




De la base de données vectorielle au Vector Lakebase
Aujourd’hui, nous lançons la préversion publique de Zilliz Vector Lakebase — le prochain chapitre pour Zilliz Cloud. Vector Lakebase est l’étape suivante au-delà des bases de données vectorielles. Il s’agit d’une plateforme de données centrée sur la sémantique où le stockage ouvert et le calcul élastique convergent pour les charges de travail d’IA.
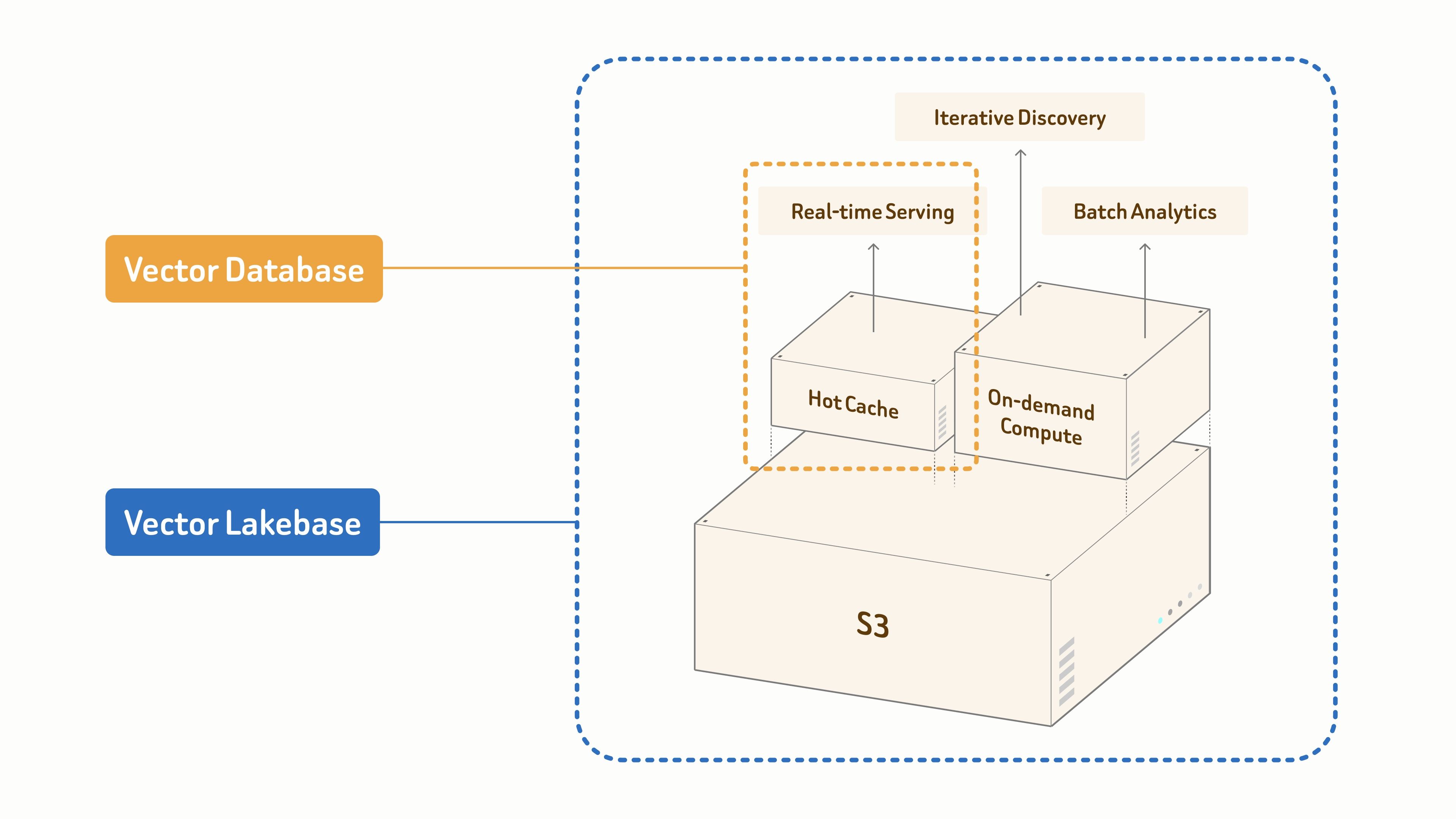
- Les bases de données vectorielles sont spécialement conçues pour le service en temps réel.
- Vector Lakebase s’appuie sur une fondation de données unifiée basée sur S3 pour alimenter l’IA et les agents selon trois modes de charge de travail :
- récupération en temps réel pour le service en production critique en latence,
- découverte itérative pour l’exploration interactive et en plusieurs étapes,
- analytique par lots pour l’exploration hors ligne et l’optimisation des jeux de données.
Le tout avec une mise à l’échelle allant des gigaoctets aux pétaoctets.
Pourquoi la fondation de données unifiée et les trois modes de charge de travail sont-ils vraiment importants ?
En bref : parce que les systèmes d’IA ne se résument plus à un problème de récupération par requête unique. Ils fonctionnent comme une boucle continue de service, d’apprentissage et d’amélioration.
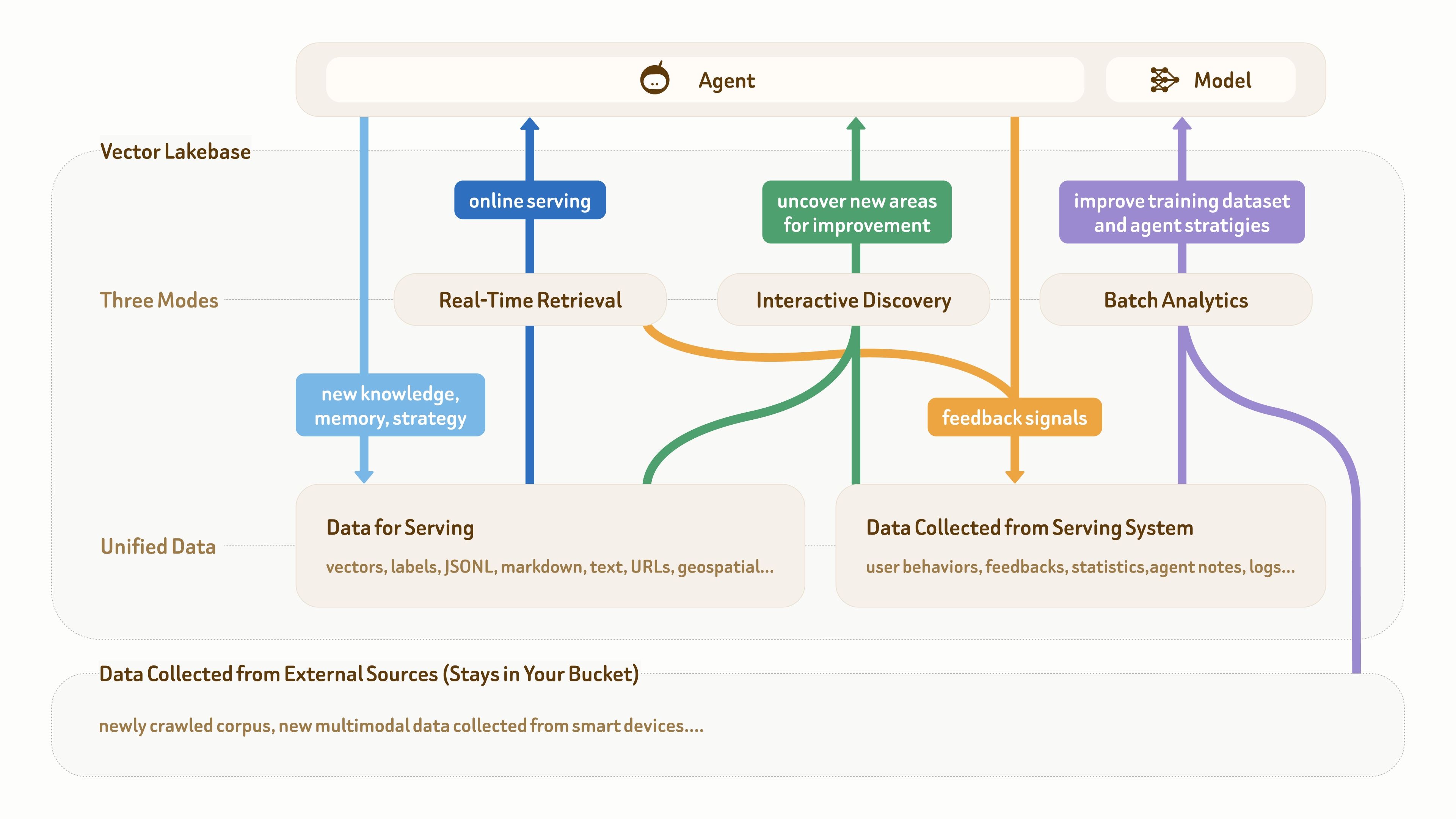
Comme le montre cette figure, la fondation de données pour les applications d’IA et d’agents comporte généralement trois parties : des données multimodales brutes en bas, des données sémantiques pour le service en ligne (telles que du texte, des vecteurs et des étiquettes), et des données de feedback collectées à partir des systèmes de production (telles que le comportement des utilisateurs, les journaux, les notes d’agents et les statistiques).
De nombreuses applications d’agents matures disposent déjà de ce type de fondation de données. Le véritable point de douleur est que ces différents types de données sont souvent dispersés entre plusieurs pipelines et systèmes, sans plan de données unifié et structuré pour prendre en charge la boucle de workflow :
service en ligne (bleu foncé) → accumulation de connaissances et de feedback (bleu clair et orange) → découverte d’insights (vert) → amélioration des jeux de données et des stratégies (violet) → meilleur service en ligne.
Comme l’image le montre également, une base de données vectorielle seule ne suffit plus, car elle prend principalement en charge la récupération en temps réel et les écritures de données orientées service (les deux chemins bleus). Dans cette boucle, les deux autres modes d’accès — découverte interactive et analytique par lots — sont tout aussi importants.
Par exemple, les développeurs d’IA (manuellement ou via des systèmes agentiques) doivent souvent explorer les données de feedback et le corpus sous-jacent pour comprendre pourquoi la qualité du service est médiocre. Ils peuvent également exécuter une déduplication et un clustering sémantiques à grande échelle sur des données récemment explorées, puis explorer les clusters de bord pour découvrir de nouveaux candidats de données d’entraînement.
Ces charges de travail sont très différentes du traitement traditionnel du big data. Le calcul central est sémantique plutôt que numérique. Les données se composent principalement de vecteurs, de texte, d’étiquettes et de métadonnées sémantiques, tandis que les opérations principales incluent la recherche vectorielle, la recherche plein texte, le reranking, le clustering sémantique et les tâches de récupération sémantique associées.
De ce fait, la découverte interactive et l’analytique par lots s’alignent naturellement avec les bases de données vectorielles, tant au niveau des données que du calcul. Dans de nombreux cas, le service en ligne et le traitement hors ligne partagent même la même fondation de données sous-jacente.
Par exemple, les équipes peuvent regrouper et analyser hors ligne des tâches utilisateur à forte valeur tout en vérifiant simultanément si les connaissances ou stratégies de support dans le système de service présentent des problèmes de rareté ou de qualité.
Dans l’ensemble, toute architecture de données fragmentée ou tout îlot d’infrastructure isolé ralentit cette boucle — ce qui peut être fatal dans la course en évolution rapide aux capacités d’IA. Vector Lakebase accélère cette boucle grâce à une approche simple mais efficace : fournir un plan de données sémantique sans copie accessible efficacement par les trois modes de charge de travail — récupération en temps réel, découverte interactive et analytique par lots.
Les fonctionnalités clés de Vector Lakebase
Zilliz Vector Lakebase prend en charge cette boucle de workflow grâce à cinq capacités fondamentales :
- Solutions de service par niveaux
Niveaux de service flexibles optimisés pour différentes charges de travail en temps réel — offrant des performances ultra-élevées, une efficacité équilibrée et une mise à l’échelle rentable sur des jeux de données massifs. - Recherche à la demande
Conçue pour les charges de travail à grande échelle où la latence est moins critique et où le calcul reste inactif la plupart du temps — notamment la recherche peu fréquente, l’exploration de données et l’analytique par lots. - Recherche dans un lac de données externe
Ajoutez des capacités d’indexation de pointe et de recherche à grande échelle directement à vos données de lac existantes. - Recherche à spectre complet Du vectoriel et du texte au JSON et au géospatial—combinés à la récupération hybride, au filtrage et au reranking pour des requêtes multimodales expressives.
- Stockage unifié lake-native
Stockage unifié pour le service et l’analytique, construit sur Vortex — un format ouvert de nouvelle génération offrant des lectures aléatoires plus rapides et moins coûteuses que Lance et Parquet, ainsi qu’une flexibilité de format par colonne et des capacités de modélisation des données plus étendues.
Solutions de service en temps réel par niveaux
Les solutions de service par niveaux de Zilliz Cloud proposent trois niveaux de service : Performance-Optimized, Capacity-Optimized et Tiered-Storage. Chaque niveau est conçu avec des algorithmes d’indexation dédiés et des stratégies de placement des données dans la hiérarchie de stockage, offrant un large éventail de compromis entre performance et coût.
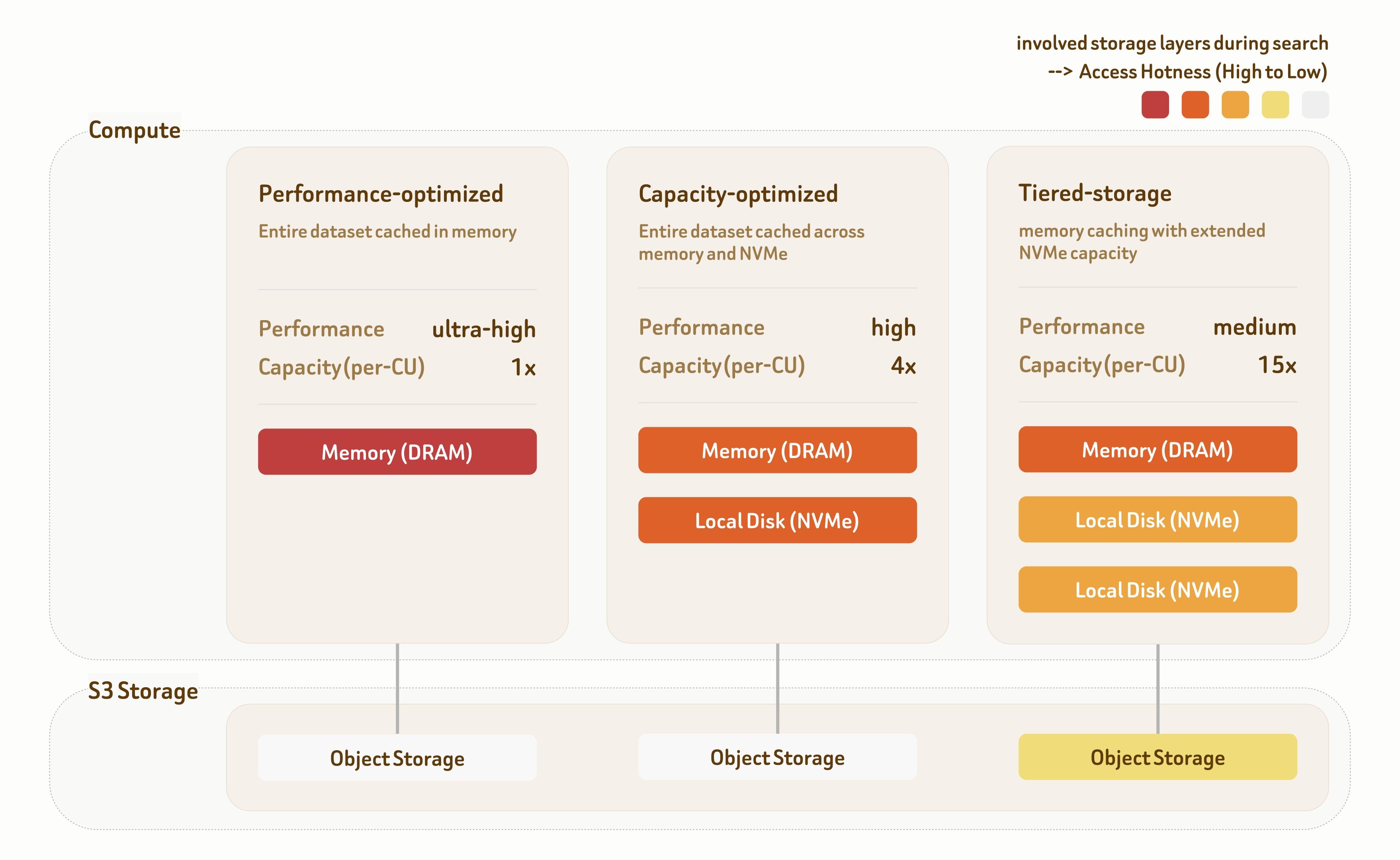
Le niveau Performance-Optimized cible les scénarios de performances ultra-élevées. Toutes les données sont servies directement depuis la mémoire, offrant plus de 1000 QPS avec une latence en millisecondes à un seul chiffre. Le débit évolue en outre linéairement avec un déploiement multi-réplicas.
Le niveau Capacity-Optimized combine la mémoire et le stockage NVMe local afin d’équilibrer performance et capacité. Il offre 100~500 QPS avec une latence inférieure à 100 ms, ce qui le rend adapté à la plupart des charges de travail de récupération.
Le niveau Tiered-Storage couvre la mémoire, le NVMe local et le stockage objet. Grâce à des stratégies de prélecture et de mise en cache hautement optimisées, plus de 95 % des accès aux données atteignent encore la mémoire ou le disque local, fournissant 10~50 QPS avec une latence d’environ 100 ms à un coût d’infrastructure nettement inférieur.
Les trois niveaux offrent 95 %–98 % de rappel par défaut, avec un réglage flexible de l’indexation et de la recherche—prenant en charge un rappel de 90 % à 99 %+ selon les exigences de la charge de travail.
Ces architectures de service ont fait leurs preuves dans certaines des charges de travail d’IA et d’Internet à grande échelle les plus exigeantes au monde, notamment :
- des plateformes d’IA multi-locataires à l’échelle d’Internet,
- des niveaux de service différenciés pour les utilisateurs d’entreprise premium comme pour les grands pools d’utilisateurs gratuits,
- des bases de connaissances d’agents hautes performances,
- des systèmes de recommandation à débit ultra-élevé,
- des moteurs de recherche IA à l’échelle du web,
- une planification dynamique des données chaudes/froides au niveau de la seconde entre les niveaux de stockage,
- des pipelines d’exploration de données pour la conduite autonome à l’échelle de 100B+ sous des contraintes de coûts extrêmes.
Pour le service en ligne, Zilliz Cloud fournit également des capacités de cluster global pour une haute disponibilité interrégionale et la reprise après sinistre, soutenues par un SLA de disponibilité de 99,99 %.
Recherche à la demande
La découverte interactive et l’analytique par lots opèrent souvent sur des volumes de données supérieurs d’un à trois ordres de grandeur à ceux du service en ligne, en particulier lorsqu’ils incluent des données de retour, des notes générées par des agents, des journaux et des corpus explorés. Ces jeux de données peuvent facilement atteindre l’échelle du To, voire du Po. Mais l’utilisation de centaines, voire de milliers de nœuds de base de données vectorielle pour les servir est souvent difficile à justifier du point de vue coût–bénéfice.

Plus important encore, ces charges de travail sont généralement pilotées par des tâches. Contrairement à la couche de service en ligne des applications d’agents, elles ne nécessitent pas une infrastructure active 24/7. Les ressources de calcul ne sont fortement utilisées que pendant les tâches de traitement actives, tout en restant inactives la plupart du temps, souvent avec plus de 97 % de temps d’inactivité.
Les solutions de service serverless peuvent sembler attrayantes, mais elles deviennent souvent beaucoup plus coûteuses pour ces charges de travail.
Au niveau de la couche de calcul, les systèmes serverless et On-Demand Search suivent tous deux un modèle de paiement à l’usage. Malgré des différences dans les modèles de tarification détaillés, le coût de calcul sous-jacent est souvent similaire. Cependant, dans une architecture serverless, les surcoûts liés à la mutualisation, à l’indexation et aux données persistantes sont intégrés dans des majorations supplémentaires sur les écritures et le stockage, plutôt que de refléter directement le coût réel des ressources sous-jacentes.
À l’inverse, Zilliz On-Demand Search facture directement le stockage objet et le calcul à la demande — de manière similaire à AWS Lambda, où la tarification repose principalement sur la taille des ressources allouées et le temps d’exécution, tandis que le coût de stockage reste proche du coût S3 sous-jacent. Cela évite les surcoûts d’infrastructure cachés et les modèles de tarification opaques.
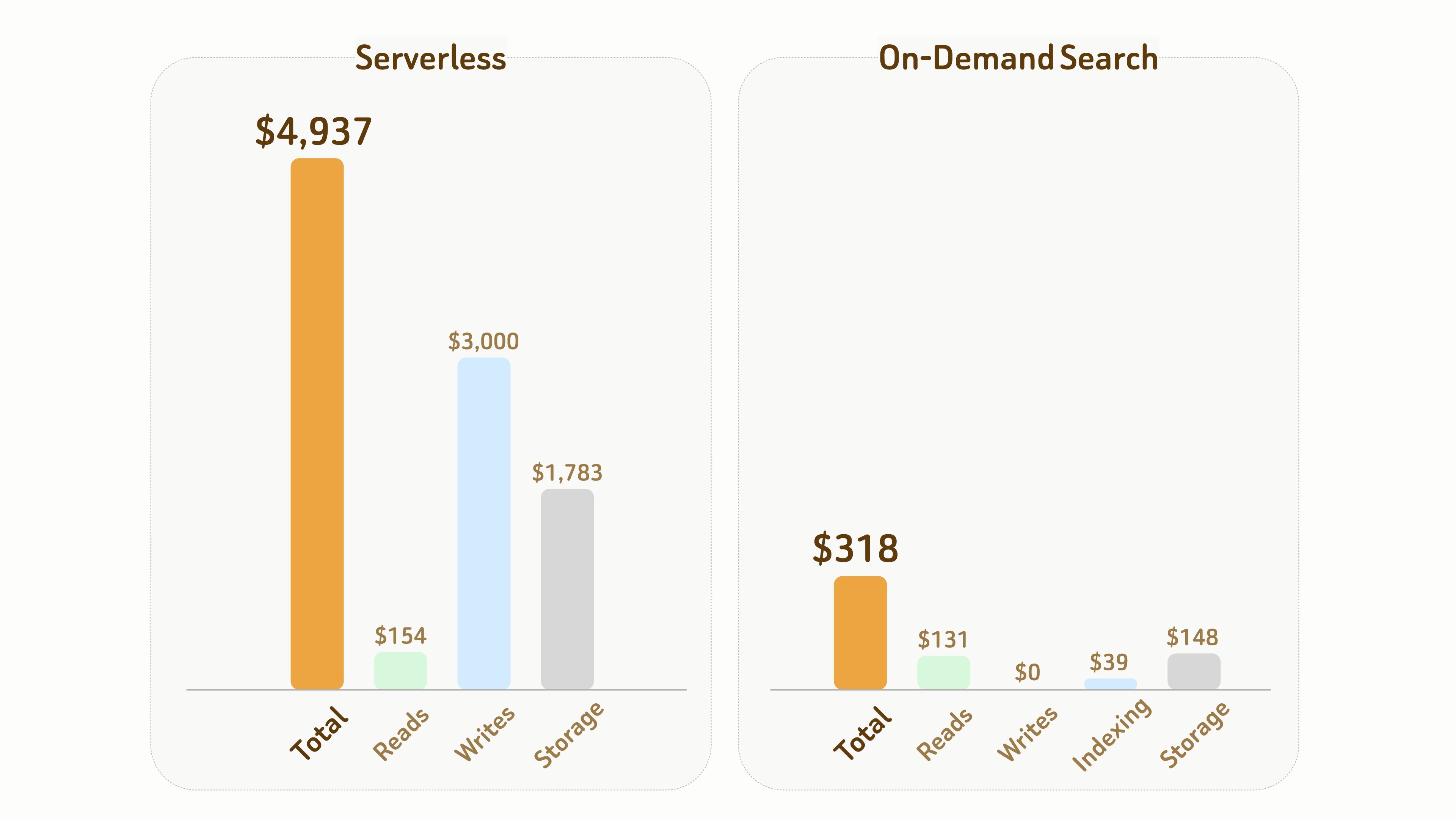
La comparaison suivante illustre la différence de coût entre Serverless et On-Demand Search.
Configuration :
- 1B vecteurs avec 768 dimensions, nécessitant environ 6 To de stockage, fichiers de données et d’index inclus,
- 1 mois de durée avec 10 heures de temps de calcul actif accumulé.
Dans l’ensemble, dans cette expérience, le coût total d’On-Demand Search n’est que d’environ 1/15 ($318 contre $4,937) de celui de Serverless.
Recherche dans un lac de données externe
Zilliz Vector Lakebase fournit un stockage et un calcul de requêtes entièrement gérés, permettant aux utilisateurs de stocker et d’exploiter leurs données directement dans Zilliz Cloud. Cependant, certains clients disposent déjà d’une infrastructure de lac de données mature et de pipelines de gouvernance en place.
Pour les applications d’IA, l’un des principaux défis consiste à permettre une récupération efficace et une exploration sémantique directement au-dessus des données de lac existantes. Les systèmes traditionnels de big data tels que Spark et Ray ne sont pas optimisés pour ces charges de travail, car ils sont fondamentalement conçus autour du scan complet des données et du calcul map-reduce plutôt que de requêtes accélérées par index et de récupération sémantique.
Pour résoudre ce problème, Zilliz fournit un mode External Collection. Il crée une correspondance logique zéro copie entre le plan de données Zilliz et les tables de lac appartenant au client, tout en permettant des index hautes performances et une recherche complète sur cette correspondance.
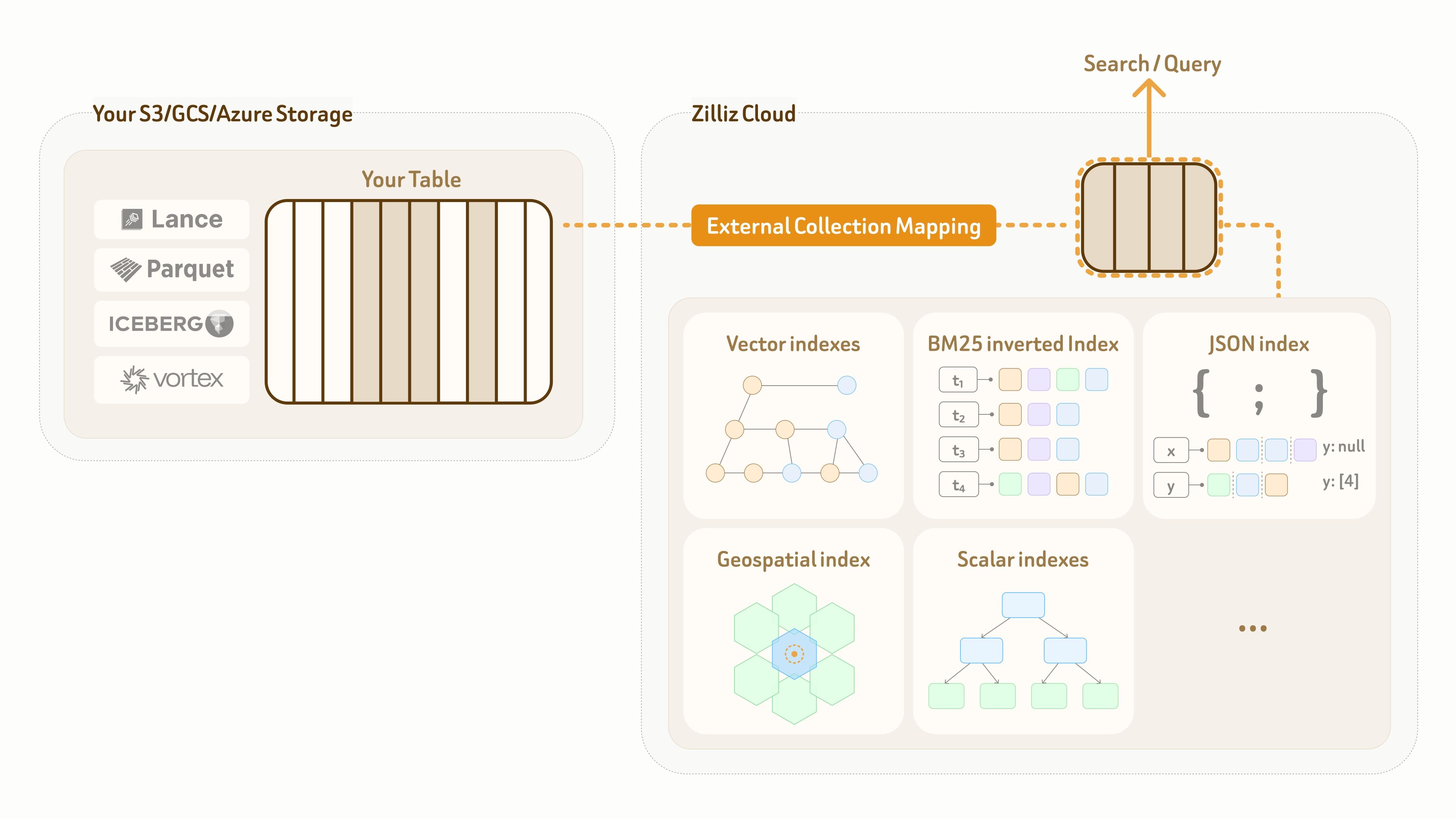
Actuellement, External Collection prend en charge deux formats de tables de lac de données — Lance et Iceberg, ainsi que deux formats de données ouverts — Parquet et Vortex.
Pour les mises à jour du lac de données, Zilliz External Collection fournit des capacités de synchronisation incrémentielle. En fonction du schéma de mise à jour du lac de données et des exigences de visibilité des requêtes, les utilisateurs peuvent synchroniser les données à tout moment avec un appel de rafraîchissement.
Recherche full-spectrum
Les applications d’IA ont de plus en plus besoin de récupérer et d’analyser des données provenant de différentes sources et modalités — à la fois pour combiner des informations complémentaires et pour extraire plusieurs perspectives du même contenu brut afin d’améliorer la qualité de la récupération et de l’analyse.
Zilliz Vector Lakebase prend en charge la modélisation en table large avec des types de données riches, notamment des vecteurs denses et clairsemés, du texte, JSON, des données géospatiales et des types primitifs, ainsi que des structures complexes telles que Struct et Array — permettant une modélisation sémantique imbriquée efficace directement au sein d’une disposition de table unifiée.

Cela permet une modélisation unifiée du contexte en associant chaque entité au niveau applicatif directement à une seule ligne. Par exemple, au lieu de diviser un document en centaines de lignes pour les segments de texte, les images et les tableaux, Zilliz Vector Lakebase peut modéliser l’intégralité du document comme une seule ligne. Cela améliore la récupération et l’analytique multimodales tout en évitant les surcoûts de performance et d’exploitation liés aux JOINs et aux agrégations.
Au-delà de la modélisation des données, Vector Lakebase fournit également des capacités d’indexation et de recherche de pointe pour tous les types de données pris en charge. Les capacités détaillées sont listées ci-dessous :
| Vector Search | Algorithmes d’indexation avancés surpassant HNSW, IVF et RaBitQ, avec 10 niveaux d’ajustement rappel-latence. |
|---|---|
| Full-Text Search | Recherche en texte intégral avec BM25, expressions, préfixes, correspondance approximative et un large éventail d’analyseurs. |
| Grep | Prise en charge regex intégrée couvrant la plupart des motifs de correspondance de style grep. |
| Hybrid Search | Recherche vectorielle hybride dense et clairsemée pour améliorer le rappel et la pertinence. |
| Query on JSON | Découpage et indexation JSON intégrés pour un filtrage et des requêtes rapides sur des champs JSON imbriqués. |
| Geospatial Search | Recherche géospatiale rapide avec filtrage par rayon, plus proche voisin et zone. |
| Multi-Vector Search | Recherche sur plusieurs embeddings générés à partir d’une ou plusieurs modalités, avec reclassement unifié. |
| Vector Search with Filtering | Recherche vectorielle avec filtrage par attributs, optimisée sur une sélectivité de filtre faible à élevée. |
| Range Search | Renvoie tous les vecteurs situés dans un seuil de distance spécifié par rapport au vecteur de requête. |
| Iterative Search | Recherche itérative avec affinement progressif de la requête basé sur les résultats intermédiaires. |
| Multi-Path Retrieval | Récupération multi-chemins avec plusieurs stratégies, chaque chemin pouvant utiliser n’importe laquelle des méthodes de recherche ci-dessus. |
ainsi que des capacités de reclassement utilisées conjointement avec la récupération multi-chemins.
| Cohere Reranker | Un modèle de reclassement cross-encoder qui note les paires requête–document avec une grande précision sémantique afin de réordonner les résultats de récupération pour une pertinence maximale. |
|---|---|
| Voyage AI Reranker | Un modèle de reclassement léger et à haut débit, optimisé pour une notation de pertinence rapide et économique dans les pipelines de récupération à grande échelle. |
| Boost Reranker | Applique des filtres conditionnels aux résultats correspondants et ajuste leurs scores avec un poids spécifié afin de promouvoir ou de rétrograder les classements. |
| Decay Reranker | Ajuste les scores des résultats en appliquant une fonction de décroissance basée sur des facteurs tels que la distance ou le temps, diminuant progressivement la pertinence à mesure que les valeurs s’écartent d’une cible. |
| RRF Reranker | Fusionne plusieurs listes de résultats en combinant les positions de classement de chaque élément dans les listes en un classement unique. |
| Weighted Reranker | Combine les scores de plusieurs listes de résultats à l’aide de poids configurables pour produire un classement unifié. |
Stockage unifié natif du lake
Zilliz Cloud repose sur une architecture stockage–calcul entièrement découplée, avec une persistance intégrale sur le stockage objet cloud.
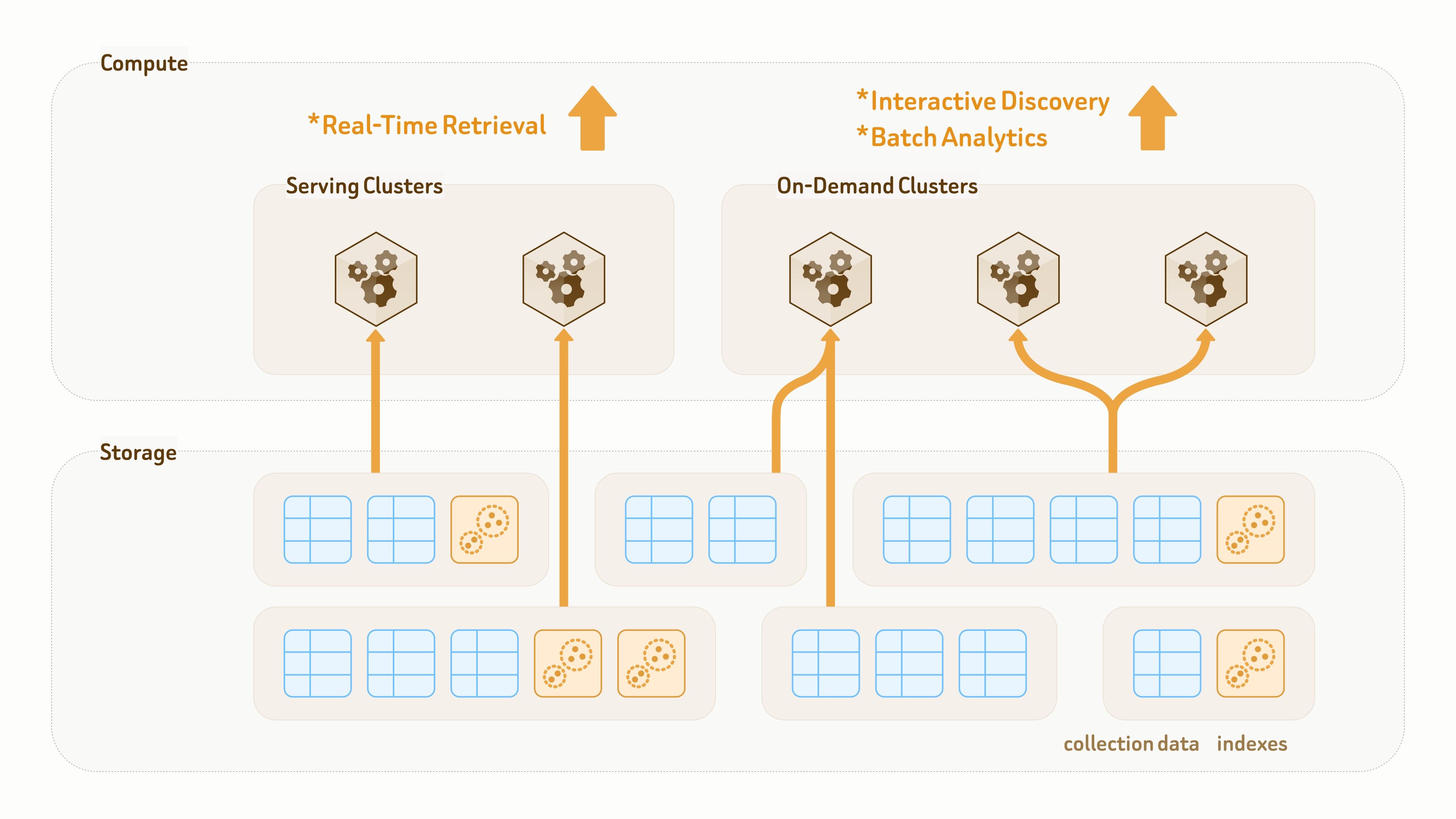
Contrairement aux data lakes traditionnels conçus principalement pour le stockage, la couche de données de Zilliz Vector Lakebase est conçue à la fois pour la persistance et l’exécution des requêtes. Les collections et les index sont découplés des clusters de calcul, ce qui permet aux mêmes données et index d’être montés via un accès sans copie par différents clusters pour différents workloads de requêtes et d’analytique.
Pour les applications d’IA et d’agents avec des modèles de données en évolution continue — comme l’ajout fréquent de nouveaux libellés et fonctionnalités ou le changement de modèles d’embedding — Zilliz fournit un mécanisme fluide et rapide d’évolution de schéma et de rétroremplissage des données.
Les nouveaux champs sont rétroremplis et alignés par des ressources de calcul de plateforme mutualisées, puis exposés aux clusters de requêtes via des mises à jour de métadonnées. Un rétroremplissage de 100 M de lignes peut généralement être réalisé en quelques minutes à un chiffre.
Comme la majeure partie du travail est prise en charge par les ressources de calcul côté plateforme, les clusters utilisateur existants ne sont pas affectés et peuvent continuer à servir le trafic de lecture et d’écriture tout au long du processus.
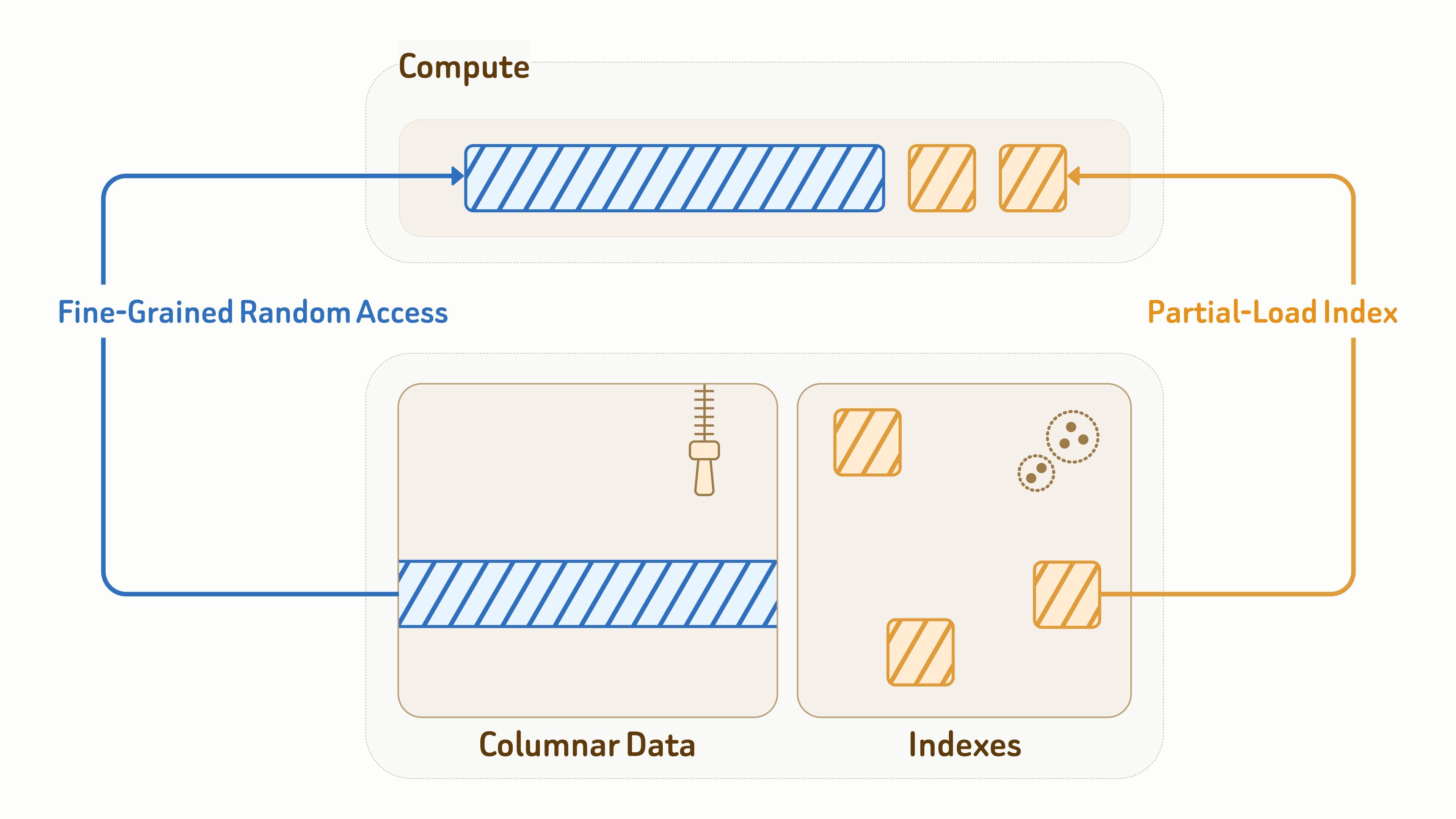
Comme la couche de données sert également directement les workloads de requêtes, des E/S efficaces sont essentielles tant pour la latence que pour le débit.
Pour les données de collection, Zilliz utilise le format ouvert Vortex pour l’organisation du stockage en colonnes, combinant un encodage efficace avec un accès aléatoire à granularité fine aux fragments de données — nettement plus rapide que Lance et Parquet pour les lectures aléatoires.
Pour les index, Zilliz fournit des conceptions d’algorithmes d’indexation adaptées au stockage objet, avec des organisations et des schémas d’accès profondément optimisés pour des E/S efficaces, notamment des index vectoriels, des index inversés BM25 et des index JSON.
Lors de l’exécution des requêtes, les nœuds de calcul ne chargent que partiellement les pages d’index et les entités de données touchées par la requête. Combiné à la mise en cache et à l’élagage des données, cela réduit considérablement l’amplification de lecture de plus de 90 %.
Principaux cas d’utilisation de Vector Lakebase
Les scénarios d’application typiques de Vector Lakebase incluent, sans s’y limiter :
Charges de travail de service en temps réel :
- Mémoire d’agent et récupération de stratégies critiques en latence.
- Bases de connaissances de domaines verticaux pour le juridique, la santé, la finance et d’autres secteurs spécialisés.
- Moteurs de recherche IA à l’échelle du Web.
- Systèmes de recommandation à ultra-haut débit.
- Planification dynamique des données chaudes/froides à l’échelle de la seconde entre les niveaux de stockage.
- Niveaux de service différenciés pour les utilisateurs d’entreprise premium comme pour les grands pools d’utilisateurs gratuits.
Charges de travail de découverte itérative :
- Analyse de la qualité des services IA et découverte de problèmes à partir de données de feedback, de notes générées par des agents, de journaux et d’autres données multi-sources.
- Exploration efficace de jeux de données à grande échelle.
- Recherche approfondie itérative en plusieurs étapes.
Charges de travail d’analyse par lots :
- Déduplication et clustering de corpus à très grande échelle.
- Ajout de capacités de recherche complètes à Spark et Ray pour un filtrage, une récupération et des pipelines de requêtes en deux étapes, de l’approximation au reranking, efficaces.
- Préparation de jeux de données pour l’entraînement et le fine-tuning.
Cas hybrides :
- Indexation et récupération accélérées sur des tables de data lake existantes telles que Lance et Iceberg.
- Modèles de données en évolution continue avec de fréquents backfills à grande échelle.
- Modélisation de tables larges sémantiques multimodales, unifiant vecteurs, métadonnées, résumés générés par des LLM et champs structurés dans des tables centrées sur les entités, avec versioning cohérent et gestion de la lignée.
Essayer Zilliz Vector Lakebase
Pour plus d’informations sur Vector Lakebase et les dernières mises à jour, visitez le site Web de Zilliz ou explorez la documentation Zilliz Cloud. Si l’architecture ou les cas d’utilisation présentés dans cet article sont pertinents pour votre travail, contactez l’équipe Zilliz pour une discussion technique plus approfondie.

Continuer à lire

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.