




Auto GPT Explained: A Comprehensive Auto-GPT Guide For Your Unique Use Case
This article was originally published in The Sequence and is reposted here with permission.
In December of 2022, ChatGPT, the chatbot interface powered by GPT, introduced large language models (LLMs) into mainstream media. Since then, numerous GPT apps have popped up. One of the most popular ones? Auto-GPT. An open-source GPT-based app that aims to make GPT completely autonomous. In a short few weeks, it has accumulated over 120k stars on GitHub, eclipsing PyTorch, Scikit-Learn, HuggingFace Transformers, and any other open-source AI/ML library you can think of.
What makes Auto-GPT such a popular project? First, it shows promise in delivering on the self-described vision of autonomous GPT. Auto-GPT has “agents” built in to search the web, speak, keep track of conversations, and more. People have used it to order pizza, code apps, and sell merch. Now it’s your turn to learn how to leverage Auto-GPT to supercharge your workflow and automate away mundane tasks.
In this Auto GPT tutorial, you’ll learn:
- What is Auto-GPT?
- How to Set Up Auto GPT in Minutes
- Configure
.envfor Auto-GPT
- Configure
- Run Your First Task with Auto-GPT
- Adding Memory to Auto-GPT
- Using Milvus Standalone (Docker Compose)
- Using Milvus Lite(Pip Install)
- Summary of "Auto-GPT Explained"
What is Auto-GPT?
AI has been hot recently. ChatGPT is reported to be the fastest-growing app of all time, reaching over 1 billion visitors monthly as of February of 2023. LLMs have been heralded as the coming of Artificial General Intelligence (AGI), the future of software, and the technology breakthrough that will lead humanity to enlightenment or destruction. However, LLMs have one glaring flaw. They cannot act on their own. They require someone to repeatedly prompt them from task to task.
Auto-GPT sets out to solve this problem. Auto-GPT is an open-source software that aims to allow GPT-4 to function autonomously. How does it provide this autonomy? Through the use of agents. Auto-GPT enables users to spin up agents to perform tasks such as browsing the internet, speaking via text-to-speech tools, writing code, keeping track of its inputs and outputs, and more.
This extended functionality feeds the hype and the media’s doom and gloom narrative. You don’t have to be afraid of AI though. As long as you understand how to leverage AI for your own good, your AI narrative can be positive and productive. So let’s take a look at how you can get Auto GPT up and running on your local machine in just a few minutes.
How to Set Up Auto-GPT in Minutes
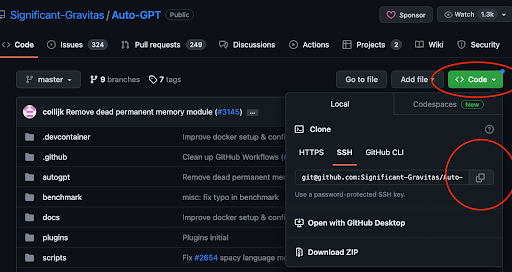 How to configure auto-GPT
How to configure auto-GPT
Auto-GPT is surprisingly easy to set up. First, go to the Auto-GPT GitHub page and copy the clone link. Then, open up your terminal or VSCode instance and navigate to a working directory. For me, it's ~/Documents/workspace. Use git clone [git@github.com](mailto:git@github.com):Significant-Gravitas/Auto-GPT.git to clone the repo locally. Next, navigate to the newly created folder.
In the newly created folder, make a new Python virtual environment so you have a clean slate. Once you’re in your virtual environment, run pip install -r requirements.txt install all the dependencies. We now have Auto-GPT installed. The last thing we need to do to get an instance up and running is to put our OpenAI API key in the environment variables.
Configure .env for Auto-GPT
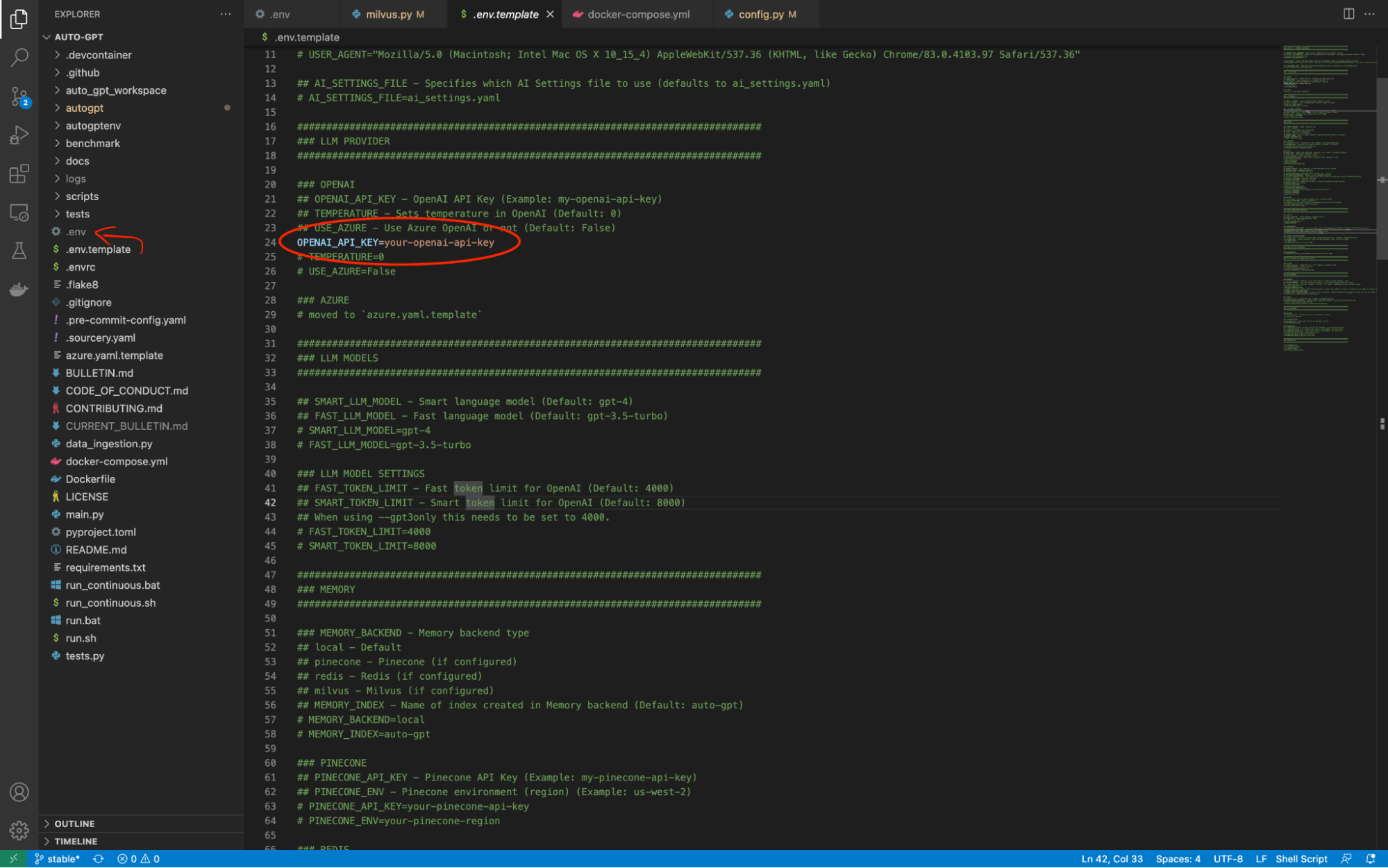 configure-env.png
configure-env.png
Auto-GPT has a file titled .env.template in its root directory. We have to change this filename to just .env. Then, we can use this file to store all of the info we need to connect with the external tools that give Auto-GPT its autonomous capabilities. There is one change we need to make before we can even launch Auto-GPT. We have to change the value of OPENAI_API_KEY to our OpenAI API key.
Run Your First Task with Auto-GPT
 run-task-auto-gpt.png
run-task-auto-gpt.png
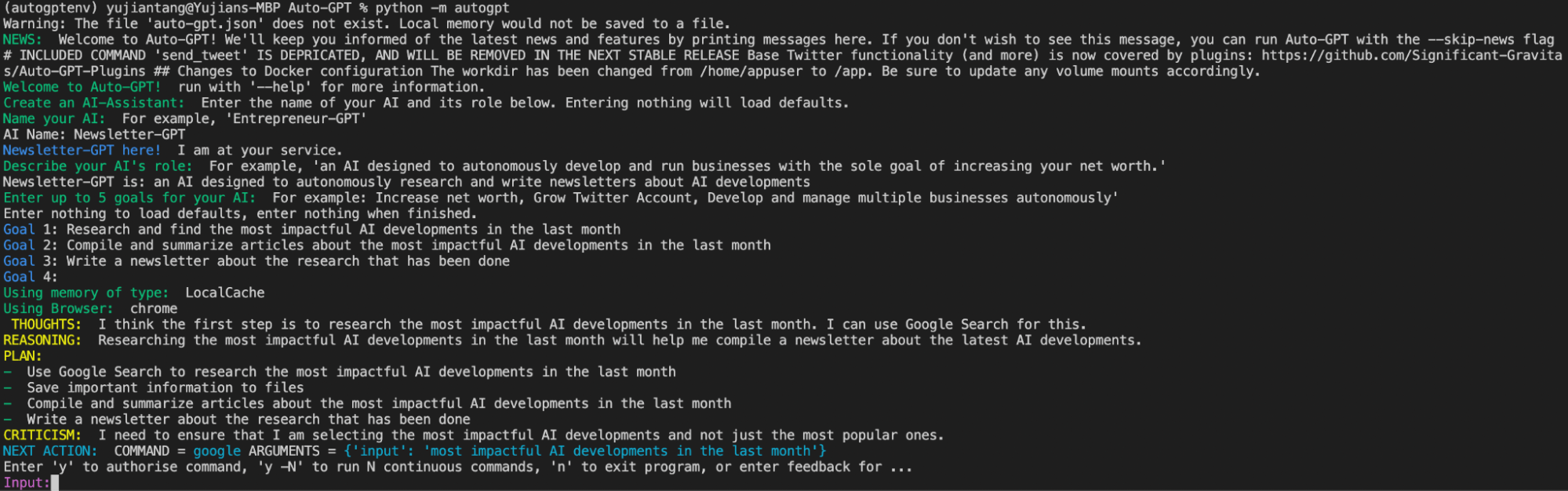
With your OpenAI API Key updated, you can start using Auto-GPT to automate some work for you. In this example, we automate the creation of a newsletter about last month’s most impactful developments in AI. Run python -m autogpt in your terminal to start it up. When we start Auto-GPT it prompts us to give it a name, define a role for it, and give it some goals.
 run-first-task-auto-gpt.png
run-first-task-auto-gpt.png
In this example, we name our AI “Newsletter-Generator”. For the next prompt, we tell the AI that Newsletter-Generator is an AI designed to autonomously research and write newsletters about AI developments. Next, Auto-GPT prompts us to give up to five goals for our AI.
I’ve given Newsletter-Generator three goals. First, to research and find the most impactful AI developments in the last month. Second, to compile and summarize articles about the most impactful AI developments in the last month. Third, to write a newsletter about the research that has been done. Once the setup is complete, Auto-GPT generates a file called ai_settings.yaml to save this configuration and begins its tasks.
For each task , it provides thoughts, reasoning, a plan, a criticism of its plan, and the next step. Before executing a task, it prompts us for approval or feedback on its plan. We can allow it to perform the next N tasks autonomously without prompting us for approval if we want.
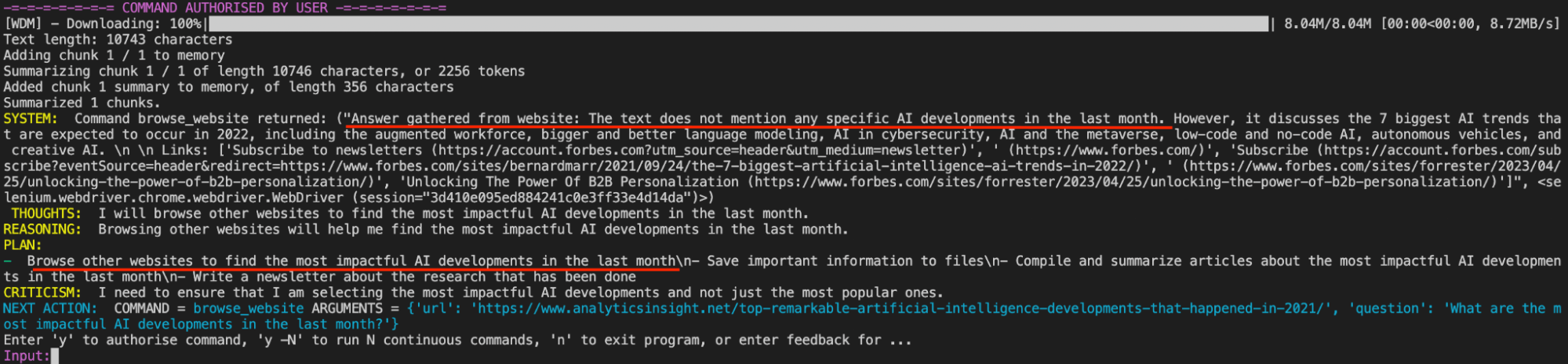 auto-gpt-ability.png
auto-gpt-ability.png
In the image above, we see Auto-GPT’s ability to discern that the first article it found on Google actually doesn’t contain the necessary information to complete its task. It returns this to us and then drums up the next step in getting last month’s impactful AI developments.
Adding Memory to Auto-GPT
 adding-memory-auto-gpt.png
adding-memory-auto-gpt.png
When using Auto-GPT’s default “local” storage option, Auto-GPT generates a document called auto-gpt.json which looks something like the image above. It contains a block of text followed by a bunch of numbers. The text blocks keeps track of your current conversation with Auto-GPT and the numbers are the vector embeddings representing that conversation.
Using a JSON file for memory is not a scalable solution. As you work more with Auto-GPT, it produces more data. Not just in the form of a memory of your conversation so far, but also files to write and additional “agents”. While JSON can keep track of this info, if you ever want to search, retrieve, or edit anything you’ve made, you’ll need a permanent storage backend.
Luckily, Auto-GPT can use many different memory backends. Since we are storing vector data, a vector database like Milvus is an ideal solution. Milvus is an open-source vector database with multiple solutions including distributed solutions to run on Kubernetes or Docker and a way to run a local instance. In this example, we cover two ways to use Milvus as a backend.
First, we cover how to use Milvus Standalone, a distributed solution using Docker Compose that you can run locally. Second, we cover how to use Milvus Lite, to instantiate and use a vector database in your Python code. The first solution only requires a couple changes in the Auto-GPT code, but requires you to download Milvus via Docker Compose. The second solution requires a few more changes in the existing package, but allows you to use Milvus with just a pip install.
Using Milvus Standalone (Docker Compose)
Using Milvus Standalone as a memory solution requires fewer changes to the Auto-GPT code but requires Docker. Follow the Milvus Standalone instructions and get an instance up and running on a local Docker container.
Once we have a Milvus instance up and running, we only need to make a few changes to get Auto-GPT to use our Milvus instance for long-term storage. In the .env file, find MEMORY_BACKEND and change it from local to milvus. Then, find MILVUS. Underneath MILVUS are two environment variables, MILVUS_ADDR and MILVUS_COLLECTION. Uncomment them. You can leave the defaults.
Run pip install pymilvus to get the Milvus SDK. Then, start up Auto-GPT again using python -m autogpt. This time, you should notice a change. The terminal should display a Using memory of type: MilvusMemory message. That’s all there is to add Milvus to Auto-GPT.
 add-milvus-auto-gpt.png
add-milvus-auto-gpt.png
Using Milvus Lite (Pip Install)
Note: The pull request to get these changes into Auto-GPT is open.
Unlike Milvus Standalone, Milvus Lite doesn’t have any extra dependencies. We install Milvus Lite and the Milvus Python SDK with pip by running pip install milvus pymilvus. Since we aren’t going to boot up Milvus externally before we start Auto-GPT, we have to have it boot up as Auto-GPT is setting up.
We do this by making changes in three files: .env, autogpt/memory/milvus.py, and autogpt/config/config.py. We start by making the same changes as we did with the Milvus Standalone instance. Change the MEMORY_BACKEND variable to milvus and uncomment the MILVUS_ADDR and MILVUS_COLLECTION variables. Under the Milvus section in the .env file, add a new environment variable called MILVUS_TYPE and set it equal to lite.
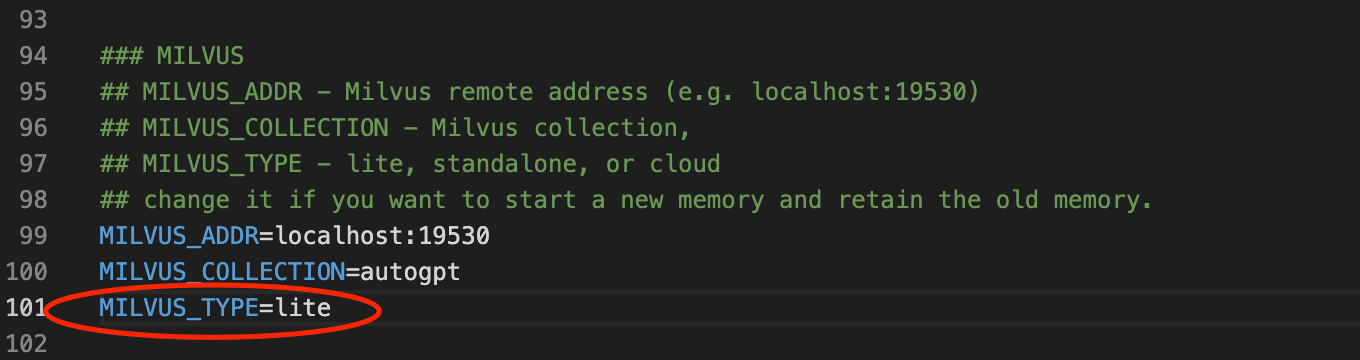 milvus-type.png
milvus-type.png
There are two files under the autogpt folder that we make changes to. In the config.py file under the config folder, set the milvus_type value to get MILVUS_TYPE from the environment variables.
# milvus type can be standalone, lite, or cloud
self.milvus_type = os.getenv("MILVUS_TYPE")
In the milvus.py file under the memory folder we add an if statement that checks for the value of milvus_type in the config. If the value is lite, then we import Milvus, start up a server, and connect to the default Milvus Lite server. We shift the original line of code into the else statement.
if cfg.milvus_type == "lite":
from milvus import default_server
print("Starting Milvus Lite")
default_server.start()
connections.connect(host='127.0.0.1', port=default_server.listen_port)
else:
connections.connect(address=cfg.milvus_addr)
Once these changes are made, we can run Auto-GPT like normal. Running python -m autogpt starts an instance of Auto-GPT with a slightly different startup output. The terminal should display a line that says “Starting Milvus Lite” and the Milvus Lite output text. It should still show “Using memory of type: MilvusMemory”.
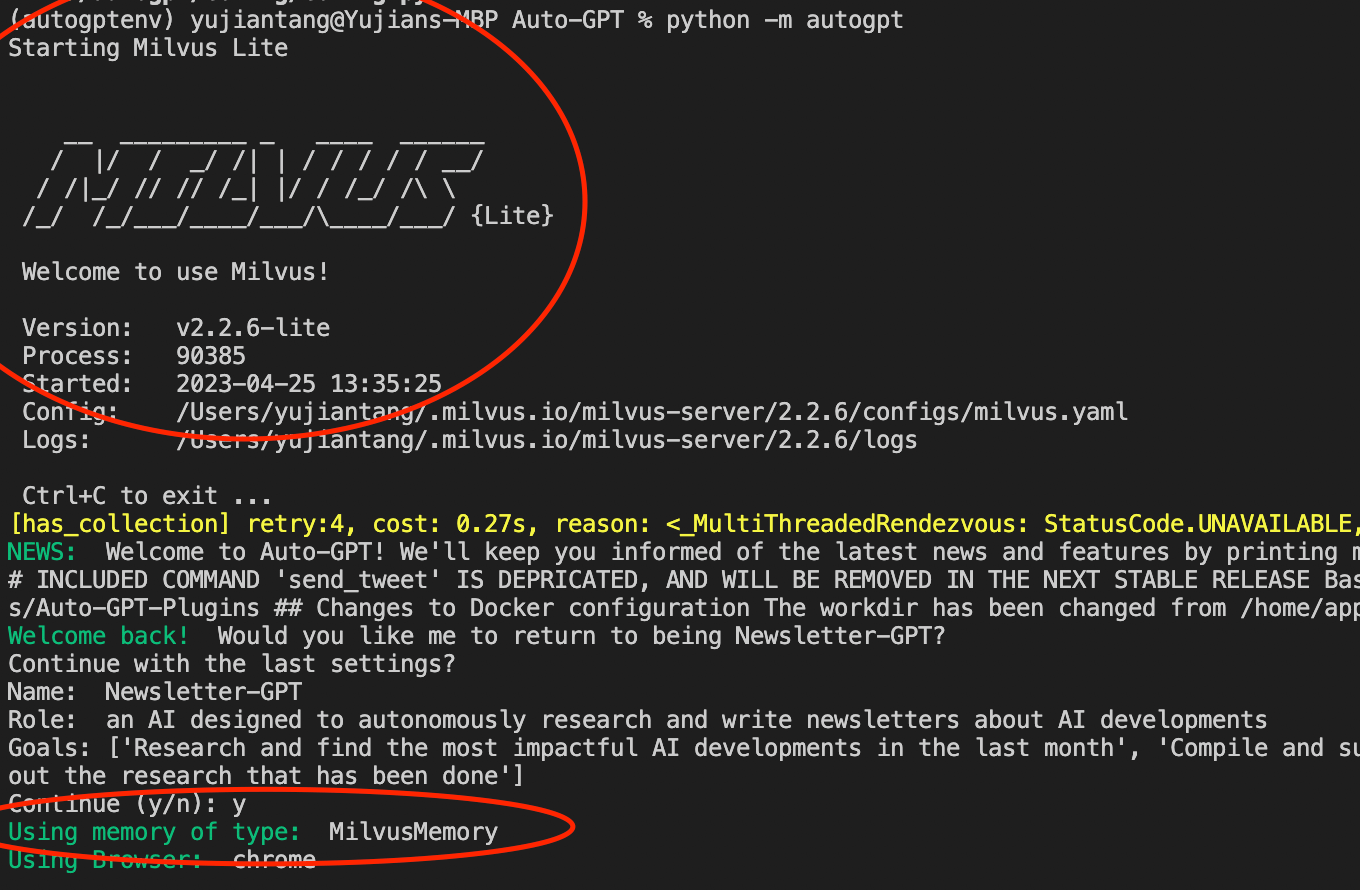 milvus-memory.png
milvus-memory.png
Summary of "Auto GPT Explained"
In this article we took a tour of the basics of Auto-GPT. First we downloaded Auto-GPT from GitHub and got an instance running. After getting it running, we looked at the files generated by Auto-GPT. From looking at Auto-GPT’s files, we found that it uses a JSON file full of vectors to keep track of its memory locally.
JSON files are not scalable. For a more robust memory backend, we use the Milvus vector database, one of the other memory options integrated into Auto-GPT. We show how to add a Milvus backend in two ways: as a set of standalone Docker containers or as an instance spun up by Auto-GPT. Stay tuned for more posts about vector databases with LLMs.

Keep Reading

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.