




効率的な検索拡張世代(RAG)構築のための3つの主要戦略を探る
Retrieval Augmented Generation(RAG)は、AIを搭載したチャットボットで独自のデータを使用するための便利なテクニックです。このブログポストでは、RAGを最大限に活用するための3つの重要な戦略について説明します:
1.1. スマート・テキスト・チャンキング 📦:
- 最初のステップは、テキストデータを意味のある、管理可能なチャンクに分解することです。このステップにより、ベクターデータベースが最も関連性の高い情報を迅速かつ正確に検索できるようになります。
2.さまざまな埋め込みモデルを繰り返す ᔍ:
- 埋め込みモデルの反復は非常に重要です。埋め込みモデルは、データがどのようにベクトルとして表現されるかを決定します。ベクトルはAIの共通言語であり、ベクトル・データベースが適切な情報を取得する方法を強化する。
3.様々なLLMや生成モデルを試す 🧪:
- 各言語モデル(LLMAPIはコスト、待ち時間、精度が異なる。 それらをテストすることで、ワークロードに最適なものを選択することができる。
これらのストラテジーがどのように機能するのか、また、実際のRAGアプリケーションに最適な構成をどのように特定できるのか、評価しながら探っていきましょう!🚀📚
スマート・テキスト・チャンキング
テキストチャンキングとは、長い物語を一口サイズに切り分けるようなもので、質問に答えたり作業を手伝ったりするときに、コンピュータが最も重要な部分を簡単に見つけて使えるようにするものです。
以下に、いくつかのテクニックを説明しよう。これらのテクニックは、Greg Kamradtによるこのオリジナル記事で詳しく説明されています。
1.再帰的文字テキスト分割 🔄:
- 文字数に基づいてテキストを分割することで、各パーツが管理しやすく、首尾一貫したものになります。
2.小から大へのテキスト分割 📏:
- 大きなチャンクから始め、徐々に小さなチャンクに分割する。検索はスモールを使い、検索はビッグを使う。
3.意味的テキスト分割 🧠:
- 意味に基づいてテキストを分割し、各チャンクが完全なアイデアやトピックを表し、文脈が保たれるようにすること。
これらの方法は、様々な用途でテキストを効果的に整理・検索するのに役立ちます。それぞれのテクニックがどのように機能するのか、実際に試してみましょう!
再帰的な文字テキストの分割 🔄 🔄 🔄 文字列の分割
LangChainのRecursiveCharacterTextSplitterを使って、テキストを一定の大きさの塊に分割し、一定の大きさの重なりを持たせることから始めます。
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f "chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# より小さな(子)チャンクを作成するために使用するスプリッター。
child_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE、
chunk_overlap=chunk_overlap、
length_function = len, # Python組み込みのlen関数を使う
separators = ["\n", "\n", ", ".", ""], # デフォルト
)
# 生のドキュメントから直接子ドキュメントを作成する
sub_docs = child_text_splitter.split_documents(docs)
# チャンクの長さを調べる
print(f"{len(docs)}個のドキュメントを{len(sub_docs)}個の子ドキュメントに分割します。")
plot_chunk_lengths(sub_docs, '再帰的文字')

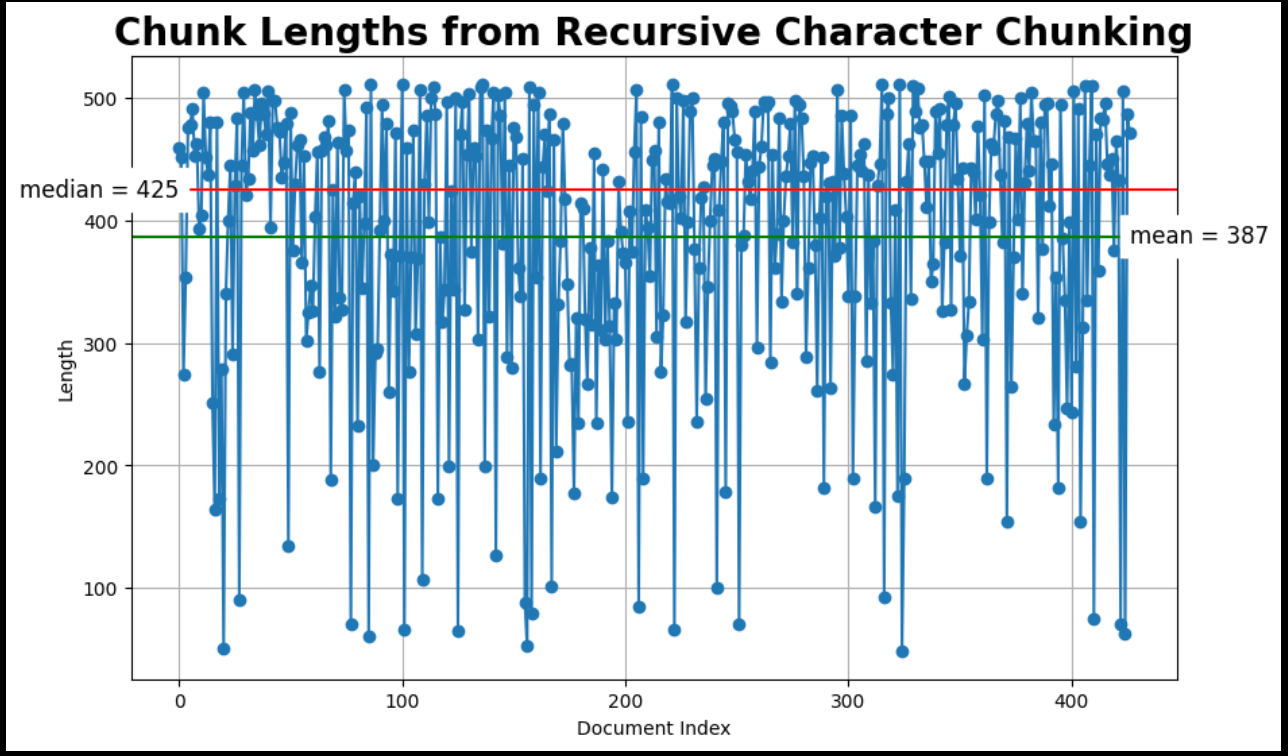
著者による画像:RecursiveCharacterTextSplitterのチャンクの長さをMatplotlibでプロットしたもの完全なコードはGitHubで入手可能。
小さなテキストから大きなテキストへの分割 📏。
このテクニックは、小さな(子)チャンクを使って検索しますが、大きな(親)テキストチャンクを使って検索します。 2つのメモリーストアが使われる:1) docストレージと2) vectorストレージ。 以下のコードはLangChainのMultiVectorRetrieverを使っています。
from langchain_milvus import Milvus
from langchain.text_splitter import RecursiveCharacterTextSplitter
import uuid
from langchain.storage import InMemoryByteStore
from langchain.retrievers.multi_vector import MultiVectorRetriever
# 親ドキュメント用のdocストレージを作成
store = InMemoryByteStore()
id_key = "doc_id"
# ベクターインデックスと検索用にベクターストアを作成する。
COLLECTION_NAME = "MilvusDocs"
ベクトルストア = Milvus(
コレクション名=COLLECTION_NAME、
embedding_function=embed_model、
connection_args={"uri":"./milvus_demo.db"}、
auto_id=True、
# 既存のコレクションが存在する場合、それを削除するためにTrueを設定します。
drop_old=True、
)
# MultiVectorRetriever(最初は空)
retriever = MultiVectorRetriever(
vectorstore=vectorstore、
byte_store=store、
id_key=id_key、
)
parent_chunk_size = 1586
# より大きな(親の)チャンクを作成するために使用するスプリッター
parent_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=PARENT_CHUNK_SIZE、
length_function = len, # Python組み込みのlen関数を使用する。
# separators=["\n"], # 段落の最後で分割する
)
# 生のドキュメントから直接ドキュメントを親にする
parent_docs = parent_text_splitter.split_documents(docs)
doc_ids = [str(uuid.uuid4()) for _ in parent_docs].
# チャンクの長さを調べる
print(f"{len(docs)} docs split into {len(parent_docs)} parent documents.")
plot_chunk_lengths(parent_docs, 'Parent')


チャンクサイズ = 512
チャンク・オーバーラップ = np.round(CHUNK_SIZE * 0.10, 0)
print(f "chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# より小さな(子)チャンクを作成するために使用するスプリッター。
child_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE、
chunk_overlap=chunk_overlap、
length_function = len, # Python組み込みのlen関数を使う
separators = ["\n", "\n", ", ".", ""], # デフォルト
)
# 親ドキュメントから直接子ドキュメントを作成する
sub_docs = child_text_splitter.split_documents(parent_docs)
# チャンクの長さを調べる
print(f"{len(docs)}個のドキュメントを{len(sub_docs)}個の子ドキュメントに分割します。")
plot_chunk_lengths(sub_docs, '小から大')

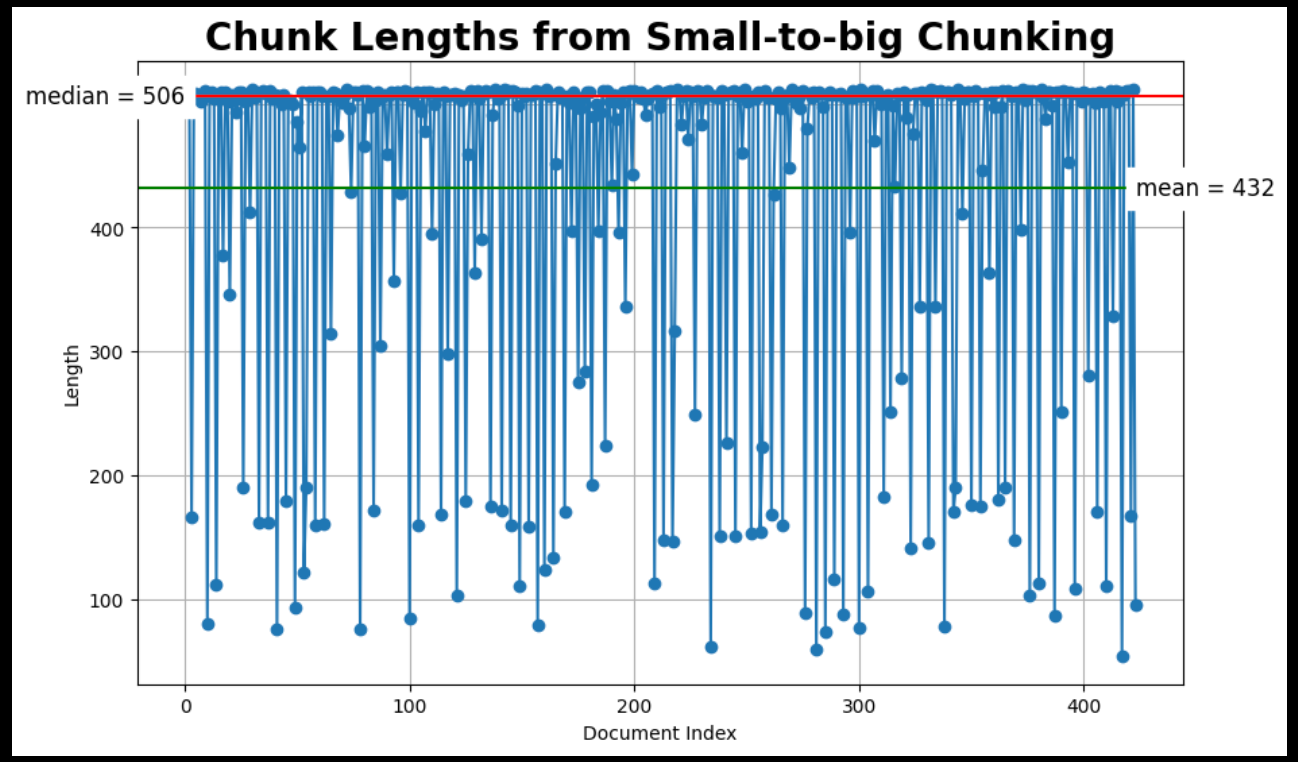 small-to-big chunking.png
small-to-big chunking.png
画像は著者によるものです: Matplotlibで小チャンクから大チャンクの長さをプロット; 全コードはgithubで入手可能。
意味的テキスト分割 🤎。
このチャンカーは文章を「分割」するタイミングを決定することで動作します。隣接するセンテンス間のコサイン距離を計算することで、このタスクを実行する。これらのコサイン距離をすべて見渡し、ある閾値を超えた異常値距離を探す。この異常値距離がチャンクを分割するタイミングを決定する。
この閾値を決定する方法はいくつかあり、breakpoint_threshold_type kwargによって制御される。
from langchain_experimental.text_splitter import SemanticChunker
semantic_docs = [].
for doc in docs:
# ドキュメントの内容を抽出してきれいにする。
clean_content = clean_text(doc.page_content)
# 埋め込みモデルでSemanticChunkerを初期化する。
text_splitter = SemanticChunker(embed_model)
semantic_list = text_splitter.create_documents([cleaned_content])
# semantic_docsにセマンティックチャンクのリストを追加する。
semantic_docs.extend(semantic_list)
# チャンクの長さを検査する
print(f "Created {len(semantic_docs)} semantic documents from {len(docs)}.")
plot_chunk_lengths(semantic_docs, 'Semantic')

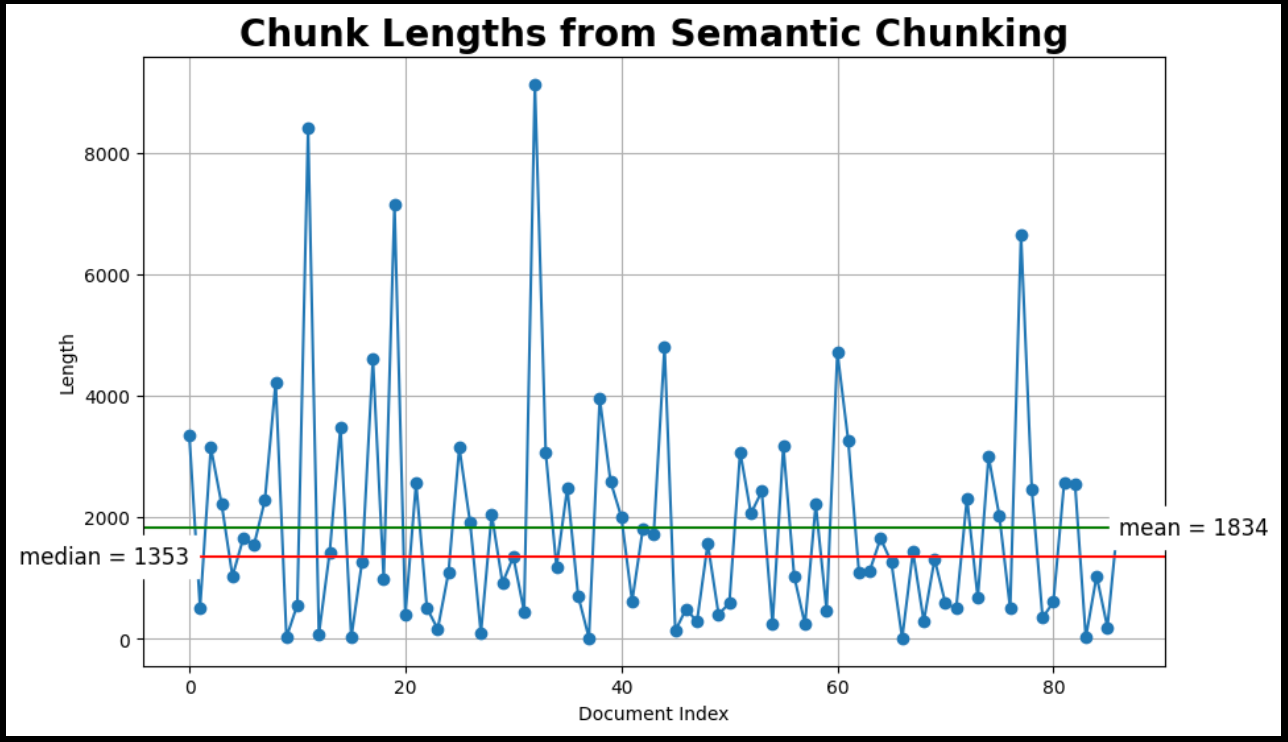
データとしてMilvus documentationを使用し、RAGの評価方法としてRagasを使用します。RAGASの使い方についてのブログ](https://medium.com/towards-data-science/rag-evaluation-using-ragas-4645a4c6c477)をお読みください。
結果は
- top_k=2のチャンキング法=Recursive Character Text Splitterが最も優れていた。
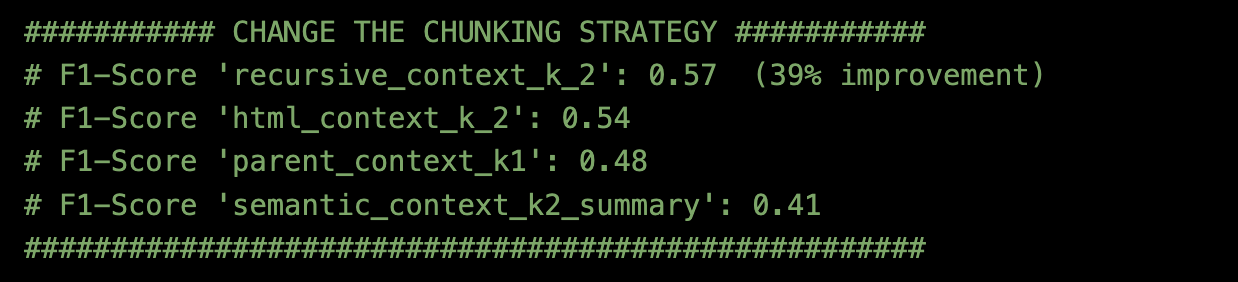
異なる埋め込みモデル
top_k=2のRecursive Character Text Splitterにチャンキング方法を固定し、2つの異なるEmbeddingモデルを試してみた。
BAAI/bge-large-en-v1.5
Text-embedding-3-small (embedding-dim = 512)
Milvusのドキュメントと評価方法Ragasを使用した結果は以下の通り:
- 埋め込みモデル=BAAI/bge-large-en-v1.5がベストでした。

異なるLLM
チャンキングの方法をtop_k=2の再帰的文字テキスト分割に、埋め込みモデルをBAAI/bge-large-en-v1.5に固定した後、6つの異なるLLM APIエンドポイントを試してみた。
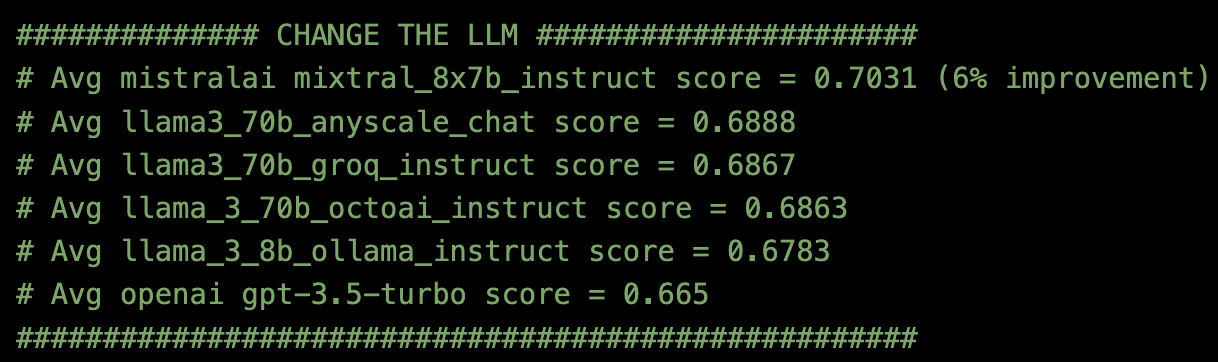
Milvusのドキュメントと評価方法Ragasを使用した結果:
- Anyscale Endpointsを使用したLLM = MistralAI mixtral_8x7b_instructがベストでした。
結論
RAGパイプラインの評価は、特定のデータとユースケースによって異なります。個人的な経験と文献から得た1つの重要な教訓は、最も重要な改善は、検索戦略を洗練させることによってもたらされることが多いということです。🛠️
Milvus docsのデータとRagasの評価を用いて、このブログは観察した:
チャンキング戦略を変更することで35%の改善** 📦。
エンベッディング・モデルを変更することで27%の改善** 🔍。
LLMモデル** 🤖の変更による6%の改善
これらの要素を反復することで、RAGパイプラインを最適化し、より良い結果を得ることができます!
参考文献
1.Greg Kamradt テキスト分割の5つのレベルに関するチュートリアル:https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/tutorials/LevelsOfTextSplitting/5_Levels_Of_Text_Splitting.ipynb
2.LangChain再帰的文字テキスト分割ツール:https://python.langchain.com/v0.2/docs/how_to/recursive_text_splitter/
3.LangChain Multivector Retriever: https://python.langchain.com/v0.2/docs/how_to/multi_vector/#smaller-chunks
4.LangChain Semantic Chunker: https://python.langchain.com/v0.2/docs/how_to/semantic-chunker/#standard-deviation
5.RAGASを使ってRAGパイプラインを評価する方法: https://medium.com/towards-data-science/rag-evaluation-using-ragas-4645a4c6c477

読み続けて

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.