




Comparing Different Vector Embeddings
This article was originally published in The New Stack and is reposted here with permission.
How do vector embeddings generated by different neural networks differ, and how can you evaluate them in your Jupyter Notebook?
Large language models (LLMs) are trending and we’re facing a new paradigm of language applications like ChatGPT. Vector databases will be a core part of the stack. So, it’s important to understand vectors and why they are so important.
This project demonstrates the difference in vector embeddings between models and shows how to use multiple collections of vector data in one Jupyter Notebook. In this post, we’ll cover what vector embeddings are, why they are important, and how we compare different vector embeddings in your Jupyter Notebook.
What are vector embeddings and why are they important?
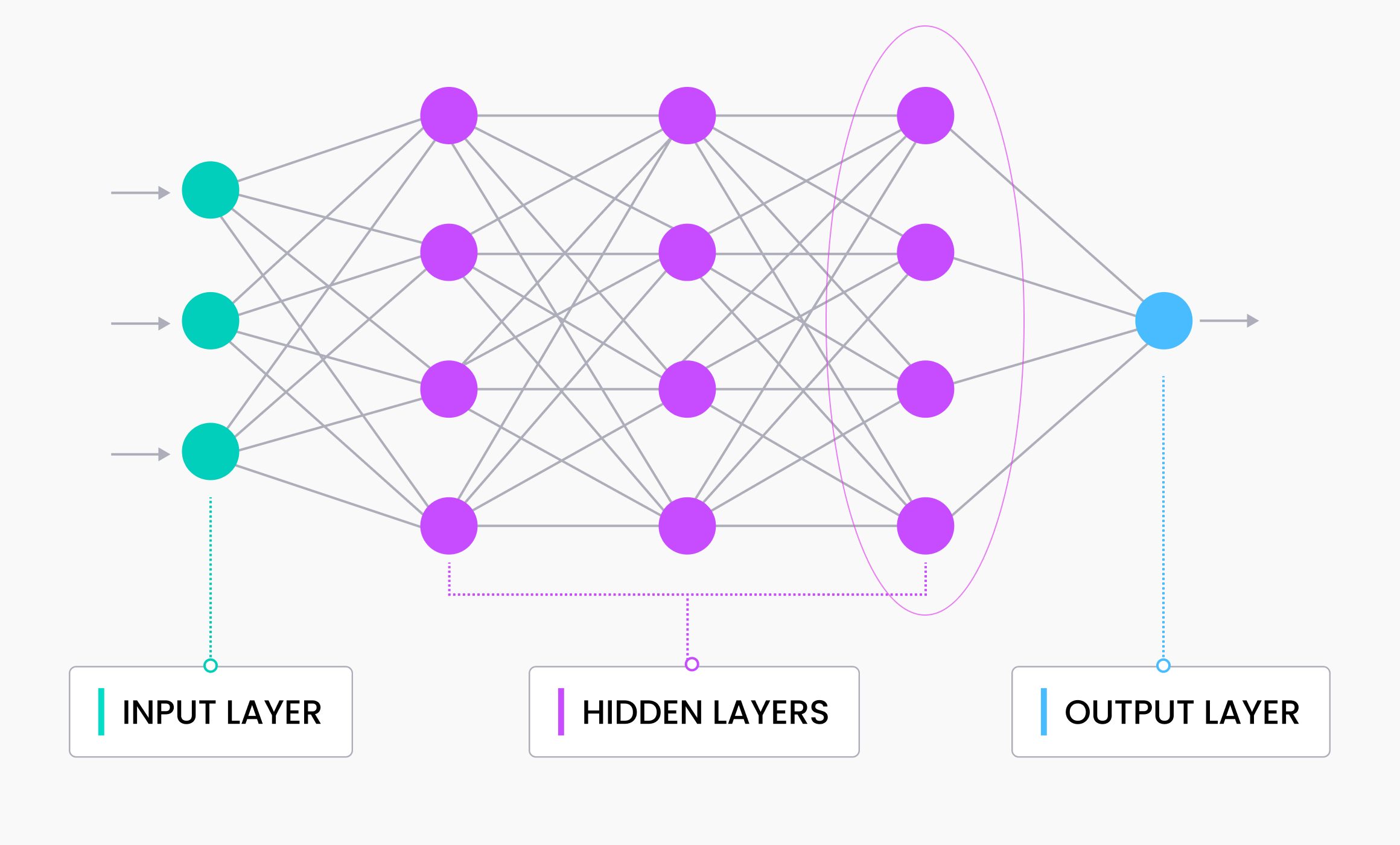 Where do vector embeddings come from?
Where do vector embeddings come from?
In the simplest terms, vector embeddings are numerical representations of data. They are primarily used to represent unstructured data. Unstructured data are images, videos, audio, text, molecular images, and other kinds of data that don’t have a formal structure. Vector embeddings are generated by running input data through a pre-trained neural network and taking the output of the second-to-last layer.
Neural networks have different architectures and are trained on different data sets, making each model’s vector embedding unique. That’s why working with unstructured data and vector embeddings is challenging. We’ll see how models with the same base fine-tuned on different data sets can yield different vector embeddings later.
The differences in neural networks also mean that we must use distinct models to process diverse forms of unstructured data and generate their embeddings. For example, you can’t use a sentence transformer model to generate embeddings for an image. On the other hand, you wouldn’t want to use ResNet50, an image model, to generate embeddings for sentences. Therefore, it is important to find models that are appropriate for your data type.
How do we compare vector embeddings?
Next, let’s look at how to compare them. This section compares three different multilingual models based on MiniLM from Hugging Face. There are many ways to compare vectors. In this example, we use the L2 distance metric and an inverted file index as the vector index.
For this project I’ve developed some of my data, inspired by Taylor Swift’s recent album release, defined right in the Jupyter Notebook. You can use my examples or come up with your own sentences. Once we have the data, we get the different embeddings and store two sets of the embeddings in a vector database like Milvus. We query them to make the comparisons using the third model’s embeddings.
We’re looking to see if the search results are different and how far off the search results are from each other. In a production setting, you’d want to know the results you want to see, then check that against the returned results.
Comparing vector embeddings from different models
The three models we compare are the base multilingual paraphrase model using MiniLM from Sentence Transformers, a version that was fine-tuned for intent detection, and one that Sprylab fine-tuned without details on what it was tuned for. Finding three compatible models I could run on my laptop was one of the hardest parts of this project.
We need vectors of the same length/dimension to compare vector embeddings. In this example, we are using 384-dimensional vectors as per the MiniLM Sentence Transformer model. Note that this doesn’t mean we are creating 384 “features” or “categories” for each piece of data, but rather generating an abstract representation of the data in a 384-dimensional space. For example, none of the dimensions will represent anything like a part of speech, the number of words in the sentence, whether something is a proper noun or anything conceptual like that.
Vector embedding comparison data
We are using sentence transformer models, which means our data should be in the form of sentences. I recommend having at least 50 sentences to compare. The example notebook contains 51. I also recommend using data that has some similarity to it. In this example, I used lyrics from four of Taylor Swift’s songs: “Speak Now,” “Starlight,” “Sparks Fly,” and “Haunted.”
I picked these songs because many of the lyrics form complete sentences, so it’s easy to turn from lyric format into sentence format. I also wanted to test a hypothesis. The first three songs are more or less love songs, while the last one, “Haunted,” is more like a break-up song. So I hypothesize that it’s less likely for “Haunted” to show up in the return results for the first three songs than each other.
Comparing vector embeddings in your Jupyter Notebook
Let’s get into the code. With Milvus Lite, a lightweight version of Milvus, you can compare your vector embeddings directly in a Jupyter Notebook. For this example code, you’ll need to ! pip install pymilvus milvus sentence-transformers. You only need a few imports for this project; the time library is optional. After running the imports, start the default_server from Milvus and set up a connection.
from sentence_transformers import SentenceTransformer
from milvus import default_server
from pymilvus import connections, utility, FieldSchema, CollectionSchema, DataType, Collection
from time import time
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
Get the sentence transformer models from Hugging Face
Step 1 is to get our vector embedding models. We use the paraphrase multilingual MiniLM series for this example. The first one is the canonical version. The next two are the differently fine-tuned versions. This model choice gives us a clear example of how fine-tuning can noticeably change your vectors.
v12 = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2")
ft3_v12 = SentenceTransformer("Sprylab/paraphrase-multilingual-MiniLM-L12-v2-fine-tuned-3")
ft5_v12 = SentenceTransformer("hroth/psais-paraphrase-multilingual-MiniLM-L12-v2-5shot")
Load the data sets into two collections in a vector database
I’ve listed 51 sentences from Taylor Swift’s “Speak Now” album below. Feel free to copy and paste this code snippet. Or read it if you’d like; she’s a great lyricist.
# inspired by Speak Now (Taylor's Version)
# Lyrics from: Speak Now, Starlight, Sparks Fly, Haunted
sentences = [
"I am not the kind of girl, who should be rudely barging in on a white veil occasion, but you are not the kind of boy who should be marrying the wrong girl",
"I sneak in and see your friends and her snotty little family all dressed in pastel and she is yelling at a bridesmaid somewhere back inside a room wearing a gown shaped like a pastry",
"This is surely not what you thought it would be.",
"I lose myself in a daydream where I stand and say, 'Don't say yes, run away now I'll meet you when you're out of the church at the back door.'",
"Don't wait, or say a single vow you need to hear me out and they said, 'Speak now'.",
"Fond gestures are exchanged.",
"And the organ starts to play a song that sounds like a death march.",
"And I am hiding in the curtains, it seems that I was uninvited by your lovely bride-to-be.",
"She floats down the aisle like a pageant queen.",
"But I know you wish it was me you wish it was me don't you?",
"I hear the preacher say, 'Speak now or forever hold your peace'",
"There's the silence, there's my last chance.",
"I stand up with shaky hands, all eyes on me",
"Horrified looks from everyone in the room but I'm only looking at you.",
"And you'll say, 'Let's run away now' I'll meet you when I'm out of my tux at the back door",
"Baby, I didn't say my vows So glad you were around When they said, 'Speak now'",
"I said, 'Oh my, what a marvelous tune'",
"It was the best night, never would forget how we moved.",
"The whole place was dressed to the nines and we were dancing, dancing like we're made of starlight",
"I met Bobby on the boardwalk summer of '45",
"Picked me up late one night out the window we were seventeen and crazy running wild, wild.",
"Can't remember what song he was playing when we walked in.",
"The night we snuck into a yacht club party pretending to be a duchess and a prince.",
"He said, 'Look at you, worrying so much about things you can't change You'll spend your whole life singing the blues If you keep thinking that way'",
"He was tryna to skip rocks on the ocean saying to me 'Don't you see the starlight, starlight don't you dream impossible things'",
"Ooh, ooh he's talking crazy Ooh, ooh dancing with me Ooh, ooh we could get married Have ten kids and teach 'em how to dream",
"The way you move is like a full on rainstorm.",
"And I'm a house of cards",
"You're the kind of reckless that should send me running but I kinda know that I won't get far",
"And you stood there in front of me just close enough to touch",
"Close enough to hope you couldn't see what I was thinking of",
"Drop everything now",
"Meet me in the pouring rain",
"Kiss me on the sidewalk",
"Take away the pain",
"'Cause I see sparks fly, whenever you smile",
"Get me with those green eyes, baby as the lights go down",
"Gimme something that'll haunt me when you're not around",
"My mind forgets to remind me you're a bad idea",
"You touch me once and it's really something you find I'm even better than you imagined I would be",
"I'm on my guard for the rest of the world but with you, I know it's no good"
"And I could wait patiently but I really wish you would"
"I run my fingers through your hair and watch the lights go wild",
"Just keep on keeping your eyes on me it's just wrong enough to make it feel right",
"And lead me up the staircase won't you whisper soft and slow, I'm captivated by you, baby like a fireworks show",
"You and I walk a fragile line I have known it all this time, But I never thought I'd live to see it break",
"It's getting dark and it's all too quiet And I can't trust anything now And it's coming over you like it's all a big mistake",
"Oh, I'm holding my breath Won't lose you again",
"Something's made your eyes go cold",
"Come on, come on, don't leave me like this I thought I had you figured out",
"Something's gone terribly wrong you're all I wanted",
"Can't breathe whenever you're gone can't turn back now, I'm haunted",
"I just know You're not gone, you can't be gone, no",
]
We must first define the schemas to put data into a vector database. We have the same schema for both collections for this example, so we only need to make one. Make sure to create two collections, though.
Once the collections are ready, we encode all the sentences into embeddings for their models and define the vector index parameters. We use L2 as our distance metric and an inverted file index with four centroids. There are only 51 entries, after all. Then we get to format the data and load it into Milvus.
# object should be inserted in the format of (title, date, location, speech embedding)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="sentence", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=DIMENSION),
]
schema = CollectionSchema(fields=fields)
collection_v12 = Collection(name=COLLECTION_V12, schema=schema)
collection_v12_ft5 = Collection(name=COLLECTION_V12_Q, schema=schema)
v12_embeds = {}
v12_q_embeds = {}
for sentence in sentences:
v12_embeds[sentence] = v12.encode(sentence)
v12_q_embeds[sentence] = ft5_v12.encode(sentence)
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 4},
}
collection_v12.create_index(field_name="embedding", index_params=index_params)
collection_v12.load()
collection_v12_ft5.create_index(field_name="embedding", index_params=index_params)
collection_v12_ft5.load()
for sentence in sentences:
v12_insert = [
{
"sentence": sentence,
"embedding": v12_embeds[sentence]
}
]
ft_insert = [
{
"sentence": sentence,
"embedding": v12_q_embeds[sentence]
}
]
collection_v12.insert(v12_insert)
collection_v12_ft5.insert(ft_insert)
collection_v12.flush()
collection_v12_ft5.flush()
Query the vector stores to compare the embeddings
Next, it’s time to compare. In this example, we will use the first two sentences. We use the third model to generate the vector embeddings for them.
search_embeds = {}
search_data = []
for sentence in sentences[0:2]:
vector_embedding = ft3_v12.encode(sentence)
search_embeds[sentence] = vector_embedding
search_data.append(vector_embedding)
Now we query Milvus. I’m also tracking time on this. The times for the searches that I got are shown below. Make sure to pass in the same metric type under the search parameters.

start1 = time()
res_v12 = collection_v12.search(
data=search_data, # Embeded search value
anns_field="embedding", # Search across embeddings
param={"metric_type": "L2",
"params": {"nprobe": 2}},
limit = 3, # Limit to top_k results per search
output_fields=["sentence"])
time1 = time() - start1
print(f"Time for first search: {time1}")
start2 = time()
res_v12_ft5 = collection_v12_ft5.search(
data=search_data, # Embeded search value
anns_field="embedding", # Search across embeddings
param={"metric_type": "L2",
"params": {"nprobe": 2}},
limit = 3, # Limit to top_k results per search
output_fields=["sentence"])
time2 = time() - start2
print(f"Time for second search: {time2}")
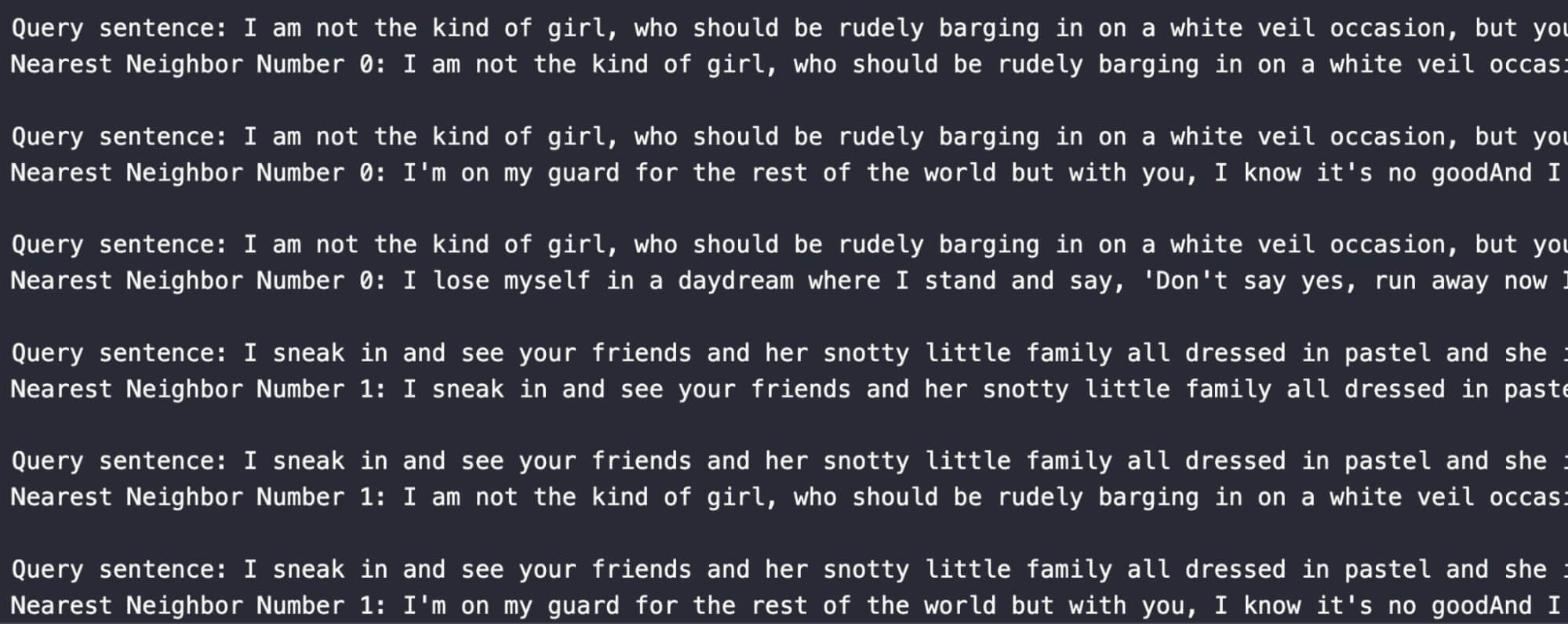
Now let’s look at the results and compare. We see surprisingly similar results for the original model vs. the fine-tuned one by Sprylab. The only difference is that the first result returned is the sentence itself. This tells us that results in two and three are more similar to the two example search sentences than they are to each other in these two vector spaces.
for i, hits in enumerate(res_v12):
for hit in hits:
print(f"Query sentence: {sentences[i]}")
print(f"Nearest Neighbor Number {i}: {hit.entity.get('sentence')} ---- {hit.distance}\n")

Next, let’s compare the two fine-tuned models. From these results, we’ll see that the sentence starting with “I’m on my guard for the rest of the world …“ is semantically similar to our search sentences because it pops up in both comparisons. Two interesting points here are: 1) different results from the first query, and 2) the second query sentence doesn’t appear in the top three for the first, but the reverse is true.
for hit in hits:
print(f"Query sentence: {sentences[i]}")
print(f"Nearest Neighbor Number {i}: {hit.entity.get('sentence')} ---- {hit.distance}\n")
Summary
In this tutorial, we learned about vector embeddings and how to compare them and made some comparisons ourselves with our custom data. As a bonus, we also show an example of how to work with two different collections at the same time. This is how you can query different latent vector spaces.
We showed the difference between a model and some fine-tuned versions of it. We also saw how one result popped up in both embedding spaces. A query result in multiple vector representations means that that query must be semantically similar in numerous ways. Try doing this with image models, different dimensionality language models or your data for the next steps.

Keep Reading

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.