




Neo4jとMilvusによるGraphRAGエージェントの構築
このブログは元々Neo4jに投稿されたもので、許可を得てここに再投稿した。
概要
このブログポストでは、Neo4jグラフデータベースとMilvusベクトルデータベースを使って、GraphRAGエージェントを構築する方法を詳細に説明します。このエージェントは、グラフデータベースとベクトル検索のパワーを組み合わせ、ユーザのクエリに対して正確で適切な回答を提供する。この例では、LangGraph, Llama 3.1 8B with Ollama and GPT-4oを使います。
従来の検索拡張生成(RAG)システムは、関連文書を検索するためにベクトルデータベースにのみ依存している。我々のアプローチは、Neo4jを取り入れることで、さらに進化し、エンティティや概念間の関係を捉え、情報のより微妙な理解を提供する。我々は、これら2つの技術を組み合わせることで、より強固で情報量の多いRAGシステムを作りたいと考えている。
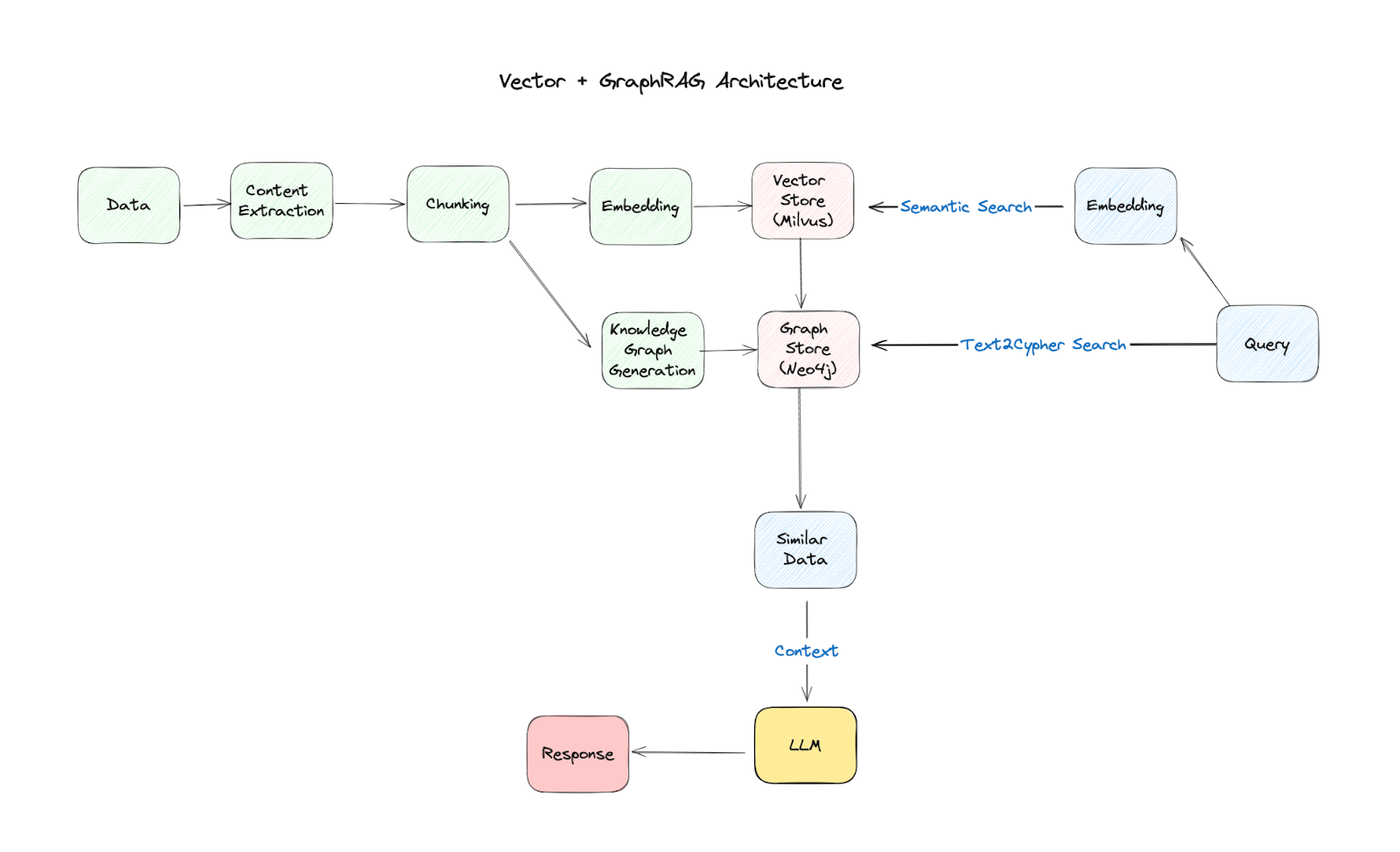
RAG エージェントの構築
我々のエージェントは、ルーティング、フォールバックメカニズム、自己修正という3つのキーコンセプトに従っています。これらの原則は一連のLangGraphコンポーネントを通して実装されています:
ルーティング** - 専用のルーティングメカニズムが、クエリに基づいてベクトルデータベース、ナレッジグラフ、またはその両方を組み合わせて使用するかを決定します。
フォールバック** - 最初の検索が不十分な場合、エージェントはTavilyを使ったウェブ検索にフォールバックします。
自己修正** - エージェントは自身の答えを評価し、幻覚や不正確さを修正しようとします。
その他、以下のようなコンポーネントがあります:
検索** - オープンソースで高性能なベクトルデータベースであるMilvusを使用し、ユーザのクエリに対する意味的類似性に基づいて、ドキュメントチャンクを保存し、検索する。
グラフの強化** - Neo4jは、検索されたドキュメントから知識グラフを構築するために使用され、関係やエンティティでコンテキストを豊かにする。
LLMの統合** - ローカルLLMであるLlama 3.1 8Bは、回答を生成し、検索された情報の関連性と正確性を評価するために使用され、GPT-4oは、Neo4jによって使用されるクエリ言語であるCypherを生成するために使用される。
GraphRAG アーキテクチャ
我々のGraphRAGエージェントのアーキテクチャは、いくつかのノードが相互に接続されたワークフローとして可視化することができる:
質問ルーティング** - エージェントはまず、最適な検索戦略(ベクトル検索、グラフ検索、またはその両方)を決定するために質問を分析する。
検索** - ルーティングの決定に基づいて、関連ドキュメントがMilvusから検索されるか、情報がNeo4jグラフから抽出されます。
生成** - LLMは検索されたコンテキストを使って回答を生成します。
評価** - エージェントは生成された答えの関連性、正確性、幻覚の可能性を評価する。
洗練** (必要な場合) - 答えが不満足と判断された場合、エージェントは検索を洗練させるか、エラーを修正しようとするかもしれない。
エージェントの例
LLMエージェントの機能を紹介するために、2つの異なるコンポーネントを見てみましょう:グラフ生成と 複合エージェント` です。
完全なコードはこの投稿の一番下にありますが、これらのスニペットはこれらのエージェントがLangChainフレームワークの中でどのように動作するかをより良く理解するのに役立つでしょう。
グラフ生成
このコンポーネントは、Neo4jの機能を使用することで、質問回答プロセスを改善するように設計されています。Neo4jグラフ・データベースに埋め込まれた知識を活用することで、質問に回答します。以下はその仕組みです:
1. GraphCypherQAChain` - LLMがNeo4jグラフデータベースとやりとりできるようにする。LLMを2つの方法で使用する:
cypher_llm` - LLMのこのインスタンスは、ユーザーの質問に基づいてグラフから関連情報を抽出するCypherクエリを生成する。
バリデーション** - Cypherクエリが構文的に正しいかどうかのバリデーションを行う。
2.Context retrieval - 検証されたクエリは、必要なコンテキストを取得するためにNeo4jグラフ上で実行される。
3.回答生成 - 言語モデルは、取得されたコンテキストを使用して、ユーザの質問に対する回答を生成する。
### サイファークエリーの生成
llm = ChatOllama(model=local_llm, temperature=0)
# チェーン
graph_rag_chain = GraphCypherQAChain.from_llm(
cypher_llm=llm、
qa_llm=llm、
validate_cypher=True、
graph=graph、
verbose=True、
return_intermediate_steps=True、
return_direct=True、
)
# 実行
question = "エージェントのメモリ"
generation = graph_rag_chain.invoke({"query": question})
このコンポーネントは、RAGシステムがNeo4jを利用することを可能にし、より包括的で正確な回答を提供するのに役立ちます。
複合エージェント、グラフ、ベクトル
ここでマジックが起こる:我々のエージェントはMilvusとNeo4jの結果を組み合わせることができ、情報をより良く理解し、より正確でニュアンスのある答えを導くことができます。その仕組みは以下の通りです:
1.プロンプト - LLMが質問に答えるためにMilvusとNeo4jの両方のコンテキストを使うように指示するプロンプトを定義します。
2.検索 - エージェントは、Milvus(ベクトル検索を使用)とNeo4j(グラフ生成を使用)から関連情報を検索する。
3.回答生成 - Llama 3.1 8Bは、プロンプトを処理し、ベクトルデータベースとグラフデータベースからの複合連鎖を利用した簡潔な回答を生成する。
### 複合ベクトル+グラフ生成
cypher_prompt = PromptTemplate(
template="""あなたはNeo4jのCypherクエリを生成するエキスパートです。
次のスキーマを使用して、与えられた質問に答えるCypherクエリを生成してください。
大文字と小文字を区別しないマッチングと、適切な場合には部分的な文字列マッチングを使用して、クエリを柔軟にしてください。
論文のタイトルは、最も関連性の高い情報を含んでいるので、重点的に検索してください。
スキーマ
{スキーマ}
質問{質問}
Cypherクエリ:""、
input_variables=["schema", "question"]、
)
# QAプロンプト
qa_prompt = PromptTemplate(
template="""あなたは質問応答タスクのアシスタントです。
以下のCypherのクエリ結果を使って質問に答えてください。答えがわからない場合は、わからないと答えてください。
回答は3文以内で簡潔に。トピック情報がない場合は、論文タイトルに注目する。
質問質問
サイファー・クエリー{クエリー}
クエリの結果{コンテキスト}。
回答:""、
input_variables=["question", "query", "context"]、
)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# チェーン
graph_rag_chain = GraphCypherQAChain.from_llm(
cypher_llm=llm、
qa_llm=llm、
validate_cypher=True、
graph=graph、
verbose=True、
return_intermediate_steps=True、
return_direct=True、
cypher_prompt=cypher_prompt、
qa_prompt=qa_prompt、
)
グラフ・データベースとベクトル・データベースの長所を組み合わせて、研究論文の発見を強化した検索結果を見てみよう。
まずはNeo4jを使ったグラフ検索から:
# 入力データの例
question = "マルチエージェントについて述べている論文は?"
generation = graph_rag_chain.invoke({"query": question})
print(generation)
> 新しいGraphCypherQAChainチェーンに入る...
生成されたサイファー:
サイファー
MATCH (p:Paper)
WHERE toLower(p.title) CONTAINS toLower("Multi-Agent")
RETURN p.title AS PaperTitle, p.summary AS Summary, p.url AS URL
> チェーンが終了しました。
{'query': 'マルチエージェントについて述べている論文は?', 'result':[{'PaperTitle':'Collaborative Multi-Agent, Multi-Reasoning-Path (CoMM) Prompting Framework', 'Summary': 'この研究では、協調的マルチエージェント、マルチ推論パス(CoMM)プロンプトフレームワークを提案することにより、LLMの推論能力の上限を押し上げることを目的とする。具体的には、LLMが問題解決チーム内で異なる役割を演じるように促し、異なる役割を演じるエージェントが目標タスクを協調的に解決するように促す。特に、異なる役割に対して異なる推論経路を適用することが、マルチエージェントシナリオにおいて数発のプロンプティングアプローチを実装するための効果的な戦略であることを発見した。また、大学レベルの2つの科学問題において、提案手法の有効性が実証された。我々の更なる分析は、LLMが異なる役割や専門家を独立して演じることを促す必要性を示している。', 'URL': 'https://github.com/amazon-science/comm-prompt'}].
グラフ検索は、関係やメタデータを見つけることに優れている。タイトル、著者、定義済みのカテゴリーに基づいて論文を素早く特定し、データの構造化されたビューを提供することができる。
次に、別の視点からベクトル検索に目を向ける:
# 入力データの例
question = "マルチエージェントについて述べている論文は?"
# ベクトル+グラフの回答を得る
docs = retriever.invoke(質問)
vector_context = rag_chain.invoke({"context": docs, "question": question})
> この論文では、「言語モデルエージェントのための適応的な会話内チームビルディング」について議論し、マルチエージェントについて述べている。この論文では、複雑なタスクを効果的に解決するためのLLMエージェントのチームを構築するための柔軟なソリューションを提供する、新しい適応的チーム構築パラダイムを提示している。キャプテン・エージェントと呼ばれるこのアプローチは、タスク解決プロセスの各ステップごとにチームを動的に形成・管理し、ネスト化されたグループ会話とリフレクションを活用して、多様な専門知識を確保し、ステレオタイプなアウトプットを防止する。
ベクトル検索は、文脈と意味的類似性を理解するのに非常に優れている。検索語が明示的に含まれていなくても、クエリと概念的に関連する論文を発見することができる。
最後に、両方の検索方法を組み合わせる:
これは我々のRAGエージェントの重要な部分であり、ベクトルデータベースとグラフデータベースの両方を使用することを可能にしている。
composite_chain = prompt | llm | StrOutputParser()
answer = composite_chain.invoke({"question": question, "context": vector_context, "graph_context": graph_context})
print(answer)
> 論文 "Collaborative Multi-Agent, Multi-Reasoning-Path (CoMM) Prompting Framework "はマルチエージェントについて述べている。この論文では、LLMが問題解決チームの中で異なる役割を果たすことを促し、異なる役割プレイエージェントがターゲットタスクを協調的に解決することを促すフレームワークを提案している。本論文では、大学レベルの2つの科学問題において、提案手法の有効性を実証した結果を示す。
グラフ検索とベクトル検索を統合することで、両アプローチの長所を活用している。グラフ検索は正確さを提供し、構造化された関係をナビゲートする一方、ベクトル検索は意味理解を通して深みを加える。
この統合された手法にはいくつかの利点がある:
1.リコールの向上:どちらかの方法だけでは見逃される可能性のある関連論文を発見できる。
2.文脈の強化:論文同士の関連性をより深く理解することができます。
3.柔軟性:特定のキーワード検索から、より広い概念の探求まで、様々なタイプのクエリに適応できる。
まとめ
このブログポストでは、Neo4jとMilvusを使ってGraphRAGエージェントを構築する方法を紹介した。グラフデータベースとベクトル検索の強みを組み合わせることで、このエージェントはユーザのクエリに対して正確で適切な回答を提供します。
我々のRAGエージェントのアーキテクチャは、専用のルーティング、フォールバックメカニズム、自己修正機能により、堅牢で信頼性の高いものとなっている。グラフ生成と複合エージェントのコンポーネントの例は、このエージェントが包括的でニュアンスのある回答を提供するために、ベクトルとグラフの両方のデータベースを利用できることを示しています。
このガイドがお役に立ち、ご自身のプロジェクトでグラフデータベースとベクトル検索を組み合わせる可能性をチェックするきっかけになれば幸いです。
現在のコードはGitHubにあります。
フォローする
 Stephen Batifol
Stephen BatifolStephen Batifol is a Developer Advocate at Zilliz. He previously worked as a Machine Learning Engineer at Wolt, where he was working on the ML Platform and as a Data Scientist at Brevo. Stephen studied Computer Science and Artificial Intelligence. He enjoys dancing and surfing.
 Jason Koo
Jason KooJason Koo is a Developer Advocate at Neo4j
読み続けて

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.