




Up to 50x Cost Savings for Building GenAI Apps Using Zilliz Cloud Serverless
Introduction
With recent advancements in Generative AI, the use case for vector databases is growing exponentially. For example, Retrieval Augmented Generation (RAG), a popular large language model (LLM) enhancement technique, leverages vector databases such as Milvus and Zilliz Cloud (the managed Milvus) to store, index, and retrieve relevant information to help LLMs generate more accurate results.
At a recent Unstructured Data Meetup in San Francisco, James Luan, VP of Engineering at Zilliz, discussed how developers can leverage Zilliz Cloud Serverless, a new offering of Zilliz, in their Generative AI applications. In a nutshell, this new service from Zilliz allows users to store, index, and query massive amounts of vector embeddings at only a fraction of the cost. The good news is that the performance of Zilliz Cloud Serverless is also very competitive compared to in-memory vector databases.
In this article, we'll recap James's key points and explore Zilliz Cloud Serverless more deeply. You can also watch his talk on YouTube for more details.
Why Vector Databases Matter in the Era of AI
Modern AI applications and techniques such as Retrieval Augmented Generation (RAG), recommendation systems, AI-powered chatbots, and semantic search engines require a reliable system to efficiently handle massive amounts of unstructured data. Vector databases are storage systems that enable us to store, index, and retrieve this data effectively.
Vector databases like Milvus and Zilliz Cloud are equipped with advanced indexing methods that users can choose from for efficient and fast data retrieval. Many of them, particularly Milvus and Zilliz Cloud, also offer easy integrations with popular AI frameworks and platforms like LangChain, Spark, Snowflake, and Hugging Face, making it easier for generative AI developers to build sophisticated AI applications. With different semantic search approaches, such as dense vector search and hybrid search of dense and sparse vectors, developers can obtain the most relevant results for any use case.
A recent 2024 survey of 1,000 Generative AI developers in the Milvus community identified seven aspects they look for in a vector database before considering its use in their AI applications:
Search quality: How relevant are the fetched results for a given query?
Cost efficiency: How economical is the database in terms of operational and maintenance expenses?
Ease of use: How user-friendly and intuitive is the database for developers to implement and manage?
Performance: How quickly and efficiently can the database process queries and return results?
Scalability: How well can the database handle increasing data and tenants without compromising performance?
High Availability: How reliably can the database maintain uptime and prevent data loss in case of failures?
Security: How well does the database protect sensitive data and prevent unauthorized access?
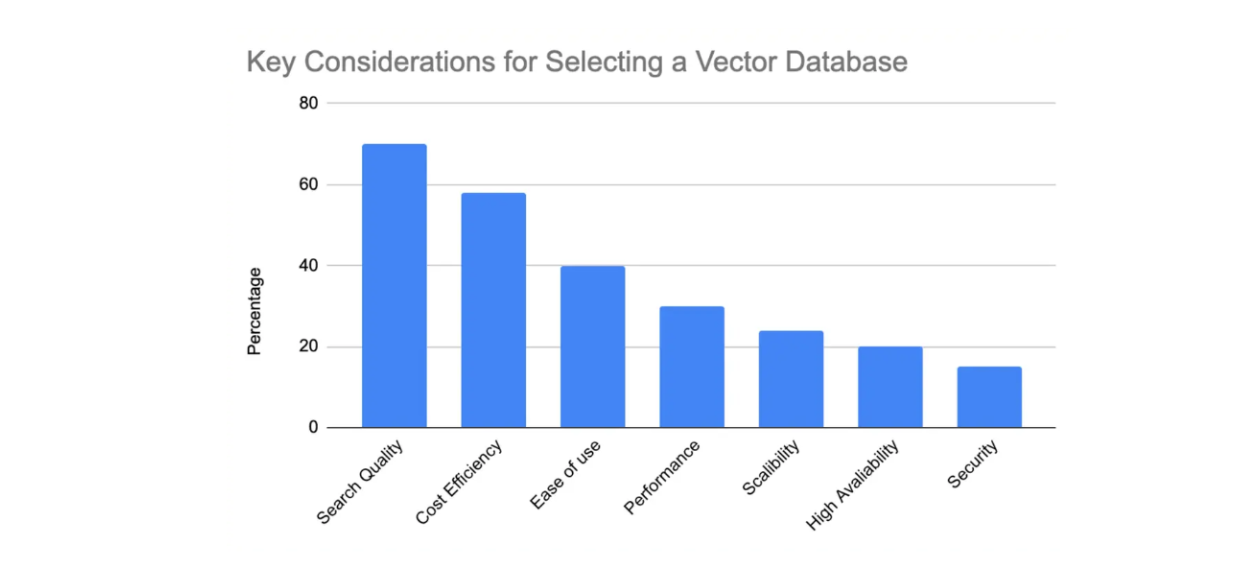 Figure 1: Key considerations for selecting a vector database gathered from 1000 Gen AI developers
Figure 1: Key considerations for selecting a vector database gathered from 1000 Gen AI developers
Milvus is highly evaluated for its search quality. It allows users to choose different indexing and vector search methods to balance performance and recall and retrieve relevant information in both depth and context.
Users can choose among Flat, IVFFlat, HNSW, and many more for indexing methods. Each indexing method has pros and cons, and you can see a detailed explanation of these methods in this article about picking a vector index.
For vector search operations, dense, sparse, or hybrid search can be used to get relevant results for a query. We can also use scalar filtering with the Boolean operation approach during a search operation to refine the result further.
The introduction of Zilliz Cloud Serverless significantly enhances the second and third most desirable aspects of a vector database mentioned above: cost efficiency and ease of use. The following sections will demonstrate how Zilliz Cloud Serverless improves Milvus in these two aspects.
Common Problems in the Development of AI Applications
When developing an AI application, developing a prototype is the next step after deciding which vector database to use. In this stage, we usually store all or a subset of our data in the vector database, then pick a large language model (LLM) and develop the prompts. Then, we select an LLM and a set of prompts that meet the quality objectives of our use case. Finally, we deploy our AI application into production.
However, as the user base of our AI application grows, the complexity of maintaining and scaling our infrastructure becomes more pronounced. We must consider aspects such as cost per user, monitoring the application's performance in production, handling multi-tenancy, managing burst traffic, addressing software bugs, and more.
The larger our user base, the more expensive it becomes to accommodate users' needs while maintaining key performance metrics like search quality, latency, and availability. Therefore, choosing the right infrastructure and software architecture is crucial when deploying your AI application into a production environment.
One solution to scale your AI application is through dedicated clusters in Zilliz Cloud.
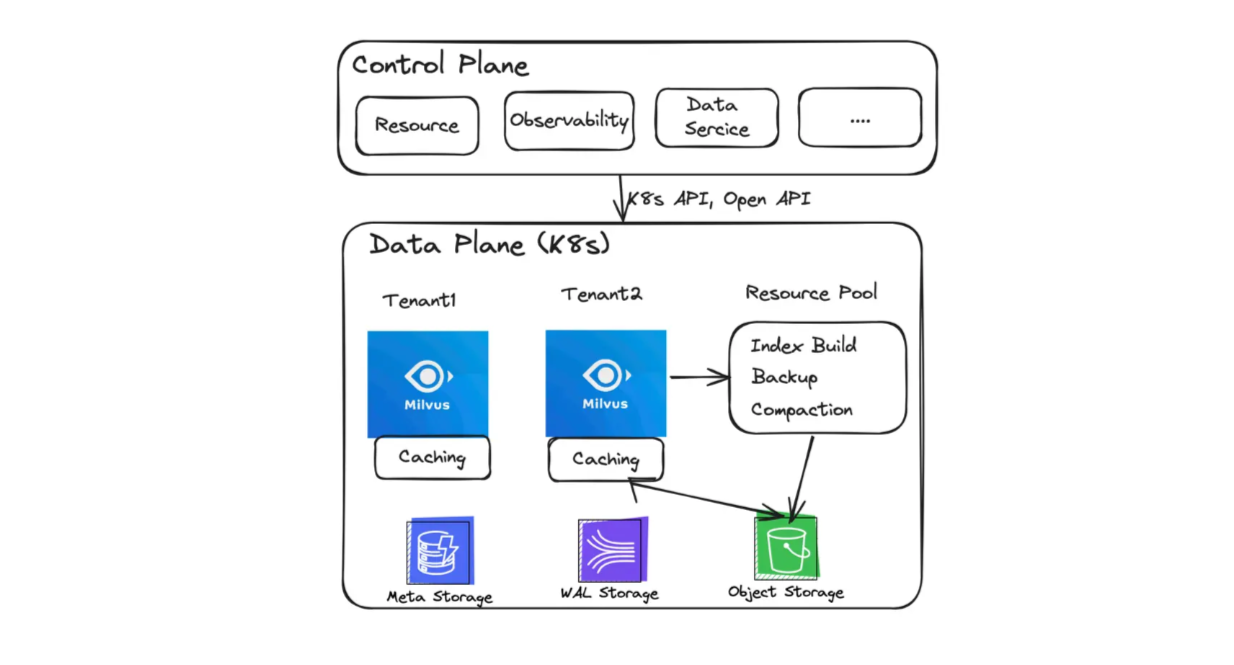 Figure 2: The architecture of Zilliz dedicated clusters
Figure 2: The architecture of Zilliz dedicated clusters
Dedicated clusters offer a dedicated environment and resources for your AI application, enabling you to process larger datasets with improved performance. They provide advanced features such as:
Separation between storage and computation.
Elastic resource pool for batch workloads.
Data backup to object storage systems like S3.
Data caching for even faster retrieval speeds.
These clusters are hosted in the cloud, eliminating the need for local infrastructure management.
However, a major disadvantage of dedicated clusters is the high initial and ongoing cost. Even when the cluster is idle with no search activity, it could potentially cost more than $100 per month. Additionally, performance may degrade as the user base of stored data and volume grows. Therefore, a better solution is needed to build an architecture that is not only cost-efficient but can also scale as our AI application reaches a higher user base.
Zilliz Cloud Serverless, up to 50x Cost Savings
Zilliz Cloud Serverless represents the latest architectural advancements offered by Zilliz to minimize infrastructure costs for running your AI applications smoothly in production. It offers up to 50x cost savings compared to in-memory vector databases through features such as pay-as-you-go pricing and auto-scaling that adapt to various workloads. The serverless offering is available on major cloud providers including AWS and GCP and will be available on Azure soon.
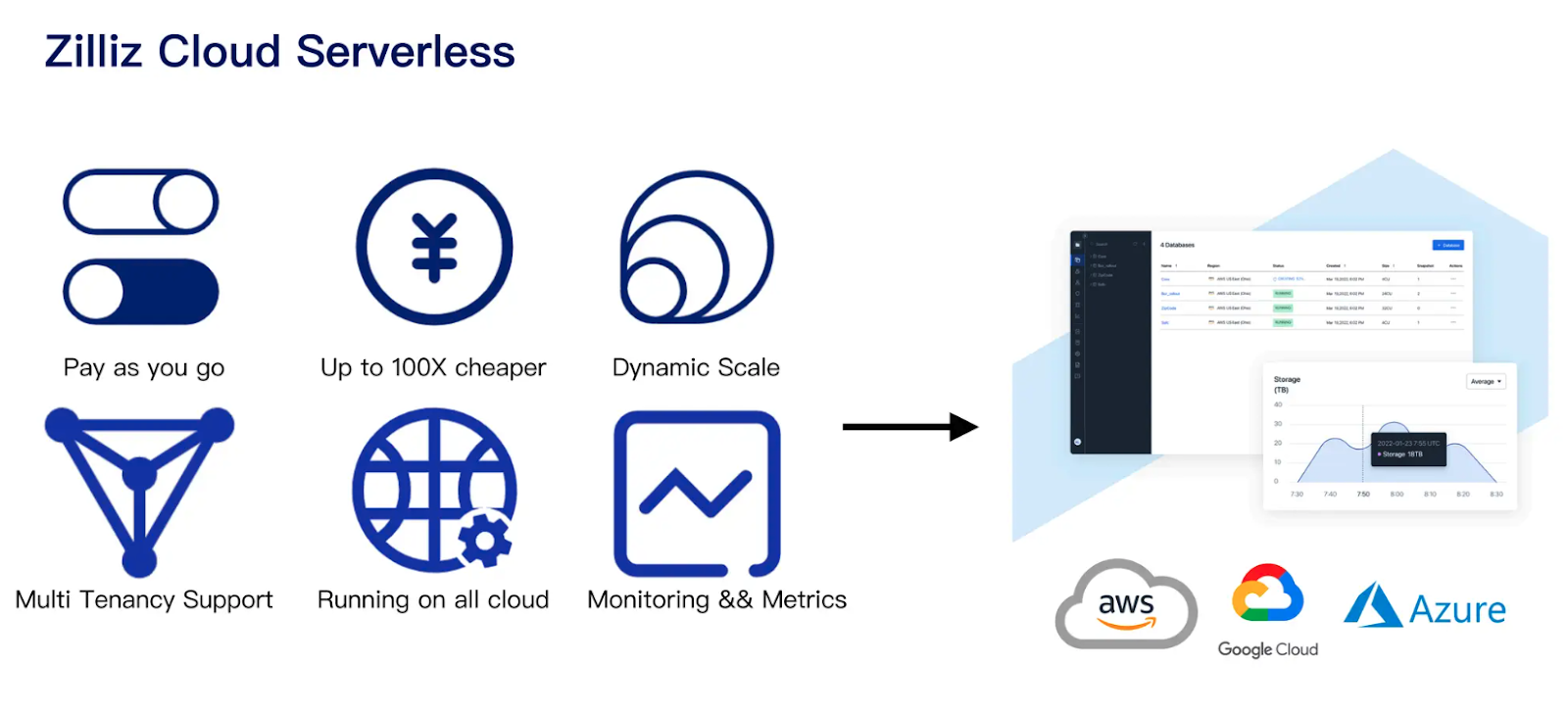 Figure 3- Zilliz Cloud Serverless Key Benefits
Figure 3- Zilliz Cloud Serverless Key Benefits
Zilliz Cloud Serverless implements four key technologies to optimize the cost of your AI applications:
Logical clusters and auto-scaling
Disaggregation of streaming and historical data
Tiered storage catered to different data storage needs
Multi-tenancy and hot-cold data separation
Let's now explore each of these technologies in greater depth.
Logical Clusters and Auto Scaling
Zilliz Cloud Serverless introduces the concept of logical clusters and auto-scaling. A logical cluster corresponds to a database in a physical cluster. A physical cluster consists of several node types, each with its own functionality:
Proxy nodes: Routes traffic, throttles requests based on quotas, and scales according to CPU and network bandwidth.
Streaming nodes: Serves streaming data search and scales based on write queue time and CPU/memory usage.
Query nodes: Handles historical data search requests and scales according to search queue time and CPU/memory.
Index nodes: Builds indexes on the blob data stored in object storage.
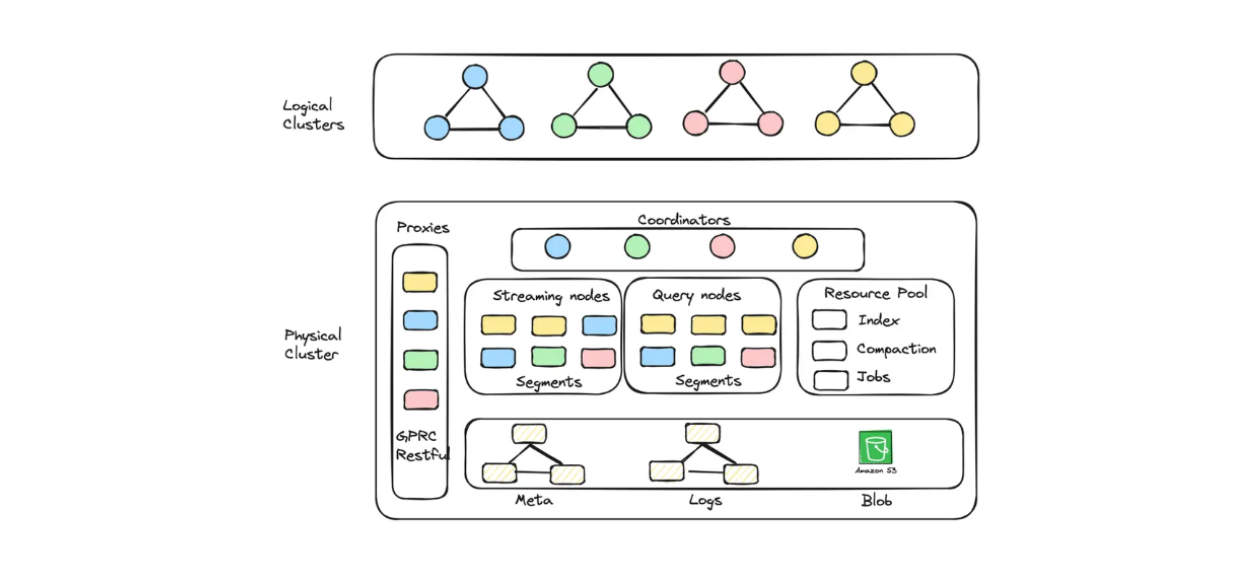 Figure 4: The diagram of logical clusters
Figure 4: The diagram of logical clusters
The logical cluster operates using an authentication mechanism for each tenant via an API key. Each tenant has a unique API key, which the system uses to route requests and ensure that the correct data is retrieved during query operations.
During data write operations, all data generated on-the-fly is stored for a specific time interval inside the streaming nodes. This ensures that fresh data can be retrieved with low latency. After a while, this streaming data is flushed into a blob storage (e.g S3), where the index node builds an index of all the data.
During query operations, all indexed data is cached on the local disks of query nodes. This method significantly reduces storage costs compared to in-memory indexing.
Disaggregation of Streaming and Historical Data
As discussed in the previous section, Zilliz Cloud Serverless effectively separates streaming data from historical data by implementing different node types in its architecture.
Streaming data refers to real-time, continuously generated data processed on the fly, while historical data refers to previously collected and stored data. The streaming data contains fresh, up-to-date information, which is stored inside the streaming nodes for a specific period, ensuring fast retrieval during query operations.
After a predetermined period, the data inside the streaming nodes is flushed into a blob storage, effectively becoming part of the historical data. This transition is crucial because blob storage is generally a more cost-effective solution for large volumes of data that don't require the same level of immediate access as real-time or fresh data.
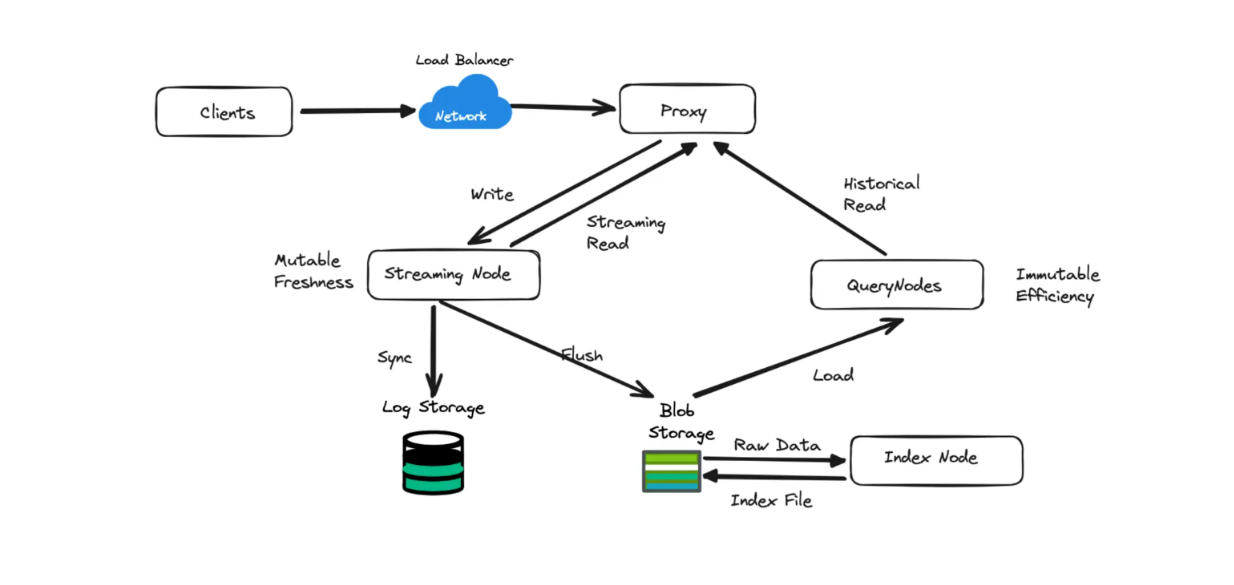 Figure 5- The workflow of different nodes in a logical cluster
Figure 5- The workflow of different nodes in a logical cluster
During search operations, all historical data is cached into query nodes. The system then merges the search results from streaming and query nodes to provide comprehensive results.
Tiered Storage
One primary reason for vector databases' high operational costs is that all data is stored in RAM. To address this issue, Zilliz Cloud Serverless introduces a tiered data storage technology in its architecture.
Tiered data storage is straightforward: data is organized into different levels based on performance requirements, cost, and access frequency. The general rule is that frequently accessed data is stored in more expensive, high-performance storage, while less frequently accessed data is stored in cheaper, slower storage. By implementing different storage tiers for each data category, we can optimize the overall cost of data storage.
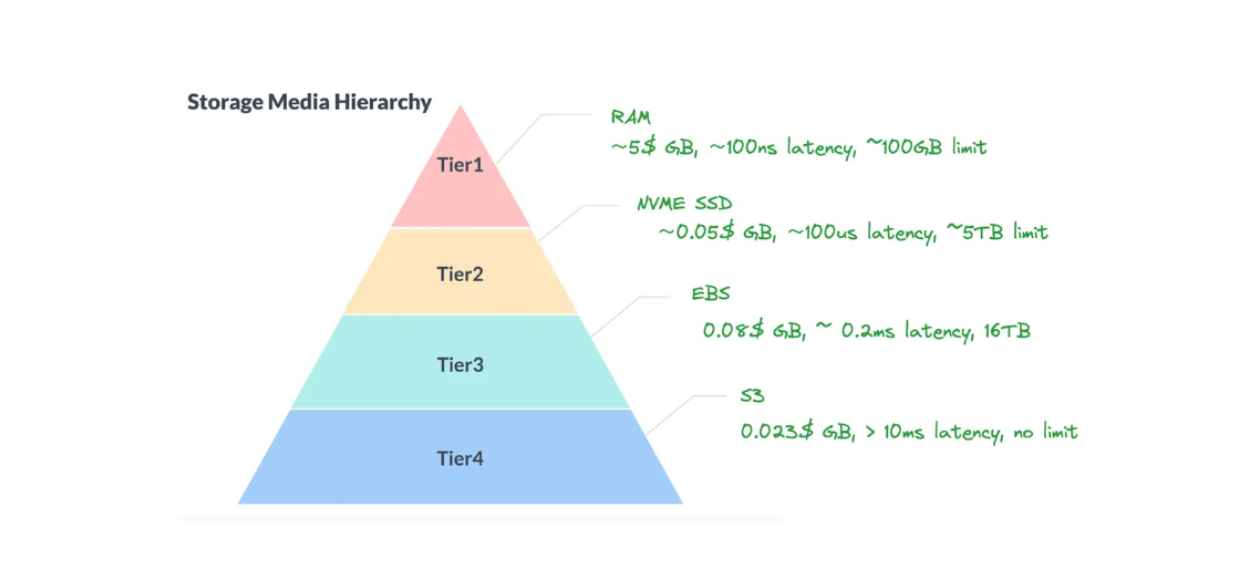 Figure 6- Tiered storage diagram
Figure 6- Tiered storage diagram
Frequently accessed data that needs to be retrieved with low latency is stored in RAM. As illustrated above, storing data in RAM costs approximately $5 per GB of storage. However, in return, we get results in approximately 100 nanoseconds, which is the fastest compared to other tiers.
On the other hand, less frequently accessed data is stored in blob storage, such as Amazon S3. This costs approximately $0.023 per GB of storage but takes more than 10 milliseconds to retrieve results.
Multi-Tenancy and Hot-Cold Separation
Zilliz Cloud Serverless introduces multi-layered data caching, particularly for multi-tenancy use cases. It distinguishes between data storage for "hot" and "cold" tenants.
A hot tenant is a highly active user who performs data searches or queries frequently. Conversely, a cold tenant is less active and conducts data searches infrequently.
When tenants are categorized as hot, their data is stored in local memory, ensuring low-latency retrieval. Meanwhile, if a tenant is categorized as cold and wants to perform a data search, all data must first be loaded from blob storage (e.g., S3), resulting in longer retrieval times than hot tenants.
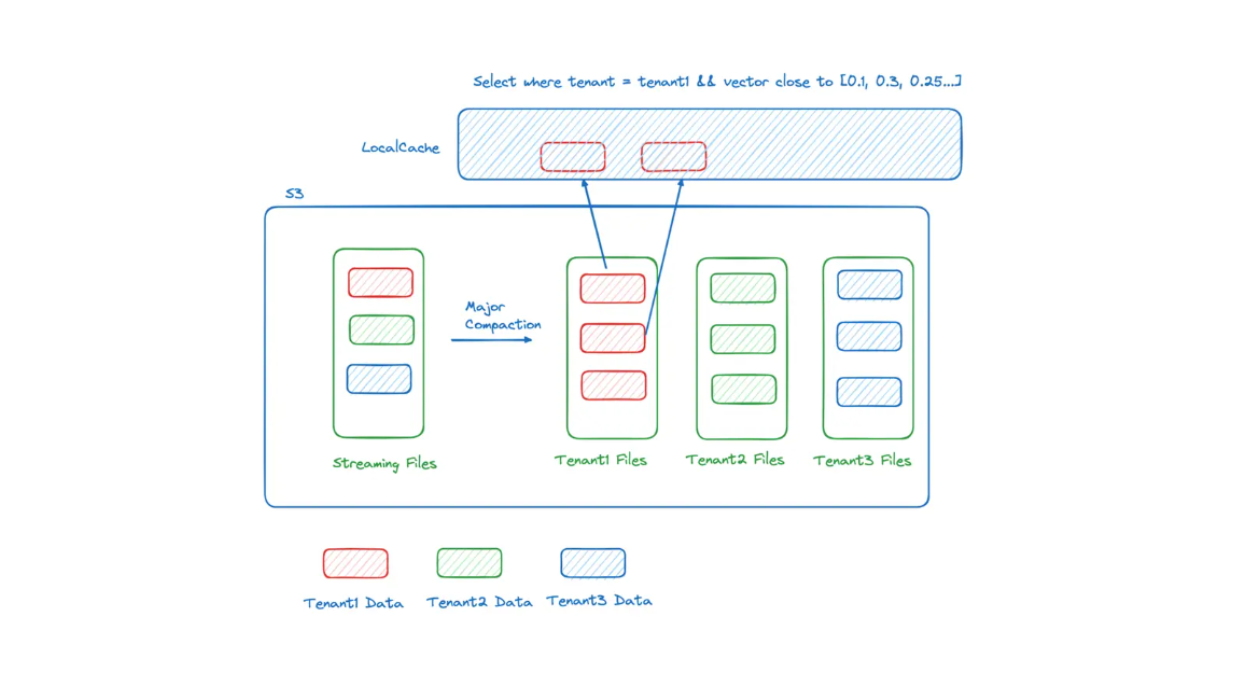 Figure 7: Hot-cold separation in a multi-tenant use case
Figure 7: Hot-cold separation in a multi-tenant use case
An application can be pre-warmed to improve latency by loading all data from blob storage into local memory. Then, when users access their AI application, the retrieval process can be completed with low latency.
Zilliz Cloud Serverless also implements data clustering by partition keys under the hood to further accelerate the data search process. During data retrieval, the system searches only data within promising partitions rather than all available data.
Below is a cost comparison between hot, warm, and cold searches:
| Cold Search | Warm Search | Hot Search | |
| 1M, 768Dim | 2.3s | 80ms | 4ms |
| 10M, 768Dim | 7s | 150ms | 7ms |
Table: Latency comparison between cold and hot search in a single tenant.
As illustrated, a cold search (where all data resides in blob storage) requires more time for data retrieval during search operations. For 10 million embeddings, each consisting of a 768-dimensional vector, the system needs approximately 7 seconds to complete a search operation. This speed is still acceptable for common generative AI use cases like RAG. In contrast, the same scenario requires only 7 milliseconds if all data resides in local memory.
However, performing a cold search results in significant cost savings. A database for cold search costs approximately 915 for a hot search. This amounts to a 50x cost saving from the Zilliz Cloud Serverless architecture.
What is New for Zilliz Cloud?
In addition to the serverless offering, Zilliz has recently announced new features in Zilliz Cloud to enhance support for running AI workloads in production environments. Here is a quick overview of these new additions and enhancements:
Serverless general availability (GA).
Migration Service ****for seamlessly transferring vector data between databases and other data systems
Fivetran Connector: a new integration with Fivetran that significantly expands the unstructured data ingestion capabilities from 500+ sources
Multi-replica: enables cluster-level replication, significantly improving query performance and system availability.
Auto-scaling (private preview): Zilliz Cloud is rolling out an auto-scaling feature in the private preview that addresses a common challenge in production environments: managing cluster capacity in response to fluctuating demands.
A New Zilliz Cloud Region Online: AWS Tokyo (ap-northeast-1), which means lower latency, better performance, and greater data sovereignty for users in Asia-Pacific and neighboring regions.
And more! For more detailed information, please read the latest Zilliz Cloud launch blog.
Conclusion
Zilliz Cloud Serverless represents the latest advancement implemented by Zilliz to optimize the operation and cost of AI application systems. By leveraging four key technologies, users can potentially operate their AI applications at a cost up to 50 times lower than in-memory vector databases. These technologies include logical clusters, streaming and historical data disaggregation, tiered storage, and multi-tenancy hot-cold separation.
If you'd like to get started with Zilliz Cloud Serverless, you can try it out for free. Visit this page to learn more!
Keep Reading

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.