




Una guía completa de benchmarks de ANN: evaluación del rendimiento de la búsqueda aproximada de vecinos más cercanos (ANNS)
Una guía completa de benchmarks de ANN: evaluación del rendimiento de la búsqueda aproximada de vecinos más cercanos (ANNS)
Imagina que estás construyendo un motor de búsqueda que necesita encontrar rápidamente los elementos más similares de una base de datos que contiene miles de millones de imágenes, documentos de texto u otros datos no estructurados. ¿Cómo te aseguras de que tu algoritmo de búsqueda no solo devuelva resultados precisos, sino que además lo haga a la velocidad del rayo? Aquí es donde entra en juego la búsqueda de vecinos más cercanos aproximados (ANN). La búsqueda ANN es crucial en muchas aplicaciones del mundo real, desde sistemas de recomendación hasta recuperación de imágenes a gran escala.
Con tantas soluciones de búsqueda ANN disponibles en el mercado, ¿cómo evaluamos la eficacia de diferentes algoritmos ANN, especialmente a escala? Entran en escena los ANN Benchmarks, que se han convertido en el estándar de oro para probar el rendimiento de los métodos de búsqueda ANN en grandes conjuntos de datos.
En este blog, exploraremos los benchmarks de ANN, por qué son importantes y cómo ayudan a los desarrolladores e ingenieros de algoritmos a elegir las soluciones de búsqueda vectorial adecuadas para cada tarea. También analizaremos algunos de los benchmarks más populares utilizados hoy en día y qué los hace esenciales en la búsqueda vectorial.
¿Qué es la búsqueda ANN y cómo funciona?
Antes de profundizar en los benchmarks, es importante comprender la búsqueda de vecinos más cercanos aproximados (ANN), o ANNS, y cómo funciona. La búsqueda ANN es una técnica poderosa en el aprendizaje automático (ML) que permite una búsqueda eficiente de similitud semántica en grandes conjuntos de datos que suelen encontrarse en bases de datos vectoriales como Zilliz Cloud. Puede encontrar rápidamente los elementos más cercanos a un elemento de consulta dado en un conjunto de datos. A diferencia de los métodos de búsqueda exacta, que garantizan un 100 % de precisión, ANNS sacrifica una pequeña cantidad de precisión a cambio de mejoras significativas en velocidad y escalabilidad.
Cómo funciona la búsqueda ANN:
Representación de datos: Cada elemento del conjunto de datos se representa como un vector en un espacio multidimensional. Los vectores suelen codificarse mediante un modelo de embeddings, como los modelos de embeddings de texto de OpenAI, los modelos multilingües de Cohere y los modelos multimodales de OpenAI. Por ejemplo, una imagen podría representarse como un vector de características, como color o forma, en un espacio de 128 dimensiones.
Procesamiento de consultas: Cuando se realiza una consulta, el algoritmo de búsqueda ANN recupera del conjunto de datos los vectores cercanos al vector de consulta, utilizando aproximaciones para acelerar el proceso.
Clasificación de resultados: El algoritmo clasifica los vecinos más cercanos en función de su distancia respecto a la consulta en el espacio de alta dimensión, a menudo usando métricas como la distancia euclidiana o la similitud del coseno. Cuanto más cerca estén ubicados los vectores, más similares y relevantes serán.
Eficiencia: La ventaja clave de la búsqueda ANN es su capacidad para entregar resultados en una fracción del tiempo que tomaría una búsqueda exacta, lo que la hace ideal para conjuntos de datos a gran escala.
Los métodos ANNS utilizan diversas estrategias para aproximar rápidamente los vecinos más cercanos:
Métodos basados en árboles: Técnicas como KD-Trees y Ball Trees organizan los datos jerárquicamente para simplificar el proceso de búsqueda. Aunque son eficaces en dimensiones más bajas, su rendimiento se degrada a medida que aumenta la dimensionalidad.
Métodos de hashing: Locality-sensitive hashing (LSH) agrupa puntos de datos similares en los mismos buckets de hash, reduciendo el número de comparaciones requeridas durante la búsqueda.
Métodos basados en grafos: Algoritmos como los grafos Navigable Small World (NSW) y los grafos Hierarchical Navigable Small World (HNSW) crean redes de puntos de datos para acelerar las búsquedas de vecinos.
Métodos de cuantización: Técnicas como Product Quantization (PQ) comprimen los datos en una forma más manejable, mejorando la eficiencia de la búsqueda.
Al aprovechar estos métodos, los algoritmos ANNS pueden equilibrar la precisión y el rendimiento de la búsqueda, lo que los hace adecuados para conjuntos de datos a gran escala.
Búsqueda ANN vs. búsqueda KNN
La búsqueda exacta de K-nearest neighbor (KNN) y Approximate Nearest Neighbor Search (ANNS) son dos enfoques fundamentales utilizados en la búsqueda vectorial, cada uno con sus propias ventajas y compensaciones.
KNN exacto proporciona resultados precisos al evaluar la distancia entre el punto de consulta y cada punto de datos del conjunto de datos, asegurando que los vecinos identificados sean los más cercanos posibles. Sin embargo, este método puede ser computacionalmente intensivo y lento debido a su naturaleza de fuerza bruta, particularmente cuando se trabaja con grandes conjuntos de datos o espacios de alta dimensionalidad. Esto hace que KNN exacto sea adecuado para conjuntos de datos más pequeños o escenarios en los que la precisión es primordial y los recursos computacionales son una preocupación menor.
En contraste, ANNS ofrece una solución práctica para manejar datos a gran escala al sacrificar cierto grado de precisión para obtener un rendimiento más rápido. ANNS emplea diversos algoritmos y técnicas, como estructuras basadas en árboles, métodos de hashing y enfoques basados en grafos, para aproximar eficientemente los vecinos más cercanos. Este enfoque reduce significativamente los costos computacionales y escala bien con conjuntos de datos masivos, lo que lo hace ideal para aplicaciones en tiempo real como motores de búsqueda y sistemas de recomendación, donde la velocidad es crucial. Aunque ANNS no siempre proporciona los vecinos exactos más cercanos, su capacidad para ofrecer resultados casi precisos rápidamente lo convierte en una herramienta valiosa en las tareas modernas de recuperación y análisis de datos.
Para obtener más información, consulta nuestra página del glosario de ANNS.
¿Qué es ANN Benchmark?
El ANN Benchmark es una herramienta de evaluación integral diseñada para medir y comparar el rendimiento de diferentes algoritmos ANNS. Alojado en ann-benchmarks.com, proporciona pruebas y métricas estandarizadas para evaluar diversos aspectos de los métodos ANNS, incluyendo:
Velocidad de búsqueda: Qué tan rápido puede el algoritmo encontrar los vecinos más cercanos.
Precisión: El grado en que los resultados del algoritmo se aproximan a los verdaderos vecinos más cercanos.
Escalabilidad: Qué tan bien funciona el algoritmo a medida que aumenta el tamaño o la dimensionalidad del conjunto de datos.
Este benchmark ofrece una variedad de conjuntos de datos y criterios de evaluación, lo que permite a los desarrolladores medir la efectividad de diferentes algoritmos bajo diversas condiciones en igualdad de condiciones.
Métricas clave en ANN Benchmarks:
Recall: El porcentaje de verdaderos vecinos más cercanos recuperados exitosamente por el algoritmo. Un recall alto indica una mejor precisión.
Tiempo de búsqueda: El tiempo que tarda el algoritmo en devolver un resultado. Tiempos de búsqueda más rápidos son cruciales para aplicaciones que requieren respuestas en tiempo real.
Uso de memoria: La cantidad de memoria que el algoritmo requiere para almacenar y buscar en el conjunto de datos. Un uso eficiente de la memoria es importante para la escalabilidad.
Escalabilidad: La capacidad del algoritmo para mantener el rendimiento a medida que aumenta el tamaño del conjunto de datos. La escalabilidad es un factor crítico en aplicaciones del mundo real donde los conjuntos de datos pueden crecer rápidamente.
Conjuntos de datos clave utilizados en ANN Benchmarks
ANN Benchmark utiliza diversos conjuntos de datos para probar algoritmos. Estos conjuntos de datos cubren una variedad de dominios, como características de imágenes, embeddings de texto y datos sintéticos. Los conjuntos de datos clave utilizados en los benchmarks incluyen:
| Conjunto de datos | Dimensiones | Tamaño de entrenamiento | Tamaño de prueba | Vecinos | Distancia | Descarga |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Angular | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Euclidiana | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Euclidiana | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Jaccard | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Euclidiana | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Jaccard | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Angular | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Euclidiana | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | Angular | HDF5 (135MB) |
Algoritmos ANN o motores de búsqueda vectorial probados
Los ANN Benchmarks han evaluado una amplia gama de algoritmos ANN y motores de búsqueda vectorial, incluidos Annoy, Faiss, Knowhere (el motor de búsqueda de Milvus) y Glass (el motor de búsqueda heredado de Zilliz Cloud). El número de algoritmos probados continúa creciendo. A continuación se muestra una lista de algoritmos y motores de búsqueda probados hasta septiembre de 2024.
scikit-learn: LSHForest, KDTree, BallTree
NMSLIB (Biblioteca de espacios no métricos) : SWGraph, HNSW, BallTree, MPLSH
NGT : ONNG, PANNG, QG
Elasticsearch : HNSW
DiskANN : Vamana, Vamana-PQ
scipy: cKDTree
Nota: Zilliz Cloud ha lanzado un nuevo motor de búsqueda llamado Cardinal, que ofrece tres veces el rendimiento del motor Glass heredado y ofrece un rendimiento de búsqueda (QPS) de hasta diez veces el de Milvus. Sin embargo, debido a limitaciones de tiempo y otros factores, el rendimiento de Cardinal no se incluye en los resultados del benchmark de ANN. En la siguiente sección, puedes explorar su rendimiento usando VectorDBBench.
Resultados del benchmark
El gráfico siguiente muestra los resultados de probar el recall/consultas por segundo de varios algoritmos basados en el conjunto de datos GIST1M (1M de vectores con 960 dimensiones). Traza la tasa de recall en el eje x frente a QPS en el eje y, ilustrando el rendimiento de cada algoritmo en diferentes niveles de precisión de recuperación.
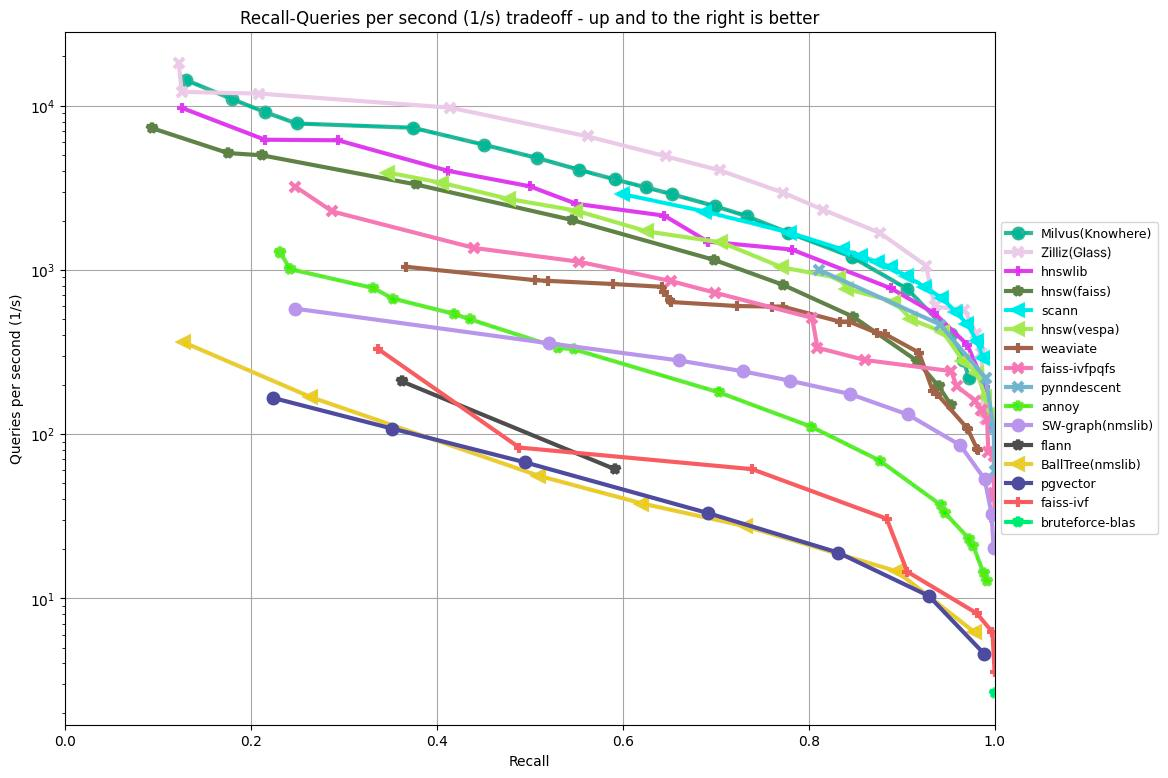 Figura 1: Resultados del benchmark de ANN en el conjunto de datos GIST1M
Figura 1: Resultados del benchmark de ANN en el conjunto de datos GIST1M
Figura 1: Resultados del benchmark de ANN en el conjunto de datos GIST1M
Según los resultados que se muestran en el gráfico anterior, las bibliotecas Knowhere (el motor de búsqueda de Milvus), Glass (el motor de búsqueda heredado de Zilliz Cloud) y HNSW lograron los tres mejores resultados al procesar 1,000,000 de vectores con 960 dimensiones.
Para ver más resultados de benchmarking, consulta el sitio web de ANN-Benchmark.
VectorDBBench: Una herramienta de benchmarking de código abierto para bases de datos vectoriales
La búsqueda vectorial, o búsqueda de similitud vectorial, es un concepto más amplio que se refiere al proceso de encontrar vectores similares dentro de un conjunto de datos. ANNS representa un conjunto de algoritmos que impulsan la búsqueda vectorial. Las bases de datos vectoriales son soluciones diseñadas específicamente para búsquedas eficientes de similitud vectorial.
Aunque ANN-Benchmark es increíblemente útil para seleccionar y comparar diferentes algoritmos de búsqueda vectorial, no proporciona una visión general completa de las bases de datos vectoriales. También debemos considerar factores como el consumo de recursos, la capacidad de carga de datos y la estabilidad del sistema. Además, ANN Benchmark pasa por alto muchos escenarios comunes, como las búsquedas vectoriales filtradas.
Para abordar estos desafíos, los desarrolladores de Zilliz propusieron VectorDBBench, una herramienta de benchmarking de código abierto diseñada para bases de datos vectoriales de código abierto como Milvus y Weaviate y servicios totalmente gestionados como Zilliz Cloud y Pinecone. Debido a que muchos servicios de búsqueda vectorial totalmente gestionados no exponen sus parámetros para que los usuarios los ajusten, VectorDBBench muestra las tasas de QPS y de recuperación por separado.
Los gráficos siguientes muestran los resultados de las pruebas de QPS y la tasa de recuperación de varias bases de datos vectoriales convencionales al procesar 1,000,000 de vectores con 768 dimensiones.
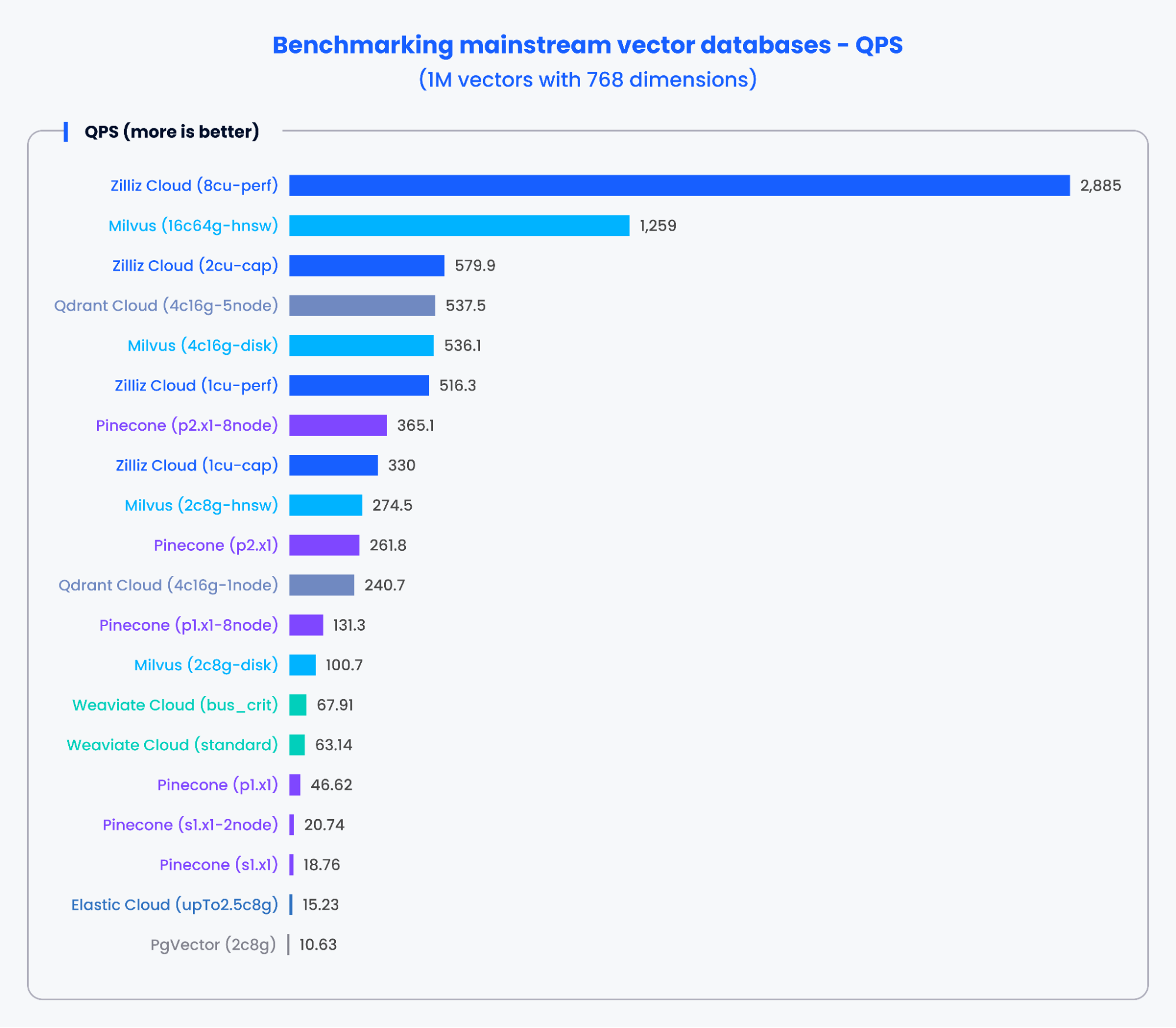 Figura 2: Resultados de benchmark para QPS
Figura 2: Resultados de benchmark para QPS
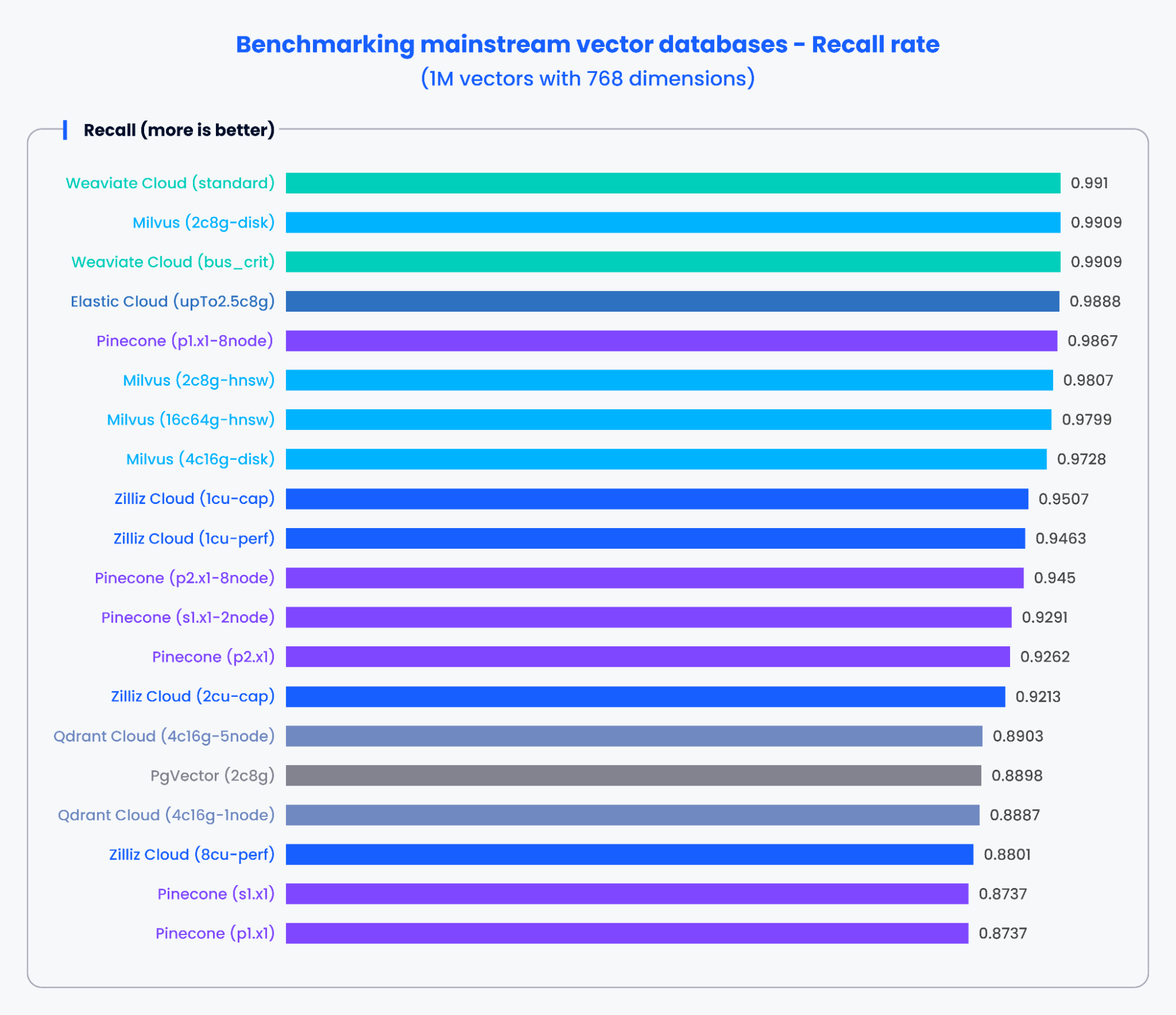 Figura 3: Resultados de benchmark para la tasa de recuperación
Figura 3: Resultados de benchmark para la tasa de recuperación
Según los resultados de los gráficos anteriores, las bases de datos vectoriales diseñadas específicamente, como Milvus y Zilliz, demostraron un rendimiento sobresaliente tanto en QPS como en tasas de recuperación. Estos resultados indican que las bases de datos vectoriales diseñadas específicamente pueden procesar rápidamente grandes cantidades de datos y recuperar resultados más precisos. En cambio, los complementos de búsqueda vectorial basados en bases de datos tradicionales mostraron un rendimiento más pobre.
Descarga VectorDBBench desde su repositorio de GitHub para reproducir nuestros resultados de benchmark u obtener resultados de rendimiento en tus propios conjuntos de datos.
Tabla de clasificación de VectorDBBench
VectorDBBench también ofrece una página de tabla de clasificación dedicada, diseñada para agilizar la presentación de los resultados de las pruebas y proporcionar un informe exhaustivo de análisis de rendimiento. Esta tabla de clasificación nos permite seleccionar métricas clave como consultas por segundo (QPS), métricas de precio de consulta ($) y latencia para una evaluación integral del rendimiento.
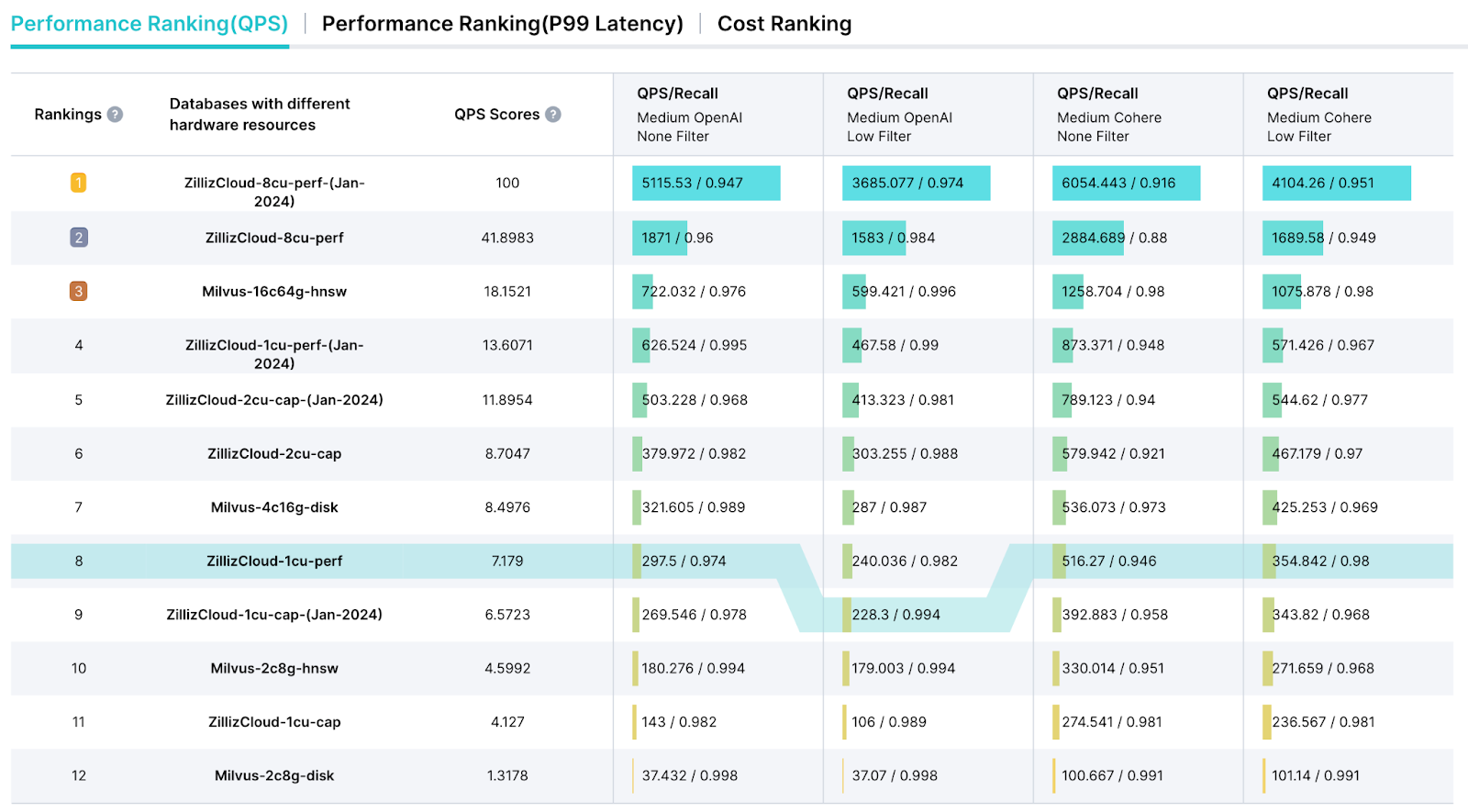 una captura de pantalla de la tabla de clasificación de vectordbbench
una captura de pantalla de la tabla de clasificación de vectordbbench
Figura 4: Una captura de pantalla de la tabla de clasificación de VectorDBBench
ANN Benchmarks vs. VectorDBBench
ANN Benchmarks evalúa algoritmos de índices vectoriales, lo que ayuda a seleccionar y comparar diferentes bibliotecas de búsqueda vectorial. Sin embargo, no son adecuados para evaluar bases de datos vectoriales complejas y maduras, y pasan por alto situaciones como la búsqueda vectorial filtrada.
Los ingenieros de Zilliz crearon VectorDB Bench para adaptarse a una evaluación integral de bases de datos vectoriales. Considera factores esenciales como el consumo de recursos, la capacidad de carga de datos y la estabilidad del sistema. Al separar el cliente de prueba y la base de datos vectorial y garantizar una implementación independiente, VectorDB Bench permite realizar pruebas que reflejan fielmente los entornos de producción del mundo real.
Factores que influyen en la evaluación del rendimiento
Varios factores afectan el rendimiento de una base de datos vectorial o de un algoritmo ANN, incluidos el conjunto de datos, las condiciones de red y la configuración de la base de datos.
Red
Las condiciones de red son críticas. La latencia puede ralentizar las respuestas a las consultas, mientras que el ancho de banda limitado afecta las tasas de transferencia de datos. La estabilidad de la red también es importante, ya que las fluctuaciones pueden causar un rendimiento inconsistente.
Conjuntos de datos
El tamaño del conjunto de datos influye en el uso de memoria y disco: los conjuntos de datos más grandes requieren más recursos. La dimensionalidad vectorial afecta la complejidad de las operaciones y los tiempos de consulta. La distribución de los datos y la estructura de indexación (p. ej., jerárquica, plana) también influyen en la eficiencia y precisión de la búsqueda.
Configuración de la base de datos
Los parámetros del índice (p. ej., número de árboles) y la configuración de búsqueda (p. ej., vecinos más cercanos) afectan directamente la eficiencia y la velocidad de recuperación. El almacenamiento en caché puede mejorar los tiempos de respuesta para los datos a los que se accede con frecuencia.
Factores ambientales
El sistema operativo y los procesos en segundo plano pueden influir en la disponibilidad de recursos y la capacidad de respuesta del sistema, lo que afecta el rendimiento general.
Considerar estos factores te ayuda a comprender y optimizar el rendimiento de tu base de datos vectorial.
Recursos adicionales
- ¿Qué es la búsqueda ANN y cómo funciona?
- ¿Qué es ANN Benchmark?
- VectorDBBench: Una herramienta de benchmarking de código abierto para bases de datos vectoriales
- ANN Benchmarks vs. VectorDBBench
- Factores que influyen en la evaluación del rendimiento
- Recursos adicionales
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis