




Meilleures pratiques dans la mise en œuvre d'applications de génération augmentée par la recherche (RAG)
Le Retrieval-Augmented Generation (RAG) est une méthode qui s'est avérée très efficace pour améliorer les réponses des LLM et traiter les hallucinations LLM. En bref, la RAG fournit aux LLM un contexte qui peut les aider à générer des réponses plus précises et contextualisées. Les contextes peuvent provenir de n'importe où : de vos documents internes, de bases de données vectorielles, de fichiers CSV, de fichiers JSON, etc.
RAG est une nouvelle approche qui consiste en de nombreux composants qui fonctionnent ensemble. Ces composants comprennent le traitement des requêtes, context chunking, la récupération du contexte, context reranking, et le LLM lui-même pour générer la réponse. Chaque composant influence la qualité de la réponse finale générée par une application RAG. Le problème est qu'il est difficile de trouver la meilleure combinaison de méthodes dans chaque composant qui conduise à la performance optimale du RAG.
Dans cet article, nous examinerons plusieurs techniques couramment utilisées dans toutes les composantes des RAG, nous évaluerons la meilleure approche pour chaque composante, puis nous trouverons la meilleure combinaison qui conduit à la réponse générée par les RAG la plus optimale, selon [ce document] (https://arxiv.org/pdf/2407.01219). Sans plus attendre, commençons par une introduction aux composantes des RAG.
Composants RAG
Comme mentionné, RAG est une méthode puissante pour atténuer les problèmes d'hallucination des LLMs, qui se produisent généralement lorsque nous posons des questions au-delà de leurs données d'entraînement ou lorsqu'elles requièrent des connaissances spécialisées. Par exemple, si nous posons à un LLM une question sur nos données internes, nous obtiendrons probablement une réponse inexacte. RAG résout ce problème en fournissant à notre LLM un contexte qui peut l'aider à répondre à notre requête.
RAG consiste en une chaîne de composants qui forment un flux de travail. Les composants typiques de RAG sont les suivants
Classification de la requête: pour déterminer si notre requête nécessite la recherche de contextes ou si elle peut être traitée directement par le LLM.
Recherche de contextes : pour récupérer les k premiers candidats dans les contextes les plus pertinents pour notre requête.
Context reranking : pour trier les k premiers candidats extraits de la composante de récupération, en commençant par le plus similaire.
Context repacking : organiser les contextes les plus pertinents dans un format plus structuré pour une meilleure génération de réponses.
Résumé de contexte : pour extraire les informations clés des contextes pertinents afin d'améliorer la génération de réponses.
Génération de réponses : pour générer une réponse basée sur la requête et les contextes pertinents.
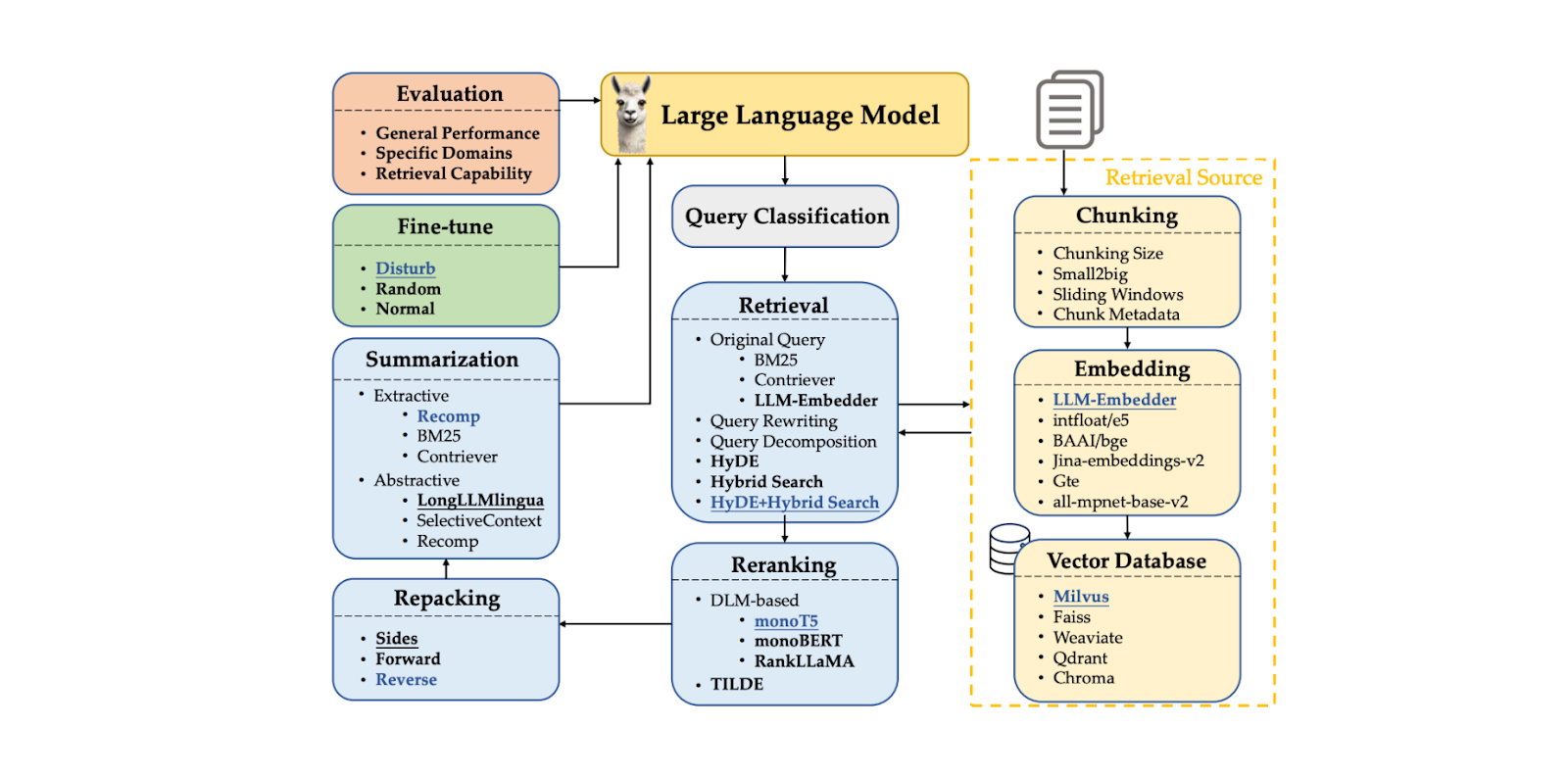 Figure- RAG Components..png
Figure- RAG Components..png
Figure : RAG Components._ Source
Bien que ces composants RAG soient utiles pendant le processus de génération de la réponse (c'est-à-dire lorsque nous avons déjà stocké tous les contextes et qu'ils sont prêts à être récupérés), plusieurs autres facteurs doivent être pris en compte avant de mettre en œuvre une méthode RAG.
Nous devons transformer nos documents contextuels en encastrements vectoriels pour les rendre utiles dans une approche RAG. Il est donc crucial de choisir [le modèle d'intégration le plus approprié] (https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data) et la stratégie pour représenter nos documents d'entrée sous forme d'intégrations.
Un embedding contient une représentation sémantiquement riche de notre document d'entrée. Cependant, si le document utilisé comme contexte est trop long, il peut perturber le LLM lors de la génération d'une réponse appropriée. Une approche courante pour résoudre ce problème consiste à appliquer une méthode de découpage en morceaux (chunking), dans laquelle nous divisons notre document d'entrée en plusieurs morceaux et transformons ensuite chaque morceau en un encapsulage (embedding). Il est essentiel de choisir la meilleure méthode de découpage et la meilleure taille, car les morceaux trop courts ne contiendront probablement pas suffisamment d'informations.
 Figure- RAG workflow.png
Figure- RAG workflow.png
Figure : Flux de travail du GCR_
Une fois que nous avons transformé chaque morceau en embeddings, nous devons envisager un stockage approprié pour ces embeddings. Si vous n'avez pas affaire à un grand nombre d'embeddings, vous pouvez les stocker directement dans la mémoire locale de votre appareil. Cependant, dans la pratique, vous aurez souvent affaire à des centaines, voire des millions d'intégrations. Dans ce cas, vous avez besoin d'une base de données vectorielle comme Milvus ou son service géré, Zilliz Cloud, pour les stocker, et le choix de la bonne base de données vectorielle est crucial pour le succès de notre application RAG.
La dernière considération est le LLM lui-même. Le cas échéant, nous pouvons affiner le LLM pour cibler nos besoins spécifiques plus précisément. Cependant, le réglage fin est coûteux et inutile dans la plupart des cas, en particulier si nous utilisons un LLM performant avec de nombreux paramètres.
Dans les sections suivantes, nous discuterons des meilleures approches pour chaque composant RAG. Ensuite, nous explorerons les combinaisons de ces meilleures approches et suggérerons plusieurs stratégies de déploiement de RAG qui équilibrent la performance et l'efficacité.
Classification des requêtes
Comme mentionné dans la section précédente, RAG est utile pour s'assurer que le LLM génère des réponses précises et contextualisées, en particulier lorsque des connaissances spécialisées de nos données internes sont nécessaires. Cependant, RAG augmente également la durée d'exécution du processus de génération de réponses. En effet, toutes les requêtes ne nécessitent pas le processus d'extraction, et beaucoup d'entre elles peuvent être traitées directement par le LLM. Par conséquent, il serait plus avantageux d'ignorer le processus de récupération du contexte si une requête n'en a pas besoin.
Nous pouvons mettre en œuvre un modèle de [classification] (https://zilliz.com/glossary/classification) de requête pour déterminer si une requête nécessite une récupération de contexte avant le processus de génération de réponse. Un tel modèle de classification consiste généralement en un modèle supervisé, tel que BERT, dont l'objectif principal est de prédire si une requête a besoin d'être récupérée ou non. Cependant, comme pour les autres modèles supervisés, nous devons l'entraîner avant de l'utiliser pour l'inférence. Pour entraîner le modèle, nous devons générer un ensemble de données d'exemples d'invites et leurs étiquettes binaires correspondantes, y compris si l'invite a besoin d'être retrouvée ou non.
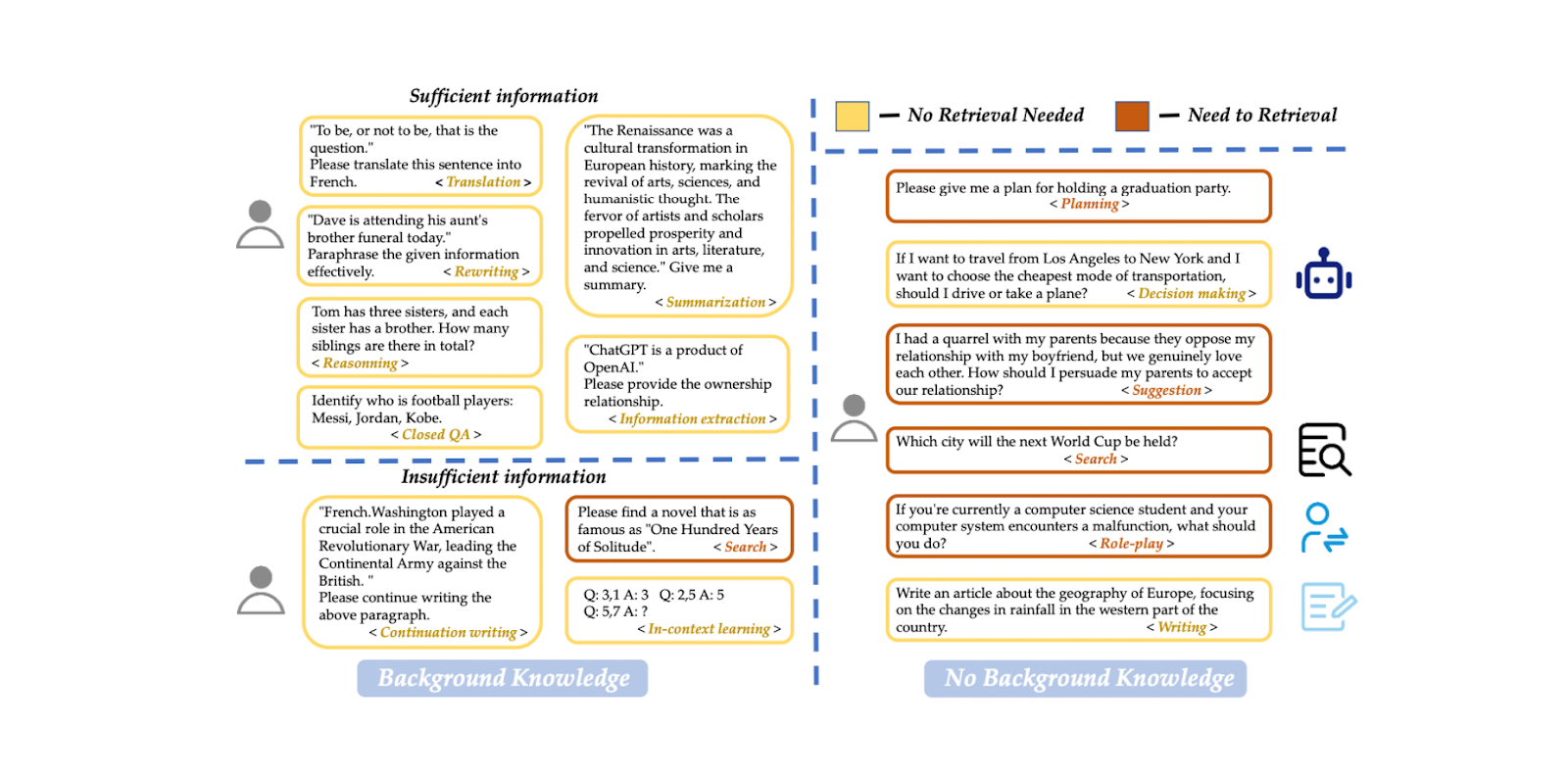 Figure- Query classification dataset example..png
Figure- Query classification dataset example..png
Figure : Exemple d'ensemble de données de classification de requêtes._ Source
Dans l'[article] (https://arxiv.org/pdf/2407.01219), un modèle multilingue basé sur BERT est utilisé pour la classification des requêtes. Les données d'entraînement comprennent 15 types d'invites au total, telles que la traduction, le résumé, la réécriture, l'apprentissage en contexte, etc. Il existe deux étiquettes distinctes : "suffisant" si l'invite est entièrement basée sur les informations fournies par l'utilisateur et ne nécessite pas de recherche, et "insuffisant" si les informations de l'invite sont incomplètes, nécessitent des informations spécialisées et requièrent un processus de recherche. En utilisant cette approche, le modèle a atteint 95 % en termes de précision et de score F1.
Cette étape de classification des requêtes peut améliorer de manière significative l'efficacité du processus RAG en évitant les recherches inutiles pour les requêtes qui peuvent être traitées directement par le LLM. Elle agit comme un filtre, garantissant que seules les requêtes nécessitant un contexte supplémentaire sont envoyées à travers le processus d'extraction qui prend plus de temps.
 Figure- Query classifier result..png
Figure- Query classifier result..png
Figure : Résultat du classificateur de requêtes._ Source
Technique de découpage
Chunking se réfère au processus de division de longs documents d'entrée en segments plus petits. Ce processus est très utile pour fournir au LLM un contexte plus granulaire. Il existe plusieurs méthodes de découpage, y compris des approches au niveau des jetons et au niveau des phrases. Le découpage au niveau de la phrase permet souvent d'obtenir un bon équilibre entre la simplicité et la préservation sémantique du contexte. Lors du choix d'une méthode de découpage, nous devons faire attention à la taille des morceaux, car les morceaux trop courts peuvent ne pas fournir un contexte utile au LLM.
 Figure- Splitting a long document into smaller chunks.png
Figure- Splitting a long document into smaller chunks.png
Figure : Découpage d'un long document en morceaux plus petits_
Pour trouver la taille optimale des morceaux, une évaluation a été menée sur le document Lyft 2021. Les 60 premières pages du document ont été choisies comme corpus et découpées en plusieurs tailles. Un LLM a ensuite été utilisé pour générer 170 requêtes basées sur ces 60 pages. Le modèle text-embedding-ada-002 a été utilisé pour les embeddings, tandis que le modèle Zephyr 7B a été utilisé comme LLM pour générer des réponses basées sur les requêtes choisies.
Pour évaluer les performances du modèle sur différentes tailles de morceaux, GPT-3.5 Turbo a été utilisé. Deux mesures ont été utilisées pour évaluer la qualité des réponses : la fidélité et la pertinence. La fidélité mesure si la réponse est hallucinée ou si elle correspond aux contextes retrouvés, tandis que la pertinence mesure si les contextes et les réponses retrouvés correspondent aux requêtes.
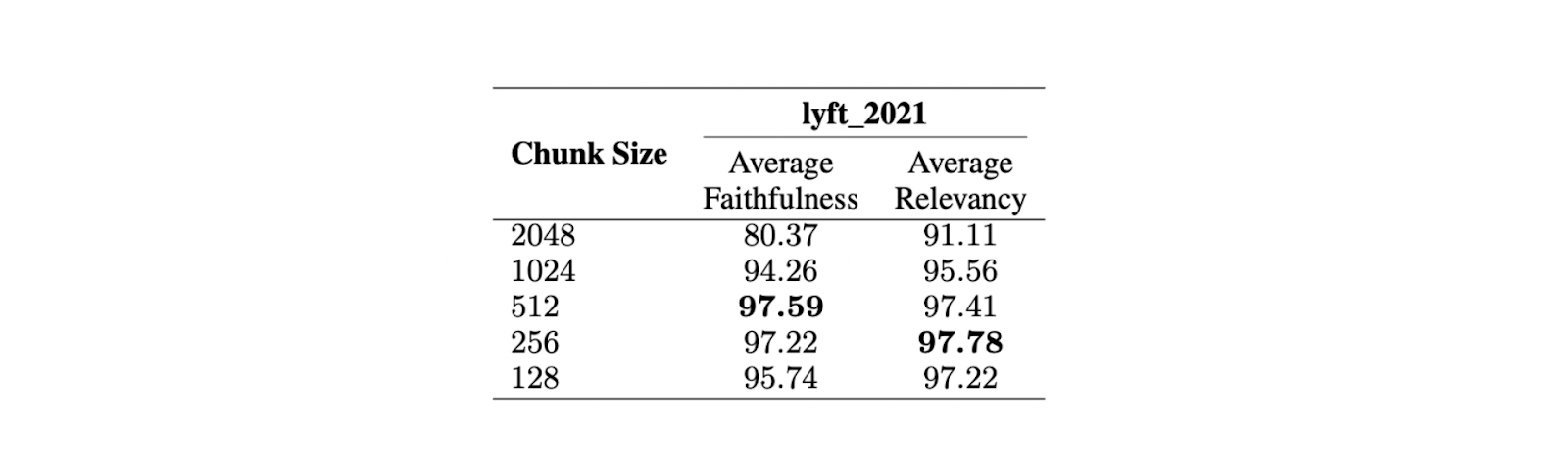 Figure- Comparaison de différentes tailles de morceaux. .png
Figure- Comparaison de différentes tailles de morceaux. .png
Figure : Comparaison de différentes tailles de morceaux._ Source
Les résultats montrent qu'une taille maximale de 512 tokens est préférable pour la génération de réponses très pertinentes à partir du LLM. Des tailles de morceaux plus courtes, telles que 256 tokens, donnent également de bons résultats et peuvent améliorer la durée d'exécution globale de l'application RAG. Des techniques de découpage avancées telles que small2big et les fenêtres coulissantes peuvent être utilisées pour combiner les avantages des différentes tailles de morceaux.
Small2big est une approche de découpage qui organise les relations entre les blocs. Les blocs de petite taille sont utilisés pour faire correspondre les requêtes, et les blocs plus grands contenant les informations des plus petits sont utilisés comme contexte final pour le LLM. Une fenêtre coulissante est une méthode de découpage qui fournit des chevauchements de jetons entre les blocs afin de préserver les informations contextuelles.
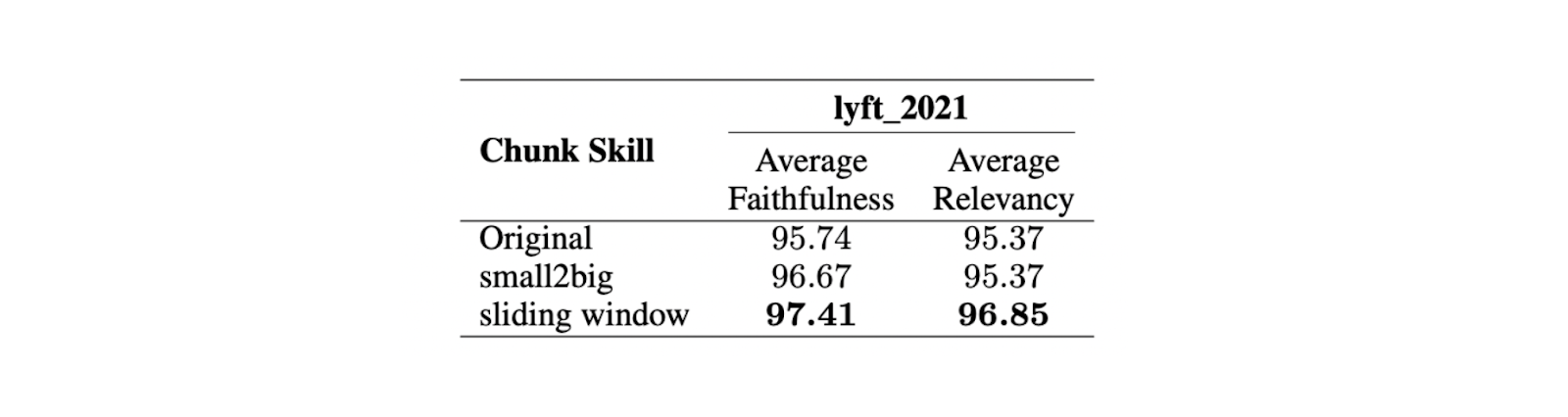 Figure- Comparaison de différentes techniques de découpage..png
Figure- Comparaison de différentes techniques de découpage..png
Figure : Comparaison de différentes techniques de découpage en morceaux._ Source
Les expériences montrent qu'avec une taille de morceaux plus petite de 175 tokens, une taille de morceaux plus grande de 512 tokens, et un chevauchement de morceaux de 20 tokens, les deux techniques de découpage améliorent les scores de fidélité et de pertinence des réponses LLM.
Ensuite, il est crucial de trouver le meilleur [modèle d'intégration] (https://zilliz.com/ai-models) pour représenter chaque morceau en tant qu'intégration vectorielle. Un test sur namespace-Pt/msmarco a été effectué à cette fin. Les résultats montrent que les modèles LLM Embedder et bge-large-en sont les plus performants. Cependant, comme LLM Embedder est trois fois plus petit que bge-large-en, il a été choisi comme intégration par défaut pour l'expérience.
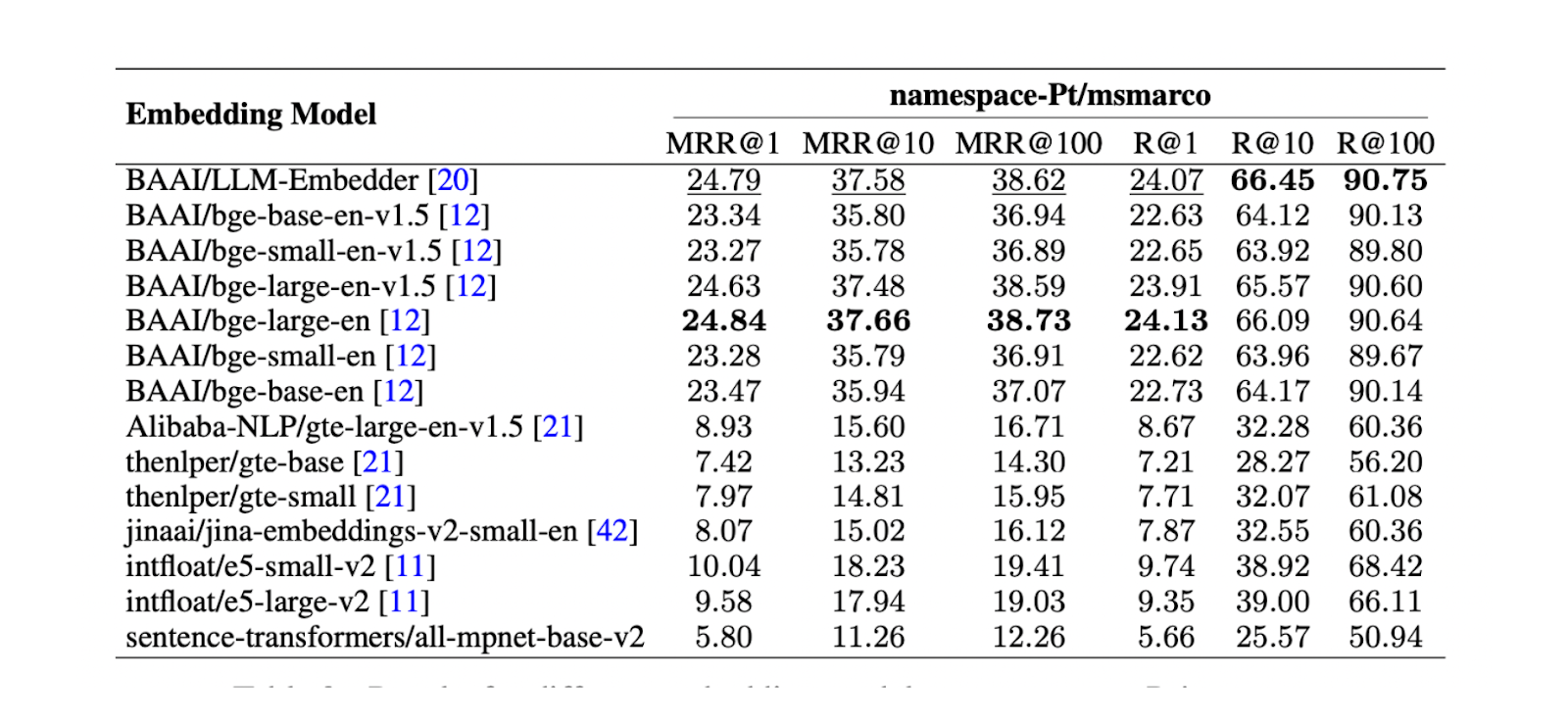 Figure- Résultats pour différents modèles d'intégration sur l'espace de noms-Pt:msmarco. .png
Figure- Résultats pour différents modèles d'intégration sur l'espace de noms-Pt:msmarco. .png
Figure : Résultats pour différents modèles d'intégration sur l'espace nominatif-Ptmsmarco._ Source
Bases de données vectorielles
Les [bases de données vectorielles] (https://zilliz.com/learn/what-is-vector-database) jouent un rôle crucial dans les applications RAG, en particulier pour le stockage et la récupération des contextes pertinents. Dans les applications RAG courantes du monde réel, nous traitons un grand nombre de documents, ce qui entraîne un grand nombre d'enchâssements de contextes qui doivent être stockés. Dans de tels cas, le stockage de ces enchâssements dans la mémoire locale est insuffisant, et le calcul de la récupération des contextes pertinents parmi de grandes collections d'enchâssements prendrait un temps considérable.
Les bases de données vectorielles sont conçues pour résoudre ces problèmes. Avec une base de données vectorielle, nous pouvons stocker des millions, voire des milliards, d'intégrations vectorielles et effectuer une recherche de contexte en une fraction de seconde. Lors du choix de la meilleure base de données vectorielle pour votre cas d'utilisation, nous devons prendre en compte plusieurs facteurs, tels que la prise en charge du type d'index, la prise en charge des vecteurs à l'échelle du milliard, la prise en charge de la [recherche hybride] (https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus) et les capacités "cloud-native".
Parmi ces critères, Milvus se distingue comme la meilleure base de données vectorielles open-source par rapport à ses concurrents comme Weaviate, Chroma, Faiss, Qdrant, etc.
 Comparaison de diverses bases de données vectorielles..png
Comparaison de diverses bases de données vectorielles..png
Comparaison de diverses bases de données vectorielles Source.
En ce qui concerne la prise en charge des types d'index, Milvus propose plusieurs méthodes d'indexation pour répondre à différents besoins, comme l'index plat naïf (FLAT) ou d'autres types d'indexation conçus pour accélérer le processus de recherche, comme l'index de fichier inversé (IVF-FLAT) et le Hierarchical Navigable Small World (HNSW). Pour comprimer la mémoire nécessaire au stockage des contextes, vous pouvez également mettre en œuvre la quantification de produit (PQ) pendant le processus d'indexation des enchâssements.
Milvus prend également en charge une approche de recherche hybride. Cette approche nous permet de combiner deux méthodes différentes au cours du processus de recherche de contexte. Par exemple, nous pouvons combiner l'intégration dense avec l'intégration éparse pour récupérer les contextes pertinents, en améliorant la pertinence du contexte récupéré par rapport à la requête. Ceci, à son tour, améliore également la réponse générée par le LLM. En outre, nous pouvons combiner l'intégration dense avec le filtrage des métadonnées si nous le souhaitons.
Si vous souhaitez utiliser Milvus sur le cloud, que ce soit sur GCP ou AWS, pour stocker des milliards d'embeddings, vous pouvez opter pour [son service géré : Zilliz Cloud] (https://zilliz.com/cloud).
Avec Zilliz Cloud, vous pouvez créer des unités de cluster (UC) optimisées en termes de capacité et de performance pour stocker des embeddings à grande échelle. Par exemple, vous pouvez créer 256 unités de cluster optimisées en termes de performances pour 1,3 milliard de vecteurs à 128 dimensions ou 128 unités de cluster optimisées en termes de capacité pour 3 milliards de vecteurs à 128 dimensions.
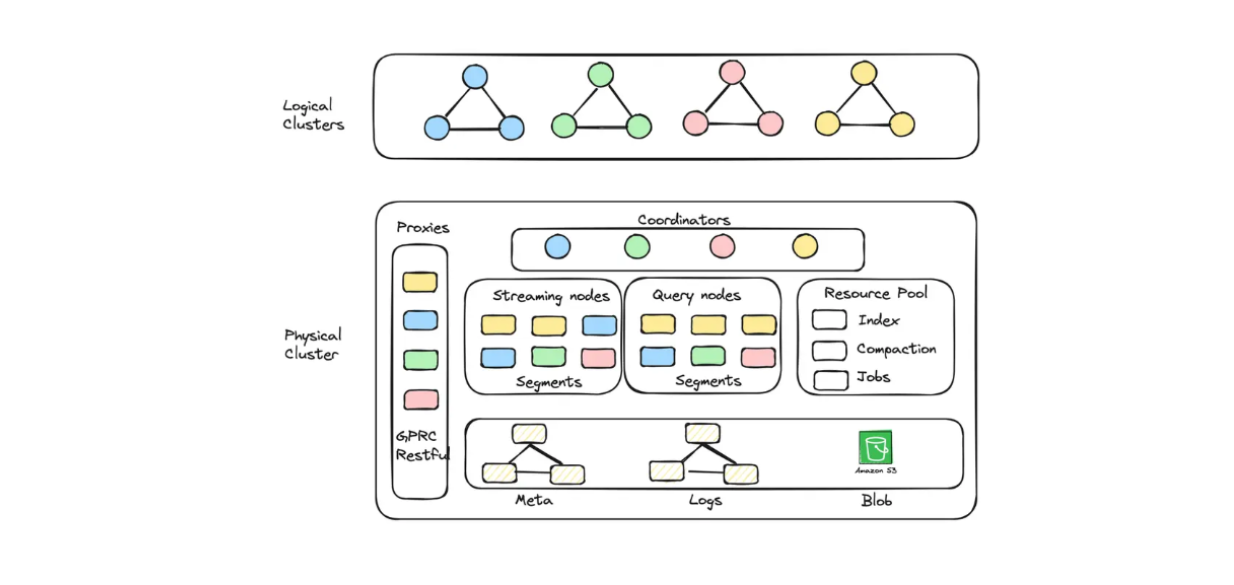 Diagramme du cluster logique et de l'auto-scaling mis en œuvre dans Zilliz Cloud Serverless..png
Diagramme du cluster logique et de l'auto-scaling mis en œuvre dans Zilliz Cloud Serverless..png
Diagramme du cluster logique et de l'auto-scaling mis en œuvre dans Zilliz Cloud Serverless.png]()
Si vous souhaitez créer une application RAG avec Milvus mais aussi économiser sur les coûts d'exploitation, vous pouvez opter pour Zilliz Cloud Serverless. Ce service offre une fonction de mise à l'échelle automatique au sein de Milvus, avec des coûts qui n'augmentent qu'en fonction de la croissance de votre entreprise. L'option sans serveur est également parfaite pour réaliser des économies, car vous ne payez que lorsque vous utilisez le service, et non lorsqu'il est inactif.
Zilliz Cloud a lancé récemment plusieurs mises à jour intéressantes, notamment un nouveau service de migration, des répliques multiples, une nouvelle intégration avec les connecteurs Fivetran, une capacité de mise à l'échelle automatique et de nombreuses autres fonctionnalités de préparation à la production. Plus de détails ci-dessous :
Zilliz Cloud Update : Migration Services, Fivetran Connectors, Multi-replicas, and More](https://zilliz.com/blog/zilliz-sep-24-launch)
Amélioration de la surveillance et de l'observabilité dans Zilliz Cloud
Débloquez la recherche alimentée par l'IA avec Fivetran et Milvus
Les 5 meilleures raisons de migrer de l'Open Source Milvus vers Zilliz Cloud
Techniques de recherche
L'objectif principal du composant de recherche est de récupérer les k contextes les plus pertinents pour une requête donnée. Cependant, un défi important dans cette composante, qui pourrait affecter la qualité globale de notre RAG, provient de la requête elle-même. Les requêtes originales sont souvent mal écrites ou mal exprimées, manquant des informations sémantiques nécessaires aux applications RAG pour récupérer les contextes pertinents.
Plusieurs techniques couramment appliquées pour résoudre ce problème sont les suivantes :
Réécriture de la requête : Invite le LLM à réécrire la requête originale pour en améliorer la clarté et les informations sémantiques.
Décomposition de la requête** : décompose la requête originale en sous-requêtes et effectue la recherche sur la base de ces sous-requêtes.
Génération de pseudo-documents](https://zilliz.com/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings):** Génère des documents hypothétiques ou synthétiques sur la base de la requête originale et utilise ensuite ces documents hypothétiques pour récupérer des documents similaires dans la base de données. La mise en œuvre la plus connue de cette approche est [HyDE (Hypothetical Document Embeddings)] (https://zilliz.com/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings).
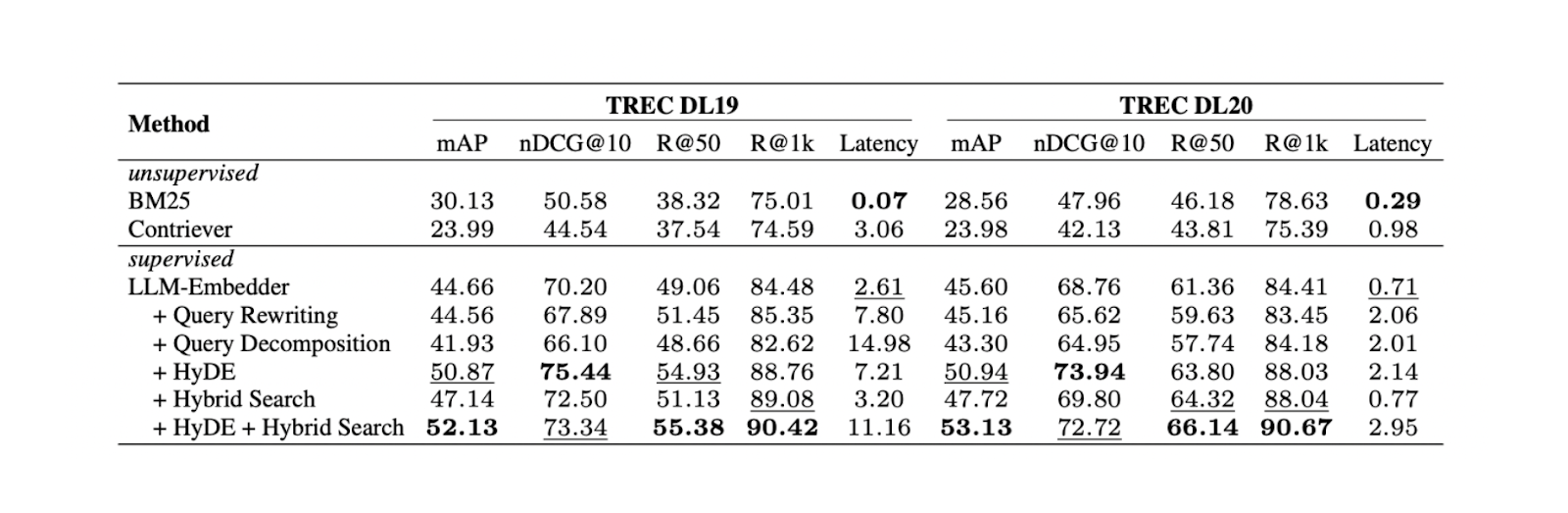
Les expériences montrent que la combinaison de HyDE et de la recherche hybride donne les meilleurs résultats sur TREC DL19/20 par rapport à la réécriture des requêtes et à la décomposition des requêtes. La recherche hybride mentionnée dans l'expérience combine LLM Embedder pour obtenir des embeddings denses et BM25 pour obtenir des sparse embeddings.
Le flux de travail de HyDe + recherche hybride est le suivant : tout d'abord, nous générons un document hypothétique qui répond à la requête avec HyDE. Ensuite, ce document hypothétique est concaténé avec la requête originale avant d'être transformé en dense and sparse embeddings en utilisant LLM Embedder et BM25, respectivement.
 Résultats pour différentes méthodes de recherche. .png
Résultats pour différentes méthodes de recherche. .png
Résultats des différentes méthodes de recherche. Source
Bien que la combinaison de HyDE et de la recherche hybride donne les meilleurs résultats, elle s'accompagne également de coûts de calcul plus élevés. Sur la base de tests supplémentaires sur plusieurs ensembles de données NLP, la recherche hybride et l'utilisation exclusive d'encastrements denses donnent des résultats comparables à HyDE + recherche hybride, mais avec un temps de latence presque 10 fois inférieur. L'utilisation d'une recherche hybride serait donc plus recommandée.
Puisque nous utilisons une recherche hybride, les contextes retrouvés sont basés sur la [recherche vectorielle] (https://zilliz.com/learn/vector-similarity-search) à partir d'encastrements denses et épars. Par conséquent, il est également intéressant d'examiner l'impact de la valeur de pondération entre les encastrements denses et épars sur le score de pertinence global selon cette équation :
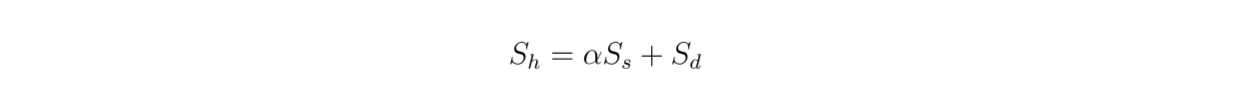 formula.png
formula.png
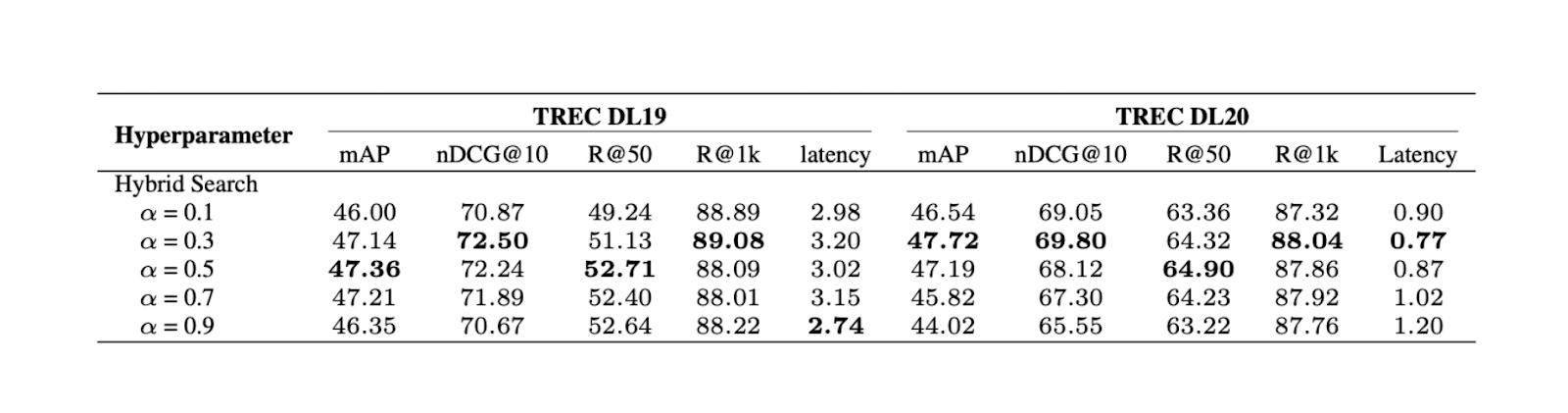 Figure- Résultats de la recherche hybride avec différentes valeurs alpha..png
Figure- Résultats de la recherche hybride avec différentes valeurs alpha..png
Figure : Résultats de la recherche hybride avec différentes valeurs alpha. Source._
L'expérience montre qu'une valeur de pondération de 0,3 produit le meilleur score de pertinence globale sur TREC DL19/20.
Techniques de reclassement et de reconditionnement
L'objectif principal des [techniques de reclassement] (https://zilliz.com/learn/what-are-rerankers-enhance-information-retrieval) est de réorganiser les k contextes les plus pertinents extraits de la méthode de recherche afin de s'assurer que le contexte le plus similaire est renvoyé en tête de liste. Il existe deux approches courantes pour réorganiser les contextes :
DLM Reranking : Cette méthode utilise un modèle d'apprentissage profond pour le reclassement. Le modèle est entraîné avec une paire composée de la requête originale et d'un contexte en entrée et une étiquette binaire "vrai" (si la paire est pertinente l'une pour l'autre) ou "faux" en sortie. Les contextes sont ensuite triés en fonction de la probabilité que le modèle renvoie lorsqu'il prédit qu'une paire de requêtes et de contextes est "vraie".
TILDE Reranking : Cette approche utilise la probabilité de chaque terme de la requête originale pour le reclasser. Lors de l'inférence, nous pouvons utiliser soit la composante de vraisemblance de la requête (TILDE-QL) seule pour un reclassement plus rapide, soit la combinaison de TILDE-QL et de sa composante de vraisemblance du document (TILDE-DL) pour améliorer le résultat du reclassement à un coût de calcul plus élevé.
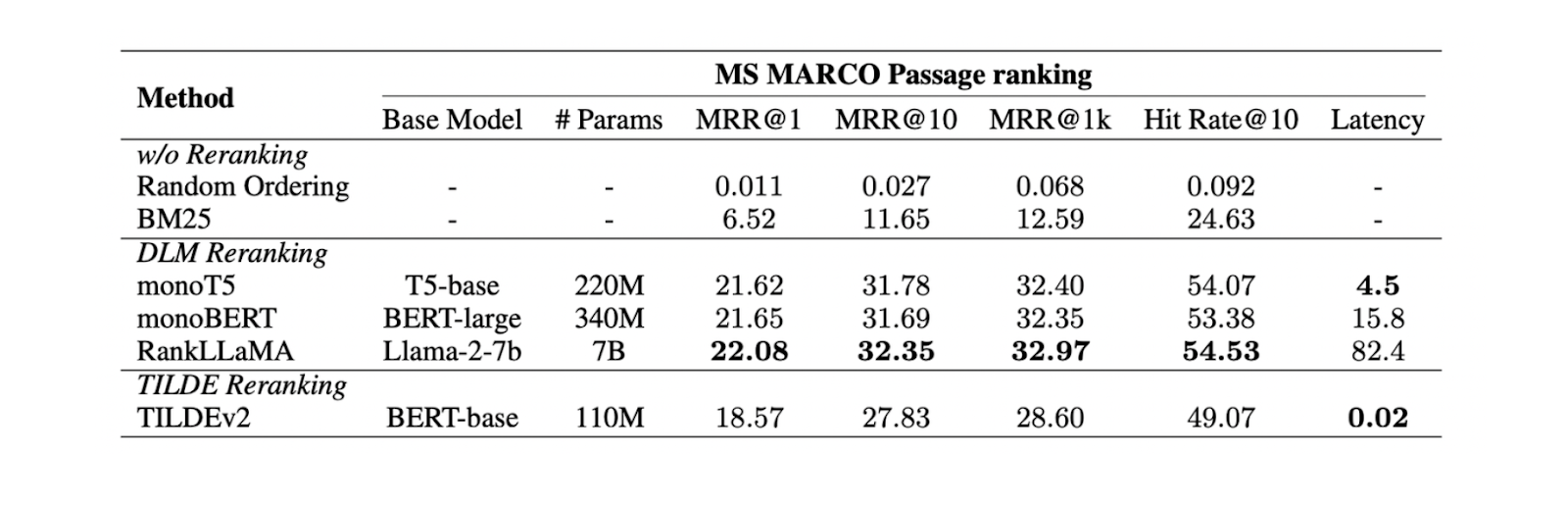 Figure- Résultats des différentes méthodes de reclassement..png
Figure- Résultats des différentes méthodes de reclassement..png
Figure : Résultats des différentes méthodes de reranking._ Source
Les expériences menées sur l'ensemble de données MS MARCO Passage ranking montrent que la méthode de reranking DLM avec le modèle Llama 27B donne les meilleures performances de reranking. Cependant, comme il s'agit d'un modèle de grande taille, son utilisation entraîne un coût de calcul important. Par conséquent, l'utilisation de mono T5 est plus recommandée pour le reranking DLM, car elle offre un équilibre entre la performance et l'efficacité de calcul.
Après la phase de reranking, nous devons également considérer comment présenter les contextes rerankés à notre LLM : dans l'ordre descendant ("forward") ou ascendant ("reverse"). Sur la base des expériences menées dans ce document, on peut conclure que la meilleure qualité de réponse est générée en utilisant la configuration "inverse". L'hypothèse est que le positionnement d'un contexte plus pertinent plus près de la requête conduit à des résultats optimaux.
Techniques de résumé
Dans les cas où nous disposons de longs contextes extraits des composants précédents, nous pouvons souhaiter les rendre plus compacts et supprimer les informations redondantes. Pour atteindre cet objectif, des approches de résumé sont généralement mises en œuvre.
Il existe deux techniques différentes de résumé de contexte : extractive et abstractive.
Le résumé extractif divise le document d'entrée en segments plus petits, qui sont ensuite classés en fonction de leur importance. La méthode abstractive, quant à elle, génère un nouveau résumé contextuel qui ne contient que les informations pertinentes.
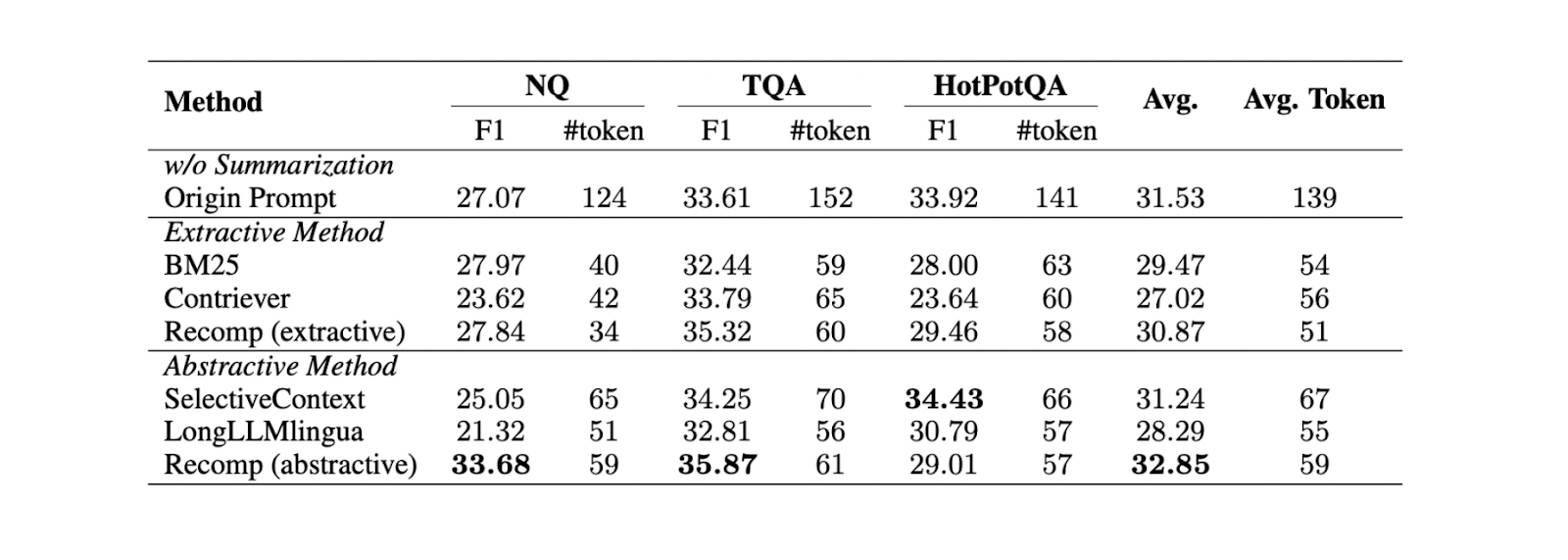 Figure- Comparaison entre différentes méthodes de résumé..png
Figure- Comparaison entre différentes méthodes de résumé..png
Figure : Comparaison entre différentes méthodes de résumé._ Source
Sur la base d'expériences menées sur trois ensembles de données différents (NQ, TriviaQA et HotpotQA), le résumé abstractif avec Recomp offre les meilleures performances par rapport à d'autres méthodes abstractives et extractives.
Le résumé des meilleures techniques de RAG
Maintenant que nous connaissons la meilleure approche pour chaque composant RAG pour des ensembles de données de référence spécifiques, nous pouvons tester toutes les approches mentionnées dans les sections précédentes sur d'autres ensembles de données. Les résultats montrent que chaque composant contribue à la performance globale de notre application RAG. Vous trouverez ci-dessous un résumé des résultats de chaque approche pour chaque composante sur la base de cinq ensembles de données différents :
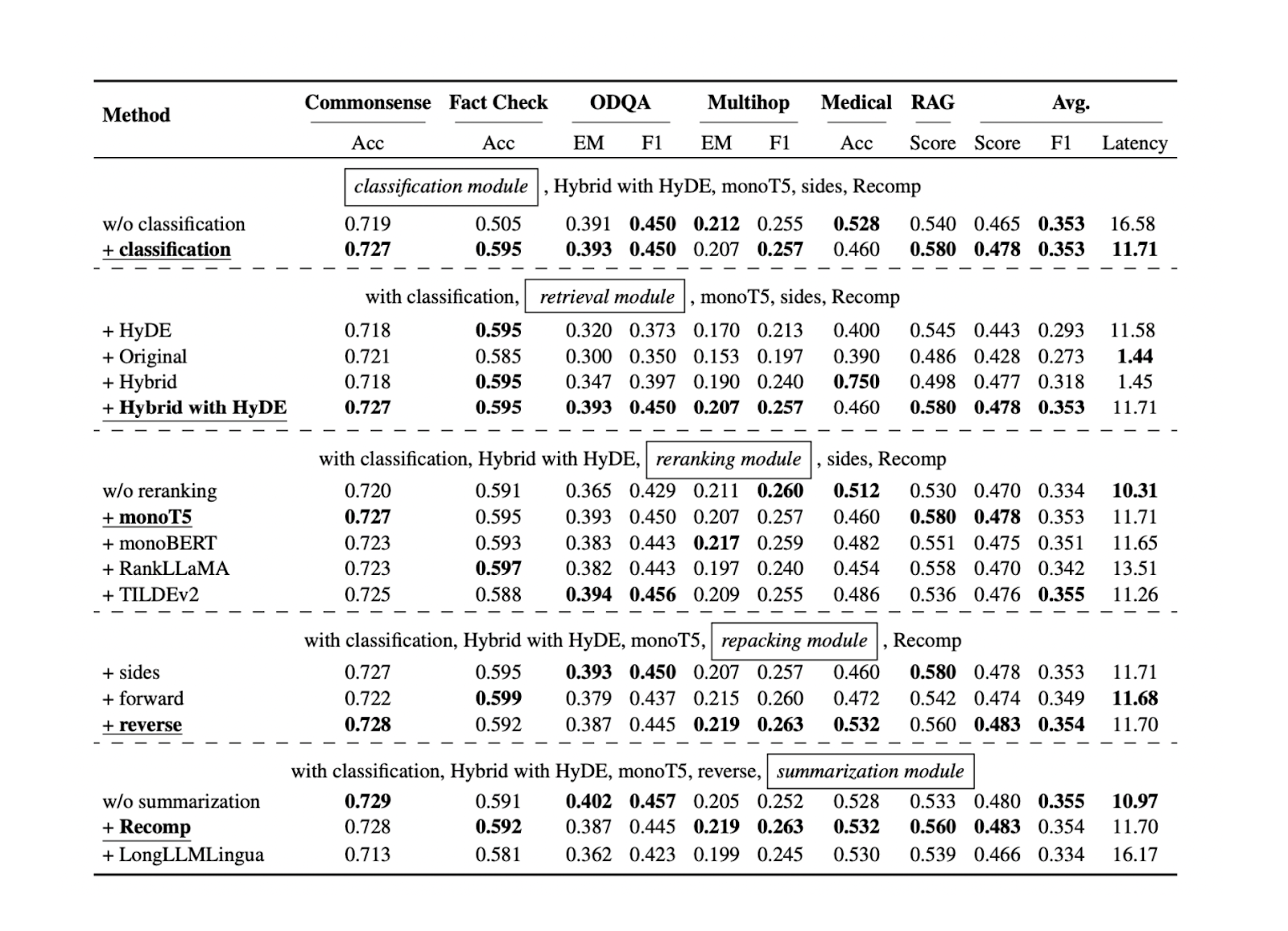 Figure- Résultats de la recherche des pratiques optimales de RAG..png
Figure- Résultats de la recherche des pratiques optimales de RAG..png
Figure : Résultats de la recherche de pratiques optimales en matière de GAR._ Source
La composante de classification des requêtes s'avère contribuer à améliorer la précision des réponses et à réduire le temps de latence global. Cette étape initiale permet de déterminer si une requête nécessite une recherche contextuelle ou peut être traitée directement par le LLM, optimisant ainsi l'efficacité du système.
La composante de récupération est cruciale pour garantir que nous obtenons des candidats contextuels pertinents par rapport à la requête. Pour cette composante, il est recommandé d'utiliser une base de données vectorielle plus évolutive et plus performante comme [Milvus] (https://milvus.io/docs/overview.md) ou son service géré, [Zilliz Cloud] (https://zilliz.com/cloud). En outre, il est recommandé d'utiliser la recherche hybride ou la recherche par intégration dense. Ces méthodes permettent de trouver un équilibre entre la correspondance contextuelle complète et l'efficacité informatique.
Le composant de reclassement garantit que nous obtenons les contextes les plus pertinents en réordonnant les k contextes les plus importants récupérés par le composant de recherche. Le modèle monoT5 est recommandé pour le reranking en raison de son équilibre entre les performances et le coût de calcul. Cette étape affine la sélection des contextes, en donnant la priorité aux contextes les plus pertinents par rapport à la requête.
La méthode inverse est recommandée pour reconditionner le contexte. Cette approche positionne le contexte le plus pertinent au plus près de la requête, ce qui peut conduire à des réponses plus précises et plus cohérentes de la part du LLM.
Enfin, la méthode abstractive avec Recomp a montré la meilleure performance pour le résumé de contexte. Cette technique permet de condenser de longs contextes tout en préservant les informations clés, ce qui facilite le traitement et la génération de réponses pertinentes par le LLM.
Réglage fin du LLM
Dans la plupart des cas, le réglage fin du LLM n'est pas nécessaire, en particulier si vous utilisez un LLM performant avec de nombreux paramètres. Cependant, si vous avez des contraintes matérielles et que vous ne pouvez utiliser que des LLM plus petits, vous devrez peut-être les affiner pour les rendre plus robustes lors de la génération de réponses liées à votre cas d'utilisation. Avant d'affiner un LLM, vous devez prendre en compte les données que vous utiliserez comme données d'entraînement.
Lors de la préparation des données, vous pouvez collecter des données de formation sous forme d'invite et de contexte en tant que paire d'entrées, avec un exemple de texte généré en tant que sortie. Les expériences montrent que l'augmentation de vos données avec un mélange de contextes pertinents et de contextes sélectionnés de manière aléatoire pendant la formation permet d'obtenir les meilleures performances. L'intuition sous-jacente est que le mélange de contextes pertinents et aléatoires pendant le réglage fin peut améliorer la robustesse de notre LLM.
Conclusion
Dans cet article, nous avons exploré les différents composants de RAG, de la classification des requêtes au résumé de contexte. Nous avons discuté et mis en évidence les approches ayant des performances optimales dans chaque composante.
Ces composants optimisés travaillent ensemble pour améliorer la performance globale du système RAG. Ils améliorent la qualité et la pertinence des réponses générées tout en maintenant l'efficacité des calculs. En mettant en œuvre ces meilleures pratiques dans chaque composante, nous pouvons créer un système RAG plus robuste et plus efficace, capable de traiter un large éventail de requêtes et de tâches.
Pour en savoir plus
Generative AI Resource Hub | Zilliz](https://zilliz.com/learn/generative-ai)
Modèles d'IA les plus performants pour vos applications GenAI | Zilliz
Construire des applications d'IA avec Milvus : Tutoriels et carnets de notes
Comment construire un RAG multilingue avec Milvus, LangChain et OpenAI
Construire un RAG multimodal avec Gemini, BGE-M3, Milvus et LangChain
Qu'est-ce que GraphRAG ? Améliorer RAG avec des graphes de connaissances
Continuer à lire

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.