




Инфраструктурные проблемы при масштабировании RAG с помощью пользовательских моделей искусственного интеллекта
Системы Retrieval Augmented Generation (RAG) значительно расширили возможности приложений ИИ, предоставляя более точные и контекстуально релевантные ответы. Однако масштабирование и развертывание этих систем в производстве сопряжено со значительными трудностями, поскольку они становятся все более сложными и включают в себя собственные модели ИИ.
Во время недавнего Unstructured Data Meetup, организованного компанией Zilliz, Chaoyu Yang, основатель и генеральный директор BentoML, поделился своим мнением об инфраструктурных проблемах при масштабировании систем RAG с пользовательскими моделями ИИ и рассказал о том, как такие инструменты, как BentoML, могут упростить развертывание и управление этими компонентами. В этом посте мы повторим ключевые моменты Чаою Яна и рассмотрим продвинутые шаблоны выводов и методы оптимизации. Эти стратегии помогут вам создать RAG-системы, которые будут не только мощными, но и эффективными и экономичными.
Смотрите повтор выступления Чаою на Youtube
Как RAG расширяет возможности приложений ИИ
Системы Retrieval Augmented Generation (RAG) появились для решения проблемы галлюцинаций в приложениях GenAI. Объединяя возможности поиска векторных сходств в векторных базах данных, таких как Milvus и Zilliz Cloud, с генеративной мощью больших языковых моделей (LLMs), системы RAG позволяют моделям ИИ создавать ответы, которые являются:
более точными
контекстуально релевантными
Невероятно информативно
Без галлюцинаций
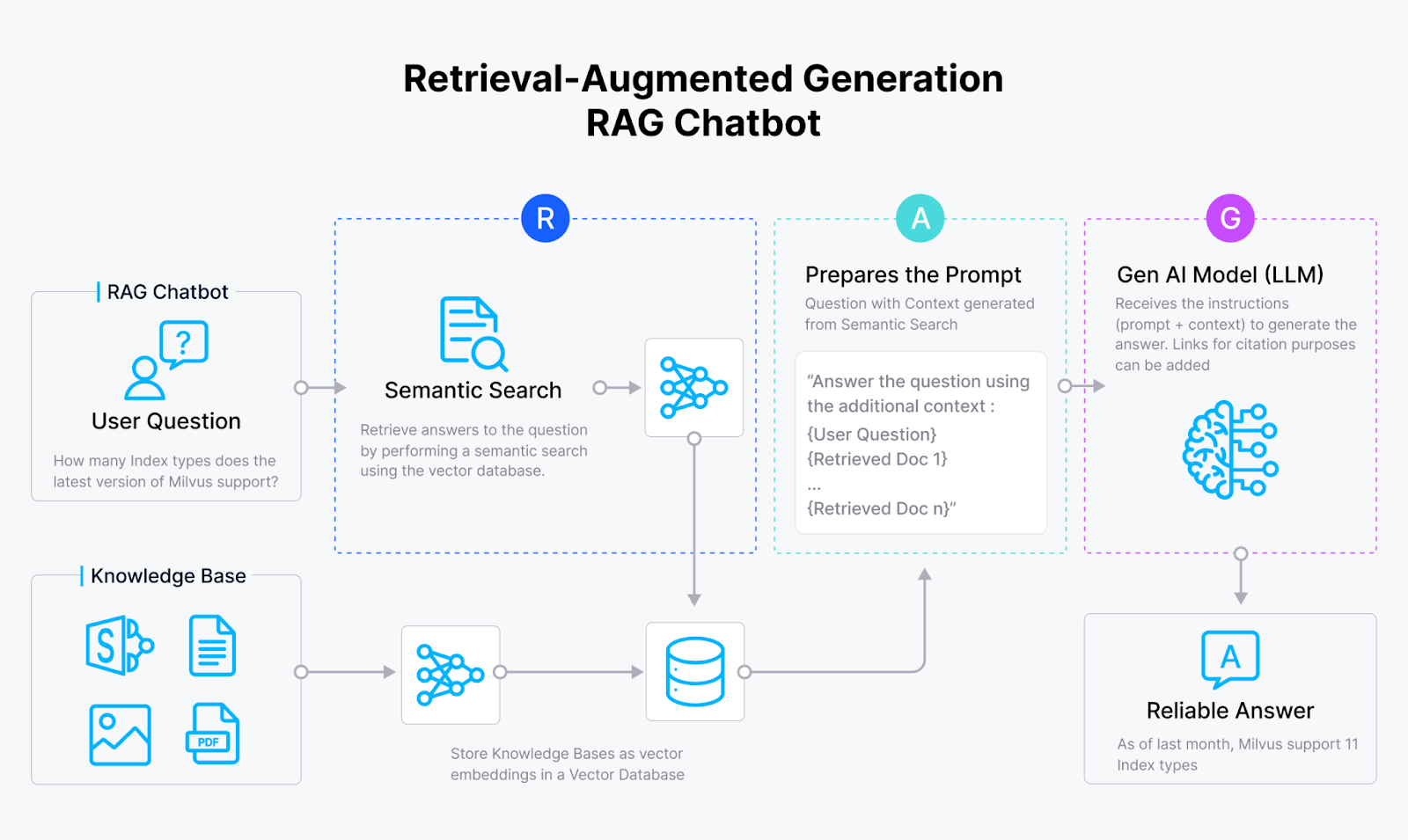
Как работает чатбот RAG
Эти системы способны преобразовать широкий спектр областей, включая:
ответы на вопросы
Резюме документов
Генерация персонализированного контента
И многое другое.
Системы RAG достигают этой цели, используя обширные знания, скрытые во внешних источниках, как некий ИИ-библиотекарь!
Проблемы при развертывании RAG-систем в производстве
Прежде чем RAG-системы начнут работать в производственных средах, им предстоит преодолеть немало трудностей. Одно из самых серьезных препятствий - обеспечение первоклассной производительности поиска, что включает в себя:
Оптимизация поиска: Убедиться, что вся необходимая информация получена.
Оптимизация точности: Минимизация количества нерелевантной информации
Что еще более интересно, системам RAG часто приходится иметь дело со сложными неструктурированными источниками данных. Представьте себе, как можно разобраться с PDF-файлом, в котором макетов, таблиц и изображений больше, чем в комиксе! Для решения этой проблемы требуются очень сложные методы обработки и понимания документов.
Еще одна проблема, с которой сталкиваются системы RAG, - генерирование ответов, которые были бы точными, контекстуально подходящими и соответствовали намерениям пользователя. Это все равно что написать связную историю, используя только фрагменты из разных книг!
Кроме того, обеспечение безопасности и достоверности генерируемого контента также имеет решающее значение, особенно когда ставки высоки. Мы же не хотим, чтобы наши системы искусственного интеллекта сбились с пути и распространяли дезинформацию!
Пользовательские модели ИИ - надежный помощник в этой истории. Благодаря тонкой настройке и адаптации моделей ИИ к конкретным областям и наборам данных разработчики могут наделить свои системы RAG сверхспособностями, необходимыми для решения этих задач.
Использование пользовательских моделей ИИ для повышения производительности RAG
Чтобы раскрыть весь потенциал RAG-систем, очень важно использовать пользовательские модели ИИ, адаптированные под конкретный случай использования. Тонкая настройка и оптимизация этих моделей позволяет значительно повысить их производительность. Давайте рассмотрим некоторые ключевые области, в которых пользовательские модели ИИ могут оказать значительное влияние.
Модели встраивания текста: Основа успеха RAG
Стандартные модели встраивания текста, такие как "text-embedding-ada-002", часто не способны уловить нюансы нашей специфической области. Эта модель занимает 57-е место в рейтинге MTEB leaderboard, что указывает на значительные возможности для улучшения.
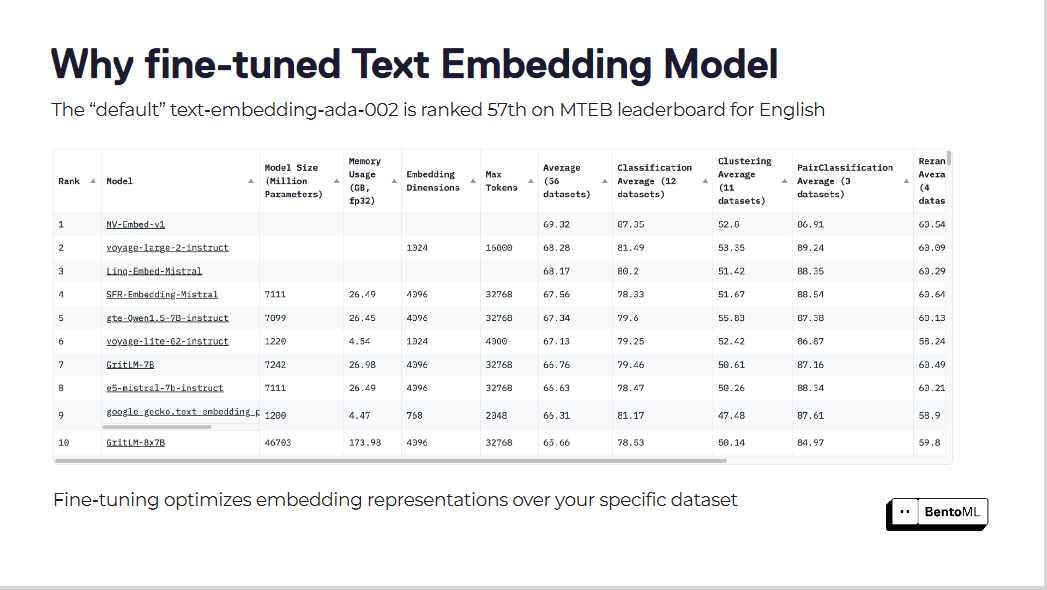
Тонкая настройка оптимизирует представления встраивания для вашего конкретного набора данных
Тонкая настройка этих моделей встраивания может привести к значительному улучшению результатов поиска. Оптимизируя модели встраивания для конкретных наборов данных, системы RAG добились значительного повышения производительности.
Хостинг наших магистров: Взятие под контроль
Собственные LLM предлагают удобство, но не всегда отвечают нашим потребностям или ограничениям. LLM с открытым исходным кодом позволяют нам настраивать и адаптировать модели к нашим требованиям. При размещении наших LLM мы должны учитывать следующие ключевые факторы:
Безопасность и конфиденциальность данных
Латентность и производительность
Необходимые специфические возможности
Стоимость и масштабируемость
Обслуживание и поддержка
Обработка и понимание документов: Извлечение информации из неструктурированных данных
Системы RAG часто нуждаются в обработке и понимании сложных неструктурированных документов, таких как PDF, изображения и т. д. Интеграция различных моделей и техник может помочь извлечь ценные сведения. Например, мы можем провести:
Анализ макета с помощью LayoutLM
Обнаружение таблиц с помощью трансформаторов таблиц TATR
OCR с помощью EasyOCR или Tesseract
Визуальный контроль качества документов с помощью LayoutLM v3 или Donut
Тонкая настройка этих моделей для конкретных типов документов может значительно повысить их производительность.
Расширенные методы для повышения точности поиска
Для дальнейшего повышения точности поиска мы можем рассмотреть возможность применения следующих методов:
Контекстно-ориентированная разбивка и глобально-концептуальная разбивка: Эти методы помогают определить наиболее релевантную информацию для поиска, учитывая контекст и общие концепции в документах.
Извлечение метаданных:** Извлечение метаданных из документов может обеспечить дополнительный контекст для улучшения поиска и синтеза ответов.
Модели реранкеров:** Тонкая настройка моделей реранкеров на пользовательских наборах данных может привести к повышению производительности на 10-30 % по сравнению с типовыми моделями.
Используя пользовательские модели ИИ в этих ключевых областях, мы можем значительно повысить производительность нашей системы RAG.
Однако эффективное развертывание и обслуживание этих моделей сопряжено с определенными трудностями. В следующем разделе мы обсудим некоторые инфраструктурные проблемы при масштабировании RAG с помощью пользовательских моделей.
Инфраструктурные проблемы при масштабировании RAG с помощью пользовательских моделей
По мере того как системы RAG становятся все более сложными и включают в себя множество пользовательских моделей, значительно возрастают требования к вычислительным ресурсам и необходимость в эффективном развертывании и управлении. Масштабирование систем Retrieval Augmented Generation (RAG) с пользовательскими моделями ИИ становится насущной необходимостью, но сопряжено с уникальным набором инфраструктурных проблем.
Эффективное обслуживание пользовательских API для вывода моделей
Одной из основных проблем является эффективное обслуживание пользовательских API для вывода моделей. Системы RAG часто требуют интеграции нескольких моделей, таких как:
Модели встраивания текста
Большие языковые модели (LLM)
Модели обработки документов
Каждая модель может иметь различные вычислительные требования и характеристики производительности. Развертывание этих моделей в виде API для выводов, способных обрабатывать запросы в режиме реального времени и масштабироваться в зависимости от спроса, является сложной задачей.
Чтобы решить эту проблему, необходимо иметь надежную и масштабируемую инфраструктуру для обслуживания API-интерфейсов вывода моделей. Эта инфраструктура должна быть способна удовлетворить специфические требования каждой модели, такие как распределение GPU, управление памятью и ограничения по задержкам. Технологии контейнеризации, такие как Docker, могут помочь инкапсулировать зависимости моделей и обеспечить согласованную среду выполнения в различных системах.
Эффективные механизмы масштабирования
Однако простого контейнеризации моделей недостаточно. Инфраструктура должна также поддерживать эффективные механизмы масштабирования для обработки различных рабочих нагрузок. Это требование включает автоматическое масштабирование количества экземпляров моделей в зависимости от входящего трафика запросов, обеспечение оптимального использования ресурсов и минимизацию времени отклика.
Оптимизация обслуживания моделей
Еще одна важная задача - оптимизация обслуживания моделей с точки зрения производительности и экономичности. Пользовательские модели ИИ, особенно большие языковые модели, могут быть вычислительно дорогими. Наивные стратегии развертывания могут привести к неоптимальному использованию ресурсов и увеличению затрат. Такие методы, как динамическое пакетирование, когда несколько запросов группируются для использования параллелизма графических процессоров, могут значительно повысить пропускную способность и сократить время отклика.
Помимо динамического пакетирования, для сокращения объема памяти и вычислительных требований пользовательских моделей можно применять и другие методы оптимизации, такие как квантование, обрезка и дистилляция моделей. Однако реализация этих оптимизаций требует тщательного учета компромиссов между производительностью модели и эффективностью использования ресурсов.
Эффективное распределение ресурсов и автомасштабирование
Эффективное распределение ресурсов и автомасштабирование также являются важными аспектами масштабирования RAG-систем с пользовательскими моделями. Инфраструктура должна быть способна динамически распределять ресурсы в зависимости от требований к рабочей нагрузке каждой модели. Такой подход предполагает мониторинг ключевых показателей, таких как загрузка GPU, использование памяти и задержка запросов, для принятия обоснованных решений по масштабированию. Механизмы автоматического масштабирования должны уметь справляться с внезапными скачками трафика и соответствующим образом масштабировать ресурсы для поддержания оптимальной производительности.
Композиция и оркестровка нескольких моделей
Кроме того, инфраструктура должна поддерживать композицию и оркестровку нескольких моделей в системе RAG. Системы RAG часто включают в себя сложные конвейеры, в которых выход одной модели служит входом для другой. Инфраструктура должна предоставлять инструменты и фреймворки для определения и управления этими конвейерами, обеспечивая беспрепятственный поток данных и эффективное выполнение.
Мониторинг и наблюдаемость
Мониторинг и наблюдаемость имеют решающее значение для поддержания работоспособности и производительности систем RAG с пользовательскими моделями. Инфраструктура должна предоставлять возможности комплексного мониторинга для отслеживания ключевых метрик, журналов и трассировок всех компонентов системы. Это позволяет быстро обнаруживать и диагностировать проблемы, а также оптимизировать и настраивать систему на основе реальных данных о производительности.
Непрерывная интеграция и развертывание (CI/CD)
Наконец, инфраструктура должна поддерживать непрерывную интеграцию и развертывание пользовательских моделей (CI/CD). По мере обновления и доработки моделей необходимо создать отлаженный процесс развертывания новых версий, не нарушающий работу всей системы. Это требует надежных механизмов версионирования, тестирования и отката для обеспечения стабильности и надежности системы RAG.
Для решения этих инфраструктурных задач требуется сочетание инструментов, фреймворков и лучших практик. В следующем разделе мы рассмотрим, как BentoML, платформа для обслуживания и развертывания моделей машинного обучения, может помочь решить эти проблемы и упростить масштабирование систем RAG с пользовательскими моделями ИИ.
Создание API-интерфейсов вывода для пользовательских моделей с помощью BentoML
BentoML упрощает процесс создания и развертывания API-интерфейсов вывода для пользовательских моделей в системах RAG. Он обеспечивает плавный переход от разработки модели к готовым к производству API, позволяя ускорить итерации и упростить интеграцию с существующими системами. Давайте посмотрим, как это может помочь нам преодолеть инфраструктурные проблемы масштабирования RAG.
От сценария вывода к конечной точке обслуживания
С помощью всего нескольких строк кода вы можете легко преобразовать сценарий вывода в конечную точку обслуживания с помощью BentoML. Давайте рассмотрим пример создания сервиса BentoML для модели встраивания текста с точной настройкой:
import torch
from sentence_transformers import SentenceTransformer, models
class SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
def encode(
self,
предложения: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
Этот фрагмент кода определяет класс SentenceTransformers для инкапсуляции модели встраивания и связанных с ней методов. Внутри метода __init__`` модель SentenceTransformerинициализируется тонкой настройкой модели и устанавливается для работы на устройстве "cuda". Методкодирования`` принимает на вход список предложений и возвращает их вкрапления в виде массива NumPy.
Чтобы превратить это в сервис BentoML, вы можете добавить декораторы @bentoml.service и @bentoml.api:
import bentoml
@bentoml.service
класс SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
@bentoml.api
def encode(
self,
предложения: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
Для обслуживания модели вы можете использовать BentoML CLI:
bentoml serve .
Эта команда запускает сервер BentoML и обслуживает модель, определенную в текущем каталоге. Вывод CLI показывает, что служба прослушивает [http://localhost:3000](http://localhost:3000).
Затем вы можете делать запросы к обслуживаемой модели с помощью клиента BentoML:
import bentoml
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
result: np.NDArray = client.encode(
sentences=["образец входного предложения"],
)
Оптимизация обслуживания
BentoML предоставляет несколько готовых оптимизаций обслуживания. Одной из самых мощных оптимизаций является динамическое пакетирование. Добавив в определение API параметр batchable=True, BentoML автоматически сортирует входящие запросы, оптимизируя загрузку GPU и повышая пропускную способность обслуживаемой модели.
@bentoml.api(batchable=True)
def encode(self, sentences: t.List[str]) -> np.ndarray:
return self.model.encode(sentences)
Динамическое пакетирование интеллектуально формирует небольшие пакеты, группируя входящие запросы, разбивая большие пакеты и автоматически настраивая размер пакета. Эта оптимизация позволяет в 3 раза увеличить время отклика и на ~200% повысить пропускную способность при обслуживании встраивания.
Инфраструктура развертывания и обслуживания
BentoML предлагает гибкую и масштабируемую инфраструктуру развертывания и обслуживания. Она поддерживает различные варианты развертывания, включая контейнеризацию с помощью Docker и оркестровку с помощью Kubernetes. Вы можете легко указать требования к ресурсам, например количество и тип графических процессоров, и настроить параметры трафика, такие как параллелизм и внешние очереди.
импорт bentoml
@bentoml.service(
ресурсы={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
трафик={
"concurrency": 512,
"external_queue": True
}
)
класс SentenceTransformers:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
Адаптивные функции микропакетов и эластичного масштабирования BentoML обеспечивают оптимальное использование ресурсов и автоматическое масштабирование в зависимости от входящего трафика. Кроме того, он предоставляет удобную панель развертывания, которая позволяет получить представление о частоте запросов, времени отклика и использовании ресурсов. Далее рассмотрим, как масштабировать LLM-инференцию с помощью BentoML.
Масштабирование служб LLM-инференции с помощью BentoML
BentoML предоставляет всесторонние возможности и оптимизации, чтобы помочь вам эффективно масштабировать ваши сервисы LLM-инференции.
Стратегии автомасштабирования
Автомасштабирование гарантирует, что ваши сервисы LLM-инференции смогут справиться с различной рабочей нагрузкой и поддерживать оптимальную производительность. Однако традиционные показатели автомасштабирования, такие как загрузка GPU и количество запросов в секунду (QPS), могут неточно отражать желаемое количество реплик для служб LLM.
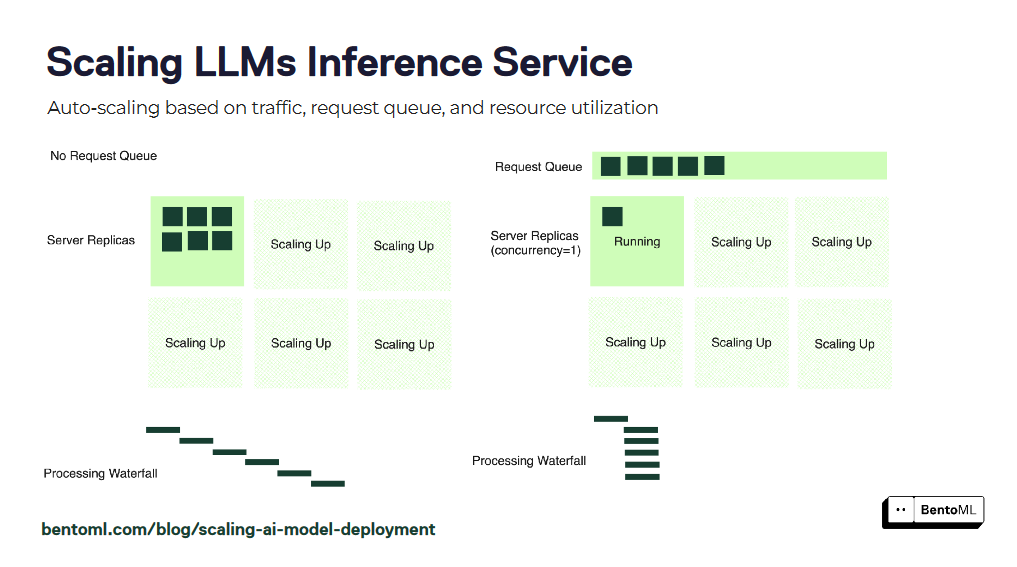
BentoML представляет автомасштабирование на основе параллелизма - более эффективный подход для масштабирования сервисов LLM-инференции. Автомасштабирование на основе параллелизма учитывает количество одновременных запросов, которые может обработать каждая реплика модели, обеспечивая более точное представление возможностей сервиса.
Оптимизация холодного старта
Холодный старт может стать серьезной проблемой при масштабировании сервисов LLM-инференции, особенно при использовании больших образов контейнеров и файлов моделей. BentoML предлагает несколько методов оптимизации для уменьшения задержки при холодном запуске.
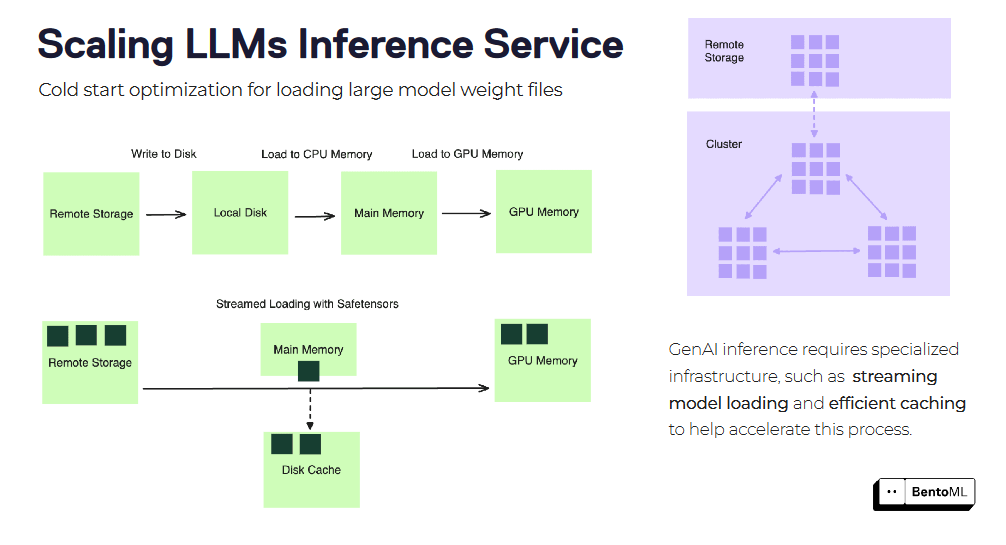
Одним из таких методов является потоковая загрузка образов контейнеров. Вместо того чтобы загружать весь образ контейнера перед запуском службы, BentoML может загружать образ в потоковом режиме, получая только необходимые файлы по требованию. Это может значительно сократить время запуска новых реплик.
Еще одна оптимизация - эффективная загрузка и кэширование файлов с весом модели. BentoML может кэшировать загруженные веса модели между репликами, сокращая время загрузки модели для каждого нового запроса. Это особенно полезно для больших языковых моделей с обширными файлами весов.
Используя стратегии автомасштабирования BentoML и оптимизацию холодного старта, вы можете эффективно масштабировать свои службы вывода LLM, чтобы справиться с требованиями вашей системы RAG. BentoML абстрагируется от сложностей управления инфраструктурой, позволяя вам сосредоточиться на разработке и итерации ваших моделей, обеспечивая при этом оптимальную производительность и масштабируемость.
Advanced Inference Patterns for RAG Systems
Системы RAG часто требуют расширенных шаблонов вывода для обработки сложных рабочих процессов и оптимизации производительности. BentoML предоставляет гибкую и расширяемую структуру для поддержки этих шаблонов, позволяя с легкостью создавать сложные RAG-системы.
Конвейеры обработки документов могут быть построены путем объединения нескольких моделей и этапов обработки, таких как анализ макета, извлечение таблиц и OCR.
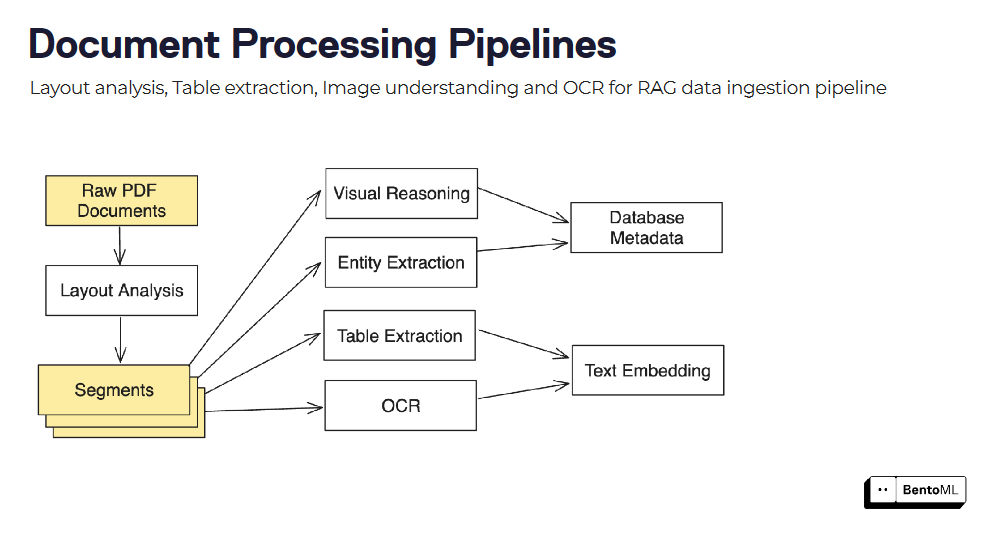
Асинхронный интерфейс BentoML эффективно справляется с длительными задачами, а поддержка пакетного анализа позволяет обрабатывать большие массивы данных с использованием параллелизма и оптимизаций.
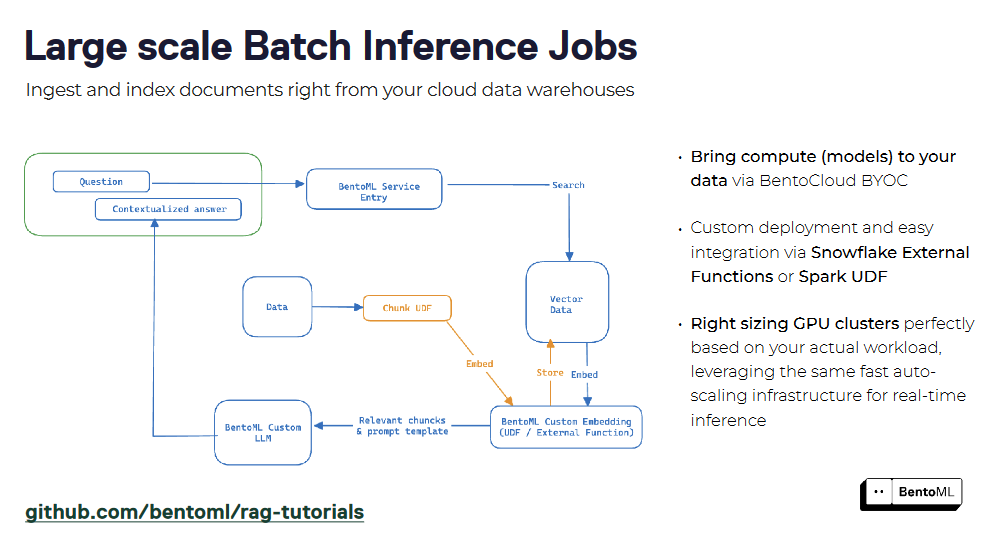
Системы RAG могут быть упакованы как сервис с помощью BentoML, создавая единый интерфейс для запросов и взаимодействия. Инкапсулируя компоненты ретривера и генератора, вы можете легко развернуть сервис RAG и интегрировать его с другими приложениями. Поддержка контейнеризации и оркестровки в BentoML упрощает масштабирование и управление сервисами RAG в производственных средах.
Эти усовершенствованные шаблоны выводов демонстрируют гибкость и расширяемость BentoML при создании мощных и эффективных RAG-сервисов, которые справляются с различными задачами и рабочими нагрузками.
Помимо инфраструктуры для обслуживания LLM, нам также нужна надежная база данных векторов для хранения наших векторных вкраплений и выполнения поиска по сходству. В этом нам поможет векторная база данных Milvus. В следующем разделе мы рассмотрим создание простого приложения RAG с использованием BentoML и Milvus.
Интеграция BentoML и векторной базы данных Milvus
Milvus - это векторная база данных с открытым исходным кодом, предназначенная для высокопроизводительного поиска сходства и являющаяся ключевым компонентом инфраструктуры для создания Retrieval Augmented Generation (RAG).
Milvus интегрирован с BentoML, что упрощает создание масштабируемых приложений RAG. В этом разделе мы расскажем вам о создании приложения RAG с помощью BentoML и векторной базы данных Milvus. В этом примере мы будем использовать Milvus Lite, облегченную версию Milvus, для быстрого создания прототипов.
Набор данных, который мы используем, можно найти здесь: City data.
Шаг 1: Настройка среды
Сначала установите необходимые библиотеки, как показано ниже:
# Установите необходимые библиотеки
pip install -U pymilvus bentoml
Шаг 2: Подготовьте данные
Давайте загрузим и обработаем данные City data.
импорт os
импорт запросов
import urllib.request
# Настройте источник данных
repo = "ytang07/bento_octo_milvus_RAG"
директория = "data"
save_dir = "./city_data"
api_url = f "https://api.github.com/repos/{repo}/contents/{directory}"
# Загрузить файлы с GitHub
response = requests.get(api_url)
data = response.json()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for item in data:
if item["type"] == "file":
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# Обработка загруженных данных
def chunk_text(filename):
with open(filename, "r") as f:
text = f.read()
предложения = text.split("\n")
return [s for s in sentences if len(s) > 7]
города = os.listdir("city_data")
city_chunks = []
for city in cities:
chunked = chunk_text(f "city_data/{city}")
city_chunks.append({
"название_города": city.split(".")[0],
"chunks": chunked
})
Шаг 3: Настройка клиентов BentoML
Теперь мы настроим клиенты BentoML для модели встраивания и LLM, как показано ниже.
import bentoml
# Устанавливаем конечные точки и API-токен
EMBEDDING_ENDPOINT = "YOUR_EMBEDDING_MODEL_ENDPOINT"
LLM_ENDPOINT = "YOUR_LLM_ENDPOINT"
API_TOKEN = "YOUR_API_TOKEN"
# Инициализация клиентов BentoML
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
Замените конечные точки и токен на ваши реальные конечные точки развертывания BentoML и токен API. Эти клиенты позволят нам генерировать вкрапления и использовать языковую модель для генерации текста.
Шаг 4: Генерация вкраплений
Перед генерацией вкраплений давайте создадим функцию вкраплений, как показано ниже:
Создать функцию встраивания
def get_embeddings(texts):
# Обработка больших партий текстов
if len(texts) > 25:
splits = [texts[x : x + 25] for x in range(0, len(texts), 25)]
embeddings = []
для split в splits:
embedding_split = embedding_client.encode(sentences=split)
embeddings += embedding_split
return embeddings
# Обрабатывать небольшие партии напрямую
return embedding_client.encode(sentences=texts)
Эта функция обрабатывает пакетную обработку для больших наборов текстов, поскольку модель встраивания может иметь ограничения на размер входных данных.
**Генерирует вкрапления для всех фрагментов.
entries = []
for city_dict in city_chunks:
# Получение вкраплений для текстовых фрагментов каждого города
embedding_list = get_embeddings(city_dict["chunks"])
# Создайте записи с вкраплениями и метаданными
for i, embedding in enumerate(embedding_list):
entry = {
"embedding": embedding,
"предложение": city_dict["chunks"][i],
"city": city_dict["city_name"],
}
entries.append(entry)
Здесь мы создаем список записей, каждая из которых содержит вставку, исходное предложение и название города. Эта структура пригодится вам при вставке данных в Milvus.
Шаг 5: Настройка Milvus
Теперь мы инициализируем векторную базу данных, используя Milvus для добавления вкраплений.
Инициализация клиента Milvus и создание схемы.
from pymilvus import MilvusClient, DataType
COLLECTION_NAME = "Bento_Milvus_RAG"
DIMENSION = 384 # Это должно соответствовать выходному размеру вашей модели встраивания
# Инициализация клиента Milvus
milvus_client = MilvusClient("milvus_demo.db")
# Создать схему
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=DIMENSION)
Здесь мы используем Milvus lite, который встраивается в приложение. Схема определяет нашу структуру данных в Milvus, включая автоматически генерируемый идентификатор и вектор встраивания.
Подготовьте параметры индекса и создайте коллекцию
# Подготовка параметров индекса
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# Создайте или воссоздайте коллекцию
if milvus_client.has_collection(collection_name=COLLECTION_NAME):
milvus_client.drop_collection(collection_name=COLLECTION_NAME)
milvus_client.create_collection(
имя_коллекции=COLLECTION_NAME, schema=schema, index_params=index_params
)
Мы используем AUTOINDEX, который автоматически выбирает оптимальный тип индекса на основе данных. В качестве метрики расстояния для сравнения векторов используется косинусное сходство.
Введите данные в Milvus
Теперь мы вставим данные в Milvus, как показано ниже
# Вставка предварительно обработанных данных в Milvus
milvus_client.insert(collection_name=COLLECTION_NAME, data=entries)
Этот шаг вставляет все наши предварительно обработанные данные (вкрапления и метаданные) в коллекцию Milvus.
Шаг 6: Реализация RAG
Чтобы эффективно реализовать RAG, мы создадим три функции для генерации ответа RAG, получения соответствующего контекста из коллекции и генерации ответа, как показано ниже:
Создайте функцию для LLM для генерации ответов.
def generate_rag_response(question, context):
# Подготовьте подсказку для LLM
prompt = (
f "Вы - полезный помощник. Ответьте на вопрос пользователя, основываясь только на контексте: {context}. \n"
f "Вопрос пользователя - {question}"
)
# Генерируем ответ с помощью LLM
results = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(results)
Эта функция строит подсказку, используя полученный контекст и вопрос пользователя, а затем использует LLM для генерации ответа.
Создайте функцию для получения соответствующего контекста
def retrieve_context(question):
# Генерируем вкрапления для вопроса
embeddings = get_embeddings([question])
# Поиск похожих векторов в Milvus
res = milvus_client.search(
collection_name=COLLECTION_NAME,
data=embeddings,
anns_field="embedding",
limit=5,
output_fields=["sentence"],
)
# Извлечение и объединение релевантных предложений
sentences = [hit["entity"]["sentence"] for hits in res for hit in hits]
return ". ".join(sentences)
Эта функция вставляет вопрос пользователя, ищет похожие векторы в Milvus и извлекает соответствующие фрагменты текста для контекста.
Комбинируйте вышеуказанные функции для создания конвейера RAG.
def ask_question(question):
# Получаем соответствующий контекст
context = retrieve_context(question)
# Генерируем ответ на основе контекста и вопроса
return generate_rag_response(question, context)
Эта функция связывает все вместе, создавая наш конвейер RAG.
Шаг 7: Используйте вашу систему RAG
Теперь мы можем использовать нашу систему RAG для ответов на вопросы, как показано ниже:
# Пример использования
вопрос = "В каком штате находится Кембридж?"
answer = ask_question(question)
print(f "Вопрос: {question}")
print(f "Ответ: {answer}")
Этот пример демонстрирует, как использовать систему RAG для ответа на конкретный вопрос о городе.
Важные замечания:
Перед выполнением этого кода убедитесь, что ваши модели встраивания и большие языковые модели правильно развернуты на BentoML.
Размерность ваших вкраплений (384 в данном примере) должна соответствовать выходным данным вашей модели вкраплений.
В этой установке используется Milvus Lite, который подходит для небольших наборов данных. Для более масштабных приложений лучше использовать полное развертывание Milvus на Docker или K8s.
Эффективность системы RAG зависит от качества и охвата ваших исходных данных о городе. Для достижения наилучших результатов убедитесь, что ваш набор данных является полным и точным.
Интеграция BentoML и Milvus позволяет создать мощную систему RAG, способную отвечать на вопросы на основе предоставленной информации о городе. Вы можете расширить эту систему, добавив дополнительные данные или настроив ее для конкретных случаев использования.
Заключение
Создание и масштабирование Retrieval Augmented Generation (RAG) систем с пользовательскими моделями ИИ представляет собой уникальную задачу. Разработчики могут создавать высокопроизводительные и масштабируемые системы RAG, используя возможности пользовательских моделей, оптимизируя инфраструктуру развертывания и обслуживания, а также применяя передовые модели вывода.
BentoML - ценный инструмент на этом пути. Он упрощает процесс создания и развертывания API для выводов, оптимизирует производительность сервисов и обеспечивает плавное масштабирование.
Интегрируя BentoML с векторной базой данных Milvus, организации могут создавать более мощные и масштабируемые системы RAG. Эта комбинация позволяет эффективно извлекать релевантную информацию и генерировать ответы с учетом контекста, открывая возможности для передовых приложений ИИ в различных областях и отраслях.
Для получения дополнительной информации о BentoML и RAG ознакомьтесь со следующими ресурсами
How to Enhance the Performance of Your RAG Pipeline - Zilliz blog
Mastering LLM Challenges: An Exploration of RAG - Zilliz blog
Ingesting Chaos: MLOps Behind Handling Unstructured Data Reliably at Scale for RAG (milvus.io)
Почему Milvus делает построение RAG проще, быстрее и экономически эффективнее - блог Zilliz
Читать далее

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.