




De la base de datos vectorial a Vector Lakebase
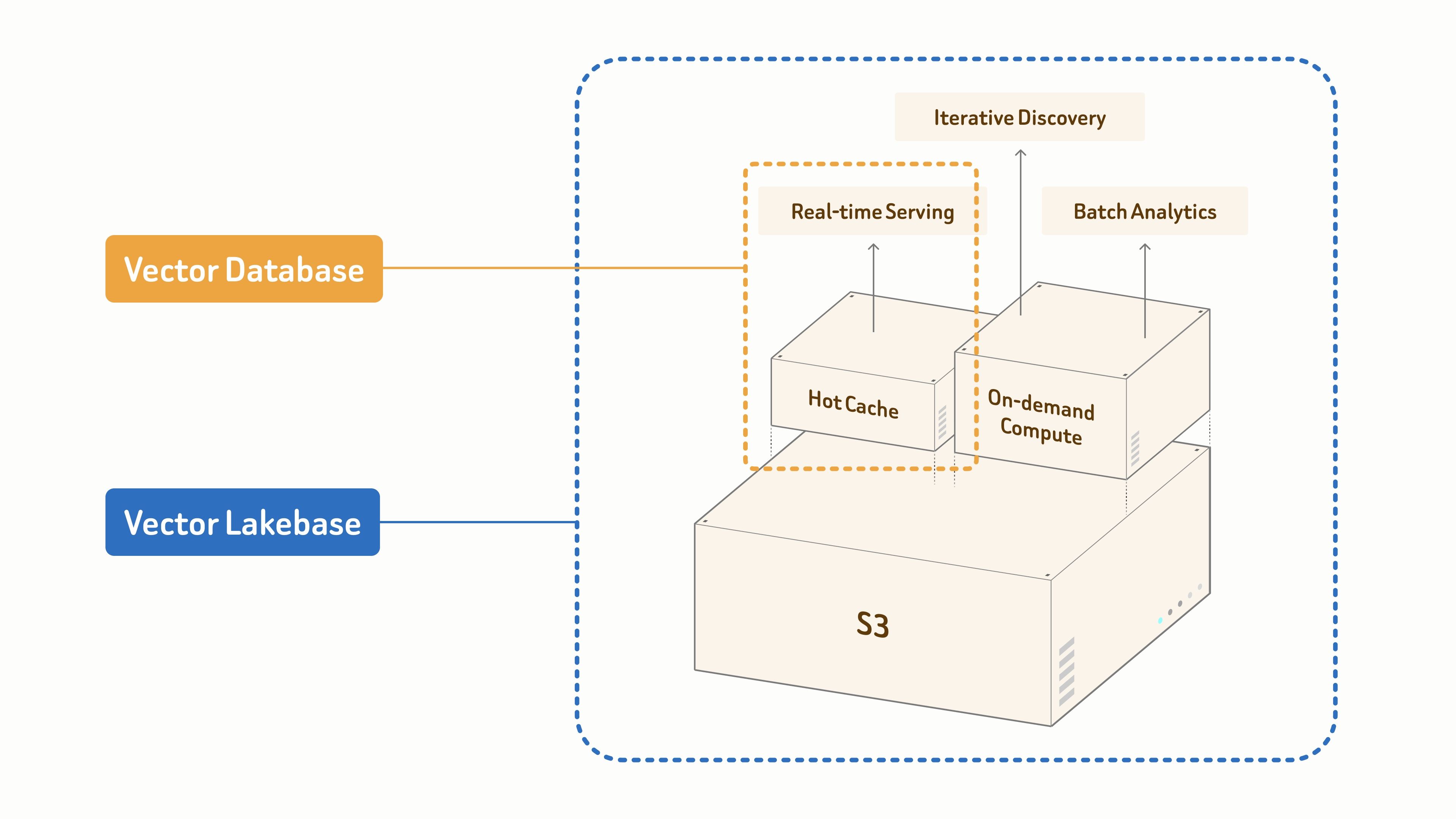
Hoy lanzamos la vista previa pública de Zilliz Vector Lakebase — el siguiente capítulo para Zilliz Cloud. Vector Lakebase es el siguiente paso más allá de las bases de datos vectoriales. Es una plataforma de datos centrada en la semántica donde el almacenamiento abierto y el cómputo elástico convergen para cargas de trabajo de IA.
- Las bases de datos vectoriales están diseñadas específicamente para el servicio en tiempo real.
- Vector Lakebase se basa en una base de datos unificada basada en S3 para impulsar la IA y los agentes en tres modos de carga de trabajo:
- recuperación en tiempo real para el servicio de producción crítico en latencia,
- descubrimiento iterativo para la exploración interactiva y de múltiples pasos,
- analítica por lotes para la minería offline y la optimización de conjuntos de datos.
Todo escalando desde gigabytes hasta petabytes.
¿Por qué importan realmente la base de datos unificada y los tres modos de carga de trabajo?
En pocas palabras: porque los sistemas de IA ya no son solo un problema de recuperación de una sola consulta. Funcionan como un ciclo continuo de servicio, aprendizaje y mejora.
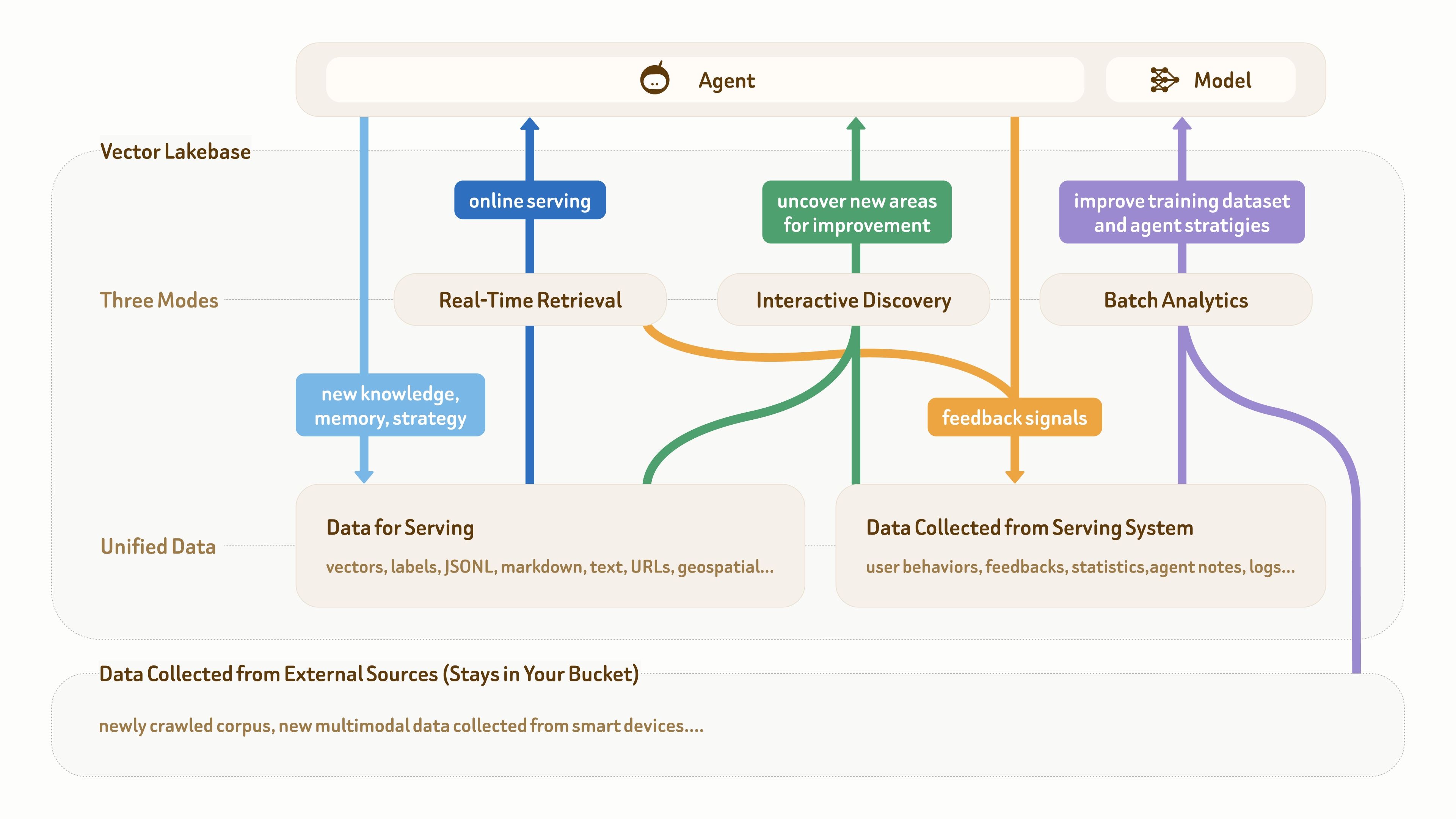
Como muestra esta figura, la base de datos para aplicaciones de IA y agentes suele tener tres partes: datos multimodales sin procesar en la parte inferior, datos semánticos para el servicio online (como texto, vectores y etiquetas) y datos de retroalimentación recopilados de sistemas de producción (como comportamiento de usuarios, registros, notas de agentes y estadísticas).
Muchas aplicaciones de agentes maduras ya cuentan con este tipo de base de datos. El verdadero punto de dolor es que estos diferentes tipos de datos suelen estar dispersos en múltiples pipelines y sistemas, sin un plano de datos unificado y estructurado que respalde el ciclo de trabajo:
servicio online (azul oscuro) → acumulación de conocimiento y retroalimentación (azul claro y naranja) → descubrimiento de insights (verde) → mejora de conjuntos de datos y estrategias (morado) → mejor servicio online.
Como también muestra la imagen, una base de datos vectorial por sí sola ya no es suficiente, porque principalmente admite la recuperación en tiempo real y las escrituras de datos orientadas al servicio (las dos rutas azules). En este ciclo, los otros dos modos de acceso — descubrimiento interactivo y analítica por lotes — son igual de importantes.
Por ejemplo, los desarrolladores de IA (ya sea manualmente o mediante sistemas agénticos) a menudo necesitan explorar los datos de retroalimentación y el corpus subyacente para entender por qué la calidad del servicio es deficiente. También pueden ejecutar deduplicación semántica y clustering a gran escala sobre datos recién rastreados, y luego minar clústeres periféricos para descubrir nuevos candidatos de datos de entrenamiento.
Estas cargas de trabajo son muy diferentes del procesamiento tradicional de big data. El cómputo central es semántico más que numérico. Los datos consisten principalmente en vectores, texto, etiquetas y metadatos semánticos, mientras que las operaciones centrales incluyen búsqueda vectorial, búsqueda de texto completo, reranking, clustering semántico y tareas relacionadas de recuperación semántica.
Por esta razón, el descubrimiento interactivo y la analítica por lotes se alinean naturalmente con las bases de datos vectoriales tanto en las capas de datos como de cómputo. En muchos casos, el servicio online y el procesamiento offline incluso comparten la misma base de datos subyacente.
Por ejemplo, los equipos pueden agrupar y analizar tareas de usuario de alto valor offline mientras verifican simultáneamente si el conocimiento o las estrategias de soporte en el sistema de servicio presentan problemas de escasez o calidad.
En general, cualquier arquitectura de datos fragmentada o islas de infraestructura aisladas ralentizan este ciclo — lo cual puede ser fatal en la carrera en rápida evolución por las capacidades de IA. Vector Lakebase acelera este ciclo mediante un enfoque directo pero eficiente: proporcionar un plano de datos semántico de copia cero al que puedan acceder eficientemente los tres modos de carga de trabajo — recuperación en tiempo real, descubrimiento interactivo y analítica por lotes.
Las características clave de Vector Lakebase
Zilliz Vector Lakebase respalda este ciclo de trabajo mediante cinco capacidades principales:
- Soluciones de servicio por niveles
Niveles de servicio flexibles optimizados para diferentes cargas de trabajo en tiempo real: ofrecen rendimiento ultraalto, eficiencia equilibrada y escalado rentable en conjuntos de datos masivos. - Búsqueda bajo demanda
Diseñada para cargas de trabajo a gran escala donde la latencia es menos crítica y el cómputo permanece inactivo la mayor parte del tiempo, incluidas la búsqueda infrecuente, la exploración de datos y la analítica por lotes. - Búsqueda en lagos de datos externos
Añade capacidades de indexación de vanguardia y búsqueda a gran escala directamente a tus datos de lago existentes. - Búsqueda de espectro completo Desde vectores y texto hasta JSON y geoespacial, combinada con recuperación híbrida, filtrado y reordenamiento para consultas multimodales expresivas.
- Almacenamiento unificado nativo de lago
Almacenamiento unificado tanto para servicio como para analítica, construido sobre Vortex — un formato abierto de próxima generación que proporciona lecturas aleatorias más rápidas y económicas que Lance y Parquet, además de flexibilidad de formato por columna y capacidades más amplias de modelado de datos.
Soluciones de servicio en tiempo real por niveles
Las soluciones de servicio por niveles de Zilliz Cloud proporcionan tres niveles de servicio: optimizado para rendimiento, optimizado para capacidad y almacenamiento por niveles. Cada nivel está construido con algoritmos de indexación dedicados y estrategias de colocación de datos en toda la jerarquía de almacenamiento, ofreciendo una amplia gama de compensaciones entre rendimiento y costo.
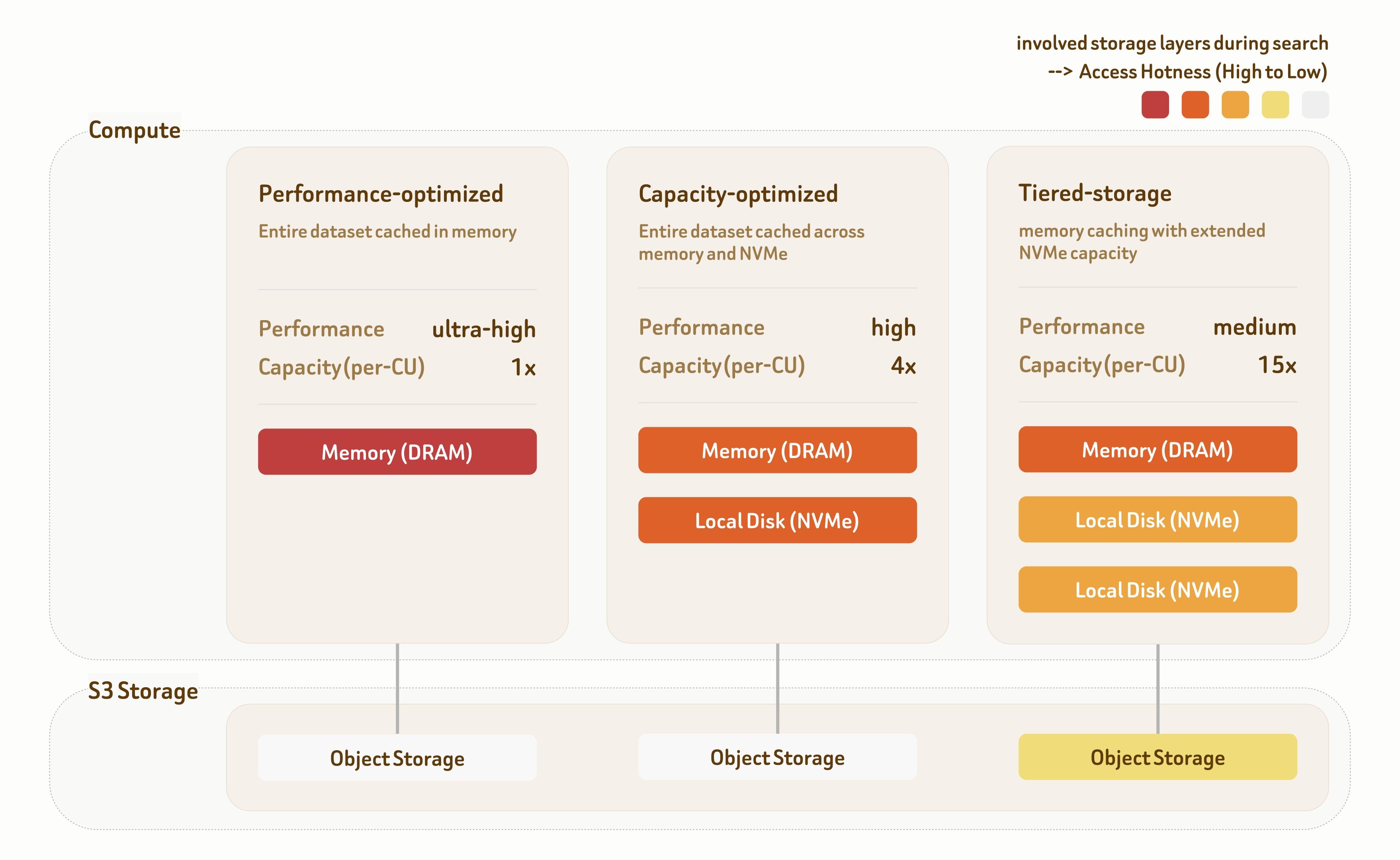
El nivel optimizado para rendimiento apunta a escenarios de rendimiento ultraalto. Todos los datos se sirven directamente desde la memoria, ofreciendo más de 1000 QPS con latencia de milisegundos de un solo dígito. El rendimiento escala aún más de forma lineal con la implementación de múltiples réplicas.
El nivel optimizado para capacidad combina memoria y almacenamiento NVMe local para equilibrar rendimiento y capacidad. Ofrece 100~500 QPS con latencia inferior a 100 ms, lo que lo hace adecuado para la mayoría de las cargas de trabajo de recuperación.
El nivel almacenamiento por niveles abarca memoria, NVMe local y almacenamiento de objetos. Con estrategias de precarga y caché altamente optimizadas, más del 95% del acceso a datos aún llega a memoria o disco local, proporcionando 10~50 QPS con una latencia de alrededor de 100 ms a un costo de infraestructura significativamente menor.
Los tres niveles ofrecen 95%–98% de recall de forma predeterminada, con ajuste flexible en indexación y búsqueda, admitiendo un recall del 90% al 99%+ según los requisitos de la carga de trabajo.
Estas arquitecturas de servicio han sido probadas en batalla en algunas de las cargas de trabajo de IA e internet a gran escala más exigentes del mundo, incluidas:
- plataformas de IA multiinquilino a escala de internet,
- niveles de servicio diferenciados tanto para usuarios empresariales premium como para grandes grupos de usuarios gratuitos,
- bases de conocimiento de agentes de alto rendimiento,
- sistemas de recomendación de rendimiento ultraalto,
- motores de búsqueda de IA a escala web,
- programación dinámica de datos calientes/fríos a nivel de segundos en niveles de almacenamiento,
- canalizaciones de minería de datos de conducción autónoma a escala de más de 100B bajo restricciones de costo extremas.
Para el servicio en línea, Zilliz Cloud también proporciona capacidades de Global Cluster para alta disponibilidad entre regiones y recuperación ante desastres, respaldadas por un SLA de tiempo de actividad del 99,99%.
Búsqueda bajo demanda
El descubrimiento interactivo y la analítica por lotes suelen operar sobre volúmenes de datos de uno a tres órdenes de magnitud mayores que el servicio en línea, especialmente cuando se incluyen datos de retroalimentación, notas generadas por agentes, registros y corpus rastreados. Estos conjuntos de datos pueden alcanzar fácilmente escala de TB o incluso PB. Pero usar cientos o incluso miles de nodos de bases de datos vectoriales para servirlos suele ser difícil de justificar desde una perspectiva de costo-beneficio.

Más importante aún, estas cargas de trabajo suelen estar impulsadas por tareas. A diferencia de la capa de servicio en línea de las aplicaciones de agentes, no requieren infraestructura activa 24/7. Los recursos de cómputo se usan intensivamente solo durante tareas de procesamiento activas, mientras permanecen inactivos la mayor parte del tiempo, a menudo con más del 97% de tiempo inactivo.
Las soluciones de servicio serverless pueden parecer atractivas, pero a menudo terminan siendo mucho más costosas para estas cargas de trabajo.
En la capa de cómputo, tanto los sistemas serverless como On-Demand Search siguen un modelo de pago por uso. A pesar de las diferencias en los modelos de precios detallados, el costo de cómputo subyacente suele ser similar. Sin embargo, en una arquitectura serverless, la sobrecarga de agrupación, la indexación y los costos de datos persistentes se incorporan en recargos adicionales de escritura y almacenamiento, en lugar de reflejar directamente el costo real de los recursos subyacentes.
En cambio, Zilliz On-Demand Search cobra directamente por el almacenamiento de objetos y el cómputo bajo demanda, de manera similar a AWS Lambda, donde el precio se basa principalmente en el tamaño de los recursos asignados y el tiempo de ejecución, mientras que el costo de almacenamiento se mantiene cerca del costo subyacente de S3. Esto evita la sobrecarga de infraestructura oculta y los modelos de precios de caja negra.
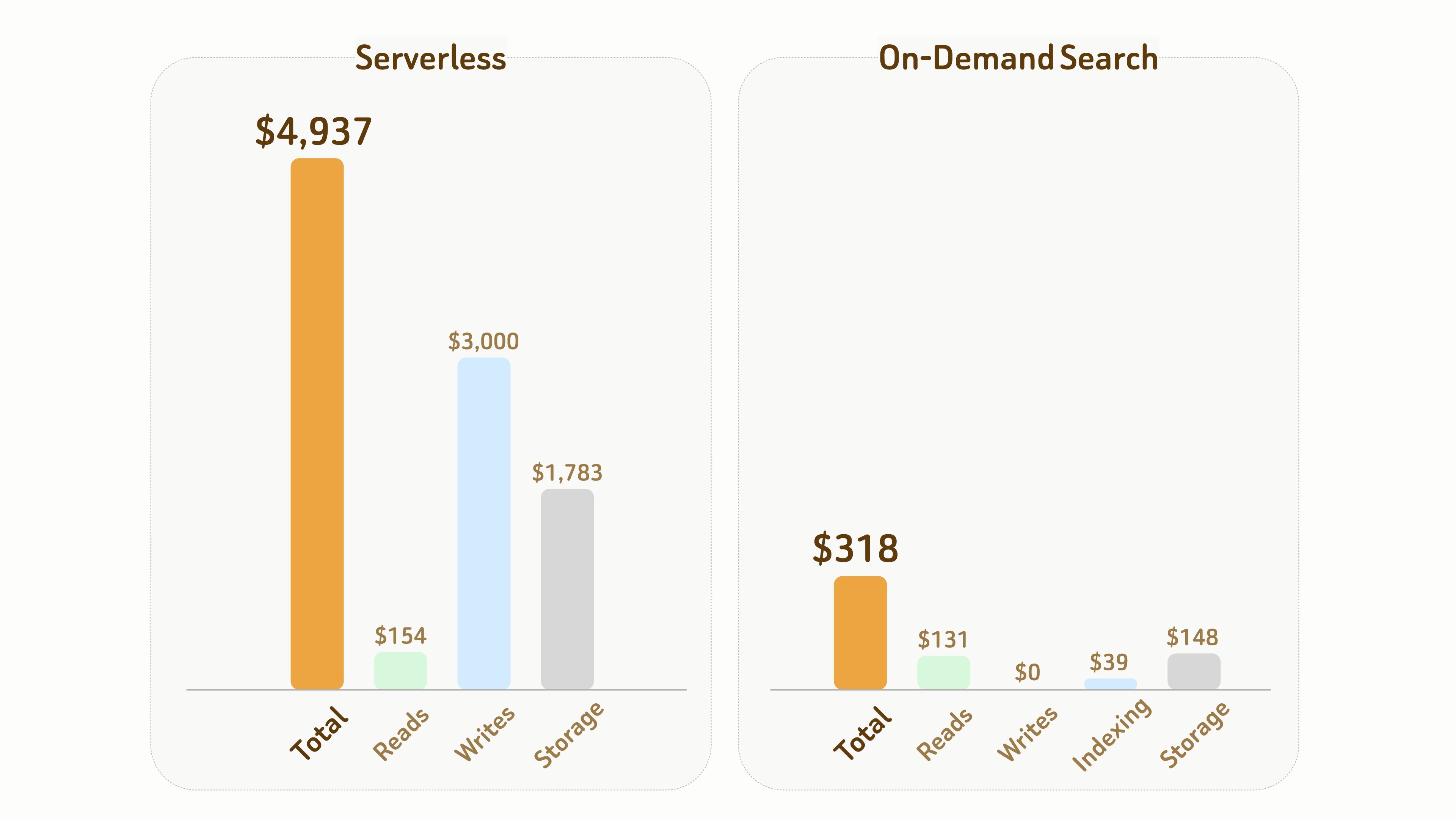
La siguiente comparación ilustra la diferencia de costo entre Serverless y On-Demand Search.
Configuración:
- 1B de vectores con 768 dimensiones, que requieren aproximadamente 6 TB de almacenamiento incluyendo archivos de datos e índices,
- 1 mes de duración con 10 horas de tiempo de cómputo activo acumulado.
En general, en este experimento, el costo total de On-Demand Search es solo alrededor de 1/15 ($318 frente a $4,937) del de Serverless.
Búsqueda en lago de datos externo
Zilliz Vector Lakebase proporciona almacenamiento y cómputo de consultas completamente gestionados, lo que permite a los usuarios almacenar y operar sus datos directamente en Zilliz Cloud. Sin embargo, algunos clientes ya cuentan con una infraestructura madura de lago de datos y canalizaciones de gobernanza en funcionamiento.
Para las aplicaciones de IA, uno de los desafíos clave es habilitar la recuperación eficiente y la exploración semántica directamente sobre los datos existentes del lago. Los sistemas tradicionales de big data como Spark y Ray no están optimizados para estas cargas de trabajo, porque están diseñados fundamentalmente en torno al escaneo completo de datos y la computación map-reduce, en lugar de consultas aceleradas por índices y recuperación semántica.
Para resolver esto, Zilliz proporciona un modo External Collection. Crea un mapeo lógico de copia cero desde el plano de datos de Zilliz hacia tablas de lago propiedad del cliente, al tiempo que habilita índices de alto rendimiento y búsqueda de espectro completo sobre ese mapeo.
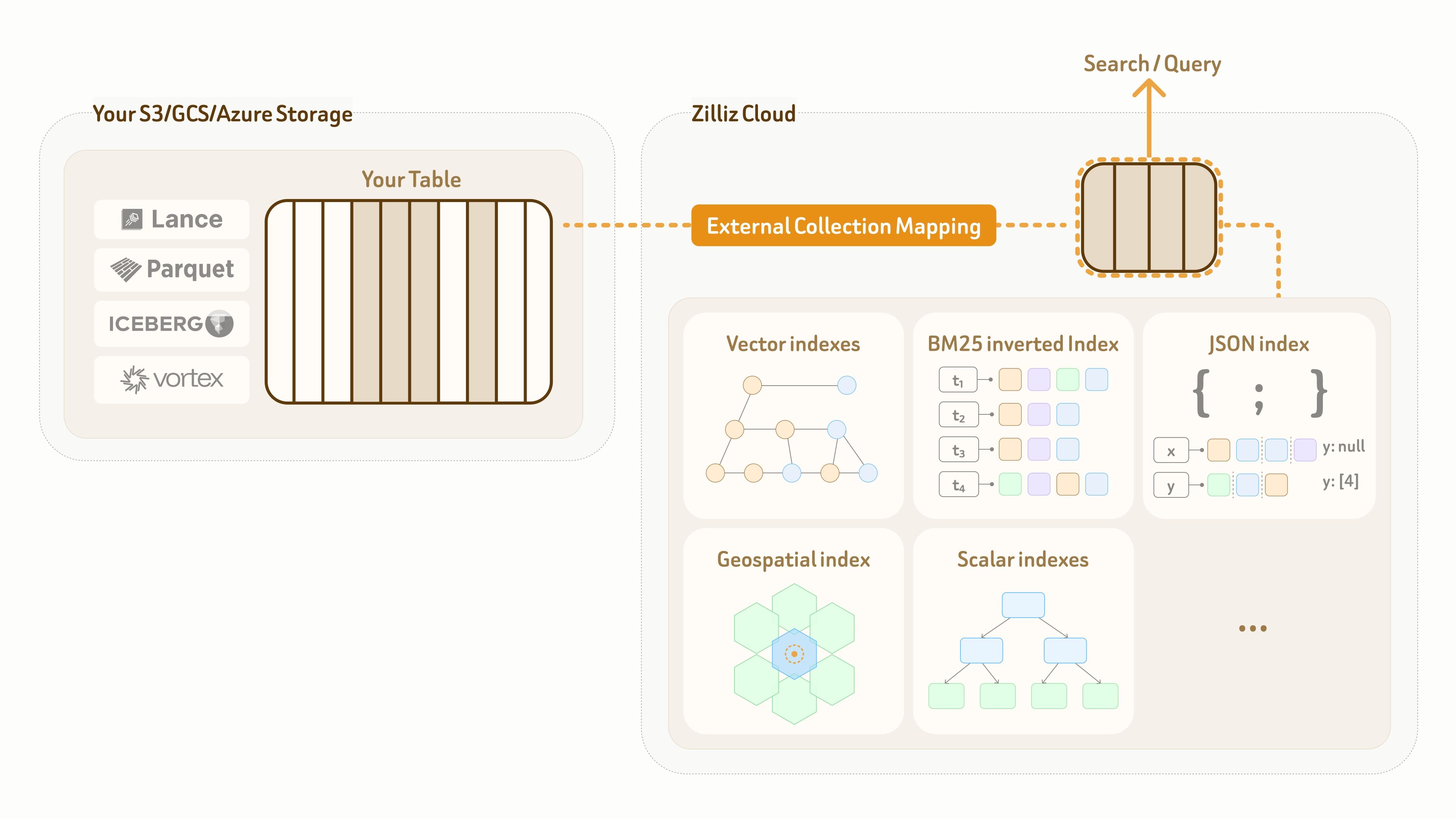
Actualmente, External Collection admite dos formatos de tablas de lago de datos — Lance e Iceberg, así como dos formatos de datos abiertos — Parquet y Vortex.
Para las actualizaciones del lago de datos, Zilliz External Collection proporciona capacidades de sincronización incremental. Según el patrón de actualización del lago de datos y los requisitos de visibilidad de consultas, los usuarios pueden sincronizar datos en cualquier momento con una llamada de actualización.
Búsqueda de espectro completo
Las aplicaciones de IA necesitan cada vez más recuperar y analizar datos de diferentes fuentes y modalidades — tanto para combinar información complementaria como para extraer múltiples perspectivas del mismo contenido sin procesar con el fin de mejorar la calidad de la recuperación y el análisis.
Zilliz Vector Lakebase admite el modelado de tablas anchas con tipos de datos enriquecidos que incluyen vectores densos y dispersos, texto, JSON, datos geoespaciales y tipos primitivos, junto con estructuras complejas como Struct y Array — lo que permite un modelado semántico anidado eficiente directamente dentro de un diseño de tabla unificado.

Esto permite un modelado de contexto unificado al mapear cada entidad a nivel de aplicación directamente a una sola fila. Por ejemplo, en lugar de dividir un documento en cientos de filas para fragmentos de texto, imágenes y tablas, Zilliz Vector Lakebase puede modelar todo el documento como una sola fila. Esto mejora la recuperación y el análisis multimodal, al tiempo que evita la sobrecarga de rendimiento y operativa de JOINs y agregaciones.
Más allá del modelado de datos, Vector Lakebase también proporciona capacidades de indexación y búsqueda de vanguardia en todos los tipos de datos compatibles. Las capacidades detalladas se enumeran a continuación:
| Búsqueda vectorial | Algoritmos de indexación avanzados que superan a HNSW, IVF y RaBitQ, con 10 niveles de ajuste de recall-latencia. |
|---|---|
| Búsqueda de texto completo | Búsqueda de texto completo con BM25, frase, prefijo, coincidencia difusa y una amplia gama de analizadores. |
| Grep | Soporte de regex integrado que cubre la mayoría de los patrones de coincidencia de estilo grep. |
| Búsqueda híbrida | Búsqueda híbrida de vectores densos y dispersos para mejorar el recall y la relevancia. |
| Consulta en JSON | Fragmentación e indexación JSON integradas para filtrado y consulta rápidos en campos JSON anidados. |
| Búsqueda geoespacial | Búsqueda geoespacial rápida con filtrado por radio, vecino más cercano y área. |
| Búsqueda multivectorial | Búsqueda sobre múltiples embeddings generados a partir de una o más modalidades, con reranking unificado. |
| Búsqueda vectorial con filtrado | Búsqueda vectorial con filtrado de atributos, optimizada desde baja hasta alta selectividad de filtros. |
| Búsqueda por rango | Devuelve todos los vectores dentro de un umbral de distancia especificado respecto al vector de consulta. |
| Búsqueda iterativa | Búsqueda iterativa con refinamiento de consulta paso a paso basado en resultados intermedios. |
| Recuperación multipath | Recuperación multipath con múltiples estrategias, donde cada ruta puede usar cualquiera de los métodos de búsqueda anteriores. |
así como capacidades de reranking utilizadas junto con la recuperación multipath.
| Cohere Reranker | Un modelo de reranking de codificador cruzado que puntúa pares consulta–documento con alta precisión semántica para reordenar los resultados de recuperación con máxima relevancia. |
|---|---|
| Voyage AI Reranker | Un modelo de reranking ligero y de alto rendimiento optimizado para una puntuación de relevancia rápida y rentable en pipelines de recuperación a gran escala. |
| Boost Reranker | Aplica filtros condicionales a los resultados coincidentes y ajusta sus puntuaciones con un peso especificado para promover o degradar rankings. |
| Decay Reranker | Ajusta las puntuaciones de los resultados aplicando una función de decaimiento basada en factores como distancia o tiempo, reduciendo gradualmente la relevancia a medida que los valores divergen de un objetivo. |
| RRF Reranker | Fusiona múltiples listas de resultados combinando las posiciones de ranking de cada elemento en las listas en un único ranking. |
| Weighted Reranker | Combina puntuaciones de múltiples listas de resultados usando pesos configurables para producir un ranking unificado. |
Almacenamiento unificado nativo de lake
Zilliz Cloud se basa en una arquitectura de almacenamiento–cómputo completamente desacoplada, con todo persistido en almacenamiento de objetos en la nube.
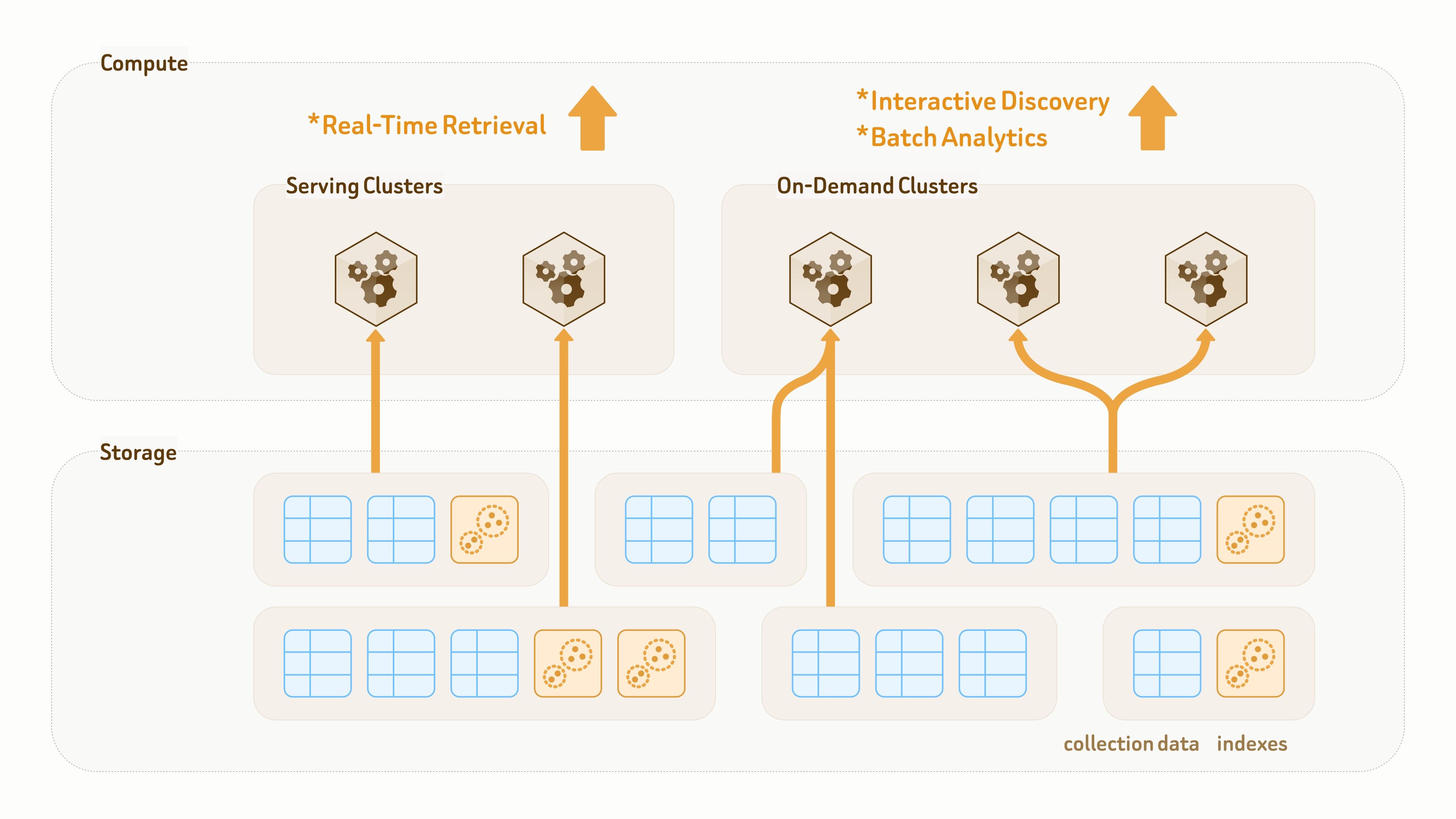
A diferencia de los data lakes tradicionales diseñados principalmente para almacenamiento, la capa de datos de Zilliz Vector Lakebase está diseñada tanto para persistencia como para ejecución de consultas. Las colecciones y los índices están desacoplados de los clústeres de cómputo, lo que permite que los mismos datos e índices se monten mediante acceso zero-copy por diferentes clústeres para distintas cargas de trabajo de consulta y analítica.
Para aplicaciones de IA y agentes con modelos de datos en evolución continua —como añadir con frecuencia nuevas etiquetas y características o cambiar modelos de embedding— Zilliz proporciona un mecanismo fluido y de alta velocidad para la evolución de esquemas y el backfill de datos.
Los nuevos campos se rellenan mediante backfill y se alinean con recursos de cómputo de plataforma compartidos, y luego se exponen a los clústeres de consulta mediante actualizaciones de metadatos. Un backfill de 100 millones de filas normalmente puede completarse en minutos de un solo dígito.
Dado que la mayor parte del trabajo la gestionan recursos de cómputo del lado de la plataforma, los clústeres de usuario existentes no se ven afectados y pueden seguir sirviendo tráfico de lectura y escritura durante todo el proceso.
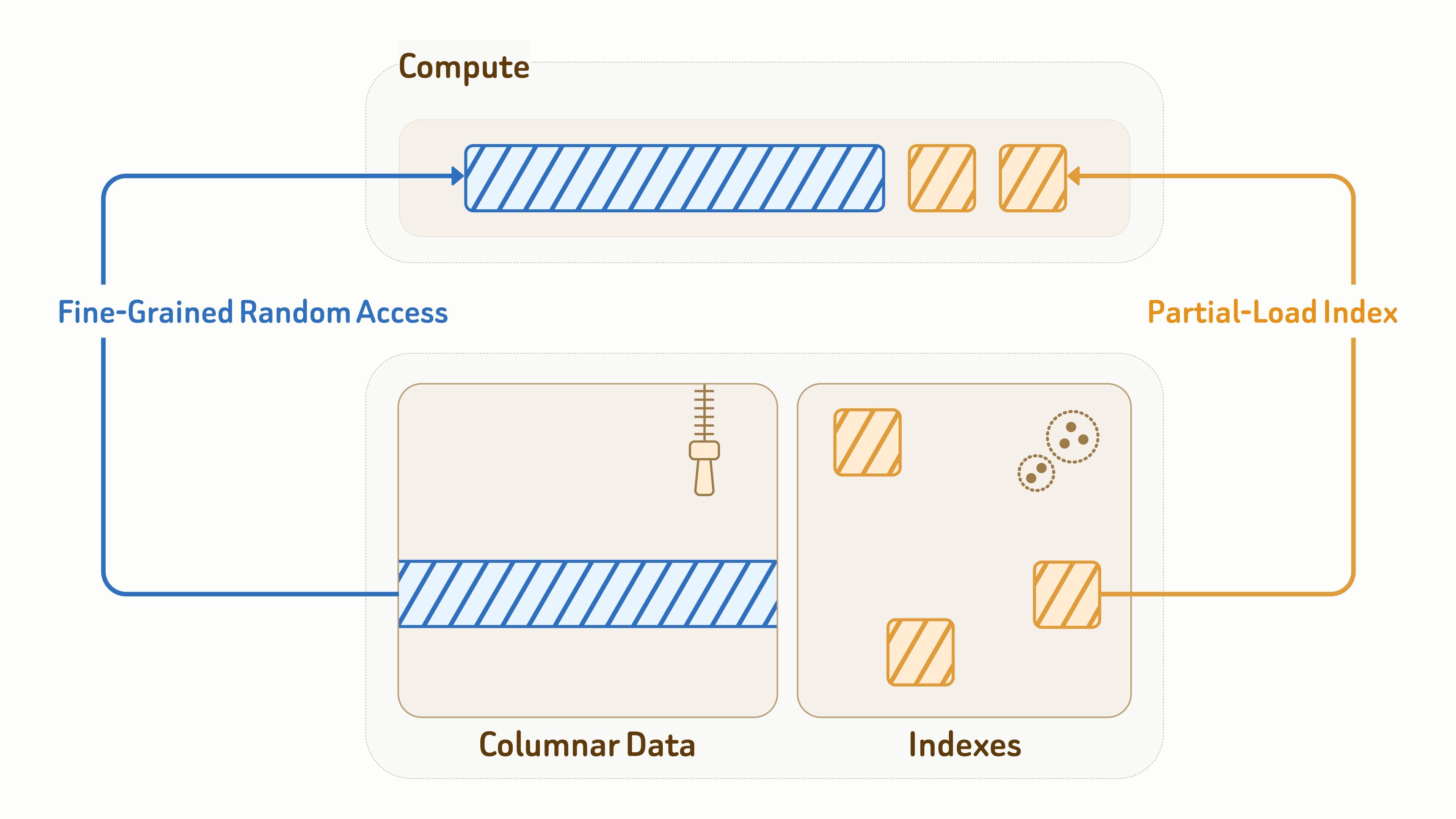
Como la capa de datos también sirve directamente cargas de trabajo de consulta, una E/S eficiente es fundamental tanto para la latencia como para el rendimiento.
Para los datos de colección, Zilliz utiliza el formato abierto Vortex para el diseño de almacenamiento columnar, combinando una codificación eficiente con acceso aleatorio de granularidad fina a fragmentos de datos, significativamente más rápido que Lance y Parquet para lecturas aleatorias.
Para los índices, Zilliz proporciona diseños de algoritmos de indexación conscientes del almacenamiento de objetos con diseños y patrones de acceso profundamente optimizados para una E/S eficiente, incluidos índices vectoriales, índices invertidos BM25 e índices JSON.
Durante la ejecución de consultas, los nodos de cómputo solo cargan parcialmente las páginas de índice y las entidades de datos afectadas por la consulta. Combinado con el almacenamiento en caché y la poda de datos, esto reduce significativamente la amplificación de lectura en más del 90%.
Casos de uso principales de Vector Lakebase
Los escenarios de aplicación típicos para Vector Lakebase incluyen, entre otros:
Cargas de trabajo de servicio en tiempo real:
- Memoria de agente y recuperación de estrategias críticas para la latencia.
- Bases de conocimiento de dominios verticales para los sectores legal, sanitario, financiero y otras industrias especializadas.
- Motores de búsqueda de IA a escala web.
- Sistemas de recomendación de rendimiento ultraalto.
- Programación dinámica de datos calientes/fríos a nivel de segundos entre niveles de almacenamiento.
- Niveles de servicio diferenciados tanto para usuarios empresariales premium como para grandes grupos de usuarios gratuitos.
Cargas de trabajo de descubrimiento iterativo:
- Análisis de calidad de servicios de IA y descubrimiento de problemas en datos de retroalimentación, notas generadas por agentes, registros y otros datos de múltiples fuentes.
- Exploración eficiente de conjuntos de datos a gran escala.
- Investigación profunda iterativa de múltiples pasos.
Cargas de trabajo de análisis por lotes:
- Deduplicación y agrupamiento de corpus a escala ultra grande.
- Incorporación de capacidades de búsqueda de espectro completo a Spark y Ray para un filtrado, recuperación y pipelines de consulta de dos etapas de aproximación preliminar a reranking eficientes.
- Preparación de conjuntos de datos para entrenamiento y ajuste fino.
Casos híbridos:
- Indexación y recuperación aceleradas en tablas de lagos de datos existentes como Lance e Iceberg.
- Modelos de datos en evolución continua con backfills frecuentes a gran escala.
- Modelado de tablas anchas semánticas multimodales, unificando vectores, metadatos, resúmenes generados por LLM y campos estructurados en tablas centradas en entidades con versionado y gestión de linaje consistentes.
Pruebe Zilliz Vector Lakebase
Para obtener más información sobre Vector Lakebase y las últimas actualizaciones, visite el sitio web de Zilliz o explore la documentación de Zilliz Cloud. Si la arquitectura o los casos de uso de este artículo son relevantes para su trabajo, contacte con el equipo de Zilliz para una discusión técnica más profunda.

Sigue leyendo

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.