




Vector Search and RAG - Balancing Accuracy and Context
Introduction
Large language models (LLMs) have made significant strides, especially in machine learning and natural language processing, making machines handle intricate tasks with ease. However, as LLM technology grows, it has faced a unique issue: AI hallucinations. This is when AI generates incorrect or false information, making us question how trustworthy these systems are. Christy Bergman, a Developer Advocate at Zilliz with rich experience in AI/ML, recently talked about the impact of these hallucinations and how they affect the rollout of AI systems at the Unstructured Data Meetup.
During her presentation, Christy discussed what causes AI hallucinations and their effects. She also mentioned the main concept called Retrieval Augmented Generation (RAG), a method used to make language models more reliable by providing relevant, current information related to a user's question. This technique helps ensure that the models can access the newest data, like recent news or research, to give better answers and reduce mistakes.
Understanding AI Hallucinations
AI hallucinations refer to the phenomenon where artificial intelligence systems, particularly those based on large language models, generate factually incorrect, misleading, or entirely fabricated outputs.
This issue can happen for several reasons:
- Lack of Context: AI models may not have enough context to generate accurate responses, especially when dealing with complex or nuanced queries.
- Training Data Issues: The data used to train AI models may contain errors, biases, or outdated information, which the models can inadvertently replicate.
- Overgeneralization: AI models might overgeneralize from their training data, leading to incorrect extrapolations when faced with novel inputs.
- Design Limitations: Some AI architectures are not designed to verify the truthfulness of their outputs, focusing instead on generating statistically likely responses based on their training data.
Christy gave a great example of this at the Unstructured Data Meetup. She asked the AI system "Gemini" to list three politicians born in New York, and it included Hillary Clinton, which is wrong because she was born in Chicago.
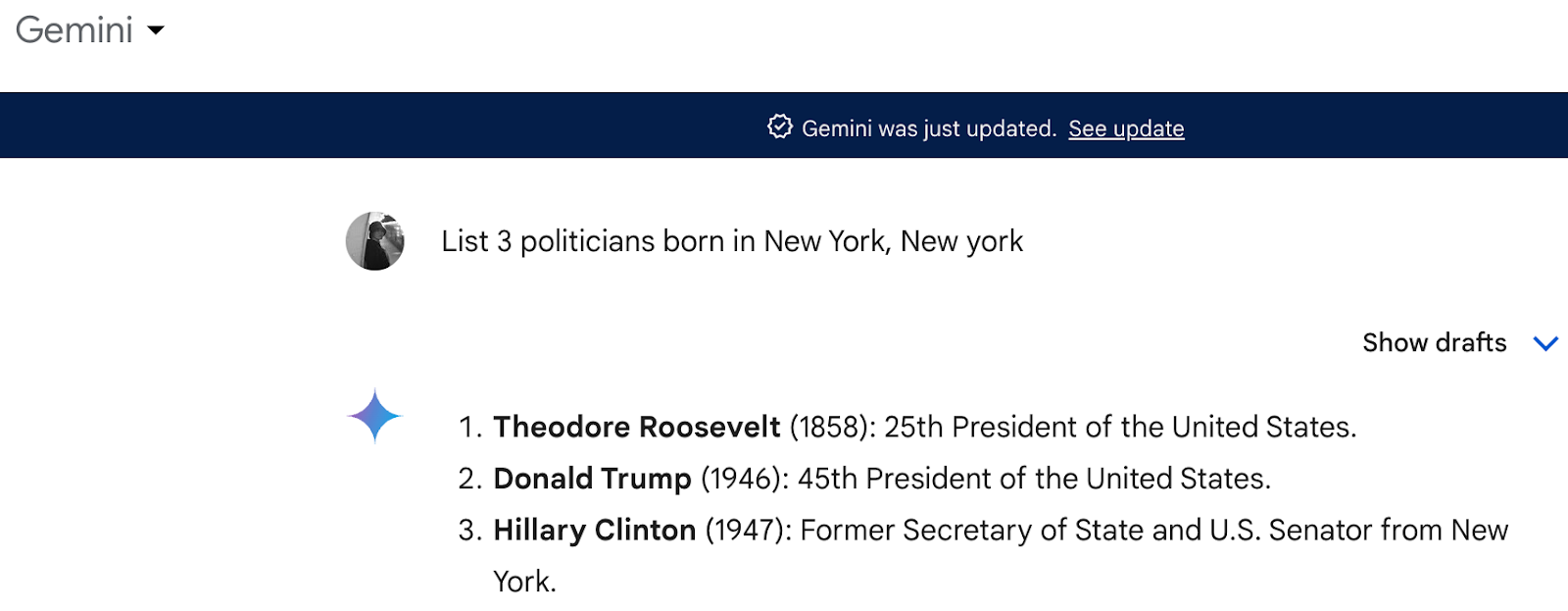

This example demonstrates how AI can make mistakes, even on simple and straightforward questions.
As Christy mentioned, “Note that LLMs can be trained on unconventional sources, such as Reddit, which may lead to unusual results.”
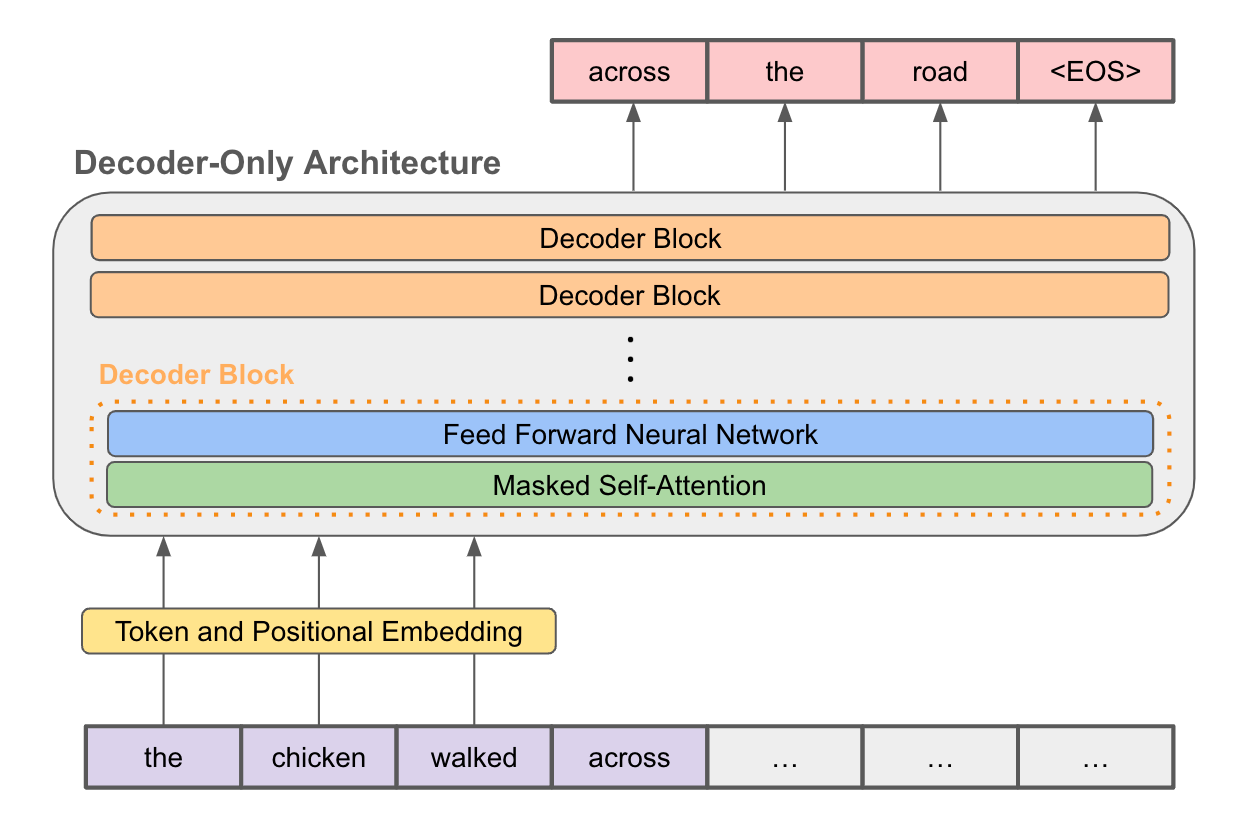
How RAG Alleviates Hallucinations
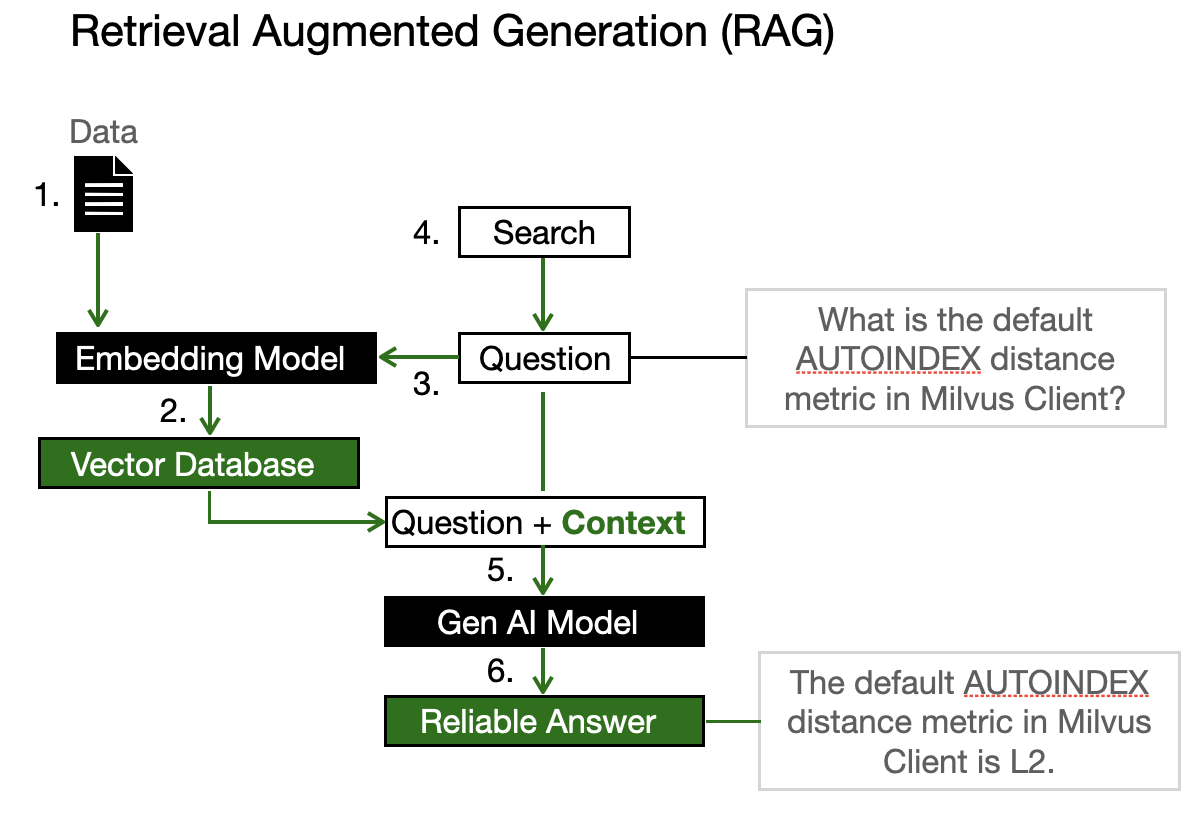
Retrieval Augmented Generation (RAG) is an advanced approach in natural language processing that aims to enhance the accuracy and reliability of AI models, particularly in reducing hallucinations.
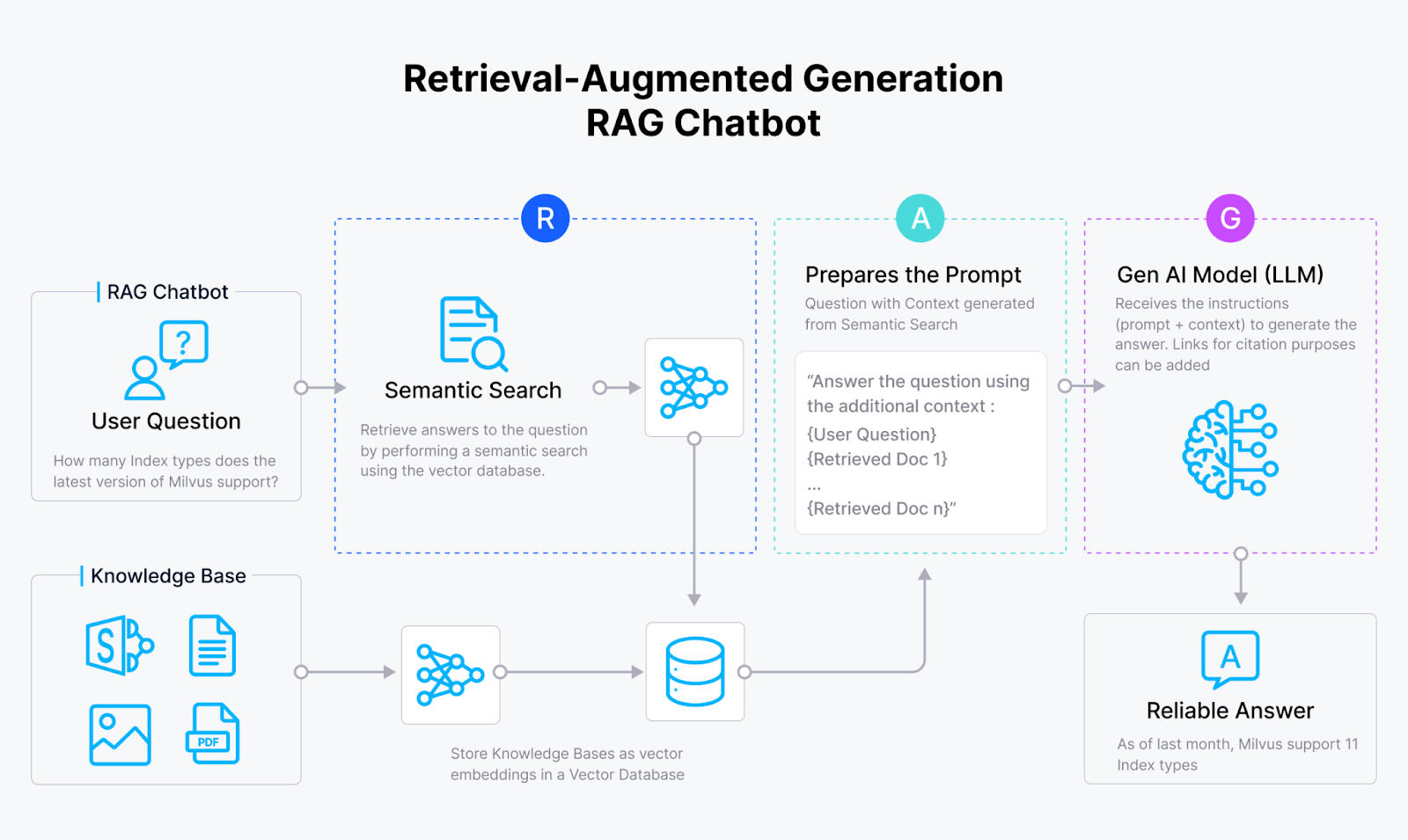
Christy explained that RAG is a new method to integrate your own data into the generative AI process. Here's how it works in simple terms:
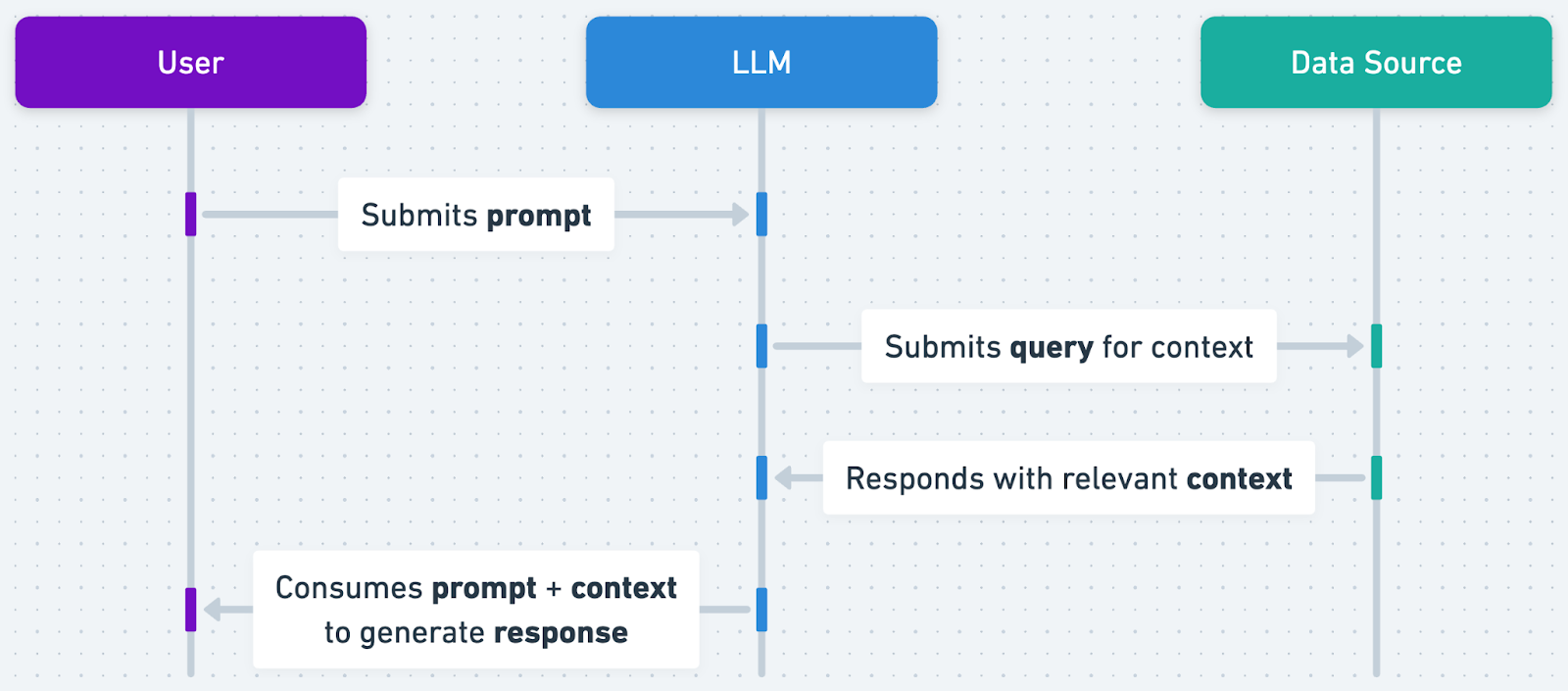
You start by feeding your data into an embedding model. This model turns the information into a bunch of numbers called vectors, which are then stored in a vector database.
When you ask a question, the same embedding model transforms your query into a vector too, and then searches for the nearest vector neighbors in this database or vector space. Once it finds the closest match, it uses that as context, along with your question, to prompt the large language model. This way, you get an answer that's more likely to be accurate.
Now, here's how RAG tackles AI hallucinations:
1. Staying Current: RAG models can incorporate the newest data, ensuring their responses are based on the latest information.
2. Accuracy and Detail: These models are designed to provide accurate answers by retrieving specific, relevant information. This process reduces the likelihood of generating false or fabricated content and ensures that the responses are detailed and precisely tailored to the question, avoiding overly general statements.
Challenges Of Building A RAG System
Building a Retrieval Augmented Generation (RAG) system involves several complex steps and decisions. Here are some key challenges:
Choosing an Embedding Model
When choosing an embedding mode, you can focus on a few key factors:
- Vector Dimension: Pick models that produce vectors of a size that's easy to work with.
- Retrieval Performance: Look at how well-known models from places like Cohere and Voyager perform.
- Model Size: Consider the model's size to ensure it fits your computational capabilities.
- Accuracy: Ensure the model can grasp the fine details important to your field or product.
- Scalability: Make sure the model can handle more data as your needs grow.
And for your options, you can choose from:
Open Source Models: These are freely available and can be compared and selected from platforms like the Hugging Face embedding model hub.
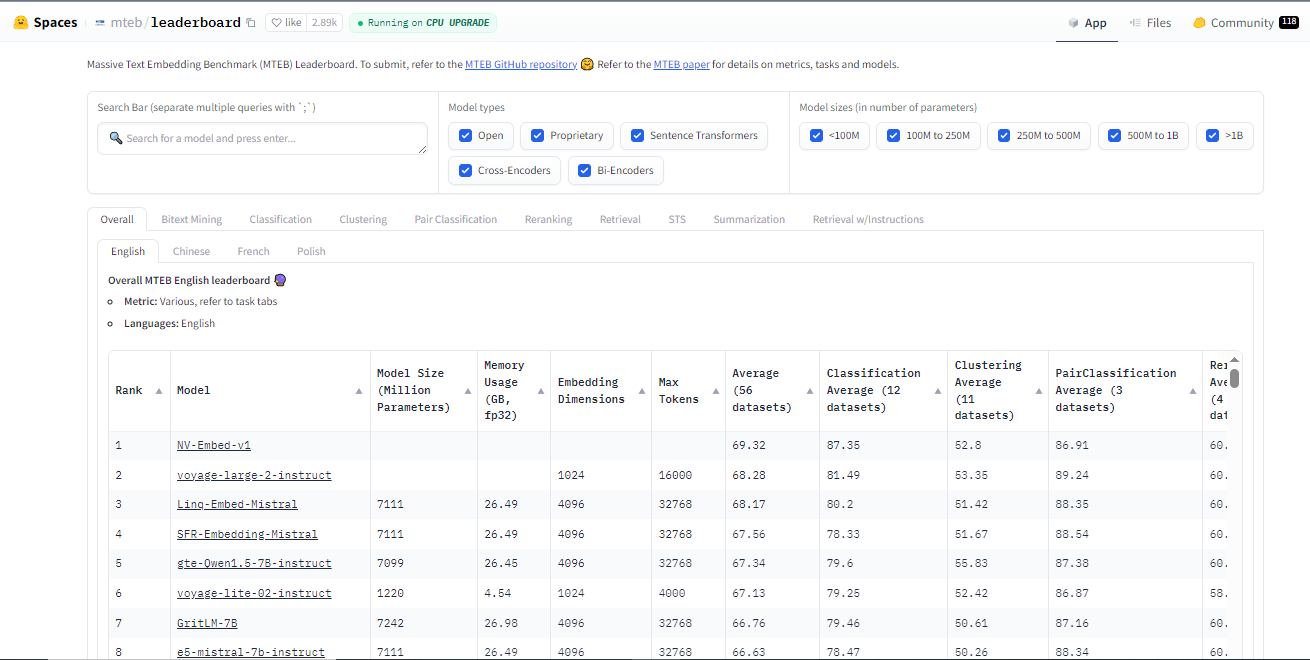
Proprietary Models: Companies like Cohere or OpenAI offer models that might have unique features or better performance for specific tasks but come at a cost.
Choosing an Index
Selecting an appropriate index structure is critical for the system's performance. This involves considering:
- Scalability: The index must be able to scale to millions or billions of documents without becoming prohibitively slow.
- Memory footprint: Efficient use of memory is important, especially when dealing with large datasets.
- Retrieval speed vs. accuracy: There's often a trade-off between how quickly documents can be retrieved and how accurately they match the query.
Chunking
Chunking involves breaking down documents into smaller, semantically coherent parts to facilitate more precise retrieval.
- Determining chunk size: Too large, and the chunks may be less focused; too small, and important context might be lost.
- Maintaining coherence: Ensuring that each chunk remains meaningful and coherent on its own.
- Handling overlaps: Deciding how to manage information that could fit into multiple chunks.
Keywords or Semantic Search
The choice between keyword-based and semantic search can affect the system's ability to understand and respond to queries.
While keyword search can seem simple and fast, missing documents that do not contain the exact keywords, even if they are semantically relevant can greatly affect our accuracy. On the contrary, semantic search offers a deeper understanding of the query's intent but requires more computational resources and sophisticated models.
Rerankers
Rerankers are additional models or algorithms that refine the initial retrieval results, aiming to improve the relevance and accuracy of the documents selected for generating the final response. The question becomes are they worth using and what do we need to integrate them successfully?
- Integration: Rerankers must be seamlessly integrated into the system without introducing significant latency.
- Training data: Like other models, rerankers need high-quality, representative training data to be effective.
- Tuning: Finding the right balance between the initial retrieval and the reranking phase can be challenging.
Is RAG Dead?
One question from Christy's talk that's been bugging me lately is whether RAG's still the star of the show now that long-context LLMs are stepping up their game.
The recent advancements in Long Context LLMs have raised questions about the future of Retrieval-Augmented Generation (RAG) techniques. With models like Claude or Gemini 1.5 Pro, which can process up to 10 million tokens, some argue that RAG's dynamic retrieval approach is no longer necessary.
The Showdown: Can Long Context Ditch RAG?
This is the question that's got everyone talking. Let's break it down.
Cost and Efficiency:
RAG's frugal nature, grabbing only what it needs, saves on computing costs. But as AI tech prices drop, long-context LLMs become more wallet-friendly. It's a close call here.
Retrieval and Reasoning Dynamics:
Long-context LLMs blend their thinking with information retrieval, creating a more personalized touch to answers. RAG's upfront info grab can feel a bit robotic in comparison.
Scalability and Data Complexity:
RAG's ability to handle trillions of tokens is its trump card, making it king for handling massive, ever-changing datasets. Long-context LLMs are left in the dust here.
Collaboration Over Competition:
Why not use both? Combining RAG's precision with the adaptability of long-context models could lead to a powerful synergy.
OpenAI RAG vs. Your Customized RAG
Well, you've seen what RAG is and the challenges it presents. Now, it's time to dive into the technical aspects of building a RAG. Specifically, we'll be discussing OpenAI's RAG and how it compares to building a customized RAG using vector databases like Milvus.
A great question asked by an audience member was “What are the reasons to do a custom RAG instead of an Open AI RAG”
As Christy mentioned the most important part is “ So you can have more insight into the RAG system which you do not have using Open AI, as a developer you know what to tweak”
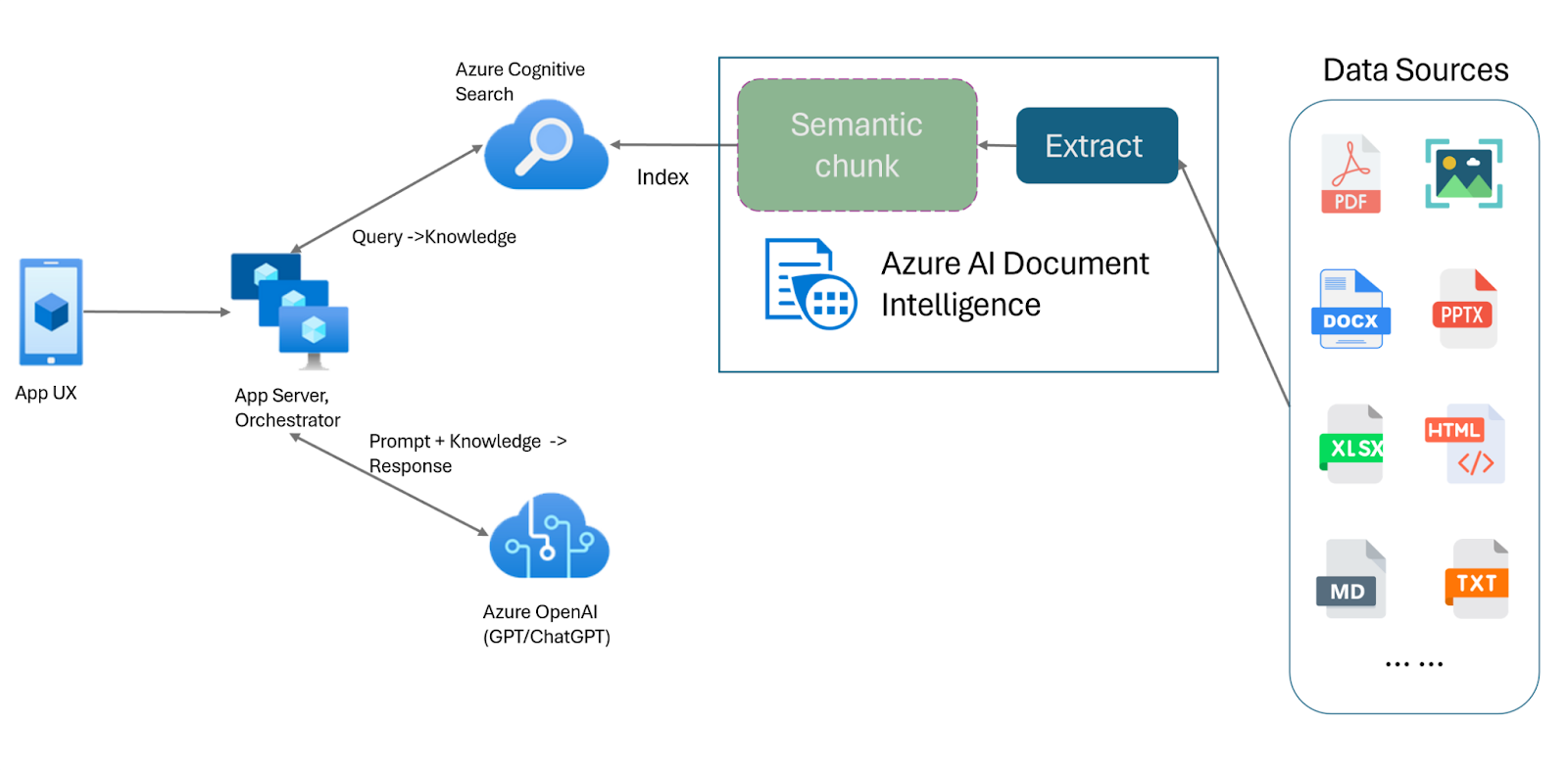
The Role of OpenAI Assistant API in Building RAG
The OpenAI Assistant API is a powerful tool that lets you create AI assistants inside your own apps. An Assistant has instructions and can use models, tools, and files to respond to user queries. This API is great for apps that need engaging, long-term conversations, like customer support or virtual personal assistants.
Comparing OpenAI RAG and Customized RAG
Christy demonstrated two approaches for building a RAG: one using the OpenAI API and another by customizing it with a vector database called Milvus. This comparison will help us understand the differences and benefits of each approach..
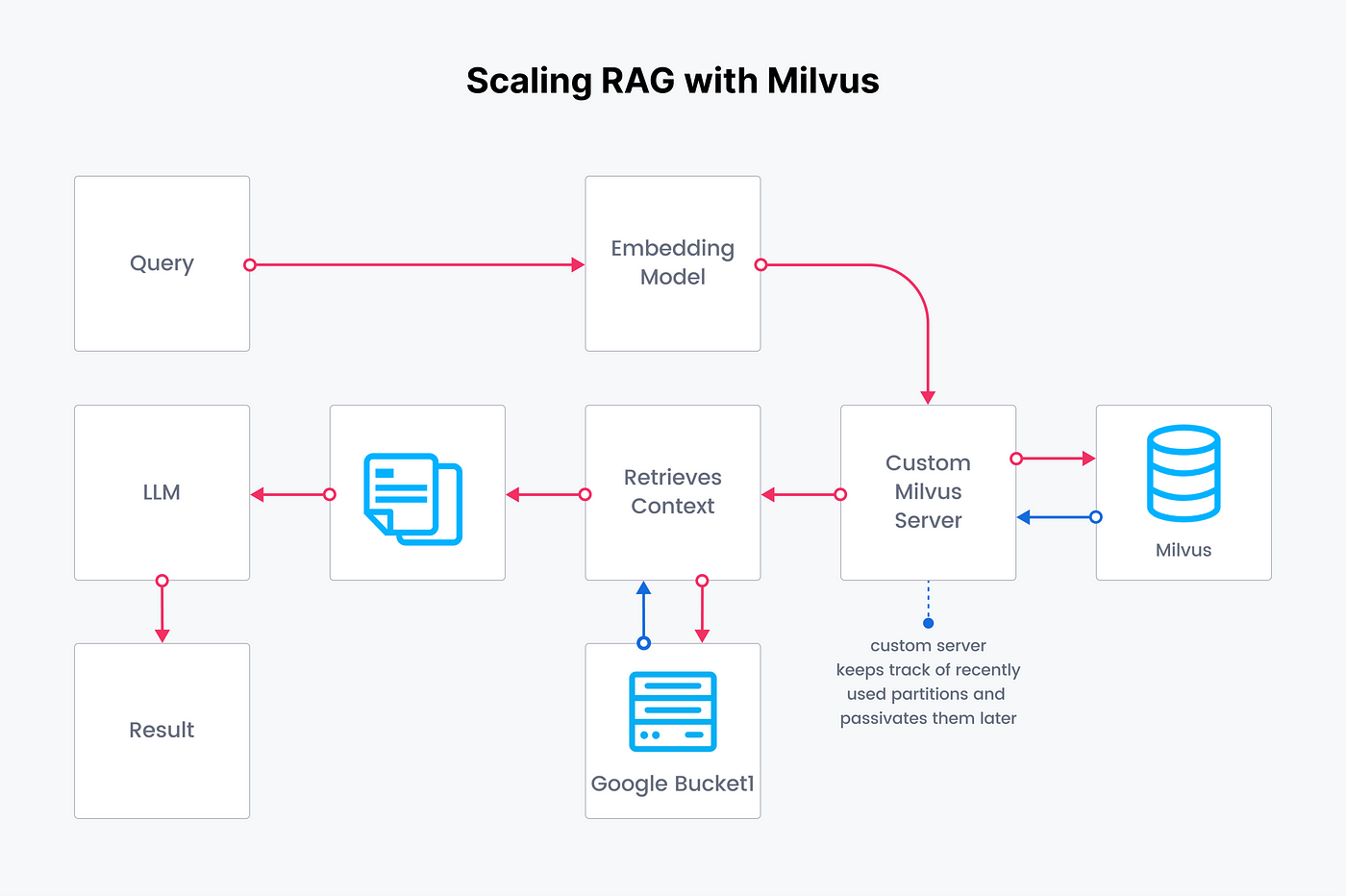
Here are the key differences between OpenAI RAG and Customized RAG.
| Criteria | OpenAI RAG | Customized RAG |
| Application Suitability | Good for customer support, virtual personal assistants, and long-term conversations | Great for academic research assistance, complex queries, and fact-based data |
| Performance and Scalability | Fast response times and high efficiency | May experience slower response times due to database retrieval |
| Implementation Complexity | Easy to set up and use | Requires expertise in AI model integration and database management |
| Cost Considerations | Pricing based on usage | Costs include computational resources and database maintenance |
A customized RAG approach using vector databases like Milvus offers more flexibility and control but requires more expertise and resources
Want to see the code in action? Check out this notebook for a hands-on example!
RAG Evaluation Methods
To evaluate a RAG pipeline, you need to look at both parts separately and together. You also need to check if the performance is getting better. To do this, you need two things: an evaluation metric and a dataset.
As Christy tackled this part in her speech the main focus she mentioned was “Is your answer grounded and does it faithfully answer the question”
One of the tools Christy mentioned is Truera, a platform that helps evaluate and optimize Large Language Model (LLM) applications.
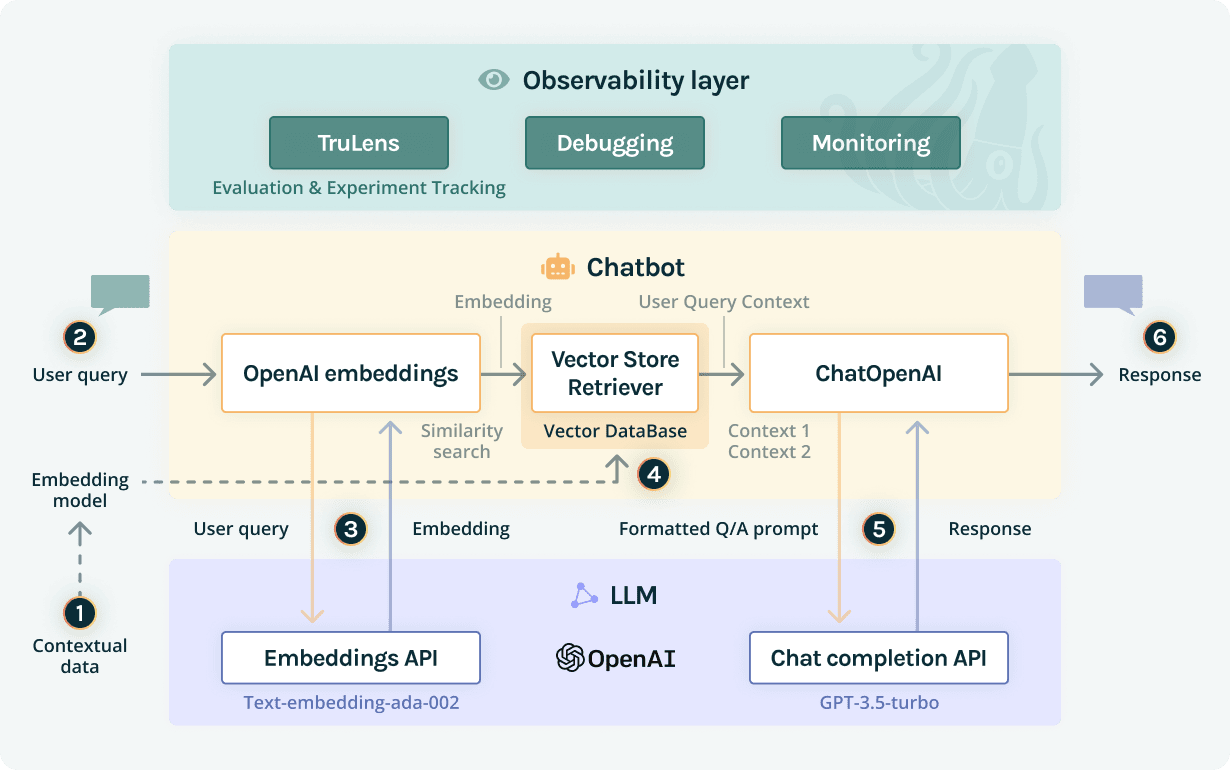
With Truera, you can:
- Evaluate your LLM apps
- Optimize your choice of LLM apps using feedback functions and app tracking
- Minimize hallucinations by leveraging features like RAG triad and other out-of-the-box feedback functions
- Monitor and track production LLM apps at scale, building responsive dashboards and setting actionable alerts
Christy also talked about RAGAs, it is a framework, purpose-built for assessing RAG pipelines. It offers all the technical necessities to evaluate each pipeline component in isolation.
RAGAs needs the following information:
· Question: The user's query
· Answer: The generated answer
· Contexts: The information retrieved from the external knowledge source
· Ground truths: The correct answer to the question (only needed for one metric)
RAGAs provides several metrics to evaluate the pipeline, including:
· Context precision: How relevant the retrieved information is
· Context recall: If all relevant information was retrieved
· Faithfulness: How accurate the generated answer is
· Answer relevancy: How relevant the generated answer is to the question
Evaluating LLMs using other LLMs as a Judge
Evaluating large language models (LLMs) can be challenging. One solution is to have LLMs evaluate each other. This process involves generating test cases and measuring the model's performance.
Here's how it works:
- Automatic Test Generation: An LLM creates a range of test cases, including different inputs, contexts, and difficulty levels.
- Evaluation Metrics: The LLM being evaluated solves the test cases, and its performance is measured using metrics like accuracy, fluency, and coherence.
- Comparison and Ranking: The results are compared to a baseline or other LLMs, showing the strengths and weaknesses of each model.
An interesting point mentioned by Christy that is truly intriguing is “GPT ranking itself higher when its the judge” which shows another aspect we have to consider when evaluating the LLMs to ensure accuracy.
you might want to check out this article to dive deeper into the topic.
Conclusion
And that's it! We've covered AI Hallucinations and how RAG can help solve the issue. Christy demonstrated a great explanation of how building RAG requires careful choices of embedding models, indexes, and semantic search approaches. By addressing the issue of AI hallucinations and leveraging dynamic retrieval of up-to-date information, RAG offers a powerful tool for creating more reliable and context-aware AI systems.
The journey of building a RAG system involves thoughtful decisions about embedding models, indexing, and handling vast datasets. While challenging, the rewards in terms of performance and accuracy are substantial.
Whether you’re intrigued by the technical nuances or inspired by the practical applications, now is the perfect time to dive into RAG. Experiment with vector databases like Milvus, integrate with advanced search techniques and witness firsthand how RAG can transform data retrieval and AI interactions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Keep Reading

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.