




FiftyOneとMilvusでマルチモーダル埋め込みを探る
マルチモーダルなretrieval augmented generation (RAG)アプリを構築する最初のステップは?マルチモーダルなベクトル埋め込みを得ることです。埋め込みがマルチモーダルであるというのは、ある意味では語弊があります。ベクトル内の複数のモダリティを扱う方法はたくさんありますが、このチュートリアルでは、マルチモーダルモデルによって生成されたベクトル埋め込みに焦点を当てます。
このチュートリアルでは
- マルチモーダルとは何か?
- Milvusはどのようにマルチモーダル埋め込みを扱うのか?
- マルチモーダルモデルの例
- FiftyOneとMilvusを使ったマルチモーダルエンベッディングの調査
- FiftyOneとCLIPによるCIFAR 10のためのマルチモーダル埋め込み探索
- FiftyOneをさらにカスタマイズしてMilvusでデータを探索するには?
- FiftyOneとMilvusによるマルチモーダル埋め込み探索のまとめ
「マルチモーダル」とは何を意味するのか?
マルチモーダル」について議論するとき、私たちはモデルの能力について言及します。RAGスタック内の大規模な言語モデル/基礎モデルと埋め込みモデルの両方がマルチモーダルである可能性があります。この例では、オープンソースのモデルからマルチモーダルな埋め込みを探ります。どのようにしてベクトル埋め込みを得るのか?ベクトル埋め込みは、埋め込みモデルの最後から2番目の層から得られます。
これは、モデルの各層が入力に関する情報を学習し、最後の層が予測を行うためです。我々は予測をしたいのではなく、データの数値表現で作業できるようにしたいので、最後のレイヤーを切り離し、モデルが学習したすべての情報を含む2番目から最後のレイヤーからの出力を取ります。探索を容易にするためにFiftyOneを使用し、ベクトルを保持するためにMilvusを使用する。
Milvusはどのようにマルチモーダル埋め込みを扱うのか?
マルチモーダル埋め込み、あるいは一般的なベクトル埋め込みが優れている点は、特別な扱いを必要としないことです。ベクトル埋め込みは、特定の入力データの数値表現に過ぎません。実際のデータ型に関して言えば、ベクトル埋め込みは単なるベクトルであり、数値のリストです。Milvusはこれらのベクトルをすべて同じように扱います。
ベクトルには密なものと疎なものがあります。密なベクトルは一般的に浮動小数点数で構成され、ディープラーニングモデルによって生成されます。スパース・ベクトルはバイナリ・ベクトルと呼ばれることもあり、0と1で構成される。ベクトルを扱うときに注意しなければならないのは、同じサイズや次元のベクトルしか比較できないということだ。さらに、同じ大きさであっても、異なるモデルによって生成された埋め込みは、必ずしも比較することができません。
マルチモーダル埋め込みは特に厄介です。ほとんどのディープラーニング・モデルは、1種類のデータ、つまりモダリティを扱うように設計されています。画像、テキスト、ビデオ、あるいはもっと特注のものなどだ。しかし、これらのモデルは1種類のデータに対してのみ最適化されているため、他のモダリティを処理したり表現したりすることができない。テキスト入力を受け入れるように訓練されたモデルは、通常、画像を受け入れることができない。
マルチモーダルモデルは、複数のタイプのデータと相互作用するようにトレーニングされる。我々の目的では、複数のデータモダリティのベクトル埋め込みを生成するマルチモーダルモデルに興味がある。特に、テキストデータと視覚データを同じ空間に埋め込み、生成されるベクトルの次元が同じで、感覚的に同じように扱えるようなモデルに興味があります。
テキストと画像の埋め込みを生成する最も一般的なマルチモーダルモデルは、OpenAIのCLIPです。これは、contrastive techniquesを用いて、写真の画像埋め込みとキャプションのテキスト埋め込みを整列させます。
マルチモーダル埋め込み探索のためのFiftyOneとMilvusの利用
FiftyOneは、非構造化データのキュレーションと可視化のための主要なオープンソースライブラリです。FiftyOneは複数のベクトルストア・バックエンドと統合可能であり、Milvusは大規模で増大するデータセットを柔軟に扱うのに特に適している。この例では、Milvus Liteを使用しています。Milvusの組み込みバージョンで、ノートブックからすぐに始めることができます。詳細については、Milvus Liteのエンドツーエンドガイドをご覧ください。
コードに入る前に、すべての適切な前提条件がインストールされていることを確認してください。pip install milvus pymilvus fiftyone torch torchvisionを実行する必要があります。最初のステップはMilvus Liteインスタンスを立ち上げることである。Milvus からdefault_serverをインポートしてstart()` 関数を呼び出すことでこれを行うことができる。
from milvus import default_server
default_server.start()
Milvusのインスタンスが準備できたので、ベクトル埋め込み比較のためにFiftyOneとリンクさせます。FiftyOne、FiftyOne Brain、 FiftyOne Zooをインポートし、CIFAR 10データセットのテストスプリットをロードします。
foとしてfiftyoneをインポート
import fiftyone.brain as fob
fozとしてfiftyone.zooをインポートする
# ステップ1:FiftyOneにデータをロードする
dataset = foz.load_zoo_dataset("cifar10", split="test")
この例では、CLIPモデルを使って画像を埋め込みます。そして、the FiftyOne Brain の compute_similarity 関数を使用します。この関数はまず、指定したモデルを使用してサンプルの埋め込みを生成し、次にこれらの埋め込みからMilvusコレクションを作成し、FiftyOneサンプルコレクションにアタッチします。FiftyOneとベクトル検索バックエンドを使用すると、画像、オブジェクトパッチ、さらにはビデオフレームに対する類似性インデックスを生成することができます!
compute_similarity関数はFiftyOneデータセットと様々な名前のパラメータを受け取ります。brain_key は、FiftyOne が実行を追跡するために使用する一意のキーです。backendキーには、FiftyOne が使用するベクトルデータベースバックエンドを指定し、model` には、FiftyOne が埋め込みデータを作成する際に利用するモデルの名前を指定します。
fob.compute_similarity(
dataset、
brain_key="clip_sim"、
backend="milvus"、
model="clip-vit-base32-torch"、
)
探索の前にここで見る最後のステップは、FiftyOneを使用してFiftyOne Appを起動することです。データセットを渡し、auto=Falseに設定することで、ウィンドウはノートブックでは開かず、localhost:5151のChromeタブからアクセスできるようにする。
session = fo.launch_app(dataset, auto=False)
CIFAR10におけるFiftyOneとCLIPによるマルチモーダル埋め込み探索
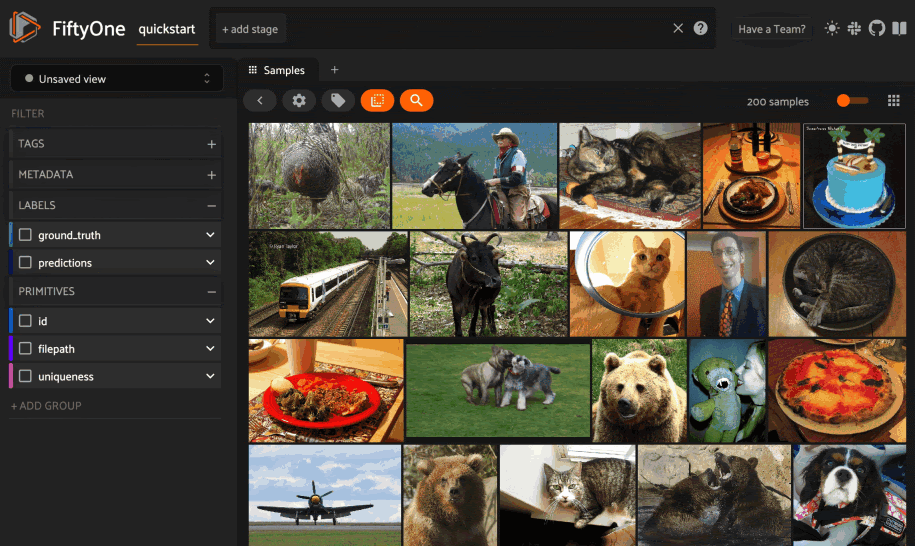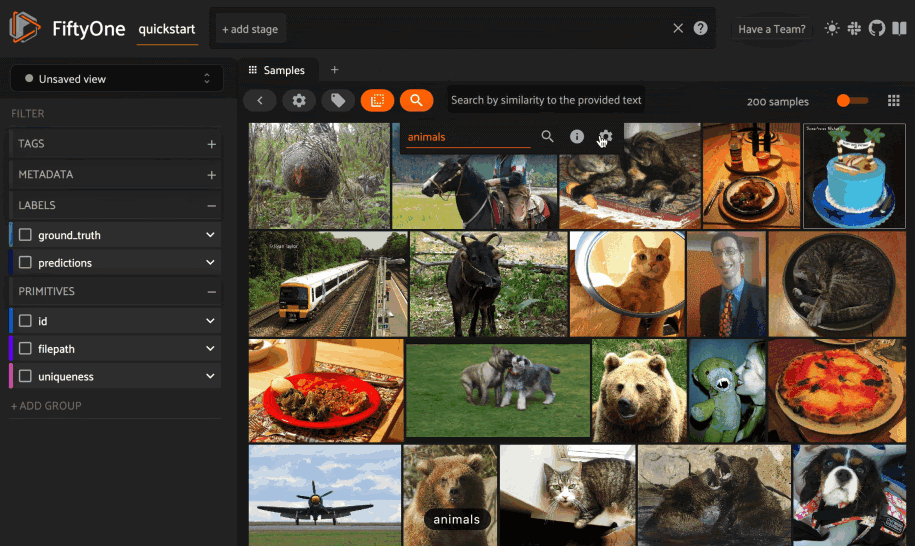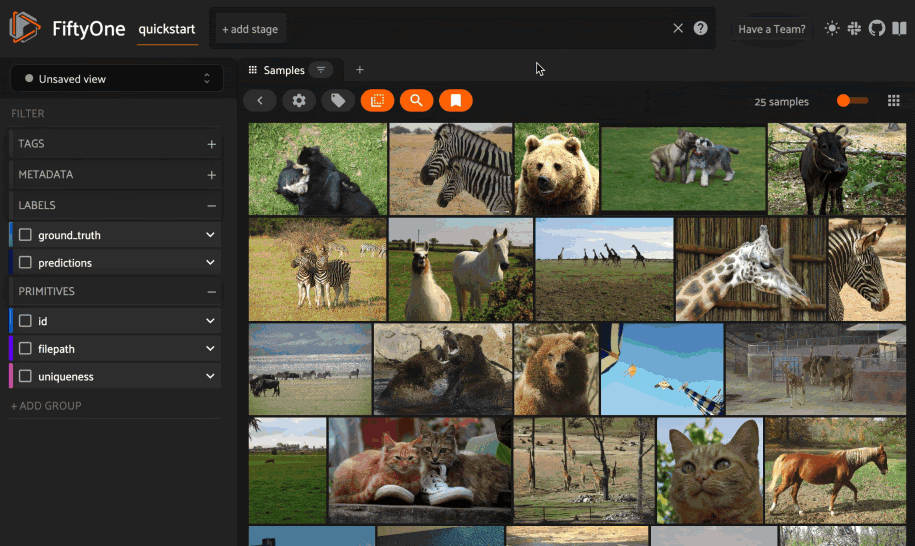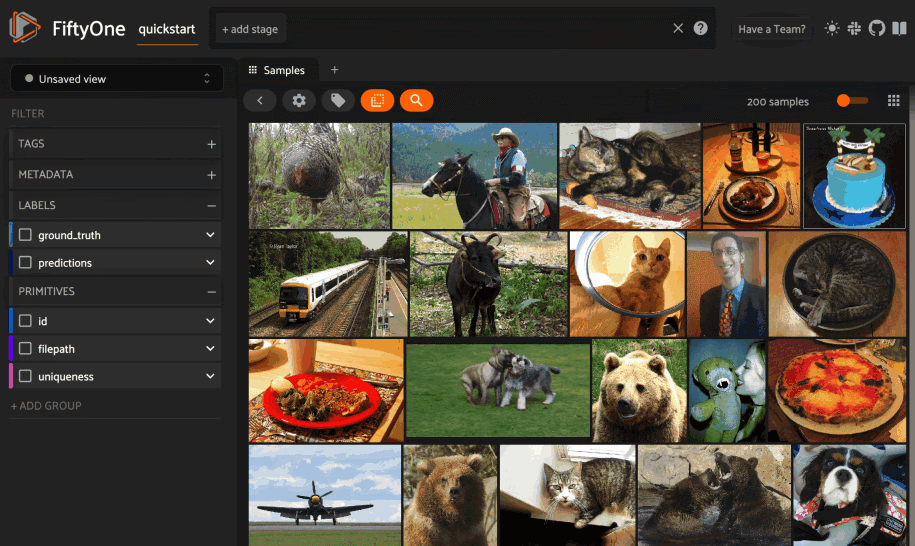
探索の時間です!意味的に似ている](https://zilliz.com/glossary/semantic-search)画像を見つけるためにtextを使う方法を見てみましょう。3つの単語を見てみよう:フェラーリ、マスタング、ポニー。
最初に検索するのはフェラーリという車だ。
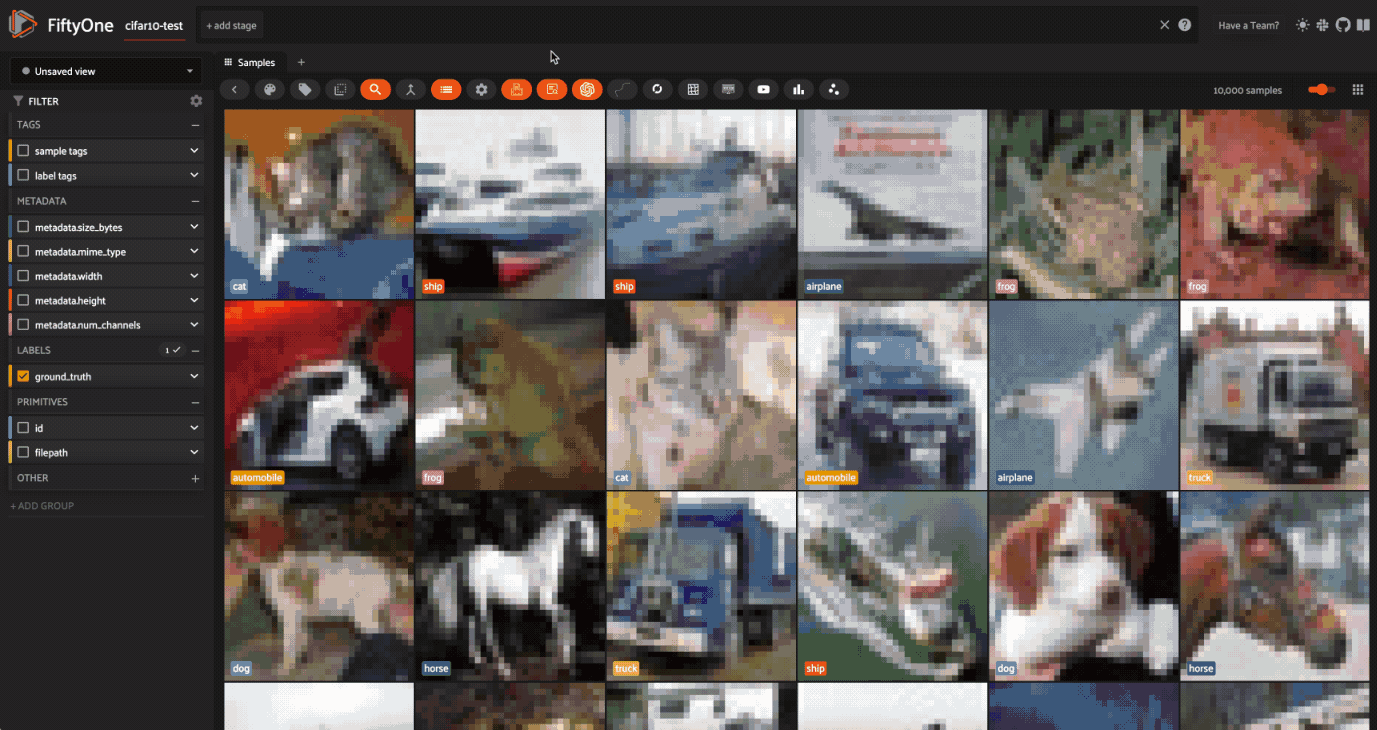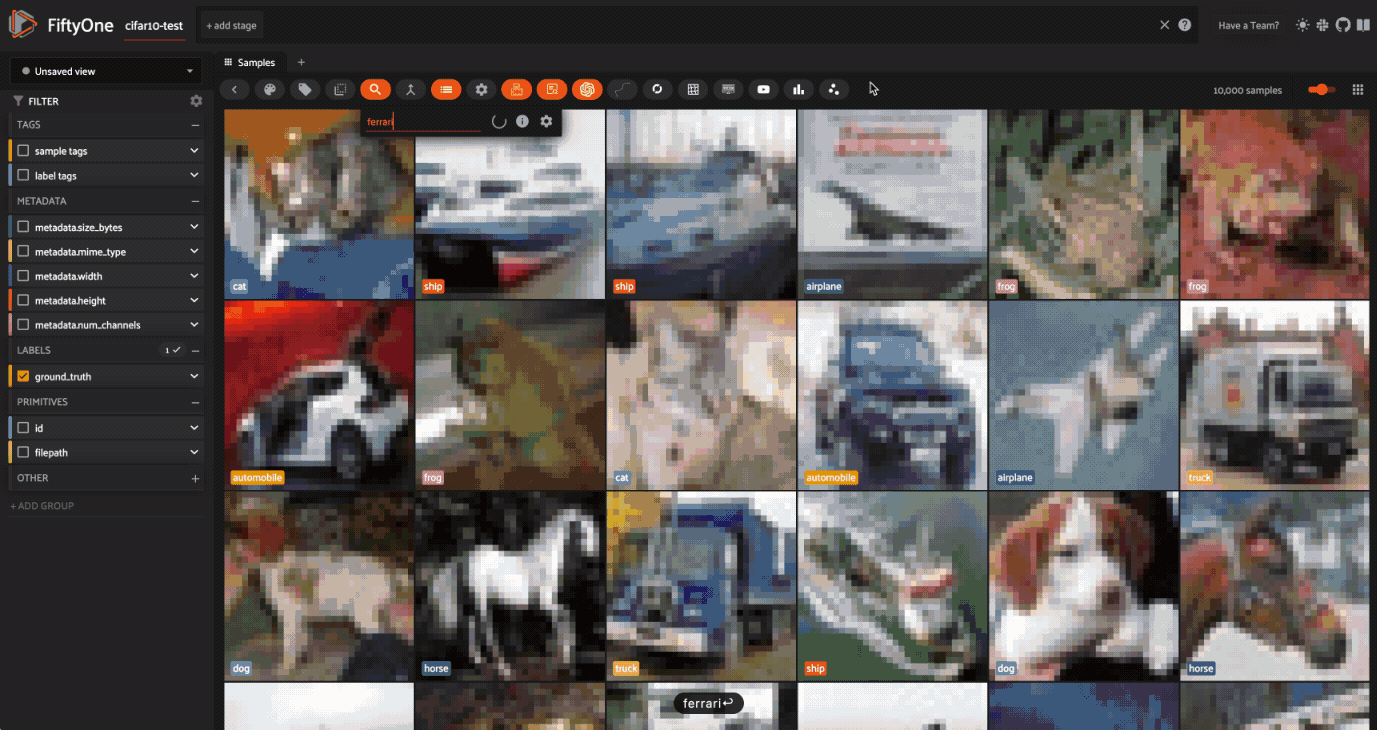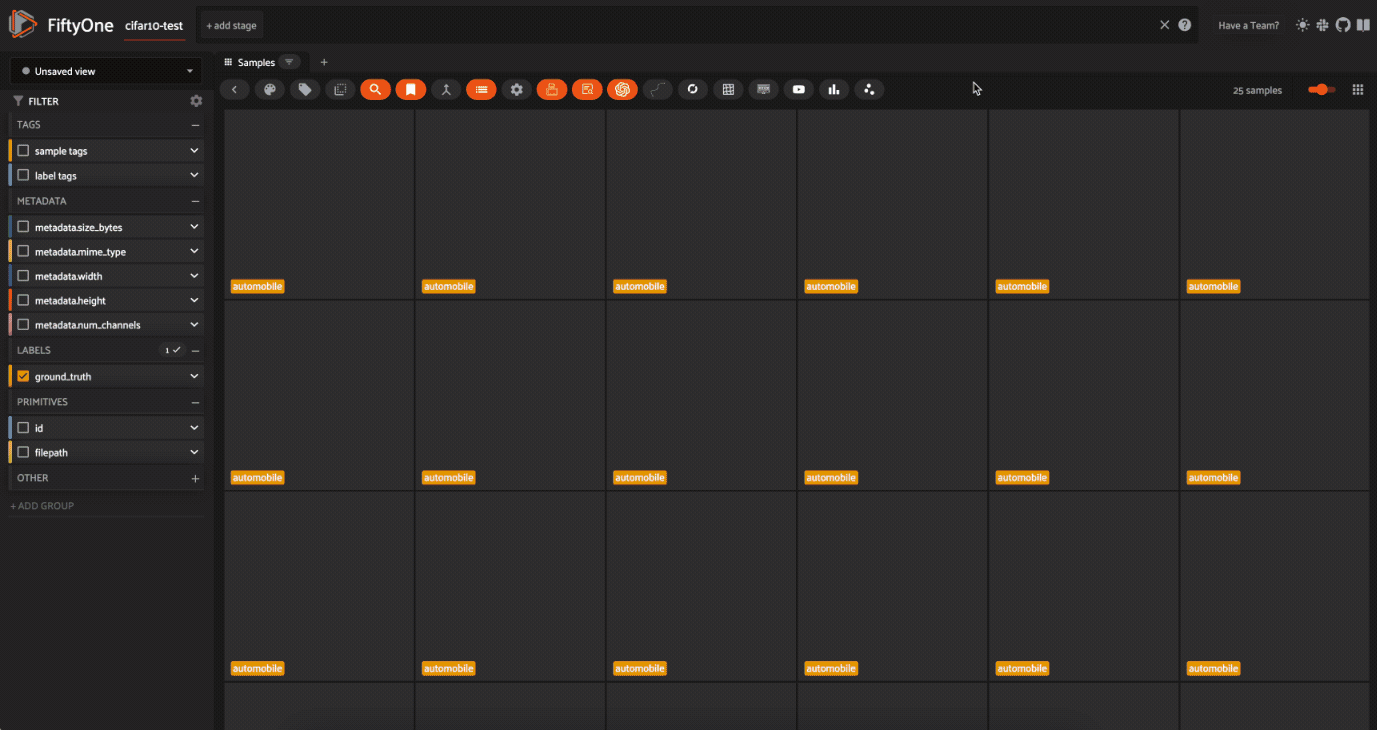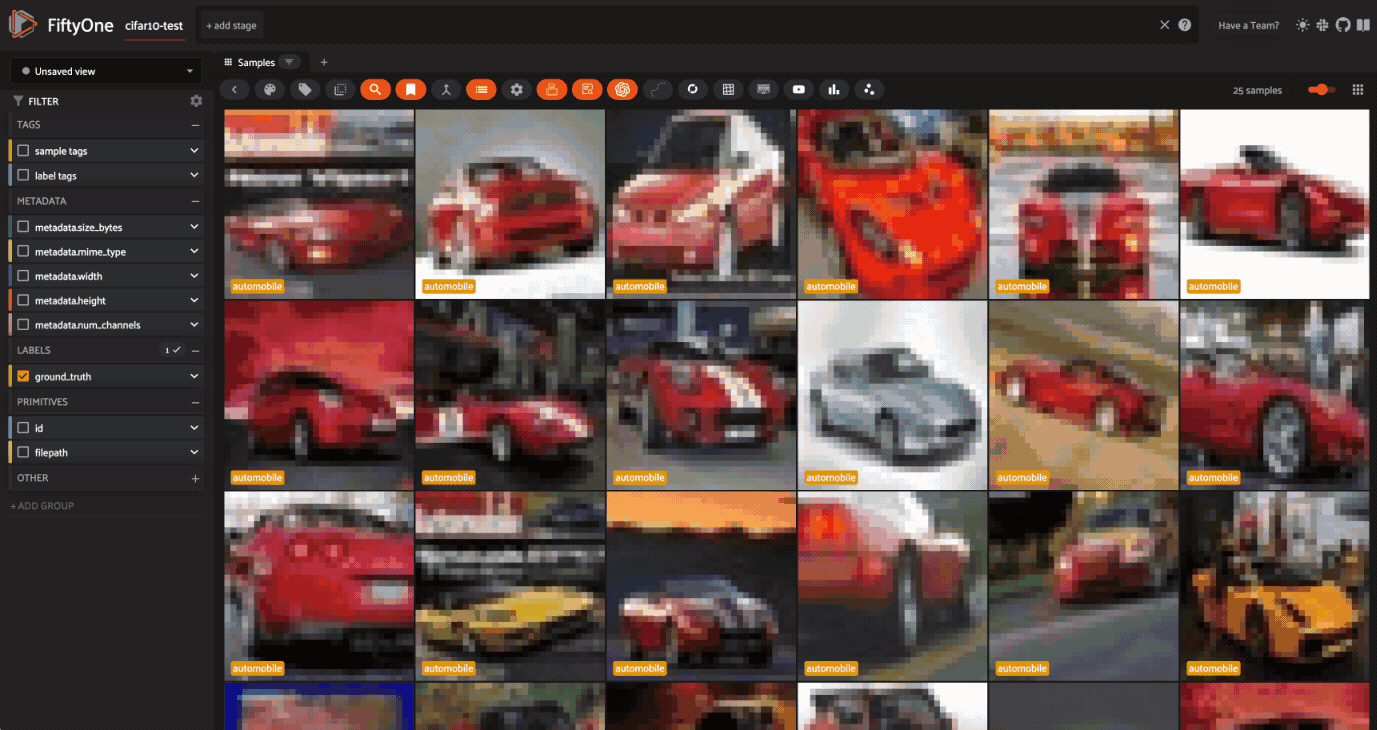
次に "pony "と検索すると、明らかに馬の写真がヒットする。
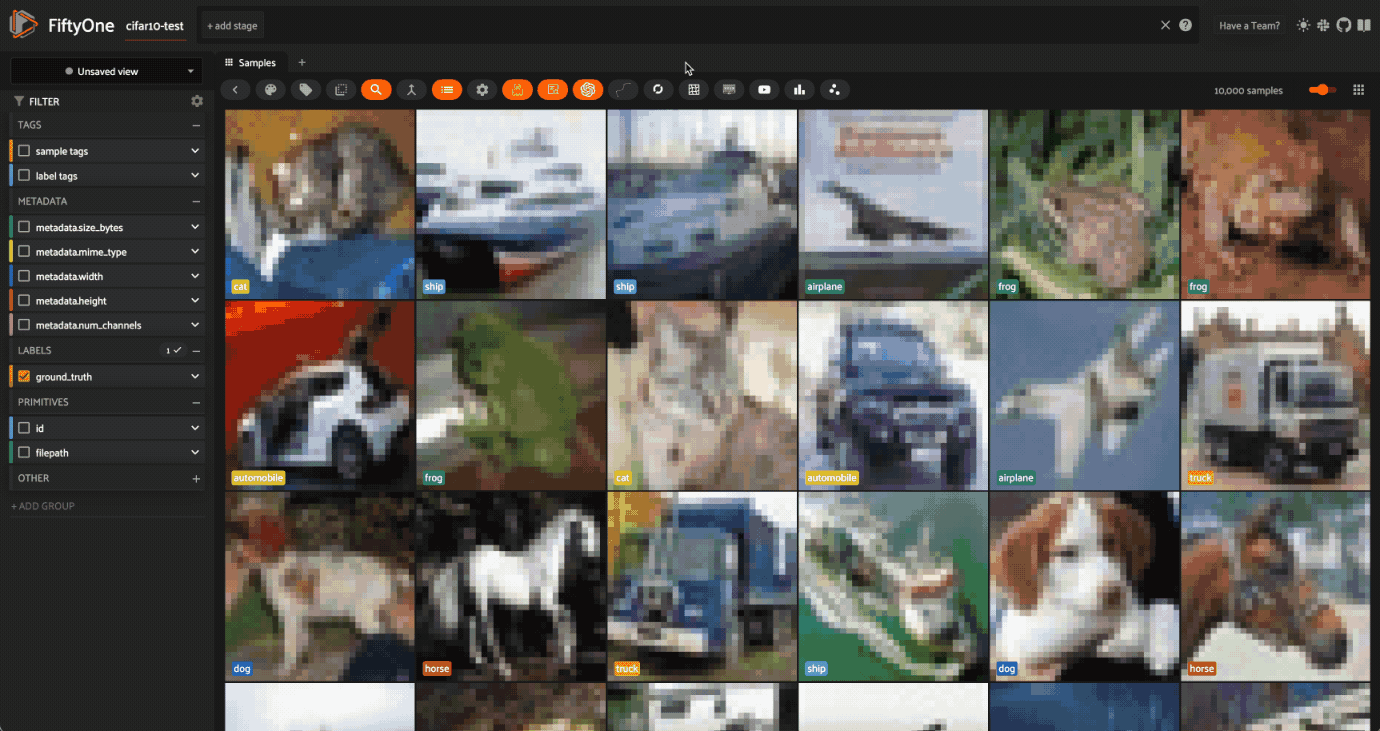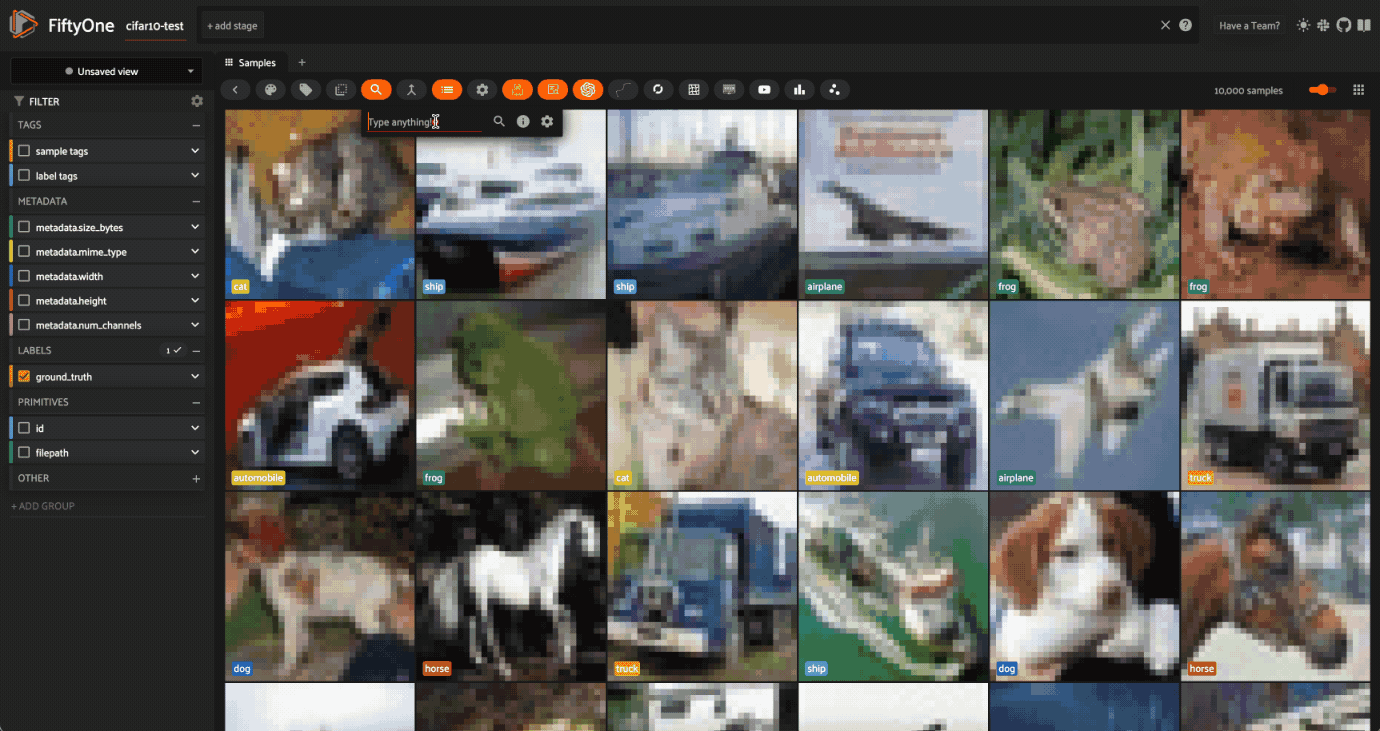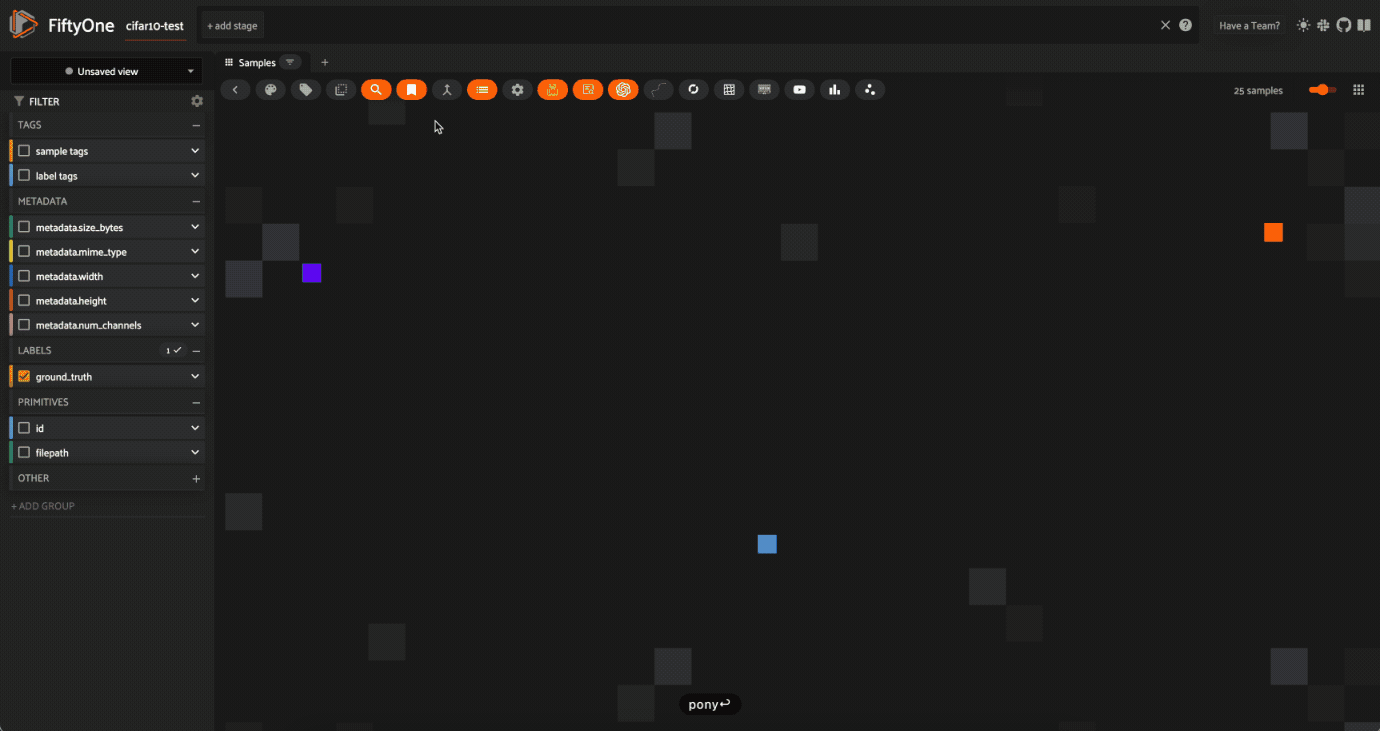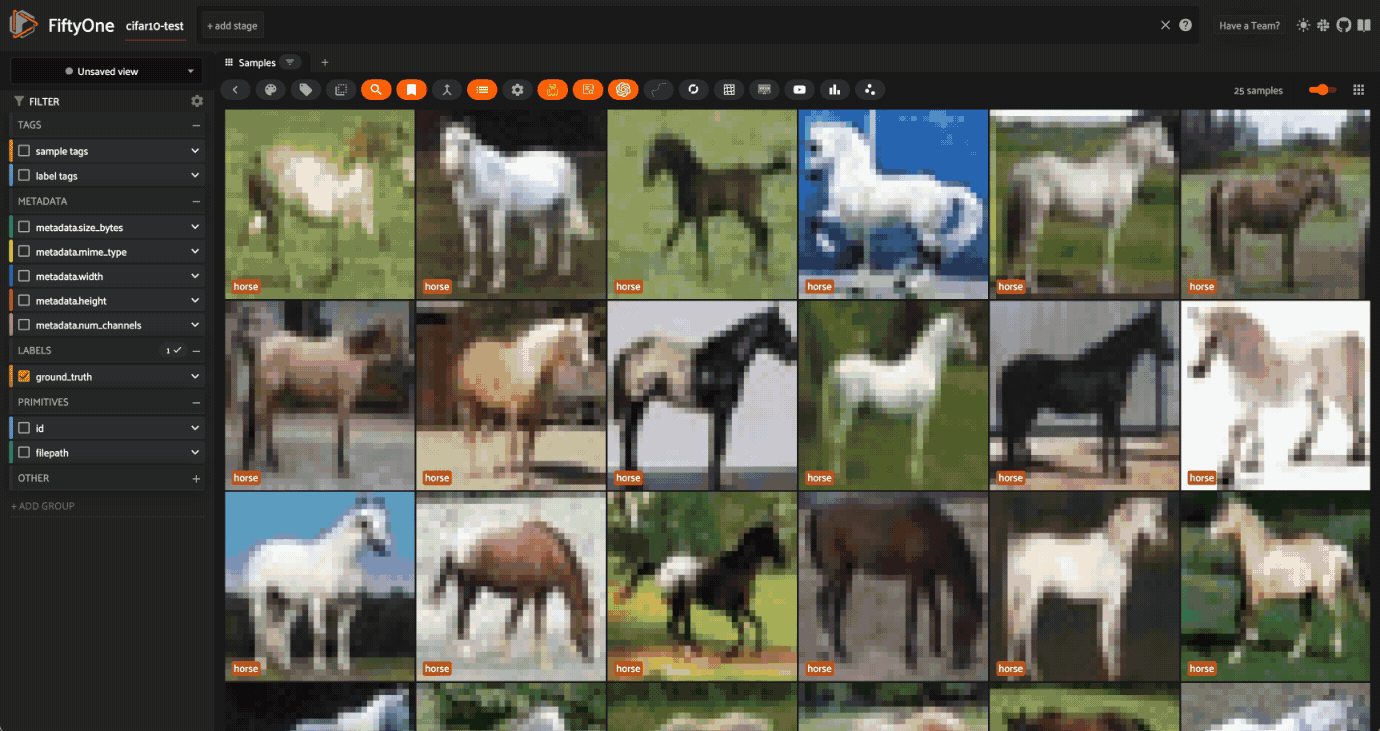
しかし、"mustang "で検索すると、ミックスが出てくる。
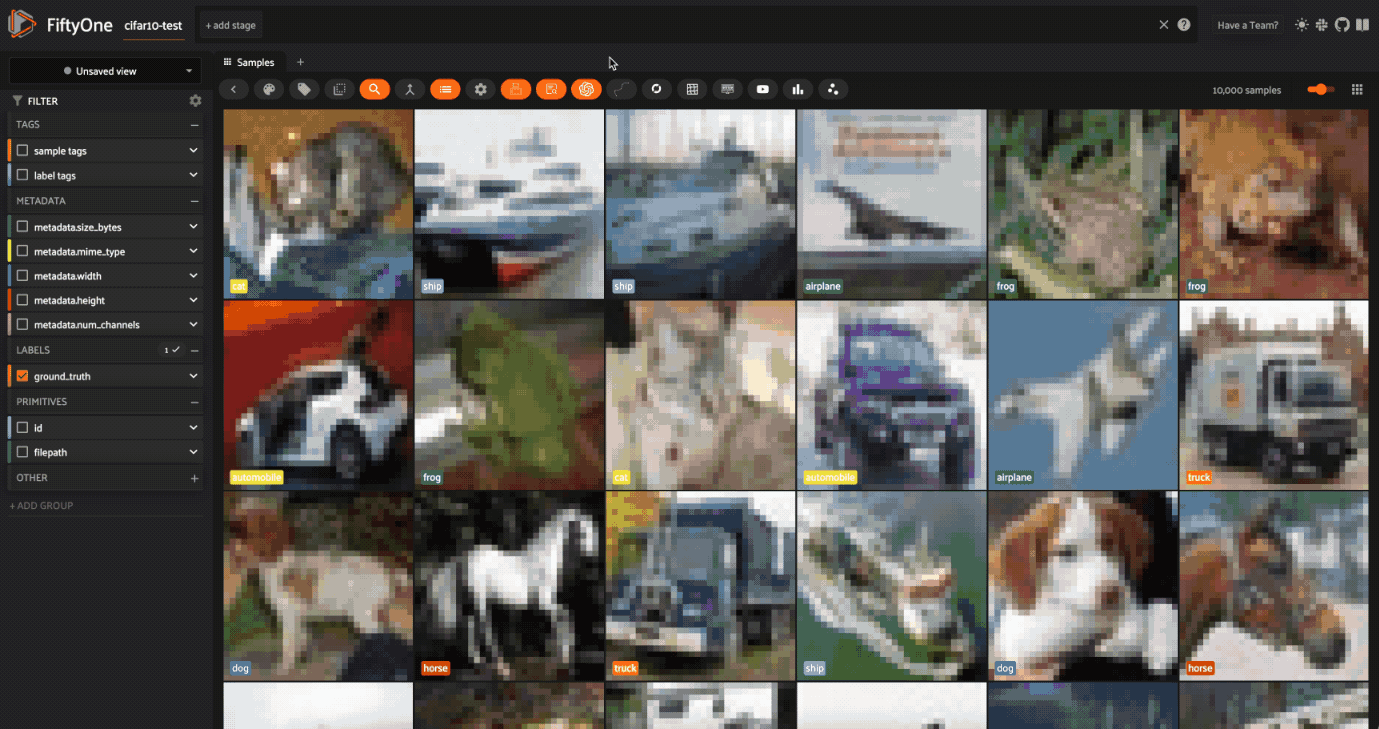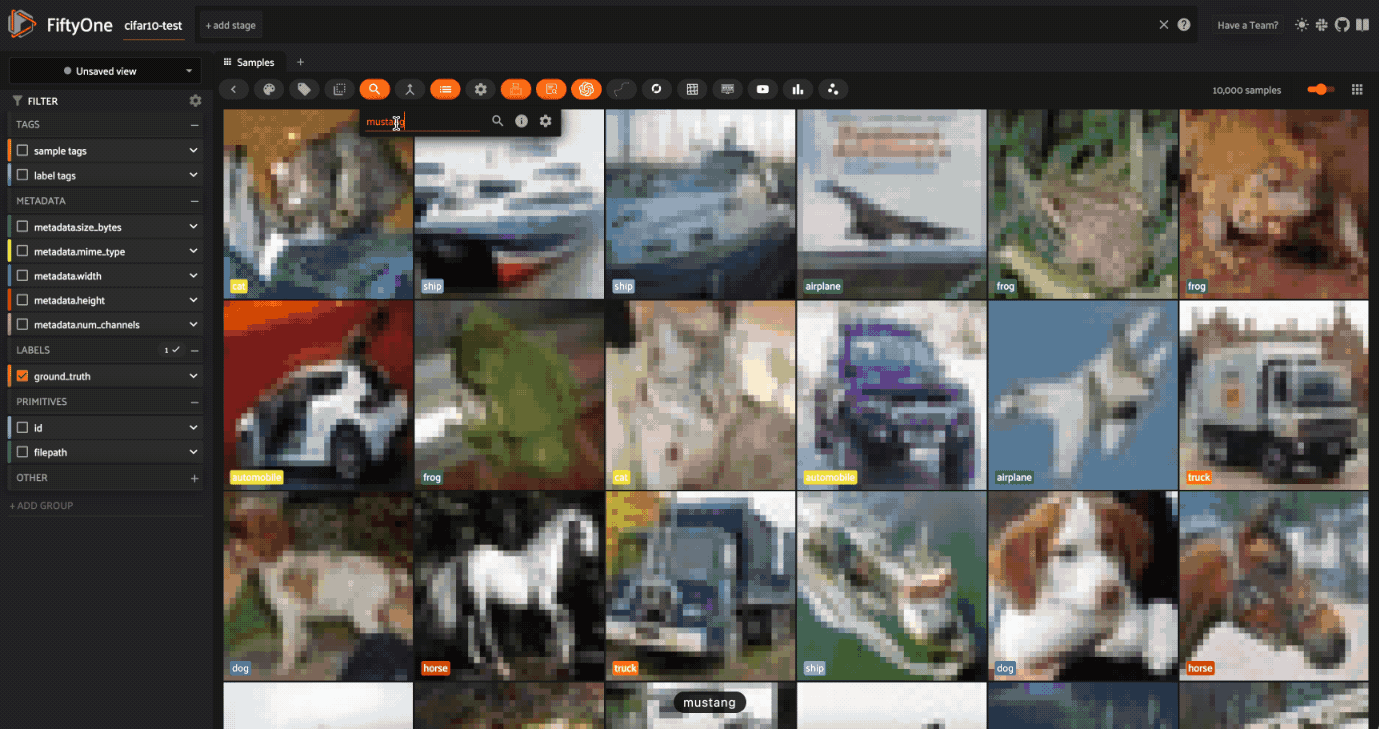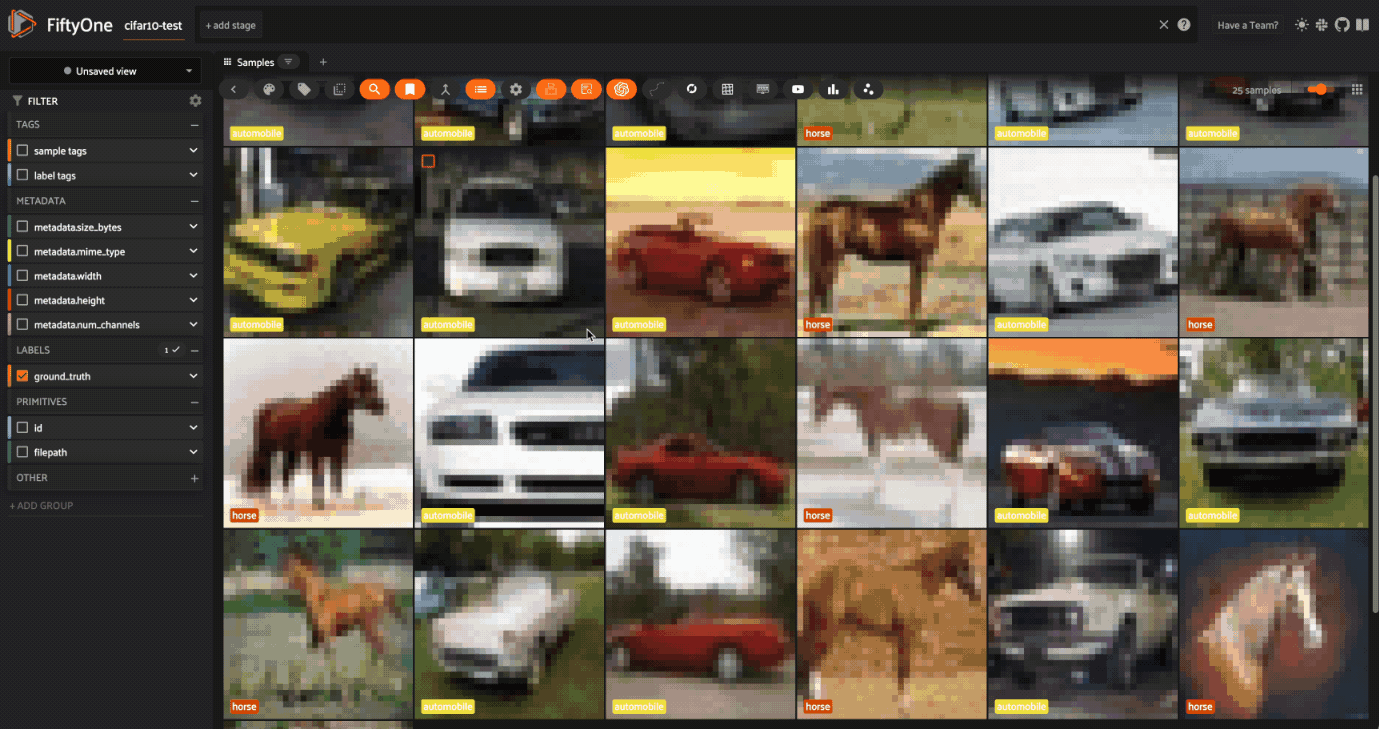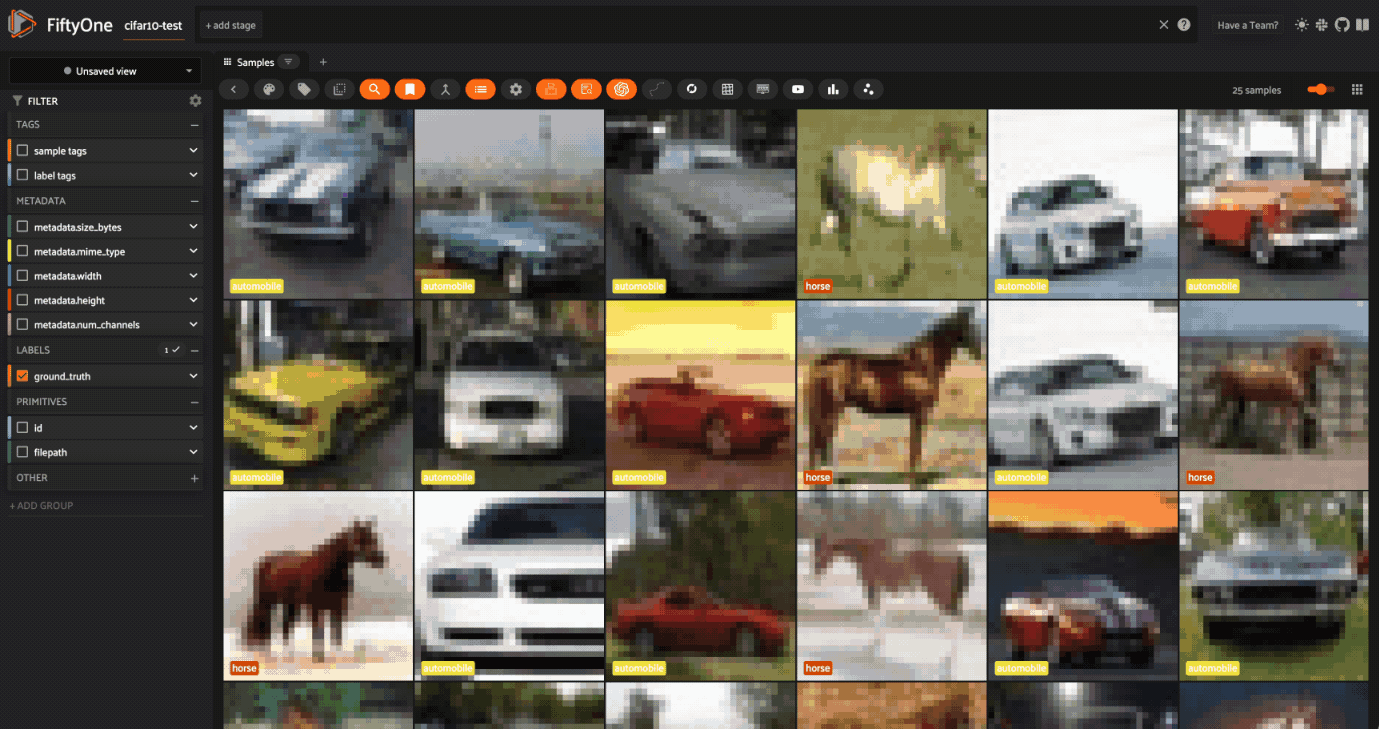
このステップは、データセットを評価し、データの文脈を理解することが不可欠であることを示している!
FiftyOneをMilvusでデータ探索のためにさらにカスタマイズするには?
MilvusをFiftyOneのベクトル検索のデフォルト「バックエンド」に設定するには、以下の環境変数をソースにします:
export FIFTYONE_BRAIN_DEFAULT_SIMILARITY_BACKEND=milvus
任意のインデックスについて、コレクション名、使用する一貫性レベル、類似性を評価するために使用するメトリックを指定することもできます。以下は、ユークリッド・メトリックとバウンデッド一貫性を使用する2番目の類似性インデックスです:
fob.compute_similarity(
dataset、
brain_key="clip_euclid"、
model="clip-vit-base32-torch"、
metric="euclidean"、
一貫性レベル="Bounded"
)
データセットに複数の類似性インデックスがある場合、虫眼鏡の下にある検索バーの横の歯車アイコンをクリックし、そのブレーン・キーでインデックスを選択することで、アプリで使用するインデックスを選択できる:
画像とテキストの埋め込みを生成するために、別のマルチモーダルモデルを使うこともできます。実際、任意のOpenCLIPモデル(数日中にもっと良いリンクができるでしょう)や、Hugging FaceのTransformersライブラリからの任意のゼロショット予測モデルを使って、そうすることができます。例として、AltCLIPで構築されたインデックスを示します:
pip install transformers
fob.compute_similarity(
データセット
brain_key="altclip"、
model="zero shot-classification-transformer-torch"、
name_or_path="BAAI/AltCLIP"、
)
FiftyOneとMilvusによるマルチモーダル埋め込み探索のまとめ
この投稿では、FiftyOneとMilvusを使って、マルチモーダル埋め込みがどのように機能するかを探りました。一般的なマルチモーダルモデルであるCLIPを、一般的なデータセットであるCIFAR 10上でどのように探索できるかを紹介しました。CLIPで入力データの埋め込みを作成し、Milvusでマルチモーダルデータの埋め込み(「マルチモーダル埋め込み」と呼ばれることもあります)を保存し、FiftyOneで埋め込みを探索します。
このようにCLIPを使えば、テキスト付きの画像を検索することができる。それを使って、異なる文脈で異なる意味を持つ可能性のある単語の画像を比較するために、自然言語を使って空間を探索した。ポニー」は明らかに馬であり、「フェラーリ」は明らかに車であるが、「ムスタング」はどちらでもあり得ることを調べた。

読み続けて

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.