




Comprendere l'intelligenza artificiale multimodale
Comprendere l'intelligenza artificiale multimodale
Il lancio di ChatGPT e di molti altri modelli linguistici di grandi dimensioni (LLMs ha segnato una tappa fondamentale nello sviluppo dell'IA. In questo periodo, i modelli di IA sono passati da applicazioni di nicchia a usi quotidiani come la scrittura, la codifica, il servizio clienti e la creazione di contenuti. Tuttavia, molti di questi progressi erano limitati a un'unica modalità: il testo.
Concentrarsi su una sola modalità non è sufficiente per realizzare la visione dell'intelligenza artificiale generale (AGI). Per sua stessa definizione, l'AGI richiede la capacità di comprendere, ragionare e agire in più domini, dal linguaggio e dalla visione agli input uditivi e sensoriali. Per questo motivo è nata la multimodalità; questo articolo vi guiderà attraverso questa tecnica.
Che cos'è l'intelligenza artificiale multimodale?
I sistemi di intelligenza artificiale sono multimodali se elaborano e analizzano informazioni provenienti da più modalità, come testo, immagini, audio e video. L'intelligenza artificiale che può elaborare solo un tipo di modalità è invece unimodale.
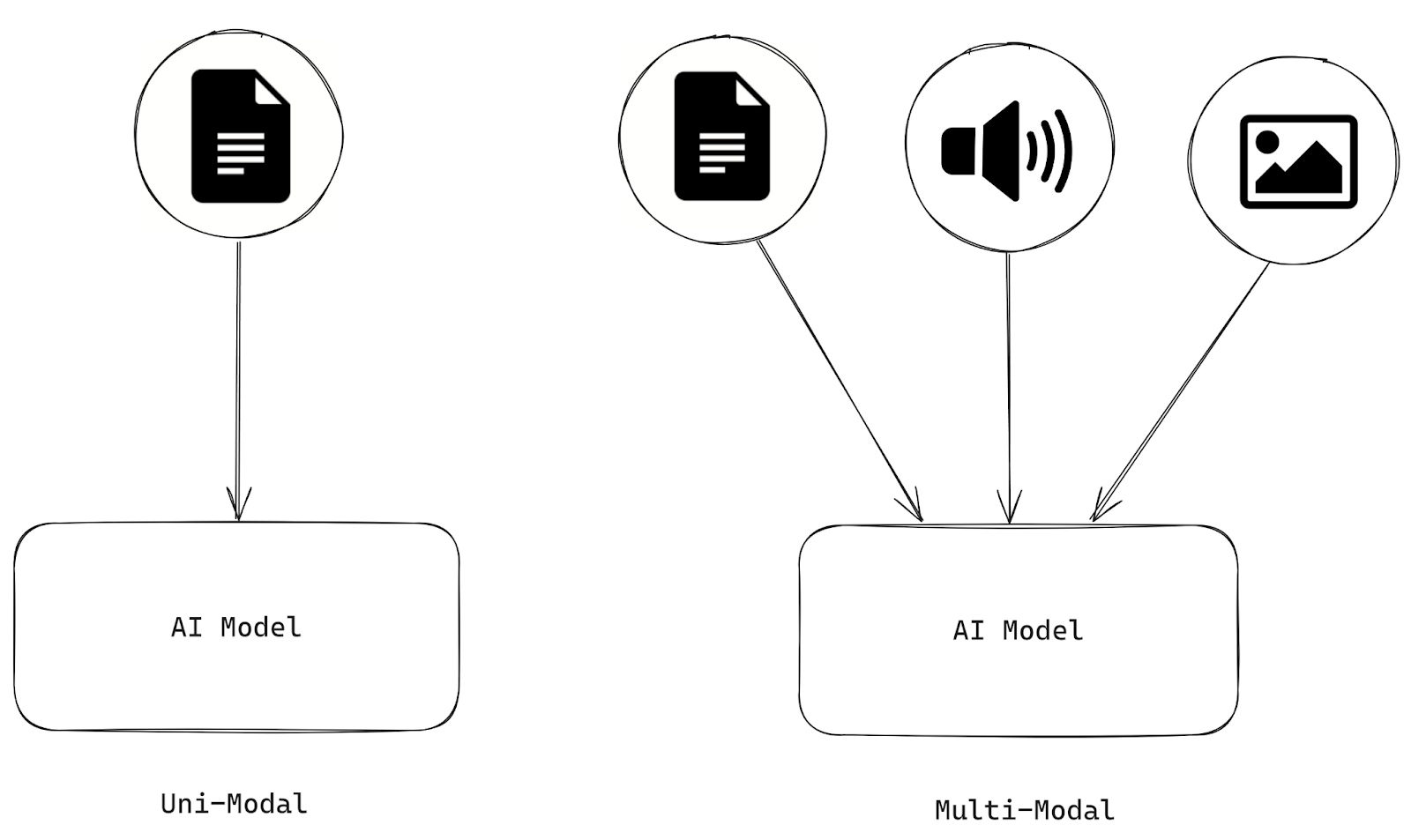 Figura 1- Differenze tra IA unimodale e multimodale.png
Figura 1- Differenze tra IA unimodale e multimodale.png
Figura 1: Differenze tra IA unimodale e multimodale
È importante chiarire la distinzione tra due termini spesso confusi: multimodale e multimodale. Multimodale si riferisce a sistemi che integrano ed elaborano informazioni provenienti da più tipi di dati. Al contrario, multimodello descrive l'uso di più modelli indipendenti che lavorano in parallelo o in combinazione per svolgere un compito. Questi modelli possono operare sugli stessi tipi di dati o su tipi diversi, ma rimangono separati piuttosto che integrati.
L'IA multimodale può avere un impatto significativo su molte applicazioni. Ad esempio, un sistema sanitario di IA multimodale può utilizzare immagini mediche, registrazioni vocali dei pazienti e note cliniche per costruire una diagnosi più precisa di quella che potrebbe essere prodotta da un sistema che si basa solo su una fonte di dati. In questo senso, i sistemi di IA multimodali si avvicinano molto di più alla cognizione umana e sono molto efficaci in compiti che richiedono una comprensione globale.
La multimodalità può essere una o più delle seguenti:
L'input e l'output sono in modalità diverse, ad esempio da testo a immagine o da immagine a testo.
Gli input sono multimodali (ad esempio, testo e immagini).
Gli output sono multimodali, ad esempio un sistema che fornisce testo e immagini.
Nella sezione che segue verrà illustrato il funzionamento dei sistemi multimodali.
Come funziona l'intelligenza artificiale multimodale?
Diversi componenti lavorano insieme in un modello multimodale. Ecco gli elementi più importanti e il loro funzionamento:
Tipi di dati: L'intelligenza artificiale multimodale integra diversi tipi di dati, tra cui testo, immagini, audio e video, consentendo una comprensione completa e la generazione di contenuti attraverso diverse modalità.
Rappresentazione: Le rappresentazioni multimodali nell'apprendimento automatico combinano i dati di diverse modalità in caratteristiche più significative che i modelli possono utilizzare. Per ottenere questo risultato si utilizzano due approcci diversi.
Rappresentazioni congiunte: I dati provenienti da diverse modalità vengono trasformati in uno spazio di rappresentazione unificato, adatto quando sono disponibili dati multimodali durante l'addestramento e l'inferenza. Le tecniche standard includono le reti neurali e i modelli grafici probabilistici. Sebbene questi metodi possano migliorare le prestazioni, devono affrontare problemi con i dati mancanti.
Rappresentazioni coordinate: Ogni modalità viene elaborata separatamente, con vincoli per allinearle in uno spazio condiviso.
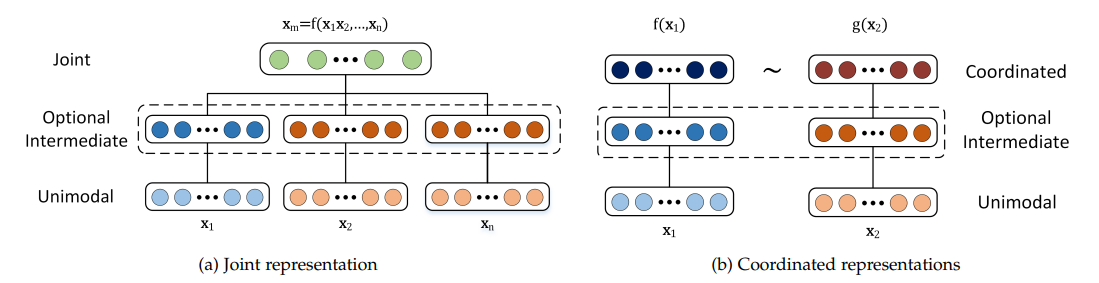 Figura 2- Struttura delle rappresentazioni congiunte e coordinate.png
Figura 2- Struttura delle rappresentazioni congiunte e coordinate.png
Figura 2: Struttura delle rappresentazioni congiunte e coordinate | Fonte.
Estrazione delle caratteristiche: Per estrarre le caratteristiche da ciascun tipo di dati si utilizzano tecniche specializzate, come natural language processing (NLP) per il testo, computer vision per le immagini e l'elaborazione dei segnali per l'audio.
Fusione di dati: La fusione combina le informazioni provenienti da due o più modalità per un compito di predizione. Gli approcci sono i seguenti:
Fusione precoce: I dati vengono integrati prima dell'analisi, in genere in un sottospazio a bassa dimensione utilizzando metodi come PCA (Principal Component Analysis) o ICA (Independent Component Analysis). Questo approccio richiede la sincronizzazione delle modalità, che può essere impegnativa a causa della diversità dei formati dei dati e delle frequenze di campionamento. Sebbene sia efficiente per l'estrazione delle caratteristiche, può portare alla perdita di dati e a problemi di sincronizzazione.
Fusione tardiva: I risultati delle singole modalità vengono combinati a livello decisionale utilizzando metodi di ensemble come bagging, boosting o approcci basati su regole (ad esempio, fusione di Bayes, max o media). Questo metodo eccelle quando le modalità non sono correlate, offrendo una flessibilità simile a quella della cognizione umana.
Modellazione: Le reti neurali in grado di elaborare più modalità, come i trasformatori o le reti neurali convoluzionali (CNN), sono utilizzate per apprendere da input diversi. Esistono modelli più sofisticati che hanno risultati superiori e sono spesso definiti LMM (Large Multimodal Models).
Modelli multimodali popolari e loro architetture
Sul mercato sono disponibili molti modelli multimodali. Di seguito sono riportati i modelli e le architetture più diffusi.
Trasformatore video-audio-testo (VATT)
Il** Video-Audio-Text Transformer (VATT) è un'architettura senza convoluzione progettata per gestire più modalità (video, audio e testo) utilizzando un framework unificato basato su Transformer**. VATT inizia inserendo ogni modalità in un livello di tokenizzazione, dove l'input grezzo viene proiettato in un embedding vector che viene successivamente elaborato da un Transformer.
Esistono due configurazioni principali: una in cui vengono utilizzati trasformatori separati con pesi unici per ogni modalità e un'altra in cui un'unica struttura portante di trasformatori con pesi condivisi gestisce tutte le modalità.
Indipendentemente dalla configurazione, il Transformer estrae le rappresentazioni specifiche per ogni modalità e le mappa in uno spazio condiviso per le attività successive. L'architettura segue la pipeline standard dei trasformatori, comunemente utilizzata in NLP e Vision Transformers (ViT), che utilizza i token in ingresso.
Inoltre, VATT incorpora un bias relativo apprendibile per il testo, rendendolo compatibile con modelli come T5. Questo approccio consente a VATT di modellare efficacemente dati multimodali per compiti come la classificazione.
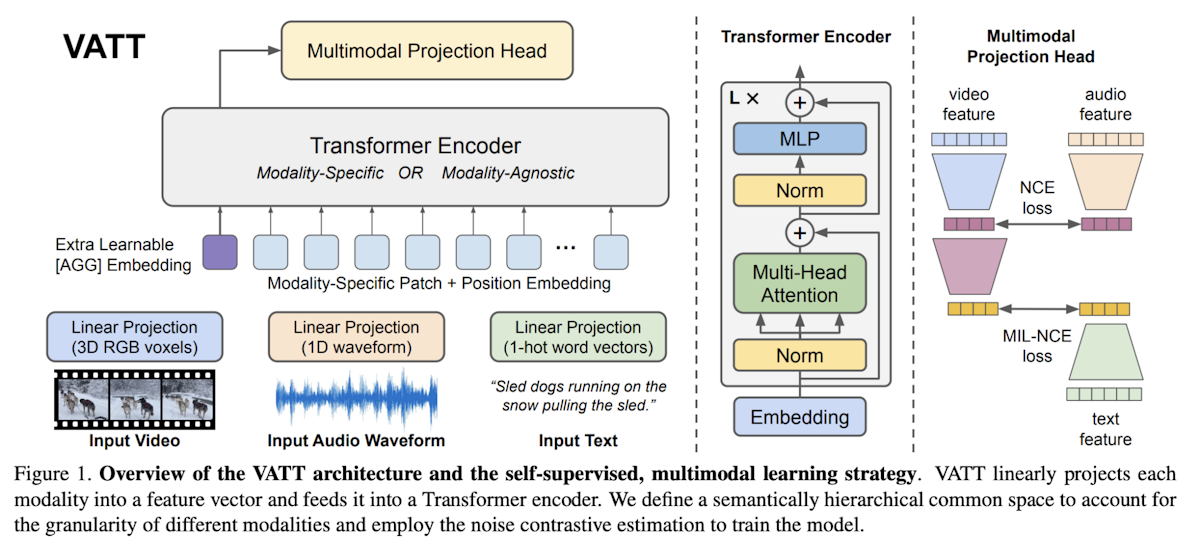 Figura 3- Vision Transformers for Multimodal Learning.png
Figura 3- Vision Transformers for Multimodal Learning.png
Figura 3: Trasformatori di visione per l'apprendimento multimodale Fonte
Autoencoder variazionale multimodale (MVAE)
L'architettura del Multimodal Variational Autoencoder (MVAE) è progettata per apprendere una rappresentazione unificata di testo e immagini. L'MVAE ha tre componenti principali: un codificatore, un decodificatore e un modulo applicativo (in questo caso un rilevatore di fake news).
 Figura 4- Multimodal Variational Autoencoder Architecture.png
Figura 4- Multimodal Variational Autoencoder Architecture.png
Figura 4: Architettura dell'autoencoder variazionale multimodale | Fonte
Encoder: Questo componente elabora gli input di testo e immagine per generare una rappresentazione latente condivisa. È costituito da due subencoder:
Codificatore testuale: Converte una sequenza di parole di un post in embedding di parole utilizzando una rete profonda pre-addestrata.
Codificatore visuale: Questo processo estrae caratteristiche visive dalle immagini utilizzando CNN (come VGG-19) per catturare la semantica spaziale e degli oggetti.
Decodificatore: Il decodificatore ricostruisce il testo e l'immagine originali dalla rappresentazione latente condivisa. Rispecchia la struttura del codificatore ed è suddiviso in:
Decodificatore testuale: Questo decodificatore ricostruisce il testo facendo passare la rappresentazione latente attraverso unità LSTM bidirezionali e uno strato completamente connesso, prevedendo la probabilità di ogni parola.
Decodificatore visuale: Inverte la codifica visiva ricostruendo le caratteristiche dell'immagine VGG-19 attraverso strati completamente connessi.
Rilevatore di notizie false: Questo componente predice se un post di notizie è reale o falso utilizzando la rappresentazione latente multimodale condivisa.
CLIP (Contrastive Language-Image Pretraining)
Il modello CLIP (Contrastive Language-Image Pretraining) è stato progettato per apprendere rappresentazioni congiunte di immagini e testo addestrandosi su un vasto insieme di coppie immagine-testo. CLIP utilizza due reti neurali separate: una per le immagini (spesso un Vision Transformer o una CNN) e una per il testo (tipicamente un Transformer).
Queste reti codificano le immagini e il testo in vettori di lunghezza fissa in uno spazio di incorporazione condiviso. Durante l'addestramento, CLIP sfrutta un obiettivo di apprendimento contrastivo, che mette insieme le incorporazioni di coppie immagine-testo corrispondenti e allontana quelle di coppie non corrispondenti.
Attraverso questo processo, CLIP impara a correlare le informazioni visive e testuali. Questo approccio consente al modello di eseguire la classificazione delle immagini a zero scatti, consentendogli di riconoscere gli oggetti nelle immagini sulla base di descrizioni in linguaggio naturale senza bisogno di un addestramento specifico. Questa potente architettura può essere utilizzata in compiti basati su immagini testuali per migliorare la capacità di generalizzazione.
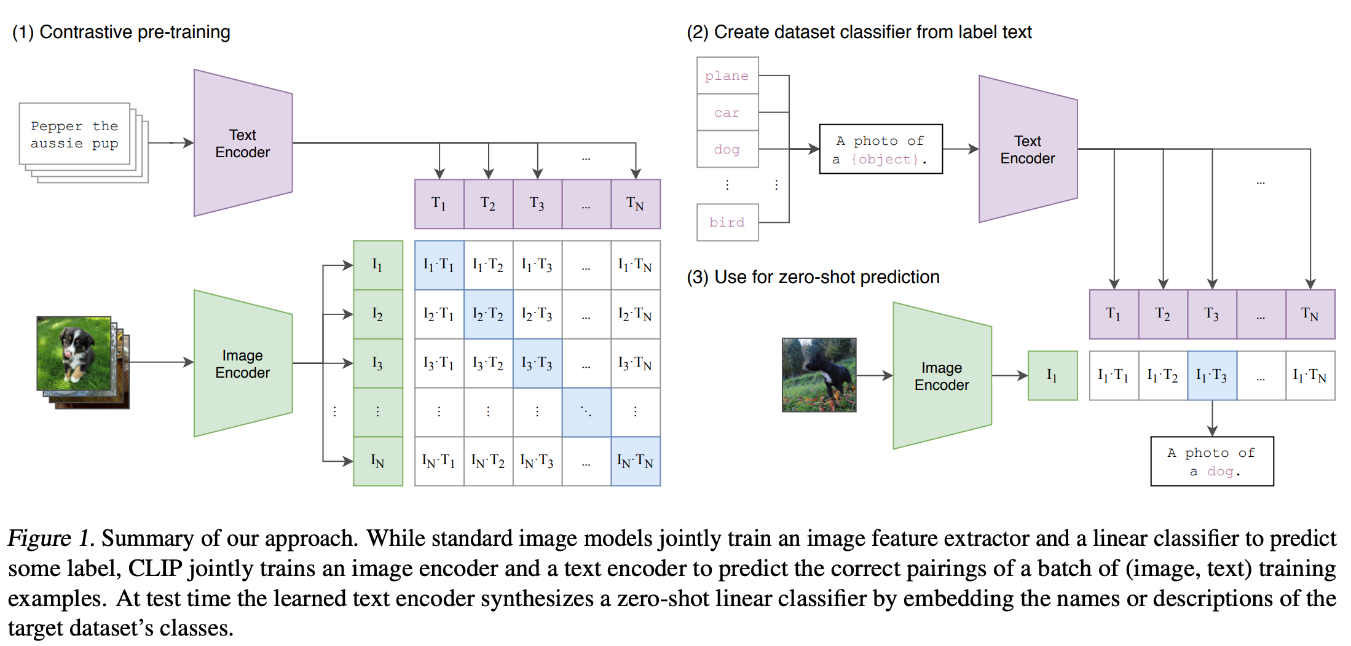 Figura 4- Architettura del modello CLIP.png
Figura 4- Architettura del modello CLIP.png
Figura 4: Architettura del modello CLIP
Alcuni modelli closed-source di queste architetture includono:
Google Gemini: Un LLM multimodale che eccelle in testi, immagini, video e audio, superando GPT-4 in diversi benchmark.
ChatGPT (GPT-4V): Supporta testo, voce e immagini, consentendo agli utenti di interagire con voci generate dall'intelligenza artificiale e di generare immagini tramite DALL-E 3.
Inworld AI: Crea PNG intelligenti per i mondi digitali, consentendo la comunicazione attraverso il linguaggio naturale, la voce e le emozioni.
Meta ImageBind: Elabora sei modalità, combinando i dati per attività come la creazione di immagini dall'audio e consentendo alle macchine di percepire i loro ambienti.
Runway Gen-2: Genera e modifica video da testo, immagini o video esistenti, offrendo capacità versatili di creazione di contenuti.
Per ulteriori informazioni sui [modelli multimodali], consultare questo post (https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know).
RAG multimodale: espansione oltre il testo
La Retrieval Augmented Generation (RAG) è un metodo per recuperare informazioni contestuali per modelli linguistici di grandi dimensioni da fonti esterne e generare risultati più accurati. Contribuisce inoltre a mitigare le [allucinazioni dell'intelligenza artificiale] (https://zilliz.com/glossary/ai-hallucination) e a risolvere alcuni problemi di sicurezza dei dati. La RAG tradizionale si è dimostrata molto efficace nel migliorare la produzione di LLM, ma rimane limitata ai dati testuali. In molte applicazioni del mondo reale, la conoscenza si estende oltre il testo, incorporando immagini, grafici e altre modalità che forniscono un contesto critico.
Di seguito è riportata una panoramica di un tipico flusso di lavoro RAG basato sul testo:
L'utente invia una richiesta di testo al sistema.
L'interrogazione viene trasformata in un embedding vettoriale, che viene poi utilizzato per cercare in un database vettoriale, come Milvus, dove i passaggi del testo sono memorizzati come embedding. Il database vettoriale recupera i passaggi che corrispondono strettamente alla query in base alla similarità vettoriale.
I passaggi di testo rilevanti vengono passati al LLM come contesto supplementare, arricchendo la sua comprensione della query.
Il LLM elabora la query insieme al contesto fornito, generando una risposta più informata e accurata.
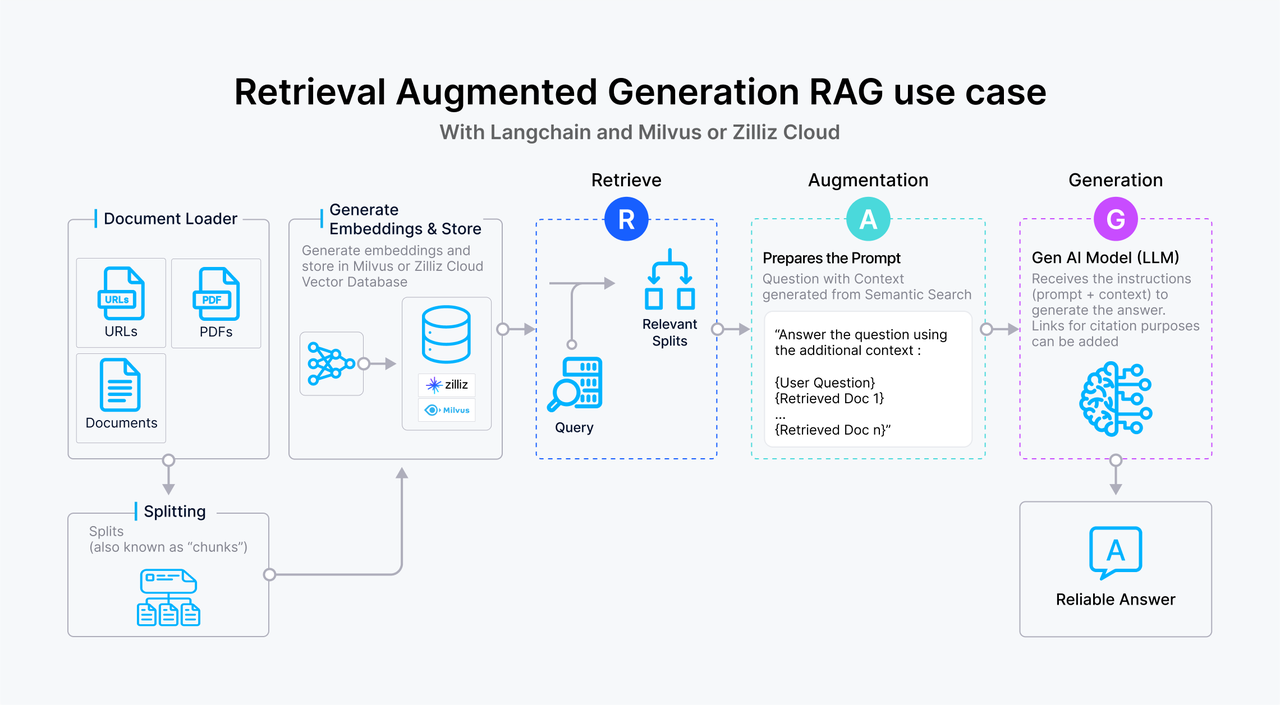 Figura 1- Come funziona RAG.png
Figura 1- Come funziona RAG.png
Figura: Come funziona il RAG
La RAG multimodale affronta la limitazione di cui sopra consentendo l'uso di diversi tipi di dati, fornendo un contesto migliore ai LLM. In parole povere, in un sistema RAG multimodale, la componente di recupero cerca le informazioni rilevanti in diverse modalità di dati e la componente di generazione genera risultati più accurati sulla base delle informazioni recuperate.
Per costruire un sistema di questo tipo, è necessario utilizzare modelli multimodali per generare embeddings e LLM con capacità multimodali, come LLAVA, GPT4-V, Gemini 1.5, Claude 3.5 Sonnet, ecc.
Ci sono un paio di modi per implementare la RAG multimodale:
Utilizzare un modello di embedding multimodale come CLIP per trasformare testi e immagini in embedding. Quindi, recuperare il contesto pertinente eseguendo una ricerca di somiglianza tra la query e le incorporazioni di testo e immagine. Infine, passare il testo grezzo e/o l'immagine del contesto più rilevante al nostro LLM multimodale.
Utilizzare un LLM multimodale per produrre riassunti testuali di immagini o tabelle. Quindi, trasformare queste sintesi testuali in embedding con un modello di embedding basato sul testo. Quindi, si esegue una ricerca di somiglianza testuale tra la query e gli embeddings della sintesi. Infine, passiamo l'immagine grezza del riassunto più rilevante al nostro LLM per la generazione della risposta.
Per saperne di più su come costruire un'applicazione RAG multimodale, consultate le nostre esercitazioni che utilizzano i diversi approcci illustrati di seguito:
Costruire un RAG multimodale con Gemini, BGE-M3, Milvus e LangChain
Costruire migliori pipeline RAG multimodali con FiftyOne, LlamaIndex e Milvus
RAG multimodale: espansione oltre il testo per un'intelligenza artificiale più intelligente
Confronto tra unimodale e multimodale
I sistemi multimodali si differenziano dai sistemi tradizionali (unimodali) per il modo in cui elaborano e integrano simultaneamente i dati provenienti da più tipi di modalità di input (ad esempio, testo, immagini e audio).
I sistemi multimodali hanno un vantaggio nella comprensione del contesto perché estraggono informazioni da due fonti: la visione e il linguaggio. Gli approcci tradizionali sono più semplici e si concentrano su domini applicativi specifici. La tabella seguente illustra alcune differenze critiche tra sistemi unimodali e multimodali.
| Aspetto | Ai tradizionale | Ai multimodale |
| Tipo di input | Utilizza un singolo tipo di input (ad esempio, solo testo, solo immagine) | Elabora più tipi di input (ad esempio, testo, immagini, audio) |
| Focalizzazione dell'elaborazione | Si concentra su un'unica modalità sensoriale o di dati | Integra e mette in relazione le informazioni tra più modalità |
| Complessità | Più semplice e spesso specifico del dominio | È più complesso a causa della necessità di integrare diversi tipi di dati |
| Comprensione del contesto | Limitata alle informazioni disponibili in una singola modalità | Può comprendere meglio il contesto utilizzando diverse modalità |
| Applicazioni | Classificazione di testi, rilevamento di oggetti, riconoscimento vocale, ecc. | Interazione uomo-macchina, robotica, veicoli autonomi, realtà aumentata, ecc. |
Benefici e sfide dell'IA multimodale
Questa sezione elenca alcuni vantaggi critici e le sfide associate alla costruzione e alla valutazione di sistemi multimodali.
Benefici
Di seguito sono elencati alcuni dei vantaggi dell'utilizzo dell'IA multimodale:
**I sistemi multimodali acquisiscono un contesto più ampio integrando informazioni complementari provenienti da fonti diverse, ad esempio combinando spunti visivi e linguistici per una migliore interpretazione.
**L'intelligenza artificiale multimodale può fare previsioni e decisioni più accurate. Ad esempio, un sistema di diagnosi medica potrebbe essere più affidabile considerando le immagini del paziente e le cartelle cliniche.
**L'IA multimodale può essere applicata a diversi compiti complessi, tra cui la sottotitolazione di immagini, la risposta a domande visive, la diagnostica medica, la guida autonoma e così via, rendendola altamente adattabile a diversi domini.
Comprensione più simile a quella umana: L'intelligenza artificiale multimodale può imitare meglio la cognizione umana e consentire una migliore interazione uomo-macchina nelle applicazioni in tempo reale, elaborando dati provenienti da diversi sensi (modalità).
Sfide
Alcune sfide legate all'uso dell'IA multimodale includono:
**Il metodo o il formato con cui vengono rappresentate le modalità estrae le informazioni complementari o ridondanti tra più modalità. La rappresentazione dei dati multimodali è molto importante ma impegnativa a causa della loro natura eterogenea. Ad esempio, il suono è un segnale e l'immagine è una rappresentazione 3D con diverse scale e dimensioni da rappresentare. Come farli confluire nello stesso spazio di rappresentazione comune è un punto di implementazione essenziale.
**La procedura può spiegare come convertire o trasformare i dati da una modalità all'altra una volta che sono eterogenei. La relazione tra le diverse modalità è principalmente soggettiva. Ad esempio, la traduzione di un video nella corrispondente descrizione testuale.
Fusione: Si riferisce alla combinazione di dati provenienti da più modalità per migliorare le previsioni. Ad esempio, nel riconoscimento vocale audiovisivo, la descrizione visiva del movimento delle labbra viene integrata con il segnale vocale per prevedere le parole pronunciate. Le informazioni possono provenire da diverse modalità e hanno vari livelli di forza predittiva, importanza, contributo e topologia del rumore. Ci sono valori di dati mancanti in almeno una delle modalità.
Spiegabilità: Un termine recente, Explainable AI (XAI), mira a fornire spiegazioni e ragionamenti significativi su un modello. Nel caso di più modalità, è più difficile capire come i modelli arrivino a conclusioni con fonti di dati diverse.
FAQ dell'IA multimodale
- **Che cos'è l'IA multimodale?
L'IA multimodale è un tipo di sistema di intelligenza artificiale in grado di elaborare e analizzare informazioni provenienti da diverse modalità, tra cui testo, immagini, audio e video.
- **Quali tipi di dati può utilizzare l'IA multimodale?
L'intelligenza artificiale multimodale utilizza vari tipi di dati, tra cui testo, immagini, audio, video, sensori e dati grafici.
- **L'IA multimodale sostituisce l'IA tradizionale?
L'IA multimodale non sostituisce l'IA tradizionale, ma ne amplia le capacità integrando più modalità di dati. È un'estensione. I metodi tradizionali rimangono essenziali, mentre l'IA multimodale fornisce funzionalità aggiuntive.
- **Quali sono le applicazioni tipiche dell'IA multimodale?
Le applicazioni tipiche dell'IA multimodale comprendono la sottotitolazione delle immagini, la risposta a domande visive, il riconoscimento delle emozioni e la guida autonoma.
- **Quali sono i vantaggi dell'IA multimodale?
L'IA multimodale presenta diversi vantaggi, tra cui robustezza, efficienza, consapevolezza del contesto, un dominio applicativo diversificato e una migliore interazione uomo-macchina.
Risorse correlate
- Che cos'è l'intelligenza artificiale multimodale?
- Come funziona l'intelligenza artificiale multimodale?
- Modelli multimodali popolari e loro architetture
- RAG multimodale: espansione oltre il testo
- Confronto tra unimodale e multimodale
- Benefici e sfide dell'IA multimodale
- FAQ dell'IA multimodale
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente