




Building RAG Apps Without OpenAI - Part Two: Mixtral, Milvus and OctoAI
This blog is written by Yujian Tang and Thierry Moreau.
Retrieval Augmented Generation (RAG) is the most popular use case for LLMs to come out of 2023. While most examples show how you can build RAG with OpenAI’s GPT LLMs, this series touches on how to build RAG without OpenAI. See Building RAG without OpenAI Part One here.
This tutorial is the second installment of this series, covering building RAG with Milvus, Mixtral hosted through OctoAI, and LangChain. In particular, we share just the tip of the iceberg of the Mixtral numerous advantages in this tutorial: its multilingual capabilities.
In this blog, we’ll cover:
- MMO(L) Open Source RAG Tech Stack
- Mixtral
- Milvus
- OctoAI
- LangChain
- The RAG App Architecture
- Setup Your RAG Tools
- Select and Load Your Data
- Query Your Data with OctoAI and Mixtral
- Summary
Find the notebook on GitHub.
MMO(L) Open Source RAG Tech Stack
There are many ways to build RAG apps, and in my last market survey, I found over 50 different tools in the LLM stack. In this example, we focus on four: Mixtral as the LLM, Milvus as the vector database, OctoAI to serve the LLM and embedding model, and LangChain as our orchestrator. Before we dive into the architecture, let’s learn a bit about the tools involved.
Mixtral
Mixtral 8x7B, or just “Mixtral” for short, is the latest model released by pioneering French AI startup Mistral. Launched in December 2023 (with the paper coming out in January 2024), it represents a significant extension of the prior foundational large language model, Mistral 7B. Mixtral is an 8x7B Sparse Mixture of Experts (SMoE) language model with more substantial capabilities than the original Mistral 7B. It’s larger, using 13B active parameters during inference out of 47B parameters, and supports multiple languages, code, and a 32k context window. As of early 2024, Mixtral is the top-scoring open-source model on LLM leaderboards.
Milvus
The crux of our RAG app memory is the vector database. Milvus is a highly scalable vector database aimed at enterprise applications. Its inherent distributed system structure allows seamless scaling as you approach the true production levels of vectors. Milvus also provides other enterprise features like multi-tenancy, role-based access control, and high availability.
OctoAI
OctoAI provides the infrastructure to run LLM models at a production scale. OctoAI makes it easy for AI developers to integrate OctoAI’s hosted models, which offer a selection of powerful open-source models, including Mixtral and community finetunes like Nous Hermes. About 9 out of 10 new OctoAI sign-ups start with Mixtral as their LLM model of choice, and today Mixtral on OctoAI generates billions of tokens for customers daily. In this tutorial, we’ll substitute GPT for the highly popular Mixtral model.
LangChain
LangChain is arguably the most popular LLM App framework on the market. LangChain includes integrations with almost every tool you can imagine. While you can use it in many ways, in this example, we use it to connect everything. We load Milvus and the OctoAI endpoint through LangChain and then use it to “chain” everything together.
The RAG App Architecture
Each RAG app has four critical components: the LLM, the vector database, the embedding model, and the orchestrator. Underneath all of that sits the infrastructure layer. In this setup, we are using Mixtral as the LLM, Milvus as the vector database, GTE Large as the embedding model, LangChain as the orchestrator, and OctoAI as the infrastructure layer that serves GTE Large and Mixtral.
Setup Your RAG Tools
Let’s start by setting up our RAG tools. In this section, we set up our inference endpoints for the LLM and embeddings and spin up our vector database. Let’s start by installing the prerequisites. We need pymilvus and milvus to work with Milvus. We need langchain, sentence-transformers, and tiktoken to use the LangChain functionality for this example. Finally, we also need octoai-sdk to interface with OctoAI’s embedding and text completion APIs.
We use this first block of code to load most of our necessary imports from LangChain, including the Milvus and OctoAI imports. We also load in the LLMChain module, which allows us to chain functions together, and the PromptTemplate module, which we use to pass prompts to our LLMs. We also need to load our environment variables into memory. There are many ways to do this, but for this example, we use load_dotenv from the python-dotenv library.
# ! pip install pymilvus milvus langchain sentence-transformers tiktoken octoai-sdk python-dotenv
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain_community.llms.octoai_endpoint import OctoAIEndpoint
from langchain_community.embeddings import OctoAIEmbeddings
from langchain_community.vectorstores import Milvus
from dotenv import load_dotenv
import os
load_dotenv()
# the line below is just to show that you need to have your OCTOAI_API_TOKEN
os.environ["OCTOAI_API_TOKEN"] = os.getenv("OCTOAI_API_TOKEN")
The next step is initializing our LLM access. OctoAI lets us easily access hosted models and customizes them to our use case. We use OctoAIEndpoint from LangChain and pass the endpoint (shown in the code) to access a model. We also pass in the required LLM parameters. For this example, it’s the model name, the max number of tokens (how long the output prompt is), as well as other parameters to tell the model what you need it to do (e.g., system prompt) and how creative to be with the output (“presence_penalty”, “temperature”, “top_p”). For the embeddings, we just pass the OctoAI endpoint URL. By default, it will be using GTE Large. Over time, more embedding models will be added to OctoAI.
llm = OctoAIEndpoint(
endpoint_url="https://text.octoai.run/v1/chat/completions",
model_kwargs={
"model": "mixtral-8x7b-instruct-fp16",
"max_tokens": 128,
"presence_penalty": 0,
"temperature": 0.01,
"top_p": 0.9,
"messages": [
{
"role": "system",
"content": "You are a helpful assistant. Keep your responses limited to one short paragraph if possible.",
},
],
},
)
embeddings = OctoAIEmbeddings(endpoint_url="https://text.octoai.run/v1/embeddings")
The last piece of this is the vector database. We use Milvus Lite as our vector database. Import default_server from Milvus, and then call the start() function to start the server.
from milvus import default_server
default_server.start()
Select and Load Your Data
With everything set up, it’s time to load our data. For this example, you can find the data in the GitHub Repo. If you want to get the data, it is simply scraped from Wikipedia. Once we have our data, it is time to load it into a vector database. We use LangChain and Milvus for this task.
The two imports we need from LangChain to load up these documents are a text splitter - CharacterTextSplitter in this case - and Document. Now, we can load the entire data directory as a list of “Documents”, a LangChain abstraction. For this example, we’re loading in a directory titled “data”. We also create an empty list to hold our list of Documents.
Next, we loop through each of the files in the directory. We read in the file and use a text splitter to chunk the text. For this example, we use a chunk size of 512 and a chunk overlap of 64. These were chosen simply because they tend to make sense usually. Feel free to adjust these as you’d like to see how the results may differ.
Once we chunk the text, we store it as a document with some metadata. The metadata that we keep with the text is the document's title and the chunk number to let us know where the chunk is in the document.
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
files = os.listdir("./data")
file_texts = []
for file in files:
with open(f"./data/{file}") as f:
file_text = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=64,
)
texts = text_splitter.split_text(file_text)
for i, chunked_text in enumerate(texts):
file_texts.append(Document(page_content=chunked_text,
metadata={"doc_title": file.split(".")[0], "chunk_num": i}))
With the Documents ready, it’s time to insert them into the vector database. We use LangChain’s Milvus integration and call the from_documents function. Pass in the documents, the embedding model, the connection arguments for the Milvus Lite instance, and a name for the collections. We simply call the as_retriever() method to drop an LLM on top and start working with Milvus as our vector database for this basic RAG example.
vector_store = Milvus.from_documents(
file_texts,
embedding=embeddings,
connection_args={"host": "localhost", "port": default_server.listen_port},
collection_name="cities"
)
retriever = vector_store.as_retriever()
Query Your Data with OctoAI and Mixtral
Everything is ready. We can now use LangChain to orchestrate the retrieval piece of our puzzle. We start by giving LangChain a template. We must pass two variables through to the prompt template - the context we retrieve and the question we want to ask. We can treat the template string like an f-string and then pass it to the from_template function from PromptTemplate.
After the template, we set up the “chain” part. We need the RunnablePassthrough module to pass context around and the StrOutputParser to parse the output. Then, we set up the chain. First, we tell LangChain where to get the context and question, then we pipe those to the prompt, which gets piped to the LLM and finally to the string output parser to parse. To ask a question, we simply invoke the chain.
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = PromptTemplate.from_template(template)
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
chain.invoke("How big is the city of Seattle?")
For the example of “How big is the city of Seattle,” we can see an expected output below. The response is accurate and backed by the Wikipedia information we’ve stored in the vector database.

Leveraging Mixtral’s Multilingual Capabilities through OctoAI

Since we’re using Mixtral, let’s leverage some unique capabilities, such as multilingual expertise. The nice thing about using OctoAI is that we can leverage the same endpoint with a different instruction to do different things. In this case, we’ll tell the model to answer in French and not English.
# Let's make this a bit more fun and showcase the multilingual capabilities of Mixtal which really outshine other open source models
# Our Vector DB is populated with entries from english text - even the embedding model we're using here, GTE-Large
# works best on english text. However Mixtral has good mutlilingual capabilities in French, German, Spanish and Italian.
# So what we'll do is ask the assistant to only answer in french in the system and user prompt. RAG here is performed based on
# english text, but upon producing the user response, the Mixtral LLM will generate tokens in a different language here (french)
llm = OctoAIEndpoint(
endpoint_url="https://text.octoai.run/v1/chat/completions",
model_kwargs={
"model": "mixtral-8x7b-instruct-fp16",
"max_tokens": 128,
"presence_penalty": 0,
"temperature": 0.1,
"top_p": 0.9,
"messages": [
{
"role": "system",
"content": "You are a helpful assistant who responds in french and not in english.",
},
],
},
)
We also use a slightly modified template to ask Mixtral to answer in French. The prompt has to be remade from the new template, and the chain has to be remade from the new prompt, template, and LLM. The chain can be invoked in the same way. We ask the same question in English and expect a response in French.
template = """Answer the question in french based only on the following context:
{context}
Question: {question}
"""
prompt = PromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
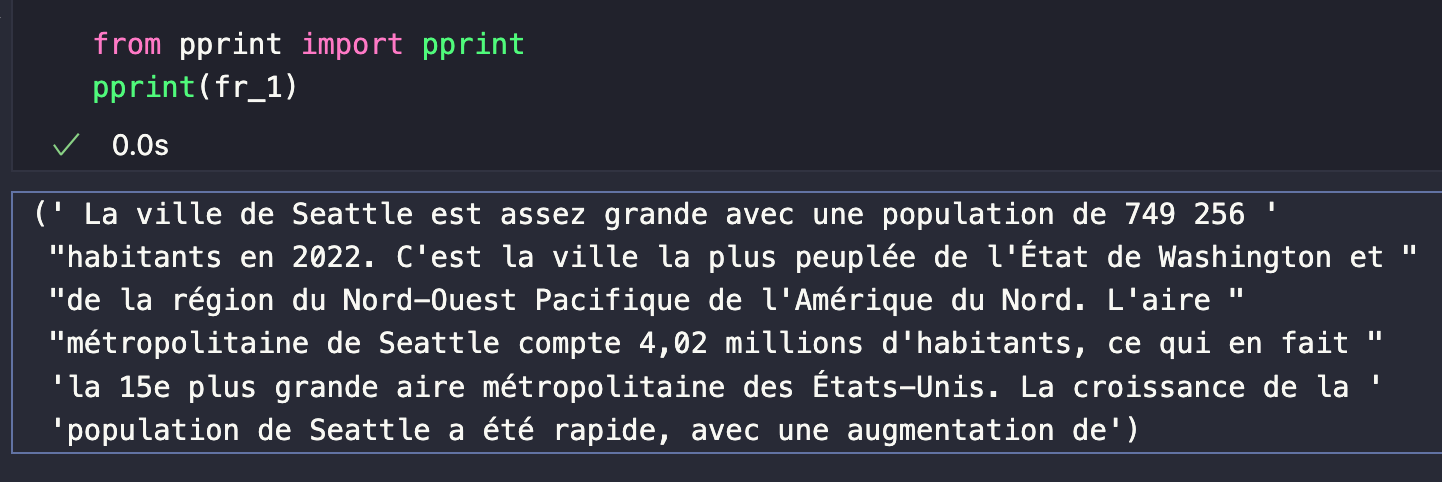
chain.invoke("How big is the city of Seattle?")
The response should look something like the image below.
Summary
In this tutorial we explored another way to build RAG without OpenAI. In part 1, we used Symbl.AI as the LLM, in this one, we used Mixtral by Mistral hosted by OctoAI. The other pieces of the RAG framework we used are Milvus as the vector database, LangChain as the orchestrator, and GTE-Large, also hosted by OctoAI, as the embedding model.
We set up our RAG tools and loaded up some Wikipedia as our example data. Then, we use LangChain to read the data into Milvus and layer “le big model” on top. In the end, we also took the time to explore one of Mixtral’s unique capabilities - the ability to work in multiple languages. For this example, we used French. Next time, we’ll explore some other languages as well!

Keep Reading

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.