




Streamlining the Deployment of Enterprise GenAI Apps with Efficient Management of Unstructured Data
Deploying GenAI applications in production environments is no small feat, especially when dealing with unstructured data. Companies often struggle to efficiently manage and utilize this type of data to gain insights and maintain a competitive edge. In a recent Unstructured Data Meetup hosted by Zilliz, Joe Maionchi, Vice President of Research and Development at Aparavi, and Hendrik Knack discussed cutting-edge techniques for managing unstructured data to streamline GenAI application deployment.
 Joe Maionchi speaking at the July SF Unstructured Data Meetup
Joe Maionchi speaking at the July SF Unstructured Data Meetup
The Challenge of Handling Unstructured Data
Unstructured data includes everything from emails, social media posts to videos, images, and documents that cannot be stored uniformly. Unlike structured data, which fits neatly into rows and columns, unstructured data is vast, varied, and challenging to manage with traditional databases. As Joe Maionchi highlighted, "75 to 80% of enterprise data is currently unstructured, and the volume grows each year." This rapid growth makes it increasingly difficult for organizations to store, process, and extract valuable insights from their data.
Key challenges of unstructured data include:
Complexity in Management: Unstructured data comes in a variety of formats, making it difficult to standardize and process. Additionally, the sheer volume of this data can lead to high storage costs and management complexity.
Data Privacy Concerns: Protecting sensitive information is a major concern for enterprises. Data breaches, particularly those involving Personally Identifiable Information (PII), can be disastrous. Storing and processing data in external environments, such as cloud-based solutions or large language models (LLMs) like GPT, increases the risk of data breaches and compliance violations.
Poor Data Quality: Unstructured data often contains inconsistencies, missing values, and redundant information. This issue makes it challenging to extract high-quality, actionable insights without extensive data cleaning.
Processing and Integration Complexity: Analyzing unstructured data requires advanced techniques such as natural language processing (NLP) and information retrieval. However, many teams lack the necessary technical expertise, leading to inefficient data utilization.
Streamlining Unstructured Data Management with Aparavi
To tackle these challenges, data management service providers like Aparavi offer a comprehensive data platform designed to simplify the management and utilization of unstructured data. Here's how the platform addresses key pain points.
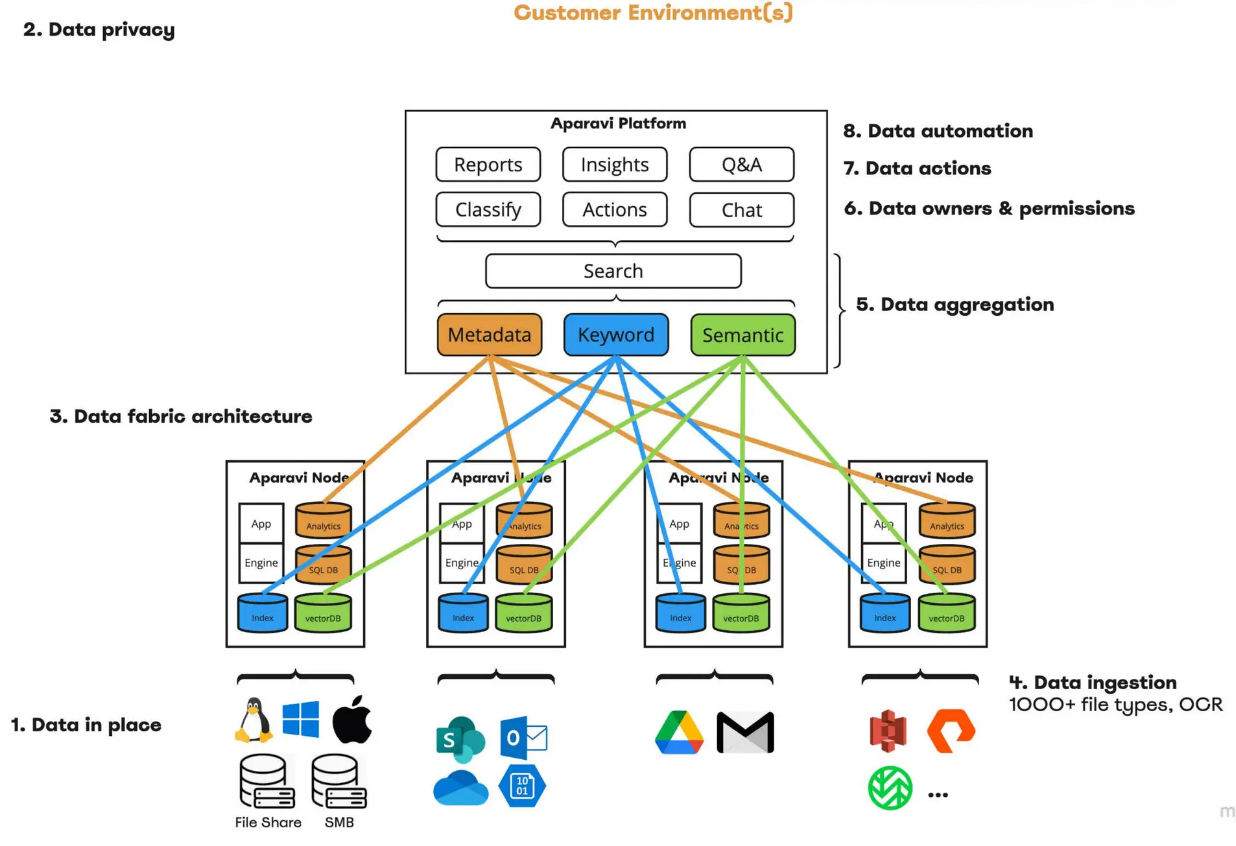 Flow of data in the customer environment
Flow of data in the customer environment
Data in Place: This platform enables enterprises to manage and analyze data without transferring it to external environments, ensuring data privacy. The platform integrates seamlessly with a wide range of data sources, including vector databases like Milvus and Zilliz Cloud (the fully managed Milvus), file stores, and cloud services like Outlook and OneDrive.
Data Privacy: Companies can extract insights without compromising sensitive information by keeping data securely on-premises. The platform's applications are deployed wherever your unstructured data resides, reducing the risk of data breaches.
Distributed Architecture: Aparavi employs a distributed data architecture, allowing organizations to manage their data more efficiently and at scale. This architecture eliminates the need for extensive server farms, as metadata, vector stores, and indexes are distributed across nodes.
Robust Data Ingestion: The platform supports ingesting over 1,000 file types and includes advanced OCR (Optical Character Recognition) capabilities for extracting text from images. This capability ensures that diverse data sources can be integrated and analyzed effectively.
Data Aggregation and Querying: Once ingested, unstructured data is aggregated, allowing users to perform queries to extract valuable insights. This capability is crucial for identifying trends and conducting granular analyses.
Granular Data Ownership and Permissions: The platform allows enterprises to control data ownership at a granular level, ensuring that only authorized users can access sensitive information. This feature is particularly important for maintaining compliance and protecting PII.
Data Actions and Automation: The platform includes built-in features that enable users to act on insights directly within the system. Automated processes ensure that data remains compliant and up-to-date without requiring manual intervention.
Scalable Enterprise RAG with Aparavi and the Milvus Vector Database
Retrieval Augmented Generation (RAG) is an AI technique that provides large language models (LLMs) with contextual information about user queries to generate more relevant and accurate answers. This approach can significantly mitigate LLM hallucination problems. It also allows many LLM-powered applications to tap into the potential of domain-specific, proprietary, or private datasets that LLMs didn’t previously have access to without worrying about data security issues.
Milvus is an open-source vector database that stores, indexes, and retrieves billions of vectors. It is purpose-built for production requirements and ideal for building enterprise RAG systems. Integrating with Milvus, Aparavi's platform offers Enterprise RAG solutions with two standout features: the Semantic Search Retriever and AI Data Loader.
Semantic Search Retriever
The Semantic Search Retriever enhances the contextual relevance of responses to queries. This tool provides a semantic search API endpoint that can be queried to extract relevant data chunks for AI projects.
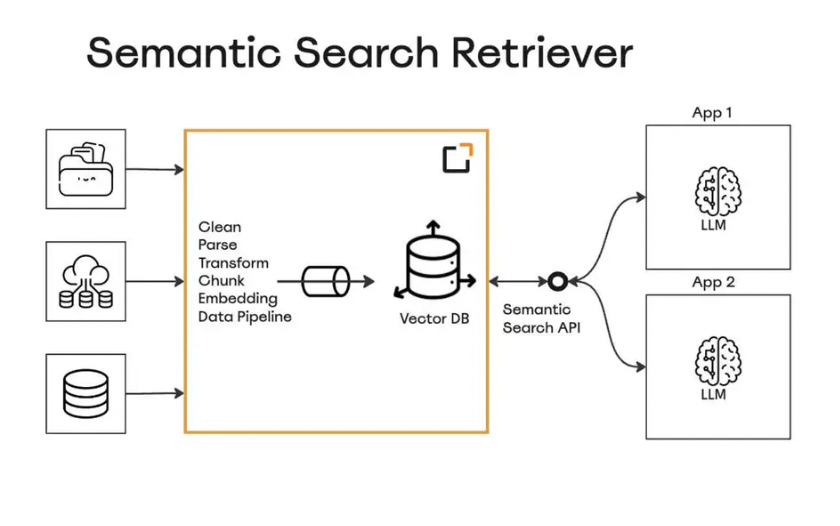 RAG as a service for information querying
RAG as a service for information querying
How It Works: Data is ingested, processed, and stored in the Milvus vector database as vector embeddings. When you make a query, it is also converted into a vector embedding. The API then leverages Milvus to retrieve the most similar vector embeddings to the query and returns the relevant data.
Benefits: This tool improves the accuracy of LLM application responses significantly. Enterprises can choose efficient vector databases like Milvus and feed data directly through the Aparavi data pipeline.
AI Data Loader
The AI Data Loader automates importing data from various sources, including on-premises systems, cloud storage, and external repositories. It handles tasks like data cleaning, deduplication, and formatting, ensuring the data is well-prepared for analysis. Then, the loader sends the pre-processed data to a vector database like Milvus for similarity search. The retrieved relevant results will be provided with the LLM as a user query context for more relevant answers.
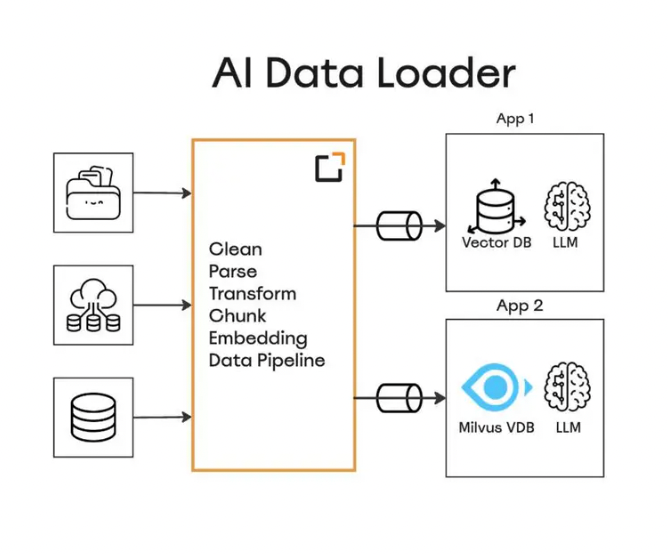 AI Data Loader in the pipeline
AI Data Loader in the pipeline
Current Limitations of Aparavi's Enterprise RAG
While Aparavi provides enterprise RAG solutions for managing unstructured data, there are still some challenges:
Heavy Footprint: Since Aparavi hosts the platform on the customer side and does not transfer data externally, the footprint can be significant, potentially affecting performance.
User Interface: Due to its complexity, new users may find it challenging to onboard and navigate the Aparavi platform.
Conclusion
As enterprises continue to explore GenAI's potential, managing unstructured data remains a critical challenge. Organizations can streamline their AI projects and scale their applications as their business grows by leveraging advanced data management platforms like Aparavi and integrating with high-performance vector databases like Milvus.
Further Resources
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 ShriVarsheni R
ShriVarsheni R
Keep Reading

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.