




Оценка RAG с помощью раг
*Это сообщение написано Кристи Бергман, Шахулом Эсом и Джитином Джеймсом.
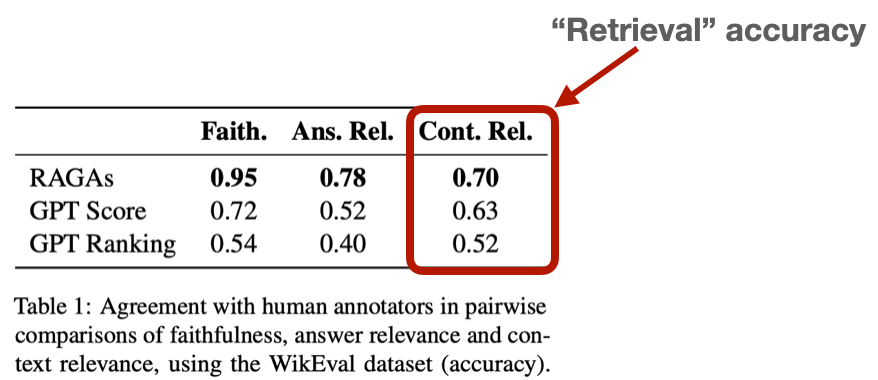
Поиск информации - важнейший компонент генеративных систем ИИ, и его проблемы особенно очевидны в Retrieval Augmented Generation (RAG). Retrieval Augmented Generation улучшает работу чат-ботов на базе ИИ, генерируя ответы на основе обширных данных, на которых были обучены большие языковые модели (LLM). Несмотря на развитость систем RAG, точность поиска остается серьезным препятствием, о чем свидетельствуют низкие результаты таких бенчмарков, как WikiEval. Чтобы преодолеть эти трудности, необходимо создать комплексную систему оценки и провести тщательные эксперименты для точной настройки параметров RAG и достижения оптимальной производительности.
**Однако прежде чем проводить эксперименты с RAG, необходимо найти способ оценить, какие эксперименты дали наилучшие результаты.
Источник изображения: https://arxiv.org/abs/2309.15217
Что такое рага?
Ragas - это специализированная система оценки, предназначенная для определения эффективности систем Retrieval Augmented Generation (RAG). Она предоставляет структурированный подход к оценке эффективности реализаций RAG, используя в качестве судей продвинутые большие языковые модели (LLM). Ragas фокусируется на автоматизации процесса оценки, предлагая масштабируемые и экономически эффективные решения для оценки ответов, сгенерированных ИИ. Система призвана устранить предвзятость и предложить непрерывные, объяснимые оценки для естественно-языковых результатов. Ragas упрощает оценку сложных систем RAG, предоставляя интуитивно понятные метрики и оптимизируя процесс оценки качества поиска.
Важность оценки систем RAG
Эффективная оценка RAG-систем крайне важна для совершенствования ответов ИИ. Надежная система оценки гарантирует, что эксперименты дадут надежные результаты и что ИИ предоставит точные и контекстуально подходящие ответы. Автоматизация процесса оценки может упростить и ускорить эту задачу, сделав ее более экономичной и масштабируемой.
Использование магистрантов в качестве судей
Использование больших языковых моделей (LLM), таких как GPT-4, для [оценки] (https://arxiv.org/pdf/2306.05685) получило распространение благодаря их способности оценивать различные аспекты качества поиска, включая релевантность и точность. Хотя может показаться необычным, что один LLM оценивает другой, исследования показывают, что GPT-4 совпадает с человеческими оценками примерно в 80% случаев, что соответствует "байесовскому пределу " человеческого согласия. Этот метод автоматизирует процесс оценки, обеспечивая масштабируемость и снижая затраты по сравнению с ручным человеческим маркированием.
Подходы к оценке на основе LLM
Существует два основных подхода к использованию LLM в качестве судей для RAG-оценки:
MT-Bench использует LLM для оценки только тех пар "вопрос-ответ", которые проверены человеком. Люди сначала проверяют вопросы и ответы, чтобы убедиться, что вопросы достаточно сложны для проведения достойных тестов, а затем LLM использует 80 пар "вопрос-ответ" для оценки различных декодеров (генеративных компонентов ИИ). [Paper, Code, Leaderboard] (https://huggingface.co/spaces/lmsys/mt-bench).
Ragas построен на идее, что LLM могут эффективно оценивать вывод естественного языка, формируя парадигмы, которые преодолевают предубеждения, связанные с использованием LLM в качестве судей напрямую, и предоставляя непрерывные оценки, которые объяснимы и интуитивно понятны). Paper, Code, Docs.
В остальной части этого блога мы расскажем о программе Ragas, в которой особое внимание уделяется автоматизации и масштабируемости оценок RAG.
Данные для оценки, необходимые для Ragas
Согласно документации Ragas, для оценки трубопровода RAG вам понадобятся четыре ключевые точки данных.
Вопрос: Заданный вопрос.
Контексты: Текстовые фрагменты из ваших данных, которые лучше всего соответствуют смыслу вопроса.
Ответ: Сгенерированный чатботом RAG ответ на вопрос.
Истинный ответ: Ожидаемый ответ на вопрос.
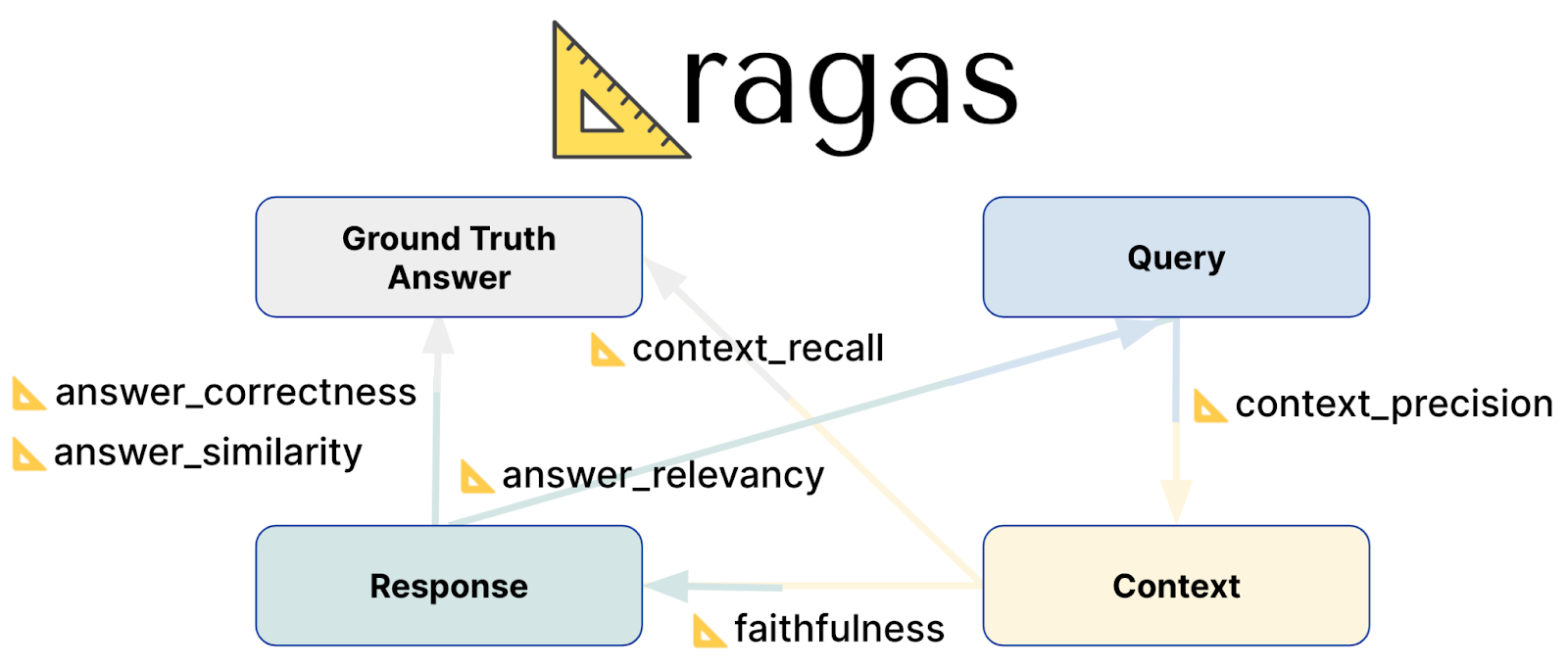 Ragas Evaluation Metrics
Ragas Evaluation Metrics
Ключевые метрики оценки
Пояснения к каждой метрике оценки, включая формулы, лежащие в их основе, можно найти в документации. Например, верность. Ragas предоставляет ряд оценочных баллов для определения эффективности систем RAG:
Faithfulness: Этот балл оценивает, насколько точно сгенерированный ответ отражает информацию в заданном контексте. Он измеряет фактическую точность ответа, обеспечивая его соответствие контексту, из которого он был получен. Баллы варьируются от 0 до 1, при этом более высокие значения указывают на большую точность и последовательность.
Актуальность ответа: Метрика соответствия ответа оценивает, насколько хорошо созданный ответ отвечает заданию. Она фокусируется на полноте и релевантности ответа, наказывая неполные или избыточные ответы. Показатель релевантности определяется на основе вопроса, контекста и ответа, причем более высокие показатели отражают лучшее соответствие запросу.
Вспоминание контекста: Показатель Context Recall измеряет, насколько эффективно найденный контекст соответствует истинному ответу. Рассчитывается доля успешно найденных релевантных фрагментов по сравнению с ожидаемой. Баллы варьируются от 0 до 1, при этом более высокие значения указывают на то, что была найдена большая часть релевантного контекста.
Точность контекста: Эта метрика оценивает, ранжируются ли наиболее релевантные элементы контекста выше, чем менее релевантные. Она проверяет, все ли релевантные фрагменты контекста появляются в верхней части списка. Точность контекста определяется с помощью вопроса, исходной истины и контекстов, при этом более высокие баллы указывают на лучшее ранжирование релевантной информации.
Релевантность контекста: Этот показатель релевантности контекста оценивает, насколько найденный контекст соответствует вопросу. Он измеряет степень соответствия контекста смыслу запроса. Метрика варьируется от 0 до 1, при этом более высокие значения показывают, что контекст более релевантен вопросу.
Припоминание контекстных сущностей: Эта метрика рассчитывает, насколько хорошо найденный контекст отражает сущности, упомянутые в исходной информации. Она измеряет долю сущностей, найденных как в контексте, так и в исходной информации, по отношению к общему количеству сущностей в исходной информации. Более высокие показатели указывают на лучший захват важных сущностей в контексте.
Подробности о том, как рассчитываются эти метрики, можно найти в их [статье] (https://arxiv.org/abs/2309.15217).
Пример кода оценки RAG
Этот код оценки предполагает, что у вас уже есть демоверсия RAG. Для своей демонстрации я создал чатбота RAG, используя для поиска Техническую документацию Milvus и векторную базу данных Milvus. Полный код моей демонстрации RAG notebook и Eval notebook находится на GitHub.
Используя эту демонстрацию RAG, я задавал ей вопросы, получал контексты RAG из Milvus и генерировал ответы бота из LLM (см. последние 2 колонки ниже). Кроме того, я привожу "истинные" ответы на те же вопросы (колонка "контексты" ниже).
Вы должны установить OpenAI, набор данных (HuggingFace), ragas, langchain и pandas.
# pip install openai dataset ragas langchain pandas
import pandas as pd
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
display(eval_df.head())

Преобразуйте кадр данных pandas в набор данных HuggingFace.
from datasets import Dataset
def assemble_ragas_dataset(input_df):
список_вопросов, список_истин, список_контекстов = [], [], []
список_вопросов = input_df.Question.to_list()
истина_лист = eval_df.ground_truth_answer.to_list()
context_list = input_df.Custom_RAG_context.to_list()
context_list = [[context] for context in context_list]
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# Создайте набор данных HuggingFace из списков истинности.
ragas_ds = Dataset.from_dict({"вопрос": список_вопросов,
"контексты": context_list,
"ответ": rag_answer_list,
"ground_truth": truth_list
})
return ragas_ds
# Создаем набор данных Ragas HuggingFace из pandas df.
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

Модель LLM, используемая Ragas по умолчанию, - это gpt-3.5-turbo-16k от OpenAI, а модель встраивания по умолчанию - text-embedding-ada-002. Вы можете изменить обе модели на любые, какие вам нравятся.
Я изменю модель LLM-as-judge на прикрепленную gpt-3.5-turbo, поскольку в последнем блоге OpenAI объявил, что она самая дешевая. Я также изменил модель embedding на text-embedding-3-small, поскольку в блоге было отмечено, что эти новые embeddings поддерживают compression-mode.
В приведенном ниже коде я использую только метрику оценки RAG context, чтобы сосредоточиться на измерении качества поиска релевантных документов.
import os, openai, pprint
from openai import OpenAI
# Сохраните ключ api в переменной env.
openai_api_key=os.environ['OPENAI_API_KEY']
# Выберите метрики, которые вы хотите видеть.
from ragas.metrics import ( context_recall, context_precision, faithfulness, )
metrics = ['context_recall', 'context_precision', 'faithfulness']
# Измените llm-as-critic.
from ragas.llms import llm_factory
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(model=LLM_NAME)
# Также измените вкрапления.
from langchain_openai.embeddings import OpenAIEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# Измените модели по умолчанию, используемые для каждой метрики.
for metric in metrics:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# Оцениваем набор данных.
из ragas import evaluate
ragas_result = evaluate( ragas_input_ds,
metrics=[ context_precision, context_recall, faithfulness, ],
llm=ragas_llm,
)
# Просмотр оценок.
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

Вы можете посмотреть полный код моих демо RAG notebook и Eval notebook на GitHub.
Заключение
В этом блоге мы рассмотрели текущие проблемы поиска в генеративном ИИ, уделив особое внимание методам Retrieval Augmented Generation ([RAG] techniques](https://zilliz.com/learn/guide-to-chunking-strategies-for-rag)) для развития систем ИИ на естественном языке. Эффективные эксперименты необходимы для оптимизации параметров RAG под конкретные данные и случаи использования, обеспечивая наилучшую производительность. Оценка систем RAG теперь может быть значительно улучшена за счет автоматизации с использованием LLM в качестве оценщиков. Мы рассмотрели ключевые метрики оценки RAG и методы их расчета, а также предложили взглянуть на их практическое применение. Кроме того, был приведен пример реализации с использованием векторной базы данных Milvus и пакета Ragas, демонстрирующий, как эти инструменты могут быть эффективно использованы для улучшения и масштабирования систем оценки RAG. Такой подход не только упрощает процесс оценки, но и повышает общую эффективность контекстного поиска в решениях, основанных на ИИ. Для дальнейшего изучения изучите реальные приложения, решите проблемы, изучите будущие направления, придерживайтесь лучших практик и обращайтесь к дополнительным ресурсам, чтобы углубить свое понимание оценки систем RAG и доработать свой конвейер RAG.

Читать далее

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.