




Aktivierungsfunktionen in neuronalen Netzwerken

Aktivierungsfunktionen in neuronalen Netzwerken
 Activation Functions.png
Activation Functions.png
Jüngste Fortschritte in der künstlichen Intelligenz (KI ) waren unglaublich, insbesondere in der Bilderkennung, Verarbeitung natürlicher Sprache (NLP) und bei selbstfahrenden Autos. Ein Schlüsselfaktor, der zu diesen Erfolgen beiträgt, ist die Fähigkeit künstlicher neuronaler Netzwerke, komplexe, nichtlineare Funktionen zu schätzen, die häufig in realen Daten vorkommen. Diese Fähigkeit wird hauptsächlich Aktivierungsfunktionen zugeschrieben, die Nichtlinearität in neuronale Netzwerke einführen und es ihnen ermöglichen, komplexe Beziehungen und Muster zu modellieren.
Lassen Sie uns Aktivierungsfunktionen eingehend verstehen, ihren Zweck, wie sie funktionieren und warum sie für neuronale Netzwerke wichtig sind.
Was sind Aktivierungsfunktionen?
Aktivierungsfunktionen sind mathematische Funktionen, die in neuronalen Netzwerken verwendet werden, um die Ausgabe eines Neurons zu bestimmen und Nichtlinearität in das Modell einzuführen. Sie werden auf die Eingaben von Knoten (Neuronen), den grundlegenden Einheiten eines neuronalen Netzwerks, angewendet, um die Ausgabe des Knotens zu erzeugen. Ein neuronales Netzwerk berechnet die gewichtete Summe der Eingaben, fügt einen Bias hinzu und leitet diese Summe dann durch die Aktivierungsfunktion, die einen modifizierten Wert ausgibt. Dieser Wert wird an die nächste Netzwerkschicht weitergegeben oder wird zur endgültigen Ausgabe.
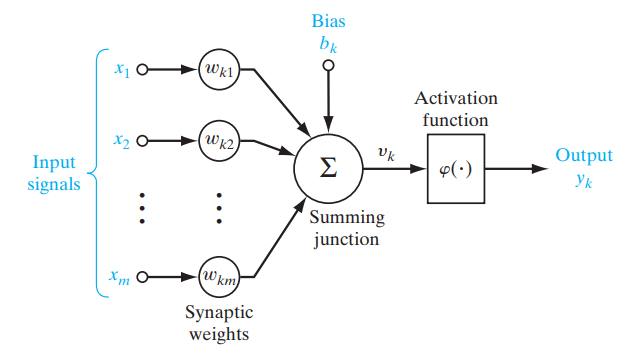 Figure- Role of an activation function in a neural network. .png
Figure- Role of an activation function in a neural network. .png
Abbildung: Rolle einer Aktivierungsfunktion in einem neuronalen Netzwerk. | Quelle
Warum Nichtlinearität wichtig ist?
Um zu verstehen, warum Aktivierungsfunktionen wesentlich sind, ist es wichtig zu wissen, warum lineare Modelle Einschränkungen haben. Ein lineares Modell stellt eine geradlinige Beziehung zwischen Eingaben und Ausgaben dar. Es funktioniert gut bei einfachen Aufgaben, versagt jedoch, wenn Daten komplexer sind und nichtlineare Muster aufweisen.
Nichtlinearität ermöglicht es neuronalen Netzwerken, Entscheidungsgrenzen zu erstellen, die keine geraden Linien sind. Daher können neuronale Netzwerke nichtlineare Muster in Daten verstehen, die durch lineare Modelle nicht dargestellt werden können.
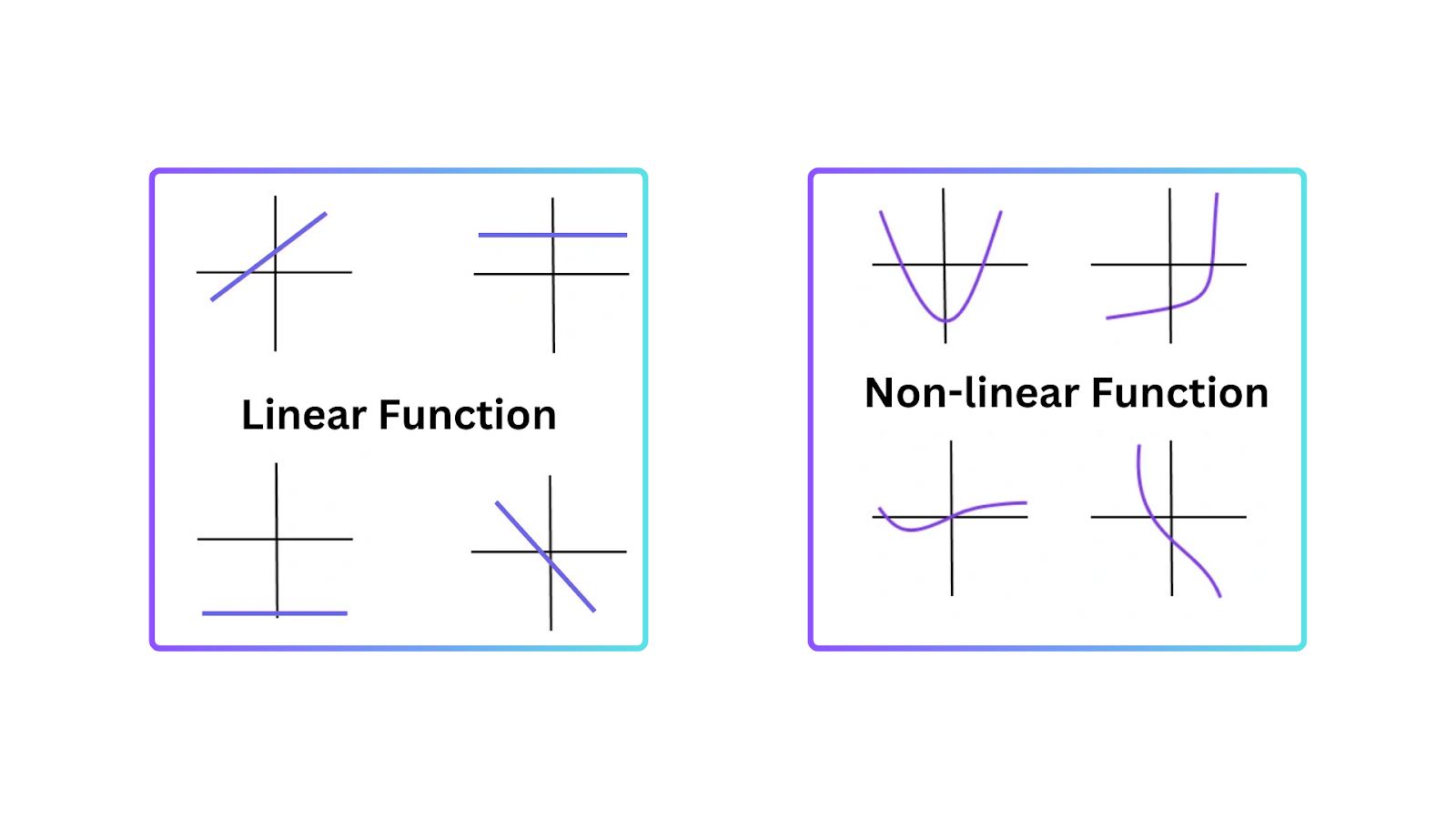 Figure- Types of Functions.png
Figure- Types of Functions.png
Abbildung: Arten von Funktionen
Wie Aktivierungsfunktionen funktionieren
Nachdem wir Aktivierungsfunktionen eingeführt haben, sehen wir uns nun an, wie diese Funktionen mathematisch funktionieren, um das Eingangssignal in ein Ausgangssignal umzuwandeln, einen Bereich, der häufig zwischen 0 und 1 oder -1 und 1 liegt. In jedem Neuron eines neuronalen Netzwerks fließen Daten in den folgenden Schritten:
Eingabe: Jedes Neuron in einem neuronalen Netzwerk erhält eine oder mehrere Eingaben. Diese Eingaben können aus den ursprünglichen Daten stammen, die in das Netzwerk eingespeist werden (im Fall der Eingabeschicht), oder aus den Ausgaben von Neuronen in der vorherigen Schicht.
Berechnung der gewichteten Summe: Die Eingaben werden mit entsprechenden Gewichten multipliziert, um ihre Bedeutung zu bestimmen. Anschließend werden die gewichteten Eingaben aufsummiert, und ein einzelner Wert wird zurückgegeben, der als gewichtete Summe bekannt ist.
Anwendung der Aktivierungsfunktion: Sobald die gewichtete Summe berechnet wurde, wird sie durch eine Aktivierungsfunktion geleitet, und das Ergebnis der Aktivierungsfunktion wird zur Ausgabe des Neurons.
Dieser Prozess wiederholt sich in jedem Neuron über die Netzwerkschichten hinweg, um die Daten auf komplexere Weise zu verändern.
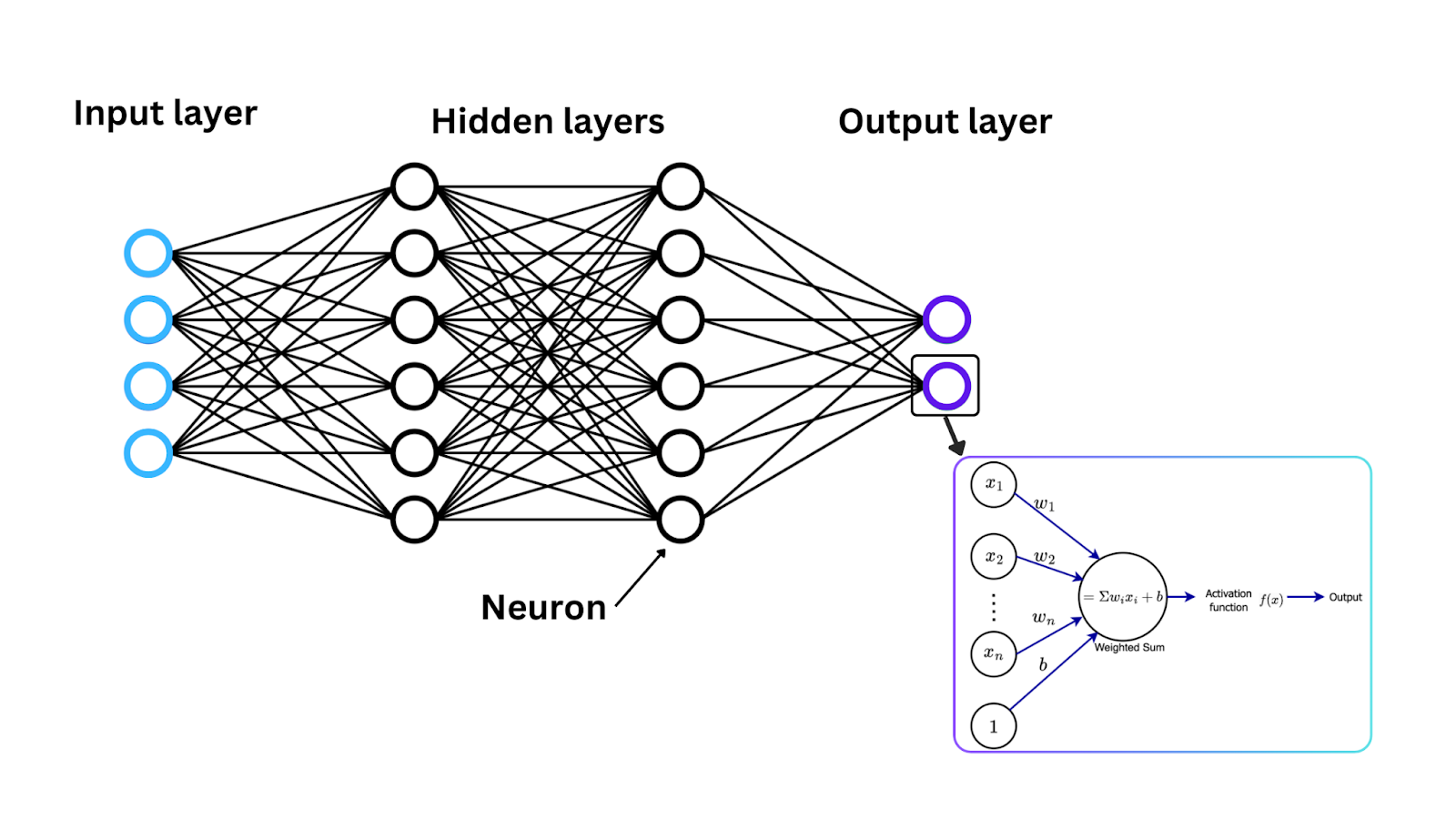 Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figure- Neural network architecture, activation function, and neuron weight updates. .png
Abbildung: Architektur neuronaler Netzwerke, Aktivierungsfunktion und Aktualisierungen der Neuronengewichte.
Neuronale Netze verwenden verschiedene Arten von Aktivierungsfunktionen. Jede Funktion hat ihre eigenen Stärken und ist für bestimmte Aufgaben besser geeignet. Beispielsweise ist die Sigmoid-Funktion optimal für binäre Klassifikationsprobleme, Softmax ist nützlich für die Mehrklassen-Vorhersage, und ReLU hilft, das Problem des verschwindenden Gradienten zu überwinden.
Die Wahl der richtigen Aktivierungsfunktion beschleunigt das Training und verbessert die Leistung. Schauen wir uns nun einige der gängigen Aktivierungsfunktionen an:
Sigmoid-Aktivierung
ReLU (Rectified Linear Unit)-Aktivierung
Tanh (Hyperbolischer Tangens)-Aktivierung
Leaky-ReLU-Aktivierung
Sigmoid-Aktivierung
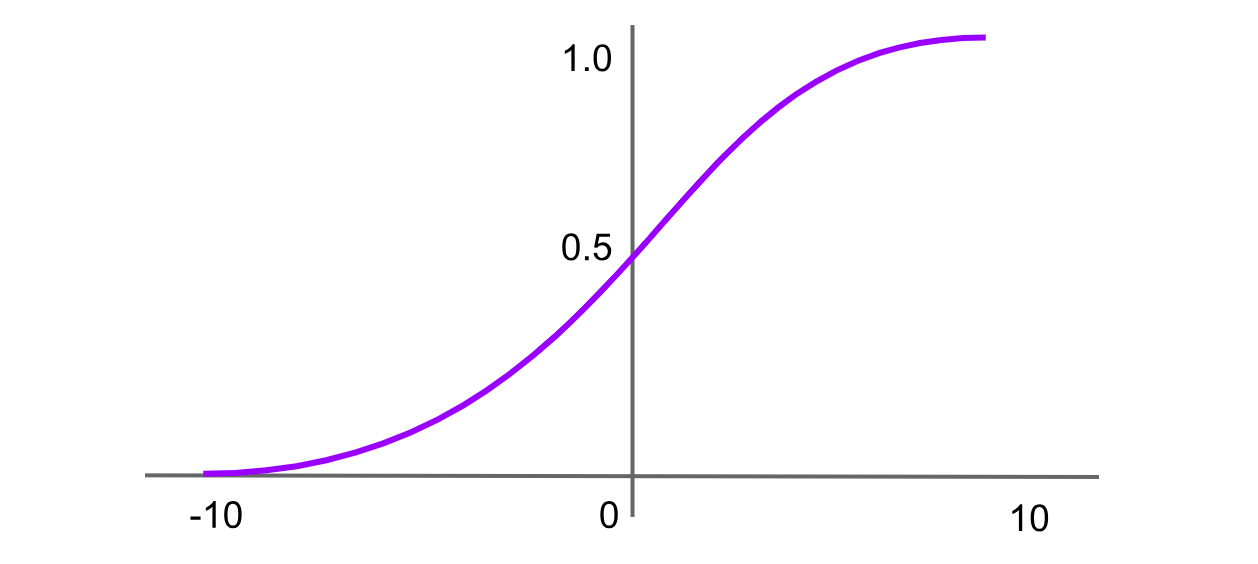 Abbildung- Sigmoid-Aktivierungsfunktion.png
Abbildung- Sigmoid-Aktivierungsfunktion.png
Abbildung: Sigmoid-Aktivierungsfunktion
Die Sigmoid-Funktion, auch als logistische Funktion bekannt, ist eine der frühesten und bekanntesten Aktivierungsfunktionen. Sie bildet jeden Eingabewert auf einen Bereich zwischen 0 und 1 ab und erzeugt eine „S“-förmige Kurve. Die Formel für die Sigmoid-Funktion lautet:
Sigmoid = σ(x) = 1 / (1 + exp(-x))
Hier ist der Code zur Definition der Sigmoid-Funktion in Python.
import numpy as np
def sigmoid_function(x):
z = (1/(1 + np.exp(-x)))
return z
Sigmoid-Funktionen sind nützlich für Modelle, bei denen wir die Wahrscheinlichkeit als Ausgabe vorhersagen müssen. Beispielsweise möchten wir bei binären Klassifikationsproblemen, dass die Ausgabe als Wahrscheinlichkeit zwischen 0 und 1 interpretiert wird.
Allerdings hat die Sigmoid-Funktion ein Problem mit verschwindenden Gradienten. Während der Backpropagation (wenn das Netzwerk durch Aktualisierung der Gewichte lernt) werden Sigmoid-Gradienten sehr klein, was bei tieferen Schichten zu langsamem Lernen führt.
Softmax-Aktivierung
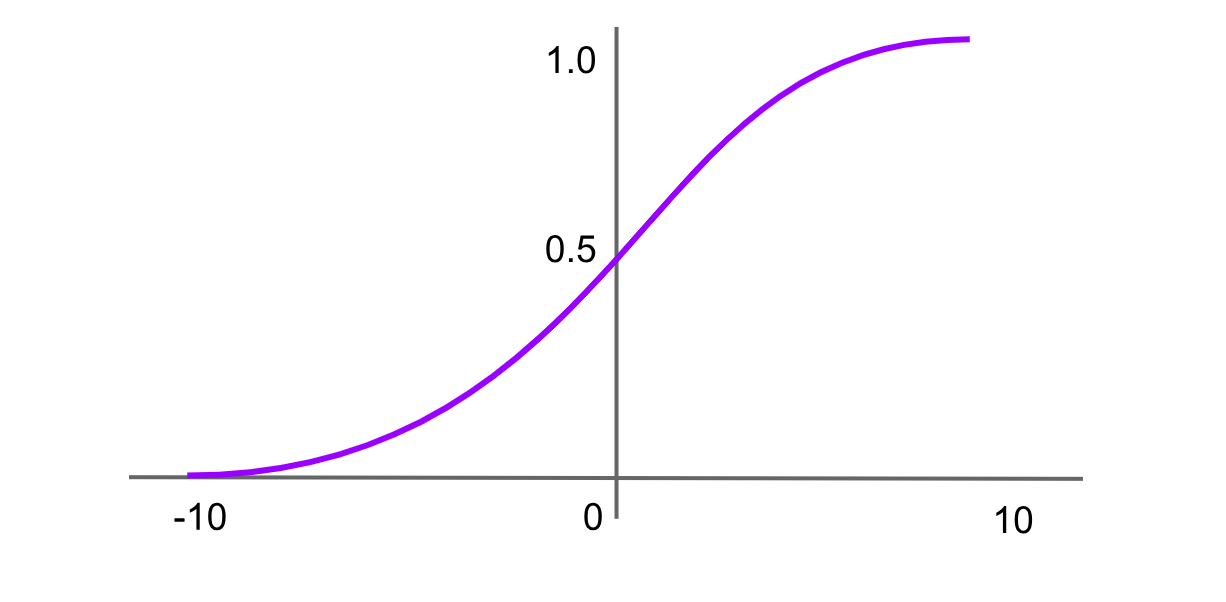 Abbildung- Softmax-Aktivierungsfunktion.png
Abbildung- Softmax-Aktivierungsfunktion.png
Abbildung: Softmax-Aktivierungsfunktion
Die Softmax-Funktion wird häufig in der Ausgabeschicht neuronaler Netze für Mehrklassen-Klassifikationsprobleme verwendet. Sie nimmt einen Vektor reeller Zahlen als Eingabe und normalisiert ihn zu einer Wahrscheinlichkeitsverteilung über die Klassen. Jede Ausgabe liegt zwischen 0 und 1, und alle Ausgaben summieren sich zu 1. Die Formel für die Softmax-Funktion lautet:
Softmax(x)=f(xi)= exp(x) / sum(exp(x))
Lassen Sie uns dies in Python programmieren.
def softmax_function(x):
z = np.exp(x)
z_ = z/z.sum()
return z_
Allerdings kann Softmax rechenintensiv sein, insbesondere in großen Netzwerken, da Exponentialfunktionen berechnet und über alle Ausgaben normalisiert werden müssen.
ReLU (Rectified Linear Unit)-Aktivierung
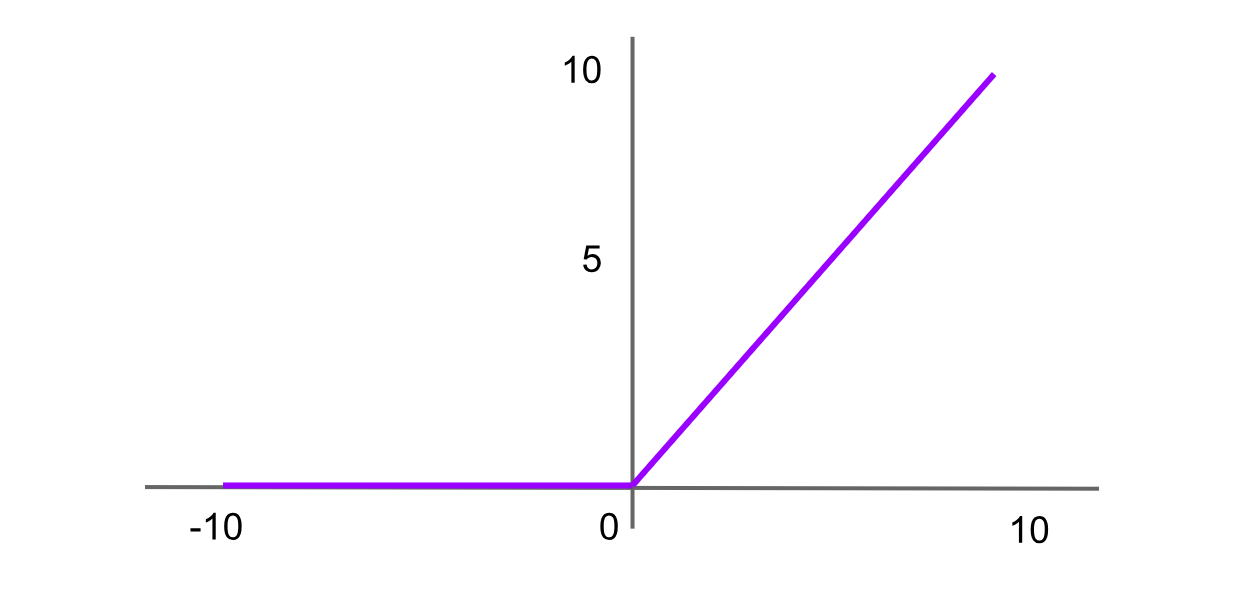 Abbildung- ReLU-Aktivierungsfunktion.png
Abbildung- ReLU-Aktivierungsfunktion.png
Abbildung: ReLU-Aktivierungsfunktion
ReLU ist eine der am häufigsten verwendeten Aktivierungsfunktionen in fortgeschrittenen neuronalen Netzen. Sie gibt für jede negative Eingabe 0 zurück, und für positive Werte gibt sie den Wert selbst zurück. Die Formel für die ReLU-Funktion lautet:
ReLU = f(x) = max(0,x)
Hier ist die Python-Funktion für ReLU:
def relu_function(x):
if x<0:
return 0
else:
return x
ReLU wird in verborgenen Schichten von neuronalen Netzen verwendet, insbesondere bei Computer-Vision-Aufgaben. Sie ist recheneffizient, da sie keine Exponential- oder Divisionsoperationen enthält. Im Vergleich zu Sigmoid ist sie außerdem weniger vom Problem des verschwindenden Gradienten betroffen. Allerdings gibt es einen Nachteil von ReLU, nämlich das Problem der „dying ReLU“. Wenn ein Neuron für alle Eingaben konsistent null ausgibt, wird es inaktiv und kann nicht mehr zum Lernen beitragen.
Tanh (Hyperbolischer Tangens)-Aktivierung
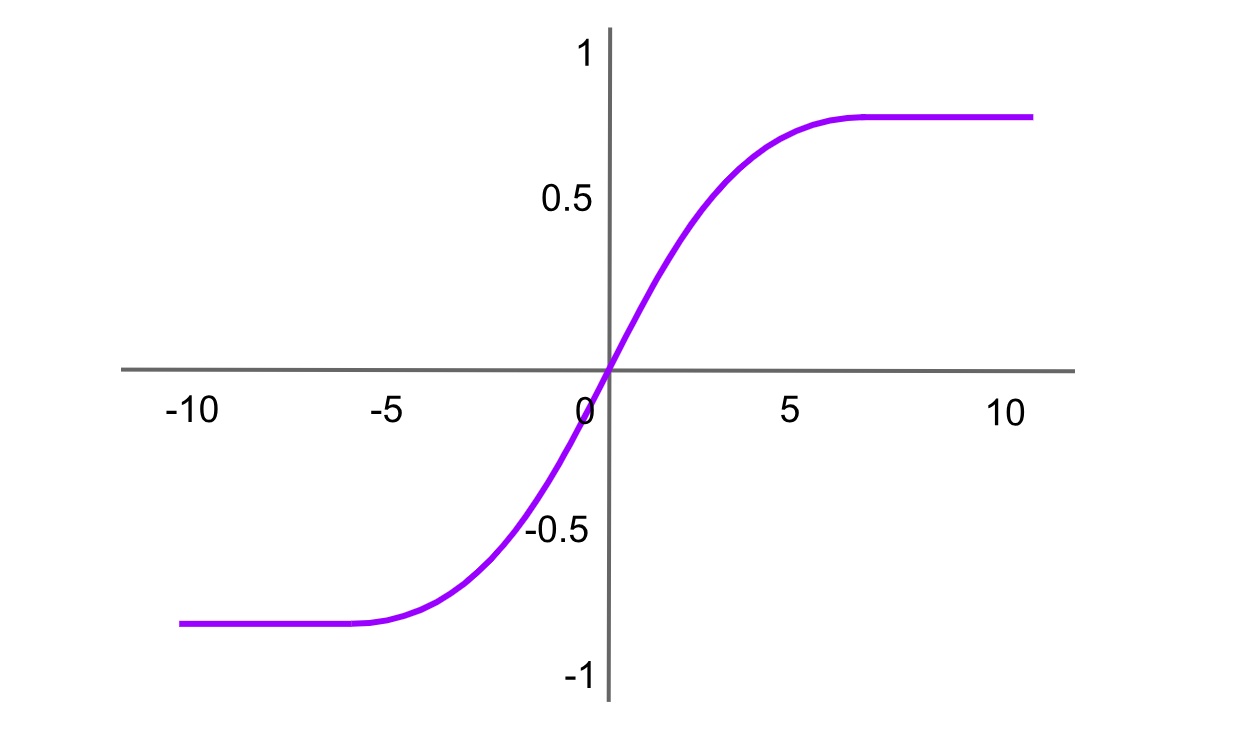 Abbildung- Tanh-Aktivierungsfunktion .png
Abbildung- Tanh-Aktivierungsfunktion .png
Abbildung: Tanh-Aktivierungsfunktion
Die hyperbolische Tangensfunktion ähnelt der Sigmoidfunktion, gibt jedoch Werte zwischen -1 und 1 aus. Die Formel für die Tanh-Funktion lautet:
tanh(x)= f(x)= 2 / (1+exp (−2x ))−1
Oder
tanh(x)= f(x)=2sigmoid(2x)-1
Hier ist der entsprechende Python-Code:
def tanh_function(x):
z = (2/(1 + np.exp(-2*x))) -1
return z
Der hyperbolische Tangens wird in verborgenen Schichten neuronaler Netzwerke verwendet, insbesondere bei Aufgaben der Verarbeitung natürlicher Sprache (NLP). Er weist einige Ähnlichkeiten mit der Sigmoidfunktion auf, hat jedoch den Vorteil, dass er um null zentriert ist, was das Lernen in bestimmten Netzwerken beschleunigen kann. Allerdings ist tanh, wie die Sigmoidfunktion, ebenfalls vom Problem des verschwindenden Gradienten betroffen.
Leaky-ReLU-Aktivierung
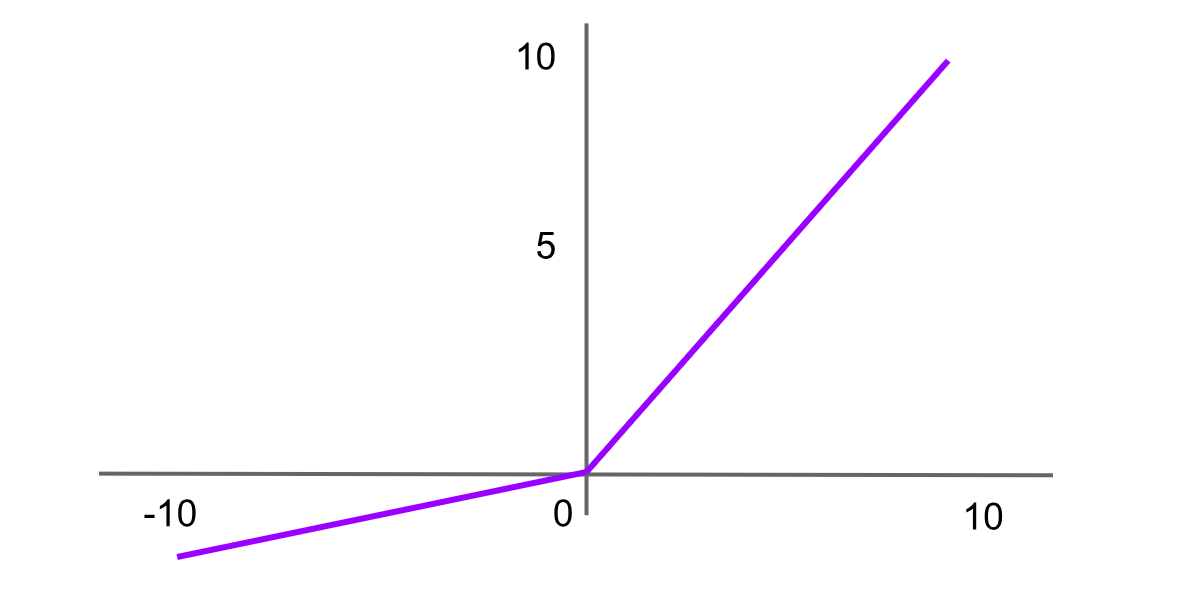 Abbildung- Leaky-ReLU-Aktivierungsfunktion .png
Abbildung- Leaky-ReLU-Aktivierungsfunktion .png
Abbildung: Leaky-ReLU-Aktivierungsfunktion
Leaky Rectified Linear Unit, oder Leaky ReLU, ist eine Variante von ReLU, die entwickelt wurde, um das Problem der „sterbenden ReLU“ zu lösen, indem für negative Werte anstelle einer flachen Steigung eine kleine Steigung eingeführt wird. Dies hilft Neuronen, weiterzulernen, anstatt dauerhaft inaktiv zu sein. Die Formel für die Leaky-ReLU-Funktion lautet:
Leaky ReLU = f(x)=max(αx,x)
Hier ist 𝛼 α eine kleine positive Konstante (z. B. 0,01), um sicherzustellen, dass das Neuron bei negativen Eingaben statt null einen kleinen negativen Wert ausgibt. Da Leaky ReLU eine Variante von ReLU ist, kann der Python-Code mit einer kleinen Änderung implementiert werden.
def leaky_relu_function(x):
if x<0:
return 0.01*x
else:
return x
Vergleich
Um ein besseres Verständnis der Aktivierungsfunktionen zu erhalten, ist es hilfreich, sie mit anderen Schlüsselkomponenten neuronaler Netzwerke zu vergleichen:
Aktivierungsfunktionen vs. Verlustfunktionen
Aktivierungsfunktionen definieren, wie die Neuronen in einem Netzwerk auf eingehende Signale reagieren. Sie werden auf die Ausgaben von Neuronen (oder Schichten) angewendet, um Nichtlinearität einzuführen, was dem Netzwerk hilft, Muster und Beziehungen in den Daten zu verstehen.
Andererseits werden Verlustfunktionen verwendet, um zu bestimmen, wie gut die Vorhersagen des neuronalen Netzwerks mit den tatsächlichen Zielwerten (der Ground Truth) übereinstimmen. Sie berechnen den Fehler zwischen der vorhergesagten Ausgabe und den tatsächlichen Ergebnissen. Zusätzlich passen Optimierungsalgorithmen die Gewichte des Netzwerks während des Trainings an, um diesen Fehler zu minimieren. Verlustfunktionen umfassen:
Mittlerer quadratischer Fehler (MSE) wird häufig für Regressionsaufgaben verwendet.
Kreuzentropieverlust wird für Klassifikationsaufgaben verwendet.
Aktivierungsfunktionen vs. Normalisierung
Aktivierungsfunktionen steuern, wie sich die Daten von einer Schicht zur nächsten bewegen und wie Neuronen basierend auf Eingaben „feuern“.
Jedoch hilft Normalisierung, wie etwa Batch-Normalisierung, dabei, das Training effektiver zu machen. Sie funktioniert, indem sie die Verteilung der Eingaben in eine Schicht verändert, um das Lernen des Netzwerks zu beschleunigen und verschwindende oder explodierende Gradienten zu verhindern. Batch-Normalisierung normalisiert die Eingabe jeder Schicht so, dass sie einen konsistenten Mittelwert und eine konsistente Varianz aufweist, und erleichtert die Konvergenz des Netzwerks. Weitere Normalisierungstechniken umfassen:
Layer-Normalisierung: Normalisiert über jede Schicht hinweg.
Instanznormalisierung: Wird üblicherweise in der Bildverarbeitung verwendet und normalisiert jede Instanz separat.
Vorteile und Herausforderungen von Aktivierungsfunktionen
Aktivierungsfunktionen bieten neuronalen Netzwerken mehrere Vorteile, bringen aber auch Herausforderungen mit sich, die adressiert werden müssen. Lassen Sie uns zunächst die Vorteile der Aktivierungsfunktionen besprechen.
Nichtlinearität: Der wichtigste Vorteil von Aktivierungsfunktionen ist, dass sie Nichtlinearität in das Netzwerk einführen. Dies hilft den Netzwerken, nichtlineare Muster in Daten zu erfassen, und ist ideal für Aufgaben wie Bilderkennung und Verständnis natürlicher Sprache.
Ausgabebereich: Aktivierungsfunktionen wie Sigmoid und Softmax begrenzen die Ausgaben auf einen bestimmten Bereich (0-1 für Sigmoid und zwischen -1 und 1 für tanh). Dadurch wird es viel einfacher, die Ausgaben zu verstehen, insbesondere bei Klassifizierungsaufgaben.
Effiziente Berechnung: Einige Funktionen, wie ReLU, sind recheneffizient, wodurch Netzwerke skaliert und auf große Datensätze angewendet werden können.
Lassen Sie uns nun die Herausforderungen von Aktivierungsfunktionen besprechen.
Vanishing-Gradient-Problem: Es tritt häufig in tiefen neuronalen Netzwerken auf, vor allem bei der Verwendung von Aktivierungsfunktionen wie Sigmoid und tanh. Während der Backpropagation können die Gradienten sehr klein werden, während sie sich durch mehrere Netzwerkschichten ausbreiten, was die langsame Konvergenz des Netzwerks verursacht und es daran hindert, effektiv zu lernen.
Explodierende Gradienten: Explodierende Gradienten sind ein Problem, bei dem sich große Fehlergradienten ansammeln, was während des Trainingsprozesses zu sehr großen Aktualisierungen der Gewichte neuronaler Netzwerkmodelle führt. Dadurch wird das Modell instabil und unfähig, aus den Trainingsdaten zu lernen.
Wahl der Funktion: Die Wahl der optimalen Aktivierungsfunktion für eine Aufgabe oder ein neuronales Netzwerk kann herausfordernd sein und erfordert in der Regel einige Experimente. Sie hängt von der Art des Problems ab, das wir zu lösen versuchen.
Anwendungsfälle von Aktivierungsfunktionen
Aktivierungsfunktionen sind wichtige Komponenten verschiedener Architekturen neuronaler Netzwerke, die unterschiedliche Aufgaben ausführen. Hier sind einige wichtige Anwendungen:
Bildklassifizierung: Convolutional Neural Networks (CNNs) verwenden ReLU-Aktivierung in ihren verborgenen Schichten, um Pixeldaten zu verarbeiten, und Softmax in der Ausgabeschicht für die Mehrklassenklassifizierung.
Verarbeitung natürlicher Sprache (NLP): Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) und Transformers verwenden tanh- oder ReLU-Aktivierungen in ihren verborgenen Schichten, um sequenzielle Daten zu verarbeiten.
Generative Modelle: Generative Adversarial Networks (GANs) verwenden typischerweise ReLU oder LeakyReLU im Generatornetzwerk, um Nichtlinearität einzuführen und realistische Ausgaben zu erzeugen, sowie Sigmoid im Diskriminatornetzwerk.
Mehrere Deep-Learning-Frameworks, darunter TensorFlow und PyTorch, bieten eine breite Palette integrierter Aktivierungsfunktionen und Implementierungen, um eigene zu erstellen.
FAQs zu Aktivierungsfunktionen
- Was ist die Aktivierungsfunktion?
Aktivierungsfunktionen sind grundlegende Bausteine neuronaler Netzwerke, die es ihnen ermöglichen, komplexe Muster in Eingabedaten zu lernen. Sie wandeln das Eingangssignal eines Knotens (Neurons) in ein Ausgangssignal um, das dann an die nächste Schicht des neuronalen Netzwerks weitergegeben wird.
- Warum wird die ReLU-Aktivierungsfunktion verwendet?
Die ReLU-Aktivierungsfunktion führt Nichtlinearität in ein neuronales Netzwerk ein, was dazu beiträgt, das Vanishing-Gradient-Problem während des Trainings von Machine-Learning-Modellen zu reduzieren.
- Was sind die am häufigsten verwendeten Aktivierungsfunktionen?
ReLU, Leaky ReLU, Softmax und Swish sind beliebte Aktivierungsfunktionen.
- Wofür wird die Aktivierungsfunktion verwendet?
Der Hauptzweck einer Aktivierungsfunktion besteht darin, die summierte gewichtete Eingabe eines Knotens in einen Ausgabewert umzuwandeln, der dann an die nächste verborgene Schicht weitergegeben oder als endgültige Ausgabe verwendet wird.
- Kann man mehrere Aktivierungsfunktionen haben?
Ja, es ist üblich, in verschiedenen Schichten eines neuronalen Netzwerks unterschiedliche Aktivierungsfunktionen zu haben. Beispielsweise könnte eine Standardkonfiguration ReLU-Aktivierung in verborgenen Schichten und Softmax in der Ausgabeschicht für ein Mehrklassen-Klassifikationsproblem verwenden.
Weitere Ressourcen
- Was sind Aktivierungsfunktionen?
- Wie Aktivierungsfunktionen funktionieren
- Vergleich
- Vorteile und Herausforderungen von Aktivierungsfunktionen
- Anwendungsfälle von Aktivierungsfunktionen
- FAQs zu Aktivierungsfunktionen
- Weitere Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren