




LangChainとMilvusを使ったオープンソースチャットボットを5分以内に構築する
前回のブログでは、数分でMilvus接続を始める方法を説明しました。この投稿では、完全にオープンソースのRAG(Retrieval Augmented Generation)スタックとLangChainを使用し、私たちの製品ドキュメントのウェブページを使用してMilvusに関する質問にお答えします。
検索でオープンソースのQ&Aを使うことで、検索、評価、開発の繰り返しなど、ほとんどすべての時間、データを無料で呼び出すので、コストを節約できます。最終的なチャット生成ステップでOpenAIに有償で問い合わせをするのは一度だけです。
技術的な側面に興味がある方のために、live ChatBotのソースコードをGitHubで公開しています。このノートブックの完全なコードはbootcamp Git Hubにあります。
RAG(検索拡張生成)は、ground生成AIテキスト(幻覚を減らすために、生成テキストを事実に基づいたカスタムデータに基づかせる)に使用されます。製品ドキュメントのような、あなたが真実だと信じているカスタム・データからのテキストは、質問に答えるためにベクトル・データベースから検索される。そして、正確なテキスト回答の「文脈」を「質問」と一緒に「プロンプト」に挿入し、それをOpenAIのChatGPTのようなLLMに送り込む。LLMは、根拠ある人間のようなチャット回答を生成する。
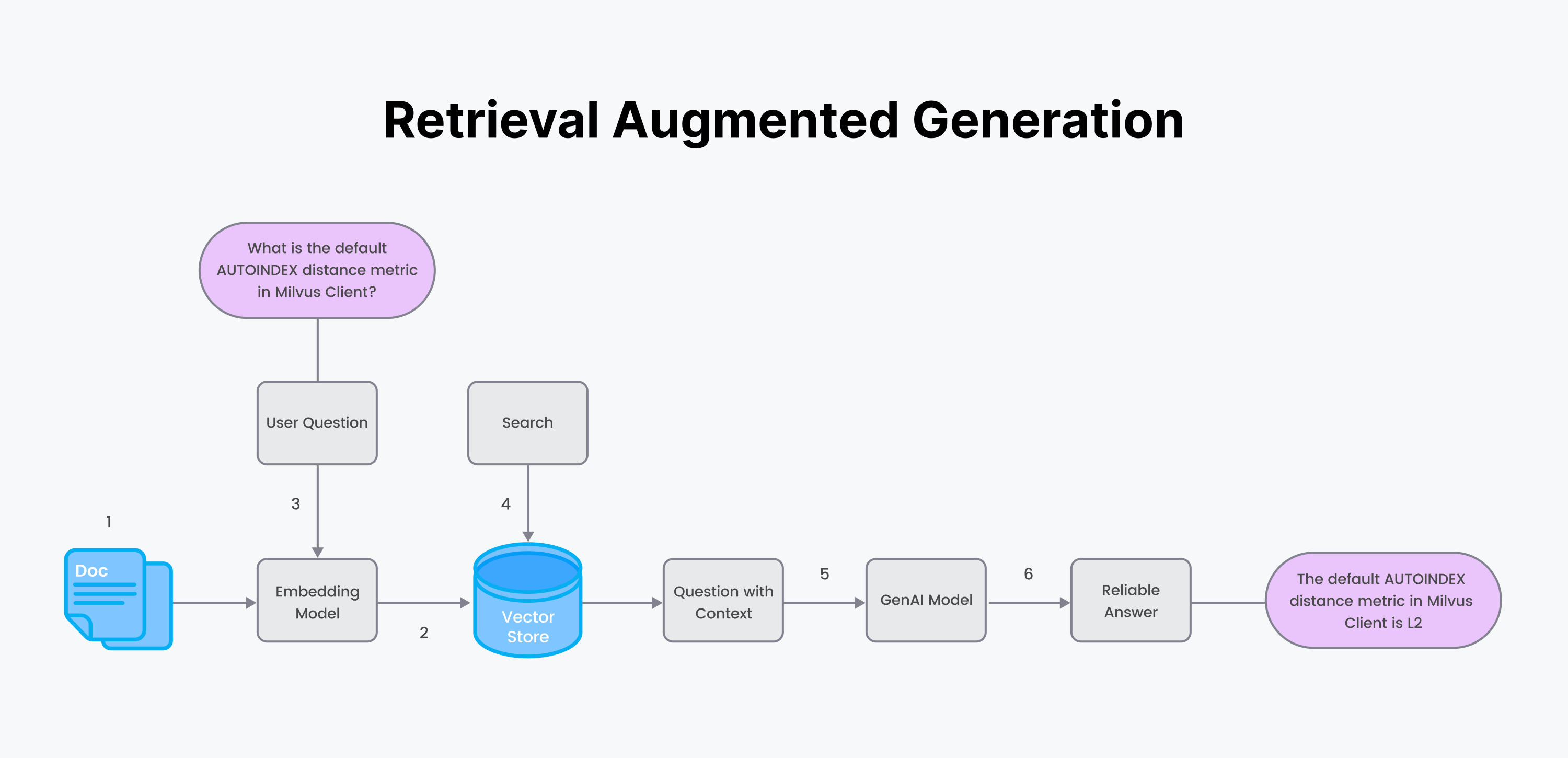
RAGプロセス:
1.真であると思われるカスタムデータと、エンコーダの埋め込みモデルから始めます。
2.2.エンコーダを使ってデータをチャンクし、エンベッディングを生成する。データとメタデータをベクトルデータベースに保存する。
3.ユーザーが質問をする。ステップ1と同じエンコーダを使用して、質問の埋め込みを生成する。
4.ベクトルデータベースを用いて意味検索を行うことで、質問に対する回答を取得する。
5.カスタムドキュメントのテキストの答えの塊を "コンテキスト "に詰め込む。質問とコンテキストをプロンプトに詰め込む。プロンプトを生成LLMに送る。
6.生成LLMから信頼できる答えを返す。
ステップ1:データの取り込み
Milvus**は高性能なベクトルデータベースで、カスタムの非構造化データの取り込みと埋め込みデータの作成を簡素化します。Milvusはエンベッディング(またはベクトル)の高速な保存、索引付け、検索のために最適化されています。
OpenAI**は、AIモデルとツールを開発・提供する組織である。GPT (Generative Pre-trained Transformer) シリーズのような最先端の言語モデルで知られています。
LangChainは、開発者が従来のソフトウェアとLLMのギャップを埋めるのを助けるツールとラッパーのライブラリです。
**ReadTheDocsは、オープンソースでフリーのソフトウェアドキュメンテーションのホスティングプラットフォームで、ドキュメンテーションはSphinxドキュメントジェネレータを使って書かれています。
さあ、始めましょう。
# ローカルにreadthedocsのページをダウンロードする。
DOCS_PAGE="https://pymilvus.readthedocs.io/en/latest/"
wget -r -A.html -P rtdocs --header="Accept-Charset:utf-8" $docs_page
上記のコードは、ウェブページをrtdocsというローカルディレクトリにダウンロードする。 次に、ドキュメントをLangChainに読み込む。
#pip install langchain
from langchain.document_loaders import ReadTheDocsLoader
loader = ReadTheDocsLoader(
"rtdocs/pymilvus.readthedocs.io/ja/latest/"、
features="html.parser")
docs = loader.load()
ステップ2:HTML階層を使ってデータを切り分ける
埋め込む前に、チャンク戦略、チャンクサイズ、チャンクの重なりを決める必要があります。このデモでは
戦略** = マークダウンのヘッダー階層を使う。長すぎない限り、マークダウンのセクションをまとめる。
チャンクサイズ** = 埋め込みモデルのパラメータ
MAX_SEQ_LENGTHを使用する。オーバーラップ** = ルールオブサム10-15%。
関数
マークダウン・セクションを分割するLangchainのHTMLHeaderTextSplitter。
長いレビューを再帰的に分割するLangchainのRecursiveCharacterTextSplitter。
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter
# HTMLHeaderTextSplitterで分割するヘッダを定義します。
headers_to_split_on = [
("h1", "ヘッダー1")、
("h2", "ヘッダー2"),] # HTMLHeaderTextSplitterのインスタンスを作成します。
# HTMLHeaderTextSplitterのインスタンスを作成する
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# 埋め込みモデルのパラメータを使う。
chunk_size = MAX_SEQ_LENGTH - HF_EOS_TOKEN_LENGTH
チャンクオーバーラップ = np.round(chunk_size * 0.10, 0)
# RecursiveCharacterTextSplitter のインスタンスを作成する。
child_splitter = RecursiveCharacterTextSplitter(
chunk_size = chunk_size、
chunk_overlap = chunk_overlap、
length_function = len,)
# HTMLHeaderTextSplitterを使ってHTMLテキストを分割します。
html_header_splits = [].
for doc in docs:
splits = html_splitter.split_text(doc.page_content)
for split in splits:
# ソースURLとヘッダー値をメタデータに追加する
メタデータ = {}.
new_text = split.page_content
for header_name, metadata_header_name in headers_to_split_on:
header_value = new_text.split("¶ ")[0].strip()
metadata[header_name] = header_value
を試す:
new_text = new_text.split("¶ ")[1].strip()
ただし
break
split.metadata = { **メタデータ
**メタデータ、
"source": doc.metadata["source"]} # ヘッダーをテキストに追加する。
# ヘッダーをテキストに追加する
split.page_content = split.page_content
html_header_splits.extend(splits)
# ドキュメントをさらに小さな、再帰的なチャンクに分割する。
chunks = child_splitter.split_documents(html_header_splits)
end_time = time.time()
print(f "chunking time: {end_time - start_time}")
print(f "docs:{len(docs)}、split into:{len(html_header_splits)}")。
print(f "チャンクに分割: {len(chunks)}, タイプ: {type(chunks[0])}のリスト")
# チャンクを検査する。
print()
print("チャンクのサンプルを見る...")
print(chunks[1].page_content[:100])
print(chunks[1].metadata)

各チャンクがドキュメント・ソースと一緒になっていることに注意してください。さらに、ヘッダーのタイトルはマークダウンテキストのチャンクと一緒に保持されます。これらのヘッダーは後でヘッダーセクション全体を取得するために使用することができます。
ステップ3:埋め込みを生成する
現在、ほとんどのデモはOpenAIのエンベッディングAPIを使っています。せっかくのカスタムデータなのですから、オープンソースの埋め込みモデルやfree-tierZilliz Cloudを使って、無料で好きなだけ自分のデータを検索してみてはいかがでしょうか?
最新のMTEBベンチマーク結果によると、オープンソースの埋め込み/検索モデルは、OpenAI Embeddings (ada-002)と同程度の性能を持っています。 以下では、最も小さい最高ランクのモデルがbge-large-en-v1.5であることがわかります。 このブログではこのモデルを使うことにする。
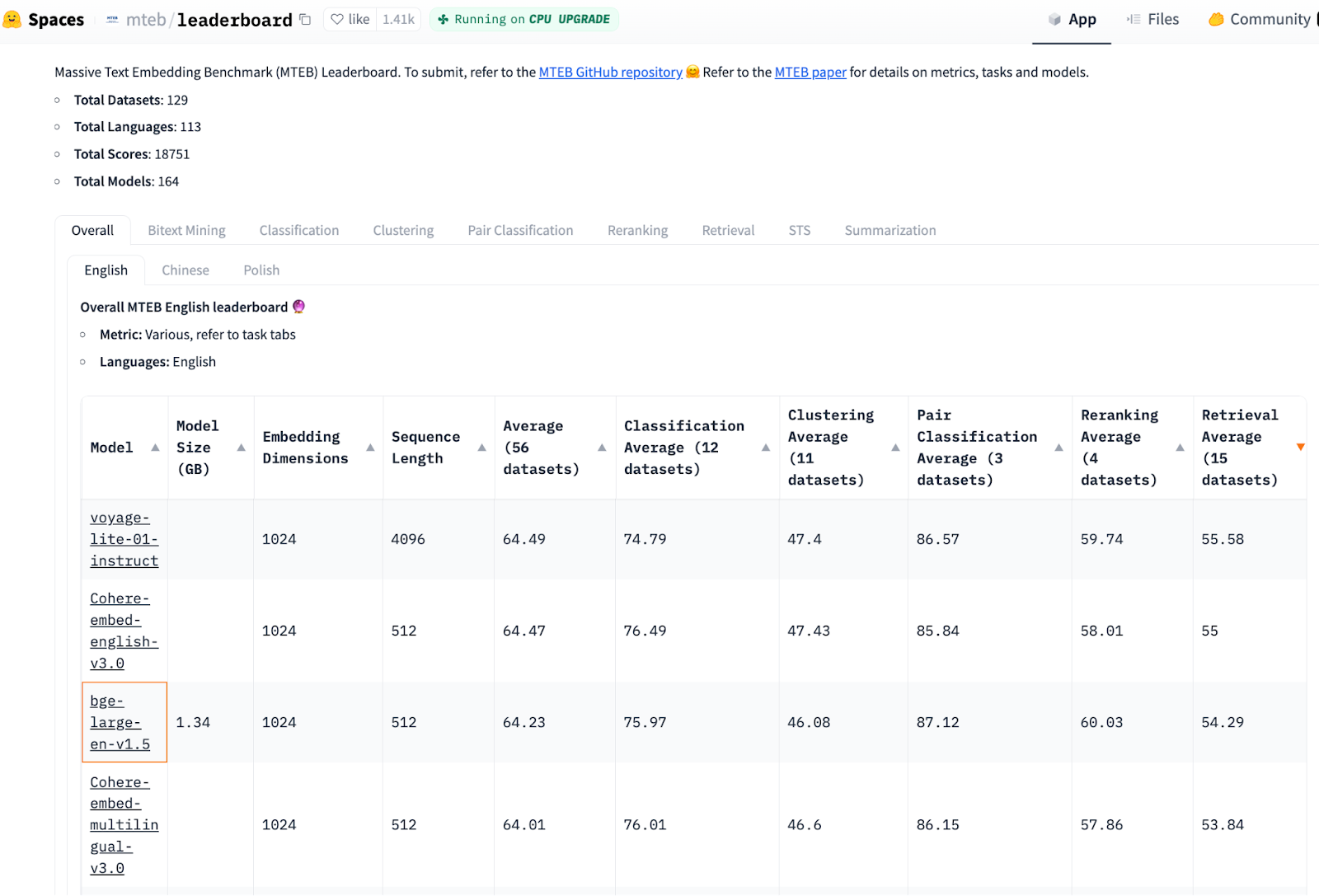
画像ソース:https://huggingface.co/spaces/mteb/leaderboard、列順、検索平均(15データセット)、2023年11月24日印刷。
上の画像は埋め込みモデルのリーダーボードで、トップは voyage-lite-01-instruct (サイズ 4.2GB)、3位は bge-base-en-v1.5 (サイズ 1.5GB)です。OpenAIEmbedding の text-embeddings-ada-002 は22位です(あまり下の方には表示されていません)。
以下では、選択された埋め込みモデルのチェックポイントを使ってエンコーダを初期化します。
#pip install torch, sentence-transformers
インポート torch
from sentence_transformers import SentenceTransformer
# トーチの設定を初期化する
DEVICE = torch.device('cuda:3')
if torch.cuda.is_available()
else 'cpu')
# huggingface model hubからエンコーダモデルをロードする。
モデル名 = "BAAI/bge-base-en-v1.5"
エンコーダー = SentenceTransformer(model_name, device=DEVICE)
# モデルのパラメータを取得し、後のために保存する。
MAX_SEQ_LENGTH = encoder.get_max_seq_length()
EMBEDDING_LENGTH = encoder.get_sentence_embedding_dimension()
ここで、HuggingFaceチェックポイントから初期化したエンコーダを使って埋め込みを生成します。すべてのデータを辞書のリストにまとめます。
chunk_list = [].
for chunk in chunks:
# HuggingFace のエンコーダを使って埋め込みデータを生成する。
embeddings = torch.tensor(encoder.encode([chunk.page_content]))
embeddings = F.normalize(embeddings, p=2, dim=1)
converted_values = list(map(np.float32, embeddings))[0] # 埋め込みベクトルを組み立てる。
# 埋め込みベクトル、元のテキストチャンク、メタデータを組み立てる。
chunk_dict = { {'vector': converted_values
'vector': converted_values、
'text': chunk.page_content、
'source': chunk.metadata['source']、
'h1': chunk.metadata['h1'][:50]、
'h2': chunk.metadata['h1'][:50],}.
chunk_list.append(chunk_dict)
ステップ4:Milvusインデックスの作成とデータの挿入
このステップでは、元のテキストチャンクごとに四則演算(vector, text, source, h1, h2)をデータベースに書き込みます。
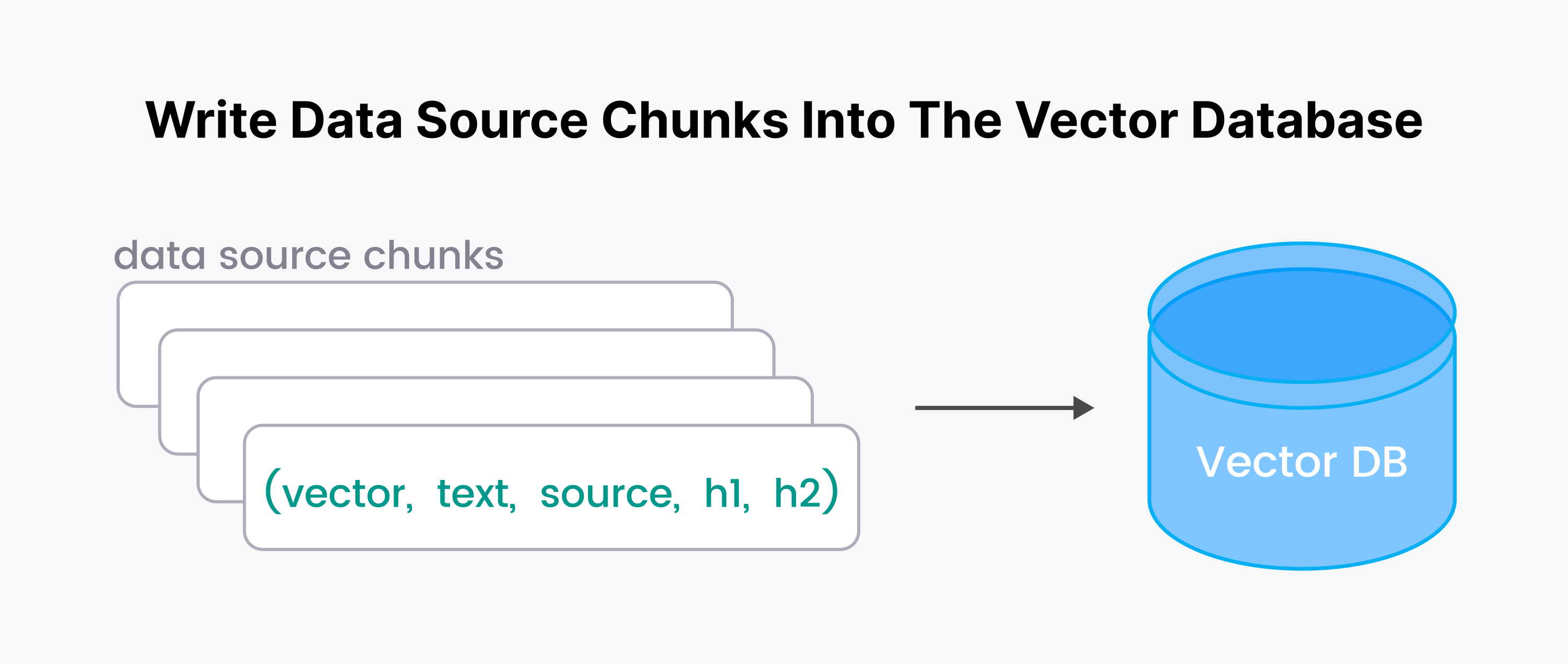
Milvusサーバーを起動して接続してみよう。サーバーレスクラウドホストのMilvusを使うには、ZILLIZ_API_KEYが必要だ。 前回のブログ【Milvusに接続する】(https://zilliz.com/blog/getting-started-with-a-milvus-connection)では、Zillizへの接続方法を紹介しました。
#pip install pymilvus
from pymilvus import connections
ENDPOINT="https://xxxx.api.region.zillizcloud.com:443"
connections.connect(
uri=ENDPOINT、
token=TOKEN)
MilvusDocs`というMilvusコレクションを作成する。 コレクションはスキーマとインデックスを取る。スキーマはエンコーダモデルの埋め込み長を使用する。
from pymilvus import (
FieldSchema, DataType、
コレクションスキーマ, コレクション)
# 1.最小限の拡張可能なスキーマを定義する。
fields = [
FieldSchema("pk", DataType.INT64, is_primary=True, auto_id=True)、
フィールドスキーマ("vector", DataType.FLOAT_VECTOR, dim=768),].
schema = CollectionSchema(
fields、
enable_dynamic_field=True,)
# 2.コレクションを作成する。
mc = Collection("MilvusDocs", schema)
# 3.コレクションにインデックスを付ける。
mc.create_index(
フィールド名="vector"、
index_params={
"index_type":"AUTOINDEX"、
"metric_type":"COSINE",}
Pinecone](https://zilliz.com/comparison/pinecone-vs-zilliz-vs-milvus)と異なり、Milvus/Zillizではすべてのデータの挿入と埋め込みインデックスの作成が高速です!
# データをMilvusコレクションに挿入する。
insert_result = mc.insert(chunk_list)
# 最後のエンティティが挿入された後、フラッシュを呼び出す。
# メモリに残っているセグメントの成長を停止する。
mc.flush()
print(mc.partitions)

ステップ5:ドキュメントについて質問する
セマンティック検索](https://zilliz.com/glossary/semantic-search) セマンティック検索は、ユーザーの質問に答える最も近いマッチングドキュメントを見つけるために、ベクトル空間で最近傍のテクニックを使用します。セマンティック検索は、単なるキーワードのマッチングではなく、質問や文書の背後にある意味を理解することを目的としている。**検索中、Milvusは検索体験を向上させるためにメタデータを利用することもできる(Milvus APIオプションのexpr=でブール式を使用する)。
# データに関する質問例を定義します。
QUESTION = "AUTOINDEXで使用されるデフォルトの距離メトリックは何ですか?"
QUERY = [質問].
# 検索を行う前に、データをメモリにロードする。
mc.load()
# 同じエンコーダを使って質問を埋め込む。
embedded_question = torch.tensor(encoder.encode([QUESTION])) # 質問を埋め込む。
# エンベッディングを単位長に正規化する。
embedded_question = F.normalize(embedded_question, p=2, dim=1) # 埋め込みを単位長さに正規化。
# 埋め込みをnp.float32のリストに変換。
embedded_question = list(map(np.float32, embedded_question))
# AUTOINDEXで上位k個の結果を返す。
TOP_K = 5
# クエリとベクトルデータベースを使ってセマンティックベクトル検索を実行する。
start_time = time.time()
results = mc.search(
data=embedded_question、
anns_field="vector"、
# AUTOINDEXのパラメータはありません。
param={}、
# もしあればブール式
expr=""、
output_fields=["h1", "h2", "text", "source"]、
limit=TOP_K、
consistency_level="Eventually")
elapsed_time = time.time() - start_time
print(f "Milvus search time: {elapsed_time} sec")

以下では、何が検索されたかを簡単に見てみよう。 そして、すべてのテキストを context フィールドに詰め込む。
for n, hits in enumerate(results):
print(f"{n}th query result")
for hit in hits:
print(hit)
# コンテキストを詰め文字列として組み立てる。
context = ""
for r in results[0]:
text = r.entity.text
コンテキスト += f"{text}"
# 答えと一緒に取得するコンテキストメタデータも保存します。
コンテキストメタデータ = {
"h1": results[0][0].entity.h1、
"h2": results[0][0].entity.h2、
"source": results[0][0].entity.source,}.

上記で、確かに5つのチャンクのテキストが検索されたことがわかります。特に、最初のチャンクにはデフォルトメトリックに関する質問の答えが含まれている。 **MilvusのAPIオプションである output_fields= を使って検索しているため、チャンクと一緒にソースと引用のメタデータも取得されている。
id:445766022949255988, distance:0.708217978477478, entity:{
'chunk':"...#オプション、デフォルトはMetricType.L2 } timeout (float) - 秒単位で指定します。
RPCの実行時間を秒単位で指定します。
RPC を実行します。...",
'source': 'https://pymilvus.readthedocs.io/en/latest/api.html'、
'h1': 'API reference'、
'h2': 'クライアント'}.
ステップ6: LLMを使って、取得したコンテキストを使ってユーザーの質問に対するチャットのレスポンスを生成する
HuggingFaceで公開されている、オープンでとても小さな生成AIモデル、つまりLLMを使います。
#pipでtransformersをインストールする
from transformers import AutoTokenizer, pipeline
tiny_llm = "deepset/tinyroberta-squad2"
tokenizer = AutoTokenizer.from_pretrained(tiny_llm)
# コンテキストを空にすることはできないので、ランダムなテキストを入れる。
QA_input = {
'question': 質問、
'context': 'The quick brown fox jumped over the lazy dog' }.
nlp = pipeline('question-answering'、
model=tiny_llm、
tokenizer=tokenizer)
result = nlp(QA_input)
print(f "質問: {question}")
print(f "答え:{result['answer']}")

答えはあまり役に立ちませんでした! では、取得したコンテキストを使って同じ質問をしてみましょう。
QA_input = {
'question': 質問、
'context': context,}
nlp = pipeline('question-answering'、
model=tiny_llm、
tokenizer=tokenizer)
result = nlp(QA_input)
# 質問、回答、根拠となるソース、引用を表示する。
答え = assemble_grounding_sources(result['answer'], context_metadata)
print(f "Question: {question}")
print(answer)

この答えは少し良さそうだ! オープンソースのLLMを使って、自分たちのデータを無料で検索する練習をしました。 **今度は、OpenAI GPTを有料で使ってみましょう。 単純なオープンソースのLLMと同じ答えを期待しますが、より人間に近くなります。
def prepare_response(response):
return response["choices"][-1]["message"]["content"]
def generate_response(
llm、
温度=0.0, #再現性のある実験のための0
grounding_sources=None、
system_content="", assistant_content="", user_content=""):
response = openai.ChatCompletion.create(
model=llm、
temperature=temperature、
api_key=openai.api_key、
messages=[
{"role":"system", "content": system_content}、
{"role":「assistant", "content": assistant_content}、
{"role":"user", "content": user_content}, ])
answer = prepare_response(response=response)
# グラウンディングソースと引用を追加する
answer = assemble_grounding_sources(answer, grounding_sources)
return answer
# レスポンスを生成する
response = generate_response(
llm="gpt-3.5-turbo-1106",
temperature=0.0、
grounding_sources=context_metadata、
system_content="提供されたコンテキストを使って質問に答えてください。簡潔に、
user_content=f "質問:質問: {質問}, コンテキスト:{コンテキスト}")
# 質問、回答、根拠となるソース、引用を表示します。
print(f "質問: {QUESTION}")
print(レスポンス)

要約
カスタムドキュメントを使ったRAG検索と質問応答チャットボットのデモを最初から最後まで行った。私たちは、無料で自分のデータを使って検索し、質問に答えることで、いかに簡単に反復できるかを見た。これはLangChain、Milvus、そしてエンコーダとチャット生成のためのオープンソースのLLMで可能でした。検索中、Milvusはソースと引用を提供した(データロード中にメタデータにこれらのフィールドを追加し、API検索コールで'output_fields='を使用するだけ)。最後に、私たちは、検索、評価、開発の繰り返しなど、ほとんど常にデータへの無料コールを行っているため、このアプローチでコストを節約できることがわかりました。最終的なチャット生成ステップでは、OpenAIへの有料コールを一度だけ行います。
MilvusとZillizを始めるためのその他のリソース
ベクターデータベース101ブログシリーズ](https://zilliz.com/learn/what-is-vector-database)
あなたのユースケースに適したベクターデータベースを見つけるためのベンチマーク](https://zilliz.com/learn/open-source-vector-database-benchmarking-your-way)
Zilliz統合ハブ](https://zilliz.com/product/integrations)
GPTCacheを使った100倍速いレスポンスとコスト削減](https://zilliz.com/blog/building-llm-apps-100x-faster-responses-drastic-cost-reduction-using-gptcache)
NVIDIA MerlinとMilvusを使用したレコメンダーワークフロー](https://zilliz.com/blog/efficient-vector-similarity-search-recommender-workflows-using-milvus-nvidia-merlin)
リアルタイムAIのためのKafkaコネクタ](https://zilliz.com/blog/announce-confluent-kafka-connector-for-Milvus-and-Zilliz-unlock-power-of-real-time-ai)

読み続けて

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.