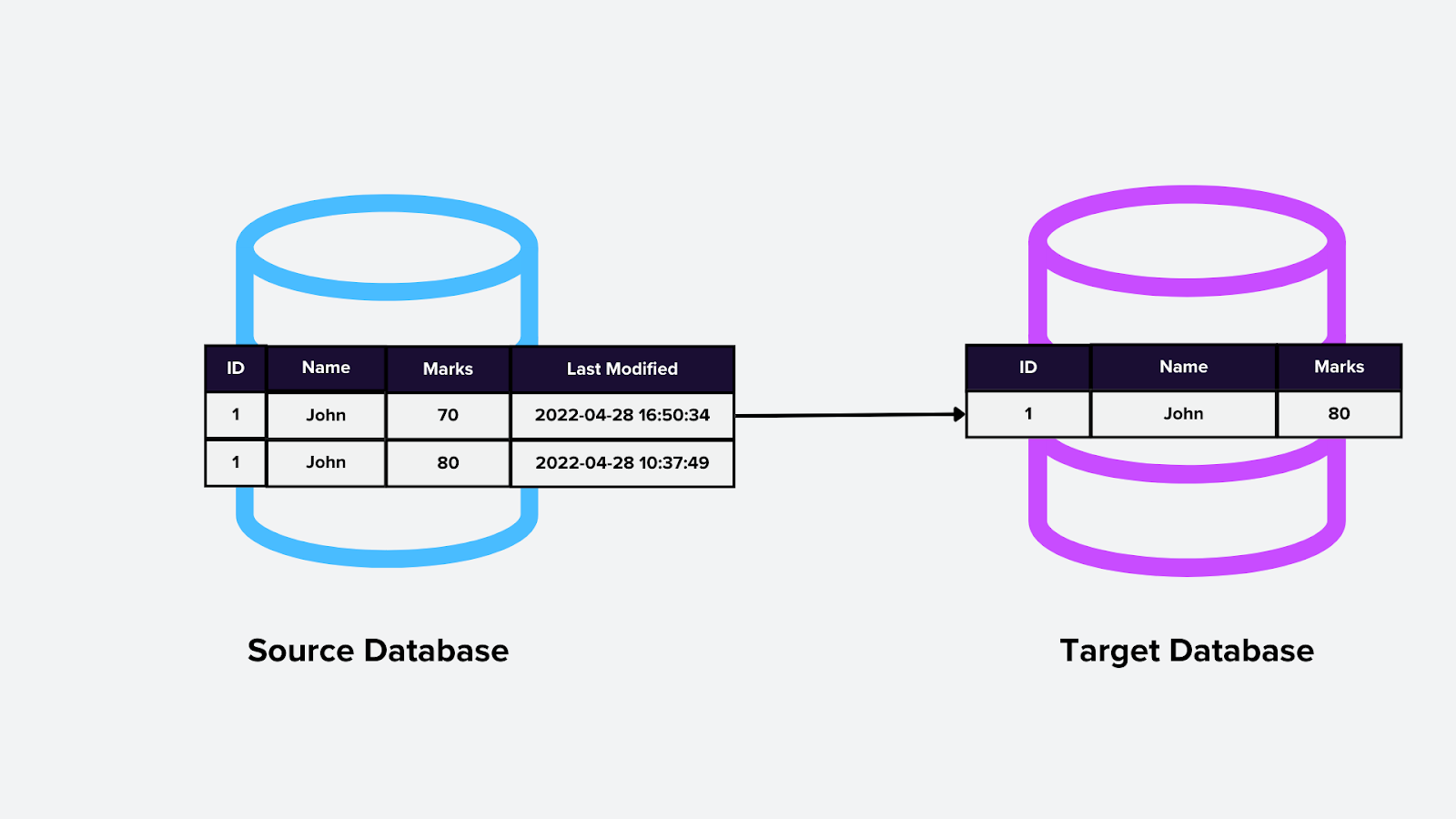 Figure- Query-based CDC.png
Figure- Query-based CDC.png
Рисунок: CDC на основе запросов
Плюсы:
Простая настройка: Не требует глубокой интеграции с базой данных или ее модификации.
Независимость от базы данных: Работает практически с любой базой данных, поддерживающей запросы.
Минусы:
Задержка: Не в реальном времени, поскольку зависит от расписания запросов.
Накладные расходы на производительность: Частые запросы могут создавать нагрузку на базу данных.
Ограниченная точность: Может пропустить изменения, если модификации данных происходят между интервалами запросов.
Сравнение механизмов CDC
Таблица ниже дает краткое представление о различных механизмах CDC и их вариантах использования:
| Механизм | Реальное время | Влияние на производительность | Простота настройки | Пригодность для сценария использования |
| На основе логов | Да | Низкое | Средняя | Транзакционные системы с большим объемом данных |
| На основе триггеров | Да | Среднее-высокое | Низкая-средняя | Сценарии, требующие пользовательской логики изменений |
| На основе запросов | Нет | Высокое | Высокая | Простые конфигурации с редкими изменениями |
Таблица: Сравнение механизмов CDC
CDC с Milvus: интеграция данных в реальном времени для векторных баз данных
Milvus, векторная база данных с открытым исходным кодом (разработанная инженерами Zilliz), созданная для управления неструктурированными данными, такими как векторные эмбеддинги из моделей машинного обучения, имеет собственный инструмент CDC, Milvus-CDC, который специально разработан для выполнения задач репликации и синхронизации данных в экземплярах Milvus. Milvus-CDC фиксирует инкрементальные изменения данных для бесшовной синхронизации между исходными и целевыми экземплярами Milvus. Это поддерживает такие задачи, как инкрементное резервное копирование, аварийное восстановление и постоянная репликация данных при сохранении целостности и согласованности данных. Milvus-CDC включает два основных компонента: HTTP Server, который управляет пользовательскими запросами, выполняет задачи и поддерживает метаданные задач, и Corelib, который обрабатывает синхронизацию задач, с reader, извлекающим данные из исходного экземпляра Milvus и очереди сообщений, и writer, который обрабатывает эти изменения и отправляет их в целевой экземпляр Milvus.
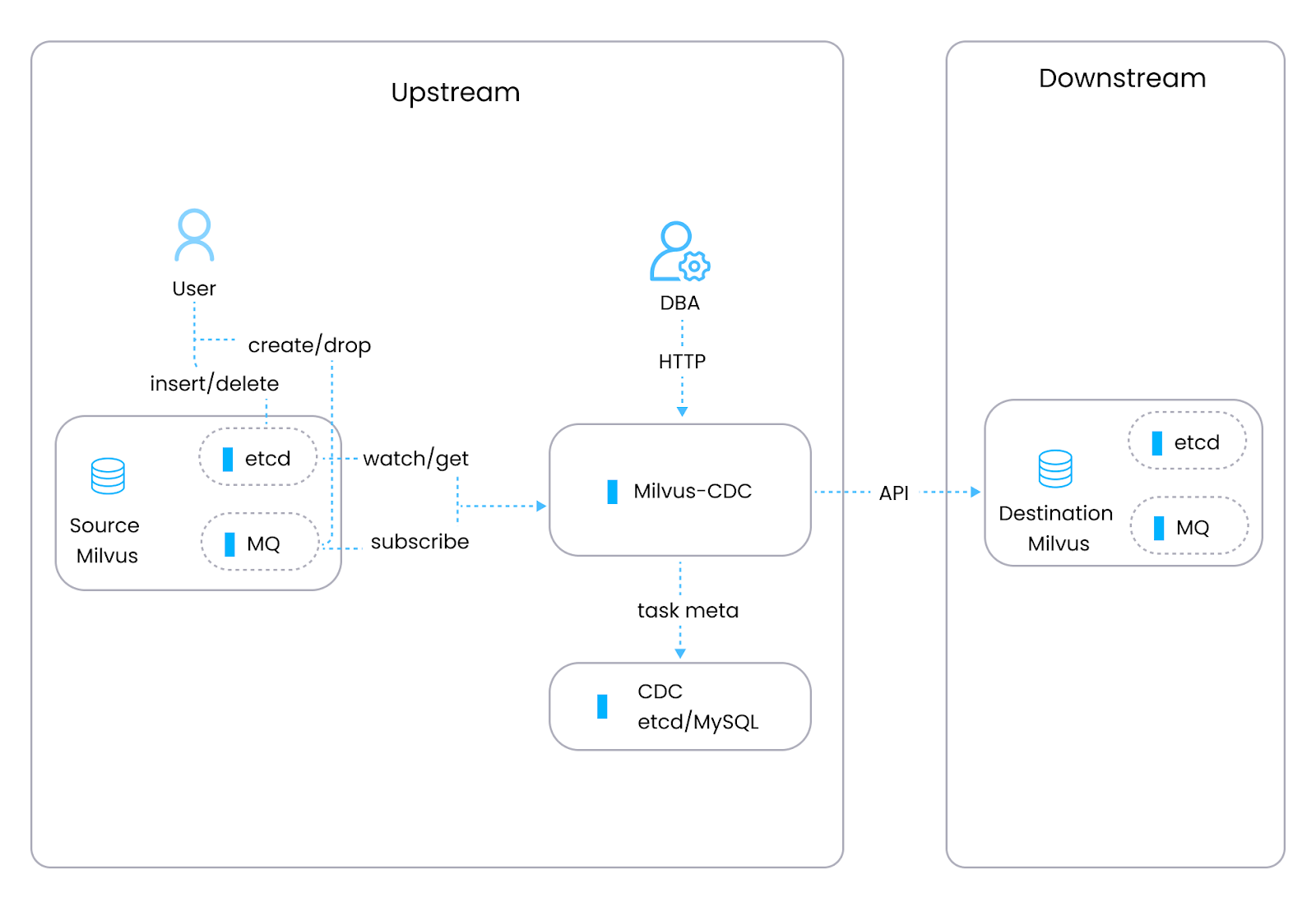 Figure- The Milvus-CDC architecture.png
Figure- The Milvus-CDC architecture.png
Рисунок: Архитектура Milvus-CDC
Milvus-CDC: ключевые возможности
Последовательная синхронизация данных: Обеспечивает применение изменений для сохранения согласованности данных между экземплярами Milvus.
Инкрементальная репликация данных: Фиксирует и реплицирует изменения, такие как вставки и удаления, из исходного Milvus в целевой экземпляр.
Управление задачами: Пользователи могут создавать, управлять и удалять задачи CDC с помощью OpenAPI для интеграции с различными рабочими процессами.
Интеграция с будущими системами: Планируется расширить поддержку интеграции с системами потоковой обработки.
CDC в Milvus с использованием Kafka
Хотя Milvus-CDC специально адаптирован для Milvus, интеграция Milvus с Apache Kafka предлагает еще один подход к CDC. Kafka является центральным узлом, который фиксирует и распространяет изменения данных из различных источников с использованием инструментов CDC, таких как Kafka Sink connector. Затем эти изменения загружаются в Milvus, чтобы поддерживать векторную базу данных в актуальном состоянии с последними эмбеддингами или векторами признаков.
Чтобы подключить Kafka к Milvus, вы можете следовать этому руководству: Connect Kafka with Milvus.
Роль CDC в распределенных базах данных и облачно-ориентированных приложениях
По мере того как организации внедряют распределенные базы данных и облачно-ориентированные приложения для обработки крупномасштабных, географически распределенных рабочих нагрузок, CDC играет критически важную роль в бесшовной синхронизации данных между этими сложными системами.
Синхронизация данных в распределённых системах: В распределённых базах данных данные часто распределены между несколькими узлами или регионами для повышения производительности и масштабируемости. CDC немедленно распространяет изменения, внесённые на одном узле, на другие, чтобы поддерживать согласованность во всей системе.
Обмен данными в реальном времени в облачно-нативных архитектурах: Облачно-нативные приложения часто полагаются на микросервисы, каждый со своим хранилищем данных. CDC позволяет этим сервисам обмениваться обновлениями в реальном времени, не полагаясь на тяжёлые пакетные процессы, для поддержки событийно-ориентированных архитектур.
Репликация для высокой доступности и аварийного восстановления: Распределённые системы часто используют репликацию данных для высокой доступности. CDC фиксирует и реплицирует изменения на резервные узлы или системы аварийного переключения.
Оптимизация конвейеров данных: В средах, где несколько систем зависят от общих наборов данных, CDC предоставляет механизм для передачи изменений в реальном времени в аналитические платформы, озёра данных или очереди сообщений.
Применения CDC в векторной базе данных
Вот конкретные варианты использования CDC, особенно в AI-приложениях, работающих с векторной базой данных:
Семантический поиск: CDC обновляет векторную базу данных последними embeddings, что позволяет системам семантического поиска предоставлять точные и релевантные результаты. Например, корпоративная поисковая система может выдавать точные ответы на основе обновлений embeddings документов или запросов в реальном времени.
Рекомендательные системы: Векторные базы данных используют embeddings для формирования персонализированных рекомендаций. CDC передаёт изменения в реальном времени, такие как новое поведение пользователей или обновления продуктов, поэтому рекомендательные системы быстро адаптируются к изменяющимся данным.
Обнаружение мошенничества: В финансовых системах embeddings из транзакционных данных непрерывно обновляются в векторной базе данных. CDC обеспечивает потоковую передачу этих обновлений в реальном времени, чтобы мгновенно обнаруживать необычную активность и отмечать потенциальное мошенничество.
Распознавание изображений и видео: Для приложений, таких как тегирование или поиск визуально похожего контента, CDC поддерживает актуальность векторных embeddings, сгенерированных из изображений или видео, в базе данных. Это обеспечивает точные и быстрые результаты для сценариев использования в реальном времени, таких как модерация в социальных сетях или визуальный поиск в электронной коммерции.
Чат-боты и виртуальные ассистенты: CDC помогает RAG-based LLM чат-ботам предоставлять точные ответы в реальном времени. Например, embeddings, представляющие живые взаимодействия пользователей или обновлённые базы знаний, фиксируются и обновляются мгновенно, что улучшает производительность чат-ботов.
Обнаружение аномалий: CDC полезен в кибербезопасности, где необычные паттерны в сетевом трафике или системных журналах требуют немедленного внимания.
Преимущества CDC
CDC предоставляет значительные преимущества для современных архитектур данных, позволяя им работать эффективно и принимать обоснованные решения. Вот ключевые преимущества:
Инсайты в реальном времени: CDC предоставляет самые свежие данные для поддержки быстрого принятия решений. Поэтому компании могут мгновенно отслеживать производительность и тенденции.
Снижение задержки данных: Устраняет задержки, вызванные традиционной пакетной обработкой. Поскольку изменения отражаются в системах почти сразу, они повышают отзывчивость приложений, зависящих от синхронизированных данных.
Масштабируемость в крупных системах: Он обрабатывает большие объёмы изменений данных, что делает его подходящим для крупномасштабных баз данных и распределённых сред.
Бесшовная репликация и миграция данных: Эта функция облегчает репликацию данных между системами в реальном времени для высокой доступности, аварийного восстановления и балансировки нагрузки. Она также упрощает миграции баз данных с использованием синхронизированных данных во время переходов с минимальным временем простоя.
Поддержка событийно-ориентированных архитектур: Обеспечивает работу событийно-ориентированных приложений, запуская последующие рабочие процессы или процессы на основе изменений данных. Таким образом, это повышает автоматизацию и оперативность бизнес-операций.
Точность и согласованность данных: Все подключенные системы имеют согласованные и точные данные, что снижает количество ошибок и несоответствий. Таким образом, это обеспечивает надежную основу для создания устойчивых решений на основе данных.
Проблемы внедрения CDC
Внедрение CDC может быть сложным, и организациям необходимо решить несколько проблем для обеспечения эффективной и надежной работы. Ключевые препятствия включают:
Накладные расходы производительности: Захват и обработка изменений в реальном времени могут создавать дополнительную нагрузку на базу данных, что влияет на производительность основных приложений. Кроме того, ресурсоемкие методы, такие как триггеры или частые запросы, могут ухудшать время отклика базы данных. Баланс между скоростью, точностью и надежностью требует оптимизированного проектирования конвейера.
Обработка изменений схемы: Изменения схемы базы данных, такие как добавление столбцов, изменение типов данных или изменение структур таблиц, могут нарушить работу конвейеров CDC.
Сетевые и хранилищные аспекты: Непрерывная потоковая передача данных в CDC требует достаточной емкости хранилища и эффективных методов сжатия, чтобы избежать стремительного роста затрат. Увеличение сетевого трафика может создать нагрузку на пропускную способность, особенно в географически распределенных системах.
Целостность данных в конвейере CDC: Сбои или несоответствия в конвейере могут поставить под угрозу точность последующих систем. Обработка событий, поступающих не по порядку, и разрешение конфликтов в распределенных средах могут добавить сложности.
Совместимость инструментов и привязка к поставщику: Некоторые решения CDC привязаны к конкретным базам данных или технологиям, что ограничивает гибкость в гетерогенных средах. Переход на другие инструменты или обновление систем может потребовать переработки процессов CDC.
Риски безопасности и соответствия требованиям: Потоковая передача конфиденциальных данных в реальном времени требует надежного шифрования и контроля доступа для предотвращения несанкционированного доступа. Соблюдение правил защиты данных, таких как GDPR или CCPA, может усложнить внедрение CDC.
Инструменты и фреймворки для CDC
Для внедрения CDC доступно несколько инструментов и фреймворков, каждый из которых имеет уникальные функции, адаптированные под конкретные сценарии использования. Вот список популярных вариантов:
Debezium**: Платформа CDC с открытым исходным кодом, построенная на Apache Kafka, Debezium поддерживает различные базы данных, такие как MySQL, PostgreSQL, MongoDB и SQL Server. Она идеально подходит для потоковой передачи данных в реальном времени и интеграции с событийно-ориентированными архитектурами.
Oracle GoldenGate: Надежное CDC-решение корпоративного уровня от Oracle, GoldenGate поддерживает высокопроизводительную репликацию данных и интеграцию в реальном времени между гетерогенными базами данных. Оно широко используется для аварийного восстановления и миграции.
AWS Database Migration Service (DMS): ****Полностью управляемый сервис от Amazon, поддерживающий CDC для различных баз данных как локально, так и в облаке. Он упрощает миграцию и репликацию данных, не требуя значительных накладных расходов.
Qlik Replicate: Ранее известный как Attunity Replicate, Qlik Replicate поддерживает CDC для широкого спектра баз данных и файловых систем. Он разработан для быстрой, масштабируемой репликации данных и интеграции в аналитические платформы.
Confluent Kafka Connect: Часть экосистемы Confluent, Kafka Connect предлагает возможности CDC для потоковой передачи изменений данных в темы Kafka. Он также бесшовно интегрируется с платформой Kafka для обработки событий в реальном времени.
Заключение
CDC играет жизненно важную роль в современных системах данных благодаря обновлениям в реальном времени и интеграции между платформами. Устраняя ограничения пакетной обработки, CDC поддерживает аналитику в реальном времени, событийно-ориентированные архитектуры и бесшовную синхронизацию данных. Такие инструменты, как Apache Kafka, дополнительно усиливают CDC, упрощая обработку изменений в нижестоящих системах, включая векторные базы данных, такие как Milvus. Это помогает компаниям работать с неструктурированными данными, масштабировать операции и создавать отзывчивые приложения.
Связанные ресурсы
- Что такое Change Data Capture (CDC)?
- Эволюция интеграции данных: роль CDC
- Как работает Change Data Capture?
- CDC с Milvus: интеграция данных в реальном времени для векторных баз данных
- Роль CDC в распределенных базах данных и облачно-ориентированных приложениях
- Применения CDC в векторной базе данных
- Преимущества CDC
- Проблемы внедрения CDC
- Инструменты и фреймворки для CDC
- Заключение
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно