




画像とテキストを組み合わせる:マルチモーダル検索が検索をどう変えるか
マルチモーダルモデルの台頭
2024年の large language models (LLMs)の急速な進歩を振り返ってみると、AIが技術革新と投資の増加を通じて進歩し続けていることは明らかだ。豊富なテキストデータが利用可能である一方で、研究者たちは、人間が複数の感覚を通して世界を理解していることを認識しており、画像、音声、動画などの他のデータタイプを活用する方向へのシフトを促している。このシフトが、 マルチモーダルAIモデルの台頭を促した。このモデルは、複数のソースからのデータを処理・理解することができ、より豊かで複雑な情報の解釈を可能にする。
2024年前半には、OpenAIのGPT-4o、AnthropicのClaude 3、GoogleのGemini 1.5 Pro、AppleのFerret-UIなど、重要なマルチモーダルモデルがリリースされた。これらのモデルは、AIの能力をテキスト以外にも拡張し、クリエイティブ産業、生産性ツール、よりインタラクティブなシステムなど、新たなアプリケーションを開拓している。かつてはニッチな学術的概念であったものが、今や主流となり、開発者はこれらのAPIを活用してAIと多様なメディアを統合するアプリケーションを構築し、イノベーションの新たな可能性を引き出している。
 新しくリリースされたGPT-40のマルチモーダル機能を示すOpenAIの科学者たち.png
新しくリリースされたGPT-40のマルチモーダル機能を示すOpenAIの科学者たち.png
図:新しくリリースされたGPT-40のマルチモーダル機能を示すOpenAIの科学者たち_。
マルチモーダル検索と合成画像検索(CIR)
マルチモーダルモデルが発展するにつれ、マルチモーダル検索は、複数のモダリティ(典型的にはテキストと画像)からの入力を組み合わせるもので、ますます人気が高まっています。このアプローチは、両方のモダリティの長所を活用することで、ユーザーの検索意図をよりニュアンス豊かかつ正確に捉えることを可能にする。
マルチモーダル検索の中で最も一般的なタスクの1つは、合成画像検索(CIR)であり、ユーザは説明的なキャプションと共に参照画像を含むクエリを提供する。この二重入力アプローチは、視覚的コンテンツとテキストによる指示を組み合わせることで、より詳細で正確なクエリを作成し、特定の画像を検索することを可能にする。
従来の画像検索は、主に視覚的 類似性メトリクスに依存しており、多くの汎用クエリに有効である。しかし、単一の参照画像ではユーザーの意図を十分に表現できない場合、テキスト入力が不可欠な補完となる。テキストは、画像だけでは不足しがちなコンテキストと精度を追加し、ユーザーが検索クエリを微調整できるようにする。このようなモダリティの融合により、開発者はより堅牢で柔軟な検索システムを構築することができ、ユーザーは複雑なクエリをより高い精度で自然に表現することができる。
以下のセクションでは、FashionIQ、CIRR、CIRCOのような一般的なデータセットを用いて評価された、合成画像検索における主要なモデルやテクニック、その方法論、様々なドメインにおけるパフォーマンスを紹介する。これらの評価により、実世界のアプリケーションにおける様々なCIRアプローチの長所と限界を明らかにする。
一般的な合成画像検索手法の概要
近年、マルチモーダル検索技術は、特にCLIPのようなモデルによって、ゼロショットの普遍性を目指して進歩している。これらの技術は、利用可能なリソースに応じて、事前に訓練されたembeddingsまたは微調整された注釈付きデータセットのいずれかを活用し、検索性能とデータ品質の大幅な向上につながる。
以下の表は、一般的な合成画像検索(CIR)手法の概要、そのコアとなる手法、およびそれらが生成し検索に使用するエンベッディングのタイプを示しています:
| ------------- | ----------------------------------------------------------------------------------------------------------------------------------------- | ----------------------- | --------------------- | | テクニック | 説明 | 生成された埋め込み | 検索埋め込み | | Pic2Word| 画像をテキストに埋め込まれたトークンに変換し、画像からテキストへの柔軟な検索を可能にします。 | CLIP Text Embedding|CLIPビジュアル埋め込み | コンポディフ|CLIPビジュアルエンベッディングにノイズを適用し、ノイズ除去処理中にテキストを使用して条件付きCLIPビジュアルエンベッディングを再構築。| CLIPビジュアルエンベッド|CLIPビジュアルエンベッド | CIReVL|画像を説明的なテキストに変換し、ターゲットに合わせて説明を修正し、新しい表現を生成する。 | CLIPテキストエンベッド|CLIPビジュアルエンベッド | MagicLens|画像とテキストデータを同時に処理し、統一されたベクトル埋め込みを生成するTransformerモデルを使用。 | MagicLens Embedding|マジックレンズ埋め込み
Pic2Word:ゼロショット合成画像検索のための写真から単語へのマッピング
Pic2Wordは、ゼロショット合成画像検索(ZS-CIR)のための手法であり、大規模なラベル付きデータセットを必要とせずに、画像とテキストを入力クエリとして画像を検索することを目的としている。事前に訓練されたCLIPモデルを用いて、Pic2Wordは画像からの視覚的埋め込みを、テキスト空間で画像を表現する擬似単語トークンにマップする。これにより、このモデルは画像の特徴とテキストの説明を組み合わせて、テキストで指定された変更(例えば、オブジェクトの色のような画像の属性の変更)に基づいてターゲット画像を検索することができる。
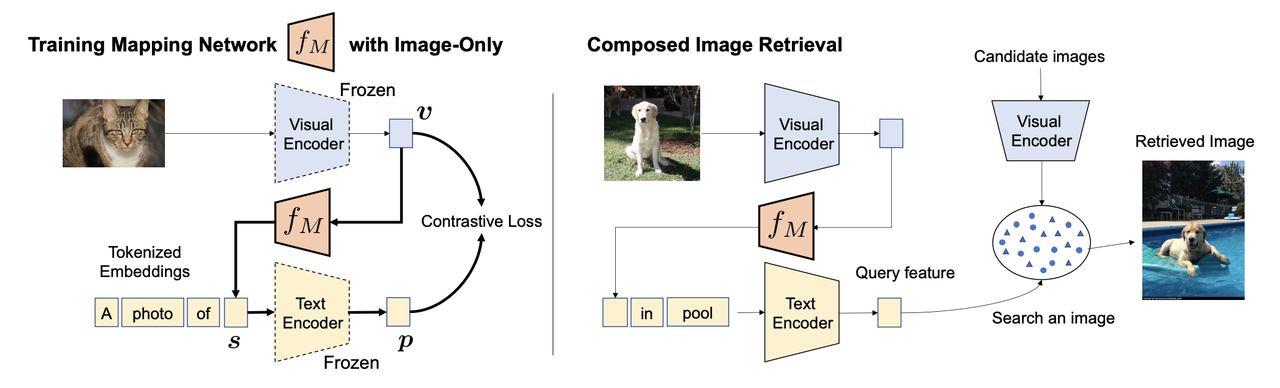 左-Pic2wordマッピングネットワークの学習過程、右-構成画像検索の過程.png
左-Pic2wordマッピングネットワークの学習過程、右-構成画像検索の過程.png
図:左:Pic2wordマッピングネットワークの学習過程、右:合成画像検索の過程_。
Pic2Wordの仕組み
上の図は、Pic2Wordマッピングネットワークの学習過程と、合成画像検索の過程を示している。学習過程では、画像(例えば猫の写真)が凍結されたVisual Encoderに渡され、視覚的埋め込みが生成される。同時に、"A photo of "のようなトークン化されたテキストプロンプトがText Encoderに渡され、対応するテキスト埋め込みが生成される。マッピングネットワークの目的は、画像埋め込みを、テキストプロンプトに組み込むことができる擬似トークンにマッピングし、"A photo of [s]"というフレーズを形成することである。
このマッピングされたトークンは、凍結されたテキスト・エンコーダを通すと、元の画像埋め込みと密接に整合するテキスト埋め込みを生成するはずである。ネットワークは対比的損失関数を用いて学習され、視覚的埋め込みとテキスト埋め込みの間の距離を最小化し、画像が単語のようなトークンとして正確に表現されることを保証する。
一旦マッピングネットワークが訓練されると、それを構成画像検索タスクに用いることができる。この段階では、ユーザは画像(例えば犬)とテキストクエリ(例えば "in a pool")を入力する。画像はビジュアル・エンコーダで処理され、テキストはテキスト・エンコーダで処理される。学習された擬似トークンはクエリを強化し、システムが画像とテキストの構成を理解できるようにする。
画像とテキスト表現を組み合わせたクエリ特徴は、候補画像のデータベースと比較される。そして、システムは、提供されたテキスト記述に基づいて入力画像を効果的に修正しながら、ベストマッチの画像(例えば、プールで泳ぐ犬)を検索する。
CompoDiff:潜在拡散を用いた汎用的な合成画像検索
CompoDiff** は、ゼロショット合成画像検索(ZS-CIR)のために設計された拡散に基づくモデルである。テキストから画像生成の技術である拡散モデルを採用し、画像編集と検索の柔軟性と精度を大幅に向上させています。これらのモデルは、単にテキストを参照するだけでなく、生成された画像が学習中に観察されたパターンと一致することを保証します。拡散モデルを使用することにより、CompoDiffは、入力テキスト、参照画像、およびマスクをマージする埋め込みを作成し、CLIP視覚的埋め込み分布に沿ったベクトルを生成します。
では、拡散モデルの仕組みをどのように理解すればよいのでしょうか?時間とともにノイズが多くなる写真を考えてみよう。鮮明でシャープな写真から始まり、古いテレビの静止画のように、徐々にランダムなノイズが加わっていくとする。画像はどんどん不明瞭になり、ほとんど認識できなくなり、純粋なノイズのように見えるようになる。これが前方拡散プロセスである。
しかし、より魅力的なのは逆のプロセスだ。拡散モデルでは、ノイズの多い画像から始めて、ゆっくりと段階的に「ノイズ除去」していくことが目標になる。モデルはノイズを除去しながら、元の画像を再構築する(あるいは、テキストプロンプトに基づいて新しい画像を作成する)。このプロセスにより、モデルは特定のテキスト記述や参照画像のような特定の条件に準拠した高品質の画像を生成することができる。
テキストを埋め込む際も同じように動作します。CompoDiffは、ガウスノイズ埋め込みを徐々にノイズ除去し、CLIPの視覚的埋め込みと一致するまで、そのS/N比を向上させます。テキストと画像は、この変換を制御し、マスクは、どの画像領域を修正するかについての特別なガイダンスを提供します。
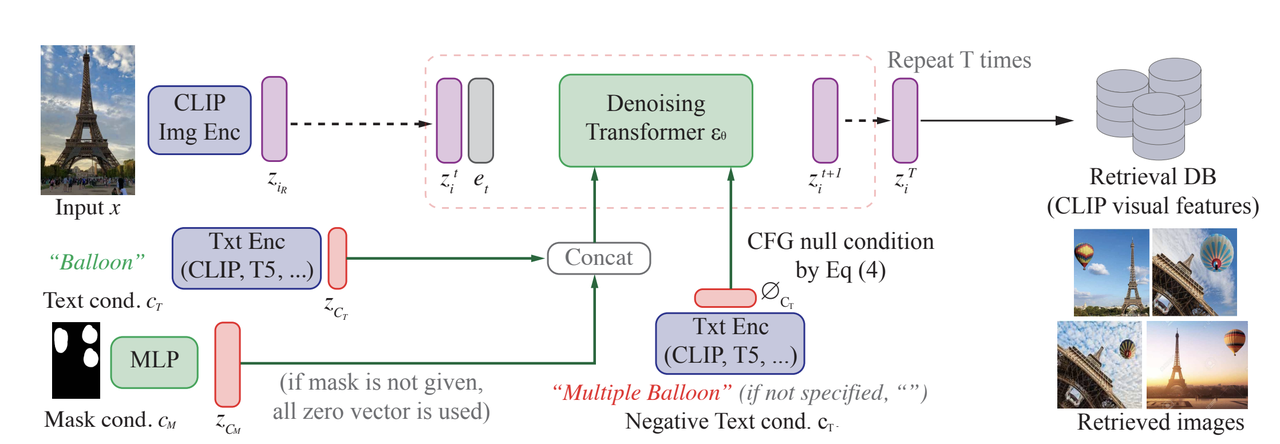 CompoDiffの仕組み.png
CompoDiffの仕組み.png
図:どのようにCompoDiffは機能するのか?
CompoDiffの推論プロセス
図のように、CompoDiffの推論フェーズでは、入力画像(例えば、エッフェル塔)からプロセスが開始され、CLIP画像エンコーダーを通して潜在空間にエンコードされ、最初の視覚的埋め込みが生成されます。この埋め込みは前方拡散処理を受け、ノイズが付加され、よりノイズの多いバージョンに変換されます。
次に、ノイズ除去変換器が適用され、複数のステップ(回繰り返す)で徐々にノイズを除去し、よりきれいな画像埋め込みを復元します。ノイズ除去プロセスは、画像がどのように再構成されるべきかに影響する条件によって導かれます。これらの条件には以下が含まれます:
1.テキスト条件:この場合、テキストプロンプト "Balloon "はテキストエンコーダ(CLIPやT5のような他のテキストモデル)を通してエンコードされ、テキスト埋め込みを生成する。この埋め込みは、ノイズ除去処理にコンテキストガイドを追加し、最終画像が "風船 "の説明と一致することを保証します。
2.マスク条件:マスクが提供された場合、それは多層パーセプトロン(MLP)を通して処理され、マスク埋め込みを生成します。このマスク埋め込みは、特定の領域における風船のような要素の修正や追加など、画像の特定の領域に焦点を当てるようにノイズ除去をガイドします。
テキストとマスクの条件は、ノイズの多い視覚的埋め込みと連結され、ノイズ除去変換器に渡されます。この変換器は、分類器なしガイダンス(CFG)を用いて、これらの条件の強さを調整します。マスクや条件が提供されない場合、スムーズな動作を保証するためにデフォルトのゼロベクトルが使用されます。
特筆すべきは、負のテキスト条件も、出力を洗練させるためにこのプロセス中に導入されることである。たとえば、"multiple balloons"(複数の気球)のような否定的な条件を適用することで、複数の気球の生成を回避し、最終的な画像にエッフェル塔付近の1つの気球が映し出されるようにすることができる。
ノイズ除去を何度か繰り返した後、得られた画像埋め込みはCLIPの視覚的特徴と整列し、次に検索データベースと比較され、ベストマッチ画像を見つけるか生成します。
CompoDiffのトレーニングプロセス
トレーニングは2段階に分かれています:
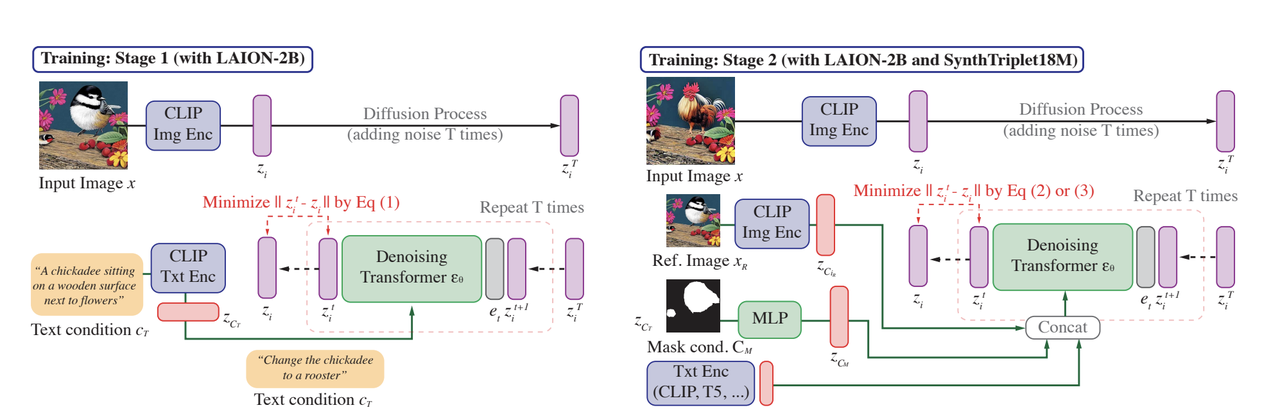 コンポディフのトレーニングプロセス.png
コンポディフのトレーニングプロセス.png
図CompoDiffのトレーニングプロセス
****
**第1段階:LAION-2Bを使用したトレーニング
第一段階では、画像とテキストのペアの大規模なコレクションを含むLAION-2Bデータセットでモデルを学習する。このステージの主な目的は、テキスト記述を指針として、ノイズの多い入力からCLIP視覚的埋め込みを生成する方法を学習することである。
このプロセスは、画像(例えば鳥)をCLIP視覚埋め込み にエンコードすることから始まる。この埋め込みは拡散過程を経て、ノイズが数段階にわたって徐々に追加され、識別可能な情報をほとんど含まない、非常にノイズの多いバージョンとなる。同時に、対応するテキスト記述、例えば "A chickadee sitting on a wooden surface next to flowers "は、CLIPテキスト埋め込み にエンコードされる。ノイズの多い視覚的埋め込みとテキスト埋め込みは、次にノイズ除去変換器に送られ、テキストに導かれながら段階的にノイズを除去する。この変換器の目的は、画像のきれいな視覚的埋め込みを徐々に再構成することです。この段階での目的は、ノイズの多い視覚的埋め込みと、テキストをガイドとした再構成された埋め込み**の差を最小化することです。これにより、視覚情報とテキスト情報を整合させ、生成された画像特徴がテキストの記述と一致するようにモデルを学習させる。
ステージ2:SynthTriplets18Mデータセットでの微調整
ステージ2では、モデルはLAION-2Bと合成SynthTriplet18M**データセットの両方でファインチューニングされ、より複雑なシナリオを処理する能力が強化されます。
この段階では、モデルはテキスト記述からだけでなく、参照画像や、修正すべき領域を示すマスク条件を組み込んで、特定の画像を生成することを学習する。学習は、ステージ1と同様に入力画像をエンコードすることから始まりますが、今度は参照画像も提供され、独自の視覚的埋め込みにエンコードされます。参照画像は、モデルが入力画像を修正する際のガイドとなる。マスク条件も導入され、画像中の修正が必要な特定の領域を強調します。マスクはMLP(多層パーセプトロン)を使って埋め込みに処理され、テキスト埋め込み**(例えば「ヒヨドリをオンドリに変える」)と連動してノイズ除去プロセスをガイドします。
1つは、テキストとマスクの条件に基づいてターゲット画像の特定の領域を不明瞭にすることを学習するもので、もう1つは、提供された参照、マスク、テキストに基づいて入力画像をターゲット画像に変換する能力を磨くものです。この交互の学習プロセスを通じて、モデルは、画像を正確かつ柔軟に修正するために、視覚情報とテキスト情報をどのようにブレンドするかを学習する。 この2つの段階が終了する頃には、CompoDiffは複雑な合成画像検索タスクに対応できるようになり、複数の条件に基づいて画像がどのように生成され、修正されるかを細かく制御できるようになります。これにより、このモデルは、詳細なテキストの指示に沿った画像を生成したり、参照画像から特徴を取り入れたり、特定の領域を選択的に修正したりすることができます。
CIReVL: 学習不要の合成画像検索のための言語別ビジョン
ほとんどの構成画像検索(CIR)モデルは、注釈付きデータセットとタスクに特化したモデルトレーニングに依存しており、コストが高く、オーバーフィッティングを起こしやすい。つまり、学習分布と異なる画像が提示された場合、モデルの性能が低下する傾向がある。この問題は、入力の種類が膨大で予測不可能な実世界のアプリケーションで特に問題となる。大規模言語モデル(LLM)や視覚言語モデル(VLM)のような大規模モデルが開発されるにつれて、ゼロショット学習パラダイム、すなわちモデルが明示的に訓練されていないタスクを実行するパラダイムが大きな注目を集めている。CIReVLは、ゼロショットCIRモデルの顕著な例であり、追加のトレーニングを必要としないにもかかわらず、頑健な性能を達成しています。
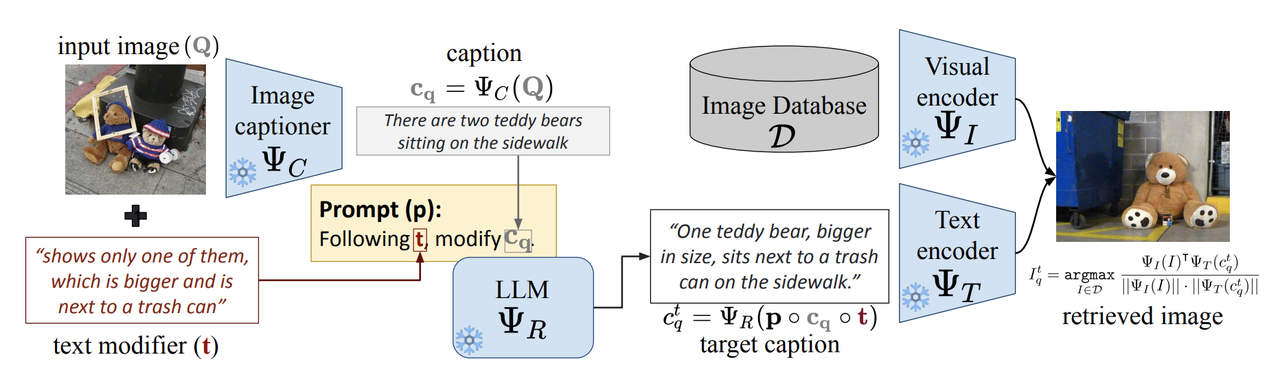 CIReVLの仕組み.png
CIReVLの仕組み.png
図:CIReVLの仕組み
具体的には、CIReVL(Compositional Image Retrieval through Vision-by-Language)は、VLMやLLMのような既存の学習済みモデルを活用した、学習不要の画像検索アプローチです。その目的は、クエリ画像とテキスト修飾子(例えば、"Eiffel Tower without people and at night "など)を組み合わせることで、データベースからターゲット画像を検索することである。CIReVLが際立っているのは、教師付き学習の必要性を完全にバイパスする能力であり、CIRタスクに対してより柔軟で効率的なソリューションを提供する。
CIReVLは3つの主要コンポーネントで構成され、それぞれが強力な汎化能力を持つ。第一に、視覚言語モデル(BLIP2など)が入力画像に対する説明的なキャプションを生成する。次に、大規模言語モデル(GPT-3.5やGPT-4など)が、提供されたテキスト指示(例えば、「人を削除し、時間を夜に変更する」など)に基づいてキャプションを修正する。最後に、修正されたキャプションは、CLIPのようなテキスト画像エンコーダを使用してテキスト埋め込みに変換され、その後、データベースから実際の画像検索を実行します。このプロセスは高度にモジュール化されており、純粋に言語領域で動作するため、より直感的な制御とユーザーの介入が可能である。この単純なパイプラインにより、CIReVLは拡張性と適応性を兼ね備えている。
MagicLens: オープンエンド命令による自己教師付き画像検索
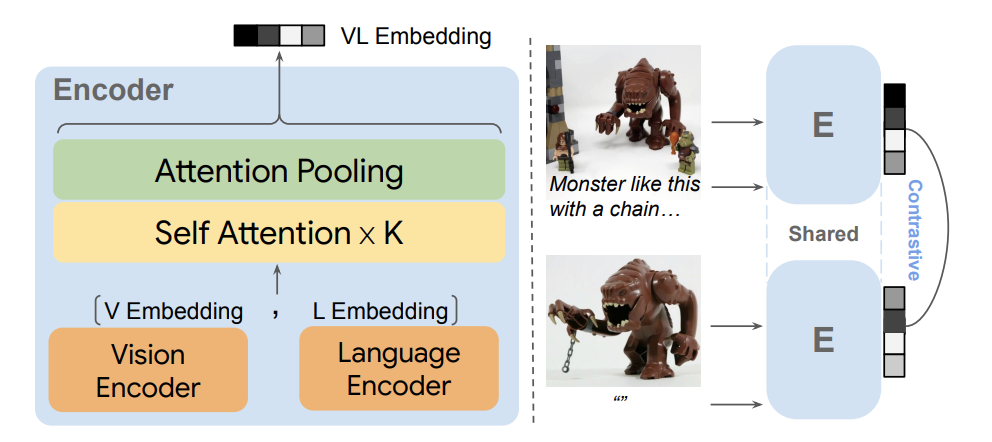
これまでの手法を振り返ってみると、合成画像検索(CIR)における最大の課題の1つは、様々なコンテキストでうまく汎化するモデルを学習するために、高品質な実世界のデータを収集し、注釈を付けることであることがわかります。モデルは複雑な画像関係を理解する必要があるが、この種のトレーニングに必要なデータは高価で入手が困難なことが多い。この問題に取り組むため、DeepMindとオハイオ州立大学の研究者は、オープンエンド命令を持つ自己教師付き画像検索モデルであるMagicLensを発表した。その中核となる革新性は、従来の視覚的類似性を超えて、より微妙な意味的関係に基づいて画像を検索する能力にある。
MagicLensは、CLIPやCoCaのような事前に訓練された視覚言語モデル(VLM)を、PaLM2のような大規模言語モデル(LLM)と一緒に構築します。この組み合わせにより、MagicLensは複雑な検索クエリを扱うことができ、ユーザが画像と柔軟なテキストプロンプト(例えば、「別の角度から」や「室内図」)を入力することで、視覚的コンテンツと意味的関係の両方に沿った画像を検索することができる。
このモデルは、同じウェブページの画像は、オブジェクトの異なるビューやオブジェクト間の相互作用のような暗黙の関係を共有することが多いという洞察を利用しています。MagicLens はウェブページからこのような画像ペアをマイニングし、それらを使用して、クエリ画像、テキスト命令、およびターゲット画像で構成される膨大な学習トリプレットのデータセットを生成します。これらのトリプレットはMagicLensの自己教師付き学習プロセスの基礎となり、モデルは提供された指示に基づいて画像をリンクすることを学習します。
 Magiclendsの仕組み.png
Magiclendsの仕組み.png
図:Magiclendsの仕組み
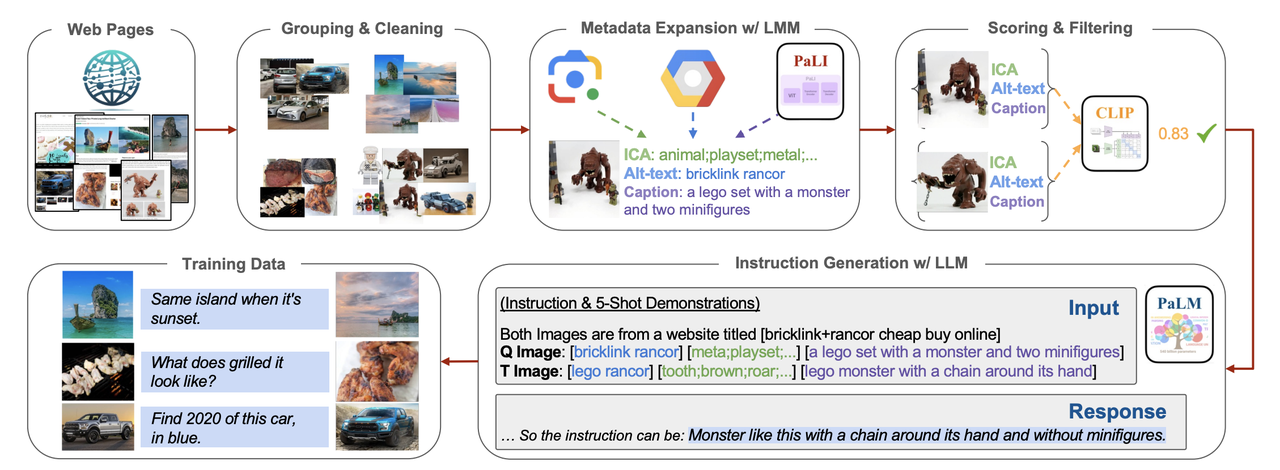
これらのトリプレットを収集し、キュレートするために、MagicLensは洗練されたデータパイプラインを採用している:
1.ウェブページ:ウェブページ**:画像は同じURLから収集されます。これにより、このモデルはコモンクロールから膨大な量のデータを収集することができます。
2.**グループ化とクリーニング収集された画像はURLごとにグループ化され、低解像度、重複、または無関係な(広告などの)画像を除去するためにフィルタリングされる。
3.メタデータの拡張:理解を深めるため、各画像にメタデータが生成される。このメタデータには以下が含まれる:
基本的なオブジェクト識別のためのICAラベル(Google Vision API経由で生成)。
Alt-text**(ウェブページからの代替テキスト説明)。
GoogleのPaLIモデルを使用して生成されたキャプション。
4.スコアリングとフィルタリング:CLIPの画像間およびテキスト間のスコアリングを使用して、MagicLensはさらに関連性の弱い画像ペアをフィルタリングし、高品質のペアのみが残るようにします。
5.インストラクション生成:ペア画像のメタデータに基づいて、GoogleのPaLM2は、クエリとターゲット画像間の関係を説明するオープンエンドのテキスト指示を生成します。
 データパイプライン.png
データパイプライン.png
図:データパイプライン
このパイプラインを通して、MagicLensは3,670万のトリプレット(参照画像、テキスト命令、ターゲット画像)からなるデータセットを生成し、モデル学習の基盤とします。この膨大なデータセットにより、MagicLensは手動によるアノテーションを必要とせずに効果的な学習を行うことができ、様々な検索タスクにおいてロバストなモデルを実現します。
合成画像検索(CIR)モデルの評価
合成画像検索(CIR)モデルのパフォーマンスを評価するために、FashionIQ、CIRR、CIRCOなどのいくつかのベンチマークデータセットが一般的に使用されています。これらのデータセットは、ファッション画像検索から自然画像検索まで様々な検索タスクをカバーしており、様々なドメインで異なるモデルを評価するのに理想的です。
FashionIQ**は、特定の衣服アイテム(ドレス、シャツなど)を含むタスクで、きめの細かいファッション画像検索に焦点を当てている。2005のクエリと5179のインデックス画像が含まれている。
CIRR**は実世界の画像に重点を置き、幅広い画像関係(空間的変化や構図変化など)をカバーしている。4148のクエリと2316のインデックス画像がある。
CIRCO**は120,000以上の自然画像を含む大規模なデータセットであり、各クエリは複数の正しいターゲット画像を持つことができる。
CIRベンチマークにおけるモデルのパフォーマンス
以下の表は、これらのデータセットにおけるいくつかの主要なCIRモデルのパフォーマンスを示しています。FashionIQとCIRRのRecall@10 (R@10)、CIRCOのMean Average Precision at 5 (mAP@5)など、様々な指標を用いてモデルを評価しています。これらの指標は、視覚入力とテキスト指示の組み合わせに基づいて、モデルがどの程度関連画像を検索できるかを評価する。
| ----------- | ----------- | ------- | ---------------- | --------- | ------------ | | ファッションIQ R@10、CIRR R@1、CIRCO mAP@5 | Pic2Word|CVPR2023|429M|24.7|23.9|8.7|。 | CVPRW2024|568M|36.0|18.2|12.6||コンポディフ
| MagicLens-L|ICML|2024|6.13M|38.0|33.3|34.1
**主な洞察
FashionIQ パフォーマンス:MagicLens-LはRecall@10で38.0と他のモデルを上回り、ファッション検索タスクにおける有効性を示している。CompoDiffは36.0と僅差で続き、ファッション関連のCIRにおける強さを示している。
CIRRパフォーマンス:MagicLens-LはCIRRでもリードしており、Recall@1で33.3と他のモデルを大きく上回っている。CIReVL**は24.6と堅実なパフォーマンスを示し、実世界の画像検索における能力を示している。
CIRCOパフォーマンスMagicLens-Lは大規模な自然画像検索タスクにおいても輝きを放ち、平均平均精度(mAP@5)は34.1と他のモデルを大きく引き離しています。これは複数の正しいターゲットを持つ複雑で大規模なデータセットを扱う際の強さを示しています。
全体として、MagicLens-Lは、CIReVLと比較してパラメータが少ないにもかかわらず、全てのデータセットで最高の一般的性能を示し、特にファッションと大規模自然画像検索の両タスクで優れている。
まとめ
この記事では、テキスト、画像、その他多くのデータタイプの検索を組み合わせることで、検索意図をより柔軟かつ正確に捉える方法を提供する、マルチモーダル検索手法の採用が増加していることについて検討した。この領域における一般的なタスクは、合成画像検索(CIR)であり、ユーザーは参照画像と組み合わせたテキスト記述を使用して画像検索を絞り込む。
我々は、Pic2Word、CompoDiff、CIReVL、MagicLensなど、CIRを推進する主要なモデルとテクニックを取り上げた。これらはそれぞれCLIPの基本的な機能をベースにしながら、検索を向上させるために異なるアプローチを採用している:
Pic2Word**は、テキストベースの検索に埋め込まれたテキストトークンに画像を変換し、CLIPのテキスト埋め込みを活用して、汎用性の高いテキスト駆動型の画像検索を実現します。
CompoDiff**は、テキスト誘導型ノイズ除去を採用しており、テキスト入力でノイズの多い視覚的埋め込みを精緻化し、画像埋め込みを条件付きで再構築することで、検索精度を向上させている。
CIReVL**は、ターゲット画像によりマッチするようにテキスト記述を修正し、新しい視覚的埋め込みを再生成する。
MagicLens**はTransformer modelsを使ってテキストと画像を並列に処理し、両方のモダリティを捕捉する統一された埋め込みを生成し、検索性能を向上させる。
マルチモーダル検索のデモをご覧ください!
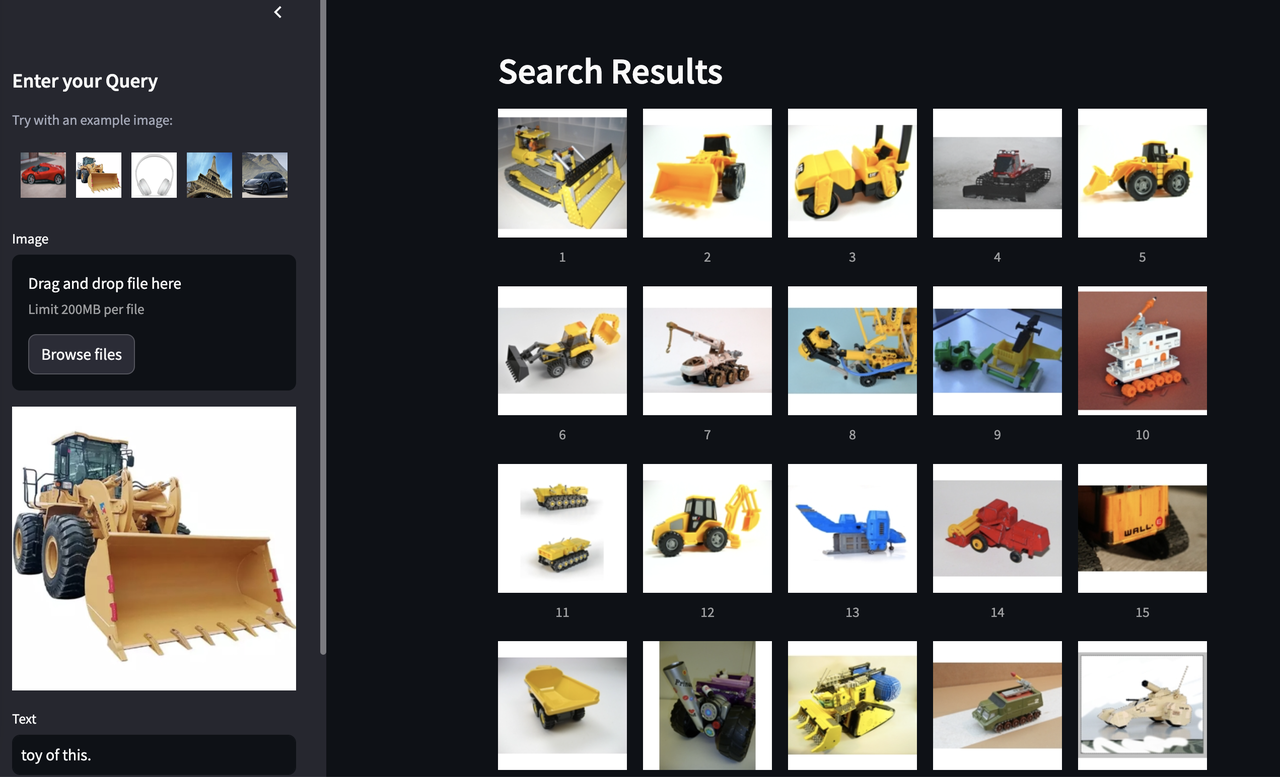
Milvusベクトルデータベース](https://milvus.io/intro)を利用したマルチモーダル検索のオンラインデモを開発しました。このデモでは、画像をアップロードしてテキストを入力すると、画像検索モデルによって処理され、視覚入力とテキスト入力の両方に基づいて一致する画像が検索されます。
このデモの中心は、MagicLens埋め込みモデルで、ユーザーの意図に従って検索結果を絞り込むために、GPT-4oベースの再ランキング・システムとともに動作する。この組み合わせは、マルチモーダルモデルがいかに現代の検索システムを変革し、より正確で直感的な検索体験を提供できるかを浮き彫りにしている。
マルチモーダル検索の未来を、ぜひ実際に体験してください!
 マルチモーダル検索モデルによる検索結果.png
マルチモーダル検索モデルによる検索結果.png
図:マルチモーダル検索モデルからの検索結果_。
デモで遊ぶマルチモーダル画像検索
ソースコードを確認するMilvusによるマルチモーダルRAG|Milvusドキュメント
その他のリソース
MagicLens GitHubページ:https://open-vision-language.github.io/MagicLens/
CIReVL GitHubページ:https://github.com/ExplainableML/Vision_by_Language
CompoDiff GitHub ページ:https://github.com/navervision/CompoDiff
Milvus のデモ:https://milvus.io/milvus-demos

読み続けて

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.