




Emerging Trends in Vector Database Research and Development
First introduced with Milvus in 2019, vector databases have rapidly risen to prominence alongside the emergence of large language models (LLMs) and the rise of generative AI (GenAI) applications. As an engineer deeply engaged in this sector, I've witnessed their evolution from basic implementations of Approximate Nearest Neighbors Search (ANNS) algorithms to sophisticated database systems integral to modern AI frameworks, from niche implementations to broad deployments.
As AI continues to mature, where is the future of vector databases headed? In my view, the development of this technology is intricately linked to product evolution, propelled by the changing demands of users. Understanding these shifts is crucial for directing the trajectory and objectives of technological developments.
In this article, I will discuss the development and anticipated future of vector databases from both technical and practical perspectives, focusing on cost-efficiency and business requirements.
Hot and Cold Data Storage Separation
Costs have long been a major concern in the wider adoption of vector databases. These costs stem primarily from two areas:
Data Storage: Traditionally, vector databases cache all data in memory or on local disks to achieve low latency. However, in the era of AI, where applications frequently handle data volumes in the billions, this approach can consume vast amounts of storage resources, ranging from tens to hundreds of terabytes.
Data Computation: In distributed database systems, we must partition data into numerous small segments to enhance expansive dataset management. Each segment is independently processed to retrieve data, which is then collectively analyzed to compile the final Top-K results. This partitioning method significantly escalates the complexity of executing queries. For instance, if we segment data totaling billions into 10 GB chunks, it results in around 10,000 segments, thus amplifying the computational demand by a factor of ten thousand.
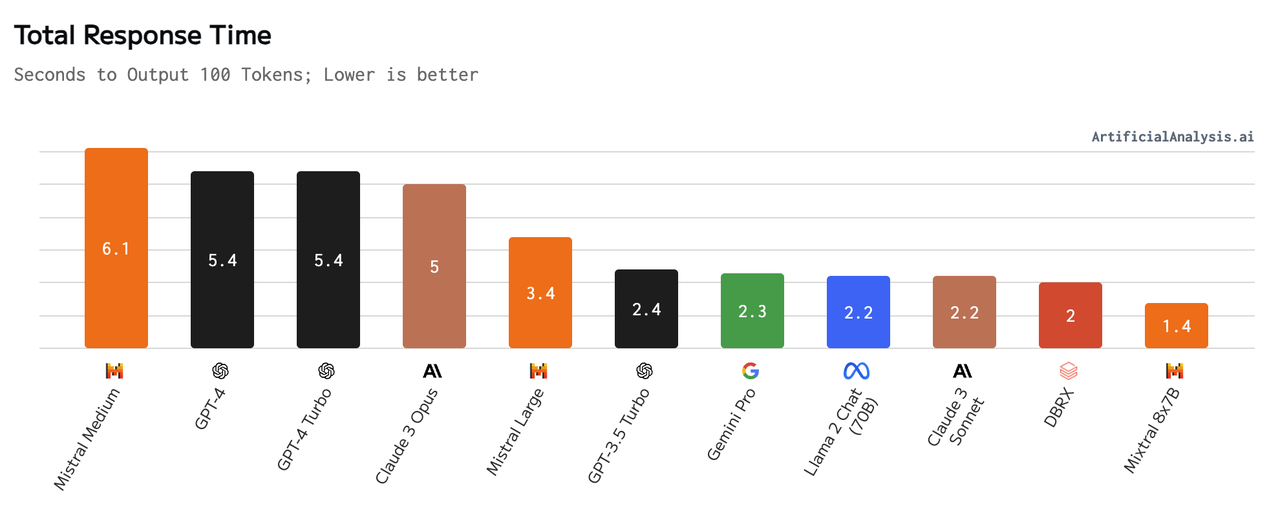 The response time of mainstream LLMs.
The response time of mainstream LLMs.
The response time of mainstream LLMs. Image source: https://artificialanalysis.ai/models
However, in the wave of building Retrieval-Augmented Generation (RAG) applications, the latency of vector databases has become a non-issue for individual users or single tenants on ToC platforms. The delay associated with vector database operations—ranging from a few milliseconds to several hundred milliseconds—is minimal compared to the often more than one-second latency typical of large language models. Additionally, the cost of cloud object storage is significantly lower than that of local disks and memory, prompting a push towards innovative solutions to optimize storage and computational efficiency.
Storage: To minimize costs, data should be stored in the most economical cloud object storage and retrieved on-demand for queries.
Computation: By refining the scope of queries in advance, we can reduce the need for broad-scale data processing, enhancing operational efficiency.
At Zilliz, we are adding improvements to Zilliz Cloud (the fully managed Milvus) that allow users to cut costs while maintaining latency at acceptable levels.
Embracing Hardware Innovations for Enhanced Performance and Cost-effectiveness
Hardware serves as the backbone of technological advancements, advancing the performance and cost-effectiveness of vector databases.
Advancement of GPU Technologies
Vector databases, known for their intense computational demands, have seen substantial performance improvements thanks to advancements in GPUs. The perception that GPUs are prohibitively expensive is being overturned. Enhanced algorithms are suitable for vector search tasks and allow for low latency and cost-effective operations.
Our testing shows that when using the GPU-based CAGRA index, the Milvus vector database achieves performance levels several to tens of times higher than when using the CPU-based HNSW index while only being two to three times more expensive. This result demonstrates that GPUs become a viable and economically efficient option for data processing, providing significant performance advantages over traditional CPU setups.
 Testing results by VectorDBBench
Testing results by VectorDBBench
Testing results by VectorDBBench
CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge Top 100 Recall: 98%
Emergence of ARM-based CPUs in Cloud Computing
The adoption of ARM-based CPUs, such as AWS's Graviton and GCP's Ampere, not only marks a shift towards more energy-efficient and cost-effective computing solutions but also provides a confident challenge to the conventional x86 architecture. These processors offer lower costs while delivering comparable or superior performance, assuring you of making a smart decision for your computing needs.
Our evaluations of AWS Graviton3 have demonstrated its superior performance and cost-efficiency relative to x86 processors. Notably, the rapid iteration of these CPUs, as seen with the release of Graviton4 in 2023—just a year after Graviton3—highlights a 30% boost in computing power and a 70% increase in memory bandwidth.
Advancements in Storage Technologies
Utilizing disks for data storage allows vector databases to expand their capacity significantly while maintaining millisecond-level latencies, which are adequate for most vector search applications. Furthermore, the cost associated with disk storage remains substantially lower than that of memory, making it an attractive option for data-intensive operations.
Overall, these hardware developments fuel the capabilities of vector databases and ensure they remain powerful and economically viable as they evolve.
Collaborating with Advanced Machine Learning Models
Machine learning models, which produce vector embeddings, are also undergoing significant transformations. These advancements aim to reduce the size and dimensionality of vectors, thereby minimizing storage requirements for large datasets and boosting computational efficiency.
Traditional methods for reducing vector dimensionality often led to compromised data retrieval accuracy. However, recent innovations provide viable alternatives. For example, the OpenAI ext-embedding-3-large model enables users to adjust the dimensions of output vectors through configurable parameters. This flexibility allows for a considerable reduction in vector size with minimal impact on the efficacy of downstream tasks. Additionally, Cohere has recently upgraded its technology to support vectors that output multiple data types—such as float, int8, and binary—all at once, enhancing operational versatility.
These advancements highlight the need for vector databases to engage with and incorporate these emerging technologies proactively. Doing so is crucial for maintaining a competitive edge in the dynamic and ever-changing fields of deep learning and data management.
Prioritizing Vector Retrieval Accuracy
Vector retrieval accuracy has become increasingly important and demanding, particularly with the expanding integration of vector databases in both production environments and cutting-edge RAG applications. As vector databases evolve, the quest to enhance search quality and accuracy has led to the adoption of innovative technologies. Among these, the ColBERT retrieval model and advanced hybrid vector search techniques are pivotal in mitigating information loss and refining domain-specific retrievals.
The Emergence of Advanced Retrieval Models like ColBERT
The ColBERT retrieval model is renowned for its efficiency in handling the information loss typically associated with the bulky architecture of traditional dual-tower models. ColBERT uses a token vector-based late interaction approach to avoid the inefficiencies of fully connected setups. Its more recent iteration, ColBERTv2, further optimizes this process by integrating vector retrieval, significantly accelerating the interaction rate.
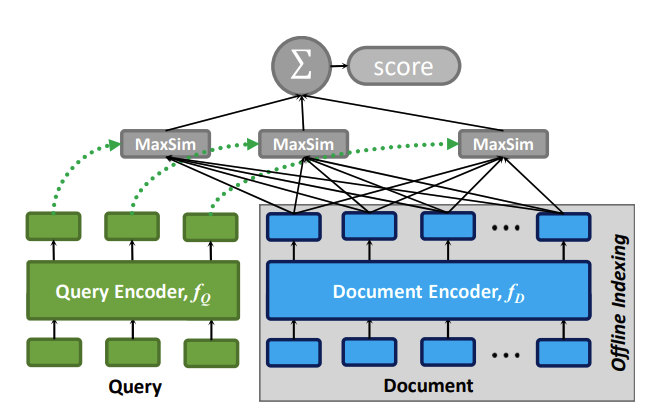 The general architecture of ColBERT, given a query q and a document d..png
The general architecture of ColBERT, given a query q and a document d..png
The general architecture of ColBERT, given a query q and a document d.
Image source: https://arxiv.org/pdf/2004.12832.pdf
Hybrid Search: Bridging Sparse and Dense Vector Techniques
Traditional dense vectors, often derived from language models like BERT, excel at capturing semantic nuances but can falter with new vocabulary or specialized terms absent from the training data. While model fine-tuning can mitigate these limitations, deploying in real-time remains costly and challenging. Conversely, sparse vectors from traditional keyword-matching algorithms like BM25 effectively tackle these out-of-domain issues.
Emerging sparse embedding models such as SPLADE and BGE's M3-Embedding blend the precision of exact term matching with the comprehensive nature of dense retrieval methods. These models generate sparse vectors that preserve keyword-matching efficacy while incorporating richer semantic information, enhancing overall retrieval quality.
The shift towards hybrid search systems leveraging keyword and vector retrieval methods has been a long-standing industry practice. With the latest advancements in sparse vector technology, integrating these into vector databases to support hybrid retrieval is increasingly considered a best practice. Notably, the Milvus vector database has adopted this approach in its recent updates.
Taking BGE's M3-Embedding as an example, It can simultaneously perform the three common retrieval functionalities of the embedding model: dense retrieval, multi-vector retrieval, and sparse retrieval. The table below shows the retrieval quality when conducting different types of vector searches. The retrieval quality of hybrid sparse and dense retrieval is much higher than that of those relying solely on dense and sparse retrieval.
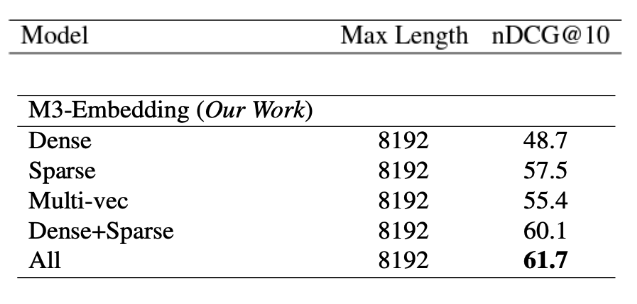 Evaluation on NarrativeQA (nDCG@10)
Evaluation on NarrativeQA (nDCG@10)
Evaluation on NarrativeQA (nDCG@10)
Image source: https://arxiv.org/abs/2402.03216
Note: Retrieval quality is often assessed using NDCG (Normalized Discounted Cumulative Gain), which evaluates ranking systems' effectiveness in providing users useful item lists. The value of K in NDCG, such as 5, 10, or 25, indicates the number of top-ranked items evaluated, thus providing insights into the precision of the retrieval system at different levels. For example, NDCG@10 evaluates the ranking of the top 5 items.
Optimizing Vector Databases for Offline Use Cases
While vector databases' current focus is predominantly on online applications such as Retrieval-Augmented Generation (RAG) and image similarity searches, their potential in offline use cases is vast yet underutilized.
Online applications typically handle small data volumes with high frequency and stringent latency requirements, often necessitating responses within seconds, even in cost-sensitive, performance-minimal environments. Conversely, offline applications often perform large-scale data processing tasks like data deduplication and feature mining, where task duration may extend from minutes to hours.
Here are a few challenges and ways to address them with vector databases in offline use:
Computational Efficiency: Unlike online use cases, which prioritize low latency for each query, offline tasks require high computational efficiency across large batches of data. Achieving low latency is particularly critical in the offline components of search and recommendation systems. Enhancing computational density, for example, through GPU indexing, can significantly improve the handling of extensive data queries in these scenarios.
Vast data return: In data mining applications, vector retrieval aids models in recognizing specific situations. These tasks frequently necessitate retrieving substantial data volumes, raising bandwidth and algorithm efficiency issues, especially for large Top-K searches. Developing efficient solutions to manage these large-scale retrievals is crucial for supporting robust offline vector database applications.
By addressing these challenges, vector databases can be better equipped to support a broader range of applications, extending their utility beyond the online environments.
Expanding Feature Sets in Vector Databases for Diverse Industries
As the adoption of vector databases expands across different sectors, the diverse range of applications necessitates the development of specialized features tailored to address industry-specific requirements. The versatility of vector databases demands customized capabilities to optimize their performance and functionality for the unique challenges faced by each domain. These enhancements cater to different fields' unique requirements and improve vector databases' overall functionality and versatility in production environments. Here are some examples of how vector databases are evolving to meet these demands:
Biopharmaceutical Applications: The use of binary vectors to retrieve drug molecular formulas is becoming commonplace in the biopharmaceutical industry. Binary vectors allow for efficient searching and matching of complex chemical structures, facilitating rapid drug discovery and development processes.
Financial Sector Needs: Unlike many industries that seek the closest vector matches, the financial sector often requires identifying the most outlier vectors. This capability is crucial for detecting anomalies and potential fraud, where the greatest deviations from the norm are of the highest interest.
Range Search Functionality: Range Search allows users to define a similarity threshold to accommodate use cases where the exact number of relevant results is unpredictable. The system then returns all results that exceed this threshold, ensuring high relevance and precision in the retrieved data.
Groupby and Aggregation Functionalities: For extensive unstructured data, such as movies or lengthy articles, vector databases must produce and handle vectors segmented by frames or text sections. This segmentation requires robust Groupby and aggregation capabilities to ensure that results effectively meet specific user criteria.
Support for Multimodal Models: The shift towards multimodal models introduces vectors of varying distributions, presenting challenges for traditional retrieval algorithms. Vector databases are evolving to accommodate these diverse data types, ensuring effective retrieval across different modalities.
These industry-specific adaptations highlight the dynamic nature of vector databases, which are evolving to meet the complex and varied demands of modern applications across sectors.
Wrapping Up
Over the past year, vector databases have seen rapid advancements, reflecting significant maturation in their use cases and intrinsic capabilities. As we progress into the AI-driven era, these developments are poised to accelerate, heralding a new wave of innovations in storing, searching, and managing data.
This overview aims to illuminate the transformative trends and emerging features in vector databases, offering insights that might inspire further innovation in this field. As we navigate these exciting changes, the collective journey toward enhancing vector databases promises to reshape our technological landscape, enabling more sophisticated and efficient data-driven solutions.
Let's continue to explore and innovate together, embracing the promising future of vector databases with enthusiasm and a spirit of collaboration.

Keep Reading

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
AWS S3 Vectors aims for 90% cost savings for vector storage. But will it kill vectordbs like Milvus? A deep dive into costs, limits, and the future of tiered storage.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.