




SuperGLUE: 高度な自然言語処理評価のための包括的ベンチマーク
SuperGLUE: 高度な自然言語処理評価のための包括的ベンチマーク
TL; DR
SuperGLUE (Super General Language Understanding Evaluation)は、自然言語理解(NLU)モデルの性能を評価するために設計されたベンチマークです。前身であるGLUEをベースに、質問応答、共参照解決、推論などの複雑な言語推論を扱うモデルの能力を評価するため、より難易度の高いタスクを導入しています。SuperGLUEは、文脈理解、知識検索、マルチタスク学習などのスキルをテストするだけでなく、多様なデータセットとメトリックのセットを含みます。NLUの限界を押し広げるために開発され、人間の推論に近いタスクを反映しています。SuperGLUEで高得点を獲得することは、実世界の言語課題に取り組むモデルの堅牢性と有効性を示します。
序論
自然言語処理(NLP)は、チャットボットからレコメンデーションシステムに至るまで、機械が人間と対話する方法を一変させた。ELMo](https://paperswithcode.com/method/elmo)、BERT、GPTなどのモデルは、言語理解の閾値を再定義し、人間の言語モデリングと理解を向上させた。これらの変革は、GLUEベンチマークへの道を開いた。ベンチマークは、様々なタスクに対する言語モデルの能力を評価する体系的な評価手段である。
しかし、NLPモデルがより賢くなるにつれ、私たちがより困難な課題に直面していることは明らかです。そこで、****SuperGLUEが登場します。このテストでは、より高度で厳しい目標を掲げ、推論、常識的な理解、ニュアンスに富んだ文脈解釈に基づく新しいタスクの数々が用意されています。SuperGLUEは、厳しい実世界の言語問題を解決するモデルの能力をテストするため、NLPモデルにはより厳しいテストが課される。
この記事では、SuperGLUEのユニークな特徴、含まれるタスク、そしてSuperGLUEがより洗練された信頼性の高い自然言語処理モデルの開発をどのように推進しているかをご紹介します。
SuperGLUE とは?
SuperGLUE** は Super General Language Understanding Evaluation の略で、NLP モデルが幅広い複雑な言語理解タスクをどの程度処理できるかをテストするために作成されたベンチマークです。これは基本的にGLUEのアップグレード版で、レベルを上げるように設計されている。GLUEがより単純なタスクに焦点を当てているのに対し、SuperGLUEはより深い推論、常識的な知識、文脈の理解を要求する、より洗練された課題を含んでいます。例えば、GLUEのタスクが2つの文が意味的に似ているかどうかを評価するのに対し、Winograd Schema Challenge (WSC)のようなSuperGLUEのタスクでは、曖昧な代名詞を常識的な推論で解決する必要があります。
SuperGLUEは、GLUEの中で最も難易度の高い2つのタスク(RTEとWNLI)を保持し、モデルを単純なパターンマッチングから意味的・語用論的知識へと押し上げるよう設計された、全く新しい6つのタスクを導入しています。
SuperGLUE の目標は?
SuperGLUEは、基本的な言語処理を超えて、複雑なシナリオにおいてモデルが推論、推論を行い、常識的な知識を使用できるかどうかを確認するように設計されています。
より難しいタスクを導入することで、SuperGLUE は研究者がより高度で有能な機械学習技術を開発する動機付けとなります。
SuperGLUEは、より単純な課題に焦点を当てたGLUEとは異なり、複雑な実世界の入力に対してモデルがどのように動作するかをテストする、より現実的で包括的な方法を提供します。
SuperGLUEは、将来を念頭に置いて構築されており、今日の最高のモデルでさえ改善の余地が十分にあるほど挑戦的であるため、NLPの進歩を追跡するための貴重なツールとなっています。
SuperGLUE の仕組み
SuperGLUEは言語スキルに挑戦することでNLPモデルを評価します。これらのタスクは、単に文章を分類したり、個々の単語を予測したりするだけでなく、現実世界の複雑な問題に取り組む必要があります。これには、共参照の解決(どの単語やフレーズが同じものを指しているかを把握すること)、推論(テキストから論理的な結論を導き出すこと)、文脈におけるエンティティ間の関係の理解などが含まれます。それぞれのタスクは、人間の言語が持つニュアンスや高度な要求を、モデルがどれだけうまく処理できるかを測るものである。
タスクの詳細
SuperGLUE は多くのタスクのスーパーセットである。その前に、モデルのパフォーマンスをスコア化するために必要な様々な評価指標を見る。
評価指標
SuperGLUE はタスクに応じていくつかの評価指標を採用している:
Exact Match (EM):**予測された答えが期待された答えと完全に一致するかどうかを評価するタスクに使用される。
F1 Score:** 複数の正解が可能な場合の精度と再現率を測定します。
BoolQのような単純な分類タスクで使用される、正しく予測された例の割合。
マクロ平均F1:** クラス間のF1スコアの平均で、クラスの不均衡があってもバランスの取れた評価を保証する。
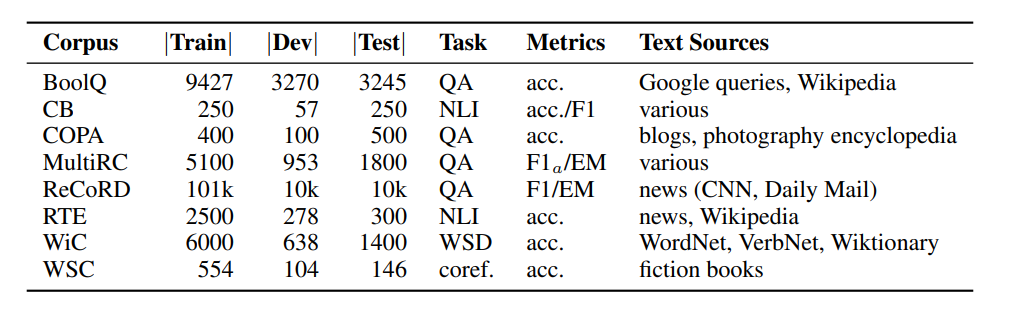 図- SuperGLUE ベンチマーク- 各タスクのコーパスサイズ、メトリクス、テキストソースを含む SuperGLUE タスクのサマリー表.png
図- SuperGLUE ベンチマーク- 各タスクのコーパスサイズ、メトリクス、テキストソースを含む SuperGLUE タスクのサマリー表.png
図SuperGLUE Benchmark:各タスクのコーパスサイズ、メトリクス、テキストソースを含む SuperGLUE タスクのサマリー表。
それでは、SuperGLUE の課題の詳細と多様性を理解するために、SuperGLUE のタスクの詳細な概要を探ってみましょう。
1.BoolQ(ブールQ)*タスク
BoolQ は、二者択一の質問応答タスクで、与えられた文章をもとに、YES/NOの質問が正しいかどうかをモデルが判断します。以下はこのタスクの入力、出力、評価基準である:
| 入力| 出力| メトリック**|です。 | -------------------------------------------------- | --------------------------------------------- | ---------- | | 通路と通路に関するYes/Noの質問。| ブール値(「はい」は「真」、「いいえ」は「偽」)。| 精度
以下はその例です:
**以下はその例である:"Barq'sはカフェインを含むソフトドリンクで、コカ・コーラ社によって瓶詰めされている。"
質問:「Barq'sのルートビアにはカフェインが含まれていますか?
出力:真
2.CB(コミットメント・バンク)* 2.
CBでは、テキストに埋め込まれた節が真(含意)、偽(矛盾)、不確定(中立)のどれであるかを評価する。
| 前提(premise)と仮説(hypothesis)。| ラベル(含意、中立、矛盾)。| 精度およびマクロ平均F1。|
以下はその例である:
前提:"彼女は会議に出席するかもしれないと言った。"
仮説:"彼女は会議に出席するのは確実だ"
出力:矛盾
3.COPA(妥当な選択肢の選択)*。
COPAは、モデルが2つの選択肢から与えられた前提の最も確からしい原因または結果を決定する因果推論タスクである。
| ---------------------------------------------- | ---------------------------------------- | ---------- | | 前提条件と2つの選択肢(因果関係)。| より確からしい選択肢(1または2)。| 精度
例を見てみよう:
前提:「草が濡れている。
代替案 1:"昨夜雨が降った"
代替案 2:"太陽は明るく輝いていた"
**アウトプット1
4.MultiRC(多文読解).
MultiRCは、パッセージに基づく問題に答えるもので、各問題には複数の正解がある場合がある。
| インプット** | アウトプット** | メトリック |
|---|---|---|
| パッセージ、質問、可能な答えのセット。 | 各回答に対するバイナリ・ラベル(真または偽)。 | F1と完全一致。 |
簡単な例です:
パッセージ:「スーザンは友人をパーティーに招待した。スーザンは友人をパーティーに招待した。
**質問"病気の友人はパーティーに出席しましたか?"
回答:「はい」、「いいえ
出力:はい
5.ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset).
ReCoRDは、文章中のマスキングされた実体を予測するために、常識的推論を必要とするClozeスタイルの読解課題である。
| ------------------------------------------- | --------------------------------------------- | ---------- | | マスクされたエンティティとクエリを含むパッセージ。| 候補リストから正しいエンティティ。| F1とEM。|
これが簡単な例である:
**以下は簡単な例である:「テスラは<マスク>によって創設された。
**クエリー「誰がテスラを創業したのか?
**候補者「イーロン・マスク"、"ニコラ・テスラ"、"トーマス・エジソン"
出力:イーロン・マスク
6.**RTE(テキスト内包の認識)
RTEは、与えられた前提に基づき、仮説が真か偽か不確定かを判断する。
| --------------------------- | ------------------------------------------------ | ---------- | | 前提および仮説。| ラベル(含意、中立、矛盾)。| 精度
以下はその例である:
前提:"クリストファー・リーブの未亡人、ダナ・リーブが44歳で亡くなった。"
仮説:"ダナ・リーヴは44歳で亡くなった"
出力:内容
7.WiC(ワード・イン・コンテクスト)*。
WiCは、ある単語が2つの異なる文脈で同じ意味で使われているかどうかを判定することで、語義曖昧性解消をテストする。
| ---------------------------------------------- | ---------------------------------------------------------------- | ---------- | | 同じ単語を含む2つの文。| 二値ラベル(同じ意味なら真、異なる意味なら偽)。| 精度
例を見てみよう:
**例を見てみよう:「彼は板を壁に釘で打ち付けた。
文章 2:"チェス盤は美しく細工されていた"
**ターゲット・ワード"ボード"
出力:偽
8.WSC (ウィノグラード・スキーマ・チャレンジ).
WSCは共参照解決タスクであり、モデルが常識的推論を用いて曖昧な代名詞の正しい参照元を特定する。
| このタスクは、コモンセンス推論を用いて曖昧な代名詞の正しい参照元を特定する。 | ------------------------------------------- | --------------------- | ---------- | | 曖昧な代名詞を含む文。| 正しい参照元。| 精度
以下はその例である:
**文章「マークはテッドに本をあげたが、気に入らなかった。
代名詞:"彼"
出力:テッド
SuperGLUEの上記のタスクは、単なる言語理解を超えてNLPモデルに挑戦するものである。したがって、SuperGLUE は、理解、推論、および常識的な知識の効果的な適用に基づいてモデルを評価します。SuperGLUEは、多様な言語理解課題におけるモデルの精度と想起の両方を捉える包括的な評価フレームワークを提供します。
実装例
以下は、Hugging Faceライブラリを使用した SuperGLUE タスク ReCoRD のロードと対話の例です:
from datasets import load_dataset
# SuperGLUEからReCoRDタスクをロードする
dataset = load_dataset("super_glue", "record", trust_remote_code = True
)
# トレーニングデータにアクセス
train_data = dataset['train'] # 学習データにアクセスする。
# データポイントの例
example = train_data[0]
print(f "通過: {example['passage']}")
print(f "Query with masked entity: {example['query']}")
load_dataset` 関数は ReCoRD タスクをロードします。入力には、通路と、解決する必要があるマスクされたエンティティを含むクエリが含まれる。このモデルは、パッセージを理解し、常識的な推論を適用する能力を示すことで、マスクされたエンティティを正しく予測することを目指す。
図- 実装例の出力.png](https://assets.zilliz.com/Figure_Output_of_Implemented_Example_2aeec3adee.png)
図実装例の出力
SuperGLUE vs. GLUE: 主な相違点
SuperGLUE は GLUE を改良し、実世界の言語理解を反映した、より難易度の高いタスクを導入しました。
| 特徴 | GLUE | SuperGLUE |
|---|
| 推論要件|必要最小限の推論|高水準の推論と推論が必要 | タスクの多様性|主に文の分類と類似性のタスク|QA、共参照、読解を含む | 実世界での応用**|限定的な実世界での考察|実世界での言語課題をエミュレートするようにデザインされたタスク| 実世界での応用|限定的な実世界での考察|実世界での言語課題をエミュレートするようにデザインされたタスク
SuperGLUE の利点と課題
SuperGLUEは、推論と高度な文脈が要求される実世界のタスクをニュアンス豊かに解く能力に焦点を移すことで、これまでのNLPモデルの評価方法に取って代わるものです。SuperGLUEがNLPにもたらす具体的な利点と、研究者がSuperGLUEを最大限に活用する上で直面する課題について説明しよう。
利点
推論とコモンセンスをテストする:** SuperGLUE には、モデルがコモンセンスな知識を利用す ることを要求するタスクが含まれています。例えば、Winograd Schema Challenge (WSC)では、コモンセンスを使用した代名詞の解決がテストされ、COPAタスクでは、与えられたシナリオの中で最も妥当な原因または結果を選択することによる因果推論が評価されます。これらの課題は、実世界のシナリオでより能力を発揮できるようにする。
SuperGLUEは、より複雑なタスクを含むことで、GLUEの飽和状態を克服し、より単純なタスクでモデルが人間に近いパフォーマンスを達成することで、進歩を識別するための効果を低下させています。
SuperGLUE の複雑なタスクは、優れたパフォーマンスを発揮し、より解釈可能な出力を提供するモデルの開発を促し、モデルが特定の予測を行う方法と理由を研究者が理解するのに役立ちます。
実世界の問題を反映:** SuperGLUE のタスクは、読解や対話システムのようなアプリケーションでモデルが遭遇する問題を反映するように設計されています。例えば、ReCoRD タスクは、欠落した情報を推論するための常識的な推論をテストし、WSC は、仮想アシスタントや会話 AI にとって重要な能力である、あいまいな代名詞の解決を評価します。
洞察に満ちたエラー分析:** SuperGLUE は、特定の弱点を強調する多様で挑戦的なタスクを提供することで、研究者がモデルがどこでどのように失敗するかを調べることを可能にします。この詳細なエラー分析は、推論、常識的理解、文脈理解など、モデルが苦手とする分野を特定するのに役立ち、モデルをより堅牢で信頼性の高いものにするための的を絞った改善を可能にします。
課題
高い計算コスト:*** SuperGLUE でのモデルのトレーニングは、タスクが複雑なため計算コストがかかります。最適化されたアーキテクチャーとクラウドベースのインフラを活用することで、リソース需要を効率的に管理することができます。
複雑な微調整:** SuperGLUE の各タスクは、異なる微調整戦略を必要とします。マルチタスク学習アプローチと転移学習は、このプロセスを合理化するのに役立ちます。マルチタスク学習は、汎化を向上させるために関連するタスクでモデルを訓練し、転移学習は、大規模なデータと訓練の必要性を最小限に抑えるために、別のタスクのパフォーマンスを向上させるために1つのタスクから知識を適用します。
SuperGLUEのタスクには限られたデータしかないものもあり、学習中にモデルがオーバーフィットするリスクが高まります。この課題は、より多様なトレーニングサンプルを作成するためのデータ増強や、モデルの汎化を改善するための正則化のような技術を採用することで対処できます。
リーダーボードのランキングはモデルの性能を示すものですが、このスコアだけに注目すると、モデルの実用的な価値が損なわれる可能性があります。実世界での応用に注意を向けることで、モデルが実用的なシナリオで競争力を持ち、影響を与えることを確実にすることができます。
実装、ハードウェア、ハイパーパラメータにばらつきがあると、研究グループ間で結果を公平に比較することが難しくなります。評価プロトコルを標準化し、コードベースを共有し、共通のベンチマークを使用することで、より一貫性のある公平な比較が可能になります。
SuperGLUE の使用例
SuperGLUEは、実世界の複雑性に基づいたタスクでモデルに挑戦することで、NLPの改善に役立つ重要なベンチマークです。このような使用例としては、より優れた会話AIや推論システム、意味検索などが挙げられます。
SuperGLUEは、NLPだけでなく、それ以外の分野でも数多くの用途があります:
会話 AI:** SuperGLUE は、より良い推論と常識でニュアンスのあるクエリを理解するモデルの能力をテストするベンチマークを提供することで、バーチャルアシスタントの開発を強化します。
SuperGLUE は、モデルの論理的推論能力を評価・改善することで、意思決定支援ツールの作成を支援します。
読解:** SuperGLUE は、高度な理解と文脈理解を必要とするタスクに挑戦することで、NLP モデルが長い文書を正確に分析し要約することを可能にし、研究と教育を支援します。
知識表現と推論:** SuperGLUE は、関係性を理解し、常識的な推論を適用するモデルの能力をテストすることで、より堅牢な知識グラフの構築を支援し、検索エンジンや推薦システムをサポートします。
意味検索とベクトルデータベース:** SuperGLUE は、モデルが複雑で大規模な情報検索タスクを効果的に処理できるようにすることで、意味検索の精度を向上させます。
SuperGLUE をサポートするツール
SuperGLUEの高度なタスクとベンチマークは、その実装と評価を容易にするために設計された他のツールとプラットフォームの開発につながりました。これらのツールは、研究者や開発者がデータへのアクセス、モデルのトレーニング、結果の分析についてより良い判断を下すのに役立ちます。
SuperGLUE の導入と相互作用をサポートし、強化するツールを見てみましょう。
ツール
Hugging Face Datasets:** SuperGLUE タスクをロードし、対話する簡単な方法を提供し、モデル開発とテストを合理化します。
TensorFlow Datasets:** SuperGLUE タスクのフォーマット済みバージョンを提供し、TensorFlowベースのモデルとうまく統合します。
AllenNLP:**NLPタスクのモジュールとコンポーネントを提供し、SuperGLUEの実験をより簡単にします。
SuperGLUE による AI モデルの評価と RAG によるモデルの強化
SuperGLUEのようなベンチマークは、大規模言語モデル(LLMs)の能力を評価するために不可欠です。SuperGLUEは、多様なタスクにおけるモデルのパフォーマンスを測定するための標準化されたフレームワークを提供し、モデル間の直接比較を容易にします。推論のような長所を強調し、複雑な推論やドメイン固有のタスクに対する苦手意識のような短所を明らかにすることで、SuperGLUEは研究者が改善のための領域を特定するのに役立ちます。これらの洞察は、モデルの理解とコンテンツ生成能力を向上させる微調整を可能にします。
しかし、SuperGLUEはLLMを改善するために有益ではありますが、万能ではありません。LLMには、ベンチマークでの性能に関わらず、固有の限界があります。LLMは静的でオフラインのデータセットで訓練され、リアルタイムまたはドメイン固有の情報にアクセスできません。これは、モデルが不正確な答えや捏造された答えを生成する幻覚につながる可能性がある。これらの欠点は、独自のクエリや高度に専門化されたクエリに対応する場合、さらに問題となる。
RAGの導入:LLM応答を強化するソリューション
これらの課題に対処するため、RAG(Retrieval-Augmented Generation)は強力なソリューションを提供する。RAGは、MilvusやZilliz Cloudのようなベクトルデータベースに格納された外部の知識ベースからドメイン固有の情報を取得する能力と、その生成能力を組み合わせることによって、大規模言語モデル(LLM)を強化する。ユーザーが質問をすると、RAGシステムは関連する情報をデータベースから検索し、より正確な応答を生成するためにこの情報を使用する。RAGプロセスがどのように機能するか見てみよう。
図- RAGワークフロー.png](https://assets.zilliz.com/Figure_RAG_workflow_5bfbcccddf.png)
RAGシステムは通常、3つの主要なコンポーネントで構成されています。埋め込みモデル、ベクトルデータベース、そしてLLMです。
1.埋め込みモデルは、文書をベクトル埋め込みに変換し、Milvusのようなベクトルデータベースに格納する。
2.2.ユーザが質問をすると、システムは同じ埋め込みモデルを用いて、クエリをベクトルに変換する。
3.次に、ベクトルデータベースは、最も関連性の高い情報を検索するために、類似検索を実行する。この検索された情報は、元の質問と組み合わされ、「文脈のある質問」となり、LLMに送られる。
4.LLMは、より正確で文脈に関連した回答を生成するために、この強化された入力を処理する。
このアプローチは、静的なLLMとリアルタイムのドメイン固有のニーズとのギャップを埋める。
SuperGLUE の FAQ
1.**SuperGLUEはGLUEをベースに、GLUEのタスクをはるかに超える推論と常識的なタスクを導入しています。
2.**Transformerベースのモデルは、文脈と長距離依存関係を捉える自己注意メカニズム、大規模データセットでの広範な事前学習、スケーラビリティ、転移学習による適応性により、SuperGLUEで優れている。
3.**SuperGLUEでのモデル学習は、タスクの複雑さにより、大きな計算資源を必要とし、微調整、推論、大規模データセットの効果的な処理のために、大規模な処理能力を必要とします。
4.**SuperGLUEは汎化に重点を置いているが、ドメイン固有のデータを用いて微調整を加えることで、特定のドメイン向けにカスタマイズすることが可能である。
5.**SuperGLUE は、セマンティック検索や会話 AI のような実世界のアプリケーションでモデルを評価するための標準となる。
関連リソース
自然言語処理入門ガイド](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing)
SuperGLUEベンチマーク](https://super.gluebenchmark.com/)
SuperGLUE リーダーボード](https://super.gluebenchmark.com/leaderboard)
Hugging Face SuperGLUE Dataset](https://huggingface.co/datasets/aps/super_glue)
SuperGLUEデータセット](https://paperswithcode.com/dataset/superglue)
自然言語処理に役立つ20のオープンデータセット](https://zilliz.com/learn/popular-datasets-for-natural-language-processing)
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
ベクトルデータベースとは何か、どのように機能するのか ](https://zilliz.com/learn/what-is-vector-database)