




Building a Multimodal Product Recommender Demo Using Milvus and Streamlit
The Milvus Composed Image Retrieval demo showcases reverse image search, while the Milvus Multimodal RAG demo uses this technique for product recommendations. Simply upload an image and enter text instructions, Google’s MagicLens multimodal embedding model will encode both the image and text into a single multimodal vector. This vector is then used to find the closest-matching Amazon products from a Milvus vector database.
🎨🔍 Introducing the Milvus Magic: Image Search & Smart Shopping!
Ever wished you could find products just by showing a picture and describing what you want? Well, now you can! 🛍️✨
Here's how our cool demos work:
📸 Snap a pic & type what you're looking for
🧙♂️ Our Milvus Magic turns your input into a special "multimodal vector" (fancy, right?)
🕵️♀️ This vector becomes a super-sleuth for searching our Milvus vector database
🎉 Voila! It finds Amazon products that match your image and description
In this blog, we’ll show how to run the Milvus Multimodal RAG demo.
Technologies Used for the Multimodal Product Recommender
Google DeepMind’s MagicLens is a multimodal embedding model using a dual-encoder architecture to process text and images based on either CLIP (OpenAI 2021) or CoCa (Google Research 2022). MagicLens supports diverse retrieval tasks, including image-to-image and text-to-image, by fusing trained weights into a common vector space. Trained on 36.7M triplets, it can perform image-to-image, text-to-image, and multimodal text-image combination retrieval tasks, outperforming previous models with a significantly smaller model size.
OpenAI’s GPT-4o is a generative Multimodal Large Language Model by OpenAI that integrates text, images, and other data types into a single model, enhancing traditional language models. This advanced AI offers deeper understanding and processing of complex information, improving accuracy and context-awareness. It supports diverse applications, from natural language processing to computer vision.
Milvus is an open-source, distributed vector database for storing, indexing, and searching vectors for Generative AI workloads. Its ability to perform hybrid search, metadata filtering, reranking, and efficiently handle trillions of vectors makes Milvus a go-to choice for AI and machine learning workloads. Milvus can be run locally, on a cluster, or hosted in Zilliz Cloud.
Streamlit is an open-source Python library that simplifies creating and running web applications. It enables developers to build and deploy dashboards, data reports, and simple machine learning interfaces using straightforward Python scripts without requiring extensive knowledge of web technologies like CSS or JavaScript frameworks such as Node.js.
Prepare Data
The data in this demo comes from the Amazon Reviews 2023 dataset. The original data source includes 54 million user reviews of 48 million items in 33 categories, such as appliances, beauty, clothing, sports, outdoors, and an additional “Unknown” category.
We’ll just use a 5K item subset of the available data by sampling evenly per category. Download images by running download_images.py.
$ python download_images.py
Each product data row consists of item metadata (such as category name and average user review rating) and image urls for thumbnail and large images of the product.
For vector data, this demo uses a single large image embedding vector per product.
Setup Instructions for MagicLens
This guide walks you through setting up the environment and downloading the model weights for MagicLens, which is a powerful image retrieval system developed by Google DeepMind. For more detailed information, visit the MagicLens GitHub repository.
Set Up the Environment
- Create a conda environment:
$ conda create --name magic_lens python=3.9
- Activate the environment:
$ conda activate magic_lens
- Clone the Scenic repository:
$ git clone https://github.com/google-research/scenic.git
- Navigate to the Scenic directory:
$ cd scenic
- Install Scenic:
$ pip install
- Install CLIP dependencies:
$ pip install -r scenic/projects/baselines/clip/requirements.txt
- Install Jax:
If you're using a GPU for processing, you may need to install the corresponding GPU version of Jax. Follow the instructions at the JAX documentation page for detailed steps.
Here are examples for specific CUDA versions (Linux only):
CUDA 12 installation:
$ pip install --upgrade "jax[cuda12_pip]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
CUDA 11 installation:
$ pip install --upgrade "jax[cuda11_pip]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
Download the Model weights locally
- Navigate back to the main folder:
$ cd .. # This will take you back to the main directory where you cloned the demo.
- Download the model (may require authentication):
$ gsutil cp -R gs://gresearch/magiclens/models ./
Create the Milvus Collection and Save Vectors
The Milvus server in this demo is Milvus Lite with schema-less Milvus Client.
Create a collection, encode each image into vectors, and load the vector data into Milvus by running index.py.
$ python index.py
This step will encode each image into a 768-dimensional vector. For each product in the sample, the image vector, along with associated product metadata is saved into a Milvus collection called “cir_demo_large” with AUTOINDEX (HNSW).
Milvus Indexing and Search
At runtime, when you reverse search for an image and text, Milvus will search for the top_k = 100 closest image vectors using COSINE vector distance.
Milvus automatically sorts the top_k in descending order (since larger values of COSINE distance mean they are closer).
Run the Streamlit Server Front End
Update your local file
cfg.py, replacing path names with your local paths for images and model weights.Launch the app by running from your terminal:
$ streamlit run ui.py
- Using the app:
Upload an image to guide the product search.
Enter a text instruction to guide the search.
Click "Search" to find similar products from the Milvus vector database.
Click "Ask GPT" for AI-powered recommendations.
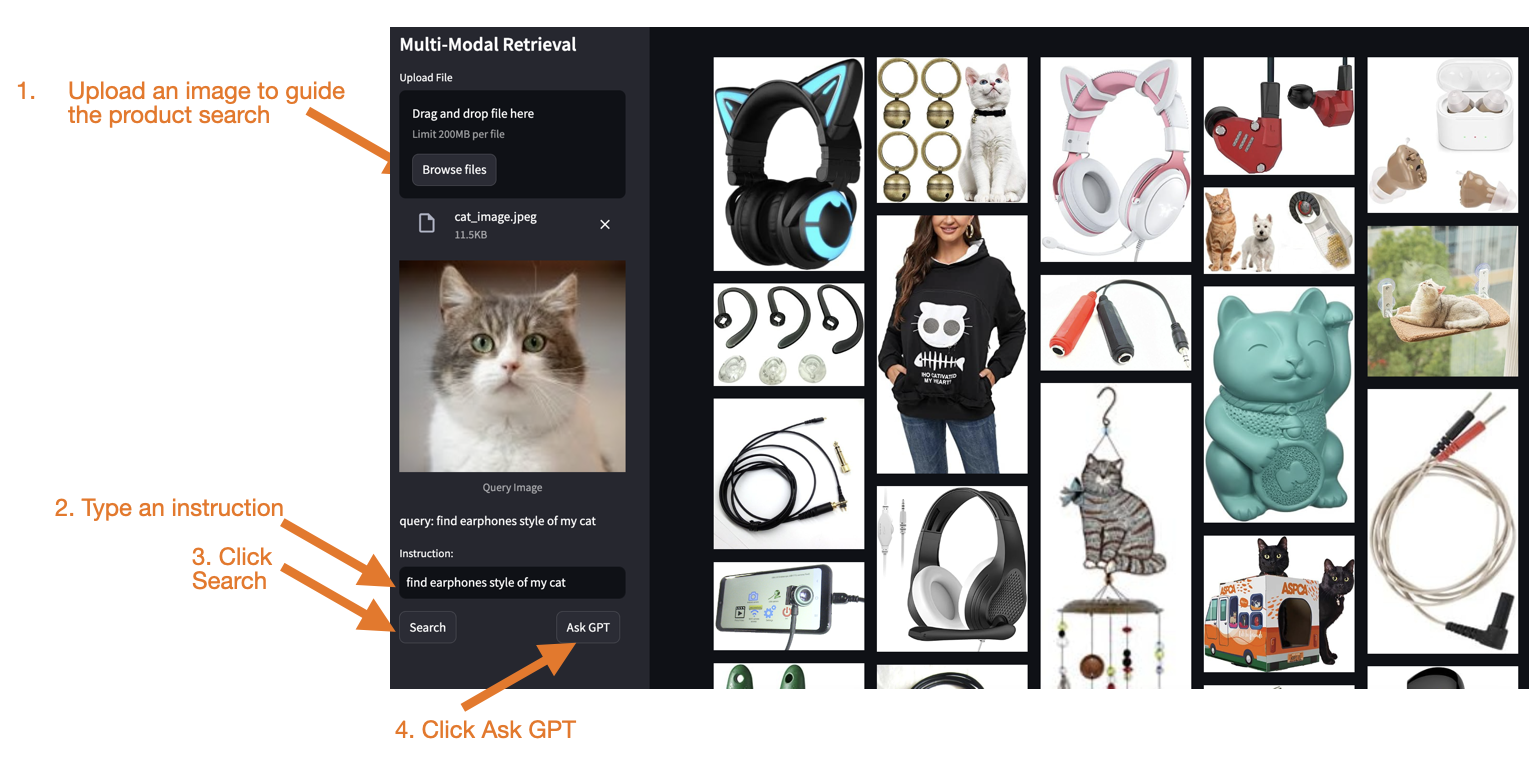 Figure 1- The interface of our demo app
Figure 1- The interface of our demo app
Figure 1: The interface of our demo app
How this app works:
The Search function will embed your image and text into a vector using the Multimodal Embedding model, MagicLens, which is the same model used to embed product images stored in the Milvus vector database. Milvus will then perform an Approximate Nearest Neighbor (ANN) vector search to find the nearest top_k product images to your input vector.
The Ask GPT function will call OpenAI’s GPT-4o mini multimodal generative model. It will take the top 25 images from the search results, stuff them in a prompt, and send them to the model. GPT-4o mini will then select the best image and explain the reason for its choice.
 Figure 2- The answers provided by GPT-4o mini
Figure 2- The answers provided by GPT-4o mini
Figure 2: The answers provided by GPT-4o mini
References
Multimodal Image Retrieval on bootcamp: https://github.com/milvus-io/bootcamp/tree/master/bootcamp/tutorials/quickstart/apps/cir_with_milvus
Multimodal RAG with Re-ranking Recommendations on bootcamp: https://github.com/milvus-io/bootcamp/tree/master/bootcamp/tutorials/quickstart/apps/multimodal_rag_with_milvus
Google MagicLens Model: https://github.com/google-deepmind/magiclens
Video about theory behind this demo: https://youtu.be/uaqlXRCvjG4?si=e83DnUsLZvVnWt-0&t=51
 Christy Bergman
Christy BergmanChristy Bergman is a passionate Developer Advocate at Zilliz. She previously worked in distributed computing at Anyscale and as a Specialist AI/ML Solutions Architect at AWS. Christy studied applied math, is a self-taught coder, and has published papers, including one with ACM Recsys. She enjoys hiking and bird watching.
 David Wang
David WangDavid Wang, Algorithm Engineer at Zilliz, brings extensive expertise in computer vision and natural language processing. His contributions to advanced embedding algorithm research, including projects like Towhee and GPTCache, reflect his commitment to advancing AI technologies. Before joining Zilliz, he worked at Alibaba Cloud for large-scale object recognition and classification projects. David holds a Master's degree from Dalian University of Technology.
 Reina Wang
Reina WangReina Wang is a Software Engineer Intern at Zilliz.
Keep Reading

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.