




正しいベクトル埋め込みを取得する方法
この記事はThe New Stackに掲載されたもので、許可を得てここに再掲載している。
**ベクトル埋め込みと、人気のあるオープンソースモデルを使ってそれを生成する方法の包括的な紹介です。
画像: Денис Марчук from Pixabay](https://assets.zilliz.com/how_to_get_right_vector_embeddings_e0838623b7.png)
意味的類似性](https://zilliz.com/learn/vector-similarity-search)を扱う場合、ベクトル埋め込みは非常に重要です。しかし、ベクトルは単なる数字の羅列であり、ベクトル埋め込みは入力データを表す数字の羅列です。ベクトル埋め込みを使うことで、非構造化データを構造化したり、あらゆるタイプのデータを数値列に変換して扱うことができます。このアプローチは、定性的な比較に頼るのではなく、入力データに対して数学的な演算を行うことを可能にします。
ベクトル埋め込みは多くのタスク、特に意味検索に影響力を持つ。しかし、ベクトル埋め込みを使う前に、適切なベクトル埋め込みを取得することが非常に重要です。例えば、画像モデルを使ってテキストをベクトル化したり、その逆をやったりすると、おそらく悪い結果が得られるだろう。
この投稿では、ベクトル埋め込みとは何か、様々なモデルを用いてアプリケーションに適したベクトル埋め込みを生成する方法、そしてMilvusやZilliz Cloudのようなベクトルデータベースを用いてベクトル埋め込みを最大限に活用する方法を学びます。
ベクトル埋め込みはどのように作成されるのか?
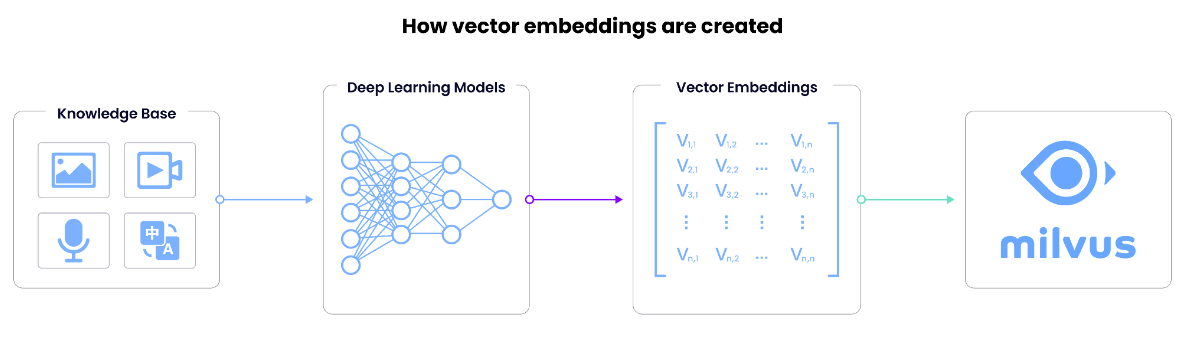
ベクトル埋込みの重要性を理解したところで、その仕組みを学びましょう。ベクトル埋め込みとは、ディープラーニングモデル(埋め込みモデルやディープニューラルネットワークとも呼ばれる)における入力データの内部表現です。では、どのようにしてこの情報を抽出するのでしょうか?
最後の層を取り除き、最後から2番目の層の出力を取り出すことでベクトルを得る。ニューラルネットワークの最後の層は通常、モデルの予測を出力するので、最後から2番目の層の出力を取る。ベクトル埋め込みは、ニューラルネットワークの予測層に供給されるデータです。
ベクトル埋込みの次元数は、モデルの最後から2番目の層のサイズと等しく、したがってベクトルのサイズまたは長さと交換可能です。一般的なベクトルの次元数には、384(Sentence Transformers Mini-LMで生成)、768(Sentence Transformers MPNetで生成)、1,536(OpenAIで生成)、2,048(ResNet-50で生成)などがあります。
ベクトル埋め込みとは?
ある人から、ベクトル埋め込みにおける各次元の意味について質問されたことがある。短い答えは「何もない」です。ベクトル埋め込みにおける1つの次元は、抽象的すぎて意味を決定することができないので、何の意味も持ちません。しかし、すべての次元を合わせると、入力データの意味論的な意味になります。
ベクトルの次元は、さまざまな属性を抽象的に表現したものです。表現される属性は、学習データとモデル自体に依存する。テキストモデルと画像モデルは、基本的に異なるデータ型に対して学習されるため、異なる埋め込みを生成します。異なるテキストモデルでさえ、異なる埋め込みを生成します。サイズが異なることもあれば、表現する属性が異なることもあります。例えば、法律データで訓練されたモデルは、医療データで訓練されたモデルとは異なることを学習します。このトピックについては、私の投稿ベクトルの埋め込みを比較するで探りました。
正しいベクトル埋め込みを生成する
どのようにして適切なベクトル埋め込みを得るのでしょうか?それは、埋め込みたいデータの種類を特定することから始まります。このセクションでは、画像、テキスト、オーディオ、ビデオ、マルチモーダルデータの5種類のデータの埋め込みについて説明します。ここで紹介するモデルはすべてオープンソースで、Hugging FaceやPyTorchから提供されています。
画像埋め込み
画像認識は、AlexNetがシーンに登場した後、2012年に一躍脚光を浴びました。それ以来、コンピュータビジョンの分野は多くの進歩を目撃してきました。最新の注目すべき画像認識モデルは、以前のResNet-34アーキテクチャに基づく50層のディープ・レジデュアル・ネットワークであるResNet-50です。
残差ニューラルネットワーク(ResNet)は、ショートカット接続を使用して、深層畳み込みニューラルネットワークにおける消失勾配問題を解決する。このショートカット接続により、前の層からの出力がすべての中間層を経由せずに直接後の層に送られるようになり、消失勾配問題が回避される。この設計により、ResNetは、以前最高の性能を誇った畳み込みニューラルネットワークであるVGGNet(Visual Geometry Group)よりも複雑でなくなった。
例として2つのResNet-50の実装を推薦する: ResNet 50 on Hugging FaceとResNet 50 on PyTorch Hubです。ネットワークは同じですが、埋め込みを得るプロセスは異なります。
以下のコードサンプルは、PyTorchを使ってベクトル埋め込みを取得する方法を示しています。まず、PyTorch Hubからモデルを読み込みます。次に、最後のレイヤーを削除し、.eval()を呼び出して、推論を実行するようにモデルに指示します。次に embed 関数でベクトルの埋め込みを生成します。
# 最後のレイヤーを削除した埋め込みモデルをロードする。
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True) model = torch.nn.Sequential(*(list(model.children())[:-1]))
model.eval()
def embed(data):
with torch.no_grad():
出力 = model(torch.stack(data[0])).squeeze()
出力を返す
HuggingFace は少し異なるセットアップを使用します。以下のコードは、Hugging Faceからベクトル埋め込みを得る方法を示している。まず、 transformers ライブラリから特徴抽出器とモデルが必要です。モデルの入力を得るために特徴抽出器を使い、出力を得て最後の隠れた状態を抽出するためにモデルを使う。
# モデルを直接読み込む
from transformers import AutoFeatureExtractor, AutoModelForImageClassification.
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")
from PIL import Image
image = Image.open("<画像パス>")
# image = Resize(size=(256, 256))(image)
inputs = extractor(images=image, return_tensors="pt")
# print(inputs)
outputs = model(**inputs)
vector_embeddings = outputs[1][-1].squeeze()
テキスト埋め込み
AIが発明されて以来、エンジニアや研究者は自然言語とAIの実験を行ってきた。初期の実験には以下のようなものがある:
- ELIZA、最初のAIセラピスト・チャットボット。
- ジョン・サールの「中国語の部屋」。中国語と英語を翻訳する能力に、その言語の理解が必要かどうかを検証する思考実験。
- 英語とロシア語の間のルールベースの翻訳。
自然言語に対するAIの操作は、ルールベースの埋め込みから大きく進化した。一次ニューラルネットワークから始まり、RNNによって再帰関係を追加し、時間のステップを追跡するようにした。そこから、変換器を使用してシーケンス変換問題を解決した。
トランスフォーマーは、入力を状態を表す行列にエンコードするエンコーダー、アテンション行列、デコーダーで構成される。デコーダは状態とアテンション行列をデコードし、出力シーケンスを終了する正しい次のトークンを予測する。GPT-3は現在最もよく使われている言語モデルであり、厳密なデコーダで構成されている。デコーダは入力をエンコードし、正しい次のトークンを予測する。
Hugging Faceの sentence-transformers ライブラリから、OpenAIのエンベッディングに加えて使える2つのモデルを紹介します:
- MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2): 384次元モデル
- MPNet-Base-V2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2): 768次元モデル
どちらのモデルの埋め込みも、同じようにアクセスすることができます。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("<model-name>")
vector_embeddings = model.encode("<input>")
マルチモーダル埋め込み
マルチモーダルモデルは、画像モデルやテキストモデルよりもあまり発達していない。画像とテキストを関連付けることが多い。
最も有用なオープンソースの例はCLIP VITで、画像からテキストへのモデルです。以下のコードに示すように、画像モデルと同じ方法でCLIP VITの埋め込みにアクセスすることができます。
# モデルを直接読み込む
from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
processor = AutoProcessor.from_pretrained("openai/clip-vit-large-patch14")
model = AutoModelForZeroShotImageClassification.from_pretrained("openai/clip-vit-large-patch14")
from PIL import Image
image = Image.open("<画像パス>")
# image = Resize(size=(256, 256))(image)
inputs = extractor(images=image, return_tensors="pt")
# print(inputs)
outputs = model(**inputs)
vector_embeddings = outputs[1][-1].squeeze()
音声埋め込み
音声のAIは、テキストや画像のAIに比べてあまり注目されていない。音声の最も一般的なユースケースは、コールセンター、医療技術、アクセシビリティなどの業界向けの音声からテキストへの変換です。一般的なオープンソースのSpeech-to-textモデルは、Whisper from OpenAIです。以下のコードは、Speech-to-textモデルからベクトル埋め込みを取得する方法を示しています。
インポートトーチ
from transformers import AutoFeatureExtractor, WhisperModel
from datasets import load_dataset
model = WhisperModel.from_pretrained("openai/whisper-base")
feature_extractor = AutoFeatureExtractor.from_pretrained("openai/whisper-base")
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
input = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
input_features = inputs.input_features
decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
vector_embedding = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
動画の埋め込み
動画の埋め込みは、音声や画像の埋め込みよりも複雑です。動画を扱う場合、同期された音声や画像が含まれるため、マルチモーダルなアプローチが必要です。人気のあるビデオモデルの1つは、DeepMindのmultimodal perceiverです。このノートブックチュートリアルでは、このモデルを使って動画を分類する方法を示しています。
入力の埋め込みを取得するには、出力を削除する代わりに、ノートブックに示されているコードの outputs[1][-1].squeeze() を使用します。このコードスニペットは autoencode 関数の中でハイライトしています。
def autoencode_video(images, audio):
# 入力としてビデオ全体を一度だけ作成する
inputs = {'image': torch.from_numpy(np.moveaxis(images, -1, 2)).float().to(device)、
'audio': torch.from_numpy(audio).to(device)、
label': torch.zeros((images.shape[0], 700).to(device)}.
nchunks = 128
再構成 = {}
for chunk_idx in tqdm(range(nchunks)):
image_chunk_size = np.prod(images.shape[1:-1]) // nchunks
audio_chunk_size = audio.shape[1] // SAMPLES_PER_PATCH // nchunks
サブサンプリング = {
image': torch.arange(
image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1))、
'audio': torch.arange(
audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1))、
label':なし、
}
# フォワードパス
torch.no_grad()を使う:
出力 = model(inputs=inputs, subsampled_output_points=subsampling)
output = {k:v.cpu() for k,v in outputs.logits.items()}。
reconstruction['label'] = output['label'].
もし'image'がreconstructionになければ
reconstruction['image'] = output['image'].
reconstruction['audio'] = output['audio'].
else:
reconstruction['image'] = torch.cat(
[reconstruction['image'], output['image']], dim=1)
reconstruction['audio'] = torch.cat(
[reconstruction['audio'], output['audio']], dim=1)
vector_embeddings = outputs[1][-1].squeeze()
# 最後に,画像と音声のモダリティを元の形状に戻します
reconstruction['image'] = torch.reshape(reconstruction['image'], images.shape)
reconstruction['audio'] = torch.reshape(reconstruction['audio'], audio.shape)
再構成を返す
なし
ベクトル埋め込みをベクトルデータベースで保存、索引付け、検索する
ベクトル埋め込みがどのようなものか、そして様々な強力な埋め込みモデルを使ってどのように埋め込みを生成するかを理解したところで、次の問題はどのように埋め込みを保存し、活用するかということです。ベクトルデータベースがその答えです。
Milvus](https://zilliz.com/what-is-milvus)やZilliz Cloudのようなベクトルデータベースは、ベクトル埋め込みを通して、非構造化データの巨大なデータセットを横断的に保存、索引付け、検索するために意図的に構築されています。また、様々なAIスタックにとって最も重要なインフラの一つでもある。
ベクトル・データベースは通常、近似最近傍(ANN)アルゴリズムを使用して、クエリ・ベクトルとデータベースに格納されているベクトル間の空間距離を計算する。2つのベクトルの位置が近ければ近いほど、関連性が高いことになる。そして、アルゴリズムは上位k個の最近傍を見つけ、ユーザーに配信する。
ベクトルデータベースは、LLM検索拡張生成(RAG)、質問応答システム、推薦システム、意味検索、画像、ビデオ、音声の類似検索などのユースケースで人気がある。
ベクトル埋め込み、非構造化データ、ベクトルデータベースについてより詳しく学ぶには、ベクトルデータベース101シリーズから始めることを検討してください。
まとめ
ベクトルは非構造化データを扱うための強力なツールです。ベクトルを使うことで、構造化されていないデータの異なる部分を意味的な類似性に基づいて数学的に比較することができます。適切なベクトル埋め込みモデルを選択することは、あらゆるアプリケーションのベクトル検索エンジンを構築する上で非常に重要である。
この投稿で、ベクトル埋め込みはニューラルネットワークにおける入力データの内部表現であることを学んだ。その結果、ベクトル埋め込みはネットワークのアーキテクチャとモデルの学習に使われるデータに大きく依存します。異なるデータタイプ(画像、テキスト、音声など)は特定のモデルを必要とします。幸いなことに、多くの事前学習済みオープンソースモデルが利用可能です。この投稿では、最も一般的な5種類のデータ(画像、テキスト、マルチモーダル、オーディオ、ビデオ)のモデルを取り上げました。また、ベクトル埋め込みを最大限に活用したいのであれば、ベクトルデータベースが最もポピュラーなツールです。

読み続けて

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.