




Les 10 principales techniques d’ingénierie du contexte que vous devriez connaître pour le RAG en production
Lorsque nous construisons pour la première fois une démo de RAG ou d’agent, les choses fonctionnent généralement bien. Avec un petit jeu de données, quelques prompts et une récupération simple, nous pouvons souvent faire fonctionner un prototype en quelques heures.
Le véritable défi apparaît lorsque nous essayons d’exécuter le système en production. À mesure que l’utilisation augmente, les problèmes apparaissent rapidement. La récupération devient plus lente, les réponses deviennent moins fiables, la latence augmente et les coûts grimpent. Ce qui fonctionnait dans une petite démo se casse souvent lorsque de vraies données, de vrais utilisateurs et des contextes plus longs entrent en jeu.
À ce stade, nous nous rendons généralement compte que le problème ne vient pas seulement du modèle. Il concerne aussi la manière dont le contexte est préparé et transmis au modèle. C’est là qu’intervient l’ingénierie du contexte. Elle se concentre sur la récupération, l’organisation, l’affinement et la gestion des informations qu’un modèle de langage utilise pour générer des réponses.
Dans cet article, nous expliquons comment l’ingénierie du contexte fonctionne en pratique. Nous examinons des approches récentes pour construire le contexte, le traiter efficacement et le gérer dans le temps. Ces techniques aident à transformer de simples démos en systèmes capables de fonctionner de manière fiable en production.
Note : Cet article est principalement basé sur l’article https://arxiv.org/html/2507.13334v1.
Qu’est-ce que l’ingénierie du contexte ?
L’ingénierie du contexte se concentre sur l’assemblage des informations dont un grand modèle de langage a besoin pour répondre correctement à une question. Ces informations ne se limitent pas au prompt. Elles incluent également la requête de l’utilisateur, les documents récupérés, l’historique de conversation et d’autres données pertinentes. L’objectif est d’améliorer la précision, de réduire le temps de réponse et de maîtriser les coûts.
Ce travail est principalement effectué automatiquement au moyen d’algorithmes. L’ingénierie du contexte combine l’ingénierie de prompts, la génération augmentée par récupération (RAG) et les techniques multi-agents en un seul système, au lieu de les utiliser séparément.
En pratique, une configuration d’ingénierie du contexte comporte deux parties. La première se compose de composants fondamentaux qui gèrent la récupération, le traitement et l’orchestration des données. La seconde couche est constituée de systèmes complexes qui combinent ces composants en applications complètes. Les équipes peuvent mélanger et réutiliser ces éléments pour les adapter à différents scénarios de production.
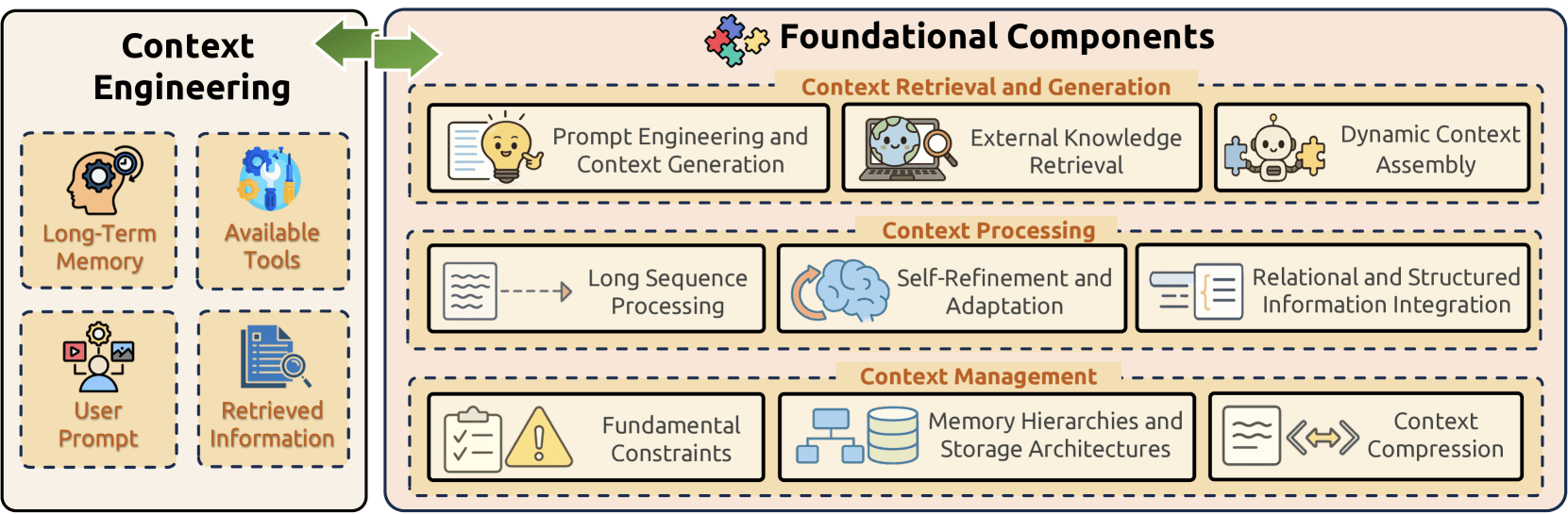
Composants fondamentaux
L’ingénierie du contexte repose sur trois composants fondamentaux qui répondent collectivement aux principaux défis de la gestion de l’information dans les grands modèles de langage :
- Récupération et génération du contexte sourcent les informations contextuelles appropriées grâce à l’ingénierie de prompts, à la récupération de connaissances externes et à l’assemblage dynamique du contexte ;
- Traitement du contexte transforme et optimise les informations acquises grâce au traitement de longues séquences, à des mécanismes d’auto-affinement et à l’intégration de données structurées ;
- Gestion du contexte s’attaque à l’organisation et à l’utilisation efficaces des informations contextuelles en traitant les contraintes fondamentales, en mettant en œuvre des hiérarchies de mémoire sophistiquées et en développant des techniques de compression.
Systèmes complexes en pratique
Au-dessus de ces composants fondamentaux, l’ingénierie du contexte est appliquée à travers plusieurs types courants de systèmes complexes.
La génération augmentée par récupération (RAG) permet à un modèle de rechercher des informations dans une base de connaissances avant de répondre à une question. Cela permet de s’assurer que la réponse repose sur des données réelles et à jour, plutôt que sur des suppositions du modèle. En pratique, la RAG peut être construite sous forme de simples pipelines modulaires, pilotée par des agents qui contrôlent la récupération, ou combinée avec des graphes de connaissances pour un contexte plus riche.
Les systèmes de mémoire permettent aux modèles de suivre les informations au fil des interactions. La mémoire à court terme conserve les détails de la conversation en cours, tandis que la mémoire à long terme stocke les conversations passées et les connaissances apprises. Cela rend les conversations à plusieurs tours plus cohérentes et aide le système à s’améliorer au fil du temps.
Le raisonnement intégré aux outils permet aux modèles d’utiliser des outils externes tels que des calculatrices, des moteurs de recherche ou des API au lieu de s’appuyer uniquement sur le raisonnement textuel. Un aspect important de cette configuration consiste à réinsérer les résultats des outils dans le contexte au bon moment afin que le modèle puisse les utiliser efficacement.
Les systèmes multi-agents utilisent plusieurs modèles qui collaborent pour gérer des tâches complexes. Chaque agent a un rôle spécifique, et le système coordonne la manière dont ils communiquent, partagent les informations et restent synchronisés afin de produire un résultat cohérent.
Traitement du contexte
Précédemment, nous avons présenté les trois principales parties de l’ingénierie du contexte : récupération et génération du contexte, traitement du contexte et gestion du contexte. Elles constituent les briques de base d’un système de contexte pratique.
Le traitement du contexte est particulièrement important. Il prend les informations brutes récupérées, les nettoie, les remodèle et les organise afin que le modèle puisse les comprendre et les utiliser plus efficacement.
Dans cette section, nous examinons comment le traitement du contexte est effectué dans des systèmes réels et quelles approches sont couramment utilisées.
Traitement des contextes longs
Le traitement de contextes très longs est coûteux, car les modèles Transformer utilisent l’auto-attention, qui évolue mal lorsque la longueur d’entrée augmente. À mesure que la séquence s’allonge, le calcul et l’utilisation de la mémoire augmentent rapidement, créant de véritables goulots d’étranglement dans les systèmes de production.
Par exemple, étendre la longueur d’entrée de Mistral-7B de 4K à 128K tokens augmente le coût de calcul d’environ 122×. L’utilisation de la mémoire augmente également fortement lors du préremplissage comme du décodage. En pratique, des modèles comme Llama 3.1 8B peuvent nécessiter jusqu’à 16 Go de mémoire pour une seule requête de 128K tokens.
Pour contourner ces limites, les chercheurs utilisent principalement trois approches.
L’une consiste à construire de nouvelles architectures de modèles, telles que Mamba, qui sont moins coûteuses à exécuter par conception. Une autre consiste à utiliser des techniques comme l’interpolation positionnelle pour permettre aux modèles existants de gérer des entrées beaucoup plus longues. La troisième approche améliore la manière dont le calcul est effectué, en évitant le travail redondant et en utilisant la mémoire plus efficacement, afin que le traitement de contextes longs soit plus rapide et consomme moins de ressources.
(1) Innovations architecturales pour les contextes longs
Pour faire face au coût quadratique des Transformers, les chercheurs ont développé de nouvelles architectures de modèles qui rendent le traitement des longues séquences moins coûteux et plus efficace.
- Les modèles d’espace d’états (SSMs) maintiennent une complexité de calcul linéaire et des besoins mémoire constants grâce à des états cachés de taille fixe, avec des modèles comme Mamba offrant des mécanismes de calcul récurrent efficaces qui s’adaptent plus efficacement que les transformers traditionnels.
- L’attention dilatée des approches comme LongNet emploie des champs attentionnels qui s’élargissent exponentiellement à mesure que la distance entre tokens augmente, atteignant une complexité de calcul linéaire tout en maintenant une dépendance logarithmique entre les tokens, ce qui permet de traiter des séquences de plus d’un milliard de tokens.
- Les réseaux neuronaux de Toeplitz (TNNs) modélisent les séquences avec des matrices de Toeplitz encodées par position relative, réduisant la complexité espace-temps à une complexité log-linéaire et permettant l’extrapolation de 512 tokens d’entraînement à 14 000 tokens d’inférence.
- Les mécanismes d’attention linéaire réduisent la complexité de O(N²) à O(N) en exprimant l’auto-attention comme des produits scalaires linéaires de cartes de caractéristiques de noyau, atteignant jusqu’à 4000× d’accélération lors du traitement de très longues séquences.
Des approches alternatives, comme les LLMs sans attention, franchissent les barrières quadratiques en employant des transformers à mémoire récursive et d’autres innovations architecturales.
(2) Interpolation positionnelle et extension du contexte
Les techniques d’interpolation positionnelle permettent aux modèles de traiter des séquences au-delà des limites de la fenêtre de contexte d’origine en redimensionnant intelligemment les indices de position plutôt qu’en extrapolant vers des positions inédites.
- Les approches par noyau tangent neuronal (NTK) fournissent des cadres mathématiquement fondés pour l’extension du contexte, YaRN (Yet another RoPE-based Interpolation method) combinant l’interpolation NTK avec l’interpolation linéaire et la correction de la distribution de l’attention.
- Approches en deux étapes : LongRoPE atteint des fenêtres contextuelles de 2048K tokens grâce à des approches en deux étapes : d’abord en affinant les modèles jusqu’à une longueur de 256K, puis en effectuant une interpolation positionnelle pour atteindre la longueur de contexte maximale.
- Position Sequence Tuning (PoSE) démontre des extensions impressionnantes de longueur de séquence jusqu’à 128K tokens en combinant plusieurs stratégies d’interpolation positionnelle.
- Les techniques Self-Extend permettent aux LLM de traiter de longs contextes sans affinage en employant des stratégies d’attention à deux niveaux — attention groupée et attention de voisinage — afin de capturer les dépendances entre tokens distants et adjacents.
(3) Techniques d’optimisation pour un traitement efficace
Sans modifier l’architecture centrale du modèle, les chercheurs ont également développé une gamme de techniques d’optimisation pour rendre le traitement des longs contextes plus efficace.
Grouped-Query Attention (GQA) partitionne les têtes de requête en groupes qui partagent les têtes de clé et de valeur, trouvant un équilibre entre l’attention multi-requêtes et l’attention multi-têtes tout en réduisant les besoins en mémoire pendant le décodage.
FlashAttention exploite la hiérarchie asymétrique de la mémoire GPU pour atteindre une mise à l’échelle linéaire de la mémoire au lieu d’exigences quadratiques, FlashAttention-2 offrant environ deux fois plus de vitesse grâce à la réduction des opérations hors multiplication matricielle et à une répartition du travail optimisée.
Ring Attention avec Blockwise Transformers permet de gérer des séquences extrêmement longues en distribuant le calcul sur plusieurs dispositifs, en tirant parti du calcul par blocs tout en chevauchant la communication avec le calcul de l’attention.
Les techniques d’attention éparse incluent Shifted sparse attention (S²-Attn) dans LongLoRA et SinkLoRA avec SF-Attn, qui atteignent 92 % de l’amélioration de la perplexité de l’attention complète avec des économies de calcul significatives.
La gestion de la mémoire et la compression du contexte réduisent le coût des entrées longues. Rolling Buffer Cache limite la fenêtre d’attention pour réduire la mémoire du cache KV, tandis que StreamingLLM prend en charge les longues séquences en ne conservant que les tokens clés et le contexte récent. D’autres méthodes comme Infini-attention et H2O améliorent l’efficacité grâce à une mémoire compressive et à une éviction de cache plus intelligente.
Auto-raffinement et adaptation contextuels
L’auto-raffinement permet aux LLM d’améliorer les sorties grâce à des mécanismes de rétroaction cycliques reflétant les processus de révision humains, en exploitant l’auto-évaluation par auto-interaction conversationnelle via l’ingénierie de prompts, distincte des approches d’apprentissage par renforcement.
L’idée est simple : pour les tâches complexes, il est plus facile d’écrire une première version puis de la corriger que de tout réussir du premier coup. Lorsque les modèles apprennent à vérifier leur propre travail et à l’améliorer étape par étape, ils obtiennent de meilleurs résultats en raisonnement, en écriture de code et dans les tâches créatives, et s’adaptent plus facilement aux nouvelles situations.
(1) Cadres fondamentaux d’auto-raffinement
- Le cadre Self-Refine utilise le même modèle comme générateur, fournisseur de rétroaction et raffineur, démontrant qu’identifier et corriger les erreurs est souvent plus facile que de produire des solutions initiales parfaites.
- Reflexion conserve du texte réflexif dans des tampons de mémoire épisodique pour la prise de décision future par le biais d’une rétroaction linguistique, tandis qu’un guidage structuré s’avère essentiel, car les prompts simplistes échouent souvent à permettre une auto-correction fiable.
- Le cadre N-CRITICS met en œuvre une évaluation fondée sur des ensembles, où les sorties initiales sont évaluées à la fois par les LLM générateurs et par d’autres modèles, les retours compilés guidant le raffinement jusqu’à ce que les critères d’arrêt propres à la tâche soient remplis.
(2) Méta-apprentissage et évolution autonome
À un stade plus avancé, l’auto-raffinement du contexte se concentre sur le méta-apprentissage et l’amélioration autonome. L’objectif est d’aider le modèle non seulement à résoudre des tâches, mais aussi à apprendre comment mieux apprendre au fil du temps.
SELF enseigne aux LLM des méta-compétences (auto-rétroaction, auto-raffinement) avec des exemples limités, puis amène le modèle à s’auto-faire évoluer en continu en générant et en filtrant ses propres données d’entraînement. Les mécanismes d’auto-récompense permettent aux modèles de s’améliorer de manière autonome grâce à un auto-jugement itératif, où un seul modèle adopte les doubles rôles d’exécutant et de juge, maximisant les récompenses qu’il s’attribue lui-même.
Le cadre Creator étend ce paradigme en permettant aux LLM de créer et d’utiliser leurs propres outils grâce à un processus en quatre modules englobant la création, la prise de décision, l’exécution et la reconnaissance.
Le cadre Self-Developing représente l’approche la plus autonome, permettant aux LLM de découvrir, d’implémenter et de raffiner leurs propres algorithmes d’amélioration au moyen de cycles itératifs générant des candidats algorithmiques sous forme de code exécutable.
Contexte multimodal
Les grands modèles de langage multimodaux (MLLM) vont au-delà du texte en travaillant avec des entrées comme des images, de l’audio et des données 3D. Ils combinent ces différents types d’informations en un contexte unique sur lequel le modèle peut raisonner.
Cela rend possibles des applications plus avancées, mais apporte aussi de nouveaux défis, tels que l’intégration de différentes modalités, le raisonnement entre elles et la gestion d’entrées longues et complexes.
(1) Intégration du contexte multimodal
L’intégration du contexte est au cœur du traitement du contexte multimodal. Elle vise à combiner des informations provenant de différentes modalités, telles que les images, le texte et l’audio, en une représentation unique avec laquelle un modèle peut raisonner.
Une approche de base transforme les images en tokens à l’aide d’encodeurs comme CLIP, puis les ajoute aux tokens textuels avant d’envoyer l’ensemble au modèle de langage. C’est facile à implémenter, mais les différentes modalités restent souvent faiblement connectées.
Des méthodes plus avancées améliorent l’intégration. L’attention intermodale permet au modèle d’apprendre des relations directes entre les tokens visuels et textuels à l’intérieur du modèle, ce qui est important pour des tâches comme l’édition d’images et le raisonnement visuel.
Pour passer à l’échelle avec des entrées longues ou complexes, les conceptions hiérarchiques traitent chaque modalité par étapes. Certains systèmes fusionnent aussi les informations provenant de plusieurs images ou entrées avant de les transmettre au modèle, au lieu de traiter chacune séparément.
D’autres travaux évitent complètement d’adapter des modèles uniquement textuels en s’entraînant dès le départ conjointement sur des données multimodales et du texte. Le raisonnement intermodal s’appuie sur cela, exigeant du modèle qu’il comprenne non seulement chaque modalité séparément, mais aussi le sens qui émerge lorsqu’elles sont combinées, comme le sarcasme exprimé à la fois par une image et du texte.
(2) Encodeurs multimodaux externes et modules d’alignement
L’intégration du contexte multimodal repose sur deux parties principales : les encodeurs multimodaux externes et les modules d’alignement qui les connectent au modèle de langage.
Dans la plupart des systèmes actuels, chaque type de données est traité par un encodeur dédié. Par exemple, les images sont traitées par des modèles comme CLIP, et l’audio est géré par des modèles tels que CLAP. Ces encodeurs transforment les entrées brutes, comme les pixels ou les ondes sonores, en vecteurs de caractéristiques.
Les modules d’alignement convertissent ensuite ces caractéristiques dans l’espace d’embedding du modèle de langage afin qu’elles puissent fonctionner avec les tokens textuels. Certains systèmes utilisent des mappings simples comme des MLP, tandis que d’autres utilisent Q-Former, qui sélectionne les caractéristiques visuelles les plus pertinentes pour le texte à l’aide de tokens de requête apprenables.
Cette configuration modulaire rend les systèmes plus faciles à maintenir. Les encodeurs peuvent être mis à jour ou remplacés sans réentraîner l’ensemble du modèle de langage, ce qui est important pour le déploiement dans le monde réel.
Contexte relationnel et structuré
Les grands modèles de langage font face à des contraintes fondamentales lors du traitement de données relationnelles et structurées, notamment les tableaux, les bases de données et les graphes de connaissances, en raison des exigences d’entrée fondées sur le texte et des limitations de l’architecture séquentielle.
La linéarisation échoue souvent à préserver les relations complexes et les propriétés structurelles, avec des performances qui se dégradent lorsque l’information est dispersée dans les contextes.
Pour résoudre ce problème, les chercheurs ont cherché des moyens de représenter les données structurées sous une forme que les modèles de langage peuvent utiliser. L’objectif est d’aider les modèles à obtenir de meilleures performances sur les tâches impliquant un raisonnement complexe et la vérification des faits.
(1) Knowledge Graph Embeddings et intégration neuronale
Les stratégies d’encodage avancées répondent aux limites structurelles grâce aux knowledge graph embeddings qui transforment les entités et les relations en vecteurs numériques, permettant un traitement efficace au sein des architectures de modèles de langage.
Les réseaux neuronaux de graphes capturent les relations complexes entre les entités, facilitant le raisonnement multi-sauts à travers les structures de graphes de connaissances grâce à des architectures spécialisées comme GraphFormers, qui imbriquent des composants GNN aux côtés de blocs transformer.
(2) Verbalisation
Une approche courante consiste à transformer des données structurées — telles que des graphes de connaissances, des tableaux ou des enregistrements de bases de données — en texte en langage naturel, afin qu’elles puissent être utilisées directement par les modèles de langage existants sans modifier leur architecture. D’autres méthodes réorganisent le texte d’entrée en couches structurées fondées sur des relations linguistiques, ou extraient les informations clés et les représentent explicitement sous forme de graphes, de tableaux ou de schémas relationnels.
Dans certains cas, représenter des données structurées à l’aide de langages de programmation fonctionne mieux que le langage naturel. Par exemple, l’utilisation de code Python pour les graphes de connaissances ou de SQL pour les bases de données conduit souvent à de meilleures performances sur les tâches de raisonnement complexe, car ces formats préservent plus clairement la structure. Il existe également des approches économes en ressources qui utilisent des représentations matricielles compactes pour traiter les données structurées avec moins de paramètres tout en maintenant de bonnes performances.
(3) Architectures hybrides
Pour gérer des données structurées présentant des relations complexes, telles que les tableaux et les graphes de connaissances, les chercheurs ont exploré des architectures hybrides qui combinent de grands modèles de langage avec des composants conçus pour les données structurées en graphes, comme les réseaux neuronaux de graphes.
Plusieurs approches pratiques sont utilisées. GraphToken rend les relations explicites en ajoutant des tokens spéciaux, ce qui aide les modèles à raisonner sur les graphes. Heterformer traite le texte et la structure du graphe ensemble dans un même cadre, en conservant les informations relationnelles tout en maîtrisant le coût de calcul.
D’autres méthodes intègrent les connaissances de différentes manières. K-BERT ajoute des informations de graphe de connaissances pendant l’entraînement afin que le modèle apprenne ces relations à l’avance. KAPING récupère les connaissances pertinentes au moment de l’inférence, sans réentraînement. Des conceptions plus avancées utilisent des adapters et l’attention pour fusionner les informations de graphe directement dans le modèle, ce qui conduit à une intégration plus étroite.
Conclusion
L’ingénierie du contexte offre une manière utile de comprendre le fonctionnement des systèmes LLM en production. En général, elle implique trois processus principaux : récupération et génération du contexte, traitement du contexte et gestion du contexte. Ensemble, ces étapes déterminent la manière dont l’information est collectée, préparée et transmise au modèle.
Parmi eux, le traitement du contexte est particulièrement important, car il détermine la manière dont les informations récupérées sont nettoyées, organisées et compressées avant d’atteindre le modèle. En raison des limites d’espace, cet article s’est principalement concentré sur cette partie et a passé en revue plusieurs approches utilisées dans des systèmes réels. La récupération et la gestion du contexte sont également des domaines importants et pourront être explorées plus en détail lors de futures discussions.
Si vous développez des systèmes RAG ou des systèmes d’agents et rencontrez des problèmes en production liés au contexte, aux coûts ou à la latence, rejoignez notre canal Slack pour discuter d’ingénierie du contexte avec d’autres ingénieurs. Vous pouvez également réserver une courte session individuelle afin d’obtenir des conseils pratiques pour passer de démos à des systèmes prêts pour la production grâce aux Milvus Office Hours.
Continuer à lire

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.