




ニュースにおける多言語ナラティブ・トラッキング
大規模言語モデル(LLMs)は、コンテンツ生成、顧客サービスのチャットボットなど、様々なタスクの実行方法を一変させた。LLMsの使用が増加するにつれて、信頼できる応答を提供するために、モデルが現在のニュースに関する知識において不偏であることを保証する必要があります。多言語ナラティブ・トラッキングはこれを達成するのに役立ちます。
物語とは、相互に結びついた出来事の連続であり、私たちを取り巻く世界を理解するための強力なツールです。例えば、バービーの新しい映画の予告編が公開され、その数日後にバス&ボディワークスがバービーエディションのキャンドルを発売したとき、この2つの出来事は物語を形成した。ニュース追跡の文脈では、私たちは本質的にこれらの物語を追跡している。バービームービーキャンペーンの物語は、さまざまな地域や言語にわたって多様な報道と感情を伴っており、その典型的な例である。このように、異なる言語(国)でどのようにナラティブが報道されたかを、その量とセンチメントの観点から分析するプロセスを、私たちは多言語ナラティブ追跡と呼んでいます。
Emergent Methodsの創設者であるロバート・コークは、最近、ベルリンで開催された Zilliz による Unstructured Data Meetup で、ニュースの多言語ナラティブ・トラッキングに関する講演を行った。Emergent Methods社は、リアルタイム適応モデリングの課題にAIを適用するためのオープンソースソフトウェアを開発している。
講演の中でロバートは、ニュース記事の様々な物語を追跡する必要性を強調している。彼は、多様な国、言語、情報源にまたがるグローバル・ニュースを追跡するために、LLMと組み合わせた埋め込みモデルのアーキテクチャを提示する。
なぜニュースの文脈をエンジニアリングする必要があるのか?
Robertは、Emergent Methodsチームがニュースのコンテキストをエンジニアリングし、ナラティブを追跡するための様々なアプローチを検討していた主な理由について説明:
ジャーナリズム基準の強化:** LLMが厳格なジャーナリズム基準を遵守することが最も重要である。検証されていない主張の流布を防ぐことは、誤報や不信につながる可能性があるため極めて重要である。
ソースと言語の多様性:** LLMは、フレンドリーなチャットボットから金融アナリストアシスタントまで、あらゆる製品のLLMベースのサービスを開発する際に、現在のニュースや進行中のイベントを知っている必要があります。LLMは、言語や国、その他の属性を超えて多様なニュースに触れなければならない。ソースが偏っていては、顧客層を民主的に代表できないからだ。例えば、ロシアとアメリカのニュース記事は、ウクライナ戦争などの問題について異なる視点を持っている。私たちは、さまざまな言語にわたって、特定のニュース記事のさまざまな視点をカバーする必要がある。
時代遅れのニュースは避けなければならない。古いニュースを報道することは、ユーザーの不満やLLMベースのサービスに対する信頼の喪失につながり、悪影響を及ぼす可能性がある。
Minimize Hallucinations:もう一つの課題は、大規模言語モデル(LLM)の[幻覚]である。幻覚は、LLMが学習データの過去のパターンに基づいて、不正確なデータ、あるいは捏造された情報で応答を生成する場合に発生する。LLMを市場に投入する場合、幻覚のコストは大きい。
規模に応じたニュース・コンテンツの民主化:**規模に応じたニュース・コンテンツの管理という課題は広く存在している。規模の大小にかかわらず、多くの企業が100万件以上のニュース記事を追跡し、論理的誤謬がないことを確認し、情報源を多様化するロジスティクスに苦慮している。この課題に対処する戦略的なツールは、多くの市場に幅広く応用できるだろう。
パラメーター空間のエンジニアリング:LLMとエンベッディングの構築で記事を充実させる
Robertはパラメータ空間をエンジニアリングする目的を次のように定義している:「私たちの目的は、多様な視点にわたるニューストピックをクラスタリングするために、きれいなパラメータ空間を作成することです。このアイデアは、特に小さな属性に由来するエンティティを抽出することである。ロバートはまた、語りを比較するために言語の違いを正規化する必要性を強調している。
きれいでよく定義されたパラメータ空間](https://assets.zilliz.com/A_clean_and_well_defined_parameter_space_f556af685c.png)
彼らは、ニュース記事をリッチ化するアプローチを考案した。そのアイデアは、大規模な言語モデルを複数のステップで使用することである。
1.記事のタイトルと内容をLLMに入力する。
2.LLMは記事の内容を翻訳し要約する。従来のベースライン要約者とは異なり、要約には主張を裏付ける証拠が含まれるべきである。これにより、幻覚や誤った情報を避けることができる。
3.要約された情報からエンティティーとキーワードのカスタム抽出を行う。これはGLiNER-newsの大規模言語モデルが輝くところである。このタスクのために微調整されたGLiNER-newsは、テキストから商品名、イベント、日付、組織などのエンティティを素早く識別し、抽出することができる。GLiNER-newsは間もなくHuggingFaceプラットフォームで利用可能になり、その効率性と有効性を一般の人々に体験してもらう予定である。
4.埋め込みページの構築エンリッチされた記事は、テキスト埋め込みモデルを用いて ベクトル埋め込みに変換され、Milvusのようなベクトルデータベースに格納される。将来的には、ベクトルデータベースから情報を照会することができる。テキスト埋め込みモデルとベクトルデータベースの選択は非常に重要である。
テキスト埋め込みモデルは、検索速度を左右します。また、埋め込みの品質にも影響します。埋め込みの作成と保存にかかるコストも、手頃なものである必要があります。HuggingFaceには、テキスト埋め込みモデルのための多くのオプションがあります。我々が選択するベクトルデータベースは、堅牢で、並列化機能をサポートする必要があります。また、メタデータのフィルタリングや量子化などの機能も必要です。Zillizは堅牢なオープンソースのベクトルデータベースMilvusを提供しています。
Milvus](https://assets.zilliz.com/222_f78a6759d7.png)
パラメータ空間で物語を追跡する
ニュースナラティブは、複数の視点を持ち、偶発的なエラーと意図的なエラーの両方を含むことが多い、一連のニュース報道である。エンリッチされた埋め込みは、我々のクリーンなパラメータ空間を特徴付ける。
最初に、埋め込まれたパラメータの意味的類似性に基づいてクラスタリングが行われる。複数の言語とソースからのソースが不可欠である。Robertは次のように言及している。
「データに競合する視点を持つことは、特定のニュースシナリオの報道を比較する上で非常に重要である。
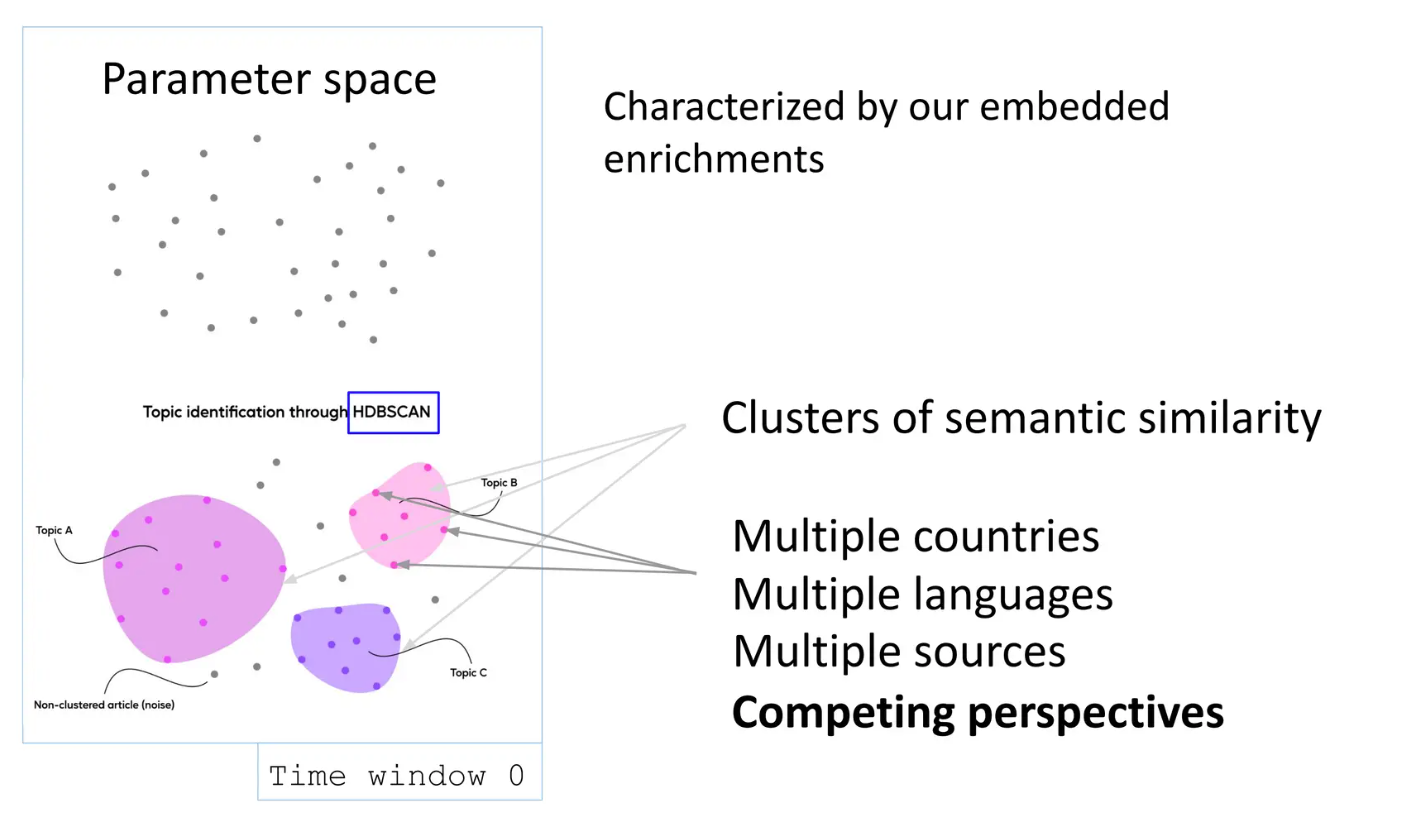
次の疑問は、同じ物語に関する異なる報道をどのように時系列で結びつけるか、ということである。
私たちは、時系列に従って、異なる時間窓でクラスタリングを行う。様々な方法によって、異なる時点のクラスタを接続することができる。ロバートもいくつかのクラスタ接続方法を推奨している:
ニュース記事が特定の物語に属するかどうかを予測するために、クラスタごとにバイナリ分類器を訓練することができます。
重心クラスターがどのように変化するかを測定することができる。これは、新しいクラスタに入るのか、古いクラスタに再び入るのか(同じニュースの物語を示す)についての情報を提供することができる。
Fuzzy C-meansやGaussian Mixture Modelsによるソフトクラスタリングなど、重複クラスタリング技術を使用することもできます。

この方法によって、特定のニッチを長い期間にわたって追跡することができる。例えば、下の画像はマドンナのコンサートに関する記事を6日間にわたって報道したものである。5月1日にはコンサートの告知があり、5月6日にはコンサートによって打ち立てられた画期的な記録に関する記事があります。クラスターを作成&接続することで、2つの記事を順番にリンクさせることができる。これにより、報道とセンチメントを時系列で追跡し、洞察を得ることができる。スペインのソースがどのように報道しているか、米国がどのように報道しているかなどを確認できる。

各クラスタは、地域/国において多様であるべきである。プロンプト・エンジニアリングによって、各観点がクラスター内で表現されていることを確認する。そして、異なる報道ソース間の整合性や矛盾を特定することができる。例えば、米国が報道するニュースとロシアが報道するニュースがどのように異なる感情を持つか。
実証例
ロバートは「アレクシ・ナヴァルニーの死」の物語を追跡する例を示す。
ナヴァルニーの死を各国がどれだけ報道したかを測定する。ロバートはロシア、フランス、アメリカのニュース報道を選び、その違いを比較する。フランスの報道の0.5%がナヴァルニーに割かれているのに対し、ロシアは0.14%しかないことが観察された。
https://assets.zilliz.com/666_f8ece438a0.png
これは、ロシアがこのトピックに関する報道に検閲を課している可能性を示している。また、ロシアがどのようなニューストピックを報道したかを、フランスやアメリカのメディアが報道したニュースと比較してみることもできる。下の画像はその一例である。ロシアでは否定的な報道が非常に少ないことがわかる。
https://assets.zilliz.com/777_3823efab65.png
ロバートはまた、ロシアとウクライナの紛争について、異なる国・言語による報道を比較した箱ひげ図も示している。この場合、米国メディアの報道は異常に低いようだ。
https://assets.zilliz.com/888_1e1c7115a6.png
これらの洞察は、ニュース記事が偏っていたり、選択的に報道されていたりするケースを理解するのにとても役立つ。これによって、選択的報道の透明性が高まり、ニュースで新しいモデルを訓練する際に偏りを取り除くことができる。
結論
AIを活用した多言語ナラティブ追跡は、透明性を高め、グローバルな視点とより包括的なイベント報道を保証することができる。これは、異なる限界や文化的背景からの声を含めるための道を開くものであり、不可欠なものです。また、さまざまな情報源で情報を相互検証し、矛盾が生じる可能性を最小限に抑えることができる。より高度なアプローチを開発するためには、プロンプトエンジニアリングとLLMアーキテクチャの継続的な研究と開発が必要である。
読み続けて

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.